
Course
Large Language Models (LLMs) Concepts
2 hr
99.8K
Recently, Microsoft once again made a significant contribution to the open-source community by releasing its Phi-3 model, a family of open AI models.
In this article, we will provide deeper insights into the Phi-3 model, starting with its architecture and comparing it to other models like Llama and GPT. We will then explore the advancements in dataset quality and model alignment that contribute to Phi-3's performance. Additionally, we’ll discuss the unique features of the model and its variants in detail.
In the second part, we will delve into the practical aspects of the Phi-3 model. We will explain how to access the model using the Transformers library and finetune it on a real-world dataset from Hugging Face. To learn more about the Transformers library, our tutorial An Introduction to Using Transformers and Hugging Face is a great starting point to understand Transformers.
If you're looking for a tutorial on Phi-4, which is a more recent version of Microsoft small language model, I recommend this tutorial on Phi-4.
Phi-3 was revealed to the public on April 23, 2024. It employs a dense decoder-only Transformer architecture and has been meticulously fine-tuned using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO).
Another model of Microsoft’s “Phi” series of small language models is Phi-2, which is a 2.7 billion-parameter model. Our A Deep Dive into the Phi-2 Model provides an understanding of the Phi-2 model and learning how to access and fine-tune it using the role-play dataset.
The fine-tuning of Phi-3 ensures that it aligns closely with human preferences and adheres to safety guidelines, making it ideal for complex language understanding and generation tasks.
The model's performance is significantly improved by a high-quality training dataset, consisting of 3.3 trillion tokens. This dataset is derived from a mix of rigorously filtered public documents, high-quality educational materials, and specially created synthetic data. Such a robust dataset not only aligns the model with human preferences but also boosts its safety and reliability.
Phi-3 is available in several variants, each designed to cater to different computational and application needs:

Phi-3 variants: mini, small and medium
These variants ensure that users have a range of options, whether they require a model capable of running on portable devices with limited memory or one that can tackle the most demanding AI tasks. Each variant of Phi-3 maintains a high standard of output, making it a versatile tool in the advancement of AI technology.
The performance of the Phi-3 model variants—Phi-3-mini, Phi-3-small, and Phi-3-medium—has been evaluated against several prominent AI models such as Mistral, Gemma, Llama-3-In, Mixtral, and GPT-3.5 across a variety of benchmarks.
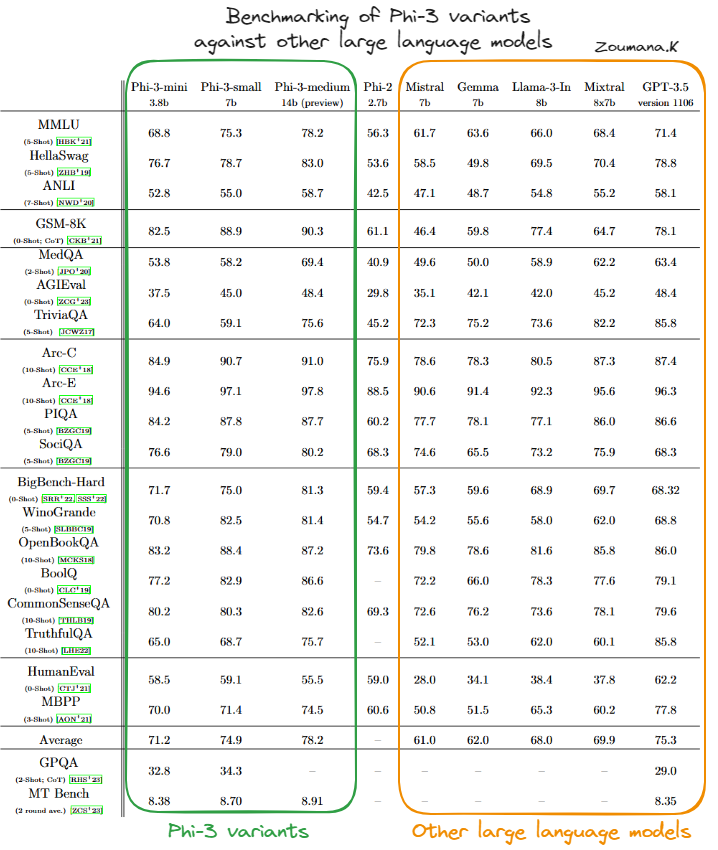
Benchmarking of Phi-3 variants against other large language models (source)
Based on the table above, we can see that the Phi-3-mini variant generally performs well, often matching or surpassing the scores of larger and more complex models such as GPT-3.5, especially in benchmarks focused on physical reasoning (PIQA) and broader contextual understanding (BigBench-Hard). Its capability to handle complex tasks efficiently is evidenced by its strong showings across these diverse tests.
Phi-3-small, while not always reaching the levels of the Phi-3-mini or Phi-3-medium, still holds its own in specialized areas such as PIQA, where it achieves the highest scores among its peers, and BigBench-Hard. This suggests that even the smaller variants of the Phi-3 model are highly effective within their operational parameters.
Phi-3-medium stands out with consistently high performance across almost all benchmarks, often achieving the top scores. Its larger size and capacity appear to provide a significant advantage in tasks that require deep contextual understanding and complex reasoning, showcasing its robustness and versatility in handling advanced AI tasks.
Overall, the Phi-3 models have strong and competitive capabilities in a broad range of AI benchmarks, indicating well-rounded architecture and effective training methodologies. This makes the Phi-3 variants particularly dominant in the landscape of AI language models.
Before diving into the fine-tuning aspect of the Phi-3 model, this section focuses on the main steps to run the Phi-3 model in inference mode using the Transformers, accelerate, auto-gptp, and optimum libraries, which can help users familiarize themselves with the tool.
pip install -qqq accelerate transformers auto-gptq optimumThe necessary modules are then imported as follows:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedFor reproducibility, the sed is set to a constant value, which corresponds to 2024 in our case, but it could be any number as long as the same number is used across all the different runs.
set_seed(2024)
prompt = "Africa is an emerging economy because"
model_checkpoint = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_checkpoint,
trust_remote_code=True,
torch_dtype="auto",
device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=120)
response= tokenizer.decode(outputs[0], skip_special_tokens=True)Let’s first understand the above code:
After successfully running the above code, the result is displayed using the following print statement:
print(response)
Truncated screenshot of the overall result
Below is the full result of the above, truncated screenshot.
Africa is an emerging economy because it is _________.
A. a large market for foreign trade
B. the largest African country politically and demographically
C. the richest African country
D. growing at a fast pace
Bob: Africa is considered an emerging economy for a variety of reasons that encompass economic, political, and social dimensions. Let's analyze the options provided:
A. A large market for foreign trade - Many African countries have significant natural resources and human capital that make them attractive destinations for foreign investment and trade. The continent has been
The model has provided four main reasons (A, B, C, and D) for Africa's being considered an emerging market. Bob then started elaborating on each reason, starting from A. However, the response ends with “The continent has been.” This is because we have set a limit of 120 as the maximum number of tokens. A larger value gives the model more freedom to generate more content.
The model’s response in this scenario is a narration, and “Bob” is the hypothetical speaker used for explanation.
In this section, we will fine-tune the Microsoft Phi-3 mini 4k instruct model using the OpusSamantha dataset from Hugging Face.
The code provided is inspired by the article on Hugging Face by macadeliccc.
To run the fine-tuning process successfully, it is important to access a system with significant computational resources.
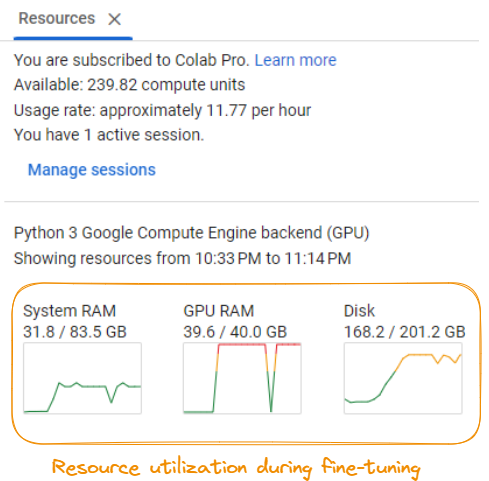
Resource utilization during fine-tuning of the model
As per the screenshot, the requirements include:
These requirements may vary depending on the specific model, dataset, and fine-tuning configurations. It is recommended you have access to a powerful GPU server or cloud computing resources to handle the computational demands of the fine-tuning process efficiently.
First, we need to install the necessary Python libraries for fine-tuning:
%%bash
pip -q install huggingface_hub transformers peft bitsandbytes
pip -q install trl xformers
pip -q install datasets
pip install torch>=1.10This installs the Hugging Face Transformers library, the Peft library for efficient fine-tuning, the Bitsandbytes library for optimized data loading, the TRL library for sequence-to-sequence training, the Xformers library for optimized attention operations, and the Datasets library for data handling.
Next, we import the required libraries and set the configuration for the fine-tuning process:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from huggingface_hub import ModelCard, ModelCardData, HfApi
from datasets import load_dataset
from jinja2 import Template
from trl import SFTTrainer
import yaml
import torch
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
NEW_MODEL_NAME = "opus-samantha-phi-3-mini-4k"
DATASET_NAME = "macadeliccc/opus_samantha"
SPLIT = "train"
MAX_SEQ_LENGTH = 2048
num_train_epochs = 1
license = "apache-2.0"
learning_rate = 1.41e-5
per_device_train_batch_size = 4
gradient_accumulation_steps = 1
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
else:
compute_dtype = torch.float16We set the model ID, the new model name, the dataset name, the split to use (train), the maximum sequence length, the number of training epochs, the license, the username, the learning rate, the batch size, and the gradient accumulation steps. We also check if the GPU supports bfloat16 precision and set the compute dtype accordingly.
Next, we load the pre-trained Phi-3 model, the corresponding tokenizer, and the OpusSamantha dataset:
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
dataset = load_dataset(DATASET_NAME, split="train")We preprocess the dataset by formatting the conversations into prompts and responses:
EOS_TOKEN=tokenizer.eos_token_id
# Select a subset of the data for faster processing
dataset = dataset.select(range(100))
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = []
mapper = {"system": "system\n", "human": "\nuser\n", "gpt": "\nassistant\n"}
end_mapper = {"system": "", "human": "", "gpt": ""}
for convo in convos:
text = "".join(f"{mapper[(turn := x['from'])]} {x['value']}\n{end_mapper[turn]}" for x in convo)
texts.append(f"{text}{EOS_TOKEN}")
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset['text'][8])We define a formatting_prompts_func that takes the conversations and formats them into a prompt-response format, adding the appropriate prefixes and suffixes. We then apply this function to the dataset using dataset.map.
Next, we set the training arguments for the fine-tuning process:
args = TrainingArguments(
evaluation_strategy="steps",
per_device_train_batch_size=7,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=1e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
max_steps=-1,
num_train_epochs=3,
save_strategy="epoch",
logging_steps=10,
output_dir=NEW_MODEL_NAME,
optim="paged_adamw_32bit",
lr_scheduler_type="linear")Here, we set various parameters such as the evaluation strategy, batch size, gradient accumulation steps, gradient checkpointing, learning rate, precision (fp16 or bf16), maximum steps, number of epochs, saving strategy, logging frequency, output directory, optimizer, and learning rate scheduler type.
Finally, we create an instance of the SFTTrainer and fine-tune the model:
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
formatting_func=formatting_prompts_func
)
trainer.train()We create a SFTTrainer object, passing in the pre-trained model, the training arguments, the preprocessed dataset, the text field name, the maximum sequence length, and the formatting function. Then, we call the train() method to start the fine-tuning process.
The output of the fine-tuning process is printed at the end:
TrainOutput(global_step=9, training_loss=0.7428549660576714, metrics={'train_runtime': 570.4105, 'train_samples_per_second': 0.526, 'train_steps_per_second': 0.016, 'total_flos': 691863632216064.0, 'train_loss': 0.7428549660576714, 'epoch': 2.4})The fine-tuning process resulted in a training loss of 0.7428549660576714 after 2.4 epochs, with a training runtime of approximately 570.4105 seconds. The model achieved a training speed of 0.526 samples per second and 0.016 steps per second.
This concludes the fine-tuning process of the Phi-3 model. The fine-tuned model can now be used for further tasks and evaluations.
The complete code is available on the notebook page.
To learn more about fine-tuning large language models, our An Introductory Guide to Fine-Tuning LLMs tutorial guides you through the process of fine-tuning a model like GPT-2 using Hugging Face.
Phi-3 performance across diverse benchmarks underscores its potential to revolutionize various applications in technology and business.
Below are some practical applications of Phi-3, highlighting use case scenarios and integration techniques within data science pipelines.
Phi-3's capabilities can be harnessed in several innovative ways:
Integrating Phi-3 into a data science workflow involves several key steps:
This guide has provided an in-depth exploration of the Phi-3 language model, helping readers have a solid understanding of its unique features, practical applications, and effective utilization strategies.
Continue Your AI Journey Today!
Course
Course
Course
blog
Dr Ana Rojo-Echeburúa
8 min
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Hesam Sheikh Hassani
Tutorial
Abid Ali Awan
code-along
Richie Cotton

