Curso
Introdução ao Processamento de Linguagem Natural em Python
4 h
141K
O processamento de linguagem natural (PNL) melhora a forma como os seres humanos e os computadores se comunicam entre si, usando machine learning para indicar a estrutura e o significado do texto. Com os aplicativos de processamento de linguagem natural, as organizações podem aumentar a produtividade e reduzir os custos analisando o texto e extraindo informações mais significativas para melhorar a experiência do cliente.
Não podemos dizer que pensamos com frequência sobre as sutilezas de nosso idioma. É um comportamento intuitivo que se baseia em pistas semânticas, como palavras, sinais ou imagens, para transmitir informações e significados. Às vezes, diz-se que aprender um idioma é mais fácil na adolescência porque é um comportamento repetitivo que pode ser instilado, assim como caminhar. Além disso, os idiomas não seguem regras rígidas e têm muitas exceções.
A aquisição de idiomas, embora seja natural para os seres humanos, é extremamente complexa para os computadores, pois possui muitos dados não estruturados, falta de regras rígidas e nenhuma perspectiva ou contexto concreto. No entanto, os seres humanos dependem cada vez mais de sistemas de computador para se comunicar e realizar tarefas. É por isso que o machine learning (ML) e a inteligência artificial (IA) estão ganhando tanta atenção e popularidade. O processamento de linguagem natural está acompanhando o desenvolvimento da IA. Embora esses dois termos possam evocar imagens de robôs futuristas, já existem aplicações simples de processamento de linguagem natural na vida cotidiana.
A PNL é um componente da IA que se concentra na compreensão da linguagem humana conforme ela é escrita e/ou falada. Para isso, são desenvolvidos programas de computador específicos; um computador típico exige que as instruções sejam transmitidas em uma linguagem de programação muito precisa, marcada, estruturada e inequívoca. Infelizmente, a linguagem humana natural é imprecisa, equívoca e confusa. Para que um programa possa entender o significado das palavras, é necessário usar algoritmos capazes de analisar o significado e a estrutura para tornar as palavras compreensíveis, reconhecer determinadas referências e, em seguida, gerar a linguagem.
Os algoritmos de NLP realizam várias análises sintáticas e semânticas para avaliar o significado das frases com base em regras gramaticais. Eles fazem isso por meio de:
As técnicas comuns de PNL incluem:
A PNL é usada em uma ampla variedade de aplicações. Aqui estão algumas das áreas mais comuns.
Os filtros de mensagens são um dos primeiros aplicativos básicos de processamento de linguagem natural on-line. A técnica foi usada pela primeira vez para criar filtros de spam para identificar mensagens indesejadas com base em determinadas palavras ou frases. Com a evolução do processamento de linguagem natural, os filtros também evoluíram.
Um dos aplicativos mais comuns e recentes dessa técnica é a classificação de e-mails do Gmail. Esse sistema pode classificar um e-mail em três categorias (Principal, Redes Sociais ou Promoções) com base em seu conteúdo. Isso permite que os usuários do Gmail gerenciem melhor suas caixas de entrada para visualizar e responder rapidamente a e-mails importantes.
Assistentes inteligentes como a Siri (Apple) e a Alexa (Amazon) usam o reconhecimento de voz para identificar padrões de fala, inferir o significado e sugerir uma resposta útil. Hoje em dia, parece normal fazer uma pergunta à Siri e esperar que ela nos entenda e responda de forma relevante. Da mesma forma, estamos nos acostumando a interagir com a Siri ou a Alexa diariamente por meio de nosso termostato, luzes, carro etc.
Agora, esperamos que assistentes como a Alexa e a Siri percebam dicas contextuais para nos ajudar em nosso dia a dia e realizar determinadas tarefas (por exemplo, fazer pedidos de itens). Até gostamos de suas respostas engraçadas ou quando nos contam sobre si mesmos. Nossas interações se tornam mais pessoais à medida que eles nos conhecem. De acordo com o artigo do New York Times Why We May Soon Be Living in Alexa's World, "Uma grande mudança está chegando. A Alexa provavelmente se tornará a terceira maior plataforma de consumo desta década."
Os mecanismos de pesquisa usam o processamento de linguagem natural para exibir resultados relevantes com base em comportamentos de pesquisa semelhantes ou na intenção do usuário. Isso permite que todos encontrem o que precisam sem ter nenhuma habilidade especial.
Por exemplo, quando você começa a digitar uma consulta, o Google mostra pesquisas populares relacionadas, mas também pode reconhecer o significado geral da sua consulta além do texto exato. Se você digitar o número de um voo no Google, saberá o status dele. Você obterá um relatório de ações se digitar um símbolo de ação. Se você digitar uma equação matemática, verá uma calculadora. Sua pesquisa pode oferecer uma variedade de resultados porque a técnica de processamento de linguagem natural que ela usa associa uma consulta ambígua a uma determinada entidade para oferecer resultados úteis.
Recursos como autocorreção, autocompletar e entrada intuitiva são tão comuns em nossos smartphones hoje em dia que os tomamos como garantidos. A digitação automática e a digitação intuitiva são comparáveis aos mecanismos de pesquisa, pois dependem do que foi digitado para sugerir o final de uma palavra ou frase. Às vezes, a correção automática até altera algumas palavras para melhorar o significado geral da sua mensagem.
Além disso, essas funções evoluem conforme você evolui. Por exemplo, a digitação intuitiva se adapta com o tempo às suas frases específicas. Isso às vezes resulta em trocas de mensagens engraçadas, com frases baseadas inteiramente em informações intuitivas. O resultado pode ser surpreendentemente pessoal e informativo e, às vezes, até atrai a atenção da mídia.
Se o seu exercício de língua estrangeira estiver cheio de erros gramaticais, seu professor provavelmente saberá que você trapaceou usando a tecnologia de processamento de linguagem natural. Infelizmente, muitos idiomas não se prestam à tradução direta porque têm construções de frases diferentes, que às vezes são ignoradas pelos serviços de tradução. No entanto, esses sistemas evoluíram muito.
Graças ao processamento de linguagem natural, as ferramentas de tradução on-line oferecem traduções mais precisas e gramaticalmente corretas. Portanto, eles são extremamente úteis se você precisar se comunicar com alguém que não fala o seu idioma. Se você precisar traduzir um texto estrangeiro, essas ferramentas podem até reconhecer o idioma do texto inserido para tradução.
Ao ligar para algumas empresas, a maioria de nós provavelmente já ouviu o aviso "esta chamada poderá ser gravada para fins de treinamento". Embora essas gravações possam ser usadas para fins de treinamento (por exemplo, para analisar uma troca com um cliente insatisfeito), elas geralmente são armazenadas em um banco de dados que permite que um sistema de processamento de linguagem natural aprenda e cresça. Os sistemas automatizados redirecionam as chamadas dos clientes para um agente ou chatbot on-line, que fornecerá informações relevantes para atender às suas solicitações. Essa técnica de processamento de linguagem natural já é usada por muitas empresas, incluindo as principais operadoras de telefonia.
A tecnologia de chamadas telefônicas digitais também permite que um computador imite a voz humana. Assim, é possível planejar chamadas telefônicas automatizadas para marcar um horário na oficina ou no cabeleireiro.
Os recursos de linguagem natural agora estão integrados aos fluxos de trabalho analíticos. De fato, cada vez mais fornecedores de BI estão oferecendo uma interface de linguagem natural para suas visualizações de dados. Uma codificação visual mais inteligente permite, por exemplo, propor a melhor visualização possível para uma tarefa específica, dependendo da semântica dos dados. Qualquer pessoa pode explorar os dados usando declarações de linguagem natural ou fragmentos de perguntas cujas palavras-chave são interpretadas e compreendidas.
A exploração de dados usando a linguagem torna os dados mais acessíveis e abre a análise para toda a empresa, além do círculo habitual de analistas e desenvolvedores de TI.
A análise de texto converte dados textuais não estruturados em dados analisáveis usando várias técnicas linguísticas, estatísticas e de machine learning.
A análise de sentimentos pode parecer um desafio assustador para as marcas (especialmente no caso de uma grande base de clientes). No entanto, uma ferramenta baseada em processamento de linguagem natural pode, normalmente, analisar as interações com os clientes (como comentários ou avaliações em mídias sociais ou até mesmo menções a nomes de marcas) para ver quais são elas. Em seguida, as marcas podem analisar essas interações para avaliar a eficácia de sua campanha de marketing ou monitorar a evolução dos problemas dos clientes. Assim, eles podem decidir como responder ou melhorar o serviço para proporcionar uma experiência melhor.
O processamento de linguagem natural também contribui para a análise de texto, extraindo palavras-chave e identificando padrões ou tendências em dados de texto não estruturados. Quais são os principais modelos de PNL?
Embora a PNL já exista há algum tempo, os avanços recentes foram notáveis, principalmente com o surgimento de modelos baseados em transformadores e modelos de linguagem em grande escala desenvolvidos pelas principais empresas de tecnologia. Alguns dos modelos mais avançados incluem:
Modelos baseados em transformadores:
Modelos de linguagem grandes (LLMs):
Neste tutorial, veremos mais de perto como o BERT é usado para NLP.
BERT, do acrônimo "Bidirectional Encoder Representations from Transformers" (Representações de codificadores bidirecionais de transformadores), é um modelo lançado pelo Google AI. Essa técnica inovadora é baseada no processamento de linguagem natural (NLP).
O algoritmo usa essencialmente machine learning e inteligência artificial para entender as consultas feitas pelos usuários da Internet. Assim, ele tenta interpretar suas intenções de pesquisa, ou seja, a linguagem natural que eles usam.
Nesse sentido, o BERT está associado a assistentes de voz pessoais, como o Google Home. A ferramenta não se baseia mais em cada palavra digitada pelo usuário, mas considera toda a expressão e o contexto em que ela está situada. Isso é feito para que você possa refinar os resultados. Ele é mais eficiente para lidar com pesquisas complexas, independentemente da mídia usada.
Em termos mais concretos, o BERT permite que o mecanismo de busca :
Para outras aplicações, o BERT é usado em :
Assim, o impacto do Google BERT seria de cerca de 10% nas consultas mais longas, digitadas de forma natural.
O processamento de linguagem natural concentra-se na análise das palavras digitadas pelo usuário. A palavra-chave, seus predecessores e seus sucessores são examinados para que você entenda melhor a consulta. Esse é o princípio de análise adotado pelos "transformadores".
O algoritmo é particularmente eficaz para pesquisas de cauda longa, em que as preposições influenciam o significado. Por outro lado, seu impacto sobre as consultas genéricas é menos importante, pois elas já são bem compreendidas pelo Google. As outras ferramentas de compreensão, portanto, permanecem funcionais.
Independentemente de a consulta ser formulada de forma desordenada ou precisa, o mecanismo de busca ainda é capaz de processá-la. Mas, para maior eficiência, é melhor usar termos mais apropriados.
O contexto desempenha um papel importante na análise realizada pelo BERT. A tradução automática e a modelagem linguística são otimizadas. Melhorias significativas também são observadas na geração de textos de qualidade.
Para usar esse modelo, vamos primeiro importar as bibliotecas e os pacotes necessários, conforme mostrado aqui:
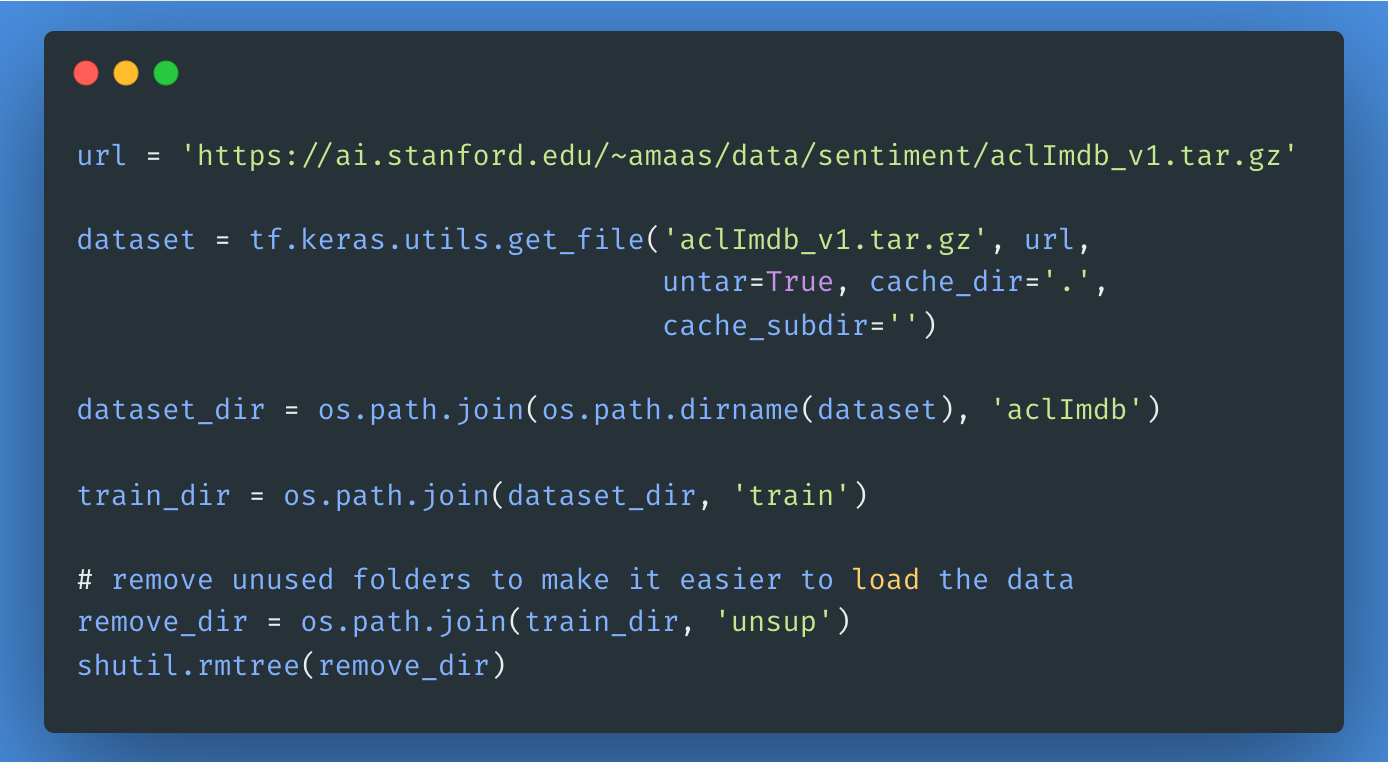
Em seguida, vamos baixar e extrair o Large Movie Review Dataset e, depois, explorar a estrutura do diretório.
Para criar um tf.data.Dataset rotulado, usaremos o text_dataset_from_directory, conforme mostrado abaixo. Em seguida, criaremos um conjunto de validação usando uma divisão de 80:20 dos dados de treinamento usando o argumento validation_split.
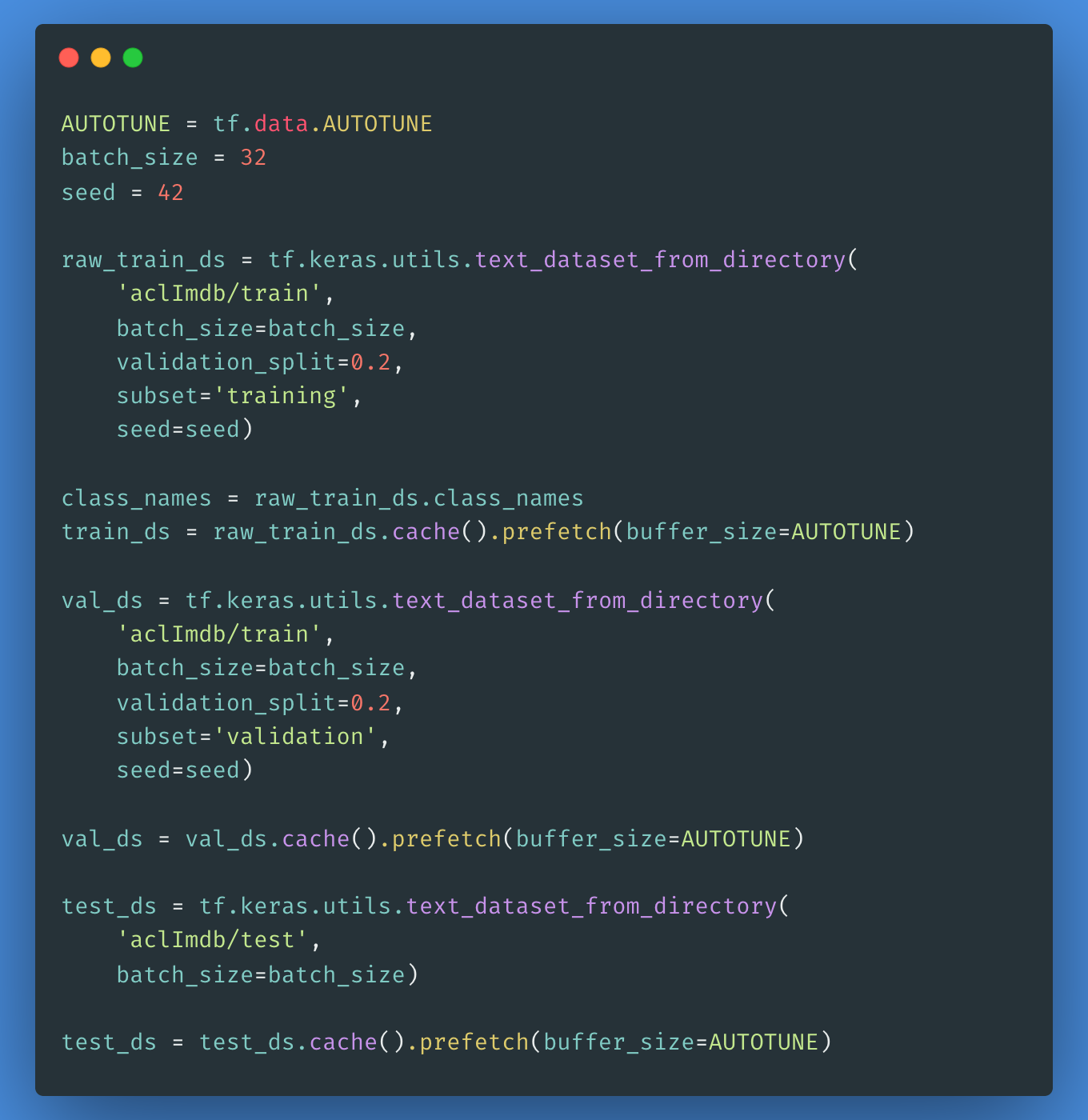
É importante que você especifique uma semente aleatória ao usar validation_split para que as divisões de validação e treinamento não se sobreponham.
A próxima etapa será escolher qual modelo BERT você gostaria de carregar e ajustar no Tensorflow Hub. Você pode usar o hub.KerasLayer para compor o modelo ajustado. Em seguida, testaremos o modelo de pré-processamento em algum texto e veremos o resultado.
Em seguida, você criará um modelo simples composto pelo modelo de pré-processamento, o modelo BERT que você selecionou nas etapas anteriores, uma camada densa e uma camada Dropout.
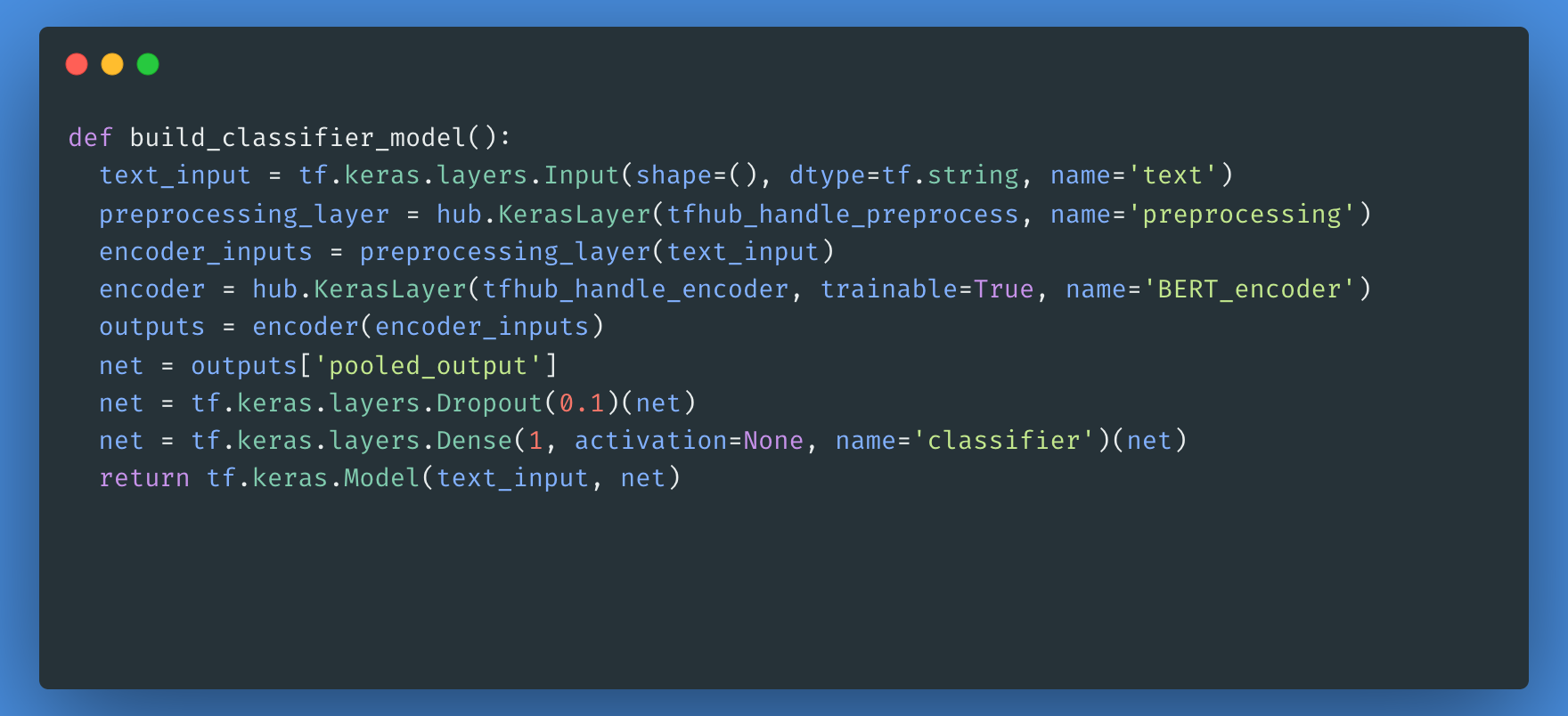
Agora, você pode verificar se o seu modelo é executado com a saída do modelo de pré-processamento.

A função de perda é uma etapa necessária aqui. Optaremos pela função de perda losses.BinaryCrossentropy, pois estamos lidando com um problema de classificação binária.

Para fazer o ajuste fino, vamos usar o mesmo otimizador com o qual o BERT foi originalmente treinado: o "Adaptive Moments" (Adam). Esse otimizador minimiza a perda de previsão e faz a regularização por decaimento de peso, que também é conhecido como AdamW.

Usando o classifier_model criado anteriormente, você pode compilar o modelo com a perda, a métrica e o otimizador.

Observe que o seu modelo pode levar menos ou mais tempo para ser treinado, dependendo da complexidade do modelo BERT que você escolheu.

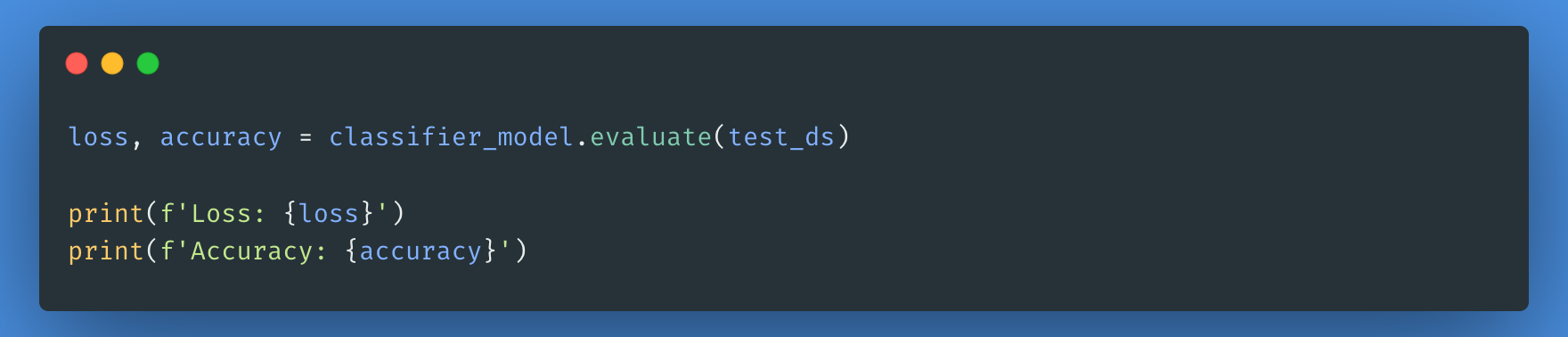
Agora, avaliaremos o desempenho do nosso modelo verificando a perda e a precisão do modelo.
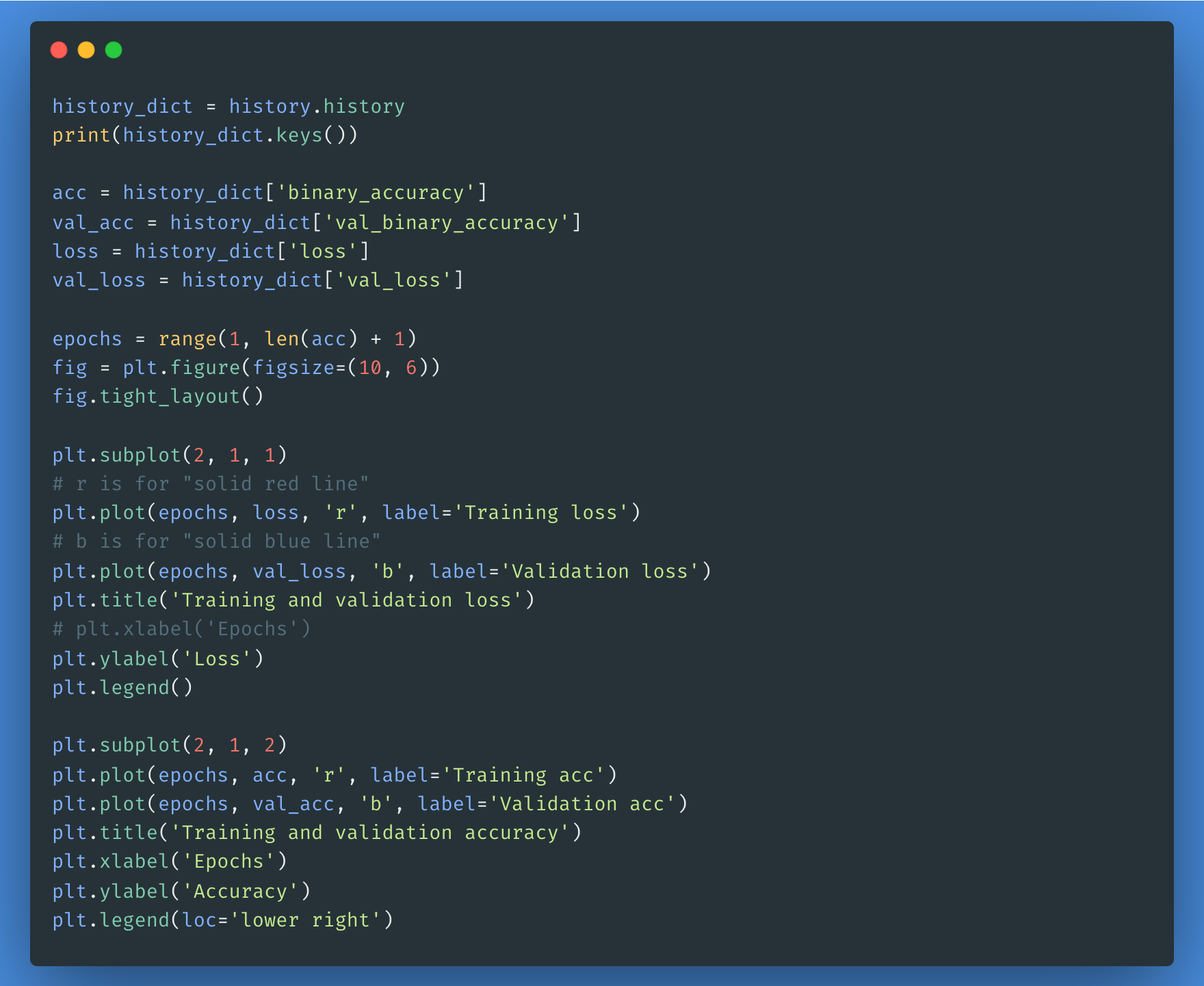
Você pode usar o objeto de histórico se quiser plotar a perda e a precisão dos conjuntos de treinamento e validação:
Todas as etapas acima estão detalhadas neste notebook. Você pode praticar as etapas acima e executar o código para ver os resultados de cada modelo BERT da lista.
O processamento de linguagem natural já está bem estabelecido no mundo digital. Suas aplicações se multiplicarão à medida que as empresas e os setores descobrirem seus benefícios e os adotarem. Embora a intervenção humana continue a ser essencial para problemas de comunicação mais complexos, o processamento de linguagem natural será nosso aliado diário, gerenciando e automatizando tarefas menores no início e, depois, lidando com tarefas cada vez mais complexas com o avanço da tecnologia.
Para saber mais sobre como a PNL funciona e como usá-la, confira nosso curso Deep Learning for NLP in Python.
Aprenda mais sobre PNL com estes cursos!
Curso
Curso
Curso
blog
Matt Crabtree
11 min
blog
Javier Canales Luna
11 min
blog
Dimitri Didmanidze
7 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
