Curso
Machine learning con modelos basados en árboles en Python
5 h
116.4K
Antes de aplicar la PPO, tenemos que instalar las bibliotecas de software necesarias y elegir un entorno adecuado para aplicar la política.
Necesitamos instalar el siguiente software:
numpy (para funciones matemáticas y estadísticas) y matplotlib (para trazar gráficos).gym a veces cambia durante el proceso de actualización, en este ejemplo, congelamos su versión a 0.25.2. Para instalarlo en un servidor o en una máquina local, ejecuta
$ pip install torch numpy matplotlib gym==0.25.2Para instalarlo utilizando un bloc de notas como Google Colabo DataLab, utiliza
!pip install torch numpy matplotlib gym==0.25.2Utiliza OpenAI Gym para crear dos instancias (una para entrenamiento y otra para pruebas) del entorno CartPole:
env_train = gym.make('CartPole-v1')
env_test = gym.make('CartPole-v1')Ahora, vamos a implementar PPO utilizando PyTorch.
Como ya se ha explicado, la OPP se aplica como un modelo actor-crítico. El actor aplica la política, y el crítico predice su valor estimado. Tanto las redes neuronales de actores como las de críticos toman la misma entrada: el estado en cada paso temporal. Así, los modelos de actor y de crítico pueden compartir una red neuronal común, que se denomina arquitectura troncal. El actor y el crítico pueden ampliar la arquitectura troncal con capas adicionales.
Los siguientes pasos describen la red troncal:
El código siguiente implementa la columna vertebral:
class BackboneNetwork(nn.Module):
def __init__(self, in_features, hidden_dimensions, out_features, dropout):
super().__init__()
self.layer1 = nn.Linear(in_features, hidden_dimensions)
self.layer2 = nn.Linear(hidden_dimensions, hidden_dimensions)
self.layer3 = nn.Linear(hidden_dimensions, out_features)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.layer1(x)
x = f.relu(x)
x = self.dropout(x)
x = self.layer2(x)
x = f.relu(x)
x = self.dropout(x)
x = self.layer3(x)
return xAhora podemos utilizar esta red para definir la clase actor-crítico, ActorCritic. El actor modela la política y predice la acción. El crítico modela la función de valor y predice el valor. Ambos toman el estado como entrada.
class ActorCritic(nn.Module):
def __init__(self, actor, critic):
super().__init__()
self.actor = actor
self.critic = critic
def forward(self, state):
action_pred = self.actor(state)
value_pred = self.critic(state)
return action_pred, value_predUtilizaremos las redes definidas anteriormente para crear un actor y un crítico. A continuación, crearemos un agente, que incluirá al actor y al crítico.
Antes de crear el agente, inicializa los parámetros de la red:
El código siguiente muestra cómo declarar las redes de actores y críticos en función de la red troncal:
def create_agent(hidden_dimensions, dropout):
INPUT_FEATURES = env_train.observation_space.shape[0]
HIDDEN_DIMENSIONS = hidden_dimensions
ACTOR_OUTPUT_FEATURES = env_train.action_space.n
CRITIC_OUTPUT_FEATURES = 1
DROPOUT = dropout
actor = BackboneNetwork(
INPUT_FEATURES, HIDDEN_DIMENSIONS, ACTOR_OUTPUT_FEATURES, DROPOUT)
critic = BackboneNetwork(
INPUT_FEATURES, HIDDEN_DIMENSIONS, CRITIC_OUTPUT_FEATURES, DROPOUT)
agent = ActorCritic(actor, critic)
return agentEl entorno da una recompensa que va de cada paso al siguiente, en función de la acción del agente. La recompensa, R, se expresa como
![]()
El rendimiento se define como el valor acumulado de las recompensas futuras esperadas. Las recompensas de pasos temporales más lejanos en el futuro son menos valiosas que las recompensas inmediatas. Así, la rentabilidad se calcula comúnmente como la rentabilidad descontada, G, definida como:
![]()
En este tutorial (y en muchas otras referencias), rendimiento se refiere al rendimiento descontado.
Para calcular el rendimiento:
La función calculate_returns() realiza estos cálculos, como se muestra a continuación:
def calculate_returns(rewards, discount_factor):
returns = []
cumulative_reward = 0
for r in reversed(rewards):
cumulative_reward = r + cumulative_reward * discount_factor
returns.insert(0, cumulative_reward)
returns = torch.tensor(returns)
# normalize the return
returns = (returns - returns.mean()) / returns.std()
return returnsLa ventaja se calcula como la diferencia entre el valor predicho por el crítico y el rendimiento esperado de las acciones elegidas por el actor según la política. Para una acción determinada, la ventaja expresa el beneficio de realizar esa acción concreta frente a una acción arbitraria (media).
En el documento PPO original (ecuación 10), la ventaja, mirando hacia adelante hasta el paso temporal T se expresa como:
![]()
Al codificar el algoritmo, la restricción de mirar hacia delante hasta un número determinado de pasos de tiempo se aplica mediante el tamaño del lote. Así pues, la ecuación anterior puede simplificarse como la diferencia entre el valor y los rendimientos esperados. Los rendimientos esperados se cuantifican en la función de valor estado-acción, Q.
Así pues, la fórmula simplificada que figura a continuación expresa la ventaja de elegir:
Esto se expresa como
![]()
OpenAI también utiliza esta fórmula para aplicar la RL. La función calculate_advantages() que se muestra a continuación calcula la ventaja:
def calculate_advantages(returns, values):
advantages = returns - values
# Normalize the advantage
advantages = (advantages - advantages.mean()) / advantages.std()
return advantagesLa pérdida de la póliza sería la pérdida estándar del gradiente de la póliza, sin técnicas especiales como la PPO. La pérdida de gradiente de la política estándar se calcula como el producto de:
La pérdida de gradiente de la política estándar no puede hacer correcciones por cambios bruscos de política. La pérdida sustitutiva modifica la pérdida estándar para restringir la cantidad que puede cambiar la política en cada iteración. Es el mínimo de dos cantidades:
Para el proceso de optimización, la pérdida sustitutiva se utiliza como sustituto de la pérdida real.
La ratio de la política, Res la diferencia entre la política nueva y la antigua, y viene dada por el cociente de las probabilidades logarítmicas de la política con los parámetros nuevos y antiguos:
![]()
La ratio de la política recortada, R'se limita de modo que
![]()
Dada la ventaja, Atcomo se ha indicado en el apartado anterior, y el coeficiente de la política, como se ha indicado anteriormente, la pérdida sustitutiva se calcula como:
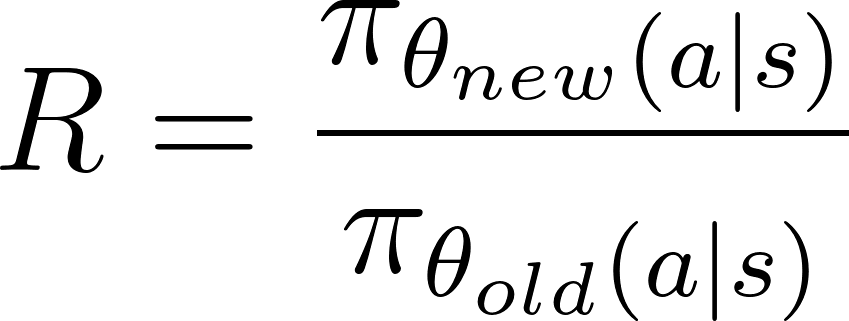
El código siguiente muestra cómo aplicar el mecanismo de recorte y la pérdida sustitutiva.
def calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages):
advantages = advantages.detach()
policy_ratio = (
actions_log_probability_new - actions_log_probability_old
).exp()
surrogate_loss_1 = policy_ratio * advantages
surrogate_loss_2 = torch.clamp(
policy_ratio, min=1.0-epsilon, max=1.0+epsilon
) * advantages
surrogate_loss = torch.min(surrogate_loss_1, surrogate_loss_2)
return surrogate_lossAhora, vamos a entrenar al agente.
Ahora estamos preparados para calcular las pérdidas de la póliza y del valor:
Ambas pérdidas, tal como se han calculado anteriormente, son tensores. El descenso gradual se basa en valores escalares. Para obtener un único valor escalar que represente la pérdida, utiliza la función .sum() para sumar los elementos del tensor. La siguiente función muestra cómo hacerlo:
def calculate_losses(
surrogate_loss, entropy, entropy_coefficient, returns, value_pred):
entropy_bonus = entropy_coefficient * entropy
policy_loss = -(surrogate_loss + entropy_bonus).sum()
value_loss = f.smooth_l1_loss(returns, value_pred).sum()
return policy_loss, value_lossAntes de iniciar el proceso de entrenamiento, crea un conjunto de buffers como matrices vacías. El algoritmo de entrenamiento utilizará estos búferes para almacenar información sobre las acciones del agente, los estados del entorno y las recompensas en cada paso temporal. La siguiente función inicializa estos búferes:
def init_training():
states = []
actions = []
actions_log_probability = []
values = []
rewards = []
done = False
episode_reward = 0
return states, actions, actions_log_probability, values, rewards, done, episode_rewardCada iteración de entrenamiento ejecuta el agente con los parámetros de la política para esa iteración. El agente interactúa con el entorno en pasos de tiempo en un bucle hasta que alcanza una condición terminal.
Después de cada paso temporal, la acción, la recompensa y el valor del agente se añaden a los búferes respectivos. Cuando termina el episodio, la función devuelve el conjunto actualizado de buffers, que resumen los resultados del episodio.
Antes de ejecutar el bucle de entrenamiento:
agent.train(). env.reset(). Este es el estado inicial para esta iteración de entrenamiento. Los pasos siguientes explican lo que ocurre en cada paso temporal del bucle de entrenamiento:
dist.sample() lo hace. env.step() para pasar esta acción al entorno y simular la respuesta del entorno para este paso de tiempo. En función de la acción del agente, el entorno genera:done (indica si el entorno ha alcanzado un estado terminal)El episodio de entrenamiento termina cuando la función env.step() devuelve true para el valor booleano de retorno de done.
Una vez finalizado el episodio, utiliza los valores acumulados de cada paso temporal para calcular los rendimientos acumulados de este episodio sumando las recompensas de cada paso temporal. Para ello utilizamos la función calculate_returns() descrita anteriormente. Las entradas de esta función son el factor de descuento y el búfer que contiene las recompensas de cada paso temporal. Utilizamos estos rendimientos y los valores acumulados de cada paso temporal para calcular las ventajas mediante la función calculate_advantages().
La siguiente función de Python muestra cómo llevar a cabo estos pasos:
def forward_pass(env, agent, optimizer, discount_factor):
states, actions, actions_log_probability, values, rewards, done, episode_reward = init_training()
state = env.reset()
agent.train()
while not done:
state = torch.FloatTensor(state).unsqueeze(0)
states.append(state)
action_pred, value_pred = agent(state)
action_prob = f.softmax(action_pred, dim=-1)
dist = distributions.Categorical(action_prob)
action = dist.sample()
log_prob_action = dist.log_prob(action)
state, reward, done, _ = env.step(action.item())
actions.append(action)
actions_log_probability.append(log_prob_action)
values.append(value_pred)
rewards.append(reward)
episode_reward += reward
states = torch.cat(states)
actions = torch.cat(actions)
actions_log_probability = torch.cat(actions_log_probability)
values = torch.cat(values).squeeze(-1)
returns = calculate_returns(rewards, discount_factor)
advantages = calculate_advantages(returns, values)
return episode_reward, states, actions, actions_log_probability, advantages, returnsCada iteración de entrenamiento ejecuta el modelo a través de un episodio completo que consta de muchos pasos temporales (hasta que alcanza una condición terminal). En cada paso temporal, almacenamos los parámetros de la política, la acción del agente, los rendimientos y las ventajas. Después de cada iteración, actualizamos el modelo basándonos en el rendimiento de la política en todos los pasos temporales de esa iteración.
El número máximo de pasos de tiempo en el entorno CartPole es 500. En entornos más complejos, hay más pasos temporales, incluso millones. En tales casos, el conjunto de datos de los resultados del entrenamiento debe dividirse en lotes. El número de pasos de tiempo de cada lote se denomina tamaño del lote de optimización.
Así, los pasos para actualizar los parámetros del modelo son:
.backward() por separado en la póliza y valora las pérdidas. Así se actualizan los gradientes de las funciones de pérdida. .step() en el optimizador para actualizar los parámetros de la política. En este caso, utilizamos el optimizador Adam para equilibrar velocidad y robustez. PPO_STEPS. Repetir el paso hacia atrás en cada lote es eficiente desde el punto de vista informático, porque aumenta efectivamente el tamaño del conjunto de datos de entrenamiento sin tener que ejecutar pases hacia delante adicionales. El número de pasos del entorno en cada alternancia entre muestreo y optimización se denomina tamaño del lote de iteración. El código siguiente implementa estos pasos:
def update_policy(
agent,
states,
actions,
actions_log_probability_old,
advantages,
returns,
optimizer,
ppo_steps,
epsilon,
entropy_coefficient):
BATCH_SIZE = 128
total_policy_loss = 0
total_value_loss = 0
actions_log_probability_old = actions_log_probability_old.detach()
actions = actions.detach()
training_results_dataset = TensorDataset(
states,
actions,
actions_log_probability_old,
advantages,
returns)
batch_dataset = DataLoader(
training_results_dataset,
batch_size=BATCH_SIZE,
shuffle=False)
for _ in range(ppo_steps):
for batch_idx, (states, actions, actions_log_probability_old, advantages, returns) in enumerate(batch_dataset):
# get new log prob of actions for all input states
action_pred, value_pred = agent(states)
value_pred = value_pred.squeeze(-1)
action_prob = f.softmax(action_pred, dim=-1)
probability_distribution_new = distributions.Categorical(
action_prob)
entropy = probability_distribution_new.entropy()
# estimate new log probabilities using old actions
actions_log_probability_new = probability_distribution_new.log_prob(actions)
surrogate_loss = calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages)
policy_loss, value_loss = calculate_losses(
surrogate_loss,
entropy,
entropy_coefficient,
returns,
value_pred)
optimizer.zero_grad()
policy_loss.backward()
value_loss.backward()
optimizer.step()
total_policy_loss += policy_loss.item()
total_value_loss += value_loss.item()
return total_policy_loss / ppo_steps, total_value_loss / ppo_stepsPor último, pongamos en marcha al agente PPO.
Para evaluar el rendimiento del agente, crea un nuevo entorno y calcula las recompensas acumuladas al ejecutar el agente en este nuevo entorno. Tienes que poner al agente en modo evaluación utilizando la función .eval(). Los pasos son los mismos que para el bucle de entrenamiento. El fragmento de código siguiente implementa la función de evaluación:
def evaluate(env, agent):
agent.eval()
rewards = []
done = False
episode_reward = 0
state = env.reset()
while not done:
state = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
action_pred, _ = agent(state)
action_prob = f.softmax(action_pred, dim=-1)
action = torch.argmax(action_prob, dim=-1)
state, reward, done, _ = env.step(action.item())
episode_reward += reward
return episode_rewardUtilizaremos la biblioteca Matplotlib para visualizar el progreso del proceso de entrenamiento. La función siguiente muestra cómo trazar las recompensas de los bucles de entrenamiento y de prueba:
def plot_train_rewards(train_rewards, reward_threshold):
plt.figure(figsize=(12, 8))
plt.plot(train_rewards, label='Training Reward')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Training Reward', fontsize=20)
plt.hlines(reward_threshold, 0, len(train_rewards), color='y')
plt.legend(loc='lower right')
plt.grid()
plt.show()def plot_test_rewards(test_rewards, reward_threshold):
plt.figure(figsize=(12, 8))
plt.plot(test_rewards, label='Testing Reward')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Testing Reward', fontsize=20)
plt.hlines(reward_threshold, 0, len(test_rewards), color='y')
plt.legend(loc='lower right')
plt.grid()
plt.show()En los gráficos de ejemplo que aparecen a continuación, mostramos las recompensas de entrenamiento y de prueba, obtenidas al aplicar la política en los entornos de entrenamiento y de prueba, respectivamente. Ten en cuenta que la forma de estos gráficos será diferente cada vez que ejecutes el código. Esto se debe a la aleatoriedad inherente al proceso de entrenamiento.
Recompensas de entrenamiento (obtenidas aplicando la política en el entorno de entrenamiento). Imagen del autor.
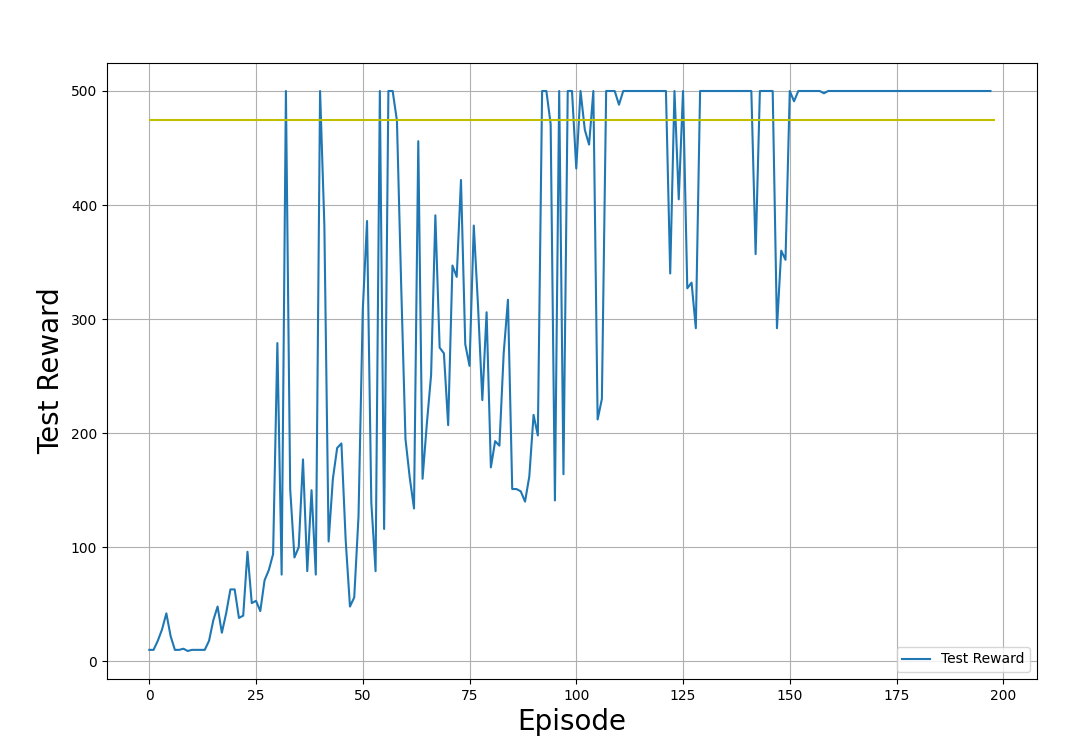
Recompensas de prueba (obtenidas aplicando la política en el entorno de prueba). Imagen del autor.
En los gráficos de salida mostrados arriba, observa el progreso del proceso de entrenamiento:
Del mismo modo, puedes trazar el valor y las pérdidas de la póliza a través de las iteraciones:
def plot_losses(policy_losses, value_losses):
plt.figure(figsize=(12, 8))
plt.plot(value_losses, label='Value Losses')
plt.plot(policy_losses, label='Policy Losses')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Loss', fontsize=20)
plt.legend(loc='lower right')
plt.grid()
plt.show()El gráfico de ejemplo de abajo muestra las pérdidas seguidas a lo largo de los episodios de entrenamiento:
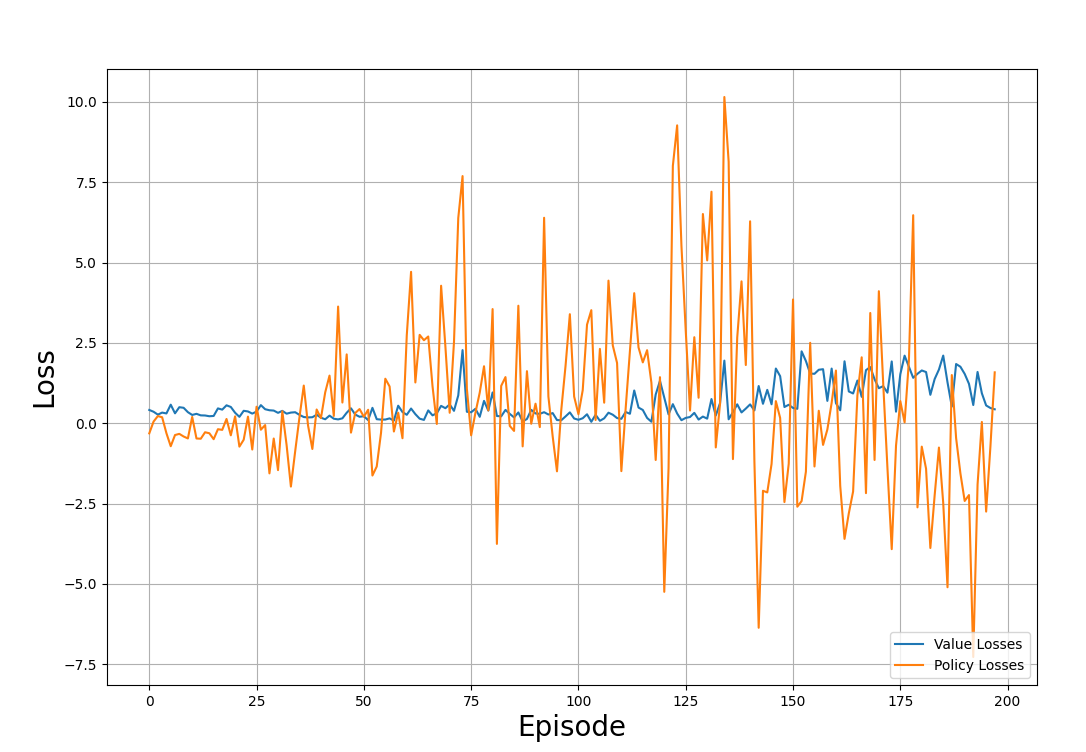
Valor y pérdidas de pólizas a través del proceso de formación. Imagen del autor
Observa la trama y date cuenta:
Ahora tienes todos los componentes para formar al agente mediante PPO. Para ponerlo todo junto, necesitas
create_agent().forward_pass() y update_policy(). evaluate(). El código siguiente muestra cómo declarar una función que haga esto en Python:
def run_ppo():
MAX_EPISODES = 500
DISCOUNT_FACTOR = 0.99
REWARD_THRESHOLD = 475
PRINT_INTERVAL = 10
PPO_STEPS = 8
N_TRIALS = 100
EPSILON = 0.2
ENTROPY_COEFFICIENT = 0.01
HIDDEN_DIMENSIONS = 64
DROPOUT = 0.2
LEARNING_RATE = 0.001
train_rewards = []
test_rewards = []
policy_losses = []
value_losses = []
agent = create_agent(HIDDEN_DIMENSIONS, DROPOUT)
optimizer = optim.Adam(agent.parameters(), lr=LEARNING_RATE)
for episode in range(1, MAX_EPISODES+1):
train_reward, states, actions, actions_log_probability, advantages, returns = forward_pass(
env_train,
agent,
optimizer,
DISCOUNT_FACTOR)
policy_loss, value_loss = update_policy(
agent,
states,
actions,
actions_log_probability,
advantages,
returns,
optimizer,
PPO_STEPS,
EPSILON,
ENTROPY_COEFFICIENT)
test_reward = evaluate(env_test, agent)
policy_losses.append(policy_loss)
value_losses.append(value_loss)
train_rewards.append(train_reward)
test_rewards.append(test_reward)
mean_train_rewards = np.mean(train_rewards[-N_TRIALS:])
mean_test_rewards = np.mean(test_rewards[-N_TRIALS:])
mean_abs_policy_loss = np.mean(np.abs(policy_losses[-N_TRIALS:]))
mean_abs_value_loss = np.mean(np.abs(value_losses[-N_TRIALS:]))
if episode % PRINT_INTERVAL == 0:
print(f'Episode: {episode:3} | \
Mean Train Rewards: {mean_train_rewards:3.1f} \
| Mean Test Rewards: {mean_test_rewards:3.1f} \
| Mean Abs Policy Loss: {mean_abs_policy_loss:2.2f} \
| Mean Abs Value Loss: {mean_abs_value_loss:2.2f}')
if mean_test_rewards >= REWARD_THRESHOLD:
print(f'Reached reward threshold in {episode} episodes')
break
plot_train_rewards(train_rewards, REWARD_THRESHOLD)
plot_test_rewards(test_rewards, REWARD_THRESHOLD)
plot_losses(policy_losses, value_losses)Ejecuta el programa:
run_ppo()El resultado debe parecerse a la muestra de abajo:
Episode: 10 | Mean Train Rewards: 22.3 | Mean Test Rewards: 30.4 | Mean Abs Policy Loss: 0.37 | Mean Abs Value Loss: 0.39
Episode: 20 | Mean Train Rewards: 38.6 | Mean Test Rewards: 69.8 | Mean Abs Policy Loss: 0.46 | Mean Abs Value Loss: 0.37
.
.
.
Episode: 100 | Mean Train Rewards: 289.5 | Mean Test Rewards: 427.3 | Mean Abs Policy Loss: 1.73 | Mean Abs Value Loss: 0.21
Episode: 110 | Mean Train Rewards: 357.7 | Mean Test Rewards: 461.4 | Mean Abs Policy Loss: 1.86 | Mean Abs Value Loss: 0.22
Reached reward threshold in 116 episodes¡Puedes ver y ejecutar elprograma de trabajo en este cuaderno DataLab!
En el aprendizaje automático, los hiperparámetros controlan el proceso de entrenamiento. A continuación, explico algunos de los hiperparámetros importantes utilizados en la OPP:
PPO_STEPS. En entornos complejos, ejecutar el pase hacia delante muchas veces es costoso desde el punto de vista informático. Una alternativa más eficaz es volver a ejecutar cada lote varias veces. Normalmente se recomienda utilizar un valor entre 5 y 10. N_TRIALS. Cuando se ajusta a un valor más alto, el entrenamiento lleva más tiempo porque la política tiene que alcanzar el umbral de recompensa en más episodios. También da lugar a una política más robusta, aunque es computacionalmente más cara. Ten en cuenta que la PPO es una política estocástica, y habrá episodios en los que el agente no cruce el umbral. Por tanto, si el valor de N_TRIALS es demasiado alto, puede que tu entrenamiento no termine.Optimizar el rendimiento de los algoritmos PPO de entrenamiento implica ensayo y error y experimentar con distintos valores de hiperparámetros. Sin embargo, existen algunas directrices generales:
Tras explicar los conceptos de la PPO y los detalles de su implantación, vamos a hablar de los retos y las mejores prácticas.
Aunque la OPP se utiliza ampliamente, debes ser consciente de los retos potenciales para resolver problemas del mundo real utilizando esta técnica con éxito. Algunos de estos retos son:
Para obtener buenos resultados utilizando PPO, recomiendo algunas prácticas recomendadas, como:
PPO_STEPS. En este artículo hablamos de la OPP como forma de resolver los problemas de RL. A continuación, detallamos los pasos para poner en práctica la OPP utilizando PyTorch. Por último, presentamos algunos consejos de rendimiento y buenas prácticas para la PPO.
La mejor forma de aprender es aplicar tú mismo el código. También puedes modificar el código para que funcione con otros entornos de control clásicos en Gym. Para aprender a implementar agentes de RL utilizando Python y Gymnasium de OpenAI, ¡sigue el curso Aprendizaje por Refuerzo con Gymnasium en Python!
Aprende más sobre aprendizaje automático con estos cursos
Curso
Curso
Curso
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial