Lernpfad
Snowflake Stiftungen
7 Std.
Snowflake ist eine Cloud-native Datenplattform, die aufgrund ihrer Skalierbarkeit, Leistung und Einfachheit von vielen Datenexperten genutzt wird und sich für alle Bereiche von der Analyse bis zur Datenwissenschaft eignet. Um das Tool optimal nutzen zu können, musst du jedoch die Snowflake-Dateneingabe beherrschen. Wenn du neu auf der Plattform bist, empfehle ich dir, mit diesem Snowflake Tutorial für Einsteiger um dich mit der Architektur der Plattform vertraut zu machen.
Effiziente und richtig entwickelte Dateneingabe-Pipelines sind entscheidend dafür, dass die Daten für nachgelagerte Anwendungsfälle verfügbar und zuverlässig sind. Egal, ob es sich um regelmäßige Batch-Updates oder Echtzeit-Datenströme handelt, die Wahl der richtigen Ingestion-Methode und -Tools wirkt sich direkt auf die Leistung und Wartbarkeit deiner Datenpipeline aus.
Bevor du ins Detail gehst, ist es wichtig, einige wichtige Konzepte zum Datenfluss zu verstehen:
Die Datenaufnahme bezieht sich auf den Prozess der Übertragung von Daten aus verschiedenen Quellen in eine Datenbank zur Speicherung, Verarbeitung und Analyse. Ganz gleich, ob deine Daten aus Cloud-Speichern, Datenbanken, Anwendungen oder Ereignisströmen stammen, die Datenaufnahme ist der erste Schritt im Lebenszyklus der Daten in Snowflake.
Die einzigartige Architektur von Snowflake trennt Rechenleistung und Speicher. Dies ermöglicht einen vereinfachten Prozess der Datenaufnahme, ohne die Analyseleistung zu beeinträchtigen. Der Ingest kann je nach Datenquelle und Anwendungsfall entweder auf interne Stufen (innerhalb von Snowflake) oder auf externe Stufen (wie S3 oder Azure Blob Storage) ausgerichtet sein. Für weitere Einblicke bietet dieser Artikel einen tiefen Einblick in die Snowflake Architektur.
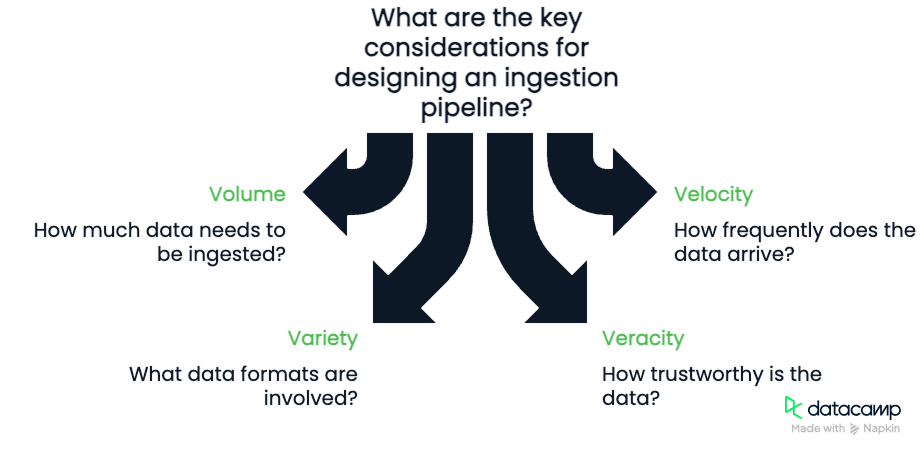
Wenn du eine Ingestion-Pipeline entwirfst, beachte die Vier Vs der Daten:
Diese vier Komponenten sind wichtig zu beachten. Volumen und Geschwindigkeit erfordern, dass wir die Bandbreite, die unserer Pipeline zur Verfügung steht, und ihre Fähigkeit, Daten zu verarbeiten, berücksichtigen. Um Vielfalt und Wahrhaftigkeit zu gewährleisten, müssen wir robuste und flexible Pipelines entwickeln, die in der Lage sind, die Qualität der Daten zu prüfen, während sie fließen.
Im Folgenden werden einige der in Snowflake zur Verfügung stehenden Methoden zur Datenaufnahme erläutert. Bei einigen Methoden wird ein Befehl wie COPY INTO, Snowpipe oder Snowpipe Streaming verwendet.
Die grundlegendste Ingestion-Methode von Snowflake ist der Befehl COPY INTO. COPY INTO lädt Daten aus Dateien, die in externen Stages gespeichert sind, in Snowflake-Tabellen. Es ist ideal, um historische Daten in großen Mengen zu laden oder regelmäßige Batch-Updates durchzuführen.
Du kannst Daten von Amazon S3, Azure Blob Storage oder Google Cloud Storage laden, indem du eine externe Stufe erstellst, die diese Cloud-Dienste mit Snowflake verbindet. Mit dem richtigen Dateipfad und den richtigen Anmeldedaten liest und verarbeitet Snowflake die Dateien effizient.
COPY INTO unterstützt mehrere Formate: CSV, JSON, Avro, ORC und Parquet. Bei der Erstellung des Konnektors gibt es verschiedene Optionen für das Format. Die Liste ist ziemlich umfangreich, aber oft gibt es Einstellungen für Dinge wie das Format von Datumsangaben, Trennzeichen (Kommas oder andere Werte), Kodierung, Null-Optionen und so weiter. Ich empfehle dir, die Dokumentation auf der Snowflake-Website zu lesen, um alle Einzelheiten zu erfahren.
Du kannst die Einstellung ON_ERROR so konfigurieren, dass problematische Zeilen übersprungen, der Ladevorgang abgebrochen oder Fehler protokolliert werden. Kombiniere dies mit dem VALIDATION_MODE, um Fehler zu verfolgen und zurückzugeben. Du kannst Metadaten-Tabellen wie LOAD_HISTORY verwenden, die auch die Anzahl der Fehler erfassen, die während eines Ladevorgangs auftreten.
Snowpipe ermöglicht eine kontinuierliche Einspeisung, indem neue Dateien automatisch erkannt und geladen werden, sobald sie in einem bestimmten Stadium erscheinen. Diese Funktion ist in die Snowflake-Plattform integriert. Es bietet automatische Dateiintegration, ereignisbasierte Auslöser und Überwachung.
Snowpipe kann so konfiguriert werden, dass Dateien durch die Integration von Cloud-Speicher-Benachrichtigungen automatisch getestet werden, wodurch die Notwendigkeit einer manuellen Ausführung reduziert wird. Bei Amazon S3 gibt es zum Beispiel Ereignisbenachrichtigungen, die Nutzer über Änderungen an einem bestimmten Bucket informieren.
Snowpipe kann mit einem Nutzer verbunden werden, der diese Benachrichtigungen sieht. Wenn dieser Nutzer eine Ereignisbenachrichtigung erhält, wird Snowpipe ausgelöst, um den Prozess der Datenaufnahme zu starten.
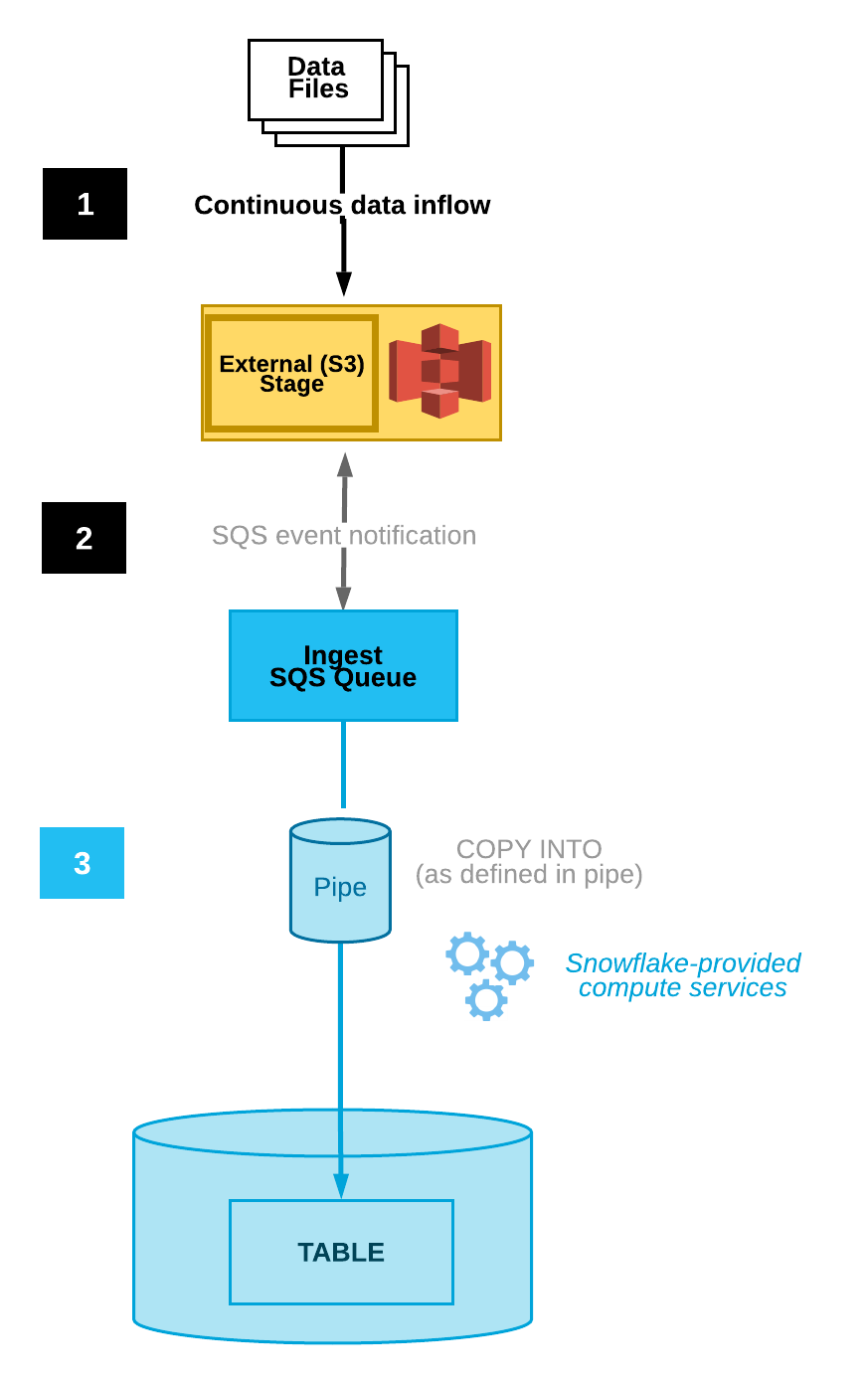
Diagramm der automatischen Dateneingabe(Snowflake Dokumentation)
Snowflake bietet verschiedene Überwachungs- und Fehlermanagement-Tools. Die Tabelle mit den Metadaten PIPE_USAGE_HISTORYermöglicht es den Nutzern, den Verlauf der Datenlast, wie z. B. die Anzahl der Bytes und Dateien, die aufgenommen wurden, einzusehen. Die Tabelle VALIDATE_PIPE_LOAD gibt Auskunft über aufgetretene Fehler.
In Snowpipe gibt es die Einstellung ON_ERROR, die es uns ermöglicht, Dateien zu überspringen und Benachrichtigungen zu senden, die uns auf Fehler aufmerksam machen.
Snowpipe Streaming ist die neueste Methode von Snowflake, um Streaming-Daten in Echtzeit mit einer Latenzzeit von weniger als einer Sekunde aufzunehmen. Anders als Snowpipe, das auf Dateien reagiert, nimmt Snowpipe Streaming die Daten zeilenweise über eine API auf. Diese Methoden ergänzen sich gegenseitig und bieten Flexibilität und Effizienz.
Mit dem Snowflake Ingest SDK können Entwickler Java- oder Scala-Anwendungen schreiben, die Daten über eine speicherresidente Warteschlange direkt in Snowflake übertragen. Diese Anwendungen sind darauf ausgelegt, Daten auf Zeilenebene von Orten wie Apache Kafka-Themen und anderen Streaming-Konnektoren zu empfangen.
Snowpipe Streaming eignet sich perfekt für Telemetrie-, Clickstream- oder IoT-Daten und stellt sicher, dass die Daten nahezu in Echtzeit verfügbar sind - bei minimalem Speicheraufwand und hohem Durchsatz. Diese Ingestion-Methode ist perfekt, wenn du Daten mit hoher Geschwindigkeit und nahezu in Echtzeit benötigst.
Wenn du mit Snowpipe und Snowpipe Streaming Daten in Snowflake einspeisen willst, brauchst du einige Tools, um Datenpipelines richtig zu verbinden. Ein wichtiges Tool ist Kafka, das häufig für die Kommunikation zwischen Datenquellen und Snowflake verwendet wird. Alternativ dazu gibt es einige Tools von Drittanbietern wie Fivetran und Matillion, die ebenfalls ETL nach Snowflake durchführen können.
Snowflake bietet einen Kafka-Konnektor, der Nachrichten aus Kafka-Themen liest und direkt in den Snowflake-Speicher schreibt. Die Daten werden in Kafka veröffentlicht, und mit Snowpipe oder Snowpipe Streaming kann Snowflake diese veröffentlichten Daten aufgreifen und in den internen Speicher übertragen. Dies ist eine äußerst flexible Art der Datenübertragung. Ich empfehle diesen Kurs Einführung in Apache Kafka, der die Leistungsfähigkeit und Skalierbarkeit von Kafka behandelt.
Um die Integration richtig einzurichten, musst du einen Kafka Connect Worker konfigurieren und Parameter wie Topic-Namen, Puffergrößen und Snowflake-Anmeldeinformationen festlegen.
Mit diesen Konfigurationen können wir auch die Datentypen und Metadateninformationen festlegen, die wir verfolgen möchten. Die beiden wichtigsten Möglichkeiten, diese Verbindungen zu definieren, sind entweder über Confluent (eine von einem Drittanbieter verwaltete Version von Apache Kafka) oder manuell mit dem Open-Source Apache Kafka JDK.
Egal, wofür du dich entscheidest, halte dich an die folgenden Best Practices:
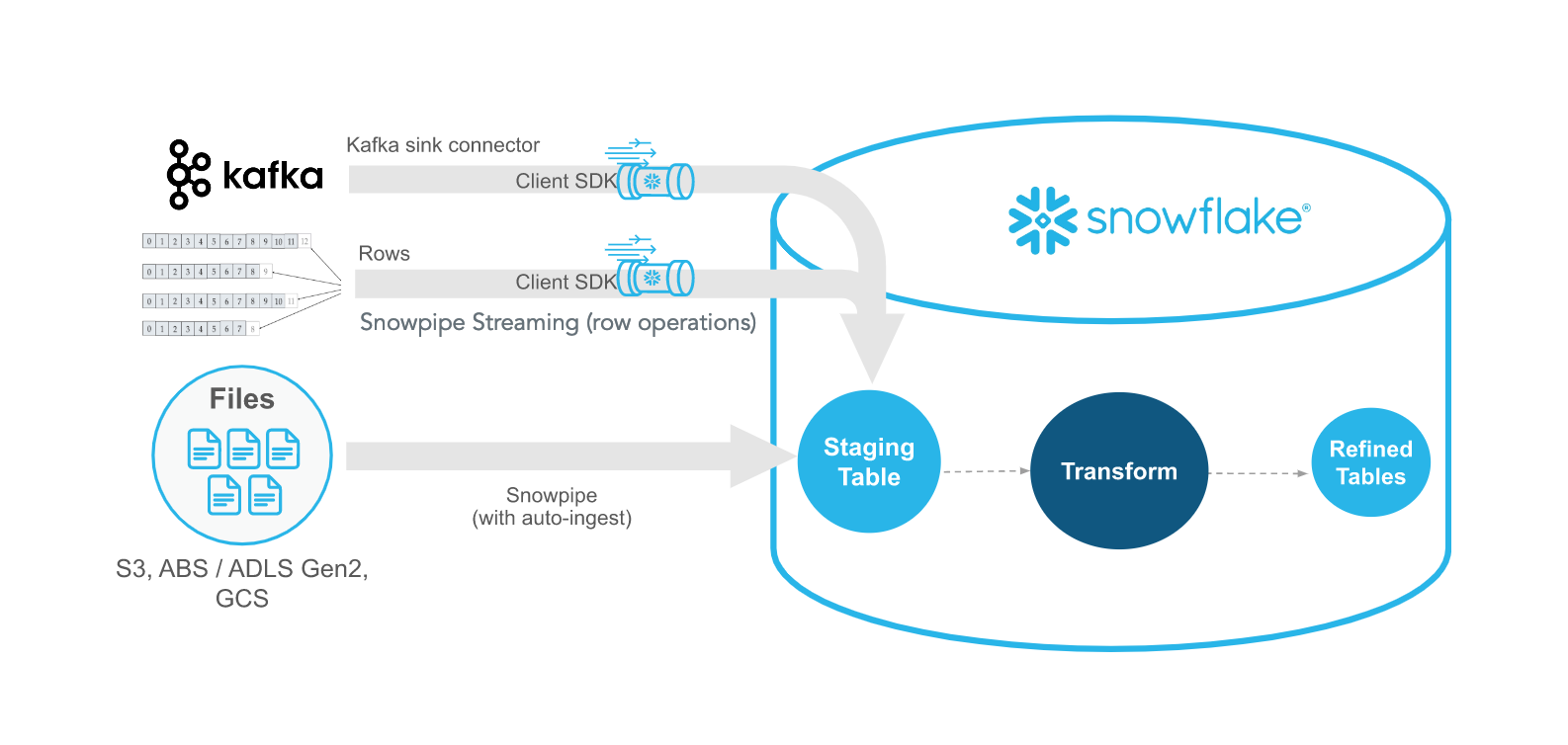
Beispiel für die Verwendung von Kafka mit Snowflake SDK für Streaming-Daten(Snowflake-Dokumentation)
Zusätzlich zu Kafka gibt es ETL-Plattformen von Drittanbietern wie Fivetran, Matillion und Talend, die verwaltete ETL/ELT-Lösungen für die Aufnahme und Umwandlung von Daten aus Hunderten von Quellen in Snowflake anbieten. Diese Plattformen von Drittanbietern bieten oft Low-Code- und vereinfachte SaaS-Lösungen für das Datenmanagement, aber die Wahl dieser Plattformen hat auch ihre Nachteile.
Bei der Verwendung von ETL-Tools von Drittanbietern müssen einige Aspekte sorgfältig bedacht werden, z. B. die Kosten und die Flexibilität. Auch wenn es sich hierbei definitiv um vereinfachte Ansätze für das Ingesting von Daten in Snowflake handelt, kann es einige Einschränkungen geben, die ihre Nutzung letztendlich erschweren.
Wenn du diese Einschränkungen kennst, solltest du bei der Entscheidung für das richtige Werkzeug berücksichtigen:
Die Entwicklung einer Pipeline ist zwar harte Arbeit, aber es gibt einige allgemeine Konzepte und Best Practices, die du befolgen kannst, um dir das Leben zu erleichtern. Diese zielen darauf ab, die Effizienz zu verbessern und die Kosten zu minimieren.
Minimiere die Größe deiner Dateien, um die Kosten für die Datenspeicherung zu senken, indem du Dateiformate wie gzip oder Parquet verwendest. Außerdem ist es bei der Übertragung der Daten oft besser, weniger, größere Dateien statt vieler kleinerer für deinen Kopiervorgang zu verwenden. Einzelne große Dateien haben einen geringeren Netzwerk-Overhead als der Versuch, mehrere kleinere Dateien zu übertragen. Schließlich solltest du große Batch-Aufträge außerhalb der Hauptverkehrszeiten planen, wenn du dir Sorgen um die Rechen- und Netzwerkkosten machst.
Schließlich solltest du sicherstellen, dass du die Schemaentwicklung in deinen Pipelines berücksichtigen kannst. Einige Datentypen, wie z.B. Parquet, ermöglichen natürlich eine Schemaentwicklung. Das bedeutet, dass sich das Datenschema der Datenquelle zwar ändern kann, dies aber keine Auswirkungen auf die historischen Daten hat und die Vorwärts- und Rückwärtskompatibilität der Daten erhalten bleibt.
Ein weiterer Punkt, den du bei der Dateneingabe beachten musst, ist die Sicherstellung der Datenqualität und der Beobachtbarkeit. Eine clevere Methode, dies zu tun, ist das Staging der Daten, bevor du sie in deinen endgültigen Datenbestand integrierst. Du kannst Hashes und Metadaten überprüfen, um sicherzustellen, dass die Daten korrekt und nicht beschädigt sind. Anstatt den Nutzern einen direkten Zugang zu den Daten selbst zu ermöglichen, können auch Ansichten erstellt werden, die verschiedene Datenquellen miteinander kombinieren.
Schließlich solltest du den Zustand deiner Datenpipeline ständig überwachen und protokollieren. Richte Dashboards mit den Metadatenansichten von Snowflake oder externen Beobachtungstools wie DataDog oder Monte Carlo ein, um den Erfolg, die Latenz und die Ausfälle von Ingestions zu verfolgen.
In diesem Abschnitt werden wir einige Beispiele dafür vorstellen, wie du in Snowflake Pipelines aufbauen kannst. Je nachdem, wie dein Datenadministrator deine Snowflake-Umgebung konfiguriert hat, können die genauen Schritte anders aussehen. Achte darauf, dass du die Best Practices deiner Organisation befolgst!
Zunächst einige Voraussetzungen. Du brauchst ein Snowflake-Konto, mit dem du die Datenbank verwalten kannst. Zu den üblichen Zugriffsrechten, die du brauchst, gehört die Möglichkeit, Schemata zu erstellen. Zweitens musst du sicherstellen, dass der Server, auf dem du dich befindest, Zugriff auf den externen Cloud-Speicher-Bucket oder den internen Speicher hat, in dem du die Daten speicherst. Sprich mit deinem Datenbankadministrator über diese.
COPY INTOSehen wir uns ein einfaches Beispiel für das Laden einer CSV-Datei in deine Snowflake-Datenbank an.
1. Daten vorbereiten und hochladen Formatiere deine Dateien (z. B. CSV) und lade sie in deinen Cloud-Speicher hoch.
2. Bühne und Dateiformat erstellen
/* specify the file format */CREATE FILE FORMAT my_csv_format TYPE = 'CSV'
/* this will help if there are double quotes or apostrophes in your data */
FIELD_OPTIONALLY_ENCLOSED_BY='"';
/* Stage the data using the credentials you have */
CREATE STAGE my_stage URL='s3://my-bucket/data/' CREDENTIALS=(AWS_KEY_ID='...' AWS_SECRET_KEY='...');3. COPY INTO ausführen und verifizieren
COPY INTO my_table FROM @my_stage FILE_FORMAT = (FORMAT_NAME = 'my_csv_format');SELECT * FROM my_table;Die Erstellung eines automatisierten Ingests mit Snowpipe kann ziemlich einfach sein!
1. Snowpipe erstellen
CREATE PIPE my_pipe
AUTO_INGEST = TRUE
AWS_SNS_TOPIC = 'arn:aws:sns:us-west-2:001234567890:s3_mybucket'
AS
COPY INTO my_table
FROM @my_stage
FILE_FORMAT = (TYPE = ‘CSV’);2. Konfiguriere Cloud-Speicher-Ereignisse Richte eine S3-Bucket-Benachrichtigung ein, um die Pipe über SNS/SQS auszulösen. Für weitere Details würde ich diesen Leitfaden befolgen AWS SNS von Datacamp.
3. Verschlucken überwachen
Stelle sicher, dass du die Tabelle mit den Metadaten SNOWPIPE_EXECUTION_HISTORY abfragst, um die Rohrleitungsaktivitäten zu sehen.
Die Einrichtung von Snowpipe Streaming kann ziemlich intensiv sein und ist etwas ausführlicher, als wir hier behandeln können. Ich werde einige der grundlegenden Schritte behandeln, aber ich empfehle vor allem, die Beispiele aus der Snowflake Streaming Dokumentation zu lesen, wie man das Client-SDK erstellt.
profile.json Datei. Zu den erforderlichen Eigenschaften gehören die Berechtigungsnachweise, die URL für Snowflake und der Benutzer. So kann sich das SDK mit deinem Snowflake-Server verbinden. Schreibe den Rest deines Java-Skripts, um die kommenden Daten zu verarbeiten, einschließlich der Methode insertRows.Snowflake bietet eine robuste und flexible Palette von Dateneingabemethoden - von traditionellen Batch-Loads bis hin zu Echtzeit-Streaming. Wenn du die verfügbaren Tools und Techniken kennst, können Datenteams Pipelines entwerfen, die zuverlässig, leistungsfähig und kosteneffizient sind. Egal, ob du gerade erst anfängst oder eine unternehmensweite Lösung optimierst, die Beherrschung der Snowflake Datenaufnahme ist ein wichtiger Schritt beim Aufbau eines modernen Datenstacks. Wenn du mehr über Snowflake erfahren möchtest, empfehle ich dir die folgenden Ressourcen:
Top Snowflake Kurse
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
