
Cursus
Fondations Snowflake
7 h
Snowflake est une plateforme de données cloud populaire et performante, tandis que Streamlit est un framework Python open source conçu pour créer des applications web de données. Streamlit in Snowflake (SiS) est une solution intégrée qui vous permet de créer et de déployer des applications de données directement dans l'écosystème Snowflake. Au lieu de jongler avec différents outils, vous pouvez utiliser Python et l'infrastructure Snowflake pour créer rapidement des applications interactives.
Ce tutoriel vous présentera Streamlit dans Snowflake, ses principales fonctionnalités, les étapes de configuration, les stratégies de déploiement, la sécurité, des conseils de performance et des cas d'utilisation concrets. À la fin, vous disposerez d'une feuille de route claire pour créer et lancer votre première application de données. Veuillez vous assurer de consulter les fondements de Snowflake et son interface. Je recommande également d'essayer Streamlit en Python en dehors de Snowflake afin de mieux comprendre ses fonctionnalités grâce à ce tutoriel Streamlit.
Streamlit dans Snowflake permet de créer des applications interactives directement connectées à vos données Snowflake sans quitter la plateforme.
Streamlit dans Snowflake combine la simplicité de Streamlit et l'évolutivité de Snowflake. Traditionnellement, la création d'applications nécessitait des serveurs externes, des API et des intégrations complexes. Streamlit réduit les fonctionnalités essentielles à quelques API orientées objet et intégrations Python. Le déploiement est ensuite transféré vers Snowflake à l'aide de Snowsight.
Cela élimine le besoin d'infrastructures supplémentaires et fournit un environnement unifié qui s'intègre parfaitement à Snowpark, Cortex AI et vos données Snowflake. Cela signifie que les développeurs Python et les équipes chargées des données travaillent à partir de la même source, sans avoir à supporter les frais supplémentaires liés au transfert de données ou de code.
En 2022, Snowflake a acquis Streamlit afin de rapprocher le développement d'applications interactives des données d'entreprise. Il perpétue la vision open source de Streamlit, qui consiste à offrir aux développeurs la possibilité d'utiliser Python pour créer de superbes applications web tout en s'intégrant à l'une des plateformes de données les plus puissantes actuellement disponibles. Il permet aux entreprises d'utiliser Streamlit de manière flexible avec moins de préoccupations en matière de sécurité et unifie le développement d'applications.
La philosophie de SiS consiste à maintenir le même niveau de sécurité et de gouvernance que celui que vous attendez de Snowflake, tout en offrant la facilité d'utilisation de Streamlit pour créer des applications web de données. Étant donné que toutes les données restent dans Snowflake, vous bénéficiez des mêmes garanties de sécurité et de sûreté que celles auxquelles vous vous attendez.
Le principal avantage réside dans le fait que l'accent est mis sur le maintien du framework Python et sur la garantie d'une expérience similaire sur Snowflake et hors Snowflake. Cela devrait rendre SiS accessible aux développeurs qui ont déjà travaillé avec Streamlit ou même à ceux qui ont une expérience de Python et qui souhaitent mettre à profit leurs compétences existantes pour créer des applications web pour les données Snowflake.
Streamlit dans Snowflake conserve les fonctionnalités cloud clés de Snowflake, telles que la gestion complète et la collaboration simplifiée. Il intègre également les fonctionnalités de visualisation et d'itération rapide de Streamlit tout en étant intégré à l'infrastructure.
Snowflake gère toute l'infrastructure en arrière-plan, ce qui signifie que vous n'avez jamais à vous soucier des serveurs, de la mise à l'échelle ou de la stabilité. Les applications fonctionnent avec une interactivité en temps réel, s'adaptent automatiquement en fonction de l'utilisation et bénéficient de la fiabilité intégrée de Snowflake.
Les applications Streamlit intégrées à Snowflake se connectent de manière native à Snowpark, Cortex AI et aux bases de données. Par exemple, vous pouvez intégrer Cortex AI Analyst à votre application Streamlit, ce qui permet aux utilisateurs de poser des questions en langage naturel sur les données et d'obtenir des réponses directement dans le tableau de bord.
D'autres fonctionnalités de Snowflake, telles que la mise en cache intégrée, minimisent les requêtes redondantes, tandis que les améliorations de l'interface utilisateur, telles que le mode sombre et les composants personnalisés, optimisent l'expérience utilisateur. L'authentification et les connexions sécurisées sont gérées automatiquement via les protocoles d'authentification de Snowflake. La sensibilité des données peut être gérée à l'aide des contrôles basés sur les rôles de Snowflake.
Cela simplifie la gestion des données et permet aux développeurs de se concentrer sur la création d'outils.
L'un des principaux atouts de Streamlit réside dans sa capacité à transformer un script Python simple en une application interactive en quelques minutes. Dans Snowflake, vous pouvez prévisualiser et itérer directement sur les applications, mettre à jour le code et voir les résultats en temps réel sans attendre de longs déploiements.
Les applications Streamlit peuvent être partagées directement avec les utilisateurs au sein de Snowflake. Cela facilite le partage de l'application avec différentes équipes en utilisant des rôles ou des membres individuels. La collaboration est intégrée au flux de travail, ce qui permet à plusieurs membres de l'équipe de travailler, de tester et de déployer des applications ensemble.
La prise en main de SiS est simple, et vous pouvez créer votre première application en quelques minutes. Nous devons simplement nous assurer que vous disposez des autorisations et des connaissances nécessaires.
Pour créer une application Streamlit dans Snowflake, il est nécessaire de disposer d'un compte Snowflake actif avec accès à Snowsight, l'interface Web. Cette présentation de Snowflake peut vous aider à vous familiariser avec Snowsight. Il est recommandé d'avoir des connaissances de base en Python. Il pourrait même être utile de revoir cette cours d'introduction à Python afin de rafraîchir vos connaissances.
Une fois que vous avez accès à Snowflake, veuillez vous assurer que vous disposez des autorisations suivantes :
USAGEUSAGE, CREATE STREAMLIT, CREATE STAGEVeuillez commencer par vous connecter à Snowsight et sélectionner ou créer une base de données et un schéma où votre application sera hébergée. Veuillez commencer par vous rendre sur My Workspace et ouvrir un nouveau fichier SQL. Créons un rôle appelé « streamlit_creator » qui aura accès à notre « streamlit_schema » sur notre « streamlit_database ». De plus, nous allons créer un entrepôt appelé streamlit_wh qui constituera la principale source de calcul pour notre application Streamlit.
CREATE ROLE streamlit_creator;
CREATE DATABASE streamlit_db;
USE DATABASE streamlit_db;
CREATE SCHEMA streamlit_schema;
CREATE WAREHOUSE streamlit_wh WITH WAREHOUSE_SIZE = ‘XSMALL’;
GRANT USAGE ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;
GRANT USAGE ON DATABASE streamlit_db TO ROLE streamlit_creator;
GRANT USAGE ON WAREHOUSE streamlit_wh TO ROLE streamlit_creator;
GRANT CREATE STREAMLIT ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;
GRANT CREATE STAGE ON SCHEMA streamlit_db.streamlit_schema TO ROLE streamlit_creator;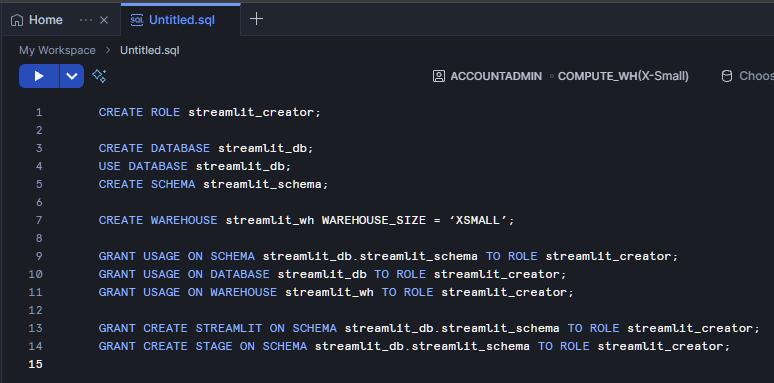
Pour illustrer cela, examinons une application simple. Une fois votre compte Snowflake et vos autorisations configurés, veuillez vous rendre sur Snowsight, puis cliquez sur « PROJECTS » (Gestionnaire de données) >> « Streamlit » (Gestionnaire de données). Dans cette fenêtre, veuillez cliquer sur « + Streamlit App » (Ajouter un nouveau compte) en haut à droite.
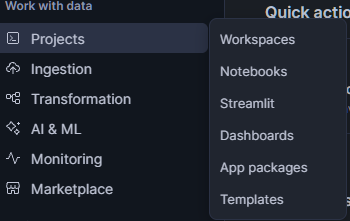
Veuillez saisir le nom de l'application de votre choix. Veuillez mettre à jour l'emplacement de l'application afin d'utiliser STREAMLIT_DB et STREAMLIT_SCHEMA. App WarehouseVeuillez ensuite sélectionner « Exécuter sur l'entrepôt », puis choisir « STREAMLIT_WH » comme emplacement de stockage.
Cela ouvre l'éditeur. Il est fourni par défaut avec un petit script. Il lancera également automatiquement l'application et vous présentera un aperçu.
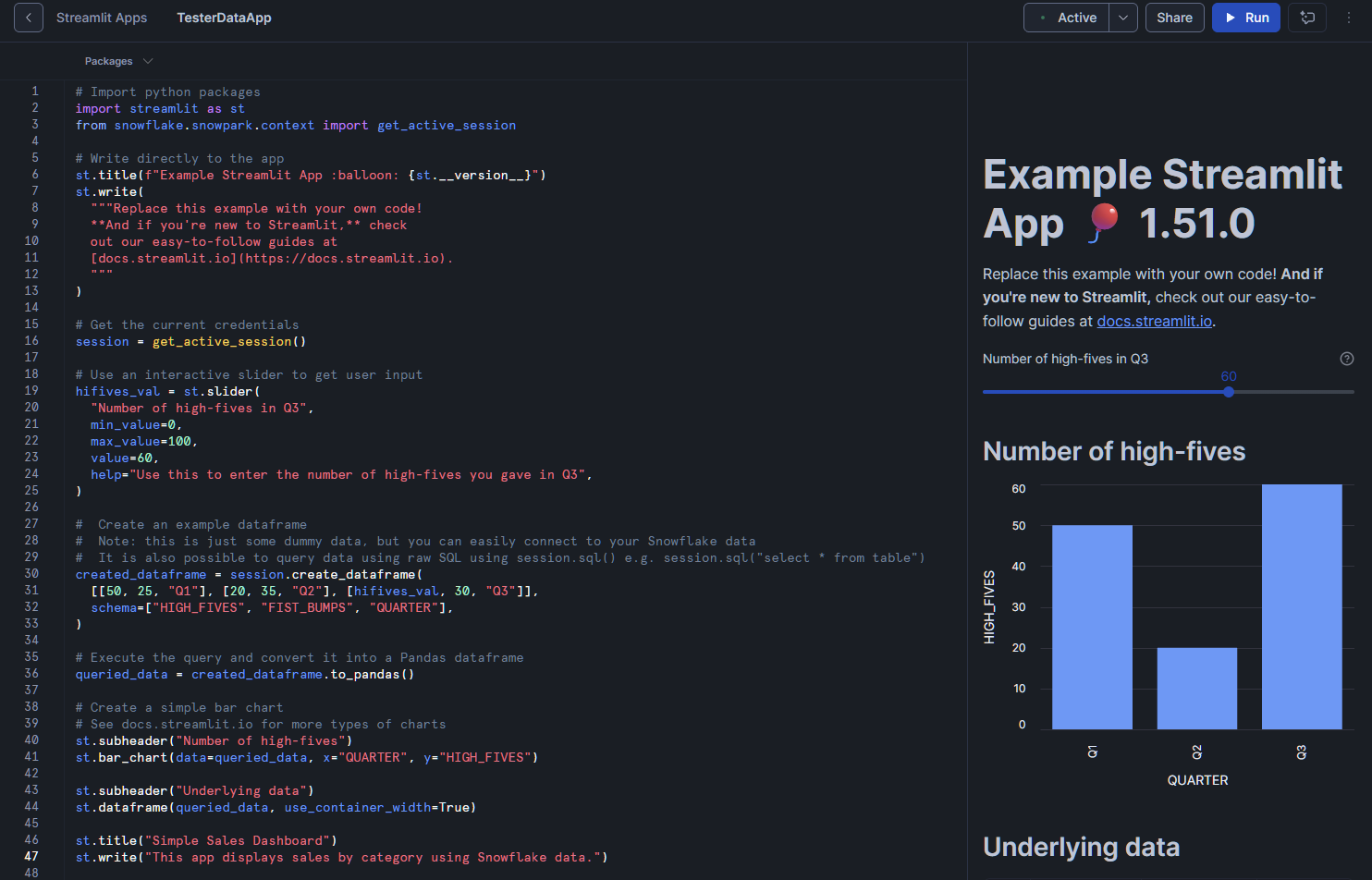
Nous allons tenter d'ajouter quelques-unes de nos propres données pertinentes à l'application. Veuillez insérer ce petit extrait au bas de notre code existant :
from snowflake.snowpark.functions import sum as sf_sum
st.title("Simple Sales Dashboard")
st.write("This app displays sales by part using Snowflake data.")
# Query sample dataset
df = (
session.table("SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.LINEITEM")
.group_by("L_PARTKEY")
.agg(sf_sum("L_QUANTITY").alias("TOTAL_SALES"))
.limit(10)
.order_by("TOTAL_SALES", ascending=False)
.to_pandas()
)
# Plot chart
st.bar_chart(data=df, x="L_PARTKEY", y="TOTAL_SALES")
# Show table
st.dataframe(df)
Veuillez ensuite cliquer sur le bouton « Exécuter » situé en haut à droite. L'aperçu dans cette application mettra à jour et traitera les données fournies par le tableau d'exemple. Il devrait afficher à la fois un tableau de données et un graphique à barres. À partir de là, vous pouvez personnaliser les requêtes, ajouter des filtres ou améliorer l'interface utilisateur à l'aide des widgets Streamlit.
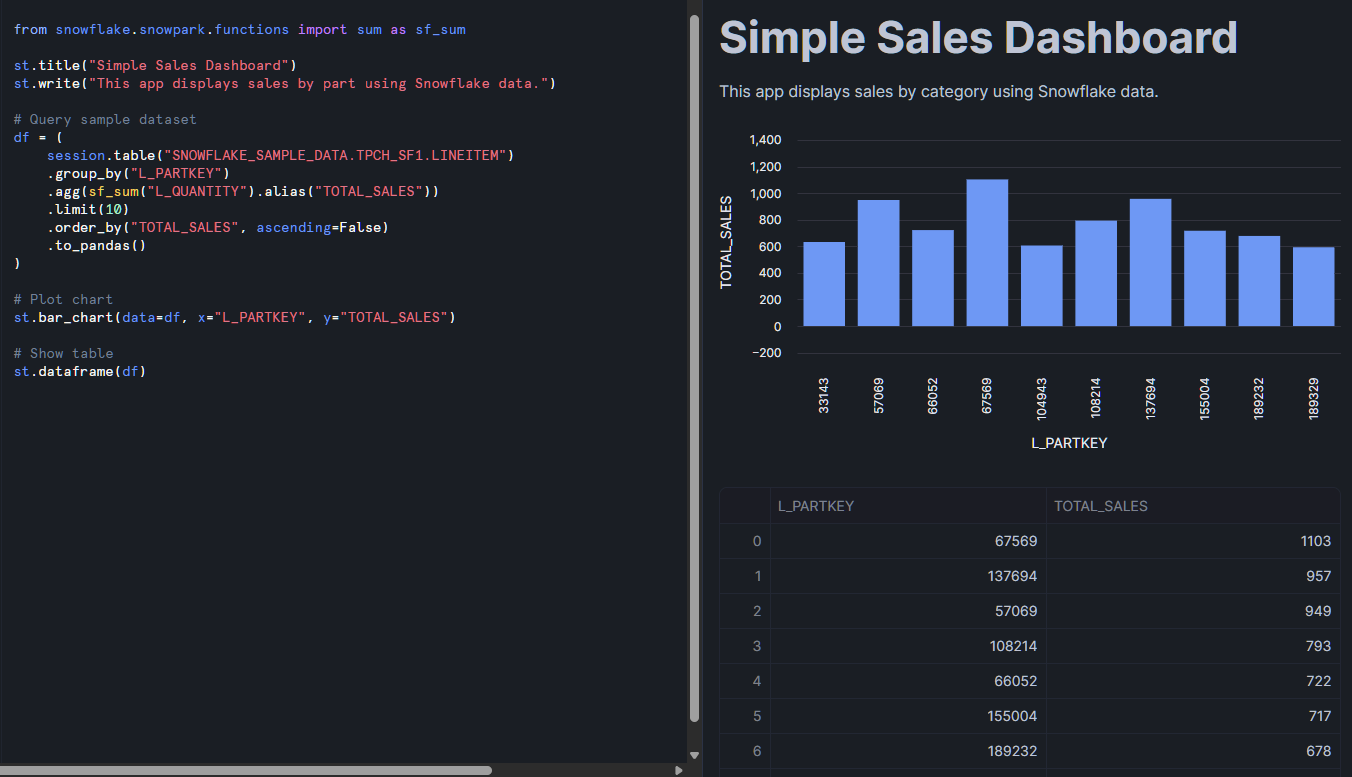
Ce que vous remarquerez ici, c'est l'utilisation de Snowpark. Si vous ne l'avez pas encore utilisé, Snowpark est la bibliothèque de Snowflake qui vous permet de traiter les données Snowflake à l'aide de langages de programmation tels que Python. Je recommande vivement cette introduction à Snowpark, car l'importation de données dans Streamlit nécessite souvent l'utilisation de Snowpark pour interagir avec vos bases de données Snowflake.
Il existe plusieurs méthodes pour déployer Streamlit dans Snowflake. La méthode la plus simple consiste à utiliser Snowsight, l'interface Web, mais vous pouvez également utiliser des outils d'interface de ligne de commande (CLI). De plus, vous pouvez intégrer des outils de workflow pour faciliter l'organisation de vos projets et l'évolutivité de votre déploiement.
Comme indiqué dans la section précédente, la méthode la plus simple consiste à utiliser Snowsight, l'interface Web de Snowflake. Le bonus supplémentaire ici est l'affichage en écran partagé qui permet de modifier et de prévisualiser votre application en temps réel. Cette configuration est particulièrement adaptée aux développeurs qui souhaitent obtenir un retour immédiat pendant qu'ils développent.
Pour les scénarios plus avancés, les outils CLI vous permettent de déployer des applications par programmation. Cela est particulièrement utile lors de l'intégration du déploiement d'applications dans des pipelines d'intégration continue et de livraison continue (CI/CD). En adoptant une approche de développement plus structurée, les applications peuvent être stockées dans des dossiers de projet sous forme de fichiers .py, comme les applications Streamlit classiques, aux côtés des fichiers .yml qui contrôlent tout environnement et les commandes Snowflake. Cela signifie que nous pouvons utiliser GitHub pour suivre les modifications, effectuer des vérifications automatisées et déployer de manière transparente.
Une autre option consiste à associer les applications Streamlit à des outils de workflow tels que dbt (data build tool), que Snowflake prend naturellement en charge. Par exemple, dbt peut gérer votre flux ETL principal qui alimente votre application Streamlit. Au sein d'un même projet dbt, vous pouvez redéployer automatiquement Streamlit selon vos besoins afin de l'adapter à votre flux de travail dbt. Cela vous permet d'organiser de manière claire des flux de données complexes en projets et d'adapter votre déploiement à votre flux de travail.
Examinons comment Streamlit dans Snowflake fonctionne concrètement.
Les applications Streamlit dans Snowflake fonctionnent dans un environnement sécurisé basé sur des conteneurs, entièrement géré par Snowflake. Cette conception garantit que les applications restent isolées tout en maintenant une connexion sécurisée aux sources de données et aux services Snowflake. À mesure que la complexité de votre application augmente ou que la taille de vos bases de données s'accroît, Snowflake gère la mise à l'échelle en arrière-plan.
Lorsque vous lancez une application, celle-ci utilise les ressources informatiques de votre entrepôt configuré. Tout comme vos requêtes SQL, la taille de l'entrepôt influe à la fois sur les performances et les coûts. Il est donc essentiel de planifier les ressources. Les développeurs trouvent utile de disposer d'un entrepôt lié à leurs applications Streamlit afin de simplifier le suivi. De plus, Snowflake utilise des étapes internes pour le stockage sécurisé des fichiers, ce qui empêche les fuites de données en dehors de la plateforme. Cela simplifie l'intégration des données dans votre application tout en garantissant la sécurité de vos données.
Les environnements Python dans SiS sont gérés et contrôlés pour des raisons de sécurité. Seuls les paquets approuvés sont disponibles, et l'installation de paquets externes est restreinte. De plus, certains éléments tels que les scripts, les styles, les polices et l'intégration d'iframes sont limités pour des raisons de sécurité. Si vous avez besoin de fonctionnalités qui ne sont pas fournies, il peut être nécessaire de les implémenter via les UDF Snowpark ou de vous appuyer sur les bibliothèques Python existantes prises en charge par Snowflake.
Heureusement, SiS utilise une grande partie de l'infrastructure de sécurité existante de Snowflake, telle que le contrôle d'accès basé sur les rôles, le partage et la sécurité réseau.
Snowflake utilise un système de contrôle d'accès basé sur les rôles (RBAC) pour les applications Streamlit et leurs données. L'accès aux données nécessite le privilège d'USAGE e pour toute application Streamlit et ses données sous-jacentes. Seuls les rôles disposant des privilèges d'CREATE STREAMLIT e peuvent créer des applications, et la propriété des applications est liée aux autorisations au niveau du schéma. Cela garantit un contrôle clair sur les personnes autorisées à développer et à gérer les applications.
Le partage d'applications est également contrôlé. Vous pouvez autoriser ou restreindre l'accès aux applications en fonction des rôles des utilisateurs. Pour l'exécution SQL, les autorisations basées sur les rôles s'appliquent également. Il exécute SQL via l'application Streamlit et ne permet pas aux développeurs d'exécuter des requêtes SQL sur des bases de données sans autorisations appropriées.
Du côté réseau, Snowflake applique des politiques de sécurité du contenu (CSP) rigoureuses. Ces mesures empêchent les applications de charger des scripts, des styles ou des ressources externes non autorisés, réduisant ainsi le risque d'exfiltration de données ou d'intégrations non sécurisées. En minimisant le nombre de bibliothèques externes importées dans l'environnement, cela réduit le risque de failles de sécurité et protège la confidentialité des données et de l'utilisateur.
À mesure que votre application gagne en complexité, il est essentiel de procéder à une optimisation adéquate afin de garantir son bon fonctionnement.
La création d'applications efficaces nécessite une attention particulière aux requêtes et aux ressources informatiques. Il est recommandé de tester vos requêtes en dehors de votre application Streamlit (sur un entrepôt similaire) afin de comprendre l'effort de calcul nécessaire à votre requête. Il est essentiel de rédiger des requêtes SQL optimisées afin d'éviter les goulots d'étranglement.
Les fonctions de mise en cache intégrées à Streamlit st.cache_data et st.cache_resource contribuent à réduire les calculs répétés et le rechargement des données. Il convient toutefois de noter que les protocoles st.cache_data et st.cache_resource ne sont pas entièrement pris en charge. Ils ne permettent que la mise en cache basée sur la session, ce qui signifie que chaque fois que l'utilisateur ouvre une nouvelle session, la requête et les données doivent être rechargées. Veuillez garder cela à l'esprit et optimiser vos requêtes autant que possible.
La sélection de l'entrepôt joue un rôle important dans la réactivité des applications. Les entrepôts plus spacieux améliorent la rapidité, mais augmentent également les coûts. Pour les applications à fort trafic, les entrepôts dédiés peuvent constituer la meilleure solution. D'autre part, les applications légères peuvent souvent fonctionner sur des entrepôts plus petits sans problèmes de performances.
L'architecture des applications est également importante. Le chargement progressif des données et la gestion de l'état peuvent améliorer la réactivité des applications, en particulier lors du traitement de grands ensembles de données. Si votre application comporte plusieurs composants, veuillez éviter de la charger en une seule fois. Veuillez ne charger que ce dont l'utilisateur a besoin à un moment donné. Concevoir des applications en tenant compte des contraintes en matière de ressources permet d'éviter des problèmes tels que le dépassement de la taille des messages ou des limites de mémoire.
Au-delà des simples tableaux de bord et applications de données, Streamlit dans Snowflake peut exploiter des outils puissants pour l'apprentissage automatique, l'IA, la veille économique et le traitement du langage naturel. Veuillez considérer quelques cas d'utilisation.
Pour les équipes d'analyse, Streamlit dans Snowflake constitue un moyen de créer des tableaux de bord interactifs et des outils de reporting. La connexion à vos bases de données Snowflake permet des mises à jour en temps réel des tableaux de bord pour une prise de décision plus efficace. Vous pouvez déployer rapidement et facilement des applications similaires destinées à différents services et équipes. Parmi les exemples, on peut citer les outils de suivi des stocks, les tableaux de bord d'utilisation des ressources informatiques ou les résumés de performance des cadres. Par exemple, nous pouvons développer des analyses de centre d'appels avec l'intégration de Snowflake Cortex et Snowpark dans l'application Streamlit en utilisant les transcriptions des données d'appels et en générant des analyses sur les appels.
Afin de tirer pleinement parti de vos données, les applications Streamlit peuvent être conçues pour le machine learning et les informations issues de l'intelligence artificielle. Par exemple, les équipes chargées de l'apprentissage automatique peuvent déployer des applications interactives qui fournissent des modèles pour la prévision de la demande, la segmentation de la clientèle ou la détection des anomalies. Grâce à Cortex AI, les développeurs peuvent également créer des applications de génération augmentée par la recherche (RAG) ou des outils d'IA conversationnelle. Une excellente implémentation ajoute des modèles PyTorch qui proposent des ventes incitatives ciblées aux clients en fonction de leur profil individuel, le tout intégrées dans une application d'inférence visuelle.
Pour obtenir des informations sur les commentaires textuels tels que les chats et les e-mails, le traitement du langage naturel est la solution idéale. En utilisant des bibliothèques telles que spaCy, NLTK ou le traitement de texte interne de Snowflake , nous pouvons exploiter toutes ces informations textuelles et développer des outils pour l'analyse des sentiments, la reconnaissance d'entités nommées et d'autres solutions de, nous pouvons exploiter toutes ces informations textuelles et créer des outils d'analyse des sentiments, de reconnaissance des entités nommées et d'autres solutions de traitement du langage naturel. Par exemple, nous pouvons utiliser Snowflake Cortex pour traiter la majeure partie de l'analyse NLP, telle que la synthèse et l'analyse des sentiments. Ces informations sont ensuite transmises à une base de données qui fournit des analyses sur les avis et le chat d'assistance à l'aide de Streamlit dans Snowflake.
Les applications Streamlit sont également efficaces pour la collecte de données et la gestion de la qualité, par exemple les outils d'annotation ou les interfaces de saisie collaborative. Bien que le téléchargement de données soit limité à 200 Mo, nous pouvons fournir un espace où les utilisateurs peuvent potentiellement télécharger de petits ensembles de données ou des documents à des fins de traitement ou de synthèse dans notre application. Les possibilités sont infinies.
La présence de Streamlit dans Snowflake est particulièrement avantageuse en raison des nombreuses intégrations disponibles au sein de l'écosystème, telles que Snowpark et le partage de données.
Snowpark facilite considérablement l'analyse dans Python avec Snowflake. Il permet un traitement avancé des données, des calculs distribués et des fonctions personnalisées. Étant donné que nous pouvons utiliser les DataFrames Snowpark de manière native dans notre application Streamlit dans Snowflake, nous pouvons facilement en tirer parti avec très peu de frais généraux. L'utilisation de procédures stockées et de fonctions définies par l'utilisateur (UDF) dans votre environnement Snowflake devient très simple grâce à l'objet Snowpark « udf».
Le partage de données au sein de Snowflake est simple et, grâce à l'interface utilisateur Snowsight, ne nécessite que quelques clics. En ajoutant des tâches Snowflake et des fonctionnalités événementielles, les développeurs peuvent également automatiser facilement les flux de travail. Par exemple, vous pouvez déclencher des mises à jour de l'application lorsque de nouvelles données arrivent, effectuer des vérifications pour vous assurer que tout fonctionne correctement et maintenir les données à jour.
En combinaison avec dbt, vous pouvez créer des workflows de bout en bout où les transformations de données sont directement intégrées dans les applications Streamlit, garantissant ainsi des mises à jour en temps réel pour les utilisateurs.
Comme pour toutes les plateformes cloud, les considérations relatives à la facturation et aux coûts sont importantes. Une application Streamlit coûteuse est moins susceptible d'être utilisée. Il est donc important de réfléchir à l'avance aux coûts afin de garantir un processus de développement fluide.
Les coûts liés à Streamlit dans Snowflake sont identiques à ceux de tout autre processus dans Snowflake. Si vous disposez d'une base de données/d'un schéma spécifique pour Streamlit, vous devrez supporter les coûts de stockage habituels associés à ces données. Comme nous l'avons mentionné précédemment, il est probable que vous souhaitiez créer un entrepôt spécifiquement dédié à vos services Streamlit dans Snowflake afin de pouvoir également suivre les coûts de calcul. La taille des entrepôts, la concurrence des applications (sessions multi-utilisateurs) et le volume de données constitueront les principaux facteurs déterminants de vos coûts.
Afin de contrôler les dépenses, il est essentiel de redimensionner les entrepôts. Les petites applications avec des charges de travail légères devraient éviter d'utiliser des entrepôts inutilement volumineux. La mise en cache Streamlit contribue à minimiser les requêtes répétées au cours des sessions, ce qui réduit l'utilisation des ressources informatiques. Snowflake fournit également des outils de surveillance qui suivent la consommation afin que vous puissiez procéder à des ajustements de coûts basés sur les données.
Bien que Streamlit dans Snowflake soit puissant, il existe quelques restrictions à prendre en compte, notamment en ce qui concerne les packages externes et les téléchargements de fichiers.
La plateforme applique des politiques de sécurité strictes en matière de contenu afin de garantir la sécurité des données. Les éléments tels que les scripts personnalisés, les styles et tout ce qui nécessite un domaine externe sont plus susceptibles d'être bloqués. Veuillez vous assurer que les composants que vous utilisez ne nécessitent pas d'appels externes. Cela améliore considérablement la sécurité de votre application, mais limite certaines des possibilités de personnalisation auxquelles vous êtes habitué si vous venez de vos propres implémentations Streamlit.
La gestion de grands ensembles de données peut s'avérer difficile en raison de certaines contraintes liées à la mise en cache et au transfert de messages. La principale limitation de la mise en cache réside dans le fait qu'elle est basée sur la session et non sur l'utilisateur. Par conséquent, les utilisateurs qui reviennent sur les applications et commencent de nouvelles sessions devront recharger les données. Veuillez réfléchir attentivement à vos utilisateurs et à la nécessité éventuelle de recommencer plusieurs fois de nouvelles sessions. Si tel est le cas, veuillez réfléchir à la manière dont vous pouvez réduire au minimum le volume de données transférées entre les sessions.
Bien qu'il n'y ait pas de limite explicite quant à la taille des requêtes ou à la quantité de données en mémoire, les messages sont limités à 32 Mo. Cela signifie que l'affichage de grands DataFrames et de cartes extrêmement complexes peut constituer un facteur limitant. Veuillez déterminer ce qui est essentiel de montrer aux utilisateurs et ce qui peut être simplifié.
Le téléchargement de fichiers est possible, mais limité à 200 Mo. Vous ne pourrez pas non plus travailler directement avec des étapes externes et devrez d'abord transférer les données dans Snowflake. Par conséquent, extraire directement depuis Apache Iceberg ne fonctionnera pas, mais extraire depuis un lac de données interne pour ces données est possible.
De plus, la fonctionnalité de téléchargement de fichiers est limitée en taille et les étapes externes ne sont actuellement pas prises en charge, ce qui restreint la manière dont les applications gèrent les fichiers.
Streamlit dans Snowflake offre un moyen puissant et intégré de créer et de déployer des applications de données interactives sans quitter votre environnement Snowflake. Il combine sécurité, évolutivité et facilité d'utilisation tout en prenant en charge des intégrations avancées avec Snowpark, Cortex AI et dbt.
Bien qu'il existe certaines limitations, telles que des restrictions sur les ressources externes et les téléchargements de fichiers, les avantages liés à l'itération rapide, à l'infrastructure gérée et au partage transparent font de SiS une plateforme transformatrice pour les équipes chargées des données. Les praticiens débutants peuvent commencer modestement, en expérimentant avec des tableaux de bord simples, puis passer à des applications d'IA et d'analyse adaptées aux entreprises. Pour plus d'informations sur Snowflake, veuillez consulter les ressources suivantes :
Meilleurs cours DataCamp
Cursus
Cursus
Cursus
blog
Nisha Arya Ahmed
15 min
Tutoriel
Matt Crabtree
Tutoriel
Stephen Gruppetta
Tutoriel
DataCamp Team
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal