
Cours
Principes fondamentaux des mégadonnées avec PySpark
4 h
65.2K
PySpark est l'API Python pour Apache Spark, conçue pour le traitement de données parallèles et distribuées sur des clusters. Le choix de l'opération d'assemblage la mieux adaptée à vos besoins influe sur la vitesse de travail, la consommation de ressources et la réussite globale.
Travailler avec de vastes ensembles de données implique souvent d'intégrer des données provenant de plusieurs sources. Il est essentiel de combiner efficacement ces informations pour obtenir une analyse précise et des informations utiles. Les jointures PySpark offrent des moyens puissants de combiner des ensembles de données distincts sur la base de clés partagées.
Cependant, des jointures inefficaces peuvent avoir un impact important sur la vitesse et la fiabilité du traitement de vos données lorsque vous traitez de vastes ensembles de données contenant des millions, voire des milliards d'enregistrements sur des clusters distribués.
Avez-vous fait l'expérience de jointures qui échouent en cas d'analyse lente ou même de données à grande échelle ? Si c'est le cas, ce guide est fait pour vous. Il aidera les data scientists, les développeurs et les ingénieurs de niveau intermédiaire à acquérir la maîtrise et la confiance nécessaires pour réaliser des jointures PySpark.
Si vous cherchez des exercices pratiques pour vous familiariser avec PySpark, consultez notre parcours de compétences Le cursus Big Data avec PySpark.
Comme vous le découvrirez dans notre Apprendre PySpark à partir de rien l'une des principales fonctionnalités de PySpark est la possibilité de fusionner de grands ensembles de données. Les opérations de jointure de PySpark sont essentielles pour combiner de grands ensembles de données basés sur des colonnes partagées, ce qui permet une intégration, une comparaison et une analyse efficaces des données à grande échelle.
Ils jouent un rôle essentiel dans le traitement des données volumineuses en aidant à découvrir les relations et à extraire des informations significatives à partir de sources de données distribuées.
PySpark propose plusieurs types de jointures, telles que les jointures internes, les jointures externes, les jointures gauche et droite, les jointures semi, et anti jointureschacune servant des objectifs analytiques différents.
Cependant, l'utilisation de jointures sur de grands ensembles de données peut poser des problèmes tels que des données asymétriques, des frais généraux de brassage et des contraintes de mémoire, ce qui rend crucial le choix de la bonne stratégie de jointure en termes de performances et de précision.
Comprendre les opérations internes de PySpark est essentiel pour joindre efficacement de grands ensembles de données, comme nous le montrons dans notre cours Introduction à PySpark. Cette section présente le cadre conceptuel de l'exécution des jointures de PySpark et le rôle de son optimiseur.
PySpark effectue des jointures dans un environnement informatique distribué, ce qui signifie qu'il divise de grands ensembles de données en partitions plus petites et les traite en parallèle sur une grappe de machines. Lorsqu'unejointure est déclenchée, PySpark répartit le travail entre ces nœuds, en visant un calcul équilibré afin d'accélérer l'exécution et d'éviter les goulets d'étranglement.
Au cœur de ce processus se trouve Catalyst, le puissant moteur d'optimisation des requêtes de Spark. Catalyst détermine comment les opérations de jointure sont exécutées. Il décide des stratégies de partitionnement, détecte les cas où le brassage des données est nécessaire et applique des optimisations de performances telles que le pushdown des prédicats et les jointures de diffusion. Cette optimisation automatisée garantit une exécution efficace sans nécessiter de réglage manuel de la part du développeur.
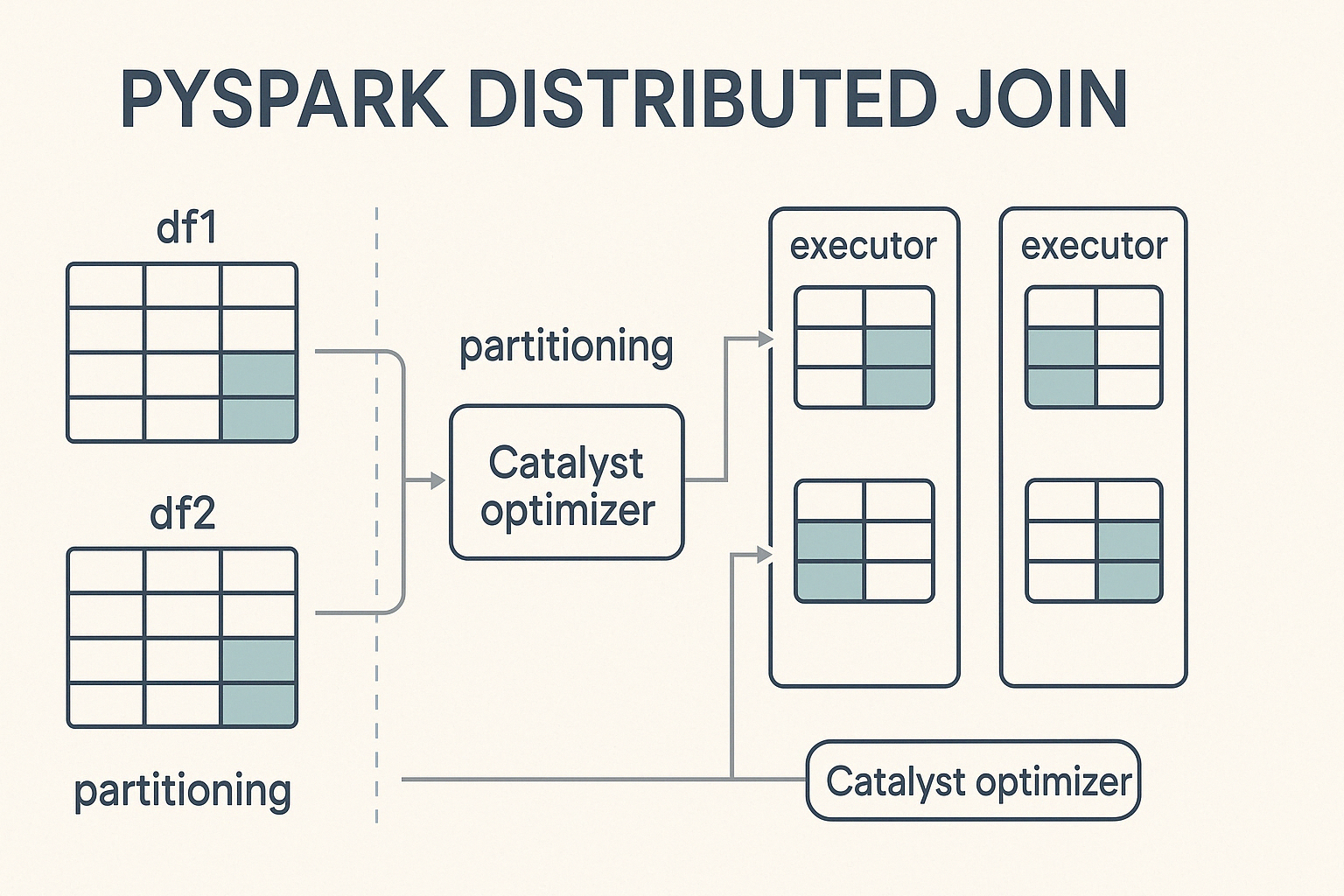
Pour effectuer des jointures dans PySpark, vous suivez une syntaxe simple qui consiste à spécifier le paramètre DataFrame, a condition de jointureet le type de jointure à exécuter.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Joins Example").getOrCreate()
# Perform a join
joined_df = df1.join(df2, on="key", how="inner")Dans cet exemple :
df1 et df2 sont les DataFrames à joindre.df1.key == df2.key est la condition de jointure, qui détermine comment les lignes de chaque DataFrame doivent être mises en correspondance.inner' specifies the join type, which could also be left, right,, outer, semi, or anti` en fonction du résultat souhaité.Suivez notre tutoriel "Getting Started with PySpark " pour savoir comment installer PySpark et exécuter les jointures ci-dessus sans erreur.
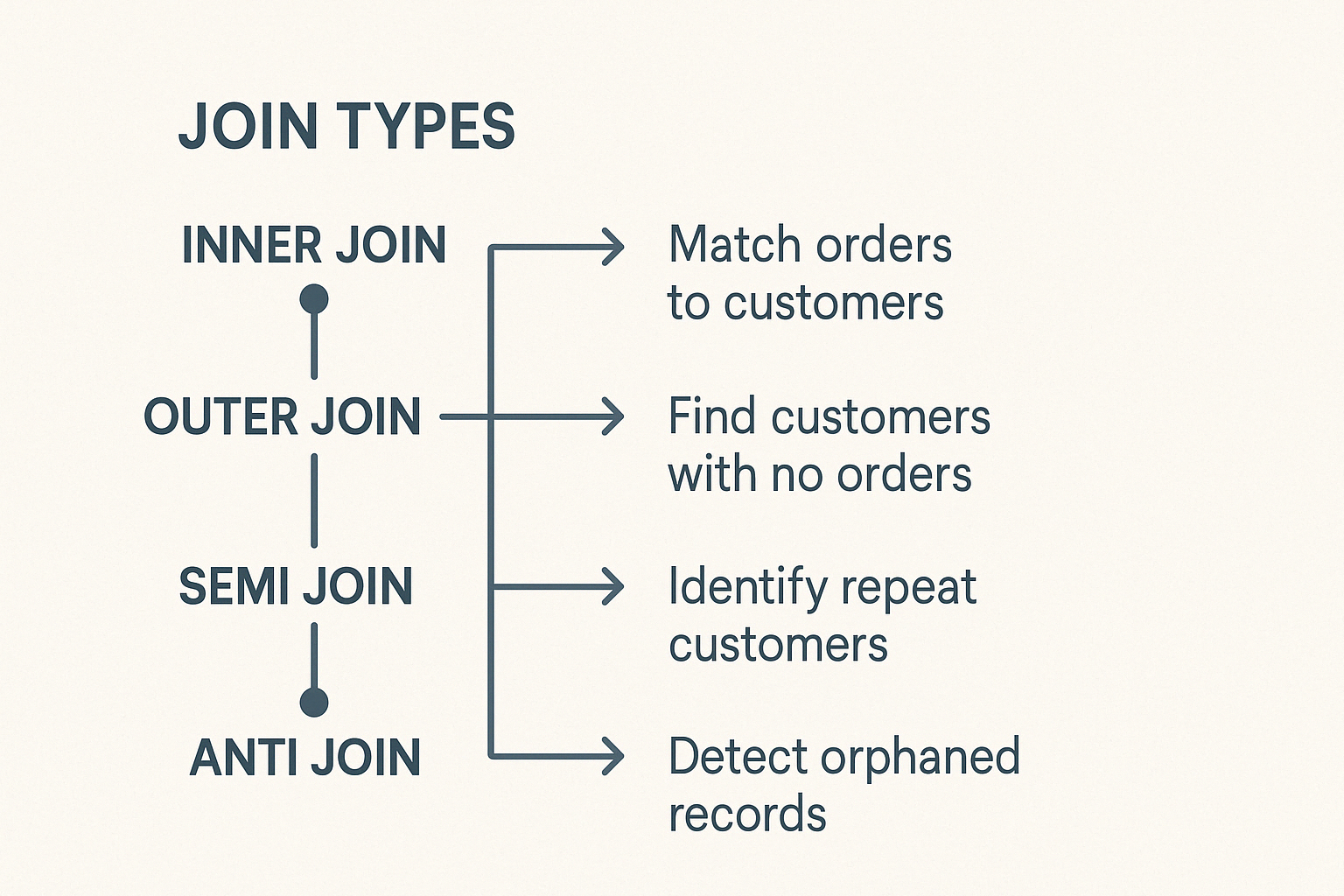
PySpark comprend différents types de jointures, chacun adapté à des tâches de données distinctes. Comprendre ces éléments vous permet de faire un choix judicieux.
La jointure interne combine les lignes de deux DataFrame lorsque des clés correspondantes existent dans les deux. Les lignes sans clés correspondantes seront exclues. C'est le type de jointure le plus courant et par défaut dans PySpark.
Les scénarios d'utilisation typiques sont les suivants :
PySpark prend en charge les jointures externes à gauche, à droite et complètes.
La jointure externe gauche renvoie toutes les lignes du DataFrame gauche et les lignes correspondantes du DataFrame droit. Lorsqu'aucune clé correspondante n'apparaît dans le DataFrame de droite, des valeurs nulles remplissent les colonnes de droite.
Cas d'utilisation :
La jointure externe droite reflète la logique de la jointure gauche. Il renvoie toutes les lignes du DataFrame de droite et les lignes correspondantes du DataFrame de gauche, en remplissant les correspondances manquantes des colonnes de gauche par des zéros.
Exemple de scénario :
La jointure externe complète renvoie toutes les lignes disponibles des deux DataFrame, en remplissant les entrées non appariées par des zéros. Il permet de repérer les divergences ou les lacunes entre deux ensembles de données.
Les semi-joints et les anti-joints remplissent des fonctions spécialisées :
Une jointure partielle renvoie les lignes du DataFrame de gauche lorsque les clés correspondantes existent dans le DataFrame de droite. Il n'ajoute pas les colonnes du bon DataFrame et évite les doublons, ce qui le rend idéal pour les contrôles d'existence.
Exemple de cas d'utilisation :
Un anti Join renvoie les lignes d'un DataFrame qui n'ont pas de clé correspondante dans le second DataFrame.
Exemple de cas d'utilisation :
Les jointures croisées créent des données en associant chaque ligne d'un DataFrame à chaque ligne d'un autre DataFrame. Sauf si vous le souhaitez expressément, évitez les jointures croisées, car elles élargissent considérablement les ensembles de données.
Utilisez-les avec précaution pour des scénarios spécifiques tels que
Les jonctions à grande échelle exigent une optimisation minutieuse. Considérez les techniques suivantes :
Les jointures de diffusion améliorent les performances en répliquant des DataFrame plus petits sur tous les nœuds, ce qui élimine les mélanges coûteux.
Exemple de syntaxe :
from pyspark.sql.functions import broadcast
joined_df = large_df.join(broadcast(small_df), "id", "inner")Tenez compte des limites de mémoire de votre système ; la diffusion de DataFrame trop volumineux ne fonctionnera pas efficacement.
L'asymétrie des données signifie que les données ne sont pas réparties uniformément entre les partitions, ce qui crée des goulets d'étranglement. Les techniques permettant de réduire l'asymétrie sont les suivantes :
L'efficacité des jointures dans PySpark dépend fortement de la minimisation de la surcharge de mélange, qui se produit lorsque les données doivent être déplacées d'un nœud à l'autre pour satisfaire les conditions de jointure. L'un des moyens les plus efficaces de réduire cette surcharge consiste à aligner les partitions des DataFrames à joindre.
Gardez à l'esprit ces bonnes pratiques :
repartition() ou broadcast() à bon escient: Utilisez repartition() pour les grands ensembles de données où une distribution uniforme est possible, et broadcast() pour les tableaux beaucoup plus petits afin d'éviter complètement le brassage.PySpark comprend des mécanismes spécialisés pour les cas les plus exigeants, permettant une efficacité encore plus grande :
Les jointures de plages sont utilisées pour faire correspondre des lignes sur la base de conditions numériques ou temporelles, plutôt que sur la base d'une égalité exacte. Ces jointures sont courantes dans les scénarios impliquant des données de séries temporelles, comme l'analyse de journaux, le cursus d'événements ou les flux de capteurs IoT.
Les meilleures pratiques pour une jonction efficace des rangs sont les suivantes :
rangeBetween ou between.Voici quelques exemples de cas d'utilisation :
L'assemblage de données en continu présente des défis uniques en raison de leur nature continue et souvent imprévisible. Les principaux problèmes sont les événements tardifs, les données non ordonnées et la nécessité de gérer efficacement l'état au fil du temps.
PySpark relève ces défis en utilisant les filigranes, qui définissent un seuil pour la durée pendant laquelle le système doit attendre les données en retard avant de les rejeter. En plaçant un filigrane sur les colonnes d'événements, PySpark peut gérer efficacement les données tardives et optimiser l'utilisation des ressources.
Les filigranes sont particulièrement utiles lorsque vous joignez deux sources de flux ou un flux avec un ensemble de données statiques, ce qui permet de maintenir à la fois les performances et la cohérence dans les pipelines de données en temps réel.
Les jointures jouent un rôle crucial dans la préparation des données pour les modèles d'apprentissage automatique. construction de modèles avec Spark MLlib. La consolidation de ces caractéristiques dans un ensemble de données unique et unifié est essentielle pour une formation et une évaluation précises des modèles.
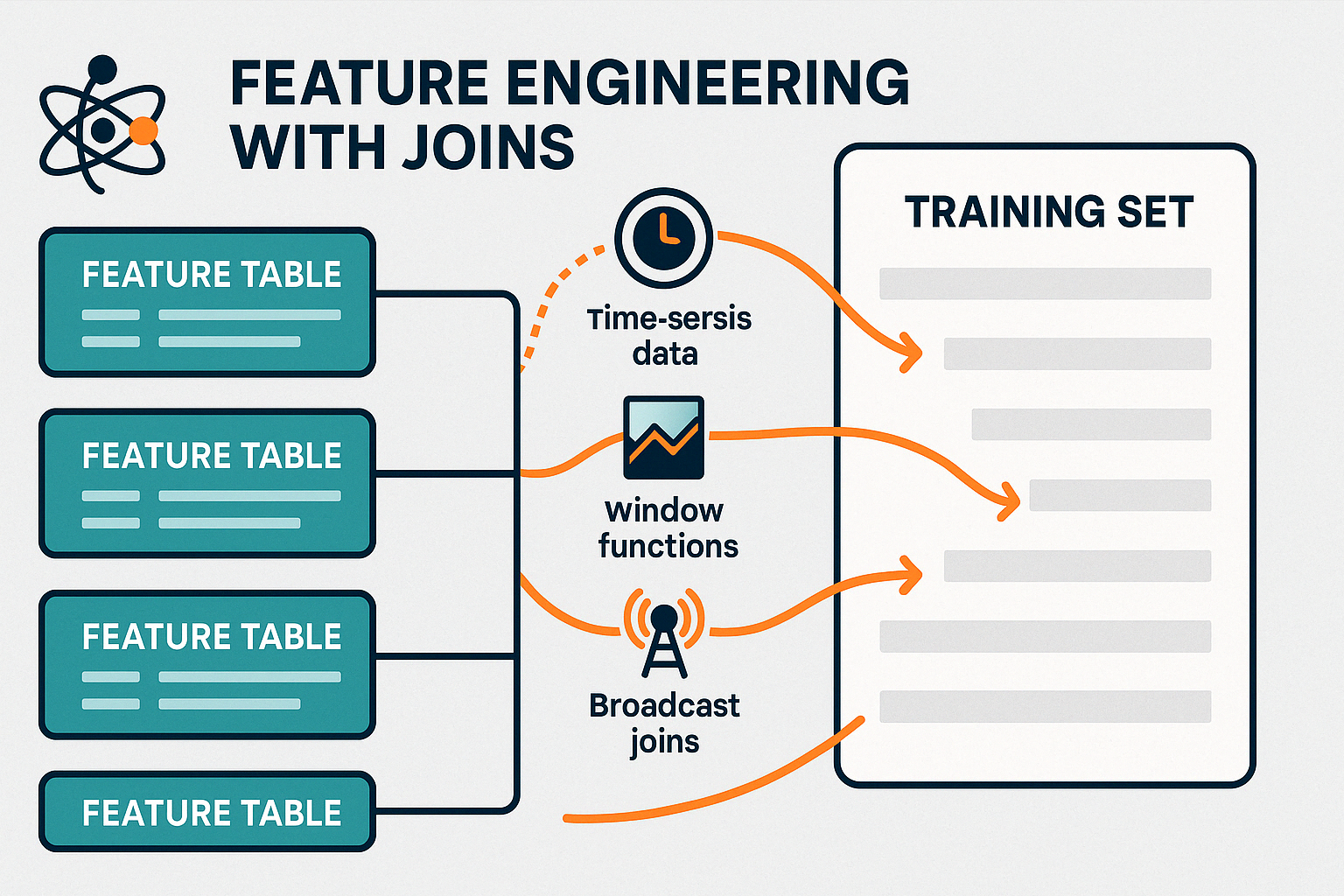
En gérant efficacement ces jointures, PySpark permet une ingénierie des fonctionnalités en temps réel, en prenant en charge à la fois les systèmes d'apprentissage en ligne et les pipelines d'apprentissage par lots actualisés.
Vous pouvez apprendre à faire des prédictions à partir de données avec Apache Spark, en utilisant des arbres de décision, la régression logistique, la régression linéaire, des ensembles et des pipelines avec notre... Apprentissage automatique avec PySpark.
Les opérations de jonction dans l'informatique distribuée requièrent une attention régulière afin d'éviter les problèmes potentiels.
Des opérations de jonction efficaces peuvent améliorer considérablement la vitesse globale du pipeline et l'utilisation des ressources. Voici les principales pratiques à suivre :
repartition() ou coalesce() pour ajuster la taille des partitions afin d'obtenir un traitement parallèle plus équilibré.Même de petites erreurs dans la logique de jointure peuvent entraîner des problèmes majeurs en termes de performances ou de précision des données. Voici les pièges les plus courants à éviter :
Même les jointures bien structurées peuvent rencontrer des problèmes de performance ou d'exécution.
Voici les problèmes les plus courants et la manière de les résoudre :
Les jointures PySpark sont la pierre angulaire du traitement des données à grande échelle, permettant des analyses puissantes et efficaces à travers des ensembles de données massifs. Lorsqu'ils sont utilisés correctement, ils révèlent des relations significatives qui permettent d'obtenir des informations plus approfondies et de prendre des décisions plus judicieuses.
Bien que l'optimisation des performances puisse présenter des défis, tels que la gestion de l'asymétrie des données ou l'optimisation du partitionnement, la maîtrise de ces aspects est essentielle pour construire des pipelines de données robustes.
Qu'il s'agisse de joindre des flux en temps réel ou de consolider des fonctionnalités pour l'apprentissage automatique, l'affinement de vos stratégies de jointure peut considérablement améliorer la vitesse d'exécution, l'efficacité des ressources et la précision de l'analyse.
Pour aller plus loin, explorez le traitement des big data avec PySpark et devenez un expert en ingénierie des données grâce à nos Fondamentaux du Big Data avec PySpark le cursus de compétences.
Les meilleurs cours de DataCamp
Cours
Cours
Cours