
Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
Avant de mettre en œuvre l'OPP, nous devons installer les bibliothèques logicielles prérequises et choisir un environnement approprié pour appliquer la politique.
Nous devons installer les logiciels suivants :
numpy (pour les fonctions mathématiques et statistiques) et matplotlib (pour le traçage de graphiques).gym change parfois au cours du processus de mise à niveau, dans cet exemple, nous figeons sa version à 0.25.2. Pour l'installer sur un serveur ou une machine locale, exécutez :
$ pip install torch numpy matplotlib gym==0.25.2Pour l'installer en utilisant un Notebook comme Google Colabou DataLab, utilisez :
!pip install torch numpy matplotlib gym==0.25.2Utilisez OpenAI Gym pour créer deux instances (une pour la formation et une autre pour les tests) de l'environnement CartPole :
env_train = gym.make('CartPole-v1')
env_test = gym.make('CartPole-v1')Mettons maintenant en œuvre le PPO à l'aide de PyTorch.
Comme nous l'avons expliqué précédemment, le PPO est mis en œuvre sous la forme d'un modèle de critique d'acteur. L'acteur met en œuvre la politique et le critique prédit sa valeur estimée. Les réseaux neuronaux d'acteurs et de critiques utilisent les mêmes données d'entrée, à savoir l'état à chaque pas de temps. Ainsi, les modèles de l'acteur et du critique peuvent partager un réseau neuronal commun, que l'on appelle l'architecture dorsale. L'acteur et le critique peuvent étendre l'architecture dorsale avec des couches supplémentaires.
Les étapes suivantes décrivent le réseau de base :
Le code ci-dessous met en œuvre l'épine dorsale :
class BackboneNetwork(nn.Module):
def __init__(self, in_features, hidden_dimensions, out_features, dropout):
super().__init__()
self.layer1 = nn.Linear(in_features, hidden_dimensions)
self.layer2 = nn.Linear(hidden_dimensions, hidden_dimensions)
self.layer3 = nn.Linear(hidden_dimensions, out_features)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.layer1(x)
x = f.relu(x)
x = self.dropout(x)
x = self.layer2(x)
x = f.relu(x)
x = self.dropout(x)
x = self.layer3(x)
return xNous pouvons maintenant utiliser ce réseau pour définir la classe d'acteurs-critiques, ActorCritic. L'acteur modélise la politique et prédit l'action. Le critique modélise la fonction de valeur et prédit la valeur. Ils prennent tous deux l'état en entrée.
class ActorCritic(nn.Module):
def __init__(self, actor, critic):
super().__init__()
self.actor = actor
self.critic = critic
def forward(self, state):
action_pred = self.actor(state)
value_pred = self.critic(state)
return action_pred, value_predNous utiliserons les réseaux définis ci-dessus pour créer un acteur et un critique. Ensuite, nous créerons un agent, comprenant l'acteur et le critique.
Avant de créer l'agent, initialisez les paramètres du réseau :
Le code suivant montre comment déclarer les réseaux d'acteurs et de critiques basés sur le réseau dorsal :
def create_agent(hidden_dimensions, dropout):
INPUT_FEATURES = env_train.observation_space.shape[0]
HIDDEN_DIMENSIONS = hidden_dimensions
ACTOR_OUTPUT_FEATURES = env_train.action_space.n
CRITIC_OUTPUT_FEATURES = 1
DROPOUT = dropout
actor = BackboneNetwork(
INPUT_FEATURES, HIDDEN_DIMENSIONS, ACTOR_OUTPUT_FEATURES, DROPOUT)
critic = BackboneNetwork(
INPUT_FEATURES, HIDDEN_DIMENSIONS, CRITIC_OUTPUT_FEATURES, DROPOUT)
agent = ActorCritic(actor, critic)
return agentL'environnement donne une récompense qui va de chaque étape à la suivante, en fonction de l'action de l'agent. La récompense, R, est exprimée comme suit :
![]()
Le rendement est défini comme la valeur cumulée des bénéfices futurs attendus. Les récompenses obtenues à des moments plus éloignés dans le futur ont moins de valeur que les récompenses immédiates. Ainsi, le rendement est généralement calculé comme le rendement actualisé, G, défini comme suit :
![]()
Dans ce tutoriel (et dans de nombreuses autres références), le rendement fait référence au rendement actualisé.
Pour calculer le rendement :
La fonction calculate_returns() effectue ces calculs, comme indiqué ci-dessous :
def calculate_returns(rewards, discount_factor):
returns = []
cumulative_reward = 0
for r in reversed(rewards):
cumulative_reward = r + cumulative_reward * discount_factor
returns.insert(0, cumulative_reward)
returns = torch.tensor(returns)
# normalize the return
returns = (returns - returns.mean()) / returns.std()
return returnsL'avantage est calculé comme la différence entre la valeur prédite par le critique et le rendement attendu des actions choisies par l'acteur conformément à la politique. Pour une action donnée, l'avantage exprime le bénéfice qu'il y a à prendre cette action spécifique par rapport à une action arbitraire (moyenne).
Dans le document original de l'OPP (équation 10), l'avantage, en regardant vers l'avant jusqu'au pas de temps T, est exprimé comme suit :
![]()
Lors du codage de l'algorithme, la contrainte d'anticipation jusqu'à un nombre déterminé de pas de temps est appliquée par le biais de la taille du lot. L'équation ci-dessus peut donc être simplifiée comme étant la différence entre la valeur et les rendements attendus. Les rendements attendus sont quantifiés dans la fonction de valeur de l'action d'état, Q.
Ainsi, la formule simplifiée ci-dessous exprime l'avantage de choisir :
Cela s'exprime comme suit :
![]()
OpenAI utilise également cette formule pour mettre en œuvre RL. Lafonction calculate_advantages() présentée ci-dessous calcule l'avantage :
def calculate_advantages(returns, values):
advantages = returns - values
# Normalize the advantage
advantages = (advantages - advantages.mean()) / advantages.std()
return advantagesLa perte de police serait la perte de gradient de police standard sans techniques spéciales telles que l'OPP. La perte de pente de la politique standard est calculée comme le produit de :
La perte de gradient de politique standard ne permet pas de corriger les changements brusques de politique. La perte de substitution modifie la perte standard afin de limiter le montant que la police peut modifier à chaque itération. C'est le minimum de deux quantités :
Pour le processus d'optimisation, la perte de substitution est utilisée comme une approximation de la perte réelle.
Le ratio de politique générale, Rest la différence entre la nouvelle et l'ancienne politique et correspond au rapport entre les logarithmes des probabilités de la politique en fonction des nouveaux et des anciens paramètres :
![]()
Le ratio de la police d'assurance écrêtée, R'est contraint de telle sorte que :
![]()
Compte tenu de l'avantage, Atcomme indiqué dans la section précédente, et le ratio de politique, comme indiqué ci-dessus, la perte de substitution est calculée comme suit :
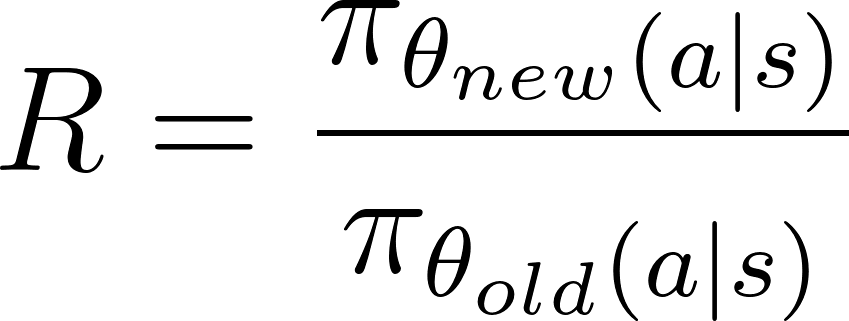
Le code ci-dessous montre comment mettre en œuvre le mécanisme d'écrêtage et la perte de substitution.
def calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages):
advantages = advantages.detach()
policy_ratio = (
actions_log_probability_new - actions_log_probability_old
).exp()
surrogate_loss_1 = policy_ratio * advantages
surrogate_loss_2 = torch.clamp(
policy_ratio, min=1.0-epsilon, max=1.0+epsilon
) * advantages
surrogate_loss = torch.min(surrogate_loss_1, surrogate_loss_2)
return surrogate_lossMaintenant, formons l'agent.
Nous sommes maintenant prêts à calculer les pertes de police et de valeur :
Les deux pertes, telles que calculées ci-dessus, sont des tenseurs. La descente de gradient est basée sur des valeurs scalaires. Pour obtenir une valeur scalaire unique représentant la perte, utilisez la fonction .sum() pour additionner les éléments du tenseur. La fonction ci-dessous montre comment procéder :
def calculate_losses(
surrogate_loss, entropy, entropy_coefficient, returns, value_pred):
entropy_bonus = entropy_coefficient * entropy
policy_loss = -(surrogate_loss + entropy_bonus).sum()
value_loss = f.smooth_l1_loss(returns, value_pred).sum()
return policy_loss, value_lossAvant de commencer le processus de formation, créez un ensemble de tampons sous forme de tableaux vides. L'algorithme d'apprentissage utilisera ces tampons pour stocker des informations sur les actions de l'agent, les états de l'environnement et les récompenses à chaque pas de temps. La fonction ci-dessous initialise ces tampons :
def init_training():
states = []
actions = []
actions_log_probability = []
values = []
rewards = []
done = False
episode_reward = 0
return states, actions, actions_log_probability, values, rewards, done, episode_rewardChaque itération de formation fait fonctionner l'agent avec les paramètres de politique de cette itération. L'agent interagit avec l'environnement par étapes temporelles dans une boucle jusqu'à ce qu'il atteigne une condition terminale.
Après chaque étape, l'action, la récompense et la valeur de l'agent sont ajoutées aux tampons respectifs. À la fin de l'épisode, la fonction renvoie l'ensemble des tampons mis à jour, qui résument les résultats de l'épisode.
Avant d'exécuter la boucle d'entraînement :
agent.train(). env.reset(). Il s'agit de l'état initial pour cette itération de formation. Les étapes suivantes expliquent ce qui se passe à chaque étape de la boucle d'apprentissage :
dist.sample(). env.step() pour transmettre cette action à l'environnement afin de simuler la réponse de l'environnement pour ce pas de temps. En fonction de l'action de l'agent, l'environnement génère :done (indique si l'environnement a atteint un état terminal)L'épisode de formation se termine lorsque la fonction env.step() renvoie true pour la valeur de retour booléenne de done.
Une fois l'épisode terminé, utilisez les valeurs accumulées à chaque étape pour calculer les rendements cumulés de cet épisode en additionnant les récompenses de chaque étape. Pour ce faire, nous utilisons la fonction calculate_returns() décrite précédemment. Les entrées de cette fonction sont le facteur d'actualisation et la mémoire tampon contenant les récompenses de chaque pas de temps. Nous utilisons ces rendements et les valeurs accumulées à chaque étape pour calculer les avantages à l'aide de la fonction calculate_advantages().
La fonction Python suivante montre comment mettre en œuvre ces étapes :
def forward_pass(env, agent, optimizer, discount_factor):
states, actions, actions_log_probability, values, rewards, done, episode_reward = init_training()
state = env.reset()
agent.train()
while not done:
state = torch.FloatTensor(state).unsqueeze(0)
states.append(state)
action_pred, value_pred = agent(state)
action_prob = f.softmax(action_pred, dim=-1)
dist = distributions.Categorical(action_prob)
action = dist.sample()
log_prob_action = dist.log_prob(action)
state, reward, done, _ = env.step(action.item())
actions.append(action)
actions_log_probability.append(log_prob_action)
values.append(value_pred)
rewards.append(reward)
episode_reward += reward
states = torch.cat(states)
actions = torch.cat(actions)
actions_log_probability = torch.cat(actions_log_probability)
values = torch.cat(values).squeeze(-1)
returns = calculate_returns(rewards, discount_factor)
advantages = calculate_advantages(returns, values)
return episode_reward, states, actions, actions_log_probability, advantages, returnsChaque itération de formation fait passer le modèle par un épisode complet composé de nombreux pas de temps (jusqu'à ce qu'il atteigne une condition finale). À chaque étape, nous stockons les paramètres de la politique, l'action de l'agent, les rendements et les avantages. Après chaque itération, nous mettons à jour le modèle sur la base des performances de la politique pour tous les pas de temps de cette itération.
Le nombre maximum de pas de temps dans l'environnement CartPole est de 500. Dans des environnements plus complexes, il y a plus de pas de temps, voire des millions. Dans ce cas, l'ensemble des résultats de la formation doit être divisé en lots. Le nombre de pas de temps dans chaque lot est appelé la taille du lot d'optimisation.
Les étapes de la mise à jour des paramètres du modèle sont donc les suivantes :
.backward() séparément sur la police et évaluez les pertes. Les gradients des fonctions de perte sont ainsi mis à jour. .step() sur l'optimiseur pour mettre à jour les paramètres de la politique. Dans ce cas, nous utilisons l'optimiseur Adam pour équilibrer la vitesse et la robustesse. PPO_STEPS. La répétition de la passe arrière sur chaque lot est efficace en termes de calcul, car elle augmente effectivement la taille de l'ensemble de données d'apprentissage sans avoir à exécuter des passes avant supplémentaires. Le nombre d'étapes de l'environnement dans chaque alternance entre l'échantillonnage et l'optimisation est appelé la taille du lot d'itération. Le code ci-dessous met en œuvre ces étapes :
def update_policy(
agent,
states,
actions,
actions_log_probability_old,
advantages,
returns,
optimizer,
ppo_steps,
epsilon,
entropy_coefficient):
BATCH_SIZE = 128
total_policy_loss = 0
total_value_loss = 0
actions_log_probability_old = actions_log_probability_old.detach()
actions = actions.detach()
training_results_dataset = TensorDataset(
states,
actions,
actions_log_probability_old,
advantages,
returns)
batch_dataset = DataLoader(
training_results_dataset,
batch_size=BATCH_SIZE,
shuffle=False)
for _ in range(ppo_steps):
for batch_idx, (states, actions, actions_log_probability_old, advantages, returns) in enumerate(batch_dataset):
# get new log prob of actions for all input states
action_pred, value_pred = agent(states)
value_pred = value_pred.squeeze(-1)
action_prob = f.softmax(action_pred, dim=-1)
probability_distribution_new = distributions.Categorical(
action_prob)
entropy = probability_distribution_new.entropy()
# estimate new log probabilities using old actions
actions_log_probability_new = probability_distribution_new.log_prob(actions)
surrogate_loss = calculate_surrogate_loss(
actions_log_probability_old,
actions_log_probability_new,
epsilon,
advantages)
policy_loss, value_loss = calculate_losses(
surrogate_loss,
entropy,
entropy_coefficient,
returns,
value_pred)
optimizer.zero_grad()
policy_loss.backward()
value_loss.backward()
optimizer.step()
total_policy_loss += policy_loss.item()
total_value_loss += value_loss.item()
return total_policy_loss / ppo_steps, total_value_loss / ppo_stepsEnfin, exécutons l'agent de l'OPP.
Pour évaluer les performances de l'agent, créez un nouvel environnement et calculez les récompenses cumulées lors de l'exécution de l'agent dans ce nouvel environnement. Vous devez mettre l'agent en mode évaluation à l'aide de la fonction .eval(). Les étapes sont les mêmes que pour la boucle d'entraînement. L'extrait de code ci-dessous met en œuvre la fonction d'évaluation :
def evaluate(env, agent):
agent.eval()
rewards = []
done = False
episode_reward = 0
state = env.reset()
while not done:
state = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
action_pred, _ = agent(state)
action_prob = f.softmax(action_pred, dim=-1)
action = torch.argmax(action_prob, dim=-1)
state, reward, done, _ = env.step(action.item())
episode_reward += reward
return episode_rewardNous utiliserons la bibliothèque Matplotlib pour visualiser la progression du processus de formation. La fonction ci-dessous montre comment tracer les récompenses des boucles d'apprentissage et de test :
def plot_train_rewards(train_rewards, reward_threshold):
plt.figure(figsize=(12, 8))
plt.plot(train_rewards, label='Training Reward')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Training Reward', fontsize=20)
plt.hlines(reward_threshold, 0, len(train_rewards), color='y')
plt.legend(loc='lower right')
plt.grid()
plt.show()def plot_test_rewards(test_rewards, reward_threshold):
plt.figure(figsize=(12, 8))
plt.plot(test_rewards, label='Testing Reward')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Testing Reward', fontsize=20)
plt.hlines(reward_threshold, 0, len(test_rewards), color='y')
plt.legend(loc='lower right')
plt.grid()
plt.show()Dans les exemples de graphiques ci-dessous, nous montrons les récompenses de formation et de test, obtenues en appliquant la politique dans les environnements de formation et de test respectivement. Notez que la forme de ces tracés sera différente à chaque fois que vous exécuterez le code. Cela est dû au caractère aléatoire inhérent au processus de formation.
Récompenses de formation (obtenues par l'application de la politique dans l'environnement de formation). Image par l'auteur.
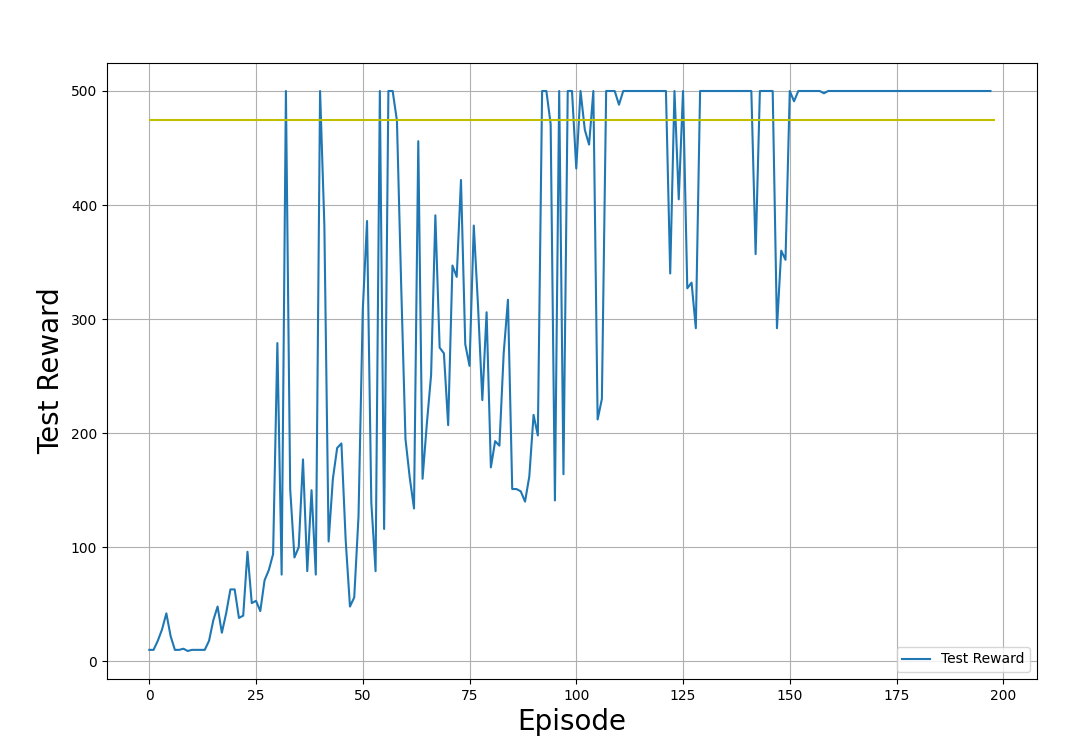
Récompenses de test (obtenues en appliquant la politique dans l'environnement de test). Image par l'auteur.
Dans les graphiques de sortie présentés ci-dessus, observez la progression du processus de formation :
De même, vous pouvez tracer la valeur et les pertes de police au fil des itérations :
def plot_losses(policy_losses, value_losses):
plt.figure(figsize=(12, 8))
plt.plot(value_losses, label='Value Losses')
plt.plot(policy_losses, label='Policy Losses')
plt.xlabel('Episode', fontsize=20)
plt.ylabel('Loss', fontsize=20)
plt.legend(loc='lower right')
plt.grid()
plt.show()L'exemple de graphique ci-dessous montre les pertes suivies au cours des épisodes de formation :
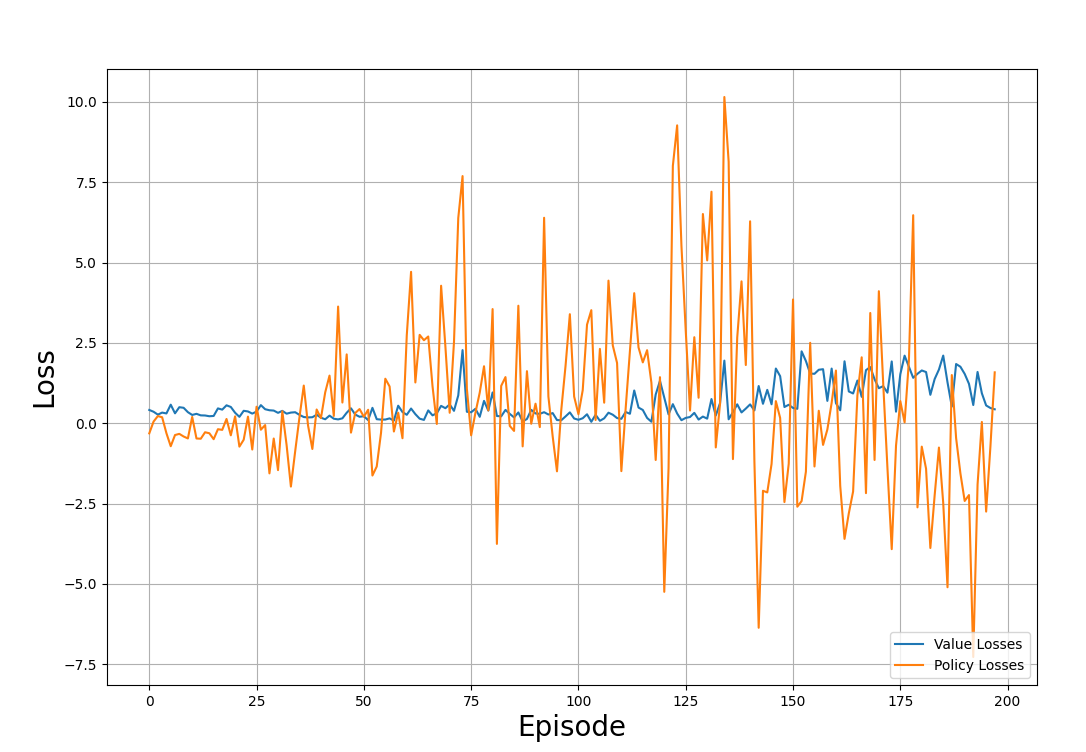
Les pertes de valeur et de politique à travers le processus de formation. Image par l'auteur
Observez l'intrigue et remarquez :
Vous disposez maintenant de tous les éléments pour former l'agent à l'utilisation de l'OPP. Pour mettre tout cela en place, vous devez.. :
create_agent().forward_pass() et update_policy(). evaluate(). Le code ci-dessous montre comment déclarer une fonction qui fait cela en Python :
def run_ppo():
MAX_EPISODES = 500
DISCOUNT_FACTOR = 0.99
REWARD_THRESHOLD = 475
PRINT_INTERVAL = 10
PPO_STEPS = 8
N_TRIALS = 100
EPSILON = 0.2
ENTROPY_COEFFICIENT = 0.01
HIDDEN_DIMENSIONS = 64
DROPOUT = 0.2
LEARNING_RATE = 0.001
train_rewards = []
test_rewards = []
policy_losses = []
value_losses = []
agent = create_agent(HIDDEN_DIMENSIONS, DROPOUT)
optimizer = optim.Adam(agent.parameters(), lr=LEARNING_RATE)
for episode in range(1, MAX_EPISODES+1):
train_reward, states, actions, actions_log_probability, advantages, returns = forward_pass(
env_train,
agent,
optimizer,
DISCOUNT_FACTOR)
policy_loss, value_loss = update_policy(
agent,
states,
actions,
actions_log_probability,
advantages,
returns,
optimizer,
PPO_STEPS,
EPSILON,
ENTROPY_COEFFICIENT)
test_reward = evaluate(env_test, agent)
policy_losses.append(policy_loss)
value_losses.append(value_loss)
train_rewards.append(train_reward)
test_rewards.append(test_reward)
mean_train_rewards = np.mean(train_rewards[-N_TRIALS:])
mean_test_rewards = np.mean(test_rewards[-N_TRIALS:])
mean_abs_policy_loss = np.mean(np.abs(policy_losses[-N_TRIALS:]))
mean_abs_value_loss = np.mean(np.abs(value_losses[-N_TRIALS:]))
if episode % PRINT_INTERVAL == 0:
print(f'Episode: {episode:3} | \
Mean Train Rewards: {mean_train_rewards:3.1f} \
| Mean Test Rewards: {mean_test_rewards:3.1f} \
| Mean Abs Policy Loss: {mean_abs_policy_loss:2.2f} \
| Mean Abs Value Loss: {mean_abs_value_loss:2.2f}')
if mean_test_rewards >= REWARD_THRESHOLD:
print(f'Reached reward threshold in {episode} episodes')
break
plot_train_rewards(train_rewards, REWARD_THRESHOLD)
plot_test_rewards(test_rewards, REWARD_THRESHOLD)
plot_losses(policy_losses, value_losses)Exécutez le programme :
run_ppo()Le résultat devrait ressembler à l'exemple ci-dessous :
Episode: 10 | Mean Train Rewards: 22.3 | Mean Test Rewards: 30.4 | Mean Abs Policy Loss: 0.37 | Mean Abs Value Loss: 0.39
Episode: 20 | Mean Train Rewards: 38.6 | Mean Test Rewards: 69.8 | Mean Abs Policy Loss: 0.46 | Mean Abs Value Loss: 0.37
.
.
.
Episode: 100 | Mean Train Rewards: 289.5 | Mean Test Rewards: 427.3 | Mean Abs Policy Loss: 1.73 | Mean Abs Value Loss: 0.21
Episode: 110 | Mean Train Rewards: 357.7 | Mean Test Rewards: 461.4 | Mean Abs Policy Loss: 1.86 | Mean Abs Value Loss: 0.22
Reached reward threshold in 116 episodesVous pouvez visualiser et exécuter leprogramme de travailsur cet ordinateur portable DataLab!
Dans l'apprentissage automatique, les hyperparamètres contrôlent le processus de formation. Ci-dessous, j'explique certains des hyperparamètres importants utilisés dans l'OPP :
PPO_STEPS. Dans les environnements complexes, l'exécution de la passe avant à de nombreuses reprises est coûteuse en termes de calcul. Une alternative plus efficace consiste à réexécuter chaque lot plusieurs fois. Il est généralement recommandé d'utiliser une valeur comprise entre 5 et 10. N_TRIALS. Lorsque cette valeur est plus élevée, l'apprentissage est plus long car la politique doit atteindre le seuil de récompense sur un plus grand nombre d'épisodes. Elle permet également d'obtenir une politique plus robuste tout en étant plus coûteuse sur le plan informatique. Notez que la PPO est une politique stochastique et qu'il y aura des épisodes où l'agent ne franchira pas le seuil. Par conséquent, si la valeur de N_TRIALS est trop élevée, votre formation risque de ne pas s'achever.L'optimisation des performances des algorithmes d'apprentissage des OPP passe par des essais et des erreurs et par l'expérimentation de différentes valeurs d'hyperparamètres. Il existe cependant quelques grandes lignes directrices :
Après avoir expliqué les concepts de l'OPP et les détails de sa mise en œuvre, examinons les défis et les meilleures pratiques.
Même si l'OPP est largement utilisé, vous devez être conscient des difficultés potentielles pour résoudre des problèmes réels en utilisant cette technique avec succès. Voici quelques-uns de ces défis :
Pour obtenir de bons résultats avec l'OPP, je vous recommande quelques bonnes pratiques, telles que
PPO_STEPS. Dans cet article, nous avons abordé la question de l'OPP comme moyen de résoudre les problèmes liés à la LR. Nous avons ensuite détaillé les étapes de la mise en œuvre de PPO à l'aide de PyTorch. Enfin, nous avons présenté quelques conseils et bonnes pratiques en matière de performance pour les OPP.
La meilleure façon d'apprendre est de mettre en œuvre le code vous-même. Vous pouvez également modifier le code pour qu'il fonctionne avec d'autres environnements de contrôle classiques dans Gym. Pour apprendre à mettre en œuvre des agents RL à l'aide de Python et de Gymnasium d'OpenAI, suivez le cours Reinforcement Learning with Gymnasium in Python!
Apprenez-en plus sur l'apprentissage automatique grâce à ces cours !
Cours
Cours
Cours