
Kurs
Grundlagen von Big Data mit PySpark
4 Std.
65.2K
PySpark ist die Python-API für Apache Spark, die für die parallele und verteilte Datenverarbeitung in Clustern entwickelt wurde. Die Wahl der richtigen Join-Operation für deine Bedürfnisse beeinflusst die Arbeitsgeschwindigkeit, den Ressourcenverbrauch und den Gesamterfolg.
Die Arbeit mit umfangreichen Datensätzen bedeutet oft, dass Daten aus verschiedenen Quellen integriert werden müssen. Die effektive Kombination dieser Informationen ist entscheidend für eine genaue Analyse und aussagekräftige Erkenntnisse. PySpark-Joins bieten leistungsstarke Möglichkeiten, getrennte Datensätze auf der Grundlage gemeinsamer Schlüssel zu kombinieren.
Ineffiziente Joins können jedoch die Geschwindigkeit und Zuverlässigkeit deiner Datenverarbeitung stark beeinträchtigen, wenn du mit großen Datensätzen mit Millionen oder sogar Milliarden von Datensätzen in verteilten Clustern arbeitest.
Hast du auch schon erlebt, dass Joins bei langsamen Analysen oder sogar bei großen Datenmengen fehlschlagen? Dann ist dieser Leitfaden genau das Richtige für dich. Es hilft fortgeschrittenen Datenwissenschaftlern, Entwicklern und Ingenieuren dabei, PySpark-Joins zu beherrschen und sicher durchzuführen.
Wenn du auf der Suche nach praktischen Übungen bist, um dich mit PySpark vertraut zu machen, schau dir unseren Big Data mit PySpark Lernpfad.
Wie du in unserem PySpark von Grund auf lernen Blogbeitrag lesen kannst, ist eine der wichtigsten Funktionen von PySpark die Fähigkeit, große Datensätze zusammenzuführen. PySpark Verknüpfungsoperationen sind unverzichtbar, um große Datensätze auf Basis gemeinsamer Spalten zu kombinieren und so eine effiziente Datenintegration, einen Vergleich und eine Analyse im großen Maßstab zu ermöglichen.
Sie spielen eine entscheidende Rolle im Umgang mit Big Data, indem sie helfen, Zusammenhänge aufzudecken und aussagekräftige Erkenntnisse aus verteilten Datenquellen zu gewinnen.
PySpark bietet verschiedene Arten von Joins, wie z.B. Inner Joins, Outer Joins, Left und Right Joins, Semi Joins, und Anti-Joinsdie jeweils unterschiedlichen analytischen Zwecken dienen.
Bei der Arbeit mit Joins auf großen Datenbeständen können jedoch Probleme auftreten, wie z. B. schiefe Daten, Overhead beim Shuffling und Speicherbeschränkungen, so dass die Wahl der richtigen Join-Strategie für Leistung und Genauigkeit entscheidend ist.
Das Verständnis der internen Abläufe von PySpark ist wichtig, um große Datensätze effizient zusammenzuführen, wie wir in unserem Kurs Einführung in PySpark. In diesem Abschnitt wird der konzeptionelle Rahmen für die Join-Ausführung von PySpark und die Rolle des Optimierers beschrieben.
PySpark führt Joins in einer verteilten Rechenumgebung durch, das heißt, es teilt große Datensätze in kleinere Partitionen auf und verarbeitet sie parallel auf einem Cluster von Rechnern. Wenn eine Verknüpfung ausgelöst wird, verteilt PySpark die Arbeit auf diese Knoten und strebt eine ausgewogene Berechnung an, um die Ausführung zu beschleunigen und Engpässe zu vermeiden.
Das Herzstück dieses Prozesses ist Catalyst, die leistungsstarke Abfrageoptimierungsmaschine von Spark. Catalyst bestimmt, wie Join-Operationen ausgeführt werden. Sie entscheidet über Partitionierungsstrategien, erkennt, wann eine Datenumschichtung notwendig ist, und wendet Leistungsoptimierungen wie Prädikat-Pushdown und Broadcast-Joins an. Diese automatische Optimierung sorgt für eine effiziente Ausführung, ohne dass der Entwickler manuell eingreifen muss.
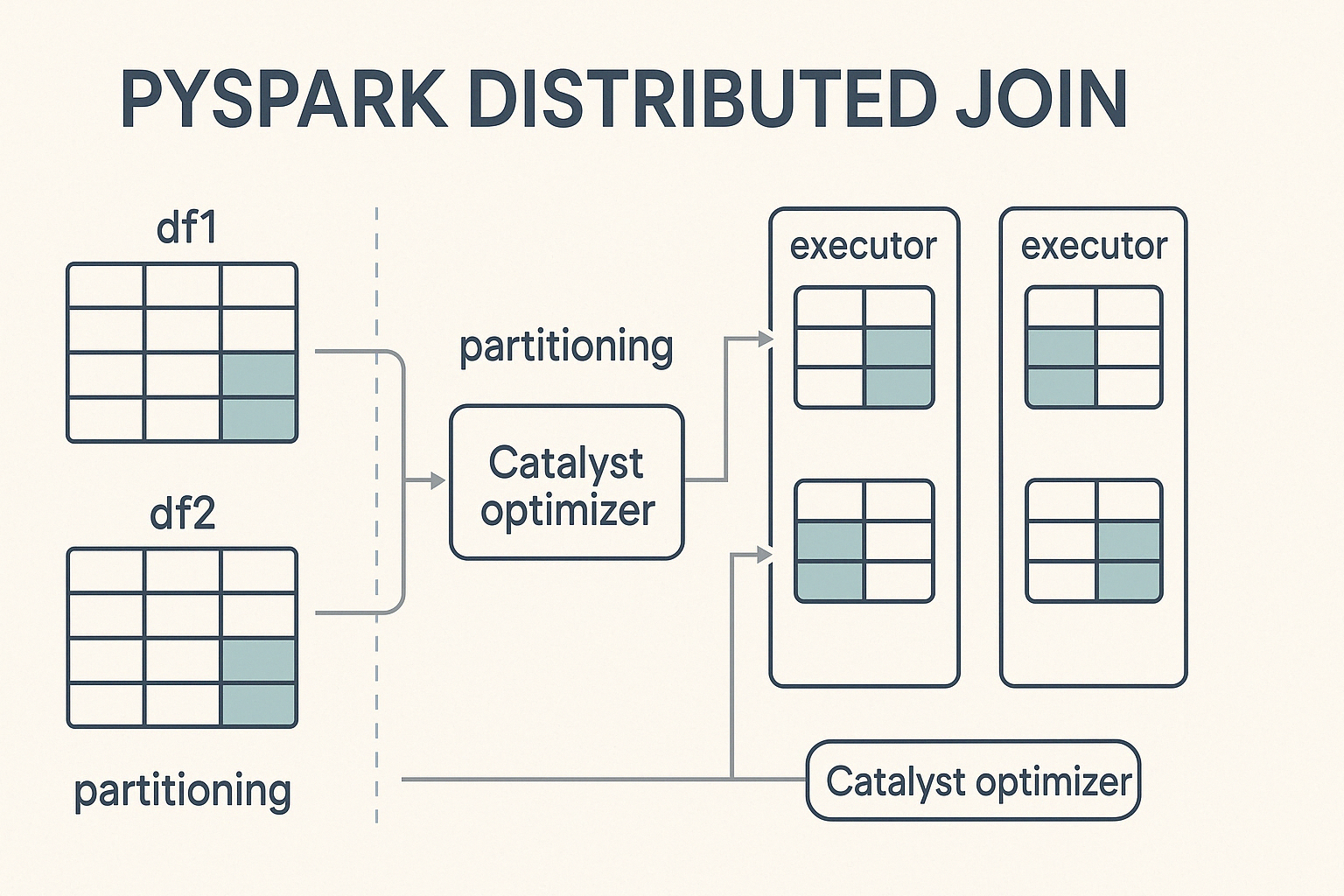
Um Joins in PySpark durchzuführen, folgst du einer einfachen Syntax, die die Angabe der DataFrames, a Verknüpfungsbedingungund die Typ der Verknüpfung der ausgeführt werden soll.
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder.appName("PySpark Joins Example").getOrCreate()
# Perform a join
joined_df = df1.join(df2, on="key", how="inner")In diesem Beispiel:
df1 und df2 sind die DataFrames, die verbunden werden sollen.df1.key == df2.key ist die Verknüpfungsbedingung, die festlegt, wie Zeilen aus jedem DataFrame abgeglichen werden sollen.inner' specifies the join type, which could also be links, rechts,, außen, halb, or anti` je nach dem gewünschten Ergebnis.In unserem Tutorial "Erste Schritte mit PySpark " erfährst du, wie du PySpark installierst und die obigen Joins fehlerfrei ausführst.
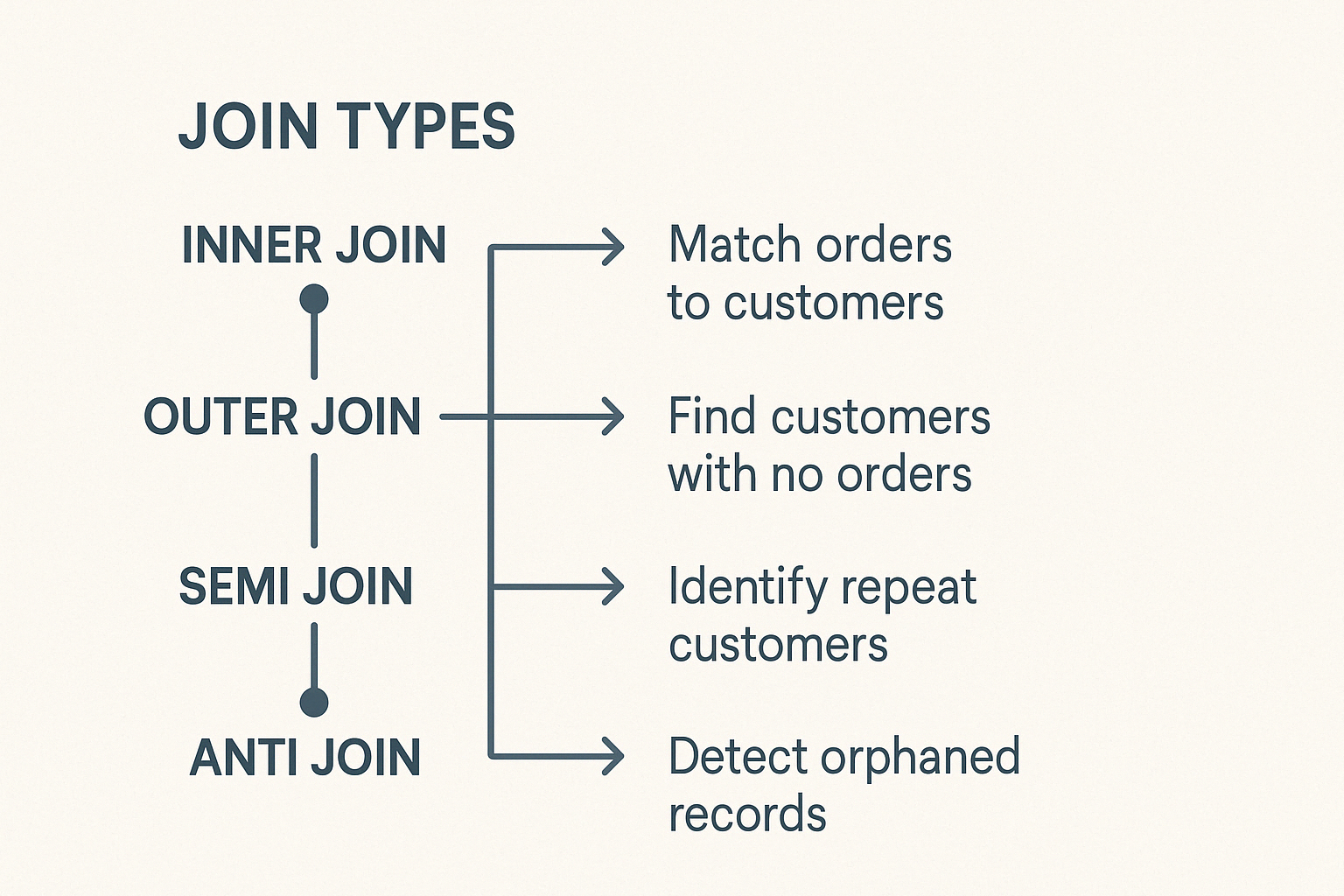
PySpark enthält verschiedene Arten von Joins, die jeweils für unterschiedliche Datenaufgaben geeignet sind. Wenn du das weißt, kannst du klug auswählen.
Die innere Verknüpfung kombiniert Zeilen aus zwei DataFrames, wenn übereinstimmende Schlüssel in beiden vorhanden sind. Zeilen ohne passende Schlüssel werden ausgeschlossen. Das ist der häufigste und standardmäßige Join-Typ in PySpark.
Typische Einsatzszenarien sind:
PySpark unterstützt linke, rechte und vollständige äußere Verknüpfungen.
Die linke äußere Verknüpfung liefert alle Zeilen aus dem linken DataFrame und passende Zeilen aus dem rechten DataFrame. Wenn im rechten DataFrame kein passender Schlüssel erscheint, werden die rechten Spalten mit Nullwerten gefüllt.
Anwendungsfälle:
Der rechte äußere Join spiegelt die Logik des linken Joins wider. Sie gibt alle Zeilen aus dem rechten DataFrame und die übereinstimmenden Zeilen aus dem linken DataFrame zurück und füllt fehlende Übereinstimmungen in den linken Spalten mit Nullen auf.
Beispielszenario:
Der Full Outer Join liefert alle verfügbaren Zeilen aus beiden DataFrames und füllt nicht übereinstimmende Einträge mit Nullen auf. Es hilft, Diskrepanzen oder Datenlücken zwischen zwei Datensätzen zu erkennen.
Semi- und Anti-Joints haben spezielle Funktionen:
Ein Semi-Join gibt Zeilen aus dem linken DataFrame zurück, wenn übereinstimmende Schlüssel im rechten DataFrame vorhanden sind. Es fügt keine Spalten aus dem richtigen DataFrame hinzu und vermeidet Duplikate, was es ideal für Existenzprüfungen macht.
Beispiel für einen Anwendungsfall:
Ein Anti-Join gibt Zeilen aus einem DataFrame zurück, die keinen passenden Schlüssel im zweiten DataFrame haben.
Beispiel für einen Anwendungsfall:
Cross Joins erstellen Daten, indem sie jede Zeile in einem DataFrame mit jeder Zeile in einem anderen DataFrame verknüpfen. Wenn es nicht ausdrücklich erwünscht ist, vermeide Cross-Joins, da sie die Datensätze drastisch erweitern.
Verwende sie mit Bedacht für bestimmte Szenarien wie z. B.:
Groß angelegte Zusammenschlüsse erfordern eine sorgfältige Optimierung. Ziehe die folgenden Techniken in Betracht:
Broadcast Joins verbessern die Leistung, indem sie kleinere DataFrames über alle Knoten hinweg replizieren und so kostspielige Shuffles vermeiden.
Beispiel für die Syntax:
from pyspark.sql.functions import broadcast
joined_df = large_df.join(broadcast(small_df), "id", "inner")Achte auf die Speicherbegrenzung deines Systems; das Senden von zu großen DataFrames wird nicht effektiv funktionieren.
Datenschieflage bedeutet, dass die Daten nicht gleichmäßig über die Partitionen verteilt sind, was zu Engpässen führt. Zu den Techniken zur Verringerung der Schräglage gehören:
Eine effiziente Join-Performance in PySpark hängt stark von der Minimierung des Shuffle-Overheads ab, der entsteht, wenn Daten zwischen Knoten verschoben werden müssen, um Join-Bedingungen zu erfüllen. Eine der effektivsten Möglichkeiten, diesen Overhead zu reduzieren, ist die Angleichung der Partitionen der zu verbindenden DataFrames.
Behalte diese Best Practices im Hinterkopf:
repartition() oder broadcast() mit Bedacht: Verwende repartition() für große Datensätze, bei denen eine gleichmäßige Verteilung möglich ist, und broadcast() für deutlich kleinere Tabellen, um das Mischen ganz zu vermeiden.PySpark enthält spezielle Mechanismen für anspruchsvollere Fälle, die eine noch größere Effizienz ermöglichen:
Bereichs-Joins werden verwendet, wenn du Zeilen auf der Grundlage von numerischen oder zeitbasierten Bedingungen abgleichst, anstatt exakter Gleichheit. Diese Verknüpfungen sind in Szenarien mit Zeitreihendaten üblich, z. B. bei der Log-Analyse, der Ereignisverfolgung oder bei IoT-Sensorströmen.
Zu den besten Praktiken für eine effiziente Verbindung von Bereichen gehören:
rangeBetween oder between.Beispiele für Anwendungsfälle sind:
Das Zusammenführen von Streaming-Daten stellt aufgrund der kontinuierlichen und oft unvorhersehbaren Natur dieser Daten eine besondere Herausforderung dar. Zu den Hauptproblemen gehören verspätet eintreffende Ereignisse, veraltete Daten und die Notwendigkeit, den Status im Laufe der Zeit effizient zu verwalten.
PySpark begegnet diesen Herausforderungen mit Wasserzeichen, die einen Schwellenwert festlegen, wie lange das System auf verspätete Daten warten soll, bevor es sie verwirft. Durch das Setzen eines Wasserzeichens auf Spalten mit Ereigniszeiten kann PySpark verspätete Daten effizient verwalten und die Ressourcennutzung optimieren.
Wasserzeichen sind besonders nützlich, wenn zwei Streaming-Quellen oder ein Stream mit einem statischen Datensatz verbunden werden, um sowohl die Leistung als auch die Konsistenz in Echtzeit-Datenpipelines zu erhalten.
Joins spielen eine entscheidende Rolle bei der Vorbereitung von Daten für Machine-Learning-Modelle, zum Beispiel bei der Modelle mit Spark MLlib erstellt werden. Die Konsolidierung dieser Merkmale in einem einzigen, vereinheitlichten Datensatz ist für ein genaues Modelltraining und eine genaue Bewertung unerlässlich.
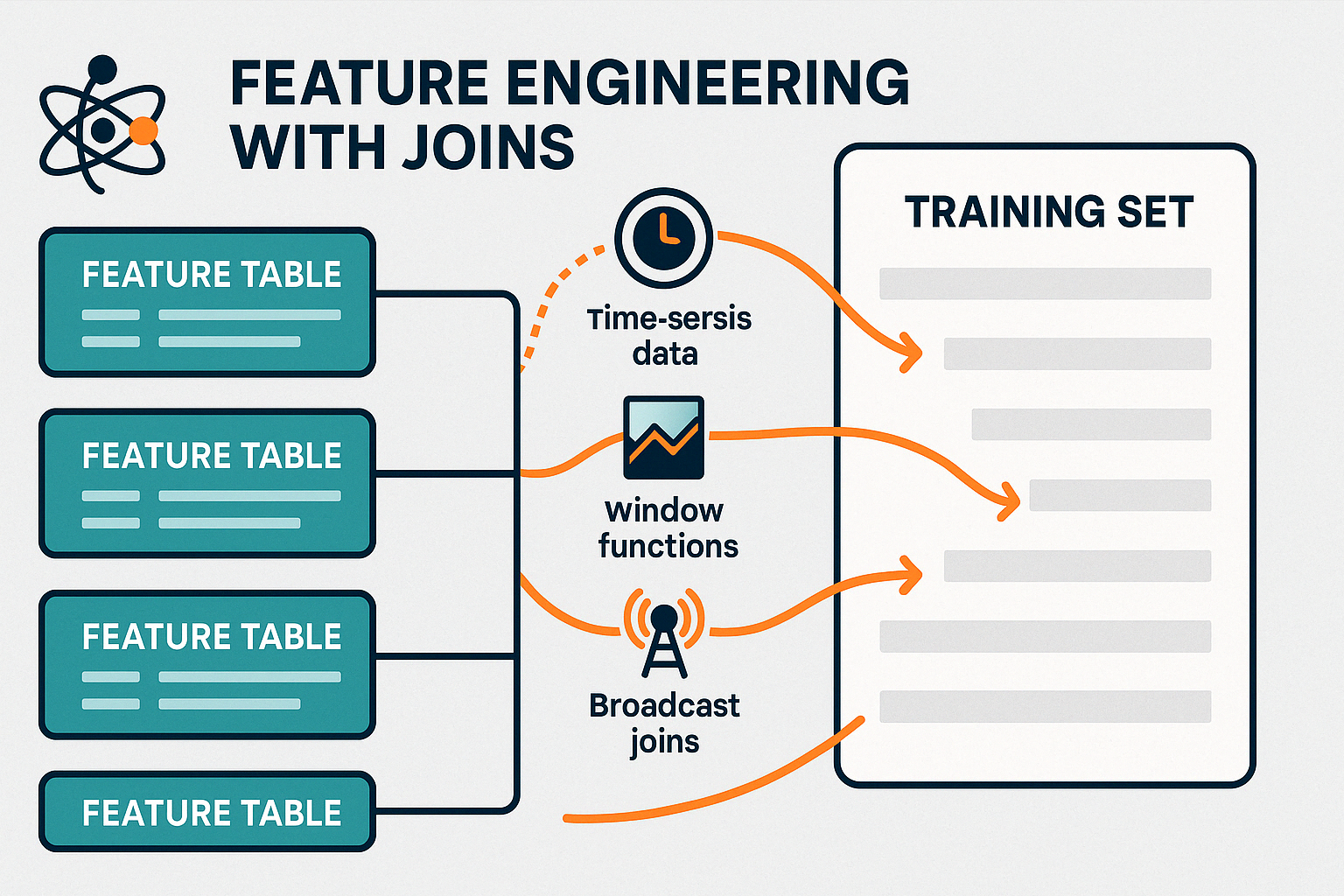
Durch die effiziente Verwaltung dieser Verknüpfungen ermöglicht PySpark das Feature Engineering in Echtzeit und unterstützt sowohl Online-Lernsysteme als auch aktuelle Batch-Trainingspipelines.
In unserem Kurs "Maschinelles Lernen mit Apache Spark" lernst du, wie du mit Hilfe von Entscheidungsbäumen, logistischer Regression, linearer Regression, Ensembles und Pipelines Vorhersagen aus Daten treffen kannst. Kurs Maschinelles Lernen mit PySpark.
Das Zusammenführen von Operationen im verteilten Rechnen erfordert regelmäßige Aufmerksamkeit, um mögliche Probleme zu vermeiden.
Effiziente Join-Operationen können die Gesamtgeschwindigkeit der Pipeline und die Ressourcennutzung drastisch verbessern. Hier sind die wichtigsten Praktiken, die du beachten solltest:
repartition() oder coalesce(), um die Partitionsgrößen für eine ausgewogenere parallele Verarbeitung anzupassen.Selbst kleine Fehler in der Verknüpfungslogik können zu großen Problemen bei der Leistung oder Datengenauigkeit führen. Hier sind die häufigsten Fallstricke, auf die du achten solltest:
Selbst bei gut strukturierten Joins können Leistungs- oder Ausführungsprobleme auftreten.
Hier sind die häufigsten Probleme und wie du sie lösen kannst:
PySpark-Joins sind ein Eckpfeiler für die Verarbeitung großer Datenmengen und ermöglichen eine leistungsstarke und effiziente Analyse riesiger Datensätze. Wenn sie richtig eingesetzt werden, zeigen sie aussagekräftige Zusammenhänge auf, die zu tieferen Einsichten und klügeren Entscheidungen führen.
Auch wenn das Leistungstuning einige Herausforderungen mit sich bringt, wie z.B. den Umgang mit schiefen Daten oder die Optimierung der Partitionierung, ist die Beherrschung dieser Aspekte der Schlüssel zum Aufbau robuster Datenpipelines.
Ganz gleich, ob du Echtzeit-Streams zusammenführst oder Features für maschinelles Lernen konsolidierst, die Verfeinerung deiner Join-Strategien kann die Ausführungsgeschwindigkeit, Ressourceneffizienz und analytische Präzision erheblich verbessern.
Wenn du tiefer eintauchen willst, erforsche die Big Data-Verarbeitung mit PySpark und werde ein Experte für Data Engineering mit unserem Big Data-Grundlagen mit PySpark Lernpfad.
Top DataCamp Kurse
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
