Programa
Fundações para Snowflake
7 h
A Snowflake é uma plataforma de dados nativa da nuvem amplamente usada por profissionais de dados devido à sua escalabilidade, desempenho e simplicidade, o que a torna ideal para tudo, desde a análise até a ciência de dados. No entanto, para que você possa tirar o máximo proveito da ferramenta, é essencial dominar a ingestão de dados do Snowflake. Se você é novo na plataforma, sugiro que comece com este Tutorial do Snowflake para iniciantes para que você se familiarize primeiro com sua arquitetura.
Pipelines de ingestão de dados eficientes e desenvolvidos adequadamente são essenciais para garantir que os dados estejam disponíveis e sejam confiáveis para casos de uso downstream. Seja lidando com atualizações periódicas em lote ou com fluxos de dados em tempo real, a escolha do método e das ferramentas de ingestão corretos afeta diretamente o desempenho e a capacidade de manutenção do seu pipeline de dados.
Antes de entrar em detalhes, é essencial que você entenda alguns conceitos-chave sobre o fluxo de dados..:
A ingestão de dados refere-se ao processo de mover dados de várias fontes para um banco de dados para armazenamento, processamento e análise. Independentemente de seus dados serem originários de armazenamento em nuvem, bancos de dados, aplicativos ou fluxos de eventos, a ingestão atua como a primeira etapa do ciclo de vida dos dados no Snowflake.
A arquitetura exclusiva do Snowflake separa a computação e o armazenamento. Isso permite um processo simplificado de ingestão de dados sem afetar o desempenho analítico. A ingestão pode ter como alvo estágios internos (dentro do Snowflake) ou externos (como o S3 ou o Azure Blob Storage), dependendo da fonte de dados e do caso de uso. Para obter mais informações, este artigo analisa profundamente a Arquitetura Snowflake.
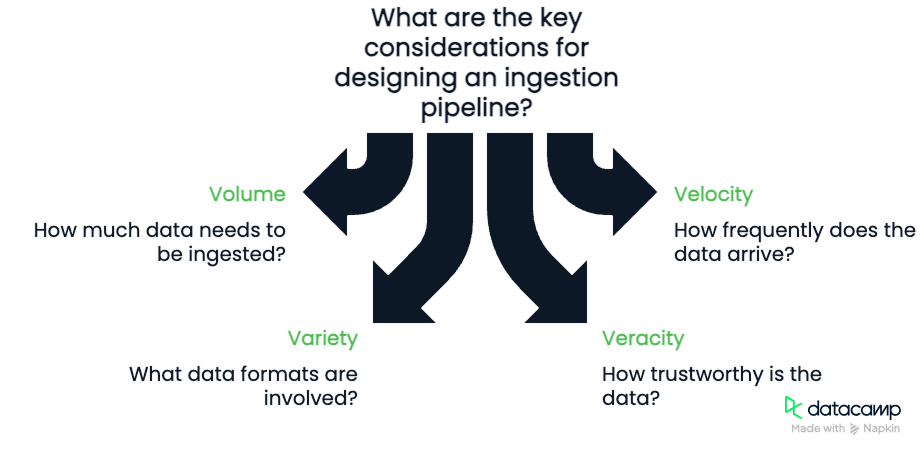
Ao projetar um pipeline de ingestão, tenha em mente os Quatro Vs dos dados:
É importante que você considere esses quatro componentes. O volume e a velocidade exigirão que consideremos a largura de banda disponível para nosso pipeline e sua capacidade de processar dados. A variedade e a veracidade exigirão que desenvolvamos pipelines robustos e flexíveis, capazes de verificar a qualidade dos dados à medida que eles fluem.
Vamos discutir alguns dos métodos de ingestão de dados que temos disponíveis no Snowflake. Alguns métodos envolvem o uso de um comando como COPY INTO, Snowpipe ou Snowpipe streaming.
O método de ingestão mais fundamental do Snowflake é o comando COPY INTO. COPY INTO carrega dados de arquivos armazenados em estágios externos para as tabelas do Snowflake. É ideal para carregar dados históricos em massa ou atualizações regulares em lote.
Você pode carregar dados do Amazon S3, do Azure Blob Storage ou do Google Cloud Storage criando um estágio externo que conecte esses serviços de nuvem ao Snowflake. Com o caminho correto do arquivo e as credenciais, o Snowflake lê e processa os arquivos com eficiência.
COPY INTO suporta vários formatos: CSV, JSON, Avro, ORC e Parquet. Como parte da criação do conector, há várias opções de tipo de formato. A lista é bastante extensa, mas geralmente há configurações para definir coisas como o formato das datas, delimitadores (vírgulas ou outros valores), codificação, opções nulas e assim por diante. Recomendo que você leia a documentação no site da Snowflake para obter todos os detalhes.
Você pode configurar a opção ON_ERROR para ignorar linhas problemáticas, abortar o carregamento ou registrar erros. Combine isso com o programa VALIDATION_MODE para rastrear e retornar erros. Você pode usar tabelas de metadados como LOAD_HISTORY, que também rastreiam o número de erros que ocorrem durante uma carga.
O Snowpipe permite a ingestão contínua, detectando e carregando automaticamente novos arquivos à medida que eles aparecem em um estágio designado. Essa funcionalidade está incorporada à plataforma Snowflake. Ele oferece integração automática de arquivos, acionadores baseados em eventos e monitoramento.
O Snowpipe pode ser configurado para testar automaticamente os arquivos por meio da integração com notificações de armazenamento em nuvem, reduzindo a necessidade de execução manual. Por exemplo, o Amazon S3 tem notificações de eventos que alertam os usuários sobre alterações em um determinado bucket.
O Snowpipe pode ser conectado a um usuário que vê essas notificações. Quando uma notificação de evento for recebida por esse usuário, o Snowpipe será acionado para iniciar o processo de ingestão de dados.
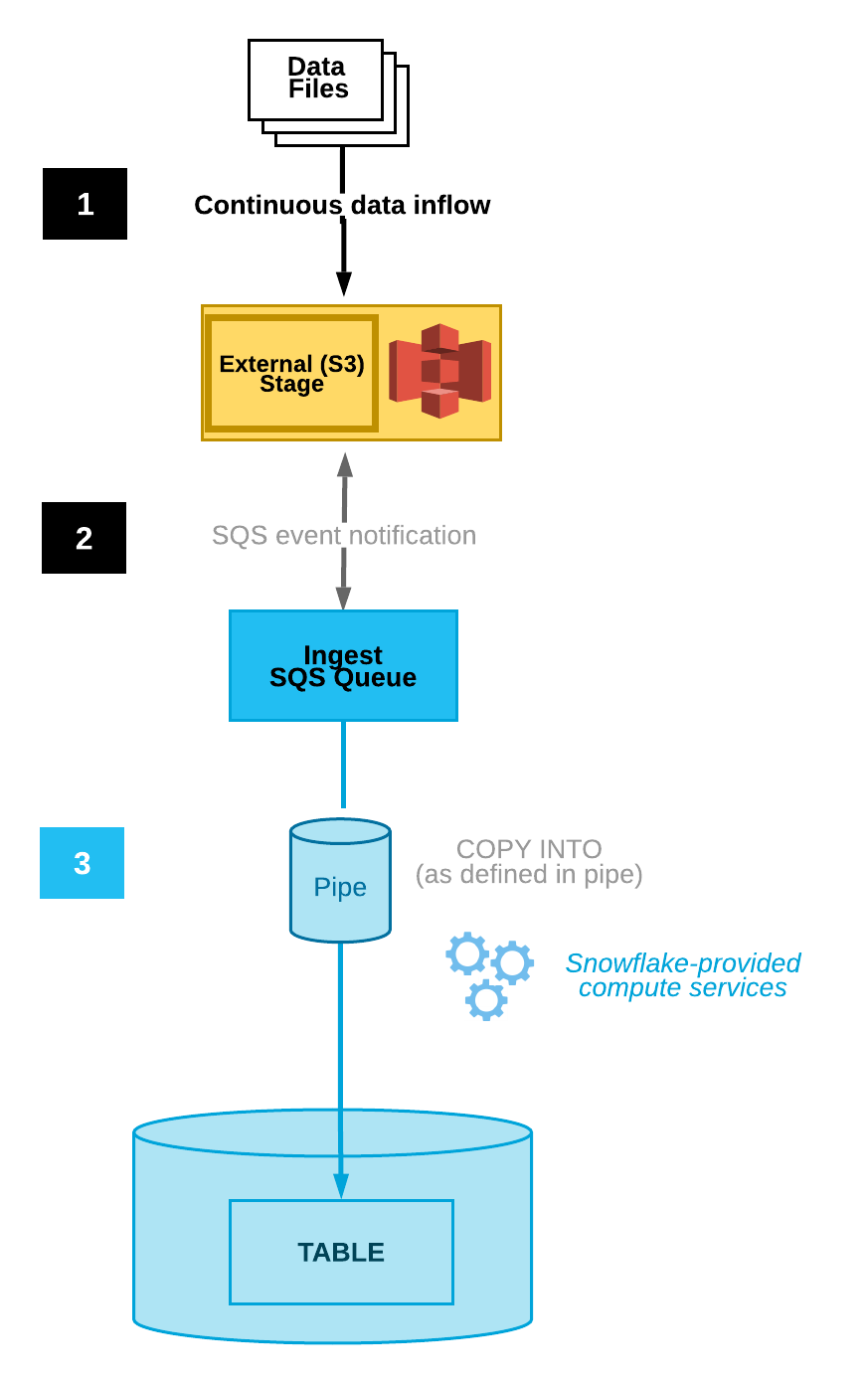
Diagrama de ingestão automatizada de dados(Documentação do Snowflake)
O Snowflake fornece algumas ferramentas diferentes de monitoramento e gerenciamento de erros. A tabela de metadados PIPE_USAGE_HISTORYpermite que os usuários visualizem o histórico de carregamento de dados, como bytes e arquivos ingeridos. Na tabela VALIDATE_PIPE_LOAD, você encontrará informações sobre os erros que ocorrem.
No Snowpipe, há a configuração ON_ERROR, que nos permite ignorar arquivos e enviar notificações que nos alertam sobre os erros.
O Snowpipe Streaming é o mais novo método do Snowflake para ingerir dados de streaming em tempo real com latência de menos de um segundo. Ao contrário do Snowpipe, que reage a arquivos, o Snowpipe Streaming ingere dados linha por linha por meio de uma API. Esses métodos se complementam, oferecendo flexibilidade e eficiência.
O Snowflake Ingest SDK permite que os desenvolvedores escrevam aplicativos Java ou Scala que enviam dados diretamente para o Snowflake usando uma fila residente na memória. Esses aplicativos são projetados para aceitar dados em nível de linha de locais como tópicos do Apache Kafka e outros conectores de streaming.
Perfeito para dados de telemetria, clickstream ou IoT, o Snowpipe Streaming garante a disponibilidade de dados quase em tempo real com o mínimo de sobrecarga de armazenamento e alta taxa de transferência. Esse método de ingestão é perfeito quando você precisa de dados de alta velocidade quase em tempo real.
Como parte da ingestão de dados no Snowflake usando coisas como o Snowpipe e o Snowpipe Streaming, há algumas ferramentas que são necessárias para que você conecte os pipelines de dados adequadamente. Uma das principais ferramentas é o Kafka, que é comumente usado como uma ferramenta de comunicação entre as fontes de dados e o Snowflake. Como alternativa, existem algumas ferramentas de terceiros, como Fivetran e Matillion, que também podem gerenciar o ETL no Snowflake.
O Snowflake oferece um conector Kafka que lê tópicos do Kafka e grava mensagens diretamente no armazenamento do Snowflake. Os dados são publicados no Kafka e, usando o Snowpipe ou o Snowpipe Streaming, o Snowflake pode pegar esses dados publicados e transferi-los para o armazenamento interno. Essa é uma maneira extremamente flexível de transferir dados. Recomendo a você este curso Introduction to Apache Kafka, que aborda o poder e a escalabilidade do Kafka.
Você precisará configurar um trabalhador do Kafka Connect e definir parâmetros como nomes de tópicos, tamanhos de buffer e credenciais do Snowflake para configurar corretamente a integração.
Essas configurações também nos permitem definir os tipos de dados e as informações de metadados que gostaríamos de rastrear. As duas principais maneiras de definir essas conexões são por meio do Confluent (uma versão gerenciada por terceiros do Apache Kafka) ou manualmente usando o Apache Kafka JDK de código aberto.
Independentemente de qual você escolher, siga estas práticas recomendadas:
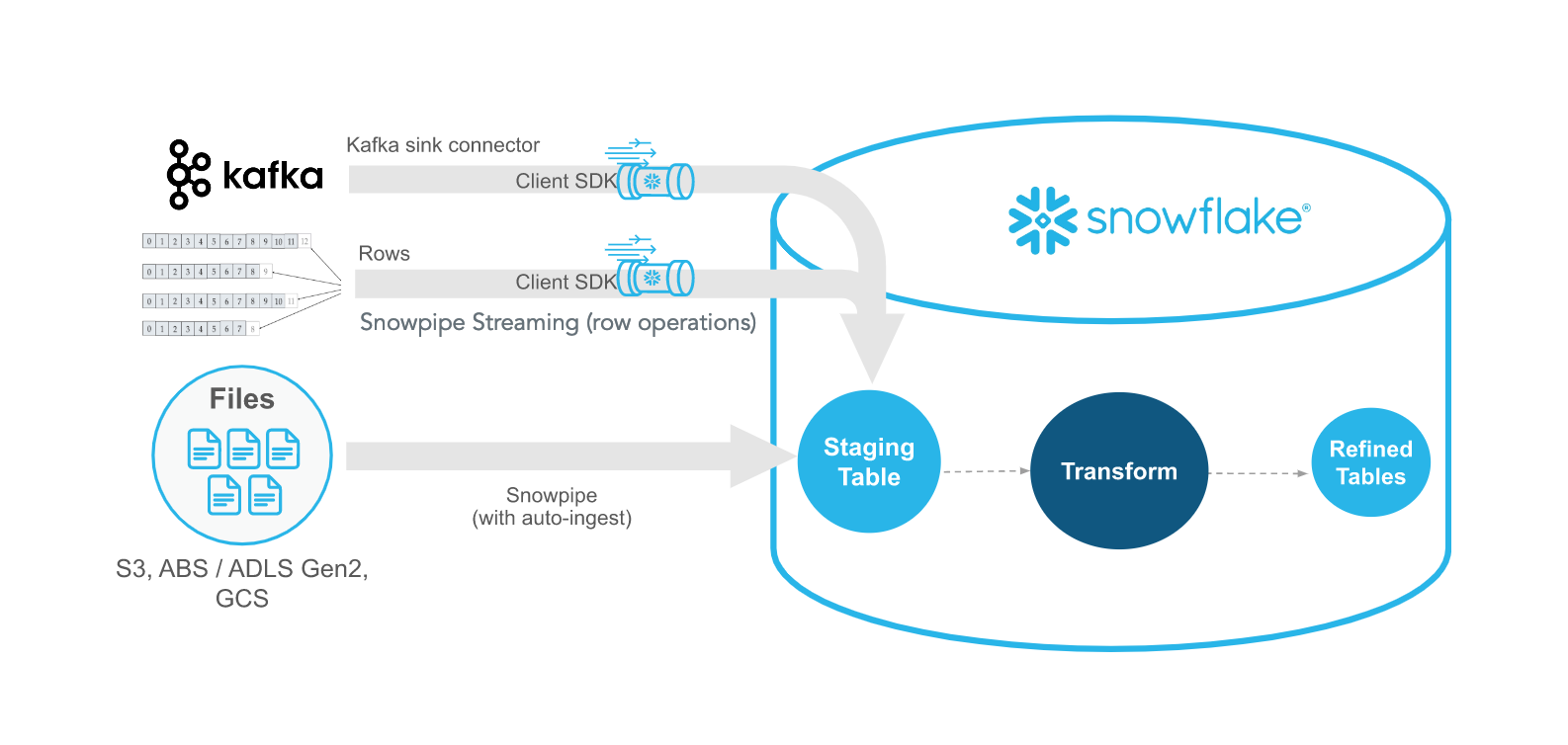
Exemplo de uso do Kafka com o Snowflake SDK para streaming de dados(Documentação do Snowflake)
Além do Kafka, há plataformas ETL de terceiros, como Fivetran, Matillion e Talend, que fornecem soluções ETL/ELT gerenciadas para ingerir e transformar dados de centenas de fontes no Snowflake. Essas plataformas de terceiros geralmente oferecem soluções SaaS simplificadas e de baixo código para o gerenciamento de dados, mas a escolha dessas plataformas tem suas próprias desvantagens.
Alguns aspectos precisam ser considerados com cuidado ao usar ferramentas de ETL de terceiros, como custo e flexibilidade. Embora sejam abordagens definitivamente simplificadas para a ingestão de dados no Snowflake, pode haver algumas restrições que acabarão tornando seu uso mais desafiador.
Sabendo dessas restrições, ao decidir sobre a ferramenta certa, você deve considerar:
Embora projetar um pipeline seja um trabalho árduo, há alguns conceitos gerais e práticas recomendadas que você pode seguir para facilitar a sua vida. Eles têm como objetivo melhorar a eficiência e minimizar os custos.
Minimize o tamanho dos seus arquivos para reduzir o custo de armazenamento de dados usando formatos de arquivo como gzip ou Parquet. Além disso, quando os dados são transferidos, geralmente é melhor favorecer menos arquivos maiores em vez de muitos arquivos menores para o processo de cópia. Arquivos grandes individuais têm menos sobrecarga de rede do que tentar transferir vários arquivos menores. Por fim, programe grandes trabalhos em lote fora do horário de pico se os custos de computação e de rede forem uma preocupação.
Por fim, certifique-se de lidar com a evolução do esquema em seus pipelines. Alguns tipos de dados, como o Parquet, permitem naturalmente a evolução do esquema. Isso significa que, embora o esquema de dados possa ser alterado em relação à fonte de dados, isso não afeta os dados históricos e mantém a compatibilidade entre os dados para frente e para trás.
Outro aspecto a ser considerado durante o pipeline de ingestão de dados é garantir a qualidade e a observabilidade dos dados. Uma maneira inteligente de fazer isso é preparar os dados antes de integrá-los ao armazenamento final do banco de dados. Você pode querer verificar hashes e metadados para garantir a precisão dos dados e a ausência de corrupção. Além disso, em vez de permitir que os usuários tenham acesso direto aos próprios dados, a criação de exibições que combinem fontes de dados diferentes pode proporcionar uma melhor experiência ao usuário.
Por fim, você deseja monitorar e registrar constantemente a integridade do seu pipeline de dados. Configure painéis usando as visualizações de metadados do Snowflake ou ferramentas externas de observabilidade, como DataDog ou Monte Carlo, para que você acompanhe o sucesso da ingestão, a latência e as falhas.
Aqui, abordaremos alguns exemplos de alto nível de como você pode criar pipelines no Snowflake. Observe que as etapas exatas podem ser diferentes, dependendo de como o administrador de dados configurou o ambiente Snowflake. Certifique-se de seguir as práticas recomendadas de sua organização!
Primeiro, alguns pré-requisitos. Você precisará de uma conta Snowflake que lhe permita gerenciar o banco de dados. Algumas permissões de acesso comuns de que você precisará são a capacidade de criar esquemas. Em segundo lugar, você deve se certificar de que o servidor em que você está tem acesso ao bucket de armazenamento em nuvem externo ou ao armazenamento interno onde você está armazenando os dados. Fale com o administrador do banco de dados sobre isso.
COPY INTOVamos ver um exemplo simples de como carregar um arquivo CSV no banco de dados do Snowflake.
1. Prepare e faça upload dos dados Formate seus arquivos (por exemplo, CSV) e faça o upload deles para o seu bucket de armazenamento em nuvem.
2. Criar estágio e formato de arquivo
/* specify the file format */CREATE FILE FORMAT my_csv_format TYPE = 'CSV'
/* this will help if there are double quotes or apostrophes in your data */
FIELD_OPTIONALLY_ENCLOSED_BY='"';
/* Stage the data using the credentials you have */
CREATE STAGE my_stage URL='s3://my-bucket/data/' CREDENTIALS=(AWS_KEY_ID='...' AWS_SECRET_KEY='...');3. Execute COPY INTO e verifique
COPY INTO my_table FROM @my_stage FILE_FORMAT = (FORMAT_NAME = 'my_csv_format');SELECT * FROM my_table;Criar uma ingestão automatizada usando o Snowpipe pode ser muito simples!
1. Criar tubo de neve
CREATE PIPE my_pipe
AUTO_INGEST = TRUE
AWS_SNS_TOPIC = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket'
AS
COPY INTO my_table
FROM @my_stage
FILE_FORMAT = (TYPE = ‘CSV’);2. Configurar eventos de armazenamento em nuvem Configure a notificação do bucket S3 para acionar o pipe usando SNS/SQS. Para obter mais detalhes, eu seguiria este guia sobre AWS SNS da Datacamp.
3. Monitorar a ingestão
Certifique-se de que você consulte a tabela de metadados SNOWPIPE_EXECUTION_HISTORY para visualizar a atividade do pipe.
A configuração do Snowpipe Streaming pode ser bastante intensa e é um pouco mais detalhada do que podemos abordar aqui. Abordarei algumas das etapas fundamentais, mas recomendo principalmente que você leia os exemplos da documentação do Snowflake Streaming para você saber como criar o SDK do cliente.
profile.json. As propriedades necessárias envolvem credenciais de autorização, URL para o Snowflake e o usuário. Isso permite que o SDK se conecte ao seu servidor Snowflake. Escreva o restante do script Java para lidar com a chegada dos dados, incluindo o método insertRows.O Snowflake oferece um conjunto robusto e flexível de métodos de ingestão de dados, desde cargas tradicionais em lote até streaming em tempo real. Ao compreender as ferramentas e técnicas disponíveis, as equipes de dados podem projetar pipelines que sejam confiáveis, eficientes e econômicos. Não importa se você está apenas começando ou otimizando uma solução em escala empresarial, dominar a ingestão de dados do Snowflake é uma etapa crítica na criação de uma pilha de dados moderna. Se você quiser saber mais sobre o Snowflake, recomendo os seguintes recursos:
Os melhores cursos de Snowflake
Programa
Curso
Curso
blog
Nisha Arya Ahmed
15 min
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Zoumana Keita
Tutorial
Vidhi Chugh