
programa
Fundaciones de Snowflake
7 h
A medida que los equipos de datos modernos adoptan pilas analíticas cada vez más complejas, se ha producido un cambio hacia la creación de prácticas estándar dentro de los flujos de trabajo de ingeniería de datos. Herramientas como dbt (Data Build Tool) son un marco de código abierto que incorpora las mejores prácticas de ingeniería de software, como el control de versiones, las pruebas y la documentación, a los flujos de trabajo de análisis.
La combinación de dbt y Snowflake (un almacén de datos nativo de la nube) se ha convertido en una piedra angular de los flujos de trabajo de ingeniería analítica. Esta guía explora los conceptos fundamentales, la configuración y las estrategias de implementación avanzadas para integrar dbt con Snowflake, lo que ayuda a los equipos de datos a lograr canalizaciones de datos más fáciles de mantener, seguras y con un mejor rendimiento.
Si acabas de empezar a utilizar estas herramientas, te recomiendo que realices nuestro programa de formación Snowflake Foundations y el curso Introducción a dbt.
Hablemos de cómo funcionan conjuntamente dbt y Snowflake. En esta sección se presentan las capacidades de dbt y se destaca su compatibilidad con Snowflake, así como las ventajas de integrarlos.
dbt (Data Build Tool) es un marco de código abierto que permite a los equipos de datos transformar, probar y documentar datos directamente en su almacén utilizando SQL mejorado con plantillas Jinja.
dbt no es un lenguaje de programación en sí mismo, sino que actúa como un compilador que toma modelos SQL modulares y los convierte en consultas SQL ejecutables que se ejecutan en el almacén (por ejemplo, Snowflake).
Al incorporar el control de versiones, las pruebas automatizadas y la documentación, dbt aporta prácticas de ingeniería de software probadas a la ingeniería analítica, lo que hace que los procesos de transformación sean más fiables, fáciles de mantener y escalables como parte de un flujo de trabajo ELT.
Tus componentes principales incluyen un compilador y un ejecutor. Estas son sus funciones:
Para que dbt funcione, hay algunos componentes subyacentes que ayudan a que todo fluya:
select guardadas como archivos .sql.Para obtener más información sobre dbt, te recomiendo este excelente curso de introducción a dbt.
Al utilizar las plantillas basadas en Jinja de dbt junto con los potentes tipos de datos de Snowflake, como Streams, podemos ser muy creativos con nuestros flujos de trabajo de transformación.
Por ejemplo, tal vez queramos transformar solo los datos recién cargados o realizar transformaciones diferentes en nuestras tablas de preparación frente a nuestras tablas de producción, para poder realizar comprobaciones del estado de los datos.
Ambos se están convirtiendo rápidamente en una combinación habitual para ayudar a los ingenieros de datos a obtener un mayor control y flexibilidad de sus canalizaciones de datos, y cada vez son más las empresas que adoptan dbt de forma habitual.
El DBT ofrece numerosas ventajas: metodología tradicional de desarrollo de software, pruebas automatizadas y mejoras en la productividad.
Podemos tratar nuestros datos y SQL más como código tradicional. Nos proporciona modularidad, capacidad de prueba y control de versiones. Al aprovechar las plantillas y las sentencias de control de flujo de Python, obtenemos algunas funciones muy potentes de dbt.
Utilizando la configuración integrada de dbt « data_test », podemos ejecutar pruebas periódicamente con nuestros datos sin necesidad de utilizar complicadas canalizaciones SQL. De hecho, dbt ya incluye algunas pruebas básicas muy potentes que podemos implementar fácilmente en nuestros archivos de configuración.
Dentro de dbt hay elementos como generadores de documentación y visualizadores de procesos. Los nuevos miembros del equipo pueden incorporarse más rápidamente y los miembros existentes pueden comprender mejor los flujos de datos. Esto ayuda a reducir el tiempo de puesta en marcha y mejora la comprensión general del flujo de trabajo por parte de todos.
El uso de la plataforma basada en la nube de Snowflake ofrece numerosas ventajas. Cuenta con una excelente arquitectura que separa los recursos de almacenamiento y computación para minimizar los conflictos entre recursos y mejorar los costos. Utiliza la clonación sin copia, lo que permite a los usuarios crear clones de bases de datos sin almacenamiento adicional.
Además, admite algunos tipos de datos de tabla complejos, como tablas dinámicas y Streams, que permiten una lógica de actualización incremental. Para obtener más información sobre Snowflake como plataforma, consulta este artículo en el que se explica cómo funciona Snowflake.
Lo más importante es que estas características complementan muy bien a dbt. Podemos aprovechar la actualización incremental para ayudar a dbt a activar transformaciones basadas en datos nuevos. También podemos aprovechar la separación entre computación y almacenamiento de Snowflake, lo que permite a dbt realizar transformaciones más intensas desde el punto de vista computacional sin afectar a la capacidad de cargar y almacenar datos.
Todo esto viene acompañado de la capacidad de Snowflake para escalar rápidamente y su modelo de coste de pago por uso. A medida que aumenta la complejidad de nuestros scripts dbt, podemos ampliar fácilmente nuestros almacenes informáticos Snowflake para satisfacer esas demandas. Al mismo tiempo, podemos utilizar la supervisión de Snowflake para optimizar vuestros almacenes y utilizar dbt para agilizar el rendimiento de vuestras consultas.
Cuando se combinan, Snowflake y dbt se complementan muy bien. El ajuste constante de Snowflake ayuda a mantener bajos los costes basados en la nube. dbt puede aprovechar métodos de partición de tablas, como claves de agrupación y el almacenamiento en caché de Snowflake, para mejorar la sobrecarga de datos.
Snowflake no se presta a ser gestionado fácilmente utilizando herramientas como Git. Dado que dbt se basa en los mismos principios que otros lenguajes de programación, podemos utilizar flujos de trabajo basados en Git para gestionar más fácilmente nuestros procesos de desarrollo con elementos como los procesos de CI/CD. Esto puede ayudar a controlar las versiones de tus procesos, lo que resultaría complicado si se hiciera completamente en Snowflake.
Para ayudar a los programadores a colaborar más fácilmente, dbt también cuenta con una interfaz de usuario que muestra todos tus trabajos de dbt en un solo lugar. Esto ayuda a los equipos a programar conjuntamente los procesos y a asegurarse de que funcionan correctamente. Además, dbt ha introducido recientemente un IDE Studio que permite una fácil integración de Git y bases de datos con los flujos de trabajo de pruebas. Algunos equipos pueden incluso optar por utilizar la interfaz de usuario de Snowflake para una integración completa.
Muchos equipos de datos han comenzado a utilizar dbt y Snowflake juntos para sacar el máximo partido a sus bases de datos. Sigue aprendiendo más sobre dbt en esta introducción práctica a dbt para ingenieros de datos y descubre cómo funciona el modelado de datos de Snowflake con este curso.
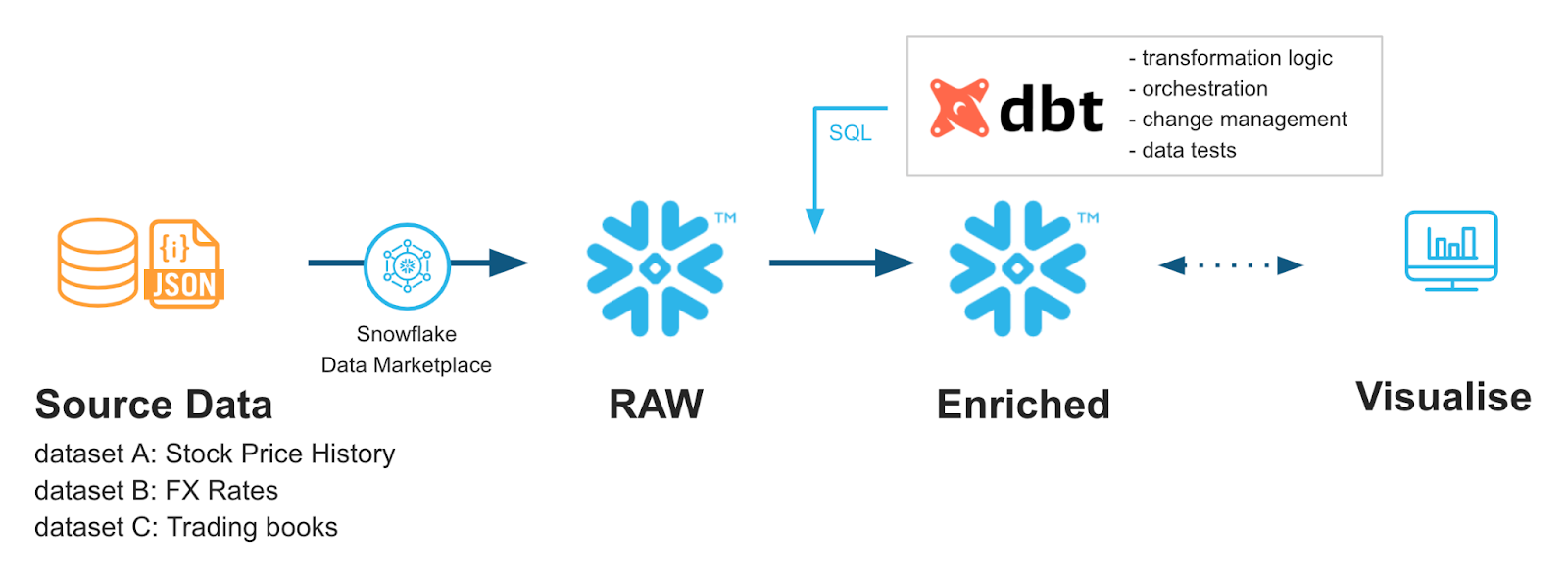
De Snowflake Quickstarts: Acelerando con dbt Core y Snowflake
Repasemos algunos conceptos básicos sobre cómo configurar Snowflake y dbt para una integración adecuada. También abordaremos algunos conceptos básicos sobre las mejores prácticas en el diseño de la estructura de proyectos.
Comenzaremos con la configuración de la base de datos Snowflake y luego pasaremos a la configuración de dbt.
Necesitarás una base de datos dedicada, un esquema y un almacén virtual que almacene tus datos dbt. Además, necesitarás un rol de usuario específico de dbt al que dbt pueda acceder. Al configurar dbt, deberás proporcionar las credenciales de ese usuario para que pueda comunicarse con Snowflake. En esta sección, te daré algunas pautas básicas, pero para obtener más detalles sobre cómo administrar bases de datos Snowflake y roles de usuario, consulta el curso Introducción a Snowflake.
CREATE DATABASE analytics_db;
CREATE SCHEMA analytics_db.transformations;
CREATE WAREHOUSE dbt_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE ROLE dbt_role;
GRANT USAGE ON WAREHOUSE dbt_wh TO ROLE dbt_role;
GRANT USAGE ON DATABASE analytics_db TO ROLE dbt_role;
GRANT USAGE, CREATE SCHEMA ON DATABASE analytics_db TO ROLE dbt_role;
GRANT ALL PRIVILEGES ON SCHEMA analytics_db.transformations TO ROLE dbt_role;
CREATE USER dbt_user PASSWORD='StrongPassword123'
DEFAULT_ROLE = dbt_role
DEFAULT_WAREHOUSE = dbt_wh
DEFAULT_NAMESPACE = analytics_db.transformations;
GRANT ROLE dbt_role TO USER dbt_user;
Para ejecutar dbt, tendrás que instalarlo utilizando pip y, a continuación, configurar tu archivo profiles.yml.
dbt-core y dbt-snowflake.pip install dbt-core dbt-snowflakeprofiles.yml y guárdalo en ~/.dbt/profiles.ymlsnowflake-db:
target:dev
outputs:
dev:
type: snowflake
account: [account_id from earlier]
user: [dbt_user]
password: [dbt_pw]
role: [dbt_role]
warehouse:[dbt_warehouse]
database: [dbt_database]
schema: [dbt_schema]
threads: 4
client_session_keep_alive: False
query_tag: [anything]dbt init --profile snowflake-dbdbt init snowflake-profile-nameEsto pasará por una inicialización paso a paso que generará un archivo profiles.yml si es necesario.
debug:dbt debug --connectionEste comando comprobará si la configuración de la conexión es válida y mostrará un error si no lo es.
Algo a tener en cuenta: en lugar de incluir tu nombre de usuario y contraseña directamente en el archivo profiles.yml , prueba a utilizar variables de entorno. Por ejemplo, el nombre de dominio completo ( dbt_password ) podría guardarse en una variable de entorno ( SNOWFLAKE_PASSWORD ). A continuación, en profiles.yml, escribirías password: “{{env_var(‘SNOWFLAKE_PASSWORD’)}}”. Esto ayuda a evitar que las personas vean las credenciales en el archivo de configuración y añade un poco más de seguridad.
Conectarte a Git te ayudará a sacar el máximo partido a tu configuración de dbt. Los pasos exactos pueden variar si lo haces como parte de tu empresa. Sin embargo, la premisa general es muy clara. Crea un repositorio en algo como GitHub o GitLab. A continuación, vincula tu cuenta dbt a la cuenta GitHub/GitLab. Una vez hecho esto, puedes git clone tu repositorio. Para obtener más información sobre cómo conectar Git a dbt, consulta la documentación de Git de dbt para tu plataforma en particular.
Una estructura de proyecto coherente y basada en plantillas ayuda a que los nuevos proyectos se pongan en marcha más rápidamente, ya que proporciona ubicaciones fijas donde debe ir cada cosa.
Estructura tu proyecto en carpetas entre staging, intermediate y marts. Dentro de cada uno, puedes especificar diferentes departamentos que tienen sus propios modelos y SQL.
models/
│ ├── intermediate
│ │ └── finance
│ │ ├── _int_finance__models.yml
│ │ └── int_payments_pivoted_to_orders.sql
│ ├── marts
│ │ ├── finance
│ │ │ ├── _finance__models.yml
│ │ │ ├── orders.sql
│ │ │ └── payments.sql
│ │ └── marketing
│ │ ├── _marketing__models.yml
│ │ └── customers.sql
│ ├── staging
│ │ ├── jaffle_shop
│ │ │ ├── _jaffle_shop__docs.md
│ │ │ ├── _jaffle_shop__models.yml
│ │ │ ├── _jaffle_shop__sources.yml
│ │ │ ├── base
│ │ │ │ ├── base_jaffle_shop__customers.sql
│ │ │ │ └── base_jaffle_shop__deleted_customers.sql
│ │ │ ├── stg_jaffle_shop__customers.sql
│ │ │ └── stg_jaffle_shop__orders.sql
│ │ └── stripe
│ │ ├── _stripe__models.yml
│ │ ├── _stripe__sources.yml
│ │ └── stg_stripe__payments.sql
│ └── utilities
│ └── all_dates.sql/Cada carpeta dentro de los modelos tiene un propósito:
Para cada uno de los archivos de configuración de los modelos de ensayo, intermedios y de mercado, es posible que desees establecer la configuración +materialized para definir cómo se crea la salida SQL en Snowflake. Podemos elegir entre vistas, tablas o conjuntos de datos incrementales.
Podría verse así:
# The following dbt_project.yml configures a project that looks like this:
# .
# └── models
# ├── csvs
# │ ├── employees.sql
# │ └── goals.sql
# └── events
# ├── stg_event_log.sql
# └── stg_event_sessions.sql
name: my_project
version: 1.0.0
config-version: 2
models:
my_project:
events:
# materialize all models in models/events as tables
+materialized: table
csvs:
# this is redundant, and does not need to be set
+materialized: viewUna gran ventaja de integrar dbt y Snowflake es que obtenemos optimizaciones de ambas plataformas. En Snowflake, podemos utilizar diferentes formas de gestionar las consultas para que se ejecuten más rápido. Para dbt, podemos optimizar vuestra codificación con macros y técnicas de materialización.
Hay algunas características únicas de Snowflake que podemos aprovechar para mejorar el rendimiento de nuestras consultas.
Dos formas importantes en las que optimizamos en Snowflake son el predicate pushdown y las claves de agrupación.
El pushdown de predicados es la idea de cambiar cuándo filtra Snowflake para que lea menos datos. Por ejemplo, imaginemos que estamos consultando nuestros datos con dos capas de filtrado: un filtro de seguridad y un filtro categórico.
El filtro de seguridad define quién puede ver determinadas partes de nuestra tabla en función de los roles de seguridad. El filtro categórico se encuentra en nuestra instrucción « WHERE » (seleccionar por) en la consulta. Snowflake elegirá el filtro que vaya primero, que requerirá leer la menor cantidad de datos.
Para facilitar este empuje de predicados, podríamos considerar la agrupación de claves. Aunque Snowflake hace un buen trabajo agrupando tablas, cuando los datos alcanzan varios TB, resulta complicado para Snowflake mantener particiones sensatas.
Al definir claves de agrupación, podemos ayudar a Snowflake a particionar los datos de una forma que se adapte a la frecuencia con la que consultamos la tabla. Por ejemplo, tal vez seleccionemos dos columnas que siempre van juntas, como fechas y tipos de propiedades. Cada tipo de propiedad puede tener un número de fechas lo suficientemente pequeño como para que la repartición resulte sensata y la ubicación de los datos sea eficaz.
La combinación de claves de agrupación con la optimización de predicados pushdown de Snowflake puede hacer que la navegación por tablas grandes sea mucho más eficiente.
¡El uso de recursos en un sistema de pago por uso como Snowflake es importante! Debes seguir unos principios sencillos:
auto-suspend » (Suspender almacenes) de Snowflake para suspender los almacenes cuando tus canalizaciones estén fuera de línea durante un periodo prolongado de tiempo.auto-resume te permitirá reiniciar el almacén según sea necesario.Estos sencillos ajustes en el almacén harán que tu uso de Snowflake sea más eficiente a largo plazo.
En cuanto a dbt, podemos aprovechar las tablas dinámicas y los modelos incrementales para simplificar la lógica de actualización.
Las tablas dinámicas son un tipo de tabla de Snowflake que se actualiza automáticamente en función de los tiempos de retraso definidos. dbt tiene la capacidad de materializar tablas dinámicas como parte de su configuración y configurarlas de manera similar a como se haría en Snowflake.
models:
<resource-path>:
+materialized: dynamic_table
+on_configuration_change: apply | continue | fail
+target_lag: downstream | <time-delta>
+snowflake_warehouse: <warehouse-name>
+refresh_mode: AUTO | FULL | INCREMENTAL
+initialize: ON_CREATE | ON_SCHEDULEEsto resulta conveniente para disponer de canales de transferencia de datos sencillos que no requieren un SQL complejo. Lo mejor es que podemos conectarnos a estas tablas dinámicas y disponer de datos actualizados según sea necesario.
Otra forma flexible de crear tablas es utilizar el modelo incremental. Al escribir nuestro SQL, filtramos una columna que nos permite saber qué datos son nuevos. A continuación, utilizamos la macro ` is_incremental() ` para indicar a dbt que solo utilice ese filtro cuando configures una tabla incremental materializada.
Tu ejemplo de SQL podría tener un aspecto similar al siguiente, extraído de la documentación de dbt:
{{
config(
materialized='incremental'
)
}}
select
*,
my_slow_function(my_column)
from {{ ref('app_data_events') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
-- (uses >= to include records whose timestamp occurred since the last run of this model)
-- (If event_time is NULL or the table is truncated, the condition will always be true and load all records)
where event_time >= (select coalesce(max(event_time),'1900-01-01') from {{ this }} )
{% endif %}Me has visto aludir a algo llamado «macro». Son fragmentos de código reutilizables en dbt. Podrían ser cálculos que se repiten o transformaciones que se producen con frecuencia.
Creamos macros utilizando plantillas Jinja. Un caso de uso habitual puede ser clonar bases de datos antes de trabajar con ellas.
{% macro clone_tables(table_to_clone) -%}
–- shows all tables within a schema
{% set all_tables_query %}
show tables in schema {{ clone_tables }}
{% endset %}
-- take the set results and use the run_query macro
{% set results = run_query(all_tables_query) %}
{{ "create or replace schema " ~ generate_schema_name(var("custom_tables_list")) ~ ";" }}
--execute the cloning function
{% if execute %}
{% for result_row in results %}
{{ log("create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";") }}
{{ "create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";" }}
{% endfor %}
{% endif %}
{%- endmacro %}Esta plantilla toma un esquema proporcionado, genera una lista de tablas y luego las clona en el almacén/esquema proporcionado en tu configuración de dbt. A continuación, puedes utilizar esta macro en tu código dbt o al iniciar dbt.
Para practicar más con Jinja en dbt, recomiendo encarecidamente este caso práctico sobre la creación de modelos de datos de comercio electrónico con dbt. Recorre algunas plantillas Jinja complejas con dbt y te proporciona una experiencia práctica bastante avanzada.
Al trabajar con información de clientes, es posible que tengamos acceso a información de identificación personal (PII) y necesitemos ocultarla en nuestra base de datos. ¡Con Snowflake es muy fácil! Podemos utilizar CREATE MASKING POLICY para indicar a Snowflake qué columnas y tipos de datos deben enmascararse cuando se ejecutan consultas. Estas políticas garantizan que no se filtre ninguna información de identificación personal al consultar información confidencial.
A continuación, podemos utilizar dbt tests con SQL personalizado que comprueba que las tablas se enmascaran correctamente. Por ejemplo, si definimos una política de enmascaramiento que solo permite que el rol ANALYST vea la PII, de la siguiente manera:
CREATE OR REPLACE MASKING POLICY email_mask AS (val string) returns string ->
CASE
WHEN current_role() IN ('ANALYST') THEN VAL
ELSE '*********'
END;A continuación, al utilizar tu rol de usuario dbt_account para consultar los datos, debería aparecer la cadena '*********'.
Si nuestra prueba hace algo sencillo como:
SELECT *
FROM schema.table
WHERE email <> '*********'Si esta prueba arroja resultados, entonces debe considerarse un fallo. Ningún correo electrónico debe devolverse como algo distinto a la cadena enmascarada. A continuación, debemos comprobar la política de enmascaramiento en Snowflake y seguir realizando pruebas hasta que funcione correctamente.
Como siempre, la seguridad es un pilar fundamental del acceso a la nube. En esta sección repasaremos algunos conceptos básicos sobre seguridad y protección de datos.
El marco de seguridad principal de Snowflake es el control de acceso basado en roles (RBAC) y el uso de cuentas de servicio.
Definir privilegios RBAC nos permite aplicar configuraciones de seguridad a un amplio grupo de usuarios sin tener que asignarlos manualmente de forma individual. Esto facilita su mantenimiento.
Como se ha indicado anteriormente, creamos roles utilizando la instrucción « CREATE ROLE ». Para otorgar permisos, utilizamos GRANT … TO ROLE y, del mismo modo, los eliminamos mediante REVOKE … FROM ROLE.
A continuación, se indican algunas prácticas recomendadas:
dbt_reader, acceso para crear tablas a dbt_writer y acceso para eliminar solo a una cuenta de administrador como dbt_admin.Las cuentas de servicio son cuentas especiales basadas en máquinas que interactúan sin intervención humana. Estas cuentas no tienen nombres de usuario ni contraseñas. En su lugar, utilizan claves públicas y restricciones de red para minimizar el riesgo.
La creación de una cuenta de servicio podría tener el siguiente aspecto:
CREATE USER dbt_service
RSA_PUBLIC_KEY = <keysring>De esta manera, tienes una cuenta única gestionada por los administradores y ya no tienes que preocuparte por los usuarios individuales. Se recomienda rotar regularmente las claves para que no se filtren. Además, asegúrate de vigilar de cerca la actividad de la red utilizando el servicio de supervisión de redes de Snowflake ( LOGIN_HISTORY).
Protege tus datos y tus inicios de sesión. Aunque hayamos codificado tus credenciales como ejemplo, en realidad se trata de una mala práctica. Utiliza gestores de claves secretas como AWS Secrets Manager o GitHub Secrets para guardar tus credenciales importantes.
Te permiten almacenar credenciales en línea a las que solo pueden acceder los usuarios con las claves RSA/Security adecuadas. Nadie puede ver el valor real y rotar contraseñas/claves es fácil gracias a su gestión automatizada.
Asegúrate de que todas las conexiones estén correctamente protegidas y de que los usuarios se encuentren en la red empresarial adecuada para acceder a los datos. Esto suele establecerse mediante el uso de VPN como GlobalProtect. Dado que os conectáis a Snowflake, gran parte del cifrado de extremo a extremo lo gestiona la nube. ¡Otra ventaja más de estar en Snowflake!
Por último, queremos auditar nuestra actividad. Snowflake registra las consultas a través de tablas como QUERY_HISTORY y QUERY_HISTORY_BY_USER. Podemos supervisar el uso, los errores y cualquier abuso de seguridad en estos registros. A través de dbt, podemos programar las nuevas ejecuciones, cambios o ediciones de los proyectos utilizando vuestras canalizaciones de control de versiones.
El control de versiones y las plantillas de codificación ayudan a mantener el programa de seguimiento de los cambios y el cumplimiento normativo. Cualquier problema derivado de los cambios se puede detectar fácilmente durante las solicitudes de extracción obligatorias y solucionar antes de que se convierta en un problema.
¡Hablemos de cómo podemos ahorrar algo de dinero! En dbt, por supuesto. Es fundamental supervisar el rendimiento de nuestro modelo. Es fácil que los modelos que antes funcionaban sin problemas se vuelvan más lentos y menos eficaces a medida que aumenta el tamaño de las tablas.
Con dbt, la mejor manera de supervisar el rendimiento es utilizar paquetes integrados como dbt-snowflake-monitoring o herramientas externas como Looker y Datafold para facilitar la visualización y la comparación de datos.
¡Empezar a utilizar dbt-snowflake-monitoring es muy fácil! En tu dbt packages.yml, añade lo siguiente:
packages:
- package: get-select/dbt_snowflake_monitoring
version: [">=5.0.0", "<6.0.0"] # We'll never make a breaking change without creating a new major version.A continuación, en el archivo YAML de cada proyecto, añade lo siguiente:
dispatch:
- macro_namespace: dbt
search_order:
- <YOUR_PROJECT_NAME>
- dbt_snowflake_monitoring
- dbt
query-comment:
comment: '{{ dbt_snowflake_monitoring.get_query_comment(node) }}'
append: true # Snowflake removes prefixed comments.¡Ahora ya estás listo para utilizar el paquete para supervisar aspectos como el uso de tu almacén, la duración de las consultas y los modelos fallidos! Utiliza el acceso existente de tu usuario dbt para escribir tablas en Snowflake, que contienen información útil. Por ejemplo, si quisieras ver tu gasto mensual en el almacén, podrías utilizar el siguiente SQL:
select
date_trunc(month, date)::date as month,
warehouse_name,
sum(spend_net_cloud_services) as spend
from daily_spend
where service in ('Compute', 'Cloud Services')
group by 1, 2Las herramientas externas como Looker o Tableau se pueden integrar directamente con dbt para facilitar la visualización de los datos y el rendimiento. Para las alertas, dbt puede enviar correos electrónicos o notificaciones de Slack.
Para realizar comparaciones más detalladas, las pilas externas como Datafold proporcionan una visión más profunda de cómo los cambios afectan a la calidad de los datos. Datafold automatiza las diferencias de datos con cada cambio de código que realices. Esto permite que otros miembros del equipo revisen fácilmente tu código y el impacto que tendrá en los datos. Este tipo de pruebas de regresión automatizadas nos permiten mantener la calidad de los datos sin tener que crear constantemente nuevas comprobaciones y herramientas.
No podemos evitar ejecutar nuestros procesos ETL, pero sin duda podemos planificar con antelación para minimizar el impacto de los costes de computación y almacenamiento. Gracias al diseño dividido de Snowflake, podemos optimizar nuestros almacenes y el almacenamiento por separado para crear un entorno más flexible y optimizado en cuanto a costes.
En el caso de los almacenes, lo mejor es reducir al mínimo el tiempo de inactividad. Distribuye tus canalizaciones automatizadas tanto como sea posible para reducir el tiempo de inactividad, los picos en las necesidades computacionales y la competencia por los recursos.
Supervisa regularmente las tablas WAREHOUSE_LOAD_HISTORY y QUERY_HISTORY para comprender cómo se están utilizando los recursos. La mejor práctica es empezar con XS. Si las consultas se ejecutan con demasiada lentitud, es hora de ampliar la capacidad en función del acuerdo de nivel de servicio (SLA) de tu equipo.
Para el almacenamiento, la mejor práctica es eliminar las tablas innecesarias. Aunque Snowflake no cuenta con niveles de almacenamiento en frío como AWS y Google, puedes optar por trasladar tus datos de Snowflake a AWS/Google para estos niveles de almacenamiento en frío y reducir así los costes de almacenamiento.
Las políticas de retención de datos pueden establecer claramente un calendario para las tablas que se utilizan con poca frecuencia y cuándo se trasladarán al almacenamiento en frío.
En el caso de las tablas grandes que crecen con frecuencia, supervisa de cerca. A medida que crecen, la capacidad de Snowflake para particionar de forma automática y eficiente se ve afectada. Aprovecha la agrupación automática mencionada anteriormente para ayudar a Snowflake a particionar mejor tus datos. Unas particiones mejores reducen el tiempo de lectura del almacenamiento y, por lo tanto, ahorran costes.
Gracias a la integración nativa de dbt con el control de versiones, la CI/CD y los procesos automatizados son muy sencillos. Cubriremos algunas opciones de orquestación automatizada y las mejores prácticas de prueba.
Con dbt Nube, podemos utilizar Snowflake Tasks para activar ejecuciones programadas de nuestros proyectos dbt. El proceso consiste en crear primero un proyecto dbt dentro de Snowflake utilizando nuestro repositorio Git y, a continuación, crear una tarea que ejecute ese proyecto dbt.
Por ejemplo, podríamos hacer algo como lo siguiente para crear un proyecto dbt:
CREATE DBT PROJECT sales_db.dbt_projects_schema.sales_model
FROM '@sales_db.integrations_schema.sales_dbt_git_stage/branches/main'
COMMENT = 'generates sales data models';A continuación, utilizamos el siguiente código para ejecutar ese proyecto:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.run_dbt_project
WAREHOUSE = sales_warehouse
SCHEDULE = '6 hours'
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.sales_model args='run --target prod';De hecho, es tan completo que incluso podemos realizar pruebas posteriores para asegurarnos de que el proyecto se ha ejecutado correctamente:
CREATE OR ALTER TASK sales_db.dbt_projects_schema.test_dbt_project
WAREHOUSE = sales_warehouse
AFTER run_dbt_project
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.test_dbt_project args='test --target prod';Para la programación, tenemos la opción de establecer una hora fija, como 60 MINUTES y 12 HOURS, o utilizar cron, como USING CRON 0 9 * * * UTC.
Sin embargo, nuestros modelos rara vez permanecen estáticos y, a menudo, tenemos que repetirlos. Crear manualmente cada parte de tu canalización puede llevar mucho tiempo. Aquí es donde entran en juego GitHub Actions. A menudo utilizamos GitHub Actions en los procesos de CI/CD para automatizar las pruebas y la compilación del código.
Las acciones de GitHub se diseñan utilizando archivos YAML dentro de una carpeta .github/workflows dentro del repositorio. Podemos hacer que se activen cada vez que realicemos una solicitud de extracción, de modo que se ejecuten algunas pruebas dbt.
name: dbt pull test
# CRON job to run dbt at midnight UTC(!) everyday
on:
pull_request:
types:
openedreopened
# Setting some Env variables to work with profiles.yml
# This should be your snowflake secrets
env:
DBT_PROFILE_TARGET: prod
DBT_PROFILE_USER: ${{ secrets.DBT_PROFILE_USER }}
DBT_PROFILE_PASSWORD: ${{ secrets.DBT_PROFILE_PASSWORD }}
jobs:
dbt_run:
name: dbt testing on pull request
runs-on: ubuntu-latest
timeout-minutes: 90
# Steps of the workflow:
steps:
- name: Setup Python environment
uses: actions/setup-python@v4
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
- name: Install dbt packages
run: dbt deps
# optionally use this parameter
# to set a main directory of dbt project:
# working-directory: ./my_dbt_project
- name: Run tests
run: dbt test
# working-directory: ./my_dbt_projectConfigurar correctamente tus automatizaciones puede facilitarte mucho la vida y ayudar a otros programadores a ver tus modelos probados. Esto agiliza el proceso de desarrollo al reducir la necesidad de realizar pruebas manuales.
dbt incluye un potente conjunto de pruebas. Incluye varias pruebas de datos genéricas listas para usar que se pueden configurar directamente en tu modelo y permiten una lógica SQL personalizada. Las pruebas genéricas se establecen en columnas concretas de tu modelo y comprueban si esas columnas específicas superan la prueba. Las pruebas listas para usar son las siguientes:
unique: todos los valores de esta columna deben ser únicos.not_null: no debe haber valores nulos en la columna.accepted_values: comprueba si los valores están en una lista de valores aceptados.relationshipscomprueba si los valores de esta columna existen en otra tabla relacionada.A continuación se muestra un ejemplo del uso de estas relaciones (de la documentación de dbt sobre pruebas):
version: 2
models:
- name: orders
columns:
- name: order_id
data_tests:
# makes sure this column is unique and has no nulls
- unique
- not_null
- name: status
data_tests:
#makes sure this column only has the below values
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
data_tests:
# makes sure that the customer ids in this column are ids in the customers table
- relationships:
to: ref('customers')
field: idPodemos utilizar SQL personalizado para crear pruebas más específicas y genéricas. El objetivo es que las pruebas devuelvan filasque no cumplen. Por lo tanto, si aparece algún resultado, la prueba se considera fallida. Estos archivos SQL personalizados se encuentran en nuestro directorio tests.
Por ejemplo, si queréis saber si alguna venta fue negativa, podéis utilizar lo siguiente:
select
order_id,
sum(amount) as total_amount
from {{ ref('sales') }}
group by 1
having total_amount < 0A continuación, haríamos referencia a esa prueba en nuestro archivo schema.yml dentro de nuestra carpeta de pruebas:
version: 2
data_tests:
- name: assert_sales_amount_is_positive
description: >
Sales should always be positive and are not inclusive of refunds
Si quisiéramos utilizar este tipo de comprobación en más tablas y columnas, tal vez nos interesara convertirla en una prueba genérica. Podría verse así:
{% test negative_values(model, group,sum_column) %}
select {{group}},
sum({{sum_column}}) as total_amt
from {{ model }}
group by 1
having total_amt < 0
{% endtest %}Ahora podemos usar esta prueba en el archivo yaml de nuestros modelos, igual que las demás pruebas genéricas que incluye dbt. ¡Podrías comprobar si hay pasajeros negativos en un viaje o beneficios negativos, etc.! Las posibilidades son infinitas.
Para que estas pruebas sean más fluidas y sencillas, podemos aprovechar la clonación sin copia de Snowflake. A continuación, todas tus pruebas y CI se pueden realizar con el objeto clonado. La ventaja de esto es que no necesitamos espacio de almacenamiento adicional para disponer de un entorno de pruebas seguro. Además, siempre que necesitemos más espacio para realizar pruebas, podemos crear más entornos de prueba con esta clonación instantánea. Veamos las mejoras y tendencias futuras que nos deparan dbt y Snowflake. dbt mejora constantemente su integración tanto con su producto principal como con la IA. En Snowflake, podemos utilizar Snowsight como interfaz de usuario para ayudar a gestionar vuestros espacios de trabajo dbt. Al integrarse de forma más fluida en nuestro entorno Snowflake, minimizamos la necesidad de trabajar en modelos dbt externamente. En su lugar, podemos centralizar nuestros flujos de trabajo permitiendo a los equipos editar y colaborar a través de la interfaz de usuario de Snowflake. Para ayudar a acelerar el desarrollo, dbt ofrece un asistente basado en inteligencia artificial llamado dbt Copilot. Se puede acceder a este asistente a través del IDE dbt Studio, Canvas o Insights, y utiliza el procesamiento del lenguaje natural para ayudar a acelerar las partes más laboriosas del desarrollo de modelos, como la redacción de documentación y la creación de pruebas. El dbt Copilot puede utilizarse incluso para ayudar a incorporar nuevos analistas, proporcionándoles resúmenes concisos de proyectos y modelos. Utiliza estas dos herramientas para acelerar tu tiempo de producción y acortar el tiempo de desarrollo, lo que permitirá a tu equipo abordar los problemas de datos más difíciles y desafiantes de tu organización. Los procesos de machine learning requieren datos limpios y bien diseñados de forma constante. dbt es la herramienta perfecta para los procesos de transformación de datos que alimentan los modelos de machine learning. Podemos aprovechar la flexibilidad y la potencia de dbt para automatizar transformaciones de datos que se integran a la perfección en vuestras canalizaciones de machine learning. Por ejemplo, podemos transformar nuestros datos directamente en un almacén de machine learning. Estos datos se pueden utilizar con Cortex AI de Snowflake para obtener información más detallada. Si tenéis varios modelos que requieren transformaciones similares, las plantillas de dbt pueden simplificar la forma en que limpiáis vuestros datos y proporcionar una mayor coherencia y una gestión de datos más sencilla. Para conocer mejor las herramientas de IA de Snowflake, lee esta guía sobre Snowflake Arctic, que es el LLM de Snowflake. Gracias a la compatibilidad nativa de Snowflake con Python y a la API Snowpark para Python, podemos ejecutar código localmente sin tener que sacar los datos de Snowflake. El siguiente nivel consiste en utilizar Snowpark Containers, que actualmente (en el momento de escribir este artículo) solo están disponibles para las regiones de AWS y Azure, para ejecutar nuestro código dbt de forma completamente aislada. Para ello, empaquetamos nuestros modelos y entornos dbt en un contenedor, que luego se almacena en el repositorio de imágenes de Snowflake. A continuación, podemos utilizar fácilmente este proyecto dbt en contenedores dentro de Snowpark. ¿Cuál es la principal ventaja? La capacidad de utilizar más fácilmente los recursos de Snowflake para transformaciones de datos complejas basadas en Python y la integración de transformaciones dbt dentro del entorno Snowflake más amplio. Si tienes curiosidad por saber más sobre Snowpark, echa un vistazo a esta información que describe Snowflake Snowpark en detalle. La integración de dbt con Snowflake permite a los equipos de datos crear canalizaciones de transformación modulares, controladas y escalables. Con características como pruebas automatizadas, flujos de trabajo de CI/CD basados en Git y una escalabilidad perfecta, esta pila es ideal para las operaciones de datos modernas. Para seguir siendo competitivos, los equipos de datos deben dar prioridad a: A medida que ambas herramientas continúan desarrollándose, la integración de dbt + Snowflake será cada vez más potente para los equipos de ingeniería de datos. Si te interesa obtener más información sobre dbt o Snowflake, consulta los siguientes recursos:CREATE TABLE CLONE , de Snowflake, puede crear un clon sin copia en tu entorno de desarrollo/pruebas.
Tendencias emergentes y perspectivas futuras
Programadores de integración nativa
Integración de machine learning
Ejecución en contenedores
Conclusión
Cursos más populares de DataCamp
programa
programa
Curso
blog
Nisha Arya Ahmed
15 min
blog
Mike Shakhomirov
11 min
Tutorial
Oluseye Jeremiah
Tutorial
Anneleen Rummens
Tutorial
Joleen Bothma