
Course
Big Data Fundamentals with PySpark
4 hr
65.2K
PySpark is the Python API for Apache Spark, designed for parallel and distributed data processing across clusters. Choosing the correct join operation for your needs affects job speed, resource consumption, and overall success.
Working with extensive datasets often means integrating data from several sources. Effectively combining this information is essential for accurate analysis and meaningful insights. PySpark joins provide powerful ways to combine separate datasets based on shared keys.
However, inefficient joins can severely impact your data processing speed and reliability when dealing with vast datasets containing millions or even billions of records across distributed clusters.
Have you experienced joins that fail with slow analysis or even with large-scale data? If so, this guide is for you. It will help intermediate data scientists, developers, and engineers gain mastery and confidence when performing PySpark joins.
If you’re looking for some hands-on exercises to familiarize yourself with PySpark, check out our Big Data with PySpark skill track.
As you will discover in our Learn PySpark From Scratch blog post, one of PySpark's main features is the ability to merge large datasets. PySpark join operations are essential for combining large datasets based on shared columns, enabling efficient data integration, comparison, and analysis at scale.
They play a critical role in handling big data by helping uncover relationships and extract meaningful insights across distributed data sources.
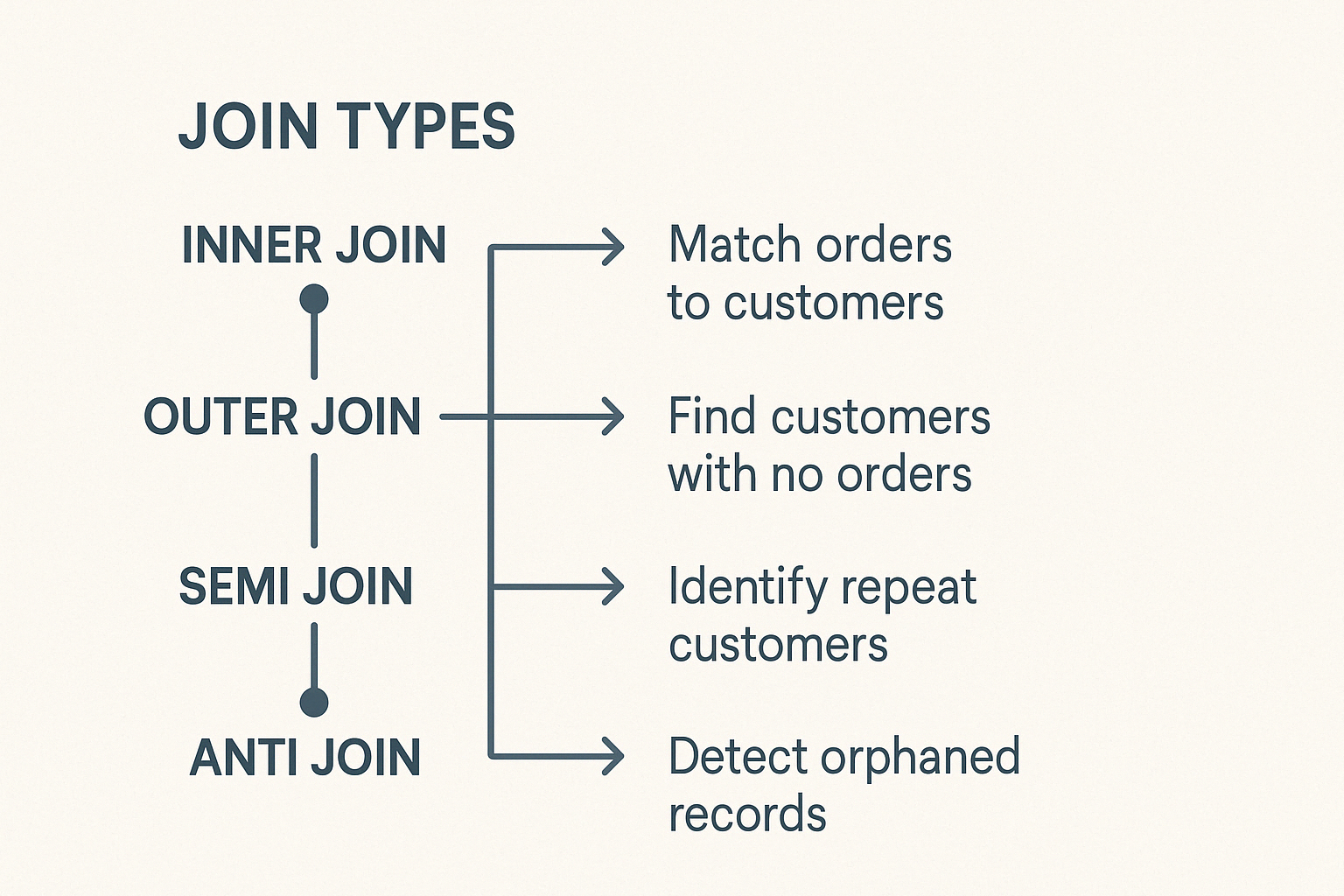
PySpark offers several types of joins, such as inner joins, outer joins, left and right joins, semi joins, and anti joins, each serving different analytical purposes.
However, working with joins on large datasets can introduce challenges like skewed data, shuffling overhead, and memory constraints, making selecting the right join strategy for performance and accuracy crucial.
Understanding PySpark's internal operations is vital for efficiently joining large datasets, as we show in our Introduction to PySpark course. This section outlines the conceptual framework behind PySpark's join execution and the role of its optimizer.
PySpark performs joins in a distributed computing environment, meaning it splits large datasets into smaller partitions and processes them in parallel across a cluster of machines. When a join is triggered, PySpark distributes the work among these nodes, aiming for balanced computation to speed up execution and avoid bottlenecks.
At the core of this process is Catalyst, Spark’s powerful query optimization engine. Catalyst determines how join operations are executed. It decides partitioning strategies, detects when data shuffling is necessary, and applies performance optimizations like predicate pushdown and broadcast joins. This automated optimization ensures efficient execution without requiring manual tuning from the developer.
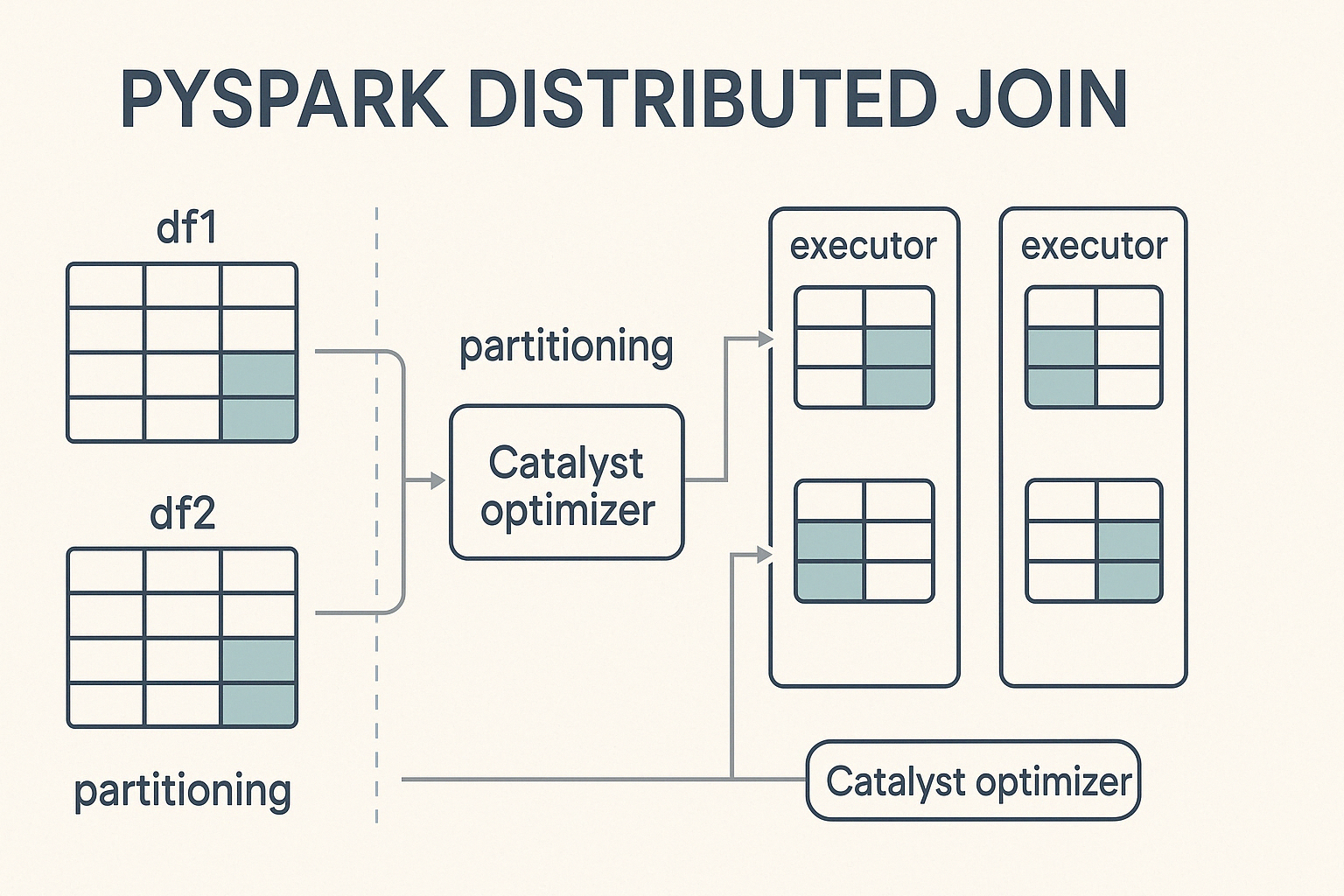
To perform joins in PySpark, you follow a straightforward syntax that involves specifying the DataFrames, a join condition, and the type of join to execute.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Joins Example").getOrCreate()
# Perform a join
joined_df = df1.join(df2, on="key", how="inner")In this example:
df1 and df2 are the DataFrames to be joined.df1.key == df2.key is the join condition, determining how rows from each DataFrame should be matched.inner' specifies the join type, which could also be left, right,, outer, semi, or anti` depending on the desired result.Follow our Getting Started with PySpark tutorial for instructions on how to install PySpark and run the above joins with no errors.
PySpark includes different kinds of joins, each suitable for distinct data tasks. Understanding these helps you select wisely.
The inner join combines rows from two DataFrames when matching keys exist in both. Rows without matching keys will be excluded. It is the most common and default join type in PySpark.
Typical usage scenarios include:
PySpark supports left, right, and full outer joins.
The left outer join returns all rows from the left DataFrame and matching rows from the right DataFrame. When no matching key appears in the right DataFrame, null values fill the right-hand columns.
Use cases:
The right outer join mirrors the logic of the left join. It returns all rows from the right DataFrame and matching rows from the left DataFrame, filling missing matches from the left columns with nulls.
Example scenario:
The Full Outer Join returns all available rows from both DataFrames, filling unmatched entries with nulls. It helps spot discrepancies or data gaps between two datasets.
Semi and anti joins serve specialized functions:
A semi join returns rows from the left DataFrame where matching keys exist in the right DataFrame. It doesn't add columns from the right DataFrame and avoids duplicates, making it ideal for existence checks.
Use case example:
An anti Join return rows from one DataFrame that have no matching key in the second DataFrame.
Use case example:
Cross joins create data by pairing every row in one DataFrame with every row from another. Unless specifically desired, avoid cross joins, as they expand datasets drastically.
Use them cautiously for specific scenarios such as:
Large-scale joins demand careful optimization. Consider the following techniques:
Broadcast joins improve performance by replicating smaller DataFrames across all nodes, eliminating costly shuffles.
Syntax example:
from pyspark.sql.functions import broadcast
joined_df = large_df.join(broadcast(small_df), "id", "inner")Be aware of your system’s memory limits; broadcasting excessively large DataFrames won't work effectively.
Data skew means data is not distributed evenly across partitions, which creates bottlenecks. Techniques to reduce skew include:
Efficient join performance in PySpark heavily depends on minimizing shuffle overhead, which occurs when data needs to be moved across nodes to satisfy join conditions. One of the most effective ways to reduce this overhead is by aligning partitions of the DataFrames being joined.
Keep these best practices in mind:
repartition() or broadcast() wisely: Use repartition() for large datasets where uniform distribution is possible, and broadcast() for significantly smaller tables to avoid shuffling entirely.PySpark includes specialized mechanisms for more demanding cases, enabling even greater efficiency:
Range joins are used when matching rows based on numerical or time-based conditions, rather than exact equality. These joins are common in scenarios involving time-series data, such as log analysis, event tracking, or IoT sensor streams.
Best practices for efficient range joins include:
rangeBetween or between.Example use cases include:
Joining streaming data introduces unique challenges due to its continuous and often unpredictable nature. Key issues include late-arriving events, out-of-order data, and the need to manage state efficiently over time.
PySpark addresses these challenges using watermarks, which define a threshold for how long the system should wait for late data before discarding it. By setting a watermark on event-time columns, PySpark can efficiently manage late data and optimize resource usage.
Watermarks are especially useful when joining two streaming sources or a stream with a static dataset, helping maintain both performance and consistency in real-time data pipelines.
Joins play a crucial role in preparing data for machine learning models, for example, when building models with Spark MLlib. Consolidating these features into a single, unified dataset is essential for accurate model training and evaluation.
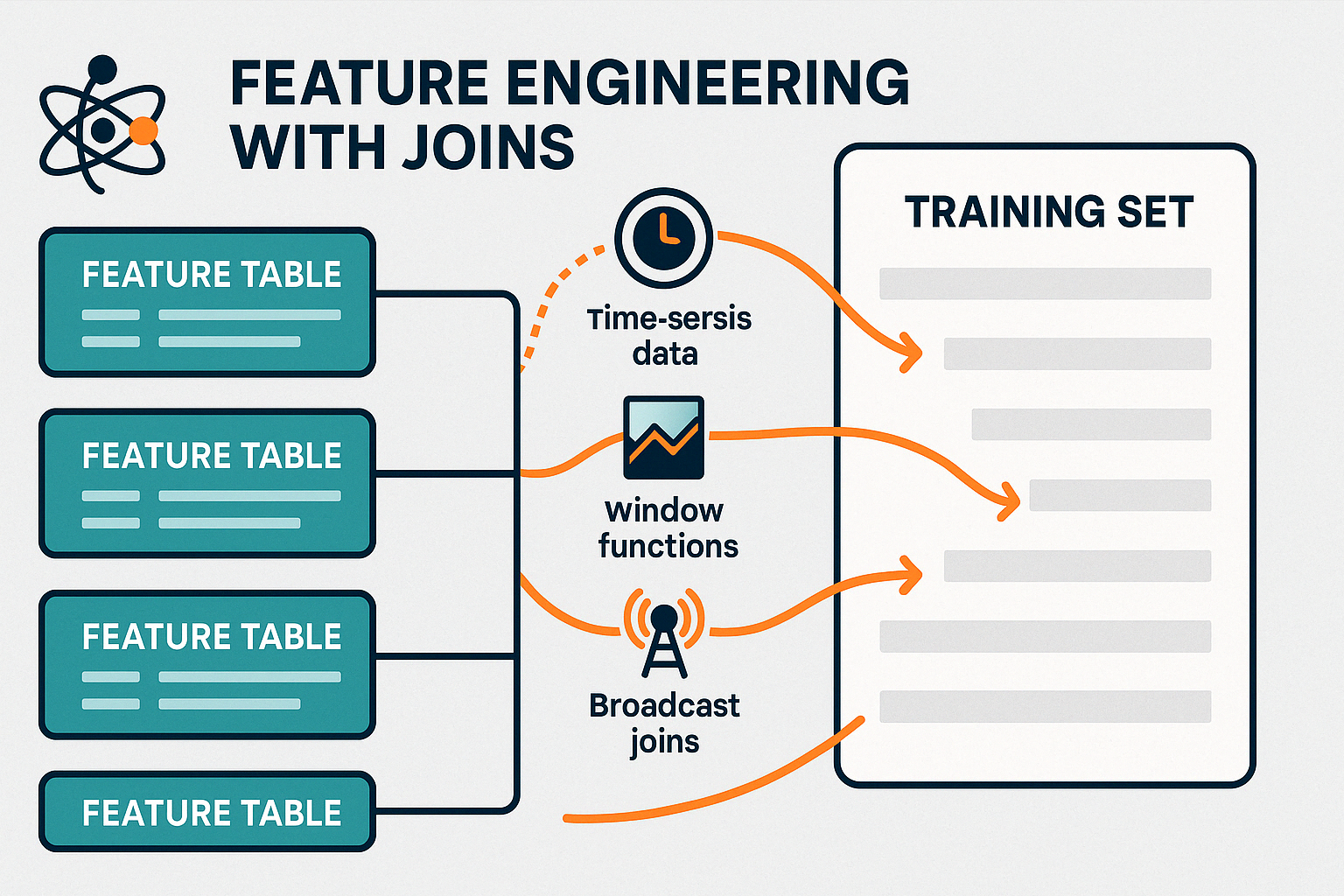
By efficiently managing these joins, PySpark enables real-time feature engineering, supporting both online learning systems and up-to-date batch training pipelines.
You can learn how to make predictions from data with Apache Spark, using decision trees, logistic regression, linear regression, ensembles, and pipelines with our Machine Learning with PySpark course.
Joining operations in distributed computing requires regular attention to avoid potential issues.
Efficient join operations can drastically improve overall pipeline speed and resource usage. Here are key practices to follow:
repartition() or coalesce() to adjust partition sizes for more balanced parallel processing.Even small missteps in join logic can lead to major issues in performance or data accuracy. Here are common pitfalls to watch out for:
Even well-structured joins can encounter performance or execution problems.
Here are common issues and how to address them:
PySpark joins are a cornerstone of large-scale data processing, enabling powerful and efficient analysis across massive datasets. When used correctly, they reveal meaningful relationships that drive deeper insights and smarter decisions.
While performance tuning can present challenges, such as handling data skew or optimizing partitioning, mastering these aspects is key to building robust data pipelines.
Whether you're joining real-time streams or consolidating features for machine learning, refining your join strategies can significantly improve execution speed, resource efficiency, and analytical precision.
To dive deeper, explore big data processing with PySpark, and work toward becoming a data engineering expert with our Big Data Fundamentals with PySpark skill track.
Top DataCamp Courses
Course
Course
Course
blog
Maria Eugenia Inzaugarat
15 min
blog
Maria Eugenia Inzaugarat
15 min
cheat-sheet
Karlijn Willems
cheat-sheet
Karlijn Willems
Tutorial
Karlijn Willems
Tutorial
Natassha Selvaraj

