
Curso
Fundamentos de Big Data com PySpark
4 h
65.2K
PySpark é a API Python para o Apache Spark, projetada para processamento de dados paralelos e distribuídos em clusters. A escolha da operação de união correta para suas necessidades afeta a velocidade do trabalho, o consumo de recursos e o sucesso geral.
Trabalhar com conjuntos de dados extensos geralmente significa integrar dados de várias fontes. A combinação eficaz dessas informações é essencial para uma análise precisa e insights significativos. As uniões do PySpark oferecem maneiras eficientes de combinar conjuntos de dados separados com base em chaves compartilhadas.
No entanto, uniões ineficientes podem afetar gravemente a velocidade e a confiabilidade do processamento de dados ao lidar com grandes conjuntos de dados contendo milhões ou até bilhões de registros em clusters distribuídos.
Você já experimentou uniões que falham com análises lentas ou mesmo com dados em grande escala? Se for o caso, este guia é para você. Ele ajudará cientistas de dados, desenvolvedores e engenheiros intermediários a adquirir domínio e confiança ao realizar junções com o PySpark.
Se você está procurando alguns exercícios práticos para se familiarizar com o PySpark, confira nossa Programa de habilidades em Big Data com PySpark.
Como você descobrirá em nosso artigo Aprenda PySpark do zero um dos principais recursos do PySpark é a capacidade de mesclar grandes conjuntos de dados. As operações de junção do PySpark são essenciais para combinar grandes conjuntos de dados com base em colunas compartilhadas, permitindo integração, comparação e análise de dados eficientes em escala.
Eles desempenham um papel fundamental no manuseio de big data, ajudando a descobrir relacionamentos e a extrair insights significativos em fontes de dados distribuídas.
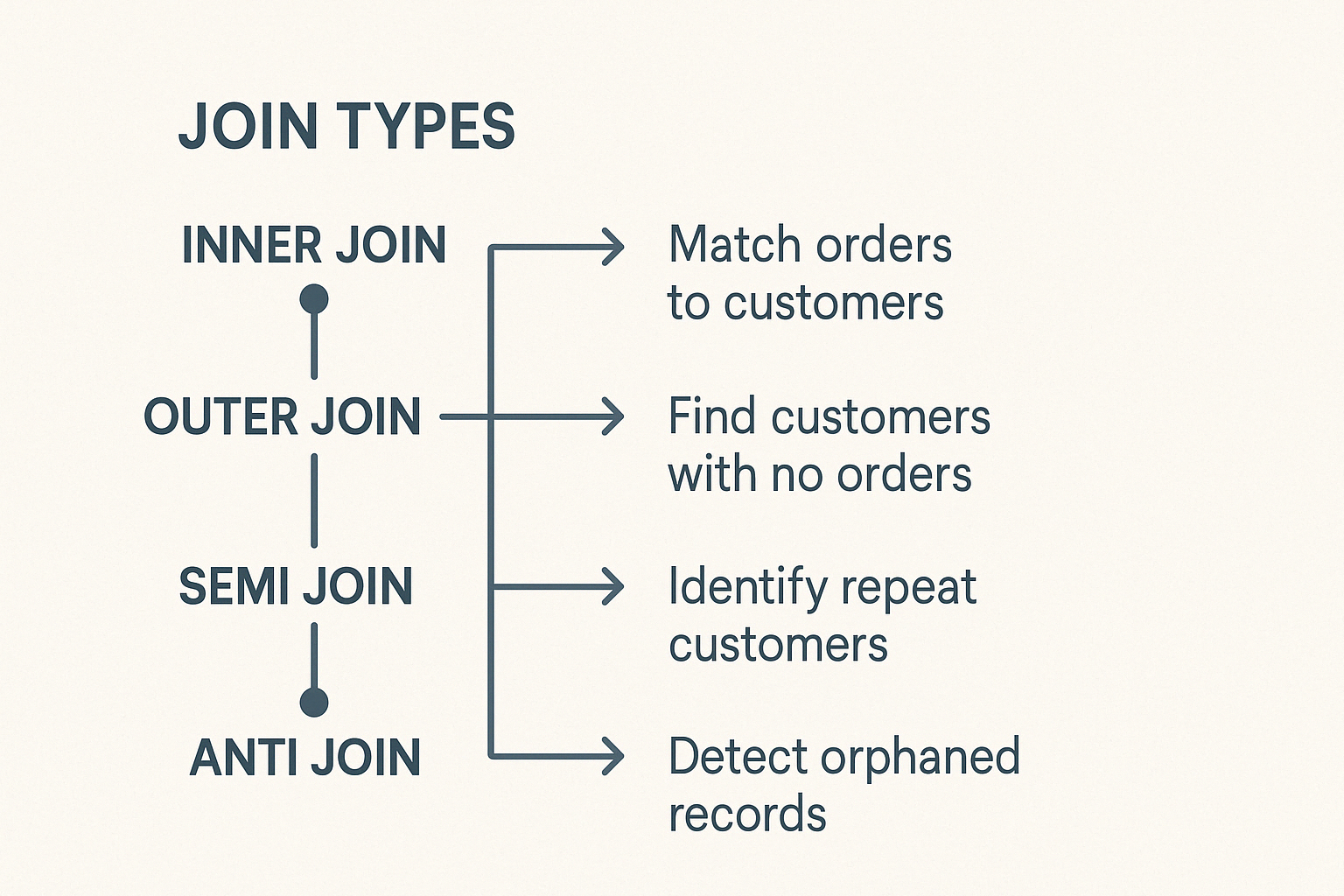
O PySpark oferece vários tipos de junções, como junções internas, junções externas, junções à esquerda e à direita, semijunções, e antijunçõescada uma servindo a diferentes propósitos analíticos.
No entanto, trabalhar com uniões em grandes conjuntos de dados pode apresentar desafios como dados distorcidos, sobrecarga de embaralhamento e restrições de memória, o que torna crucial a seleção da estratégia de união correta para desempenho e precisão.
Entender as operações internas do PySpark é vital para unir grandes conjuntos de dados com eficiência, como mostramos em nosso Curso de introdução ao PySpark. Esta seção descreve a estrutura conceitual por trás da execução de junção do PySpark e a função do seu otimizador.
O PySpark realiza junções em um ambiente de computação distribuída, o que significa que ele divide grandes conjuntos de dados em partições menores e os processa em paralelo em um cluster de máquinas. Quando umaunião é acionada, o PySpark distribui o trabalho entre esses nós, visando a uma computação equilibrada para acelerar a execução e evitar gargalos.
No centro desse processo está o Catalyst, o poderoso mecanismo de otimização de consultas do Spark. O Catalyst determina como as operações de união são executadas. Ele decide estratégias de particionamento, detecta quando o embaralhamento de dados é necessário e aplica otimizações de desempenho, como pushdown de predicado e junções de broadcast. Essa otimização automatizada garante uma execução eficiente sem a necessidade de ajuste manual por parte do desenvolvedor.
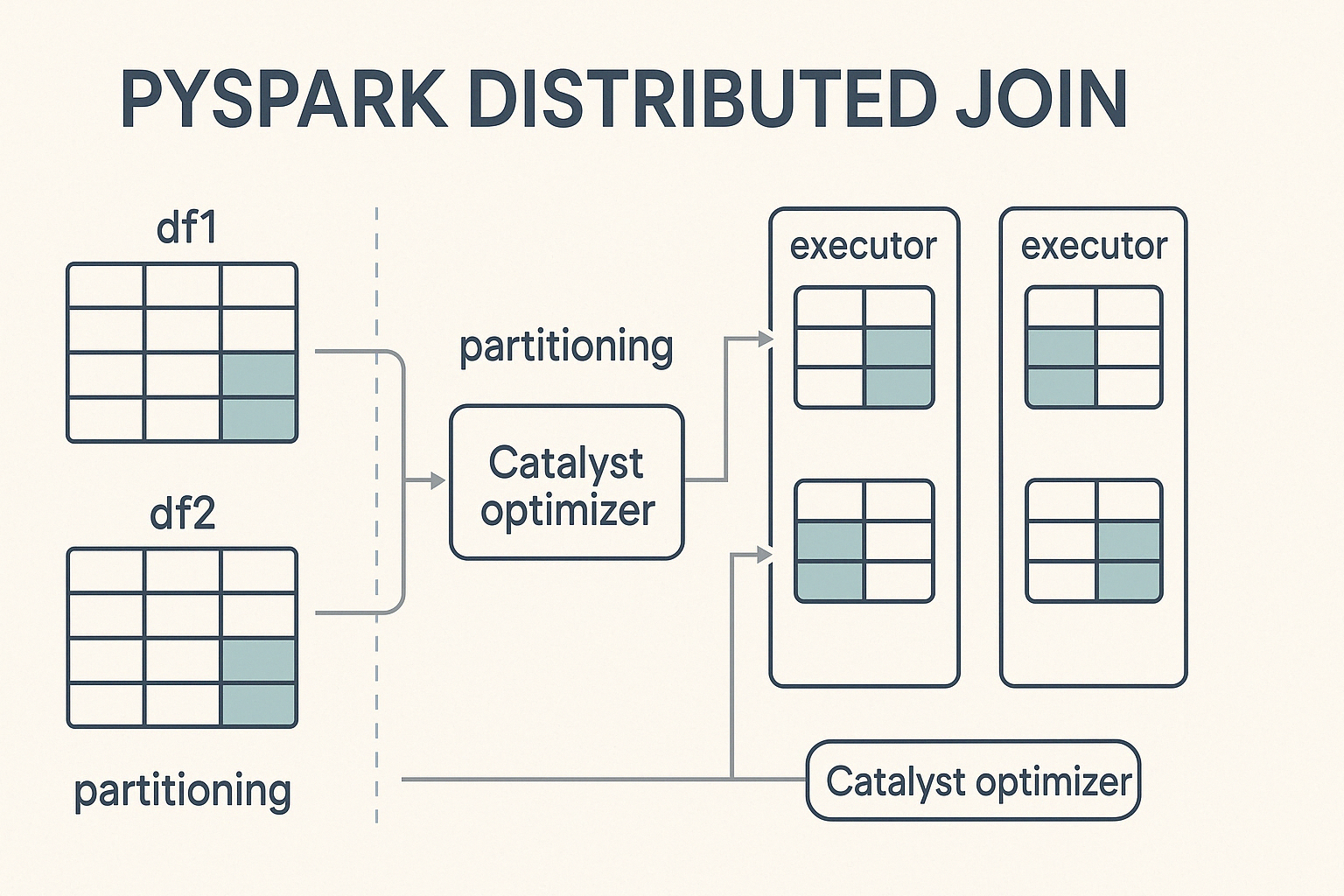
Para realizar uniões no PySpark, você segue uma sintaxe simples que envolve a especificação do parâmetro DataFrames, a condição de uniãoe o tipo de junção a ser executado.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Joins Example").getOrCreate()
# Perform a join
joined_df = df1.join(df2, on="key", how="inner")Neste exemplo:
df1 e df2 são os DataFrames a serem unidos.df1.key == df2.key é a condição de união, determinando como as linhas de cada DataFrame devem ser combinadas.inner' specifies the join type, which could also be left, right,, outer, semi, or anti` dependendo do resultado desejado.Siga nosso tutorial Getting Started with PySpark para obter instruções sobre como instalar o PySpark e executar as junções acima sem erros.
O PySpark inclui diferentes tipos de junções, cada uma adequada para tarefas de dados distintas. Entender isso ajuda você a escolher com sabedoria.
A união interna combina linhas de dois DataFrames quando existem chaves correspondentes em ambos. As linhas sem chaves correspondentes serão excluídas. É o tipo de junção mais comum e padrão no PySpark.
Os cenários de uso típicos incluem:
O PySpark suporta junções externas à esquerda, à direita e completas.
A união externa esquerda retorna todas as linhas do DataFrame esquerdo e as linhas correspondentes do DataFrame direito. Quando nenhuma chave correspondente aparece no DataFrame direito, os valores nulos preenchem as colunas da direita.
Casos de uso:
A união externa direita espelha a lógica da união esquerda. Ele retorna todas as linhas do DataFrame direito e as linhas correspondentes do DataFrame esquerdo, preenchendo as correspondências ausentes das colunas esquerdas com nulos.
Exemplo de cenário:
O Full Outer Join retorna todas as linhas disponíveis de ambos os DataFrames, preenchendo as entradas não correspondentes com nulos. Ele ajuda a identificar discrepâncias ou lacunas de dados entre dois conjuntos de dados.
As semi e antijunções têm funções especializadas:
Uma semiconjunção retorna linhas do DataFrame esquerdo em que existem chaves correspondentes no DataFrame direito. Ele não adiciona colunas do DataFrame correto e evita duplicatas, o que o torna ideal para verificações de existência.
Exemplo de caso de uso:
Um anti Join retorna linhas de um DataFrame que não têm chave correspondente no segundo DataFrame.
Exemplo de caso de uso:
As junções cruzadas criam dados ao emparelhar cada linha de um DataFrame com cada linha de outro. A menos que seja especificamente desejado, evite junções cruzadas, pois elas expandem drasticamente os conjuntos de dados.
Use-os com cautela em cenários específicos, como:
As uniões em grande escala exigem uma otimização cuidadosa. Considere as seguintes técnicas:
As uniões por difusão melhoram o desempenho ao replicar DataFrames menores em todos os nós, eliminando embaralhamentos dispendiosos.
Exemplo de sintaxe:
from pyspark.sql.functions import broadcast
joined_df = large_df.join(broadcast(small_df), "id", "inner")Esteja ciente dos limites de memória do seu sistema; a transmissão de DataFrames excessivamente grandes não funcionará de forma eficaz.
A distorção de dados significa que os dados não são distribuídos uniformemente entre as partições, o que cria gargalos. As técnicas para reduzir a distorção incluem:
O desempenho eficiente de junção no PySpark depende muito da minimização da sobrecarga de embaralhamento, que ocorre quando os dados precisam ser movidos entre os nós para satisfazer as condições de junção. Uma das maneiras mais eficazes de reduzir essa sobrecarga é alinhar as partições dos DataFrames que estão sendo unidos.
Tenha em mente estas práticas recomendadas:
repartition() ou broadcast() com sabedoria: Use repartition() para conjuntos de dados grandes em que a distribuição uniforme é possível, e broadcast() para tabelas significativamente menores para evitar totalmente o embaralhamento.O PySpark inclui mecanismos especializados para casos mais exigentes, permitindo uma eficiência ainda maior:
As uniões de intervalo são usadas para fazer a correspondência de linhas com base em condições numéricas ou baseadas em tempo, em vez de igualdade exata. Essas uniões são comuns em cenários que envolvem dados de séries temporais, como análise de registros, rastreamento de eventos ou fluxos de sensores de IoT.
As práticas recomendadas para uniões eficientes de faixas incluem:
rangeBetween ou between.Exemplos de casos de uso incluem:
A junção de dados de streaming apresenta desafios exclusivos devido à sua natureza contínua e, muitas vezes, imprevisível. Os principais problemas incluem eventos de chegada tardia, dados fora de ordem e a necessidade de gerenciar o estado com eficiência ao longo do tempo.
O PySpark aborda esses desafios usando marcas d'água, que definem um limite de quanto tempo o sistema deve esperar por dados atrasados antes de descartá-los. Ao definir uma marca d'água nas colunas de tempo de evento, o PySpark pode gerenciar com eficiência os dados atrasados e otimizar o uso de recursos.
As marcas d'água são especialmente úteis ao unir duas fontes de streaming ou um streaming com um conjunto de dados estático, ajudando a manter o desempenho e a consistência em pipelines de dados em tempo real.
As uniões desempenham um papel crucial na preparação de dados para modelos de machine learning, por exemplo, quando você cria modelos com o Spark MLlib. você criar modelos com o Spark MLlib. A consolidação desses recursos em um conjunto de dados único e unificado é essencial para o treinamento e a avaliação precisos do modelo.
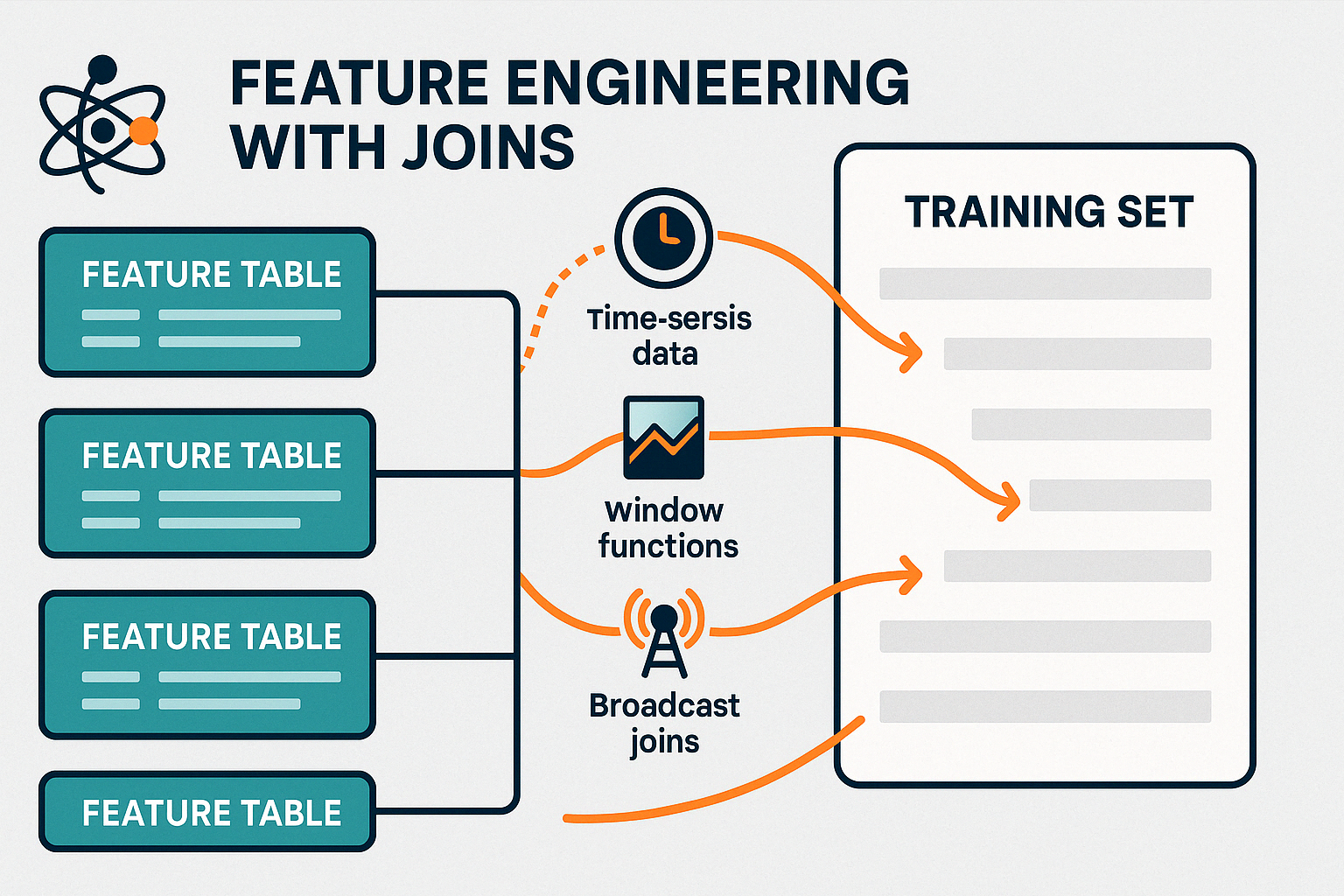
Ao gerenciar com eficiência essas uniões, o PySpark permite a engenharia de recursos em tempo real, oferecendo suporte a sistemas de aprendizagem on-line e pipelines de treinamento em lote atualizados.
Você pode aprender a fazer previsões a partir de dados com o Apache Spark, usando árvores de decisão, regressão logística, regressão linear, conjuntos e pipelines com nosso Curso de machine learning com PySpark.
A união de operações em computação distribuída requer atenção regular para evitar possíveis problemas.
Operações de junção eficientes podem melhorar drasticamente a velocidade geral do pipeline e o uso de recursos. Aqui estão as principais práticas que você deve seguir:
repartition() ou coalesce() para ajustar os tamanhos das partições para um processamento paralelo mais equilibrado.Mesmo pequenos erros na lógica de união podem levar a grandes problemas de desempenho ou precisão dos dados. Aqui estão as armadilhas comuns às quais você deve estar atento:
Mesmo as uniões bem estruturadas podem apresentar problemas de desempenho ou execução.
Aqui estão os problemas comuns e como você pode resolvê-los:
As uniões do PySpark são a base do processamento de dados em grande escala, permitindo uma análise avançada e eficiente de conjuntos de dados enormes. Quando usados corretamente, eles revelam relacionamentos significativos que geram insights mais profundos e decisões mais inteligentes.
Embora o ajuste de desempenho possa apresentar desafios, como lidar com a distorção de dados ou otimizar o particionamento, dominar esses aspectos é fundamental para criar pipelines de dados robustos.
Se você estiver unindo fluxos em tempo real ou consolidando recursos para machine learning, o refinamento de suas estratégias de união pode melhorar significativamente a velocidade de execução, a eficiência dos recursos e a precisão analítica.
Para se aprofundar, explore o processamento de Big Data com o PySpark e trabalhe para se tornar um especialista em engenharia de dados com nosso curso Fundamentos de Big Data com PySpark programa de habilidades.
Principais cursos da DataCamp
Curso
Curso
Curso
Tutorial
Natassha Selvaraj
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes
Tutorial
Joleen Bothma
Tutorial
