
programa
Fundaciones de Snowflake
7 h
Snowflake es una popular y potente plataforma de datos basada en la nube, y Streamlit es un marco de trabajo de código abierto en Python diseñado para crear aplicaciones web de datos. Streamlit in Snowflake (SiS) es una solución integrada que te permite crear e implementar aplicaciones de datos directamente en el ecosistema de Snowflake. En lugar de hacer malabarismos con herramientas independientes, puedes utilizar Python y la infraestructura de Snowflake para crear aplicaciones interactivas rápidamente.
Este tutorial te guiará a través de lo que es Streamlit en Snowflake, sus características clave, los pasos de configuración, las estrategias de implementación, la seguridad, los consejos de rendimiento y los casos de uso en el mundo real. Al final, tendrás una hoja de ruta clara para crear y lanzar tu primera aplicación de datos. Asegúrate de revisar los fundamentos de Snowflake y su interfaz. También recomiendo probar Streamlit en Python fuera de Snowflake para comprender mejor su funcionalidad con este tutorial de Streamlit.
Streamlit en Snowflake permite crear aplicaciones interactivas conectadas directamente a tus datos de Snowflake sin salir de la plataforma.
Streamlit en Snowflake combina la simplicidad de Streamlit con la escalabilidad de Snowflake. Tradicionalmente, la creación de aplicaciones requería servidores externos, API e integraciones complejas. Streamlit reduce la funcionalidad principal a unas pocas API orientadas a objetos e integraciones de Python. A continuación, la implementación se descarga en Snowflake mediante Snowsight.
Esto elimina la necesidad de infraestructura adicional y proporciona un entorno unificado que se integra perfectamente con Snowpark, Cortex AI y tus datos de Snowflake. Esto significa que los programadores de Python y los equipos de datos trabajan a partir de la misma fuente sin tener que soportar la carga adicional que supone la transferencia de datos o código.
En 2022, Snowflake adquirió Streamlit para acercar el desarrollo de aplicaciones interactivas a los datos empresariales. Mantiene la visión de código abierto de Streamlit de proporcionar a los programadores la capacidad de utilizar Python para crear hermosas aplicaciones web, al tiempo que se integra con una de las plataformas de datos más potentes disponibles en la actualidad. Permite a las empresas utilizar Streamlit de forma flexible con menos preocupaciones en materia de seguridad y unifica el desarrollo de aplicaciones.
La filosofía de SiS se centra en mantener el mismo nivel de seguridad y gobernanza que esperarías de Snowflake, al tiempo que ofrece la facilidad de uso de Streamlit para crear aplicaciones web de datos. Dado que todos los datos permanecen en Snowflake, tienes las mismas garantías de seguridad y protección que cabría esperar.
La principal ventaja es que se centra en garantizar que el marco de Python siga siendo el mismo y ofrezca una experiencia similar en Snowflake a la que obtendrías fuera de Snowflake. Esto debería hacer que SiS resulte accesible para los programadores que hayan trabajado con Streamlit en el pasado o incluso para aquellos que tengan experiencia en Python y deseen aprovechar sus conocimientos actuales para crear aplicaciones web para los datos de Snowflake.
Streamlit en Snowflake conserva las características clave de Snowflake en la nube, como la gestión completa y la fácil colaboración. También cuenta con la funcionalidad de visualización e iteración rápida de Streamlit, al tiempo que se integra con la infraestructura.
Snowflake gestiona toda la infraestructura entre bastidores, lo que significa que nunca tendrás que preocuparte por los servidores, el escalado o la estabilidad. Las aplicaciones se ejecutan con interactividad en tiempo real, se escalan automáticamente en función del uso y se benefician de la fiabilidad integrada de Snowflake.
Las aplicaciones Streamlit dentro de Snowflake se conectan de forma nativa con Snowpark, Cortex AI y bases de datos. Por ejemplo, puedes integrar Cortex AI Analyst en tu aplicación Streamlit, lo que permite a los usuarios formular preguntas en lenguaje natural sobre los datos y obtener respuestas de forma nativa en el panel de control.
Otras características de Snowflake, como el almacenamiento en caché integrado, minimizan las consultas redundantes, mientras que las mejoras en la interfaz de usuario, como el modo oscuro y los componentes personalizados, mejoran la experiencia de los usuarios. La autenticación y las conexiones seguras se gestionan automáticamente a través de los protocolos de autenticación de Snowflake. La sensibilidad de los datos se puede gestionar mediante los controles basados en roles de Snowflake.
Esto simplifica la tarea de gestión de datos y permite a los programadores centrarse en la creación de herramientas.
Una de las mayores ventajas de Streamlit es la capacidad de transformar un simple script de Python en una aplicación interactiva en cuestión de minutos. En Snowflake, puedes obtener una vista previa y repetir las aplicaciones directamente, actualizando el código y viendo los resultados en tiempo real sin tener que esperar largas implementaciones.
Las aplicaciones Streamlit se pueden compartir directamente con los usuarios dentro de Snowflake. Esto facilita compartir la aplicación con diferentes equipos utilizando roles o miembros individuales. La colaboración está integrada en el flujo de trabajo, lo que permite que varios miembros del equipo trabajen, prueben e implementen aplicaciones juntos.
Empezar a utilizar SiS es muy sencillo, y puedes crear tu primera aplicación en cuestión de minutos. Solo tenemos que asegurarnos de que tienes los permisos y los conocimientos adecuados.
Para crear una aplicación Streamlit en Snowflake, necesitas una cuenta activa de Snowflake con acceso a Snowsight, la interfaz web. Esta introducción a Snowflake te muestra cómo navegar por Snowsight. Debes tener conocimientos básicos de Python. Incluso podría valer la pena repasar esta curso de introducción a Python para refrescar tus conocimientos.
Una vez que tengas acceso a Snowflake, asegúrate de que dispones de los siguientes permisos:
USAGEUSAGE, CREATE STREAMLIT, CREATE STAGEComienza iniciando sesión en Snowsight y seleccionando o creando una base de datos y un esquema donde se alojará tu aplicación. Comienza por ir a My Workspace y abrir un nuevo archivo SQL. Creemos un rol llamado « streamlit_creator » que tendrá acceso a tu « streamlit_schema » en tu « streamlit_database ». Además, crearemos un almacén llamado « streamlit_wh », que será la fuente de cálculo principal para nuestra aplicación Streamlit.
CREATE ROLE streamlit_creator;
CREATE DATABASE streamlit_db;
USE DATABASE streamlit_db;
CREATE SCHEMA streamlit_schema;
CREATE WAREHOUSE streamlit_wh WITH WAREHOUSE_SIZE = ‘XSMALL’;
GRANT USAGE ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;
GRANT USAGE ON DATABASE streamlit_db TO ROLE streamlit_creator;
GRANT USAGE ON WAREHOUSE streamlit_wh TO ROLE streamlit_creator;
GRANT CREATE STREAMLIT ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;
GRANT CREATE STAGE ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;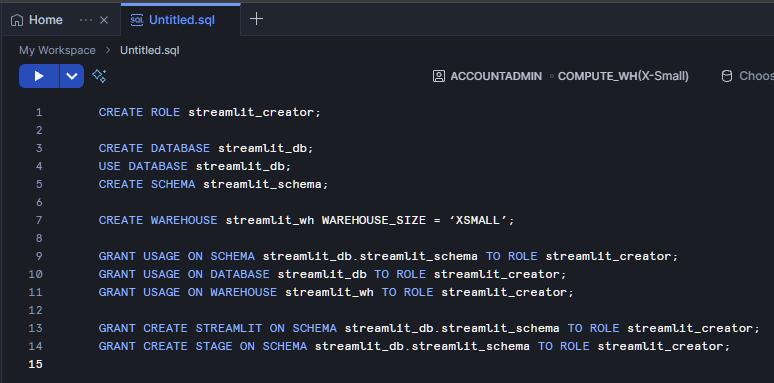
Para concretar esto, veamos una aplicación sencilla. Una vez que hayas configurado tu cuenta y permisos de Snowflake, en Snowsight, ve a « PROJECTS » (Configuración de la cuenta) >> « Streamlit » (Permisos de Snowflake). En esta ventana, haz clic en « + Streamlit App » (Añadir un nuevo elemento) en la parte superior derecha.
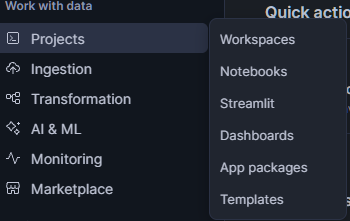
Escribe el nombre que quieras para la aplicación. Actualiza la ubicación de la aplicación para utilizar STREAMLIT_DB y STREAMLIT_SCHEMA. A continuación, selecciona «Run on warehouse» (Ejecutar en el almacén) y, a continuación, selecciona «STREAMLIT_WH» como « App Warehouse » (Ubicación de ejecución).
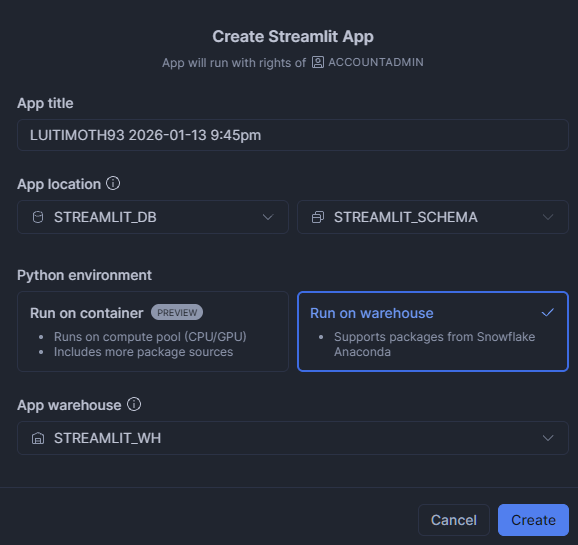
Esto abre el editor. Viene con un pequeño script por defecto. También ejecutará automáticamente la aplicación y te mostrará una vista previa.
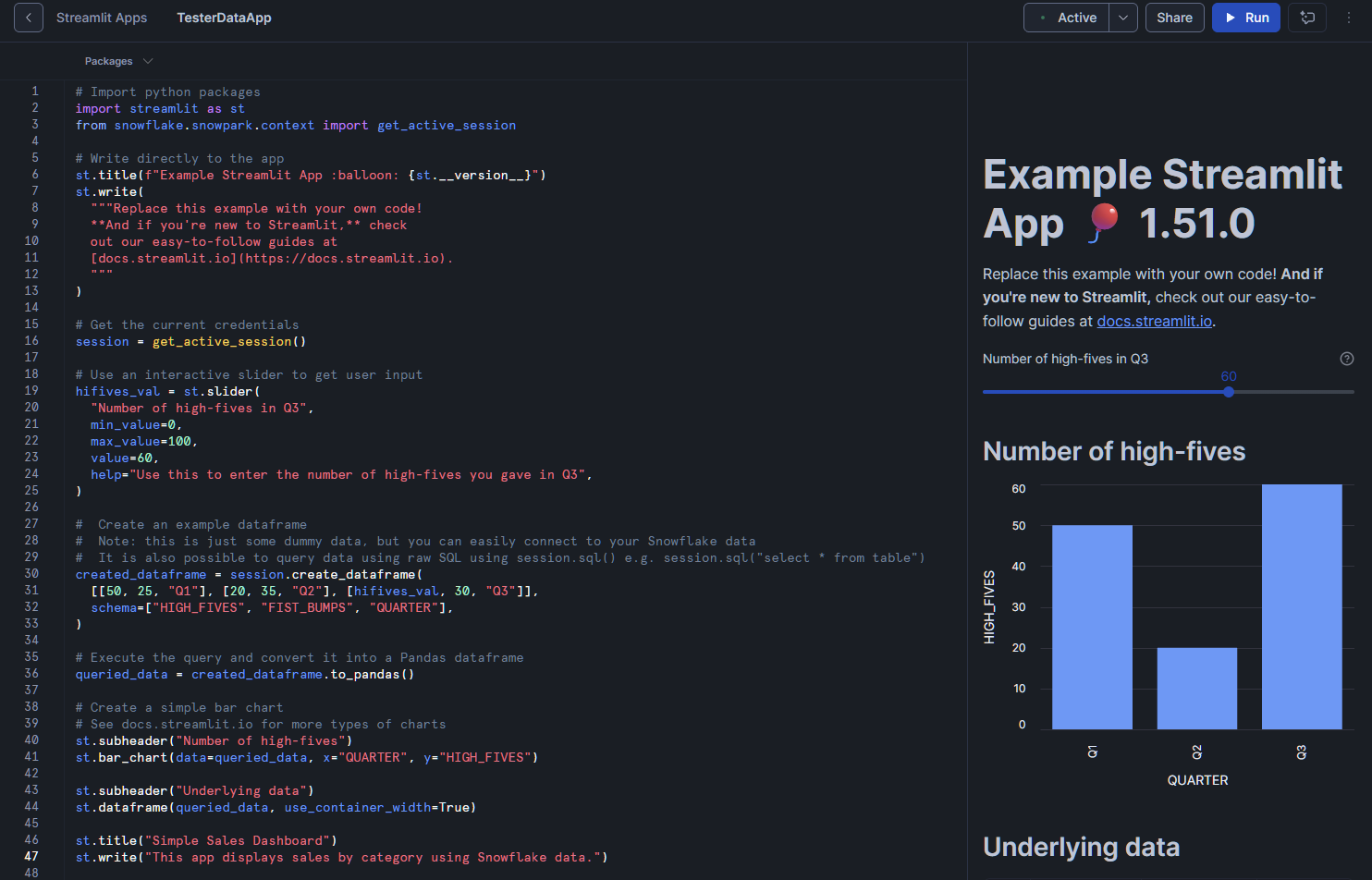
Intentemos añadir un poco de nuestros propios datos de interés a la aplicación. Pongamos este pequeño fragmento al final de nuestro código actual:
from snowflake.snowpark.functions import sum as sf_sum
st.title("Simple Sales Dashboard")
st.write("This app displays sales by part using Snowflake data.")
# Query sample dataset
df = (
session.table("SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM")
.group_by("L_PARTKEY")
.agg(sf_sum("L_QUANTITY").alias("TOTAL_SALES"))
.limit(10)
.order_by("TOTAL_SALES", ascending=False)
.to_pandas()
)
# Plot chart
st.bar_chart(data=df, x="L_PARTKEY", y="TOTAL_SALES")
# Show table
st.dataframe(df)
A continuación, pulsa el botón «Ejecutar» situado en la parte superior derecha. La vista previa de esta aplicación actualizará y procesará los datos proporcionados por la tabla de muestra. Debe mostrar tanto una tabla de datos como un gráfico de barras. Desde aquí, puedes personalizar las consultas, añadir filtros o mejorar la interfaz de usuario con los widgets de Streamlit.
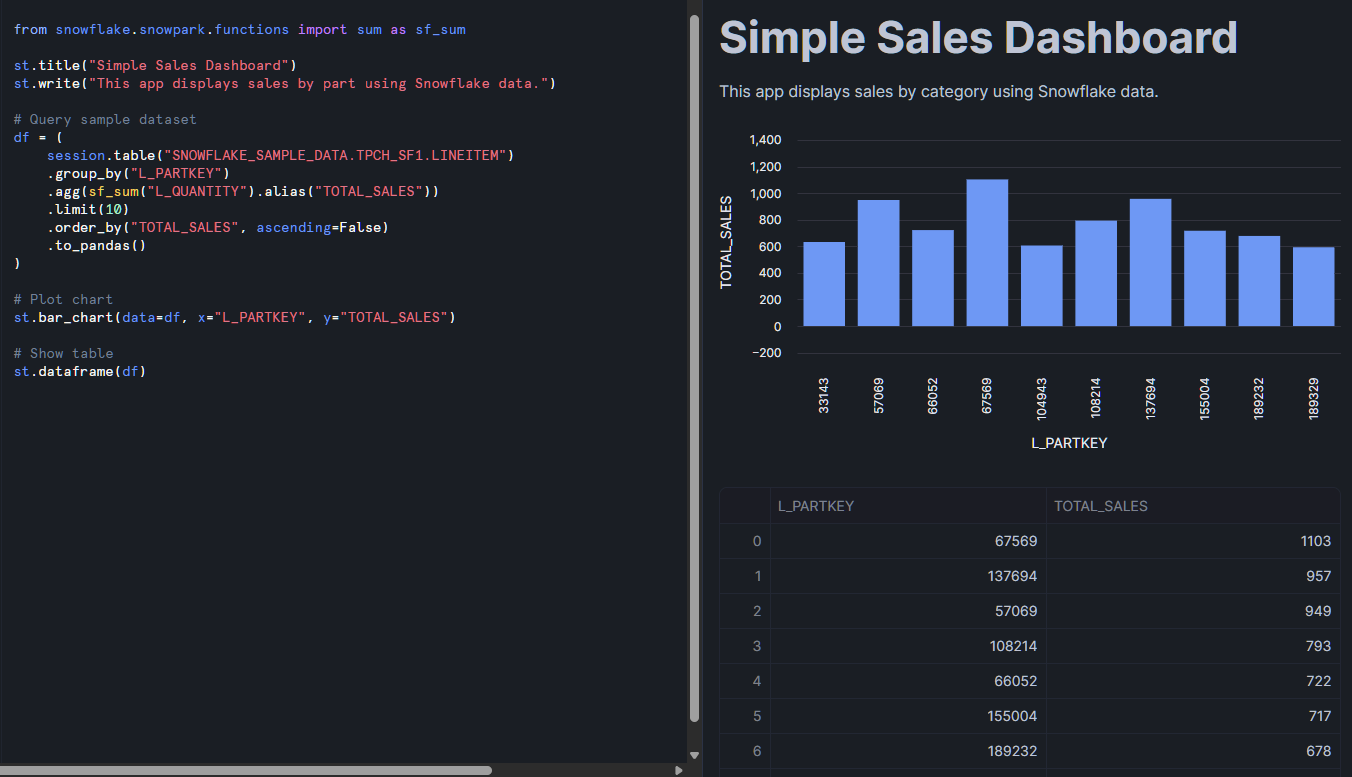
Lo que notarás aquí es el uso de Snowpark. Si aún no lo has utilizado, Snowpark es la biblioteca de Snowflake que te permite procesar datos de Snowflake utilizando lenguajes de programación como Python. Recomiendo encarecidamente esta introducción a Snowpark, ya que para importar datos a Streamlit a menudo es necesario utilizar Snowpark como interfaz con las bases de datos de Snowflake.
Hay varias formas de implementar Streamlit en Snowflake. Lo más fácil es utilizar Snowsight, la interfaz web, pero también puedes utilizar herramientas de interfaz de línea de comandos (CLI). Además, puedes añadir herramientas de flujo de trabajo para ayudar con la organización del proyecto y escalar tu implementación.
Como se ha mostrado en la sección anterior, el método más sencillo es a través de Snowsight, la interfaz web de Snowflake. La ventaja adicional aquí es la vista de pantalla dividida para editar y previsualizar tu aplicación en tiempo real. Esta configuración es ideal para programadores que desean obtener comentarios inmediatos mientras desarrollan.
Para escenarios más avanzados, las herramientas CLI te permiten implementar aplicaciones mediante programación. Esto resulta especialmente útil cuando se integra la implementación de aplicaciones en procesos de integración continua y entrega continua (CI/CD). Siguiendo un enfoque de programación más estructurado, las aplicaciones se pueden almacenar en carpetas de proyecto como archivos .py, al igual que las aplicaciones Streamlit normales, junto con archivos .yml que controlan cualquier entorno y comandos Snowflake. Esto significa que podemos usar GitHub para realizar un seguimiento de los cambios, ejecutar comprobaciones automatizadas e implementar sin problemas.
Otra opción es combinar las aplicaciones Streamlit con herramientas de flujo de trabajo como dbt (herramienta de creación de datos), que Snowflake admite de forma nativa. Por ejemplo, dbt puede gestionar tu flujo de trabajo ETL principal que se integra en tu aplicación Streamlit. Dentro del mismo proyecto dbt, puedes volver a implementar Streamlit automáticamente según sea necesario para adaptarlo a tu flujo de trabajo dbt. Esto te permite organizar flujos de trabajo de datos complejos de forma ordenada en proyectos y ampliar tu implementación junto con tu flujo de trabajo.
Hablemos de cómo funciona realmente Streamlit en Snowflake.
Las aplicaciones Streamlit en Snowflake se ejecutan en un entorno seguro basado en contenedores y totalmente gestionado por Snowflake. Este diseño garantiza que las aplicaciones permanezcan aisladas, al tiempo que se mantiene una conexión segura con las fuentes de datos y los servicios de Snowflake. A medida que aumenta la complejidad de tu aplicación o crece el tamaño de las bases de datos, Snowflake gestiona el escalado en el backend.
Cuando inicias una aplicación, esta consume recursos informáticos de tu almacén configurado. Al igual que tus consultas SQL, el tamaño del almacén afecta tanto al rendimiento como al coste, por lo que es importante planificar los recursos. A los programadores os resulta útil disponer de un almacén vinculado a vuestras aplicaciones Streamlit para simplificar el seguimiento. Además, Snowflake utiliza etapas internas para el almacenamiento seguro de archivos, lo que evita que los datos se filtren fuera de la plataforma. Esto simplifica la introducción de datos en tu aplicación, al tiempo que mantiene la seguridad de tus datos.
Los entornos Python en SiS se gestionan y supervisan por motivos de seguridad. Solo están disponibles los paquetes aprobados y la instalación de paquetes externos está restringida. Además, algunas cosas como scripts, estilos, fuentes e incrustaciones iframe están restringidas por motivos de seguridad. Si necesitas funcionalidades que no se incluyen en lo proporcionado, es posible que tengas que implementarlas mediante las funciones definidas por el usuario (UDF) de Snowpark o recurrir a las bibliotecas Python existentes compatibles con Snowflake.
Afortunadamente, SiS utiliza gran parte de la infraestructura de seguridad existente de Snowflake, como el control de acceso basado en roles, el uso compartido y la seguridad de la red.
Snowflake utiliza un sistema de control de acceso basado en roles (RBAC) para las aplicaciones Streamlit y sus datos. Para acceder a los datos, se requiere el privilegio « USAGE » (Acceso a datos) para cualquier aplicación Streamlit y sus datos subyacentes. Solo los roles con privilegios de administrador ( CREATE STREAMLIT ) pueden crear aplicaciones, y la propiedad de las aplicaciones está vinculada a los permisos a nivel de esquema. Esto garantiza un control claro sobre quién puede desarrollar y gestionar aplicaciones.
El uso compartido de aplicaciones también está controlado. Puedes conceder o restringir el acceso a las aplicaciones en función de los roles de los usuarios. Para la ejecución de SQL, se siguen los mismos permisos basados en roles. Ejecuta SQL a través de la aplicación Streamlit y no permite a los programadores ejecutar consultas SQL en bases de datos sin los permisos adecuados.
En lo que respecta a la red, Snowflake aplica estrictas políticas de seguridad de contenido (CSP). Esto evita que las aplicaciones carguen scripts, estilos o recursos externos no autorizados, lo que reduce el riesgo de filtración de datos o integraciones inseguras. Al minimizar las bibliotecas externas que se importan al entorno, se reduce el riesgo de agujeros de seguridad y se protege la privacidad de los datos y del usuario.
A medida que tu aplicación se vuelve más compleja, es importante realizar una optimización adecuada para mantener su correcto funcionamiento.
Para crear aplicaciones eficientes, es necesario prestar atención tanto a las consultas como a los recursos informáticos. Es útil probar tus consultas fuera de tu aplicación Streamlit (en un almacén similar) para comprender el esfuerzo computacional que requiere tu consulta. Escribir consultas SQL optimizadas es esencial para evitar cuellos de botella.
Las funciones de almacenamiento en caché integradas en Streamlit st.cache_data y st.cache_resource ayudan a reducir los cálculos repetidos y la recarga de datos. Sin embargo, hay que tener en cuenta que st.cache_data y st.cache_resource no son totalmente compatibles. Solo permiten el almacenamiento en caché basado en sesiones, lo que significa que cada vez que el usuario abre una nueva sesión, la consulta y los datos tendrán que volver a cargarse. Tenlo en cuenta y asegúrate de optimizar tus consultas tanto como sea posible.
La selección del almacén desempeña un papel fundamental en la capacidad de respuesta de la aplicación. Los almacenes más grandes mejoran la velocidad, pero también aumentan los costes. Para aplicaciones con mucho tráfico, los almacenes dedicados pueden ser la mejor opción. Por otro lado, las aplicaciones ligeras suelen funcionar en almacenes más pequeños sin problemas de rendimiento.
La arquitectura de la aplicación también es importante. La carga progresiva de datos y la gestión del estado pueden hacer que las aplicaciones sean más receptivas, especialmente cuando se trabaja con grandes conjuntos de datos. Intenta no cargar toda la aplicación de una vez si hay varios componentes. Carga solo lo que necesites en cada momento. Diseñar aplicaciones teniendo en cuenta las limitaciones de recursos evita problemas como superar los límites de tamaño de los mensajes o de memoria.
Más allá de los simples paneles de control y aplicaciones de datos, Streamlit en Snowflake puede aprovechar algunas potentes herramientas para el machine learning, la inteligencia artificial, la inteligencia empresarial y el procesamiento del lenguaje natural. Destacamos algunos casos de uso.
Para los equipos de análisis, Streamlit en Snowflake es una forma de crear paneles interactivos y herramientas de generación de informes. Estar conectado a tus bases de datos Snowflake permite actualizaciones en tiempo real de los paneles de control para una mejor toma de decisiones. Puedes implementar aplicaciones similares dirigidas a diferentes departamentos y equipos de forma rápida y sencilla. Algunos ejemplos son los rastreadores de inventario, los paneles de control del uso informático o los resúmenes de rendimiento ejecutivo. Por ejemplo, podemos desarrollar análisis para centros de llamadas con la integración de Snowflake Cortex y Snowpark en la aplicación Streamlit tomando transcripciones de datos de llamadas y generando análisis sobre las mismas.
Para aprovechar al máximo tus datos, las aplicaciones Streamlit pueden diseñarse para el machine learning y la inteligencia artificial. Por ejemplo, los equipos de machine learning pueden implementar aplicaciones interactivas que sirvan de modelos para la previsión de la demanda, la segmentación de clientes o la detección de anomalías. Con Cortex AI, los programadores también pueden crear aplicaciones de generación aumentada por recuperación (RAG) o herramientas de IA conversacional. Una excelente implementación añade modelos PyTorch que proporcionan ventas adicionales específicas para los clientes en función de sus perfiles individuales, todo ello envuelto en una aplicación de inferencia visual.
Para obtener información sobre comentarios basados en texto, como chats y correos electrónicos, lo mejor es recurrir al procesamiento del lenguaje natural. El uso de bibliotecas como spaCy, NLTK o el procesamiento de texto interno de Snowflake Cortex AI, podemos tomar toda esta información textual y crear herramientas para el análisis de sentimientos, el reconocimiento de entidades nombradas y otras soluciones de PLN. Por ejemplo, podemos utilizar Snowflake Cortex para gestionar la mayor parte del análisis de PLN, como la síntesis y el análisis de opiniones. Esto alimenta una base de datos que proporciona análisis sobre las reseñas y el chat de asistencia utilizando Streamlit en Snowflake.
Las aplicaciones Streamlit también funcionan bien para la recopilación de datos y la gestión de la calidad, como herramientas de anotación o interfaces de entrada colaborativas. Aunque la carga de datos está limitada a 200 MB, podemos proporcionar un lugar donde los usuarios puedan cargar pequeños conjuntos de datos o documentos para su procesamiento o resumen en nuestra aplicación. ¡Las posibilidades son infinitas!
Contar con Streamlit en Snowflake es muy útil debido a las numerosas integraciones que se obtienen dentro del ecosistema, como Snowpark y el intercambio de datos.
Snowpark facilita enormemente la realización de análisis en Python con Snowflake. Permite el procesamiento avanzado de datos, cálculos distribuidos y funciones personalizadas. Dado que pueden utilizar los DataFrames de Snowpark de forma nativa en la aplicación Streamlit in Snowflake, pueden aprovechar esta función fácilmente con muy pocos gastos generales. El uso de procedimientos almacenados y funciones definidas por el usuario (UDF) en tu entorno Snowflake se convierte en un juego de niños con el objeto « udf» (Procedimiento almacenado) de Snowpark.
Compartir datos dentro de Snowflake es sencillo y, con la interfaz de usuario de Snowsight, solo se necesitan unos pocos clics. Al añadir tareas Snowflake y funciones basadas en eventos, los programadores también pueden automatizar fácilmente los flujos de trabajo. Por ejemplo, puedes activar actualizaciones de aplicaciones cuando lleguen nuevos datos, realizar comprobaciones de datos para garantizar que nada falle y mantener los datos actualizados.
Cuando se combina con dbt, puedes crear flujos de trabajo integrales en los que las transformaciones de datos fluyen directamente a las aplicaciones Streamlit, lo que garantiza actualizaciones en tiempo real para los usuarios.
Al igual que con todas las plataformas de la nube, las consideraciones relativas a la facturación y los costes son importantes. Una aplicación Streamlit cara tiene menos probabilidades de ser utilizada, por lo que pensar en los costes por adelantado garantiza un proceso de desarrollo fluido.
Los costes de Streamlit en Snowflake son iguales que los de cualquier otro proceso en Snowflake. Si tienes una base de datos/esquema específico para Streamlit, tendrás los costes de almacenamiento habituales asociados a esos datos. Como mencionamos anteriormente, lo más probable es que quieras crear un almacén asignado específicamente a tus servicios Streamlit en Snowflake para que también puedas realizar un seguimiento de los costes de computación. El tamaño de los almacenes, la concurrencia de aplicaciones (múltiples sesiones de usuario) y el volumen de datos serán los principales factores que determinarán tus costes.
Para controlar el gasto, es importante dimensionar adecuadamente los almacenes. Las aplicaciones pequeñas con cargas de trabajo ligeras deben evitar el uso de almacenes innecesariamente grandes. El almacenamiento en caché de Streamlit ayuda a minimizar las consultas repetidas dentro de las sesiones, lo que reduce el uso de recursos informáticos. Snowflake también ofrece herramientas de supervisión que realizan un seguimiento del consumo para que puedas realizar ajustes de costes basados en datos.
Aunque Streamlit en Snowflake es muy potente, hay algunas restricciones que debes tener en cuenta, especialmente en lo que respecta a los paquetes externos y la carga de archivos.
La plataforma aplica estrictas políticas de seguridad de contenido para garantizar la seguridad de los datos. Es más probable que se bloqueen elementos como scripts personalizados, estilos y elementos que requieren un dominio externo. Asegúrate de que los componentes que utilices no requieran llamadas externas. Esto mejora considerablemente la seguridad de tu aplicación, pero limita algunas de las opciones de personalización a las que puedes estar acostumbrado si vienes de tus propias implementaciones de Streamlit.
El manejo de grandes conjuntos de datos puede ser un reto debido a algunas limitaciones en el almacenamiento en caché y la transferencia de mensajes. La principal limitación del almacenamiento en caché es que se basa en la sesión y no en el usuario. Por lo tanto, los usuarios que vuelvan a visitar las aplicaciones e inicien nuevas sesiones tendrán que volver a cargar los datos. Ten en cuenta cuidadosamente a tus usuarios y si tendrán que iniciar nuevas sesiones varias veces. Si es así, piensa en cómo puedes minimizar la carga de datos entre sesiones.
Aunque no hay un límite explícito en cuanto al tamaño de las consultas o la cantidad de datos en la memoria, los mensajes tienen un límite de 32 MB. Esto significa que mostrar DataFrames grandes y mapas extremadamente complejos puede ser un factor limitante. Considera qué es lo esencial que debes mostrar a los usuarios y qué se puede simplificar.
La subida de archivos funciona, pero está limitada a un tamaño máximo de 200 MB. Tampoco podrás trabajar directamente con etapas externas y tendrás que trasladar primero los datos a Snowflake. Por lo tanto, extraer datos directamente de Apache Iceberg no funcionará, pero sí lo hará extraerlos de un lago de datos interno para esos datos.
Además, la funcionalidad de carga de archivos tiene un tamaño limitado y, actualmente, no se admiten etapas externas, lo que restringe la forma en que las aplicaciones gestionan los archivos.
Streamlit en Snowflake ofrece una forma potente e integrada de crear e implementar aplicaciones de datos interactivas sin salir de tu entorno Snowflake. Combina seguridad, escalabilidad y facilidad de uso, al tiempo que admite integraciones avanzadas con Snowpark, Cortex AI y dbt.
Aunque existen limitaciones, como restricciones en los recursos externos y la carga de archivos, las ventajas de la rápida iteración, la infraestructura gestionada y el intercambio fluido convierten a SiS en una plataforma transformadora para los equipos de datos. Los profesionales junior pueden empezar poco a poco, experimentando con paneles sencillos, y ampliar sus conocimientos hasta llegar a aplicaciones de IA y análisis preparadas para la empresa. Para obtener más información sobre Snowflake, consulta lo siguiente:
Los mejores cursos de DataCamp
programa
programa
programa
blog
Matt Crabtree
15 min
Tutorial
Nadia mhadhbi
Tutorial
Natassha Selvaraj
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Olivia Smith
