Cours
Introduction au Natural Language Processing (NLP) en Python
4 h
141K
Le traitement du langage naturel (NLP) améliore la façon dont les humains et les ordinateurs communiquent entre eux en utilisant l'apprentissage automatique pour indiquer la structure et le sens du texte. Grâce aux applications de traitement du langage naturel, les entreprises peuvent augmenter leur productivité et réduire leurs coûts en analysant le texte et en extrayant des informations plus significatives afin d'améliorer l'expérience client.
On ne peut pas dire que nous réfléchissions souvent aux subtilités de notre langue. Il s'agit d'un comportement intuitif qui s'appuie sur des indices sémantiques tels que des mots, des signes ou des images pour transmettre des informations et des significations. On dit parfois que l'apprentissage d'une langue est plus facile à l'adolescence parce qu'il s'agit d'un comportement répétitif qui peut être inculqué, un peu comme la marche. En outre, les langues ne suivent pas de règles strictes et comportent de nombreuses exceptions.
L'acquisition d'une langue, bien que naturelle pour les humains, est extrêmement complexe pour les ordinateurs car elle comporte beaucoup de données non structurées, un manque de règles strictes et aucune perspective ou contexte concret. Pourtant, l'homme s'appuie de plus en plus sur des systèmes informatiques pour communiquer et effectuer des tâches. C'est pourquoi l 'apprentissage automatique (ML) et l'intelligence artificielle (IA) gagnent tant d'attention et de popularité. Le traitement du langage naturel suit le développement de l'IA. Bien que ces deux termes évoquent des images de robots futuristes, il existe déjà des applications simples du traitement du langage naturel dans la vie de tous les jours.
La PNL est une composante de l'IA qui se concentre sur la compréhension du langage humain écrit et/ou parlé. Pour ce faire, des programmes informatiques spécifiques sont développés ; un ordinateur typique exige que les instructions soient transmises dans un langage de programmation très précis, balisé, structuré et sans ambiguïté. Malheureusement, le langage humain naturel est imprécis, équivoque et confus. Pour permettre à un programme de comprendre le sens des mots, il est nécessaire d'utiliser des algorithmes capables d'analyser le sens et la structure pour rendre les mots compréhensibles, de reconnaître certaines références, puis de générer le langage.
Les algorithmes NLP effectuent diverses analyses syntaxiques et sémantiques pour évaluer le sens des phrases sur la base de règles grammaticales. Ils y parviennent en procédant comme suit :
Les techniques courantes de la PNL sont les suivantes
La PNL est utilisée dans une grande variété d'applications. Voici quelques-uns des domaines les plus courants.
Les filtres de messagerie constituent l'une des premières applications de base du traitement du langage naturel en ligne. Cette technique a d'abord été utilisée pour créer des filtres anti-spam afin d'identifier les messages indésirables sur la base de certains mots ou phrases. Les filtres ont évolué en même temps que le traitement du langage naturel.
L'une des applications les plus courantes et les plus récentes de cette technique est la classification des courriels par Gmail. Ce système permet de classer un courriel en trois catégories (principal, réseaux sociaux ou promotions) en fonction de son contenu. Cela permet aux utilisateurs de Gmail de mieux gérer leur boîte de réception, de consulter les courriers électroniques importants et d'y répondre rapidement.
Les assistants intelligents tels que Siri (Apple) et Alexa (Amazon) utilisent la reconnaissance vocale pour identifier les modèles de discours, en déduire le sens et suggérer une réponse utile. Aujourd'hui, il semble normal de poser une question à Siri et qu'il nous comprenne et nous réponde de manière pertinente. De même, nous nous habituons à interagir quotidiennement avec Siri ou Alexa par l'intermédiaire de notre thermostat, de nos lumières, de notre voiture, etc.
Nous attendons désormais des assistants comme Alexa et Siri qu'ils captent des indices contextuels pour nous aider dans notre vie quotidienne et effectuer certaines tâches (par exemple, commander des articles). Nous apprécions même leurs réponses amusantes ou lorsqu'ils nous parlent d'eux-mêmes. Nos interactions deviennent plus personnelles au fur et à mesure qu'ils apprennent à nous connaître. Selon l'article du New York Times intitulé Why We May Soon Be Living in Alexa's World (Pourquoi nous pourrions bientôt vivre dans le monde d'Alexa), "Un changement majeur se profile à l'horizon. Alexa deviendra très probablement la troisième plateforme grand public de cette décennie".
Les moteurs de recherche utilisent le traitement du langage naturel pour afficher des résultats pertinents basés sur des comportements de recherche similaires ou sur l'intention de l'utilisateur. Cela permet à chacun de trouver ce dont il a besoin sans avoir de compétences particulières.
Par exemple, lorsque vous commencez à taper une requête, Google vous indique les recherches connexes les plus courantes, mais il peut également reconnaître le sens général de votre requête au-delà de la formulation exacte. Si vous tapez le numéro d'un vol dans Google, vous connaîtrez son statut. Vous obtiendrez un rapport sur les actions si vous tapez le symbole d'une action. Si vous tapez une équation mathématique, vous obtiendrez une calculatrice. Votre recherche peut offrir une variété de résultats parce que la technique de traitement du langage naturel utilisée associe une requête ambiguë à une entité donnée pour offrir des résultats utiles.
Les fonctions telles que l'autocorrection, l'autocomplétion et la saisie intuitive sont si courantes sur nos smartphones aujourd'hui que nous les considérons comme allant de soi. La saisie automatique et la saisie intuitive sont comparables aux moteurs de recherche dans la mesure où elles s'appuient sur ce qui est tapé pour suggérer la fin d'un mot ou d'une phrase. L'autocorrection modifie même parfois certains mots afin d'améliorer le sens général de votre message.
En outre, ces fonctions évoluent en même temps que vous. Par exemple, la frappe intuitive s'adapte au fil du temps à vos tournures de phrases spécifiques. Cela donne parfois lieu à des échanges de messages amusants, avec des phrases entièrement basées sur l'intuition. Le résultat peut être étonnamment personnel et instructif et a même parfois attiré l'attention des médias.
Si votre exercice de langue étrangère est truffé d'erreurs grammaticales, votre professeur saura probablement que vous avez triché en utilisant la technologie de traitement du langage naturel. Malheureusement, de nombreuses langues ne se prêtent pas à une traduction directe parce qu'elles présentent des constructions de phrases différentes, qui ont parfois été négligées par les services de traduction. Cependant, ces systèmes ont beaucoup évolué.
Grâce au traitement du langage naturel, les outils de traduction en ligne offrent des traductions plus précises et grammaticalement correctes. Ils sont donc extrêmement utiles si vous devez communiquer avec quelqu'un qui ne parle pas votre langue. Si vous devez traduire un texte étranger, ces outils peuvent même reconnaître la langue du texte à traduire.
Lorsque vous appelez certaines entreprises, la plupart d'entre nous ont probablement entendu l'annonce "cet appel peut être enregistré à des fins de formation". Si ces enregistrements peuvent être utilisés à des fins de formation (par exemple, pour analyser un échange avec un client mécontent), ils sont généralement stockés dans une base de données qui permet à un système de traitement du langage naturel d'apprendre et de se développer. Les systèmes automatisés redirigent les appels des clients vers un agent ou un chatbot en ligne, qui fournira des informations pertinentes pour répondre à leurs demandes. Cette technique de traitement du langage naturel est déjà utilisée par de nombreuses entreprises, dont les principaux opérateurs téléphoniques.
La technologie des appels téléphoniques numériques permet également à un ordinateur d'imiter la voix humaine. Il est ainsi possible de planifier des appels téléphoniques automatisés pour prendre rendez-vous chez le garagiste ou le coiffeur.
Les capacités de langage naturel sont désormais intégrées dans les flux de travail analytiques. En effet, de plus en plus de fournisseurs de solutions décisionnelles proposent une interface en langage naturel pour leurs visualisations de données. Un codage visuel plus intelligent permet, par exemple, de proposer la meilleure visualisation possible pour une tâche spécifique, en fonction de la sémantique des données. Chacun peut explorer les données à l'aide d'énoncés en langage naturel ou de fragments de questions dont les mots-clés sont interprétés et compris.
L'exploration des données à l'aide d'un langage rend les données plus accessibles et ouvre l'analyse à l'ensemble de l'entreprise au-delà du cercle habituel des analystes et des développeurs informatiques.
L'analyse de texte convertit des données textuelles non structurées en données analysables à l'aide de diverses techniques linguistiques, statistiques et d'apprentissage automatique.
L'analyse des sentiments peut sembler un défi de taille pour les marques (en particulier dans le cas d'une large base de clients). Cependant, un outil basé sur le traitement du langage naturel peut généralement examiner les interactions avec les clients (telles que les commentaires ou les évaluations sur les médias sociaux, ou même les mentions de noms de marque) pour voir ce qu'elles sont. Les marques peuvent ensuite analyser ces interactions pour évaluer l'efficacité de leur campagne de marketing ou suivre l'évolution des problèmes des clients. Ils peuvent alors décider de réagir ou d'améliorer leur service pour offrir une meilleure expérience.
Le traitement du langage naturel contribue également à l'analyse de texte en extrayant des mots-clés et en identifiant des modèles ou des tendances dans des données textuelles non structurées. Quels sont les principaux modèles de PNL ?
Bien que la PNL existe depuis un certain temps, les progrès récents ont été remarquables, en particulier avec l'essor des modèles basés sur des transformateurs et des modèles de langage à grande échelle développés par des entreprises technologiques de premier plan. Parmi les modèles les plus avancés, citons
Modèles basés sur des transformateurs :
Grands modèles linguistiques (LLM) :
Dans ce tutoriel, nous allons voir de plus près comment BERT est utilisé pour la PNL.
BERT, de l'acronyme "Bidirectional Encoder Representations from Transformers", est un modèle publié par Google AI. Cette technique innovante est basée sur le traitement du langage naturel (NLP).
L'algorithme utilise essentiellement l'apprentissage automatique et l'intelligence artificielle pour comprendre les requêtes des internautes. Il tente donc d'interpréter leurs intentions de recherche, c'est-à-dire le langage naturel qu'ils utilisent.
En ce sens, BERT est associé aux assistants vocaux personnels tels que Google Home. L'outil ne se base plus sur chaque mot saisi par l'utilisateur, mais prend en compte l'ensemble de l'expression et le contexte dans lequel elle se situe. Cela permet d'affiner les résultats. Il est plus efficace pour traiter les recherches complexes, quel que soit le support utilisé.
Plus concrètement, BERT permet au moteur de recherche de :
Pour d'autres applications, BERT est utilisé dans :
Ainsi, l'impact de Google BERT serait d'environ 10 % sur les requêtes les plus longues, tapées de manière naturelle.
Le traitement du langage naturel se concentre sur l'analyse des mots tapés par l'utilisateur. Le mot-clé, ses prédécesseurs et ses successeurs sont tous examinés pour mieux comprendre la requête. C'est le principe d'analyse adopté par les "transformateurs".
L'algorithme est particulièrement efficace pour les recherches à longue traîne, où les prépositions influencent le sens. En revanche, son impact sur les requêtes génériques est moins important, puisqu'elles sont déjà bien comprises par Google. Les autres outils de compréhension restent donc fonctionnels.
Que la requête soit formulée de manière désordonnée ou précise, le moteur de recherche est toujours en mesure de la traiter. Mais pour plus d'efficacité, il est préférable d'utiliser des termes plus appropriés.
Le contexte joue un rôle important dans l'analyse effectuée par l'ORET. La traduction automatique et la modélisation linguistique sont optimisées. Des améliorations significatives sont également constatées dans la production de textes de qualité.
Pour utiliser ce modèle, importons d'abord les bibliothèques et les paquets nécessaires, comme indiqué ici :
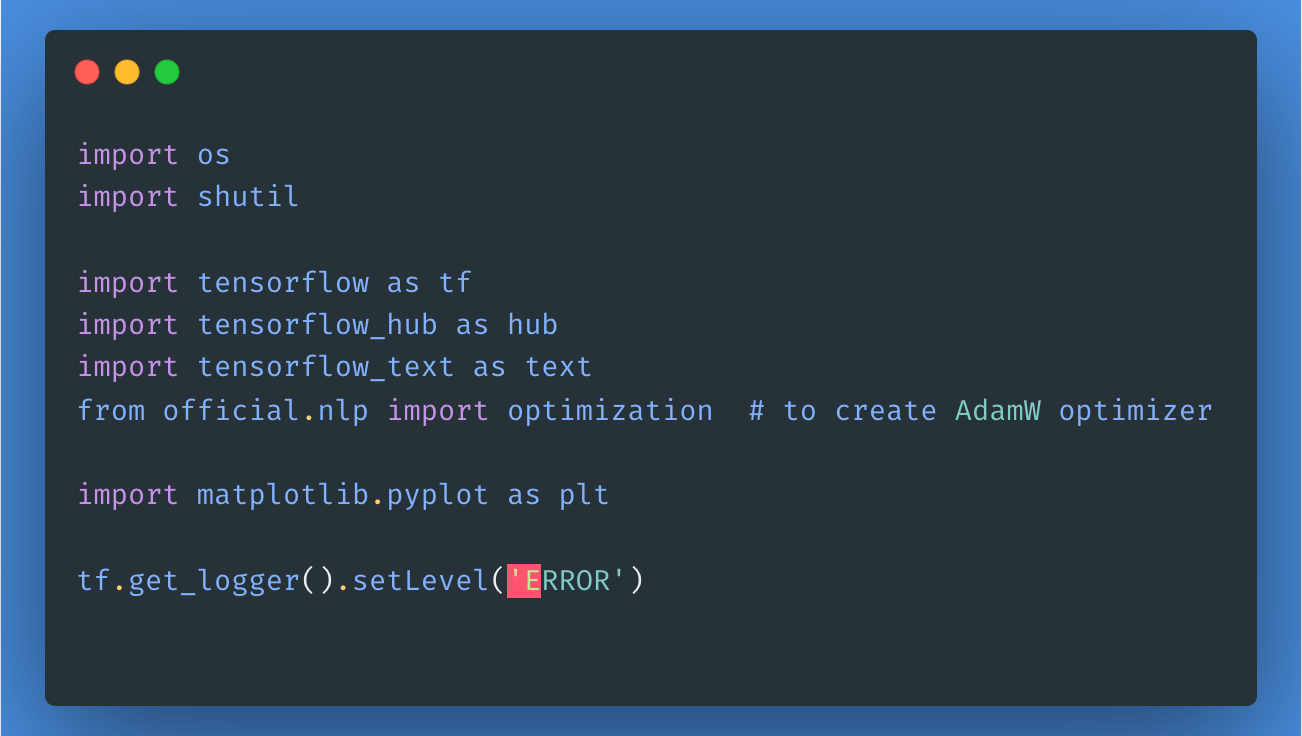
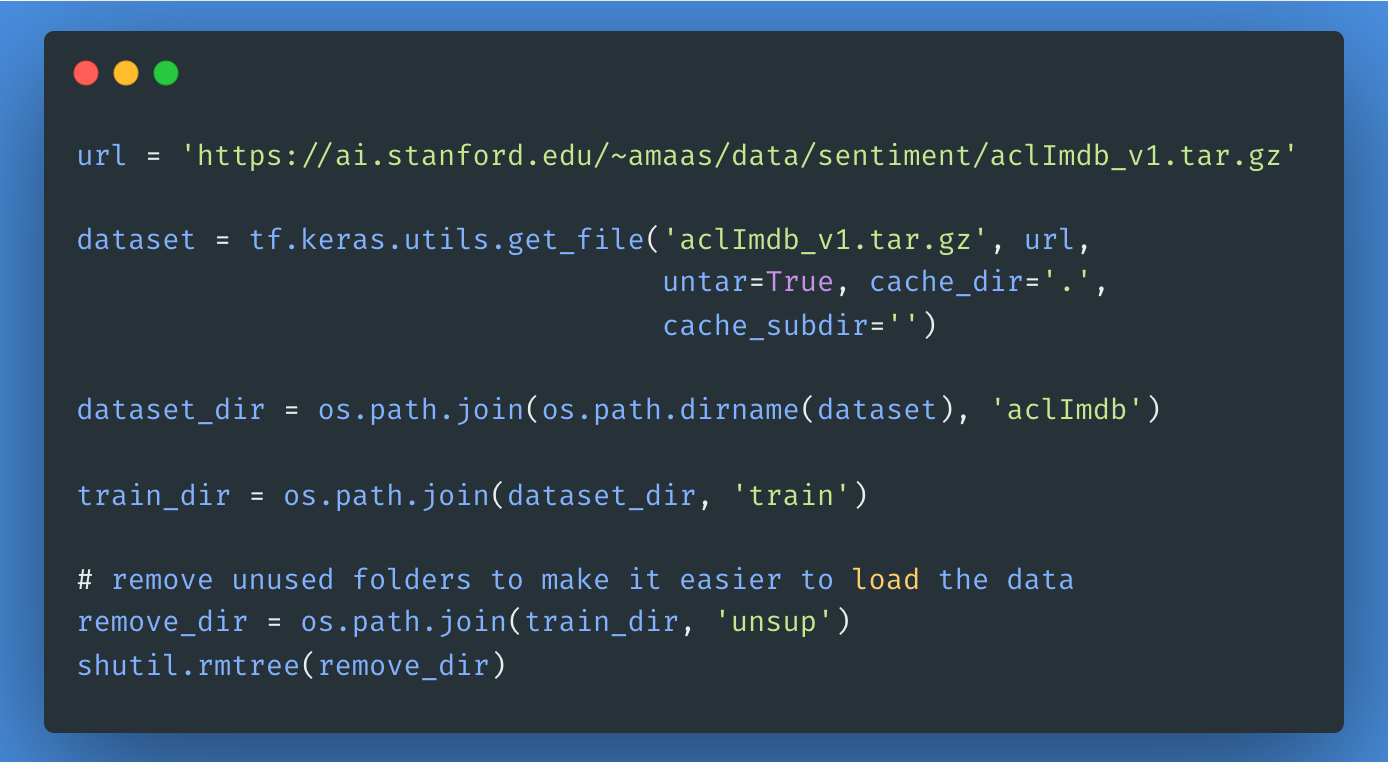
Ensuite, nous allons télécharger et extraire le Large Movie Review Dataset, puis explorer la structure du répertoire.
Pour créer un jeu de données étiqueté tf.data.Dataset, nous utiliserons le répertoire text_dataset_from_directory comme indiqué ci-dessous. Ensuite, nous allons créer un ensemble de validation en utilisant une division 80:20 des données d'apprentissage à l'aide de l'argument validation_split.
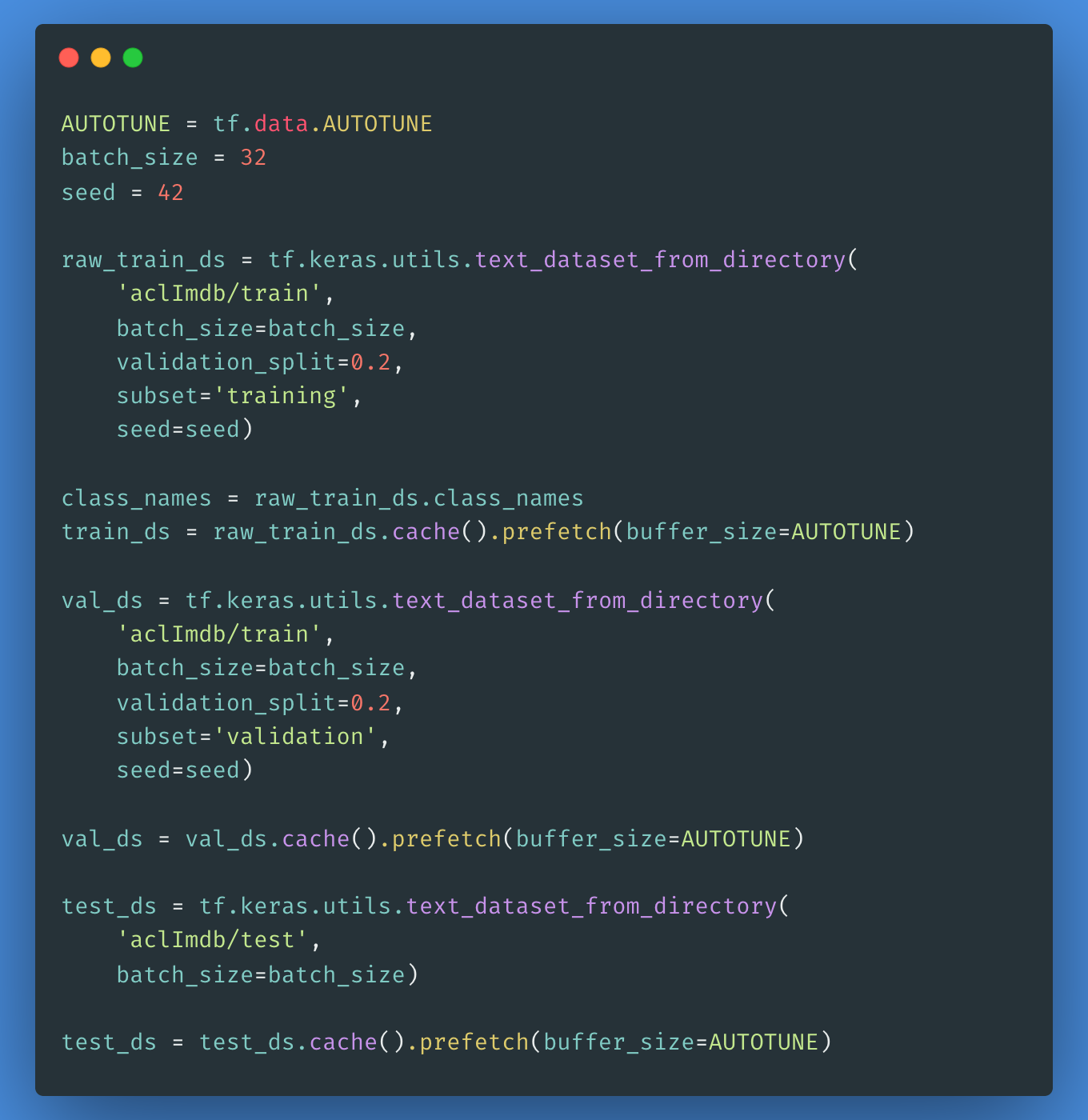
Il est important de spécifier une graine aléatoire lors de l'utilisation de validation_split afin que les divisions de validation et d'apprentissage ne se chevauchent pas.
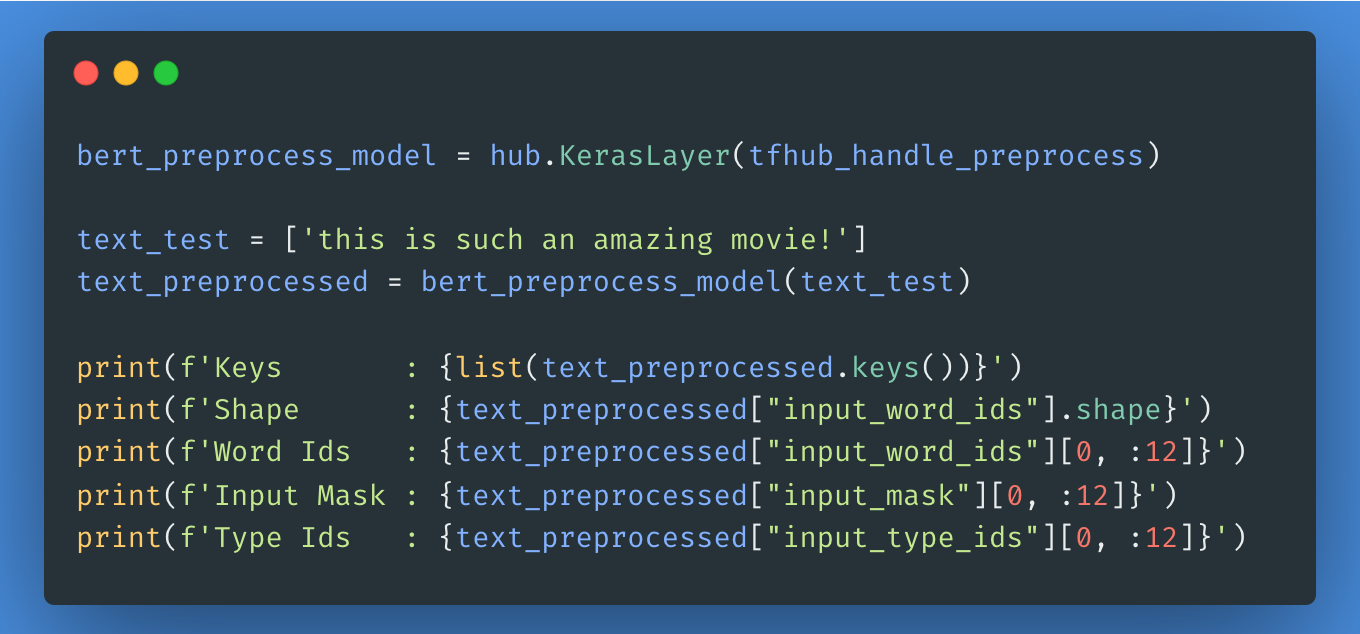
L'étape suivante consiste à choisir le modèle BERT que vous souhaitez charger et affiner à partir de Tensorflow Hub. Vous pouvez utiliser hub.KerasLayer pour composer votre modèle affiné. Ensuite, nous essaierons le modèle de prétraitement sur un texte et nous verrons le résultat.
Ensuite, vous allez construire un modèle simple composé du modèle de prétraitement, du modèle BERT que vous avez sélectionné dans les étapes précédentes, d'une couche dense et d'une couche Dropout.
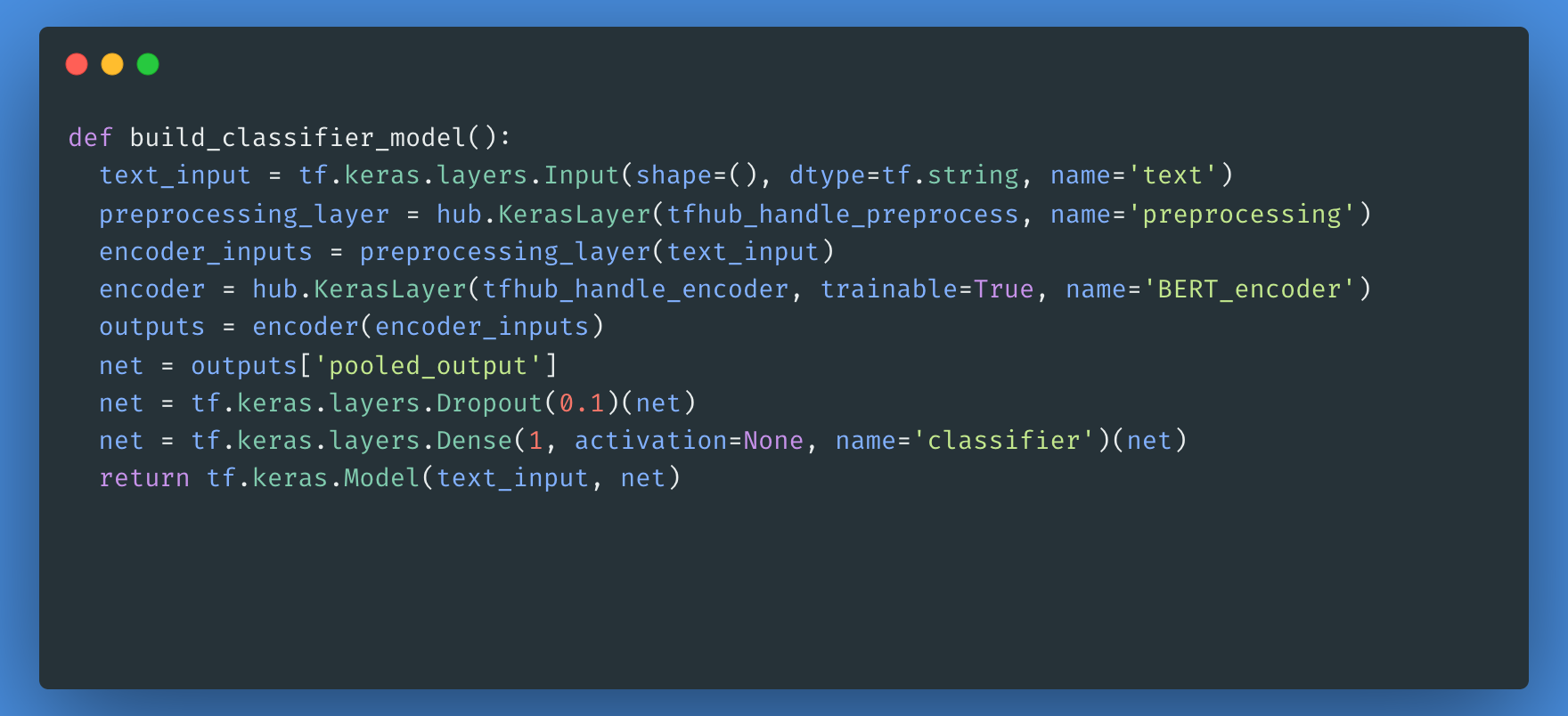
Vous pouvez maintenant vérifier si votre modèle fonctionne avec la sortie du modèle de prétraitement.

La fonction de perte est une étape nécessaire ici, nous opterons pour la fonction de perte losses.BinaryCrossentropy car nous avons affaire à un problème de classification binaire.

Pour le réglage fin, utilisons le même optimiseur que celui avec lequel BERT a été formé à l'origine : les "Moments adaptatifs" (Adam). Cet optimiseur minimise la perte de prédiction et effectue une régularisation par décroissance de poids, également connue sous le nom d'AdamW.

En utilisant le modèle de classificateur que vous avez créé précédemment, vous pouvez compiler le modèle avec la perte, la métrique et l'optimiseur.

Notez que l'apprentissage de votre modèle peut prendre plus ou moins de temps selon la complexité du modèle BERT que vous avez choisi.

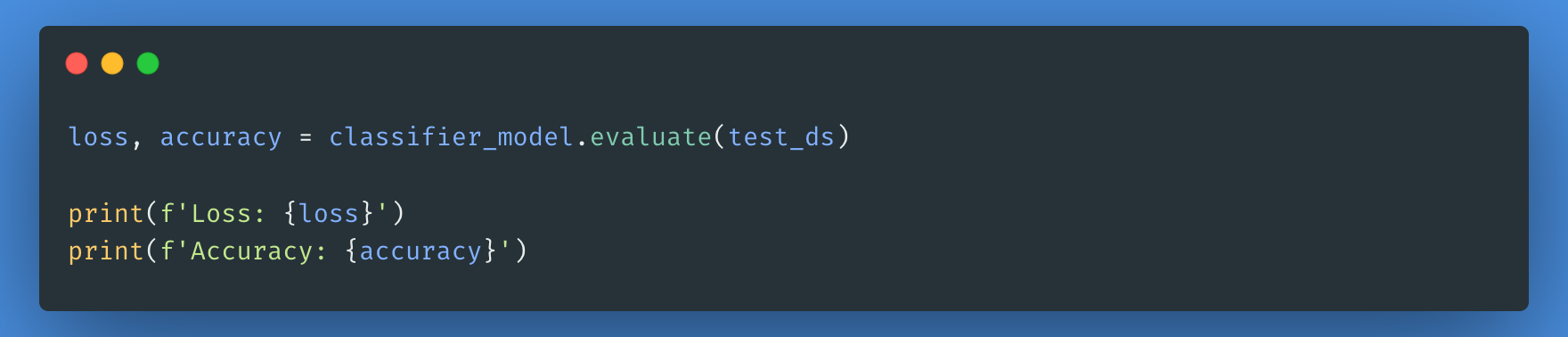
Nous allons maintenant évaluer les performances de notre modèle en vérifiant la perte et la précision du modèle.
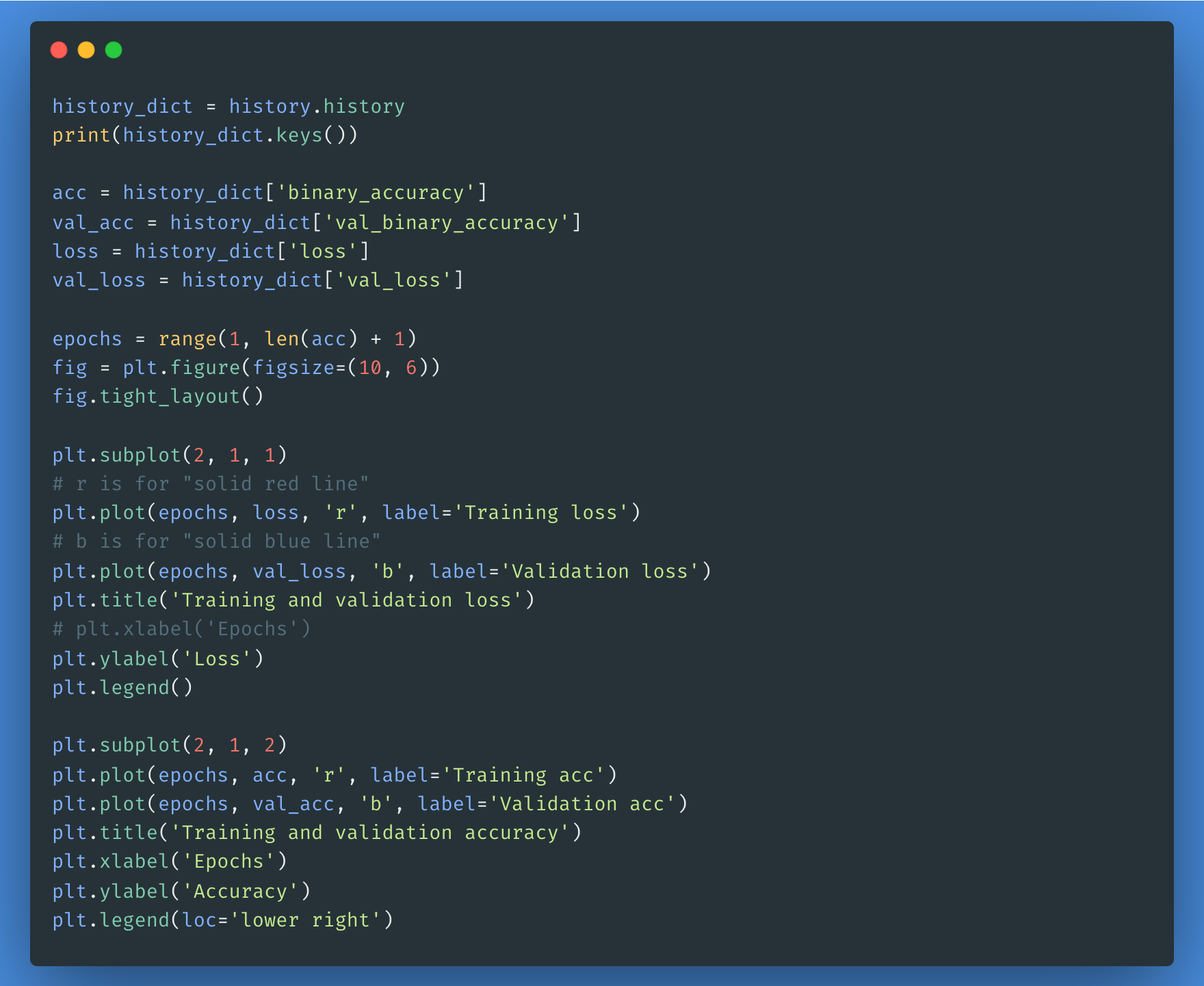
Vous pouvez utiliser l'objet historique si vous souhaitez représenter la perte et la précision pour les ensembles de formation et de validation :
Toutes les étapes ci-dessus sont détaillées dans ce carnet. Vous pouvez mettre en pratique les étapes ci-dessus et exécuter le code pour voir les résultats pour chaque modèle BERT de la liste.
Le traitement du langage naturel est déjà bien établi dans le monde numérique. Ses applications se multiplieront à mesure que les entreprises et les secteurs découvriront ses avantages et l'adopteront. Si l'intervention humaine restera essentielle pour les problèmes de communication plus complexes, le traitement du langage naturel sera notre allié de tous les jours, gérant et automatisant des tâches mineures dans un premier temps, puis des tâches de plus en plus complexes au fur et à mesure des progrès technologiques.
Pour en savoir plus sur le fonctionnement et l'utilisation de la PNL, consultez notre cours Deep Learning for NLP in Python.
Apprenez-en plus sur la PNL avec ces cours !
Cours
Cours
Cours