programa
Fundaciones de Snowflake
7 h
Snowflake es una plataforma de datos nativa en la nube muy utilizada por los profesionales de los datos debido a su escalabilidad, rendimiento y simplicidad, lo que la hace ideal para todo, desde la analítica a la ciencia de datos. Sin embargo, para sacar el máximo partido de la herramienta, es esencial dominar la ingestión de datos de Snowflake. Si eres nuevo en la plataforma, te sugiero que empieces con este Tutorial de Snowflake para principiantes para familiarizarte primero con su arquitectura.
Para garantizar que los datos estén disponibles y sean fiables para los casos de uso posteriores, es fundamental que las canalizaciones de ingestión de datos sean eficientes y estén correctamente desarrolladas. Tanto si se trata de actualizaciones periódicas por lotes como de flujos de datos en tiempo real, elegir el método y las herramientas de ingesta adecuados repercute directamente en el rendimiento y la capacidad de mantenimiento de tu canalización de datos.
Antes de entrar en detalles, es esencial comprender algunos conceptos clave sobre el flujo de datos..:
La ingesta de datos se refiere al proceso de trasladar datos de diversas fuentes a una base de datos para su almacenamiento, procesamiento y análisis. Tanto si tus datos proceden de almacenamiento en la nube, bases de datos, aplicaciones o flujos de eventos, la ingestión actúa como el primer paso en el ciclo de vida de los datos dentro de Snowflake.
La arquitectura única de Snowflake separa el cálculo y el almacenamiento. Esto permite simplificar el proceso de ingesta de datos sin afectar al rendimiento analítico. La ingestión puede dirigirse a etapas internas (dentro de Snowflake) o externas (como S3 o Azure Blob Storage), dependiendo de la fuente de datos y del caso de uso. Para más información, este artículo profundiza en Arquitectura copo de nieve.
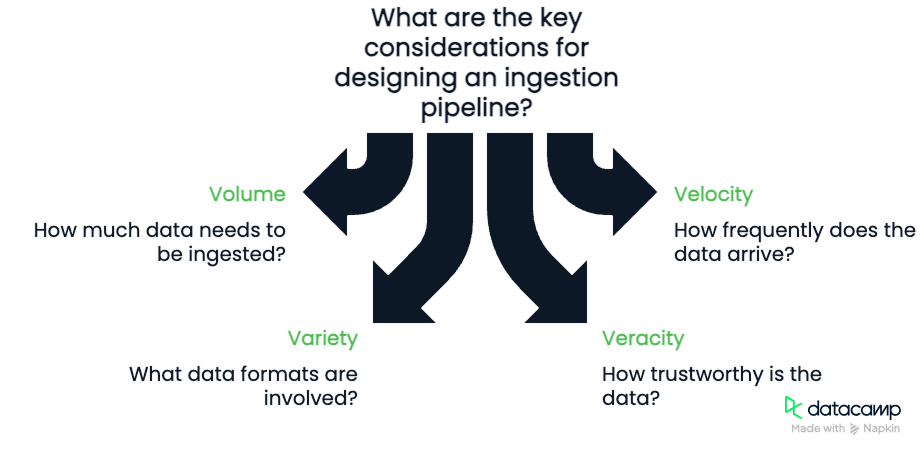
Al diseñar un canal de ingesta, ten en cuenta las Las cuatro V de los datos:
Es importante tener en cuenta estos cuatro componentes. El volumen y la velocidad nos obligarán a tener en cuenta el ancho de banda de que dispone nuestra tubería y su capacidad para procesar los datos. La variedad y la veracidad exigirán que desarrollemos canalizaciones robustas y flexibles, capaces de comprobar la calidad de los datos a medida que fluyen.
Vamos a discutir algunos de los métodos de ingestión de datos que tenemos disponibles en Snowflake. Algunos métodos implican utilizar un comando como COPY INTO, Snowpipe o Snowpipe streaming.
El método de ingestión más fundamental de Snowflake es el comando COPY INTO. COPY INTO carga datos de archivos almacenados en etapas externas en tablas de Snowflake. Es ideal para la carga masiva de datos históricos o actualizaciones periódicas por lotes.
Puedes cargar datos de Amazon S3, Azure Blob Storage o Google Cloud Storage creando una etapa externa que conecte esos servicios en la nube a Snowflake. Con la ruta de archivo y las credenciales correctas, Snowflake lee y procesa los archivos con eficacia.
COPY INTO admite varios formatos: CSV, JSON, Avro, ORC y Parquet. Como parte de la creación del conector, hay varias opciones de tipo de formato. La lista es bastante extensa, pero a menudo hay opciones para definir cosas como el formato de las fechas, los delimitadores (comas u otros valores), la codificación, las opciones nulas, etc. Te recomiendo encarecidamente que leas la documentación del sitio web de Snowflake para obtener todos los detalles.
Puedes configurar la opción ON_ERROR para que omita las filas problemáticas, aborte la carga o registre los errores. Combínalo con el VALIDATION_MODE para rastrear y devolver los errores. Puedes utilizar tablas de metadatos como LOAD_HISTORY, que también registran el número de errores que se producen durante una carga.
Snowpipe permite la ingesta continua detectando y cargando automáticamente los archivos nuevos a medida que aparecen en una etapa designada. Esta funcionalidad está integrada en la plataforma Snowflake. Ofrece integración automática de archivos, activadores basados en eventos y supervisión.
Snowpipe puede configurarse para que realice pruebas automáticas de los archivos mediante la integración con las notificaciones de almacenamiento en la nube, lo que reduce la necesidad de ejecución manual. Por ejemplo, Amazon S3 tiene notificaciones de eventos que alertan a los usuarios de los cambios en un bucket concreto.
Snowpipe puede conectarse a un usuario que vea estas notificaciones. Cuando ese usuario reciba una notificación de evento, Snowpipe se activará para iniciar el proceso de ingesta de datos.
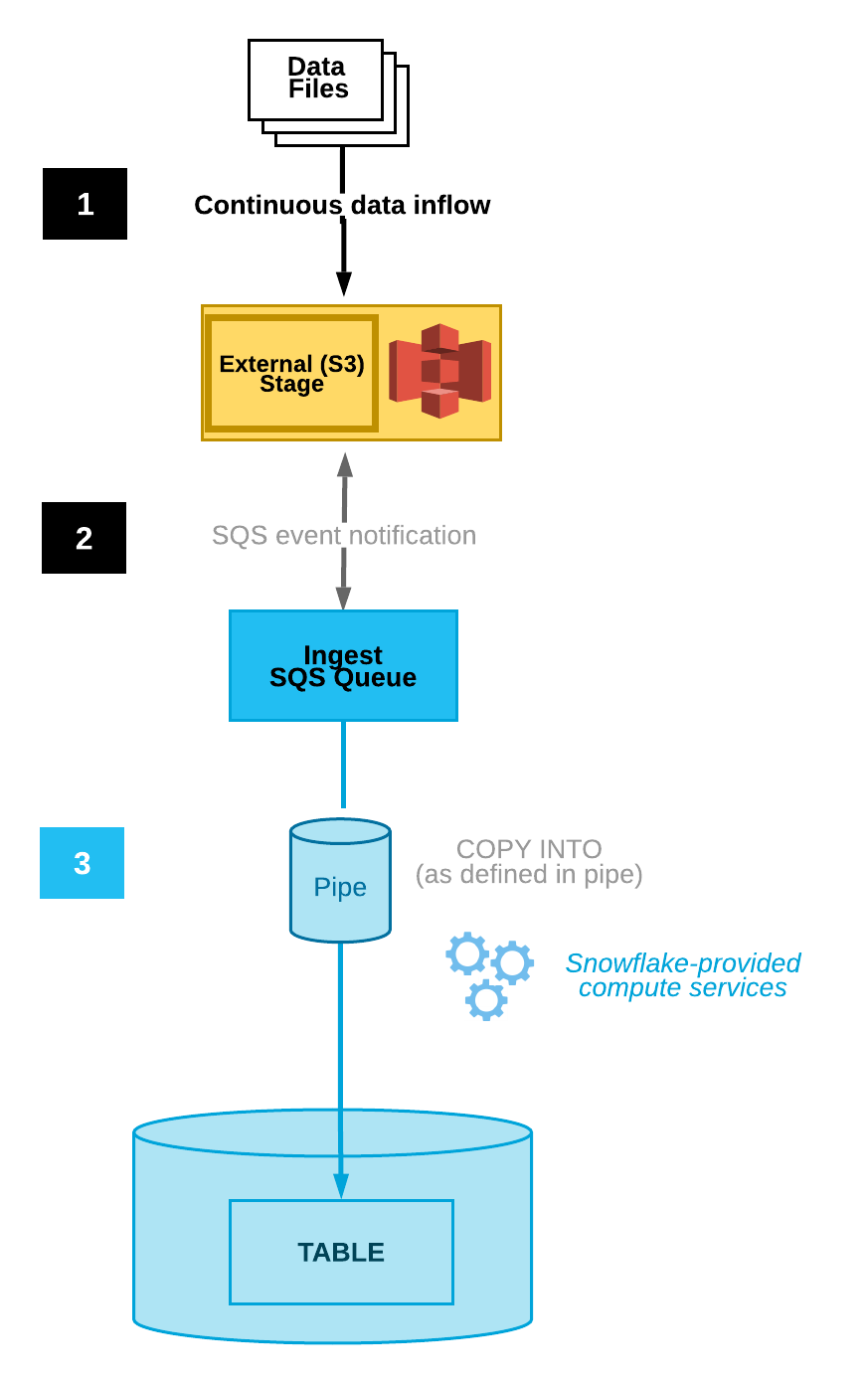
Diagrama de la ingestión automatizada de datos(Documentación Snowflake)
Snowflake proporciona algunas herramientas diferentes de supervisión y gestión de errores. La tabla de metadatos PIPE_USAGE_HISTORYpermite a los usuarios ver el historial de carga de datos, como bytes y archivos ingestados. La tabla VALIDATE_PIPE_LOAD proporcionará información sobre los errores que se produzcan.
Dentro de Snowpipe, existe la configuración ON_ERROR, que nos permite saltar archivos y enviar notificaciones que nos avisen de los errores.
Snowpipe Streaming es el método más reciente de Snowflake para ingerir datos de flujo en tiempo real con una latencia inferior al segundo. A diferencia de Snowpipe, que reacciona a los archivos, Snowpipe Streaming ingiere los datos fila a fila a través de una API. Estos métodos se complementan entre sí, ofreciendo flexibilidad y eficacia.
El Snowflake Ingest SDK permite a los desarrolladores escribir aplicaciones Java o Scala que introducen datos directamente en Snowflake utilizando una cola residente en memoria. Estas aplicaciones están diseñadas para aceptar datos a nivel de fila desde lugares como temas de Apache Kafka y otros conectores de streaming.
Perfecto para datos de telemetría, clickstream o IoT, Snowpipe Streaming garantiza la disponibilidad de los datos casi en tiempo real, con una mínima sobrecarga de almacenamiento y un alto rendimiento. Este método de ingestión es perfecto cuando necesitas datos de alta velocidad casi en tiempo real.
Como parte de la ingesta de datos en Snowflake utilizando cosas como Snowpipe y Snowpipe Streaming, hay algunas herramientas que son necesarias para conectar correctamente las canalizaciones de datos. Una herramienta importante es Kafka, que se utiliza habitualmente como herramienta de comunicación entre las fuentes de datos y Snowflake. Como alternativa, existen algunas herramientas de terceros, como Fivetran y Matillion, que también pueden gestionar el ETL en Snowflake.
Snowflake ofrece un conector Kafka que lee de temas Kafka y escribe mensajes directamente en el almacenamiento Snowflake. Los datos se publican en Kafka, y utilizando Snowpipe o Snowpipe Streaming, Snowflake puede recoger estos datos publicados y transferirlos al almacenamiento interno. Es una forma muy flexible de transferir datos. Recomiendo este curso de Introducción a Apache Kafka, que cubre la potencia y escalabilidad de Kafka.
Tendrás que configurar un trabajador de Kafka Connect y establecer parámetros como nombres de temas, tamaños de búfer y credenciales de Snowflake para configurar correctamente la integración.
Estas configuraciones también nos permiten establecer los tipos de datos y la información de metadatos que nos gustaría rastrear. Las dos formas principales de definir estas conexiones es a través de Confluent (una versión gestionada por terceros de Apache Kafka) o manualmente utilizando el JDK de Apache Kafka de código abierto.
Independientemente de cuál elijas, sigue estas buenas prácticas:
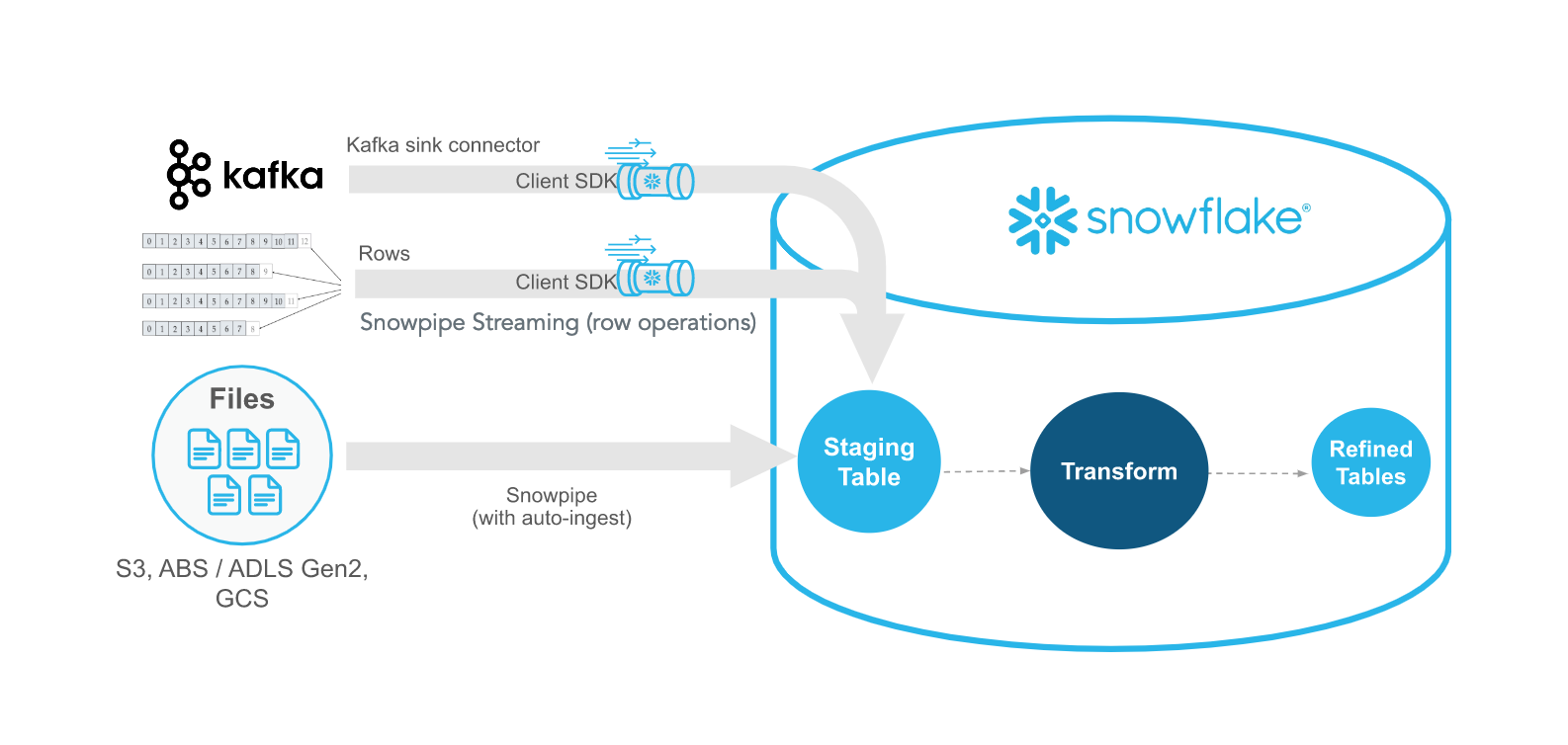
Ejemplo de uso de Kafka conSnowflake SDK para streaming de datos(Documentación de Snowflake)
Además de Kafka, hay plataformas ETL de terceros, como Fivetran, Matillion y Talend, que proporcionan soluciones ETL/ELT gestionadas para ingerir y transformar datos de cientos de fuentes en Snowflake. Estas plataformas de terceros suelen ofrecer soluciones SaaS simplificadas y de bajo código para la gestión de datos, pero elegir estas plataformas tiene sus propios inconvenientes.
Algunos aspectos deben tenerse muy en cuenta al utilizar herramientas ETL de terceros, como el coste y la flexibilidad. Aunque sin duda son enfoques simplificados para la ingesta de datos en Snowflake, pueden existir algunas restricciones que, en última instancia, harán que su uso resulte más complicado.
Conociendo estas limitaciones, a la hora de decidirte por la herramienta adecuada, debes tener en cuenta:
Aunque diseñar un pipeline es un trabajo duro, hay algunos conceptos generales y buenas prácticas que puedes seguir para hacerte la vida más fácil. Su objetivo es mejorar la eficacia y minimizar los costes.
Minimiza el tamaño de tus archivos para reducir el coste del almacenamiento de datos utilizando formatos de archivo como gzip o Parquet. Además, cuando se transfieren los datos, a menudo es mejor favorecer menos archivos grandes en lugar de muchos más pequeños para tu proceso de copia. Los archivos grandes individuales tienen menos sobrecarga de red que intentar transferir varios archivos más pequeños. Por último, programa los trabajos por lotes grandes en horas valle si te preocupan los costes de computación y de red.
Por último, asegúrate de gestionar la evolución del esquema en tus canalizaciones. Algunos tipos de datos, como Parquet, permiten de forma natural la evolución del esquema. Esto significa que, aunque el esquema de datos puede cambiar con respecto a la fuente de datos, no afecta a los datos históricos y mantiene la compatibilidad hacia delante/atrás de los datos.
Otra cosa que hay que tener en cuenta durante la ingesta de datos es garantizar la calidad y la observabilidad de los datos. Una forma inteligente de hacerlo es poner en escena los datos antes de integrarlos en el almacenamiento final de tu base de datos. Puede que quieras comprobar los hashes y los metadatos para garantizar la exactitud de los datos y la ausencia de corrupción. Además, en lugar de permitir a los usuarios el acceso directo a los propios datos, la construcción de vistas que puedan combinar fuentes de datos dispares puede proporcionar una mejor experiencia al usuario.
Por último, debes controlar y registrar constantemente el estado de tu canalización de datos. Configura cuadros de mando utilizando las vistas de metadatos de Snowflake o herramientas externas de observabilidad como DataDog o Monte Carlo para realizar un seguimiento del éxito, la latencia y los fallos de la ingestión.
Aquí cubriremos algunos ejemplos de alto nivel de cómo puedes construir canalizaciones en Snowflake. Ten en cuenta que tus pasos exactos pueden ser diferentes dependiendo de cómo haya configurado tu administrador de datos tu entorno Snowflake. Asegúrate de seguir las mejores prácticas de tu organización.
En primer lugar, algunos requisitos previos. Necesitarás una cuenta Snowflake que te permita gestionar la base de datos. Algunos permisos de acceso comunes que necesitarás es la capacidad de crear esquemas. En segundo lugar, debes asegurarte de que el servidor en el que estás tiene acceso al cubo externo de almacenamiento en la nube o al almacenamiento interno donde guardas los datos. Habla de ello con el administrador de tu base de datos.
COPY INTOVamos a ver un ejemplo sencillo de carga de un archivo CSV en tu base de datos Snowflake.
1. Prepara y sube los datos Formatea tus archivos (por ejemplo, CSV) y súbelos a tu cubo de almacenamiento en la nube.
2. Crear escenario y formato de archivo
/* specify the file format */CREATE FILE FORMAT my_csv_format TYPE = 'CSV'
/* this will help if there are double quotes or apostrophes in your data */
FIELD_OPTIONALLY_ENCLOSED_BY='"';
/* Stage the data using the credentials you have */
CREATE STAGE my_stage URL='s3://my-bucket/data/' CREDENTIALS=(AWS_KEY_ID='...' AWS_SECRET_KEY='...');3. Ejecuta COPY INTO y verifica
COPY INTO my_table FROM @my_stage FILE_FORMAT = (FORMAT_NAME = 'my_csv_format');SELECT * FROM my_table;Crear una ingesta automatizada con Snowpipe puede ser bastante sencillo.
1. Crear tubo de nieve
CREATE PIPE my_pipe
AUTO_INGEST = TRUE
AWS_SNS_TOPIC = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket'
AS
COPY INTO my_table
FROM @my_stage
FILE_FORMAT = (TYPE = ‘CSV’);2. Configurar eventos de almacenamiento en la nube Configura la notificación del cubo S3 para activar la tubería mediante SNS/SQS. Para más detalles, yo seguiría esta guía sobre AWS SNS de Datacamp.
3. Vigila la ingestión
Asegúrate de consultar la tabla de metadatos SNOWPIPE_EXECUTION_HISTORY para ver la actividad de las tuberías.
Configurar Snowpipe Streaming puede ser bastante intenso y es algo más detallado de lo que podemos cubrir aquí. Cubriré algunos de los pasos fundamentales, pero sobre todo recomiendo leer los ejemplos de la documentación de Snowflake Streaming para saber cómo construir el SDK cliente.
profile.json. Las propiedades requeridas implican las credenciales de autorización, la URL para Snowflake y el usuario. Esto permite al SDK conectarse a tu servidor Snowflake. Escribe el resto de tu script Java para manejar la llegada de datos, incluido el método insertRows.Snowflake ofrece un conjunto robusto y flexible de métodos de ingestión de datos, desde las tradicionales cargas por lotes hasta el streaming en tiempo real. Al conocer las herramientas y técnicas disponibles, los equipos de datos pueden diseñar canalizaciones que sean fiables, eficaces y rentables. Tanto si acabas de empezar como si estás optimizando una solución a escala empresarial, dominar la ingesta de datos Snowflake es un paso fundamental para construir una pila de datos moderna. Si quieres saber más sobre Snowflake, te recomiendo encarecidamente los siguientes recursos:
Los mejores cursos de copos de nieve
programa
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Tim Lu
Tutorial
Natassha Selvaraj
Tutorial
Moez Ali
Tutorial
Vikash Singh
Tutorial
Anneleen Rummens
