Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100K
Snowflake Arctic es un desarrollo innovador del campo de las incorporaciones de texto, que ofrece un potente conjunto de herramientas diseñado para simplificar el proceso de adopción de la IA en los datos empresariales.
En este tutorial, ofreceremos una descripción general de Snowflake Arctic, veremos el proceso de configuración, exploraremos las técnicas de integración y compartiremos prácticas recomendadas y consejos de solución de problemas. También mostraremos casos de uso reales, debatiremos desarrollos futuros y ofreceremos recursos de formación y asistencia continuas.
Si deseas más información sobre Snowflake, consulta el curso Introducción a Snowflake.
Entonces, ¿qué es exactamente Snowflake Arctic? Es un completo conjunto de herramientas diseñado para simplificar la integración y la implementación de la IA en Snowflake Data Cloud. Básicamente, Snowflake Arctic ofrece una colección de modelos de incorporación que nos permite extraer información valiosa de nuestros datos de forma eficiente.
Además, incluye un versátil modelo de lenguaje grande (LLM) general que puede realizar una amplia variedad de tareas, desde generar consultas SQL y código de programación hasta seguir instrucciones complejas.
Una de las características destacadas de Arctic es su perfecta integración con Snowflake Data Cloud. Este estrecho acoplamiento nos permite aprovechar la potencia de la IA directamente en nuestra infraestructura de datos existente, lo que garantiza una experiencia segura y optimizada.
Es importante destacar que todos los modelos de la familia Snowflake Arctic están disponibles con licencia Apache 2.0, lo que nos permite utilizarlos con fines académicos y comerciales.
Snowflake Arctic tiene tres componentes principales:

Componentes de Snowflake Arctic.
La arquitectura de Snowflake Arctic se basa en un diseño de transformador híbrido MoE (Mezcla de expertos) denso, innovación clave que permite un escalabilidad y una adaptabilidad eficientes. Este método aprovecha una vasta red de 480 000 millones de parámetros distribuidos entre 128 expertos especializados, cada uno ajustado para tareas específicas.
Sin embargo, no todos los expertos se activan para cada consulta. Arctic emplea un mecanismo Top-2 gating, por el que selecciona solo los dos expertos más importantes para cada entrada, lo que activa solamente 17 000 millones de parámetros. Esta optimización reduce significativamente el sobrecoste al mismo tiempo que mantiene un rendimiento de primer nivel en una amplia variedad de tareas empresariales.
Snowflake Arctic destaca por las siguientes cuatro características principales:
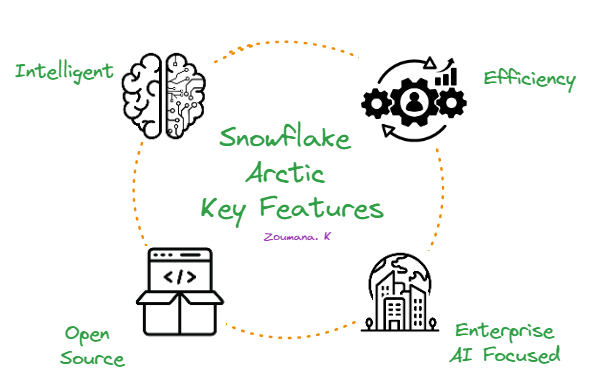
Las cuatro características principales de Snowflake Arctic.
En primer lugar y sobre todo, es extraordinariamente inteligente. Arctic destaca en tareas complejas como generar consultas SQL, escribir código y seguir instrucciones detalladas. En las pruebas comparativas del sector, supera sistemáticamente a modelos similares, lo que demuestra su capacidad para enfrentarse a situaciones reales complejas.
En segundo lugar, Arctic está diseñado para ser eficiente. Su exclusiva arquitectura le permite ofrecer un rendimiento de primer nivel consumiendo menos recursos computacionales. Esto reduce significativamente los costes, por lo que es una opción atractiva para organizaciones de todos los tamaños.
En tercer lugar, Snowflake Arctic adopta el código abierto. Está disponible con licencia Apache 2.0, lo que permite a todo el mundo acceder a su código y a los pesos del modelo.
Por último, Arctic se centra totalmente en la IA empresarial. Está diseñado para satisfacer las necesidades específicas de las empresas ofreciendo resultados de alta calidad en tareas como análisis de datos, automatización de procesos y toma de decisiones.
Para cumplir diversos requisitos de IA empresariales, Snowflake ha presentado dos modelos principales en la familia Snowflake Arctic:
Además de los modelos principales, Snowflake ofrece una familia de cinco modelos de incorporación de texto con licencia Apache 2.0, todos centrados en tareas de recuperación de información. La tabla incluida a continuación muestra el rendimiento de diferentes modelos de Snowflake Arctic en la tarea de recuperación Massive Text Embedding Benchmark (MTEB), medido por NDCG@10.
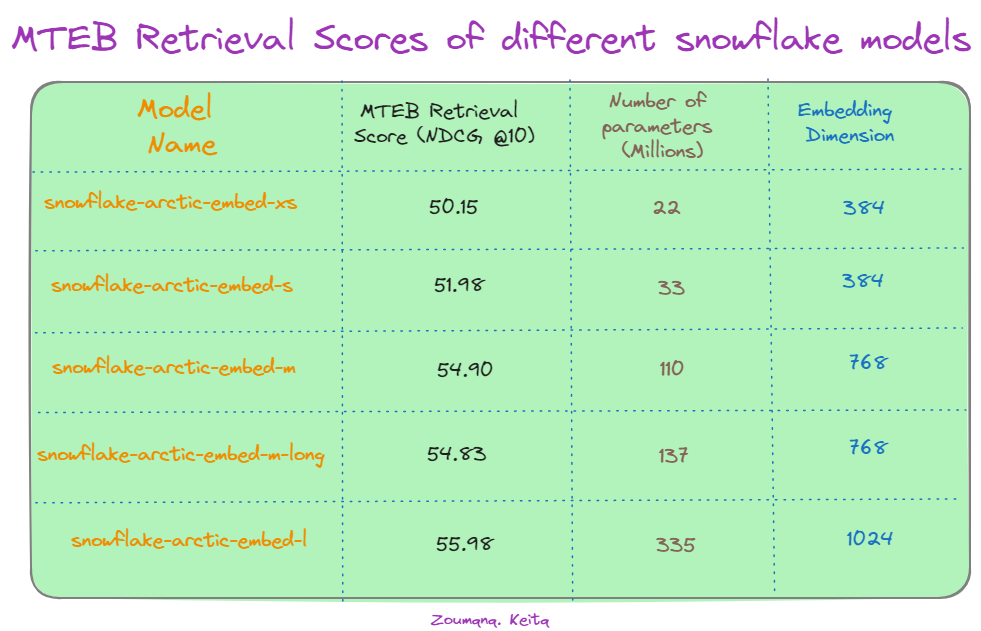
Puntuaciones de recuperación MTEB de diferentes modelos de Snowflake. Fuente: Hugging Face.
En primer lugar, observamos que hay una tendencia general de rendimiento mejorado a medida que aumenta el tamaño del modelo. El mayor modelo, "snowflake-arctic-embed-l", obtiene la puntuación más alta de NDCG@10 (55,98) utilizando 335 millones de parámetros y 1024 dimensiones de incorporación. Esto sugiere que la escala del modelo desempeña un papel importante en la captura de relaciones semánticas intrincadas en datos textuales.
Resulta interesante observar que aumentar la dimensión de incorporación de 384 a 1024 mejora la puntuación del modelo "snowflake-arctic-embed-l", lo que destaca el efecto del tamaño de incorporación en la exactitud de recuperación. Sin embargo, una notable excepción es el modelo "snowflake-arctic-embed-xs". A pesar de tener muchos menos parámetros (22 millones), su rendimiento es comparable al de modelos mayores con la misma dimensión de incorporación, 384. Esto sugiere que la eficiencia del modelo y las optimizaciones del a arquitectura pueden contrarrestar las ventajas de un gran número de parámetros en determinados casos.
Antes de pasar a la implementación técnica, veamos el modelo en acción, realizando diferentes tareas, como la generación de SQL, la programación y el seguimiento de instrucciones.
Con la demo Streamlit de Hugging Face, podemos proporcionar al modelo algunas solicitudes, ajustar los parámetros del modelo y obtener una respuesta.
Demo de Snowflake Arctic.
Primero pidamos al modelo que genere una consulta SQL:
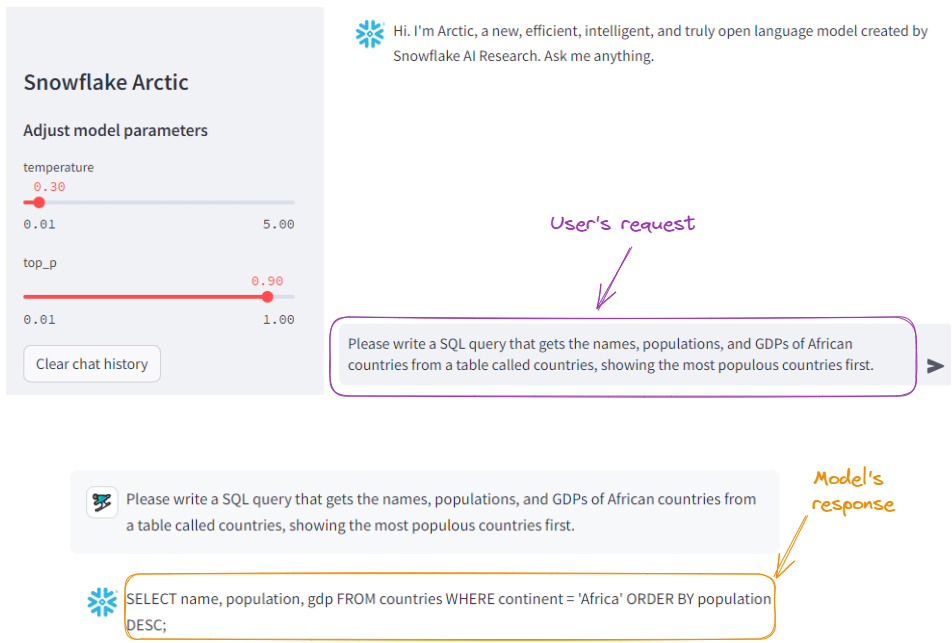
Ejemplo de generación de SQL con Snowflake Arctic.
A efectos comparativos, enviemos la misma solicitud a ChatGPT-4o: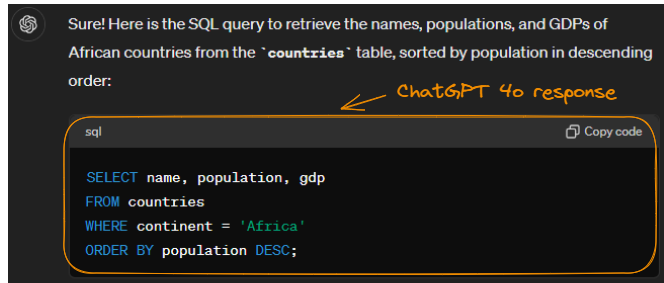
Ejemplo de generación de SQL con ChatGPT-4o.
Observa que ha generado el mismo resultado (con un formato más limpio). Podemos concluir que Arctic hizo un buen trabajo.
Vamos a pedir a Arctic que escriba algo de código Python:

Snowflake Arctic genera código Python.
Proporcionando el mismo prompt a ChatGPT-4o, obtenemos el siguiente resultado, que también es exacto:
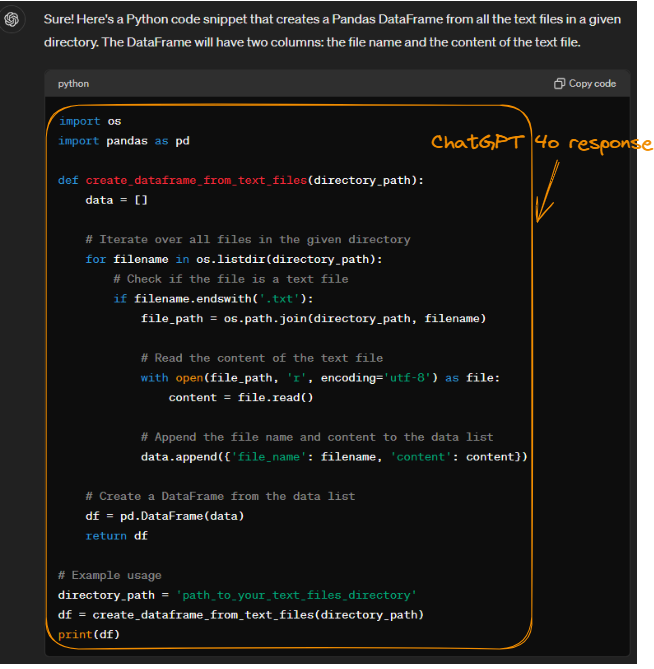
Código Python generado por ChatGPT-4o.
Aunque tanto Arctic como ChatGPT-4o realizan la misma tarea, sus métodos difieren en eficiencia y uso de memoria. Ambos modelos leen eficientemente archivos utilizando os.listdir() y open().
Sin embargo, el método de ChatGPT-4o de crear un DataFrame a partir de una lista de diccionarios puede consumir algo más de memoria que el método de Arctic de utilizar una lista de listas. Esto se debe a que Pandas puede realizar procesamiento adicional para gestionar diccionarios. A pesar de esta pequeña diferencia, la estructura de código modular de ChatGPT-4o mejora la legibilidad y la facilidad de mantenimiento.
Si quieres saber más sobre cómo elegir el LLM adecuado, consulta el tutorial Clasificación de LLM: cómo seleccionar el mejor LLM.
Ahora que conocemos las capacidades del modelo de Snowflake Arctic, centrémonos en acceder a Snowflake Arctic y configurarlo.
El uso de modelos de Arctic consume muchos recursos, por lo que utilizaremos el menor de los modelos de la familia Arctic, snowflake-arctic-embed-xs, que es el que menos recursos computacionales consume.
A continuación, vemos las características del entorno que utilizamos para este tutorial. Mostramos las características ejecutando el comando nvidia-smi:
!nvidia-smi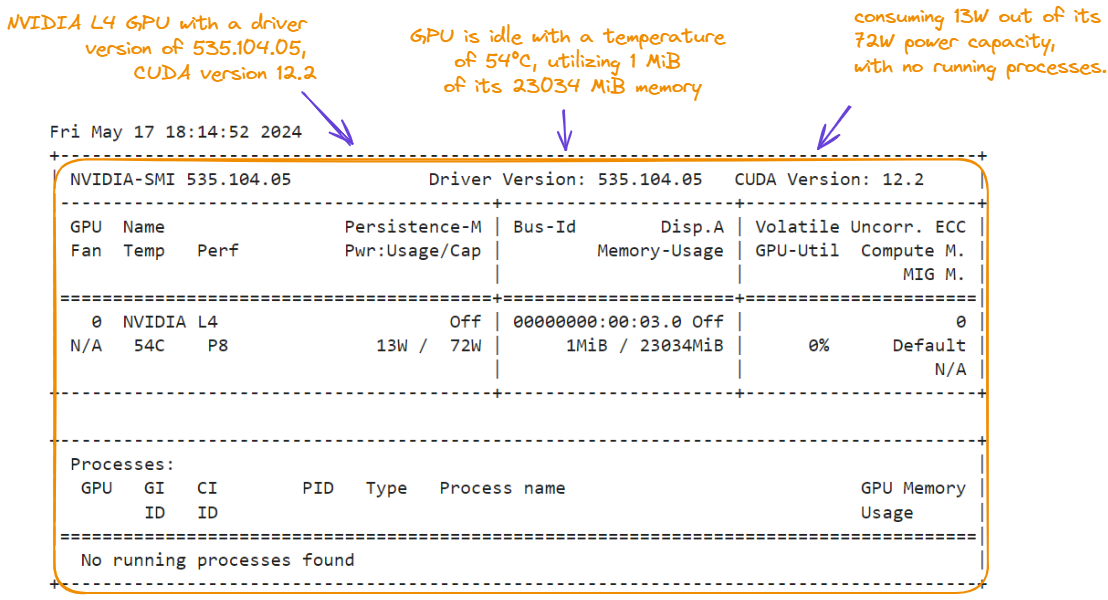
Características de la GPU para el tutorial Snowflake Arctic.
Además de la GPU NVIDIA L4, el entorno tiene las siguientes características, que pueden consultarse en la sección Recursos:
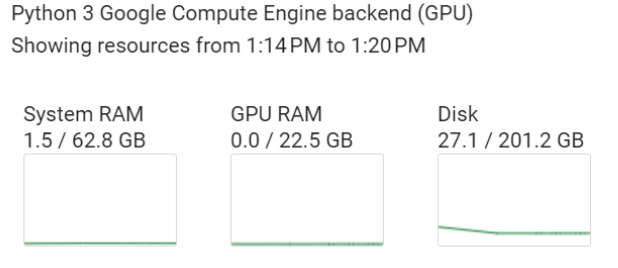
Características de backend del motor de cálculo.
Para este tutorial práctico se necesitan dos bibliotecas principales: torch y transformers (ejecutamos el código a continuación desde un notebook):
%%bash
pip -qqq install transformers>=4.39.0
pip -qqq install torchA continuación, importamos las subbibliotecas necesarias:
import torch
from transformers import AutoTokenizer, AutoModel
from torch.nn.functional import cosine_similarityContinuemos cargando el modelo de incorporación snowflake-arctic-embed-xs y su correspondiente tokenizador:
model_checkpoint = "Snowflake/snowflake-arctic-embed-xs"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint, add_pooling_layer=False)Cargamos el modelo preentrenado especificado por model_checkpoint sin una capa de agrupamiento adicional, que se utiliza para reducir la dimensionalidad del resultado del modelo.
Con todos los requisitos cumplidos, el caso de uso principal de esta sección es buscar los N documentos más similares a un documento dado, junto con sus puntuaciones de similitud coseno. Para ello, damos estos cinco pasos principales:
Búsqueda de similitud de documentos con Snowflake Arctic.
Podemos implementar los pasos anteriores utilizando las siguientes funciones de ayuda: generate_embedding() y find_similar_documents().
def generate_embedding(document):
inputs = tokenizer(document, padding=True, truncation=True,
return_tensors='pt', max_length=512)
embedding = model(**inputs)[0][:, 0]
return embedding
def find_similar_documents(query_document, document_embeddings , top_n=5):
query_embedding = generate_embedding(query_document)
similarity_scores = [cosine_similarity(query_embedding,
doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores),
descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scoresLa función generate_embedding() toma un documento y una entrada y genera su incorporación. find_similar_documents() recibe un documento de consulta, las incorporaciones de los documentos existentes y el número de documentos similares que deben devolverse.
Para simplificar, utilizaremos cinco ejemplos sencillos:
documents = [
"This is a tutorial about Snowflake Arctic Embedding models",
"Arctic-embed is a state-of-the-art text embedding model.",
"Snowflake provides various cloud data warehousing solutions.",
"Embedding models are used for representing text as dense vectors.",
"The Arctic-embed model is based on the transformer architecture."
]A continuación, generamos las incorporaciones:
document_embeddings = [generate_embedding(doc) for doc in documents]Seleccionemos "What is the Arctic-embed model?" como documento de consulta y busquemos documentos similares:
query_document = "What is the Arctic-embed model?"
top_documents, top_scores = find_similar_documents(query_document, document_embeddings)Por último, realizamos un bucle entre todos los documentos principales para imprimir el contenido del documento y su puntuación de similitud con el documento de consulta.
print("Query Document:")
print(query_document)
print("\nTop Similar Documents:")
for doc, score in zip(top_documents, top_scores):
print(f"Document: {doc}")
print(f"Similarity Score: {score:.4f}")
print()
El segundo documento es el más similar porque tiene la mayor puntuación de similitud coseno (94,99 %).
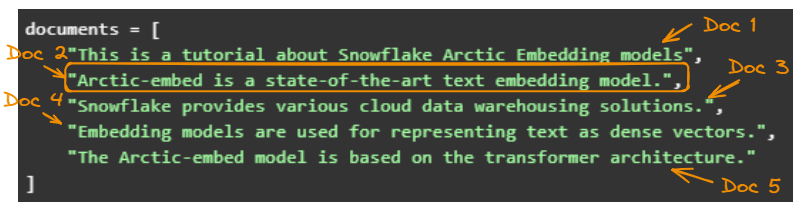
Los cinco documentos originales.
Cuando visualizamos los documentos en un espacio 3D, podemos ver los documentos que son más parecidos.
Las incorporaciones originales tienen 512 dimensiones, lo que es imposible de visualizar. La forma más sencilla es reducir las dimensiones mediante el análisis de componentes principales (PCA). Si quieres aprender más sobre PCA, consulta el tutorial Análisis de componentes principales (PCA) en Python.
Antes de utilizar el PCA, tenemos que modificar la función find_similar_documents() para que devuelva las incorporaciones de documento que utilizará el PCA.
def find_similar_documents(query_document, documents, top_n=5):
query_embedding = generate_embedding(query_document)
document_embeddings = [generate_embedding(doc) for doc in documents]
similarity_scores = [cosine_similarity(query_embedding, doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores), descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scores, document_embeddingsTambién importamos algunos módulos necesarios para generar la visualización.
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3DAhora vamos a crear la visualización 3D haciendo lo siguiente:
top_documents, top_scores, document_embeddings = find_similar_documents(query_document, documents)
# Reshape the embeddings
reshaped_embeddings = torch.stack(document_embeddings).detach().numpy()
reshaped_embeddings = reshaped_embeddings.reshape(reshaped_embeddings.shape[0], -1)
# Apply PCA to reduce the embeddings to 3 dimensions
pca = PCA(n_components=3)
reduced_embeddings = pca.fit_transform(reshaped_embeddings)
# Create a 3D plot
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# Plot the document embeddings
for i, doc in enumerate(documents):
ax.scatter(reduced_embeddings[i, 0], reduced_embeddings[i, 1], reduced_embeddings[i, 2], marker='o', label=f"Document {i+1}")
# Plot the query document embedding
query_embedding = generate_embedding(query_document)
reshaped_query_embedding = query_embedding.detach().numpy().reshape(1, -1)
reduced_query_embedding = pca.transform(reshaped_query_embedding)
ax.scatter(reduced_query_embedding[0, 0], reduced_query_embedding[0, 1],
reduced_query_embedding[0, 2], marker='*', s=100, color='red',
label="Query Document")
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.legend()
plt.title('Document Embeddings in 3D Space')
plt.show()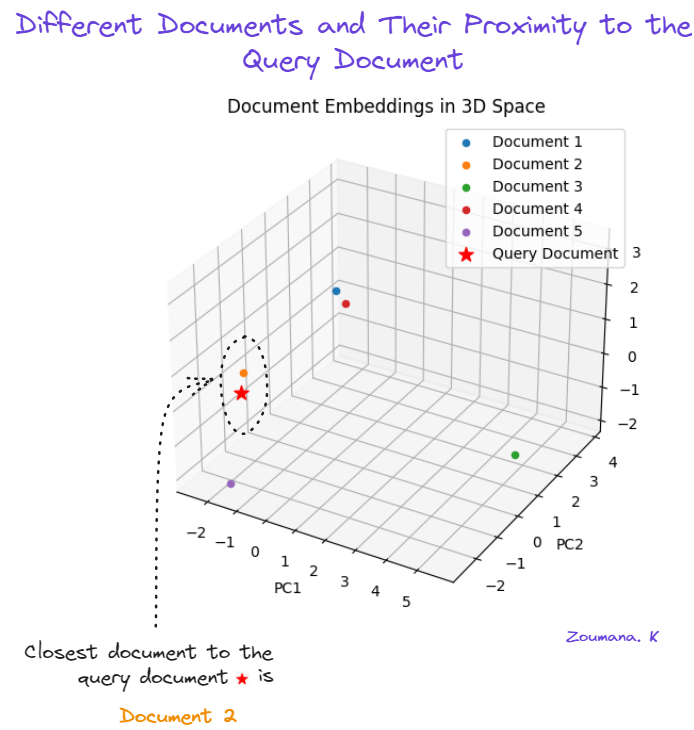
Utilización del PCA para visualizar la similitud entre documentos.
El segundo documento (naranja) es el más parecido al documento de consulta (estrella roja). El quinto documento (morado) es el segundo más parecido, y el tercer documento (verde) es el menos parecido.
Los notebooks son potentes herramientas de experimentación y visualización rápida, por lo que son muy populares entre científicos de datos e investigadores. Sin embargo, los notebooks pueden no ser la opción más adecuada para implementar modelos o aplicaciones en entornos de producción. Aquí es donde entra en juego Streamlit.
Streamlit es una biblioteca de Python que facilita el desarrollo de aplicaciones web interactivas para proyectos de ciencia de datos y machine learning. Facilita la transformación de proyectos de ciencia de datos en aplicaciones listas para la producción sin amplios conocimientos de desarrollo web.
A continuación se muestra la página de inicio de lo que vamos a construir en esta sección.
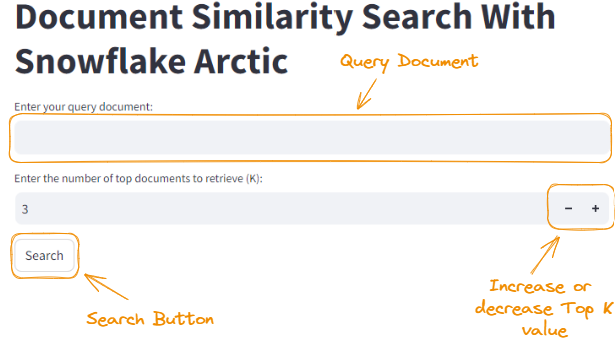
La página de inicio de la aplicación Streamlit.
Enseñar Streamlit está fuera del alcance de este tutorial, pero puedes aprenderlo desde cero en Tutorial de Python: Streamlit.
En esta sección, exploraremos cómo utilizar Streamlit para crear una aplicación web para nuestro proyecto de búsqueda de similitud de documentos. Para ejecutar una aplicación Streamlit, el código debe estar en un archivo Python (con extensión .py) y ejecutar el siguiente comando en el terminal:
streamlit run app.pySin embargo, el primer paso para utilizar Streamlit es instalarlo con el comando pip:
pip install streamlitEl código que hemos utilizado para crear la aplicación Streamlit es un poco largo, así que tómate tu tiempo para repasarlo. También lo explicaremos después del bloque de código.
import streamlit as st
from transformers import AutoTokenizer, AutoModel
import torch
from torch.nn.functional import cosine_similarity
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
model_checkpoint = "Snowflake/snowflake-arctic-embed-xs"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModel.from_pretrained(model_checkpoint, add_pooling_layer=False)
def generate_embedding(document):
inputs = tokenizer(document, padding=True, truncation=True, return_tensors='pt', max_length=512)
embedding = model(**inputs)[0][:, 0]
return embedding
def find_similar_documents(query_document, documents, top_n=5):
query_embedding = generate_embedding(query_document)
document_embeddings = [generate_embedding(doc) for doc in documents]
similarity_scores = [cosine_similarity(query_embedding, doc_embedding).item() for doc_embedding in document_embeddings]
sorted_indices = torch.argsort(torch.tensor(similarity_scores), descending=True)
top_documents = [documents[idx] for idx in sorted_indices[:top_n]]
top_scores = [similarity_scores[idx] for idx in sorted_indices[:top_n]]
return top_documents, top_scores, document_embeddings
# Sample documents
documents = [
"This is a tutorial about Snowflake Arctic Embedding models",
"Arctic-embed is a state-of-the-art text embedding model.",
"Snowflake provides various cloud data warehousing solutions.",
"Embedding models are used for representing text as dense vectors.",
"The Arctic-embed model is based on the transformer architecture."
]
# Streamlit app
st.title("Document Similarity Search With Snowflake Arctic")
query_document = st.text_input("Enter your query document:")
top_k = st.number_input("Enter the number of top documents to retrieve (K):", min_value=1, value=3, step=1)
if st.button("Search"):
top_documents, top_scores, document_embeddings = find_similar_documents(query_document, documents, top_n=top_k)
st.subheader("Top {} Similar Documents:".format(top_k))
for i, (doc, score) in enumerate(zip(top_documents, top_scores)):
st.write("{}. Document: {}".format(i+1, doc))
st.write(" Similarity Score: {:.4f}".format(score))
# Reshape the embeddings
reshaped_embeddings = torch.stack(document_embeddings).detach().numpy()
reshaped_embeddings = reshaped_embeddings.reshape(reshaped_embeddings.shape[0], -1)
# Apply PCA to reduce the embeddings to 3 dimensions
pca = PCA(n_components=3)
reduced_embeddings = pca.fit_transform(reshaped_embeddings)
# Create a 3D plot
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# Plot the document embeddings
for i, doc in enumerate(documents):
ax.scatter(reduced_embeddings[i, 0], reduced_embeddings[i, 1], reduced_embeddings[i, 2], marker='o', label=f"Document {i+1}")
# Plot the query document embedding
query_embedding = generate_embedding(query_document)
reshaped_query_embedding = query_embedding.detach().numpy().reshape(1, -1)
reduced_query_embedding = pca.transform(reshaped_query_embedding)
ax.scatter(reduced_query_embedding[0, 0], reduced_query_embedding[0, 1], reduced_query_embedding[0, 2], marker='*', s=100, color='red', label="Query Document")
ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.legend()
plt.title('Document Embeddings in 3D Space')
st.pyplot(fig)Usando el código anterior, creamos una aplicación Streamlit llamada "Document Similarity Search With Snowflake Arctic". Hagamos algunas observaciones sobre el código:
st.text_input() y especificar el número de documentos principales que se deben recuperar (K) mediante st.number_input().st.button("Search")), se llama a la función find_similar_documents() con el documento de consulta, la lista de documentos y el valor top_k especificado.st.subheader() y st.write().st.pyplot(fig).La sección Streamlit del código se centra en crear una interfaz de usuario interactiva en la que los usuarios pueden introducir un documento de consulta, especificar el número de documentos más similares que deben recuperarse y ver los resultados junto con una visualización 3D de las incorporaciones de documento.
El código completo del artículo está disponible en Jupyter Notebook.
Podemos iniciar la aplicación con el comando streamlit run app.py, que nos llevará a la página de inicio. Proporcionando el mismo documento de consulta y configurando Top K como 3, obtenemos el siguiente resultado:

Integración de Snowflake Arctic mediante Streamlit.
Cuando se trabaja con modelos de lenguaje grandes como Arctic, es fundamental probar y validar correctamente las configuraciones en nuestro entorno de destino. Esto garantiza un rendimiento y una fiabilidad óptimos. Aquí tienes algunos consejos de configuración que debes tener en cuenta:
Para garantizar un rendimiento óptimo y un funcionamiento sin problemas de Snowflake Arctic, es fundamental seguir las prácticas recomendadas y prepararse para solucionar cualquier posible problema. En esta sección, exploraremos consejos y trucos para mejorar el rendimiento con comparaciones reales e investigación académica.
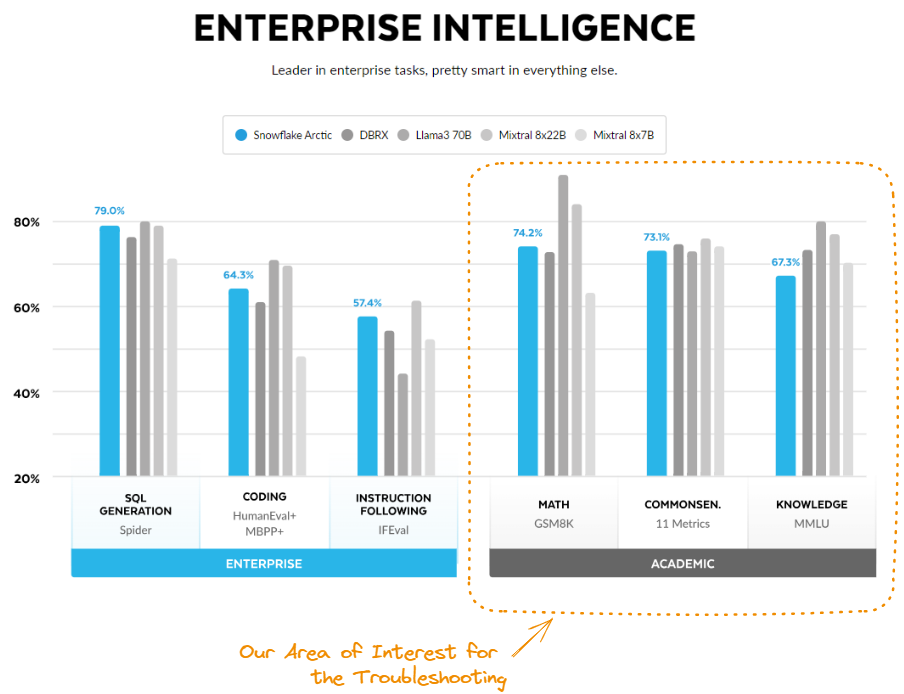
Fuente: Arctic Cloud.
Aquí tienes algunos trucos y consejos para mejorar sus prestaciones:
El rendimiento de Snowflake Arctic destaca tanto en la inferencia como en el entrenamiento. Durante la inferencia, ofrece sistemáticamente una relación rendimiento/coste superior a la de otros modelos. Esta eficiencia mejora a medida que se activan más parámetros, y se mantiene una ventaja significativa incluso con unos 60 000 millones de parámetros activos, con lo que se supera a competidores como Mixral y Llama 3.
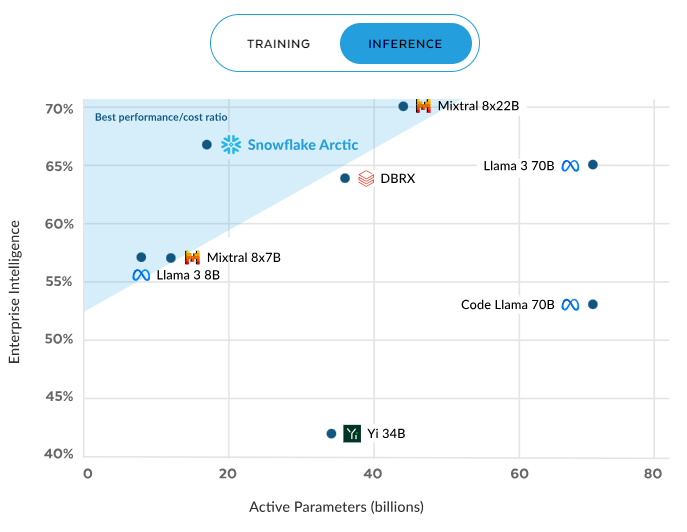
Eficiencia de la inferencia de Arctic. Fuente: Snowflake.com.
La tendencia continúa en el entrenamiento, donde Arctic vuelve a tener la mejor relación rendimiento/coste. Esta eficiencia se incrementa con la computación, y alcanza aproximadamente el 70 % con una computación de 16X, lo que supera con creces a modelos como DBRX, Llama 3, Code Llama y Yi. Estos resultados subrayan la propuesta de valor de Arctic: rendimiento de alta calidad con una parte del coste computacional, por lo que es una opción convincente para las empresas conscientes de los recursos.
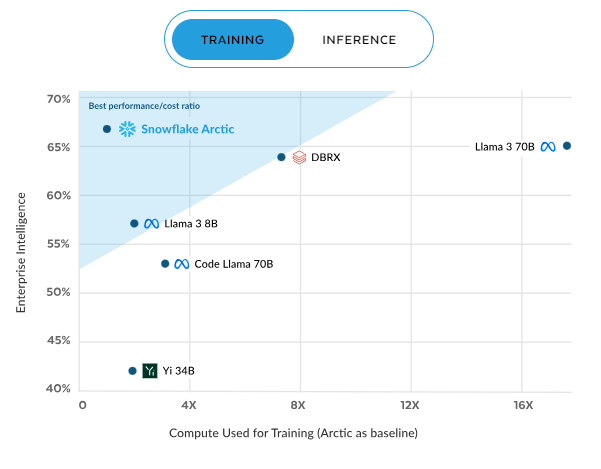
Eficiencia del entrenamiento de Arctic. Fuente: Snowflake.com.
Algunos consejos y trucos para optimizar el rendimiento de la inferencia y el entrenamiento son, entre otros:
Los impresionantes rendimiento y rentabilidad de Snowflake Arctic han establecido un nuevo estándar para los modelos de lenguaje. El desarrollo futuro puede incluir la comprensión avanzada del lenguaje natural y la mejora del aprendizaje multitarea y de la compatibilidad con aplicaciones de dominios específicos. A medida que Snowflake innove, los usuarios pueden esperar herramientas aún más potentes y versátiles.
Snowflake ofrece una gran comunidad y completos recursos de asistencia. Los usuarios pueden conectarse, compartir conocimientos y aprender unos de otros en los foros de la comunidad Snowflake. En el sitio web oficial se ofrecen tutoriales y documentación con todo detalle para ayudar a aprovechar al máximo las características de Snowflake Arctic.
Snowflake Arctic cambia las reglas del juego en el campo de las incorporaciones de texto, pues es una solución potente y eficiente para las empresas que desean aprovechar todo el potencial de sus datos. Su perfecta integración con Snowflake Data Cloud y su arquitectura escalable lo convierten en una opción ideal para las organizaciones que buscan optimizar sus procesos de análisis y recuperación de datos.
A lo largo de esta guía, hemos explorado las principales capacidades de Snowflake Arctic, abarcando desde su instalación y configuración hasta técnicas avanzadas de integración y aplicaciones prácticas. Aprovechando sus funciones avanzadas y sus optimizaciones de rendimiento, las empresas pueden lograr mayores eficiencia y exactitud en sus operaciones de incorporación de texto.
Si quieres aprender más sobre Snowflake, echa un vistazo al tutorial Snowflake para principiantes.
Más información sobre LLM
Curso
Curso
Tutorial
Moez Ali
Tutorial
Duong Vu
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan



