Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Embora a maioria das pessoas associe o Google aos mecanismos de pesquisa, a empresa também tem raízes profundas no setor de ciência de dados. Ela fornece consistentemente produtos e soluções de última geração que visam obter o máximo de benefícios dos dados. Um de seus produtos, o Vertex AI, foi lançado em 2021 para simplificar o processo de machine learning em escala empresarial.
Neste tutorial, você aprenderá como começar a usar a plataforma Vertex AI do Google e como usá-la para cobrir uma ampla gama de tarefas do ciclo de vida do ML. Você terá um modelo implantado que poderá usar para enviar solicitações e gerar previsões para uma tarefa de classificação.
Um ciclo de vida típico de machine learning consiste em vários estágios:
Todas essas etapas e subetapas exigem um conjunto diferente de ferramentas e uma equipe diversificada de especialistas para coordená-las.
O Vertex AI do Google Cloud simplifica e unifica todo esse processo em uma única plataforma.
Embora os aplicativos de ML em grande escala exijam especialistas experientes, o Vertex AI capacita usuários de qualquer nível de habilidade:
Há muitas coisas que não mencionamos nesta seção, pois você mesmo trabalhará na maioria delas neste tutorial.
Antes de começarmos a explorar a plataforma, precisamos mencionar sua matriz, os serviços do Google Cloud. O Google Cloud Services inclui uma ampla gama de soluções de computação em nuvem que fornecem armazenamento, rede, bancos de dados, análises e recursos de machine learning.
Esses serviços trabalham em sincronia com o Vertex AI para unificar o fluxo de trabalho de machine learning que você tem. Aqui você encontra um detalhamento dos serviços frequentemente usados com o Vertex AI:
Os serviços do Google Cloud estão sempre disponíveis na sua conta do Google se você visitar cloud.google.com. Se você nunca os utilizou antes, clique em "Get started for free" (Comece gratuitamente) para obter sua avaliação gratuita.
Caso contrário, você pode ir diretamente para console.cloud.google.com para que possamos começar.
Isenção de responsabilidade: Se você quiser acompanhar o tutorial, prepare-se para gastar de 25 a 30 dólares no Vertex AI. Usaremos as configurações mais baratas.
Ao visitar o Google Cloud Console, você provavelmente acabará na seguinte página de boas-vindas:
Ele lista o nome do seu espaço de trabalho; o meu é ibexprogramming.com.
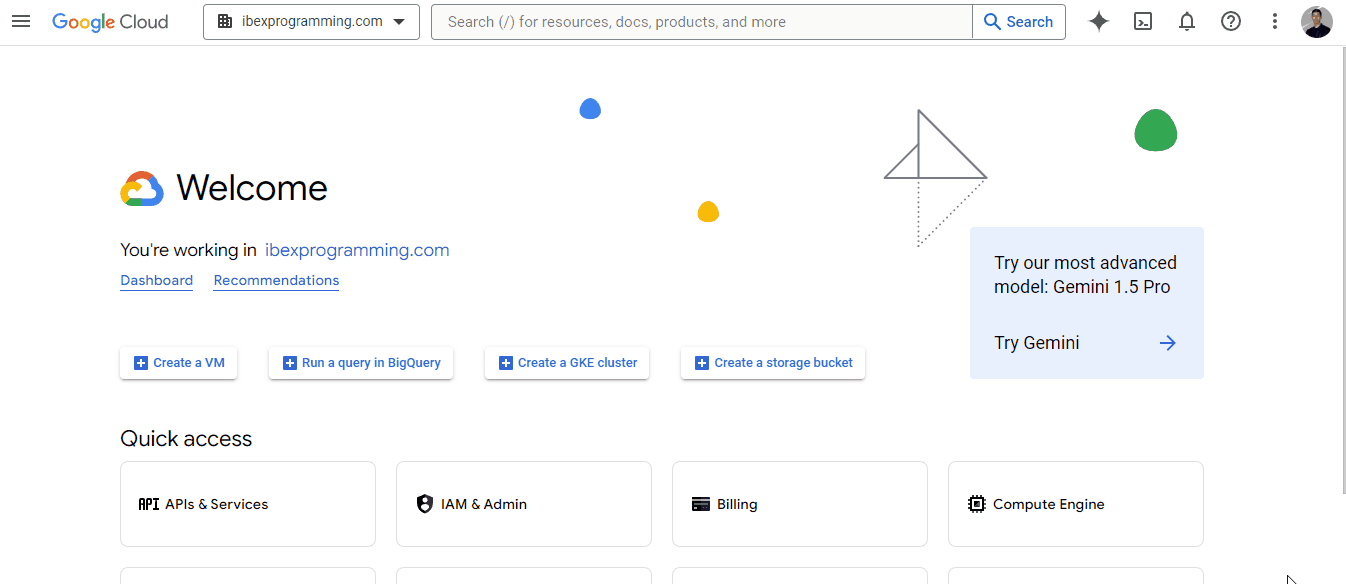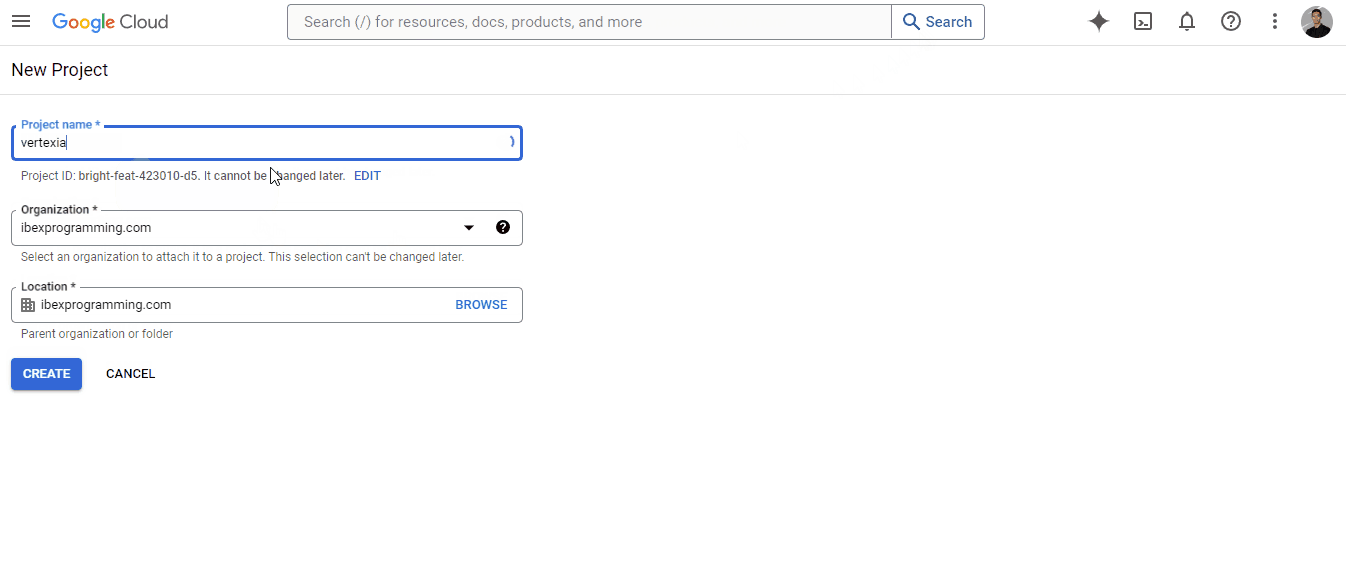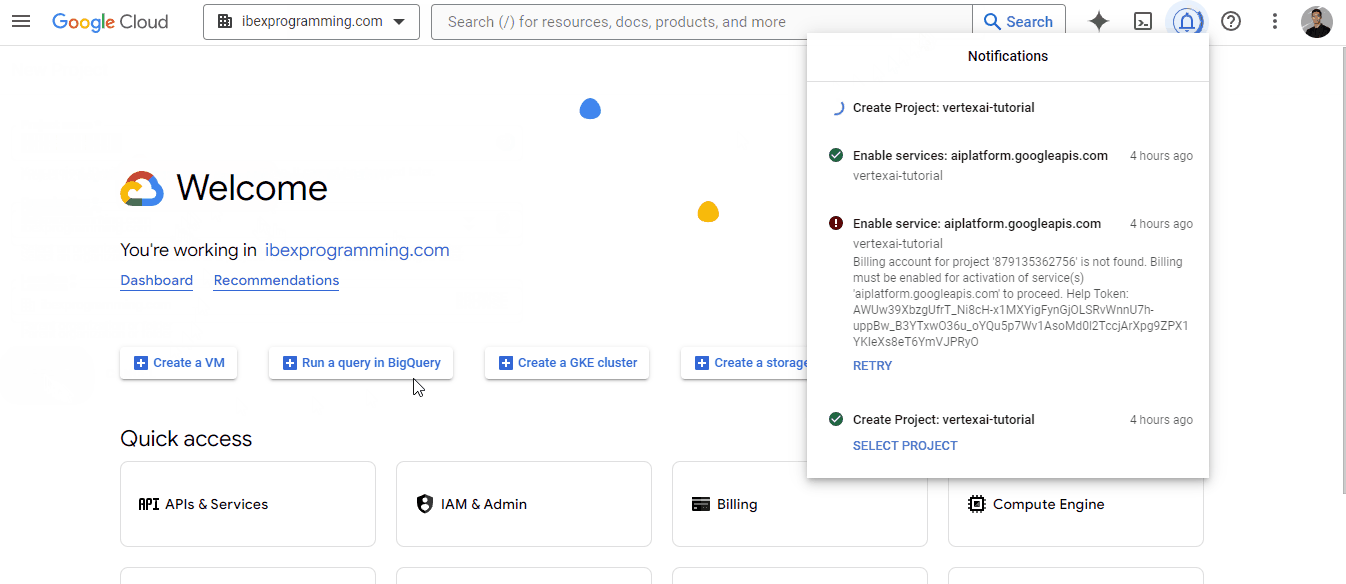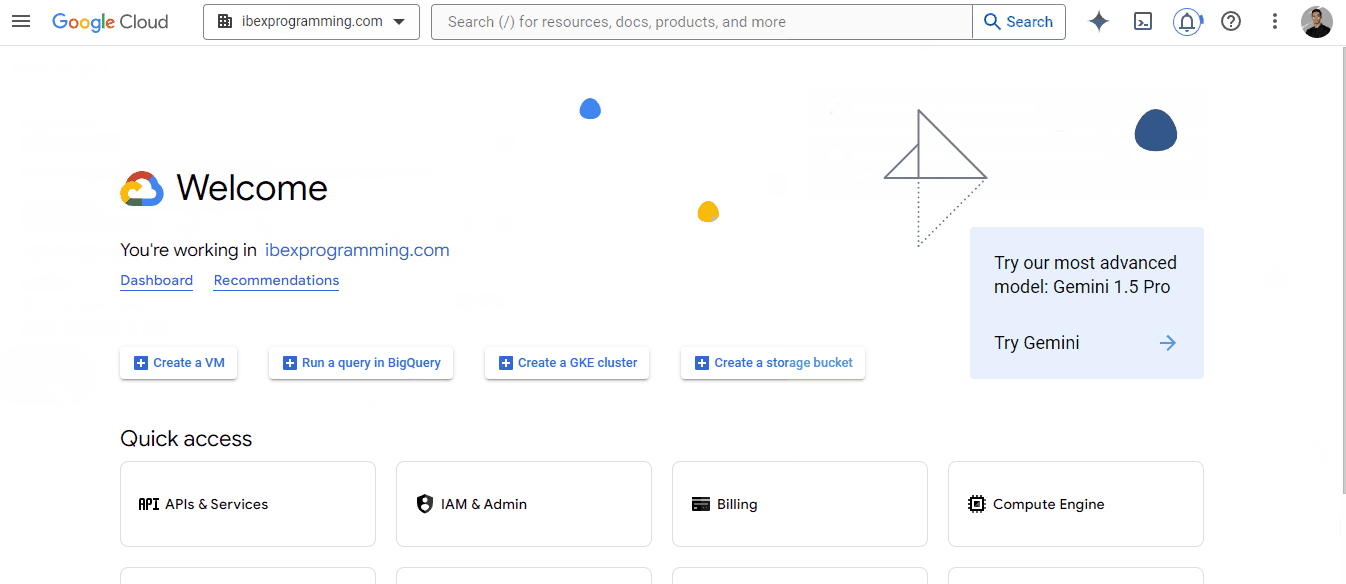
A primeira coisa que faremos é criar um projeto. Os projetos do Google Cloud são unidades organizacionais de alto nível para gerenciar recursos para uma tarefa específica. Aqui está um GIF sobre como você pode criar um:
Depois que o projeto tiver sido criado, selecione-o para que a barra superior da página mostre isso:
![]()
Agora, você precisa criar uma conta de cobrança porque a Vertex AI exige informações de cobrança para ativar seus serviços. Não se preocupe - você não será cobrado até usar recursos pagos. Portanto, acesse o site https://console.cloud.google.com/billing:
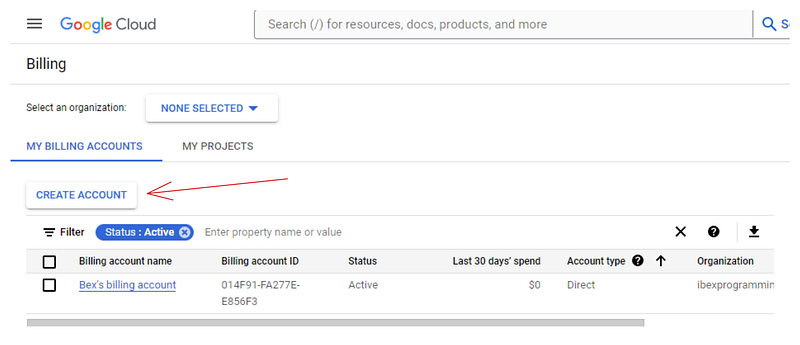
Se você ainda não tiver uma conta como a minha, clique em "Create account" (Criar conta) e siga as instruções apresentadas. Vincularemos essa conta de cobrança à nossa na próxima seção.
Depois disso, volte para https://console.cloud.google.com/ e clique no botão "View all products" (Exibir todos os produtos) na parte inferior da página:
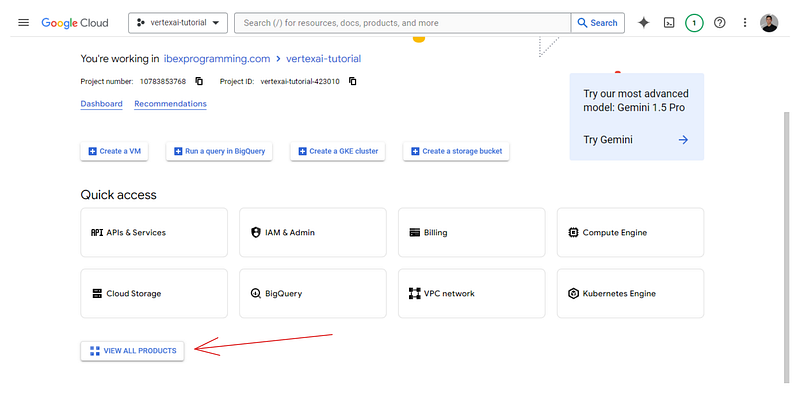
A próxima página listará todos os serviços oferecidos pelo Google Cloud para o seu projeto. Procure por "Vertex AI" (Ctrl + F) e fixe-o no menu para facilitar o acesso. Em seguida, clique no próprio serviço:
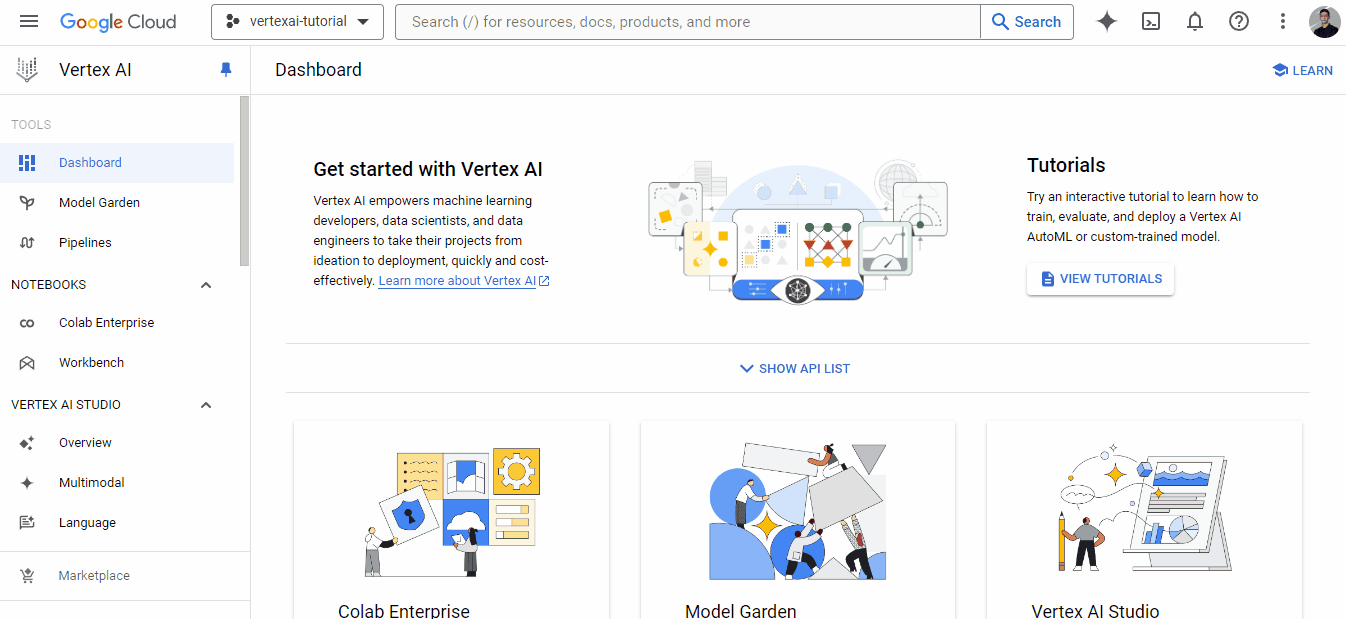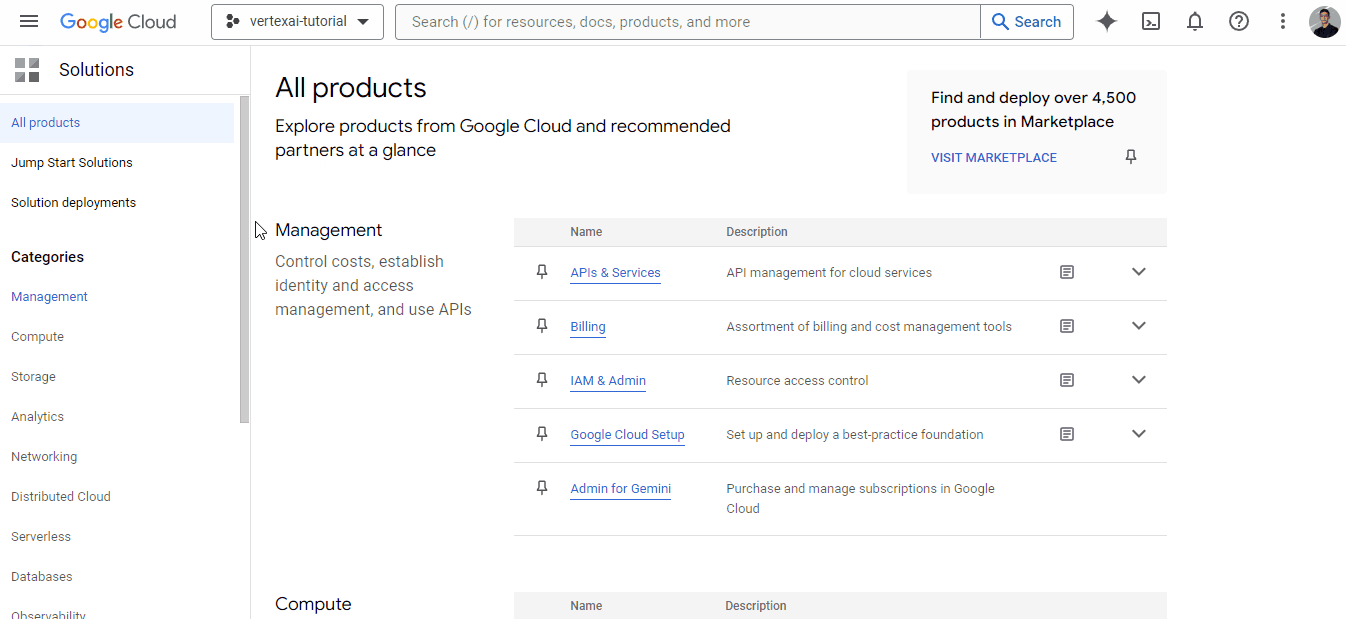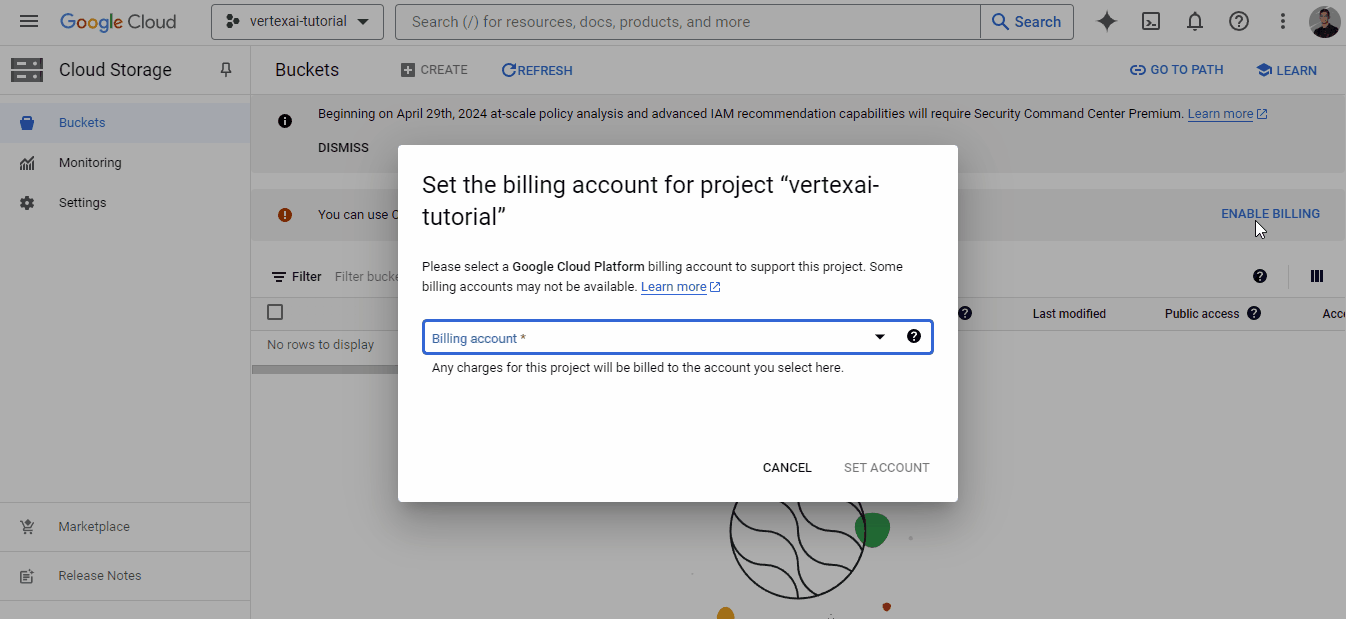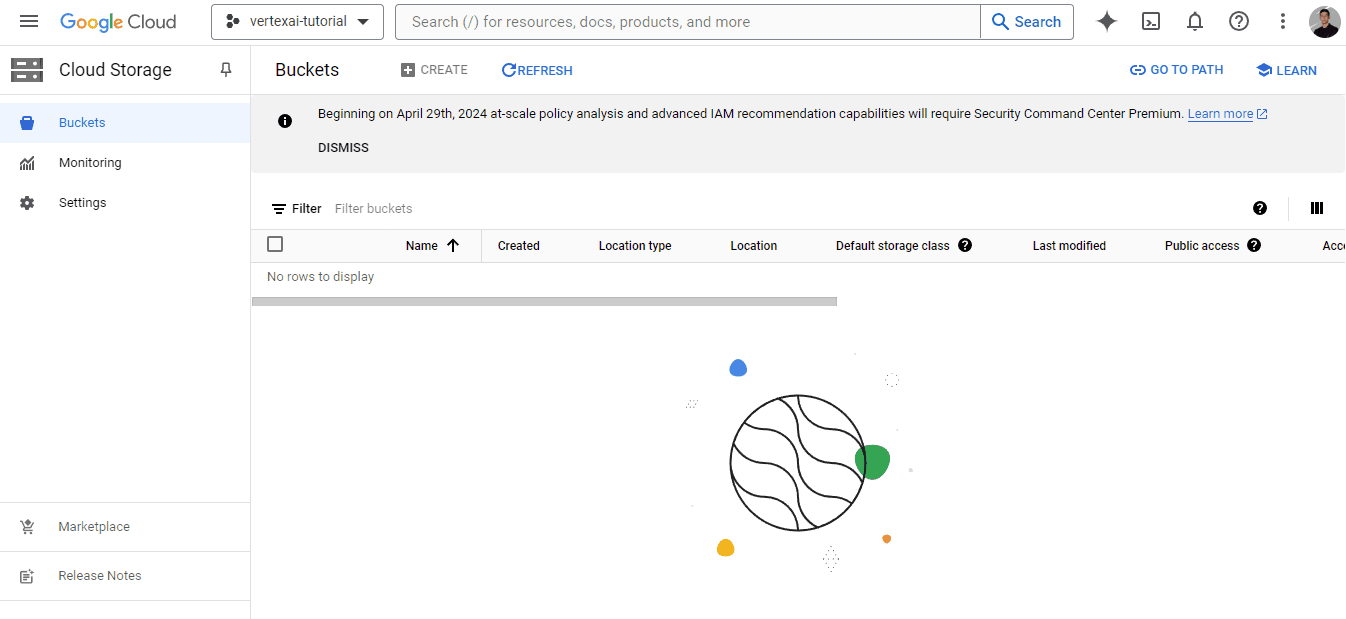
Isso direcionará você para o painel de controle do Vertex AI. Poderá aparecer uma janela solicitando que você ative a API Vertex AI - escolha "Enable" (Ativar). Se a janela não for exibida, você poderá clicar no botão "Enable all API permissions" (Ativar todas as permissões de API) para fazer o mesmo.
Agora, estamos prontos para carregar um conjunto de dados no Vertex AI.
Há várias maneiras de adicionar um conjunto de dados ao Vertex AI. Nesta seção, usaremos um arquivo CSV local para simplificar.
Para este artigo, usaremos o conjunto de dados Dry Bean do repositório UCI Machine Learning. Ele contém 13 mil instâncias de feijões e suas 15 medidas numéricas.
A tarefa é classificá-los em sete tipos de feijão: Seker, Barbunya, Bombay, Cali, Dermosan, Horoz e Sira.
Após o download, salve o arquivo do Excel dentro do ZIP baixado em seu diretório local:
from pathlib import Path
cwd = Path.cwd()
data_path = cwd / "data" / "Dry_Bean_Dataset.xlsx"
Em seguida, podemos ler esse arquivo com o pandas e salvá-lo novamente como CSV:
import pandas as pd
beans = pd.read_excel(data_path)
beans.shape
(13611, 17)Observe que a função read_excel exige que você instale a biblioteca openpyxl com o PIP.
Ótimo, temos o conjunto de dados como um DataFrame. Vamos salvá-lo novamente como um CSV:
beans.to_csv(cwd / "data" / "dry_bean.csv", index=False)Como mencionamos anteriormente, precisamos de um Google Storage Bucket para armazenar nossos dados brutos. Siga o GIF abaixo para navegar até o painel de controle do produto:
O GIF mostra que, para começar a usar os serviços de armazenamento, precisamos vincular uma conta de faturamento, o que fazemos usando a que criamos anteriormente. Em seguida, você poderá criar um bucket com um nome globalmente exclusivo:
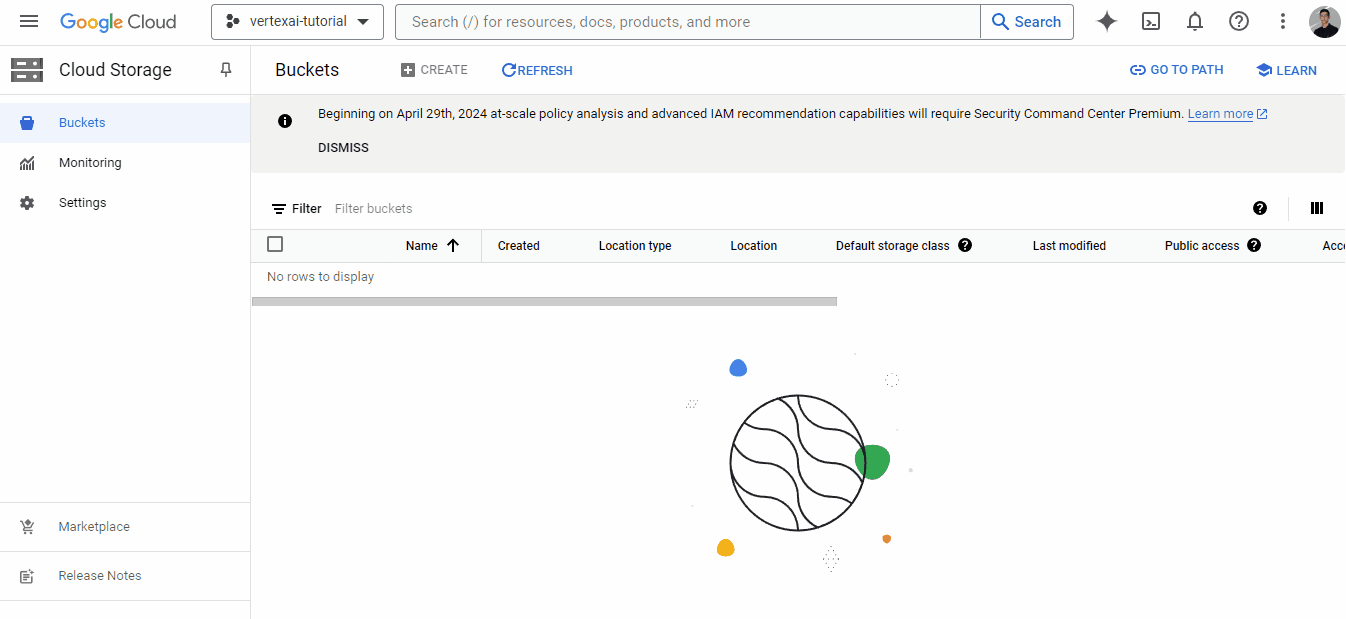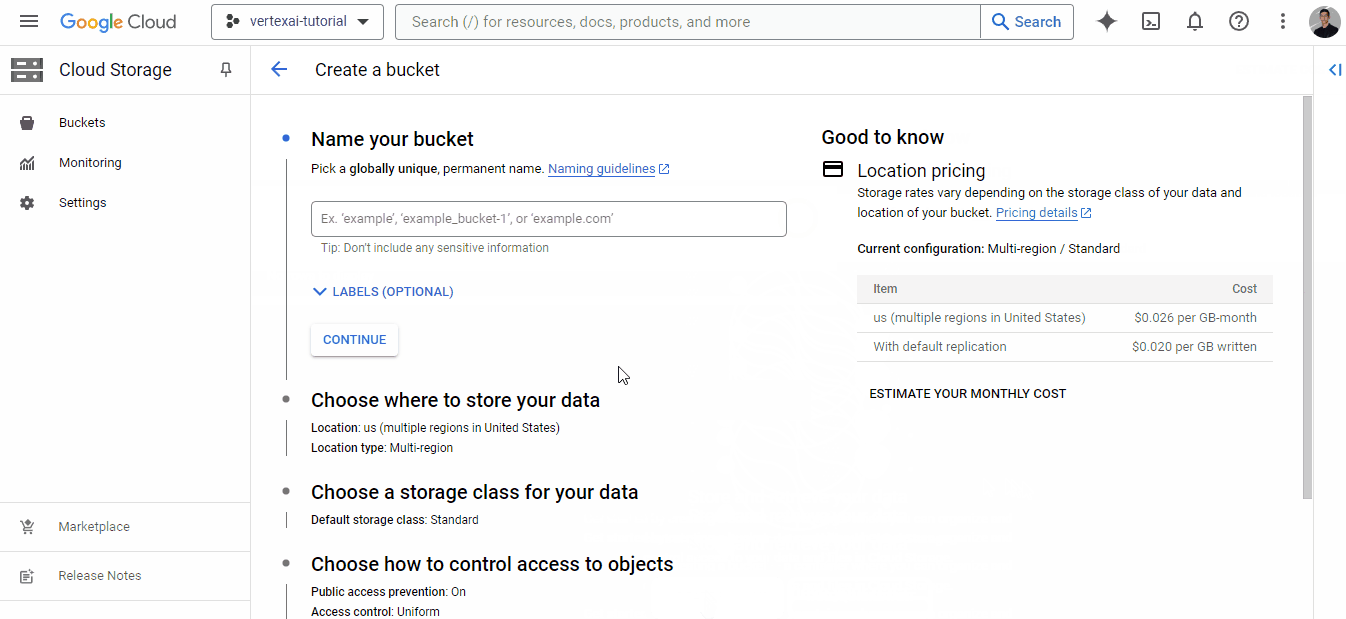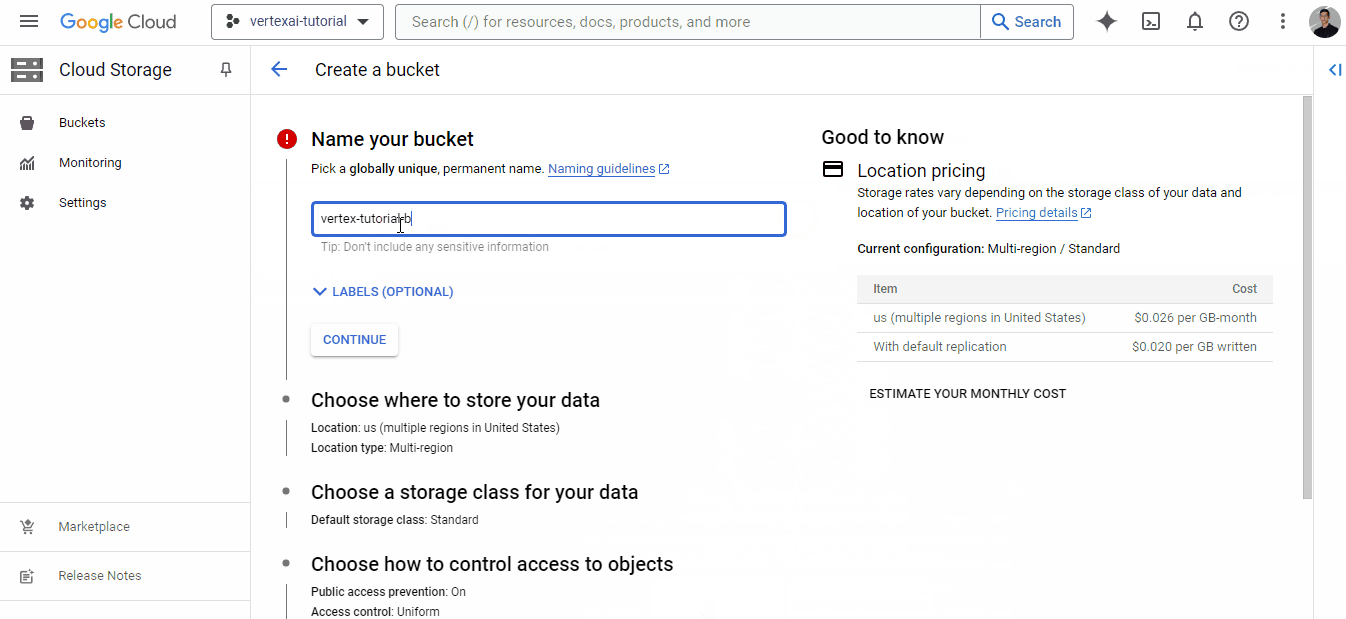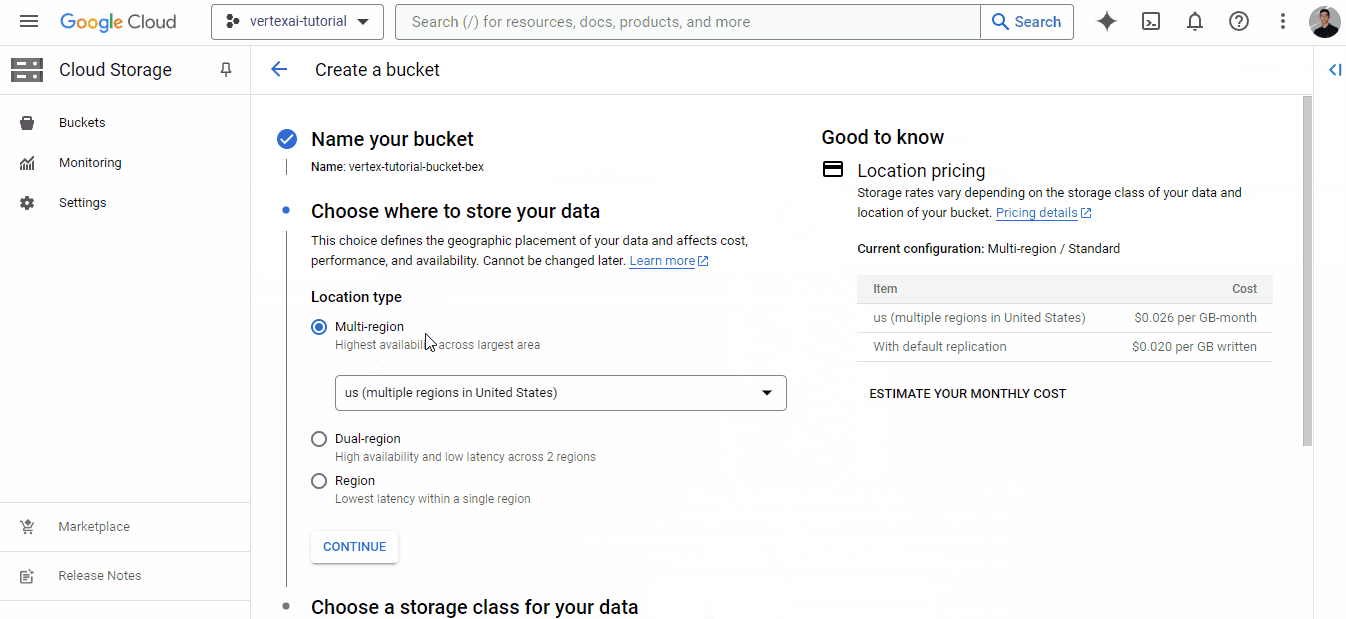
Depois de encontrar um nome exclusivo, clique em "Continue" (Continuar) até que o bucket seja criado - você pode escolher opções padrão para todos os campos.
Agora, estamos prontos para ingerir o arquivo CSV que salvamos na seção anterior.
Agora, vamos voltar ao nosso painel do Vertex AI e verificar a guia Datasets:
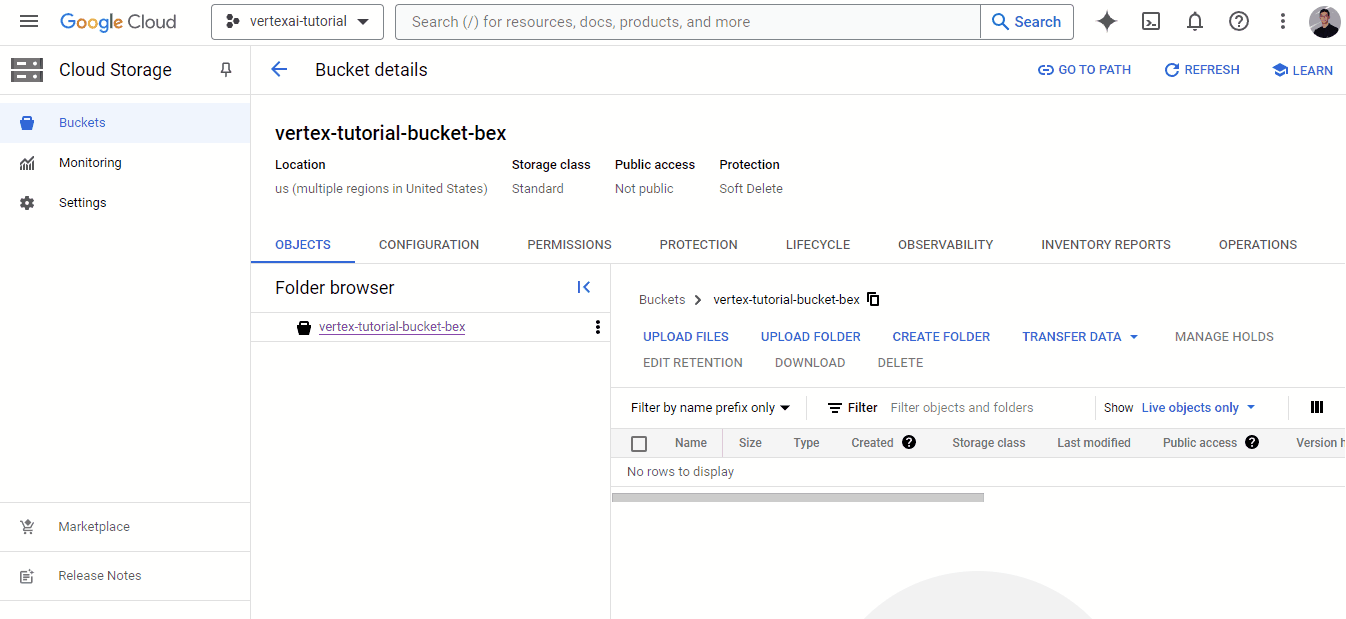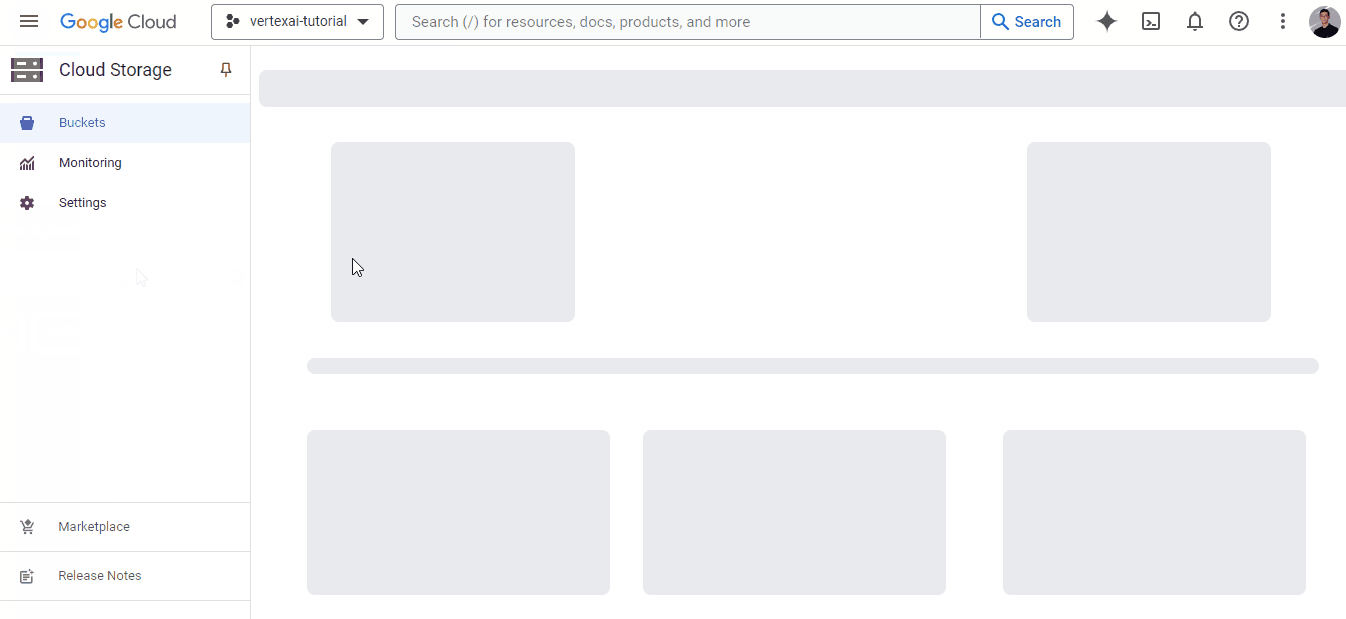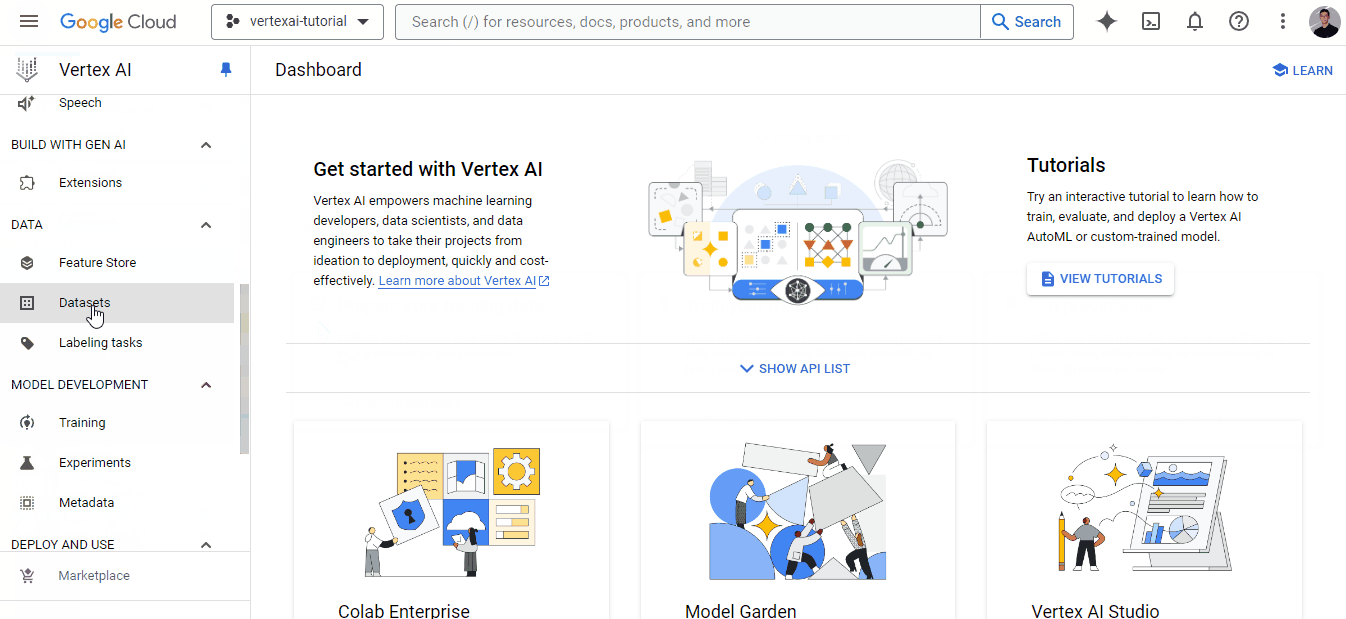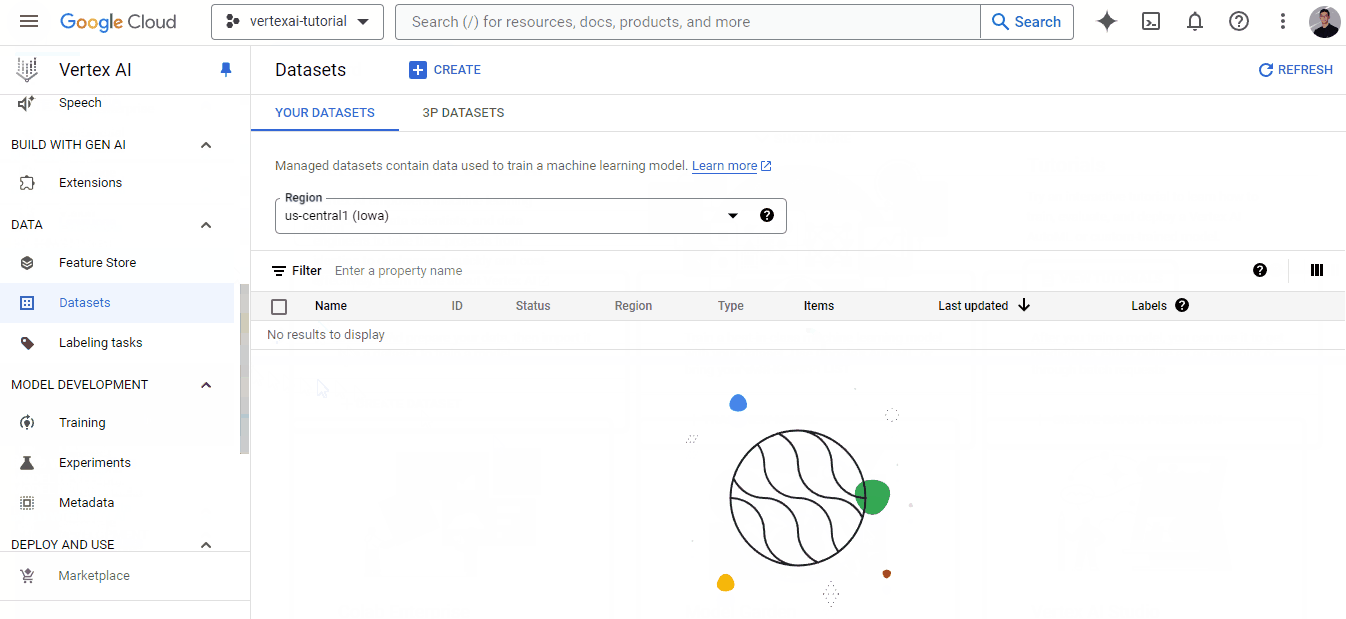
Você verá que ela está vazia, então clique no botão "+Create":
Dê ao conjunto de dados um nome exclusivo e escolha a opção tabular:
Em seguida, a plataforma mostra a você as opções de origem. Escolha fazer upload de um arquivo CSV local e, para o caminho do Cloud Storage, escolha o bucket que você acabou de criar:
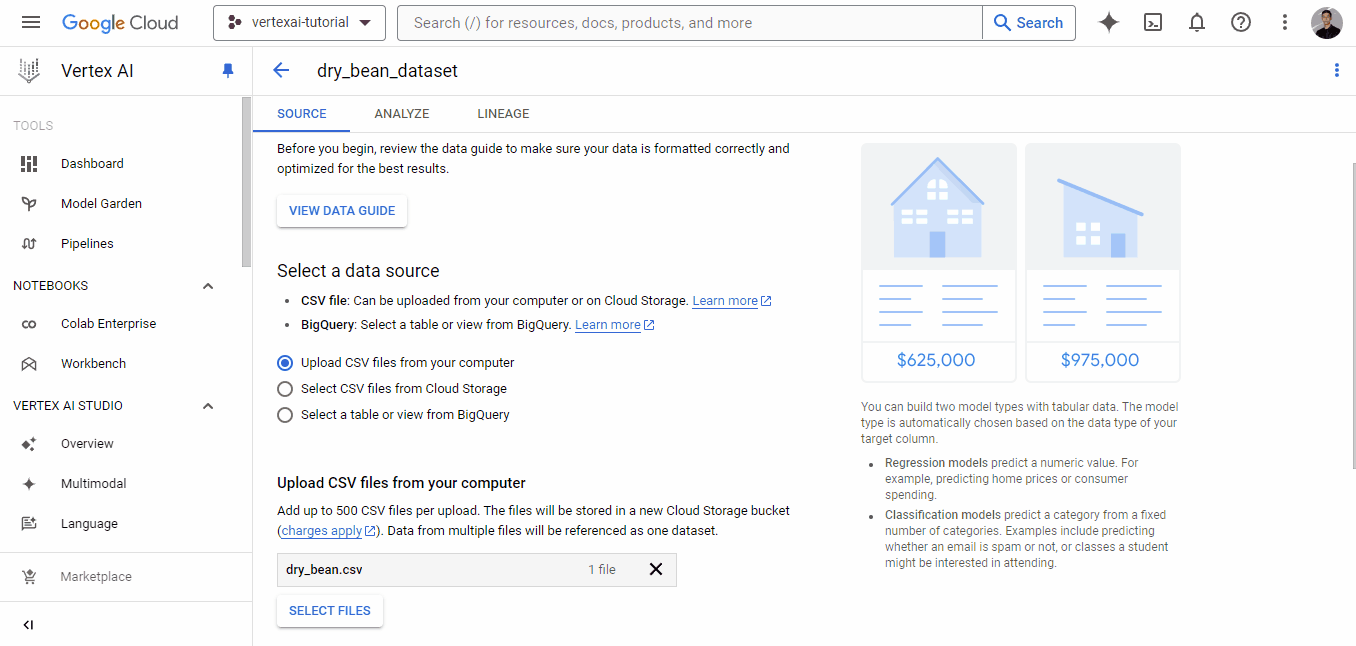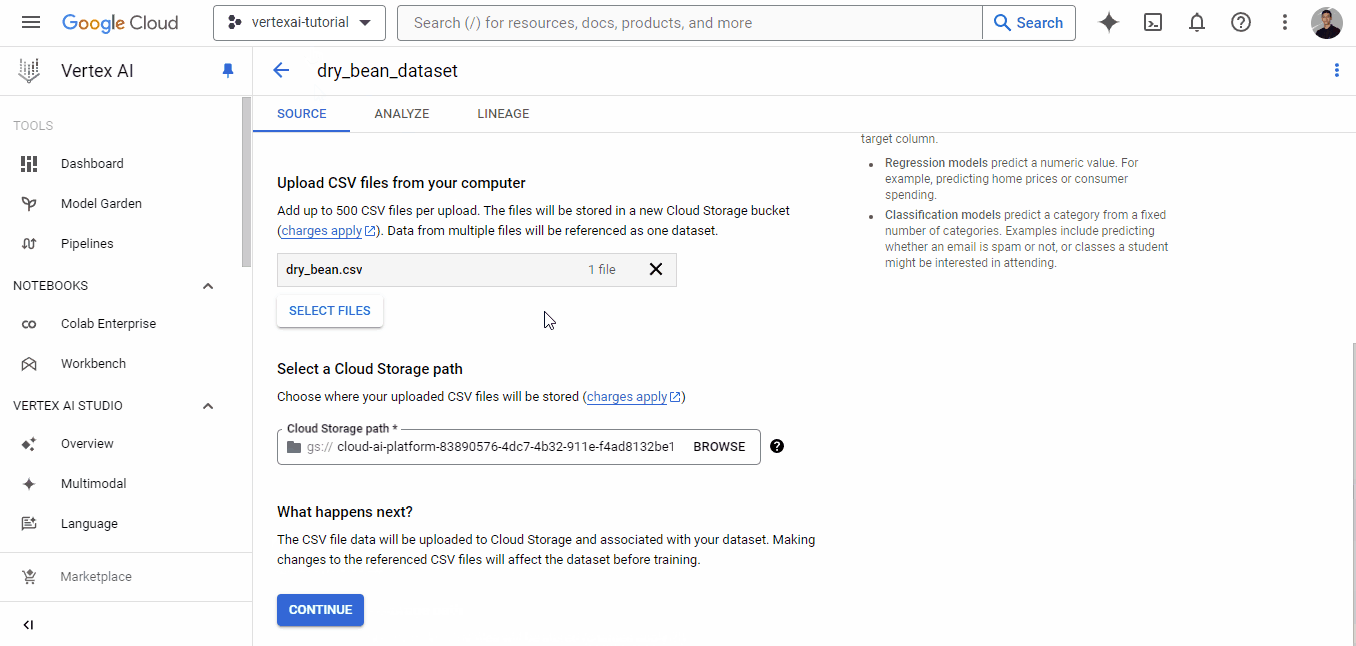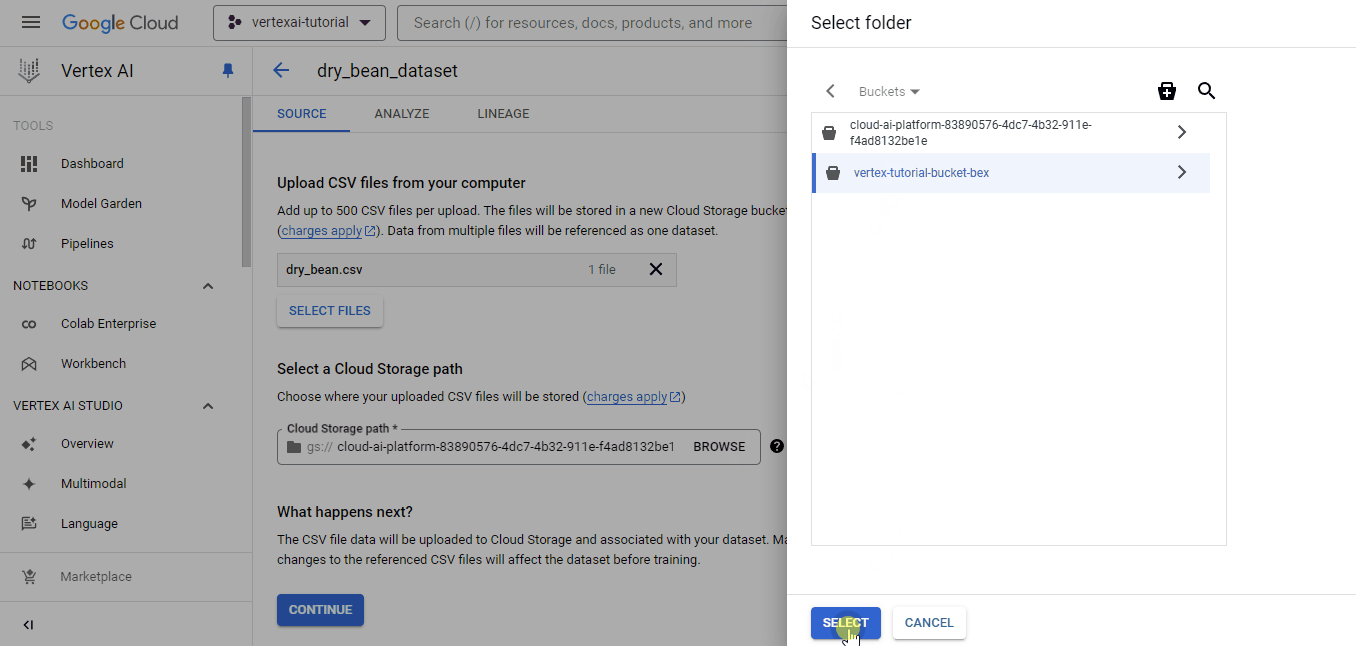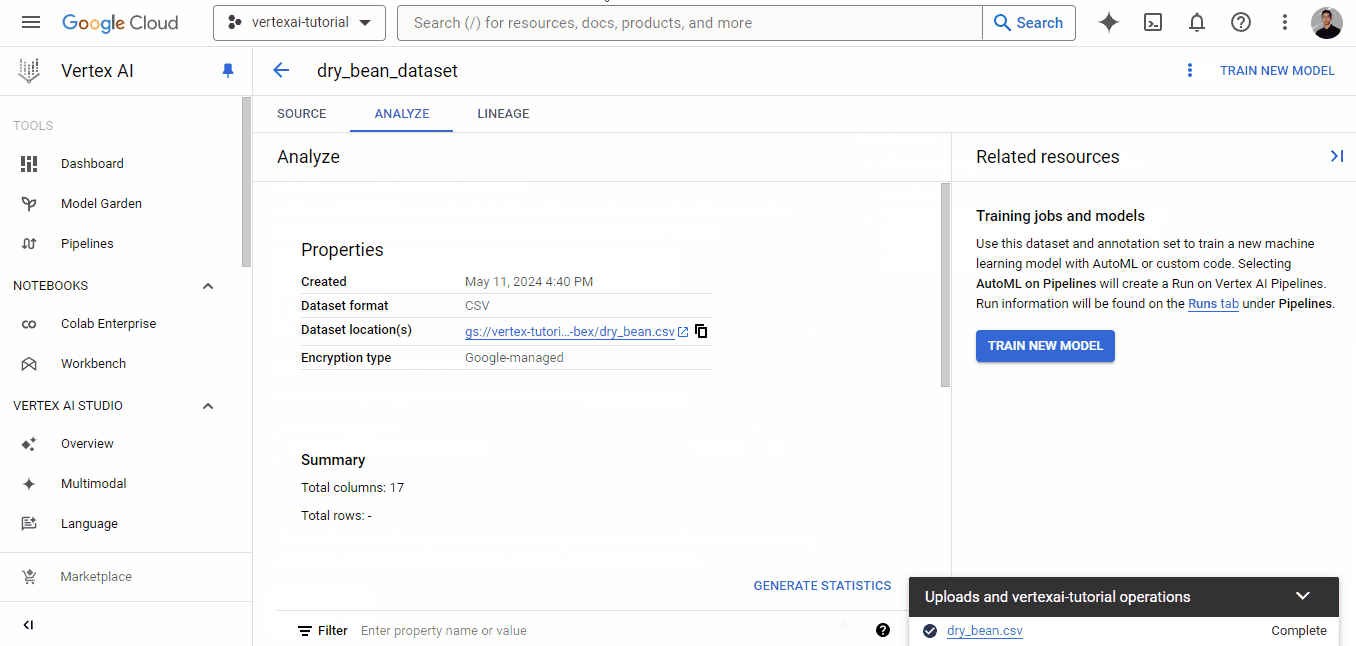
Após o upload bem-sucedido do conjunto de dados, você verá a guia "Analyze" (Analisar), que mostra metadados básicos sobre o arquivo CSV. Você também verá um botão "TRAIN NEW MODEL" (Treinar novo modelo), que iniciará um trabalho de treinamento do AutoML.
No entanto, não usaremos esse botão, pois ele é para iniciantes completos em ML. Em vez disso, usaremos o Vertex AI Workbench para configurar um ambiente de codificação do Jupyterlab e recursos de computação para executar o AutoML e as bibliotecas personalizadas.
Como a Vertex AI é uma plataforma unificada, ela também oferece ambientes de desenvolvimento chamados workbenches. Para criar uma bancada de trabalho, vá para sua própria guia e siga as instruções no GIF abaixo:
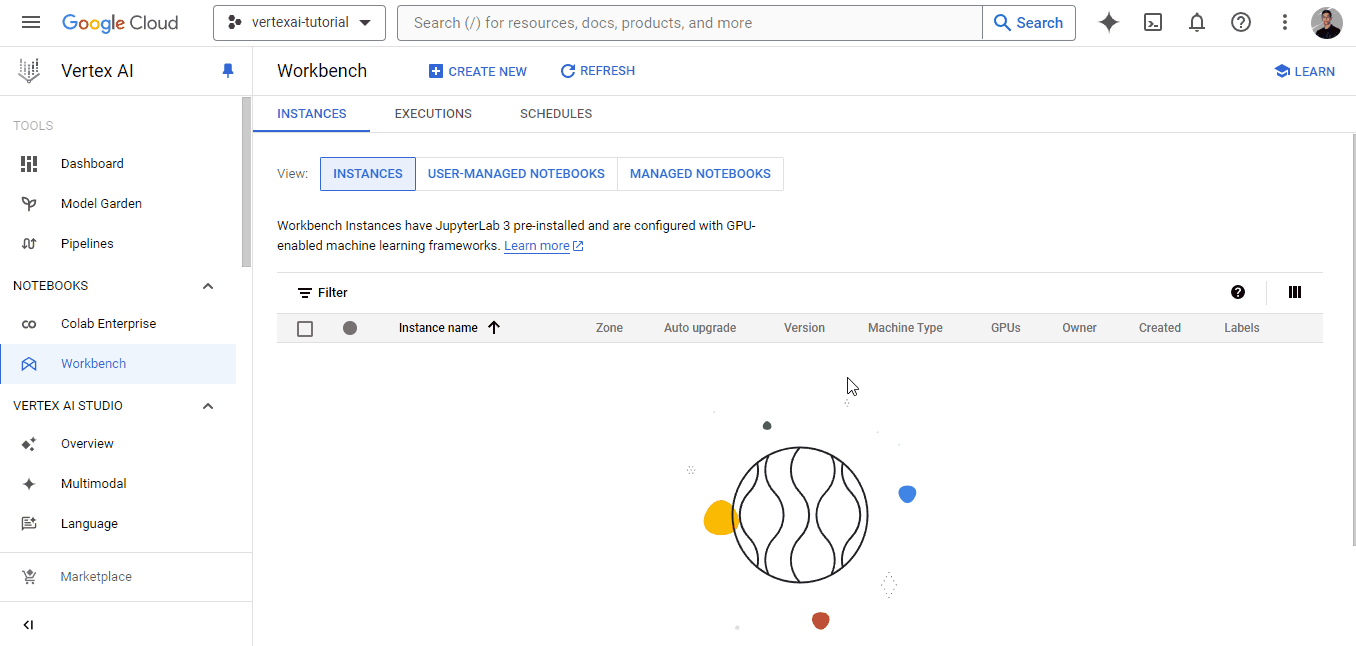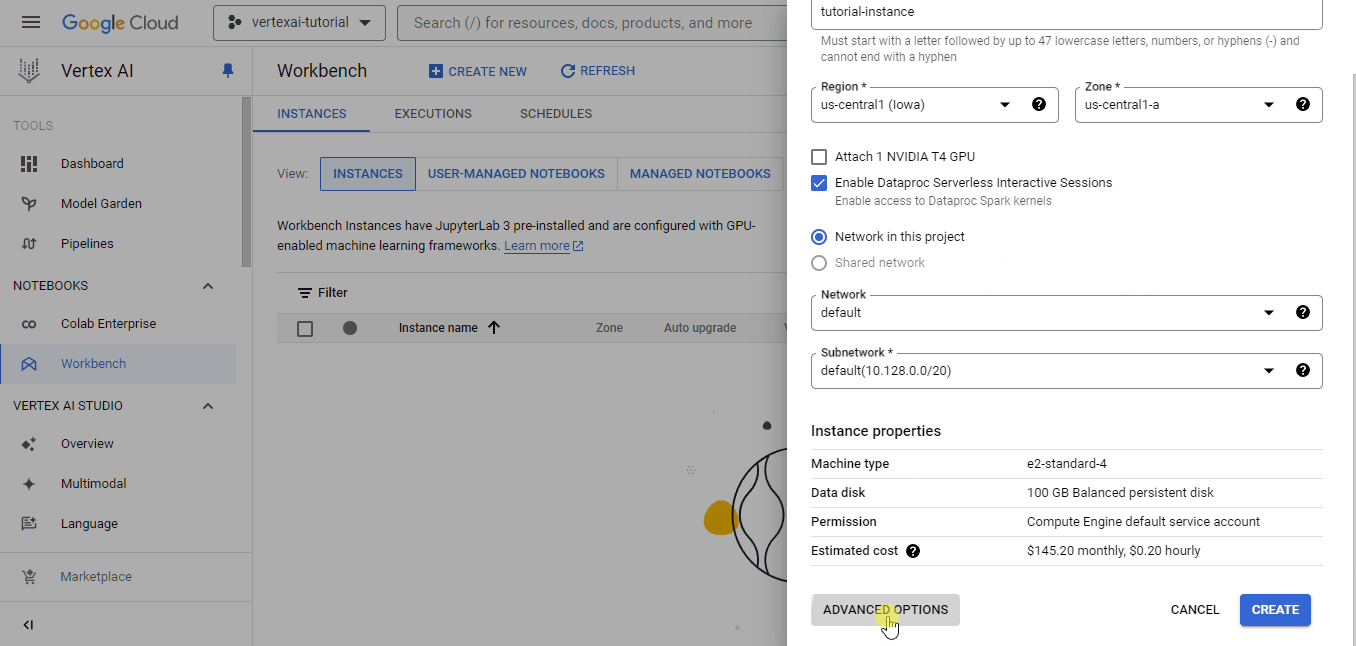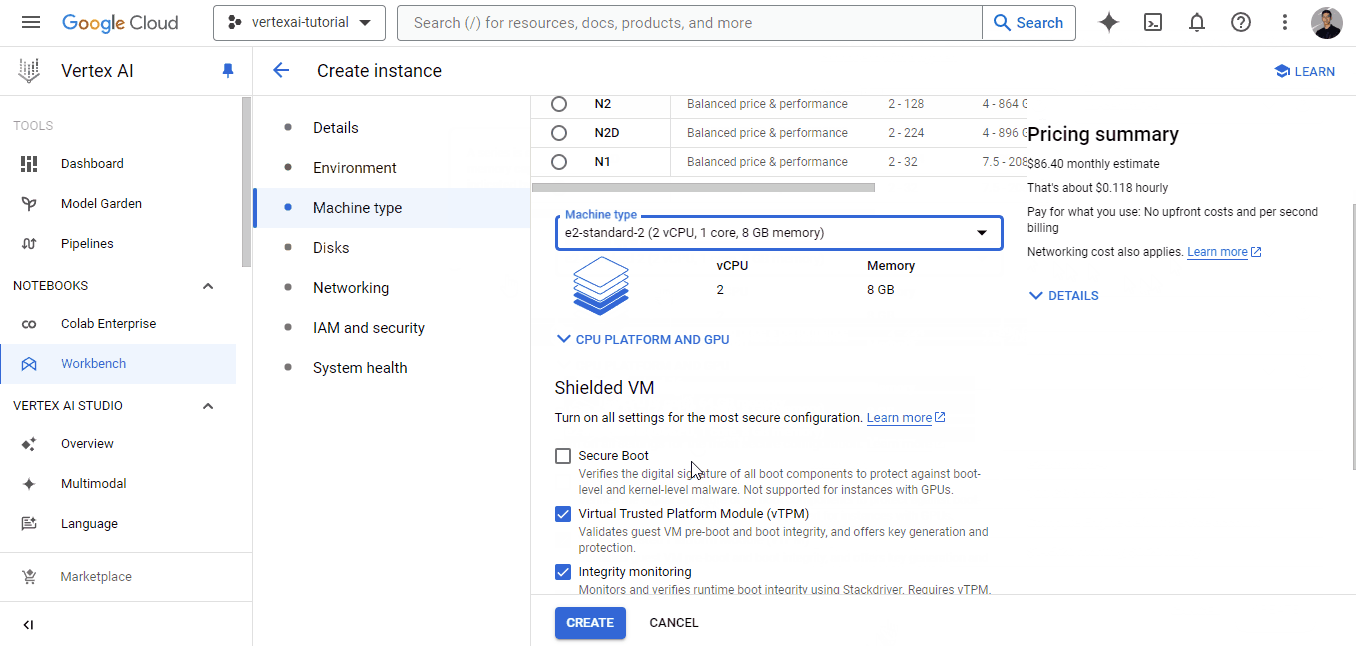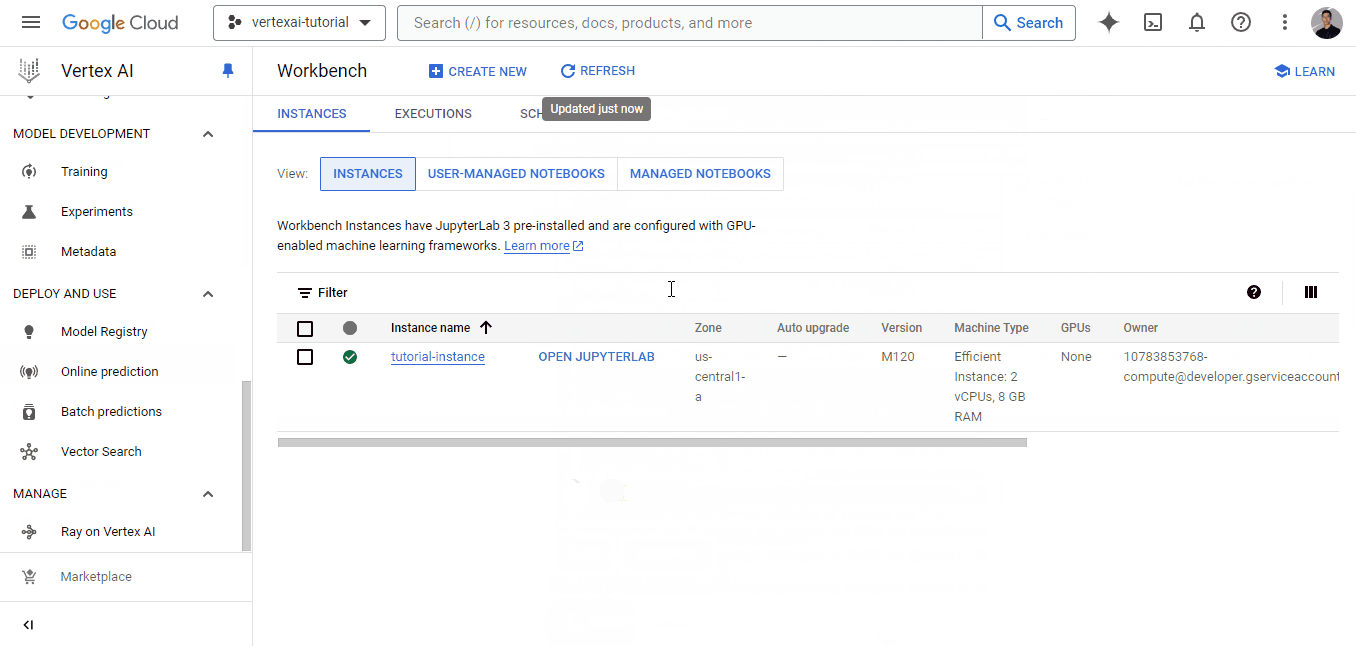
Cada bancada de trabalho vem com o Jupyterlab 3 pré-instalado. Portanto, você só precisa configurar as opções de hardware com base no seu orçamento e nas suas necessidades. Como temos um conjunto de dados bem pequeno, escolhi a instância mais fraca para ilustrar, que custa apenas ~0,12$ por hora (recomendo que você escolha uma máquina com mais núcleos de CPU para agilizar os cálculos).
Também alterei a duração do desligamento ocioso para 10 minutos para que o ambiente pare automaticamente se eu esquecer de desligá-lo.
O workbench levará algum tempo para ser inicializado. Quando isso acontecer, o botão "OPEN JUPYTERLAB" será exibido e você poderá clicar nele:
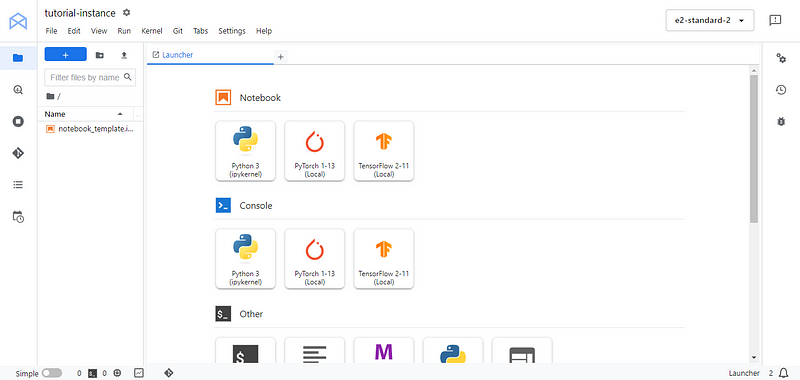
Você será direcionado para a interface conhecida do Jupyterlab. A partir daí, crie um novo notebook Python 3 e renomeie-o para o nome que você quiser. Na primeira célula, instale/atualize o SDK dos serviços do Google Cloud google-cloud-aiplatform:
!pip3 install --upgrade --quiet google-cloud-aiplatform
Em seguida, você pode listar os projetos disponíveis em sua conta com gcloud config list:
!gcloud config list
[compute]
region = us-central1
[core]
account = # HIDDEN #
disable_usage_reporting = True
project = vertexai-tutorial-423010
[dataproc]
region = us-central1
Your active configuration is: [default]
gcloud e gsutil são utilitários de terminal disponíveis em todas as bancadas de trabalho. Eles permitem que você gerencie seus serviços do Google Cloud com eficiência.
Na saída impressa, salve as seguintes informações como variáveis Python:
PROJECT_ID = 'vertexai-tutorial-423010'
BUCKET_URI = 'gs://vetex-tutorial-bucket-bex'
REGION = 'us-central1'
Não se esqueça de alterar BUCKET_URI para o nome do seu próprio balde. Em seguida, importe o submódulo aiplatform e o inicialize:
from google.cloud import aiplatform as ai
ai.init(project=PROJECT_ID, location=REGION, staging_bucket=BUCKET_URI)
aiplatform servirá como um SDK para você interagir com os recursos de IA da Vertex.
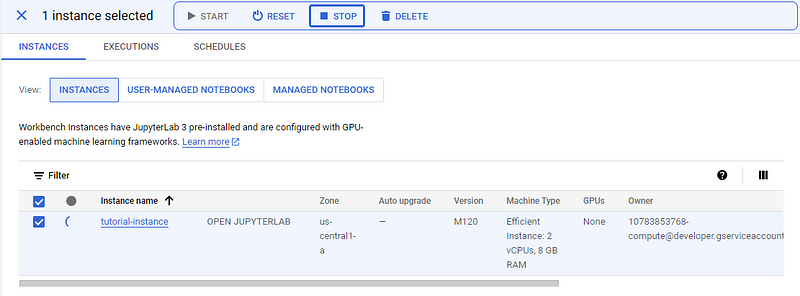
Quando você terminar de seguir o tutorial ou fizer uma pausa, não se esqueça de STOP a instância para evitar custos indesejados.
Agora, vamos treinar um modelo com o AutoML, que, como mencionamos anteriormente, cuida de todo o trabalho pesado para nós e retorna o melhor modelo que poderia treinar para o conjunto de dados fornecido. Isso significa que, para aproveitar ao máximo o AutoML, você deve garantir que o conjunto de dados que está alimentando seja o de maior qualidade possível. Portanto, vale a pena dedicar algum tempo para projetar novos recursos e executar as etapas de pré-processamento com antecedência.
O AutoML pré-processa o conjunto de dados internamente, mas não pode corrigir todos os problemas do seu conjunto de dados.
No entanto, nesta seção, treinaremos apenas um modelo AutoML de linha de base, sem pré-processamento ou engenharia de recursos, para simplificar.
A primeira coisa que queremos fazer é carregar o conjunto de dados CSV do nosso bucket e passar algum tempo explorando-o. Você pode usar o conjunto de dados CSV para fazer isso. Lembre-se de que EDA é uma etapa importante, e você pode aprender mais em nosso curso Exploratory Data Analysis in Python!
import pandas as pd
# Path to your CSV file in GCS bucket
gcs_path = "gs://vertex-tutorial-bucket-bex/dry_bean.csv"
beans = pd.read_csv(gcs_path)
beans.head()

A boa notícia é que o pandas pode baixar arquivos dos caminhos do GCS. O único problema é que o código acima só funciona nos workbenches do Vertex AI, pois eles já estão autenticados com suas credenciais do Google Cloud.
Não faremos uma análise profunda do conjunto de dados, pois isso nos distrairá do ponto principal do artigo. Portanto, vamos nos contentar em imprimir algumas estatísticas e gráficos resumidos:
beans.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 13611 entries, 0 to 13610
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Area 13611 non-null int64
1 Perimeter 13611 non-null float64
2 MajorAxisLength 13611 non-null float64
3 MinorAxisLength 13611 non-null float64
4 AspectRation 13611 non-null float64
5 Eccentricity 13611 non-null float64
6 ConvexArea 13611 non-null int64
7 EquivDiameter 13611 non-null float64
8 Extent 13611 non-null float64
9 Solidity 13611 non-null float64
10 roundness 13611 non-null float64
11 Compactness 13611 non-null float64
12 ShapeFactor1 13611 non-null float64
13 ShapeFactor2 13611 non-null float64
14 ShapeFactor3 13611 non-null float64
15 ShapeFactor4 13611 non-null float64
16 Class 13611 non-null object
dtypes: float64(14), int64(2), object(1)
memory usage: 1.8+ MB
Portanto, há 15 recursos numéricos e uma única coluna de destino -Class. Há apenas cerca de 13 mil registros e não há valores ausentes. Isso simplificará muito o treinamento.
Vamos salvar os nomes dos recursos em uma lista separada, pois poderemos precisar deles mais tarde:
feature_names = beans.columns.tolist()
Agora, vamos criar um gráfico de pares de alguns recursos que parecem importantes:
import seaborn as sns
sns.pairplot(
beans,
vars=["Area", "MajorAxisLength", "MinorAxisLength", "Eccentricity", "roundness"],
hue="Class",
);
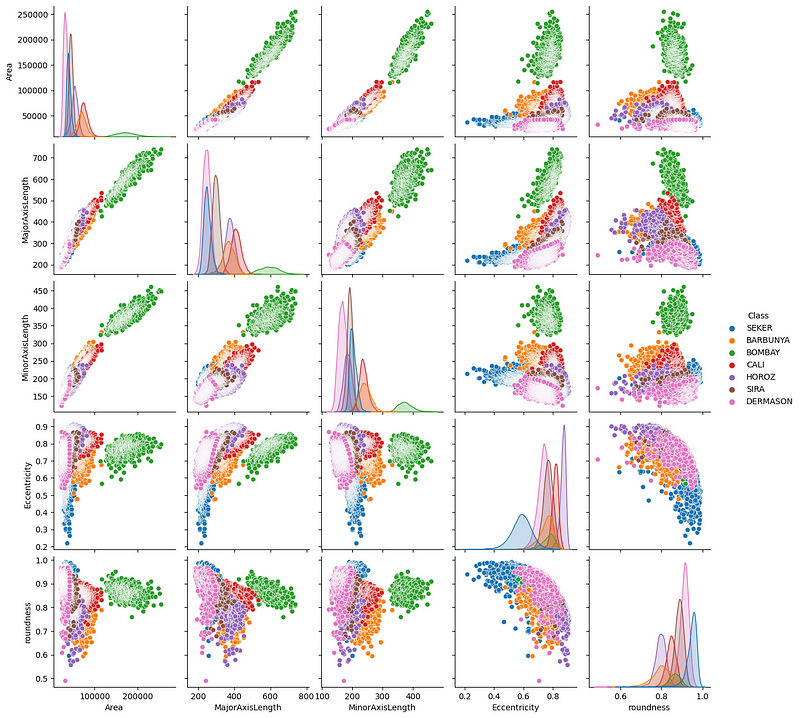
Vemos algumas tendências interessantes - principalmente, parece que o feijão Bombay (verde) está claramente separado dos outros em termos de suas medidas físicas.
Vamos também traçar uma matriz de correlação:
import matplotlib.pyplot as plt
correlation = beans.corr(numeric_only=True)
# Create a square heatmap with center at 0
sns.heatmap(correlation, center=0, square=True, cmap="coolwarm", vmin=-1, vmax=1)
plt.show()
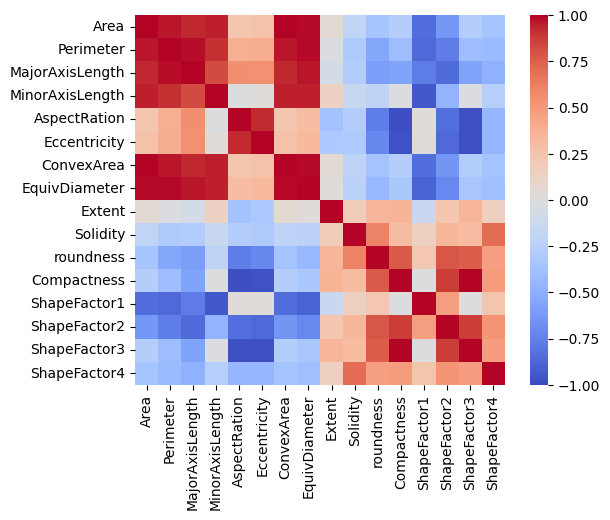
Temos alguns recursos quase perfeitamente correlacionados e isso faz sentido, pois eles estão relacionados a medições físicas. No entanto, também temos alguns pares de recursos que não apresentam correlação ou apresentam uma correlação muito pequena.
Neste ponto, deixarei que você continue essa exploração e tente encontrar algumas perguntas para responder sobre o conjunto de dados.
Para iniciar um trabalho de treinamento do AutoML, primeiro precisamos de um objeto de conjunto de dados compatível com ele:
ds = ai.TabularDataset.create(
display_name="dry_bean_dataset", gcs_source=gcs_path
)
TabularDataset created.
type(ds)google.cloud.aiplatform.datasets.tabular_dataset.TabularDataset
ds.resource_name
'projects/10783853768/locations/us-central1/datasets/4978116960081412096'
Usamos o método TabularDataset.create para inicializá-lo como ds. O Vertex AI atribui a ele seu próprio nome, que pode ser acessado por meio do atributo resource_name.
Agora, inicializamos o trabalho com a classe ai.AutoMLTabularTrainingJob. Ele requer dois argumentos:
job = ai.AutoMLTabularTrainingJob(
display_name="dry-bean-classification",
optimization_prediction_type="classification",
)
Em seguida, executamos o método run do trabalho:
model = job.run(
dataset=ds,
target_column="Class",
training_fraction_split=0.8,
validation_fraction_split=0.1,
test_fraction_split=0.1,
model_display_name="baseline-classification-model",
disable_early_stopping=False,
)
Os parâmetros do método são bastante autoexplicativos. O código levará algum tempo para ser executado (dependendo do poder de computação que você tem).
Se você for à guia "MODEL DEVELOPMENT > TRAINING" (Desenvolvimento de modelo > Treinamento) do seu painel e clicar no nome do trabalho, verá o progresso do treinamento ao vivo. A imagem abaixo mostra que o treinamento está no estágio de pré-processamento:
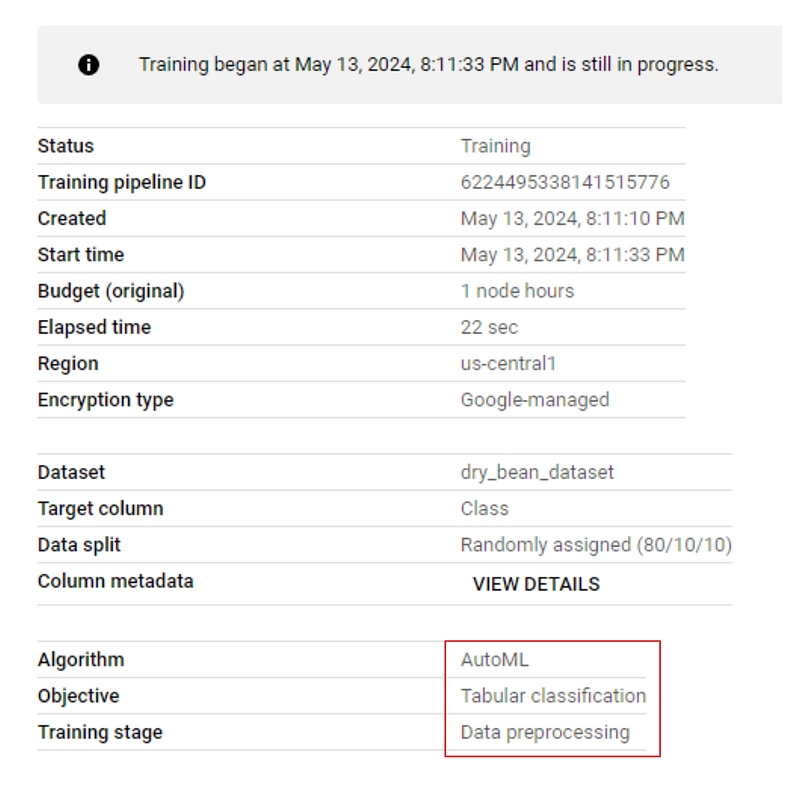
Quando o treinamento for concluído, vá para a guia de treinamento novamente e clique no nome do modelo. Desta vez, você terá métricas de desempenho listadas junto com o modelo:
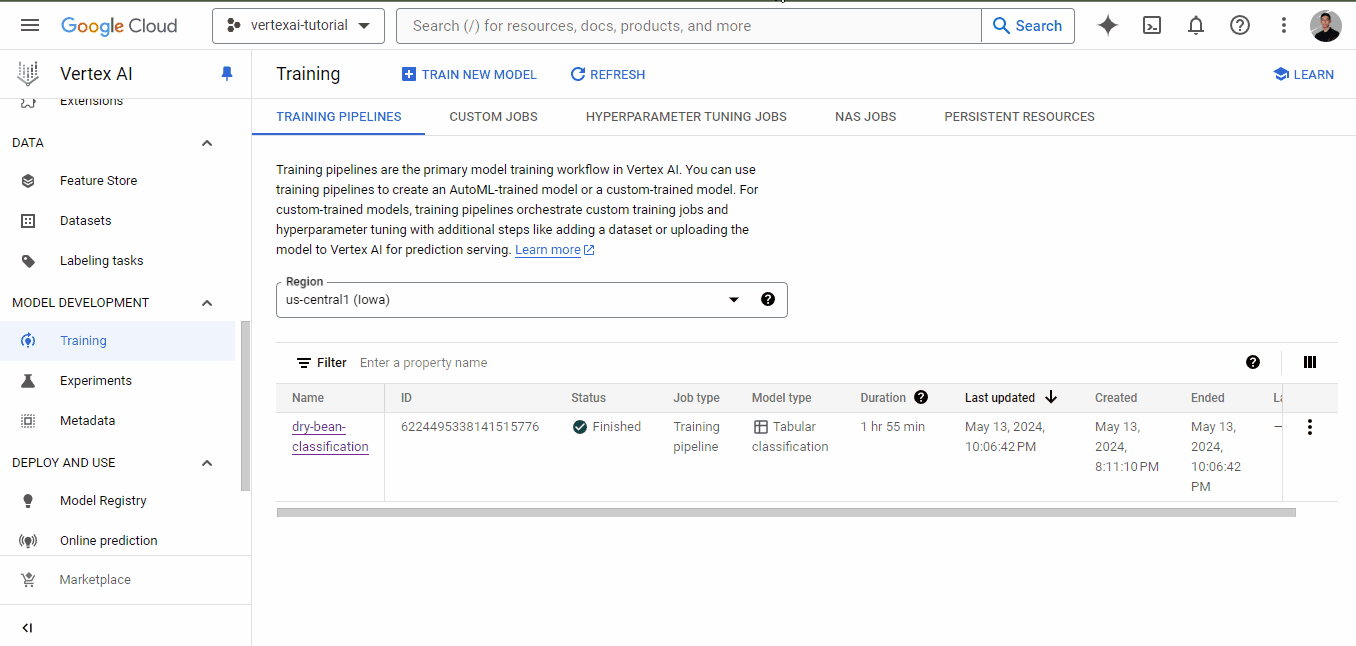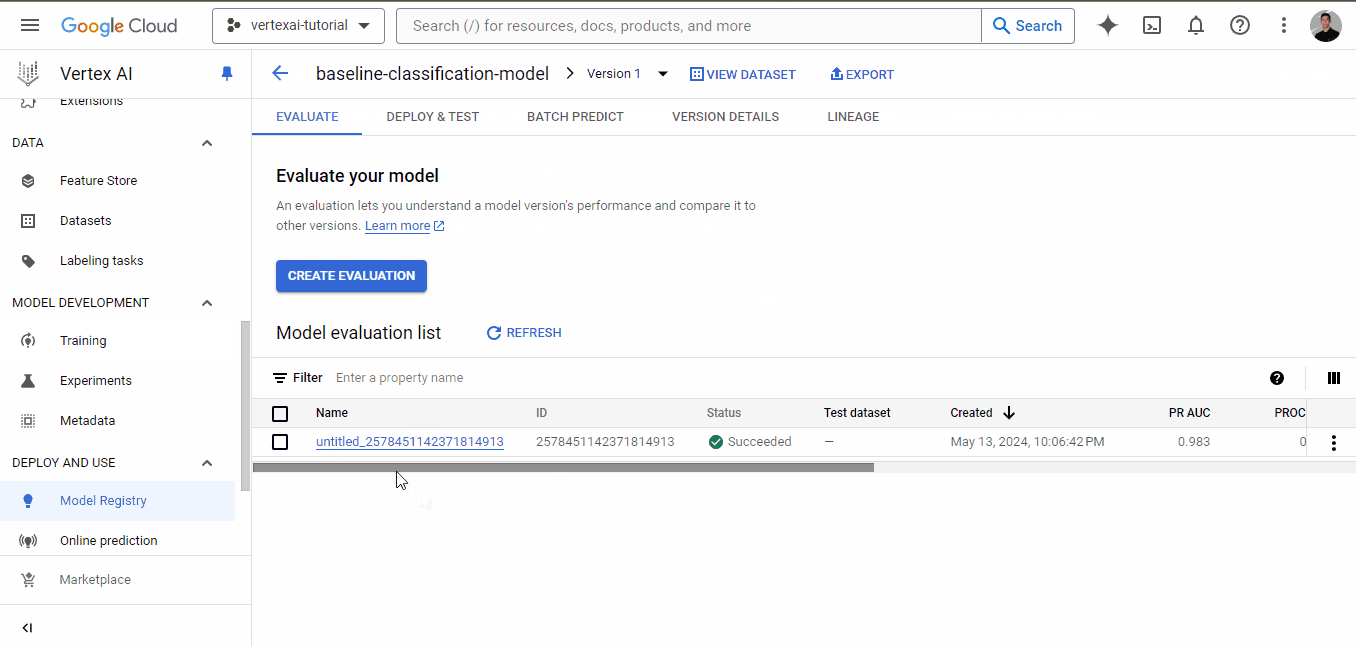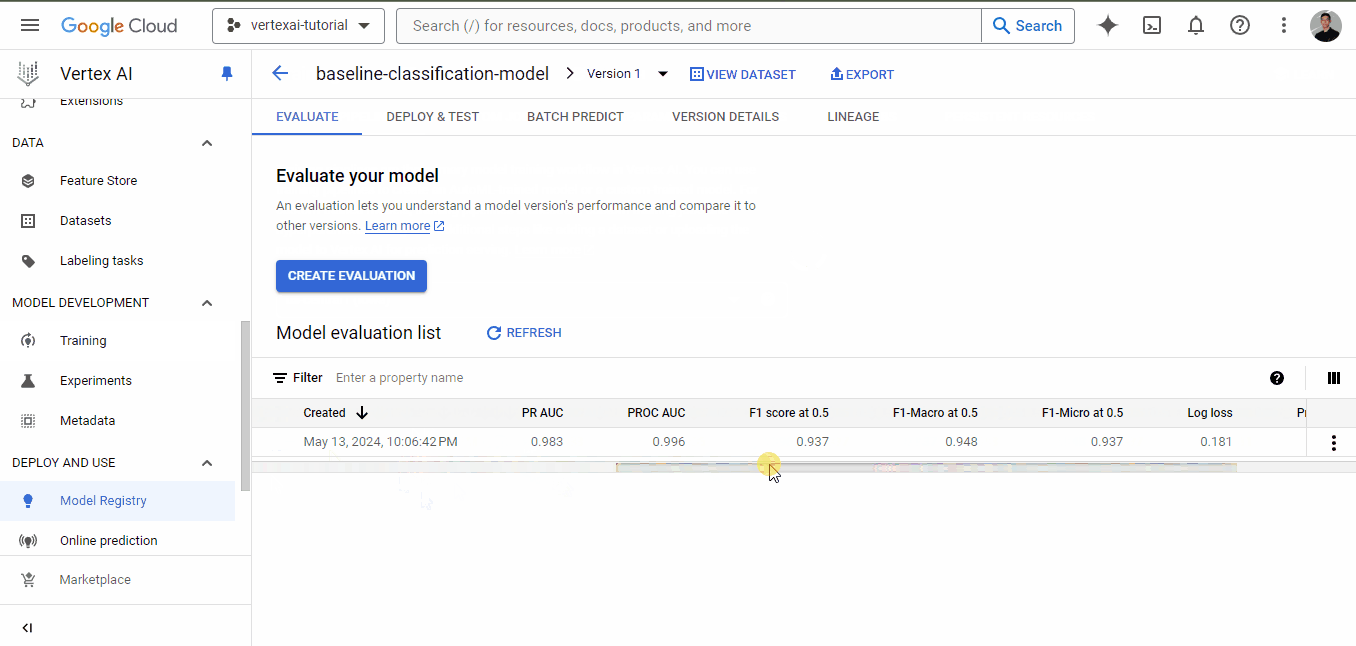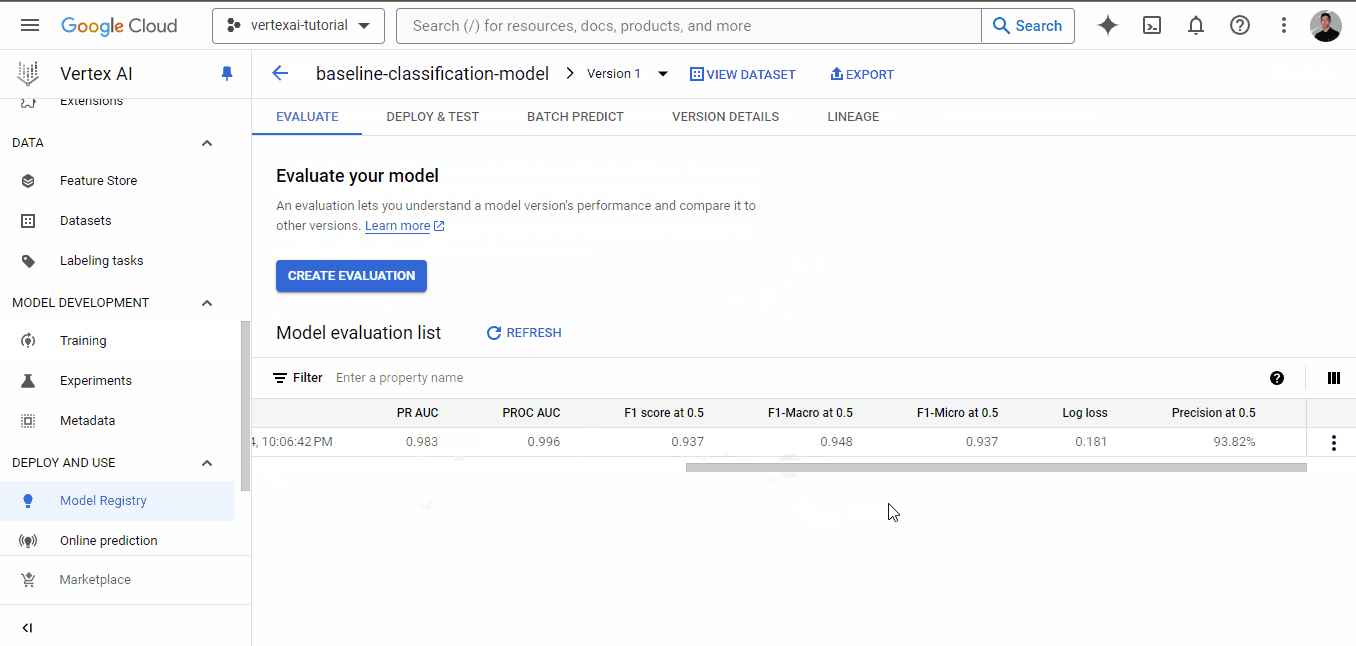
Como você pode ver, mesmo para um modelo de linha de base, temos métricas muito boas, todas acima de 0,90.
Agora, podemos implementar o site model com uma única linha de código:
endpoint = model.deploy(machine_type="n1-standard-4")
O método deploy requer apenas um único argumento: o tipo de máquina para executar a inferência. Na verdade, não executarei a linha acima, pois a implantação incorre em custos adicionais enquanto o modelo estiver on-line.
No entanto, se você executá-lo, o método deploy retornará um objeto Endpoint para o qual podemos enviar solicitações:
prediction = endpoint.predict(
[
{
"Area": "30099",
"Perimeter": "638.8209999999999",
"MajorAxisLength": "237.14191130827916",
"MinorAxisLength": "162.3034300714102",
"AspectRation": "1.4611022774068396",
"Eccentricity": "0.7290928631259719",
"ConvexArea": "30477",
"EquivDiameter": "195.76321681302556",
"Extent": "0.8036043251902283",
"Solidity": "0.9875972044492568",
"roundness": "0.9268374259664279",
"Compactness": "0.8255108332939839",
"ShapeFactor1": "0.007878730566074592",
"ShapeFactor2": "0.002256976927384019",
"ShapeFactor3": "0.6814681358857279",
"ShapeFactor4": "0.9956946453228307",
}
]
)
print(prediction)
Ele tem um método predict que aceita uma lista de amostras a serem previstas. As amostras devem ser fornecidas no formato JSON.
Você também pode usar o painel para implantar modelos. Se você for para a guia "MODEL REGISTRY", verá o modelo listado lá. Clique em seu nome e escolha a guia "DEPLOY & TEST":
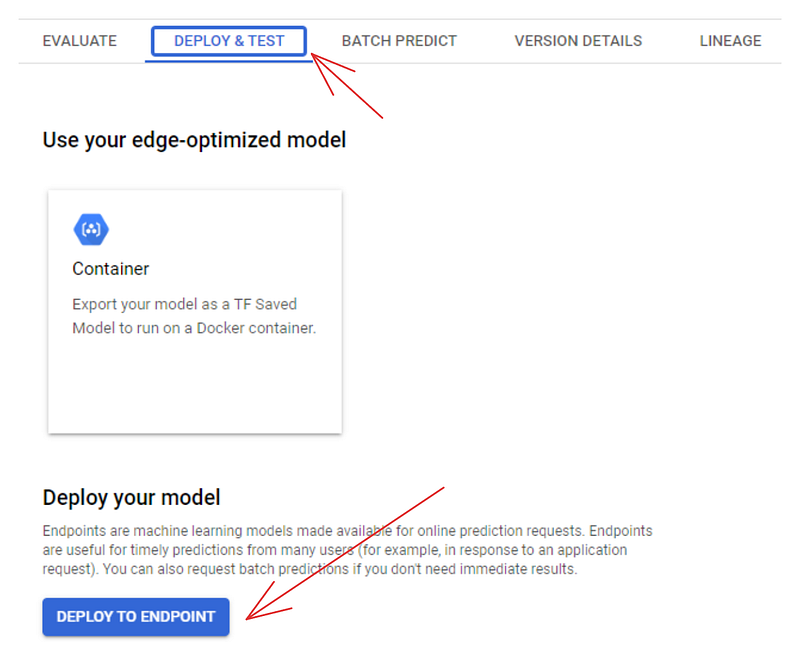
Clicar no botão "DEPLOY TO ENDPOINT" leva você a uma página separada, na qual é possível configurar a máquina para implantar o modelo. Mas antes de fazer isso, você pode testá-lo na área abaixo do botão de implantação:
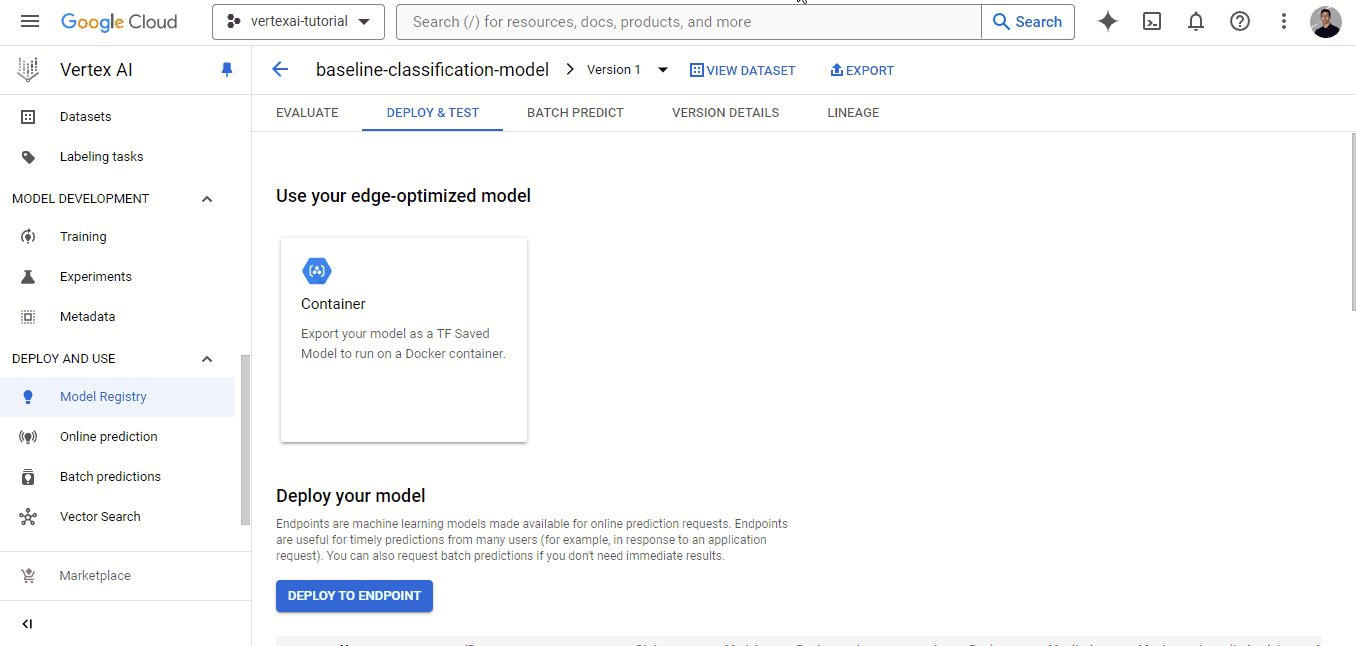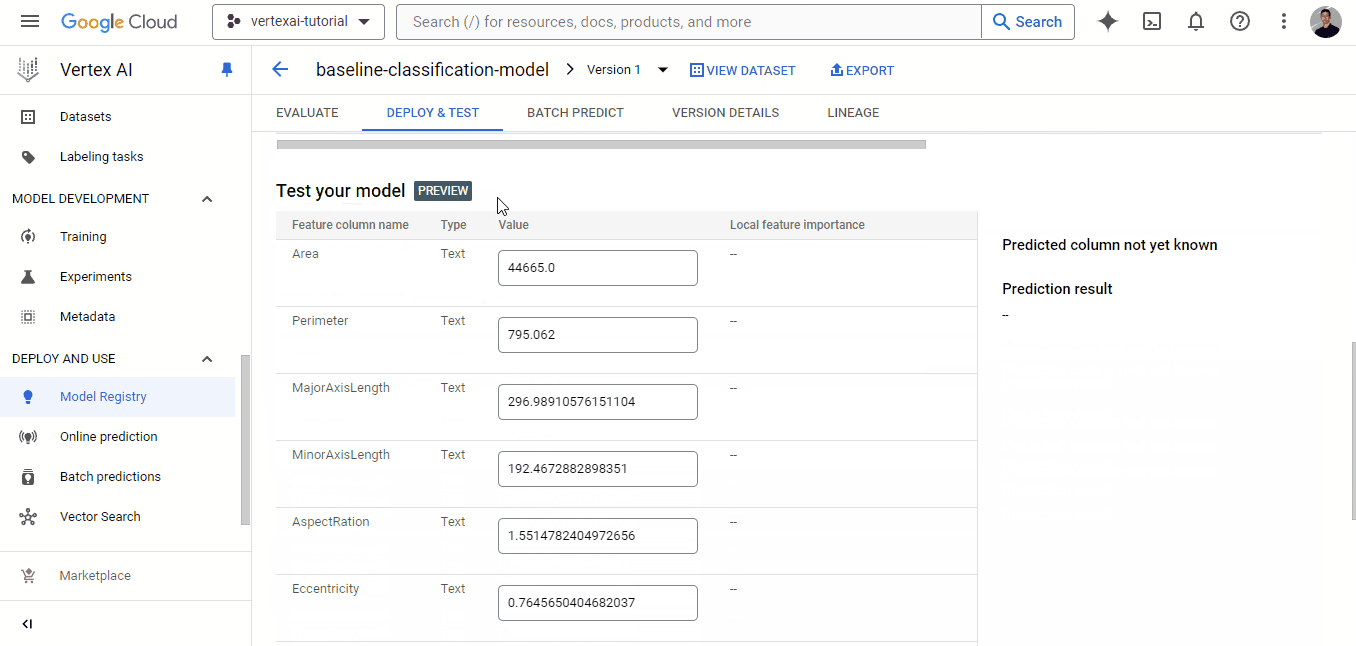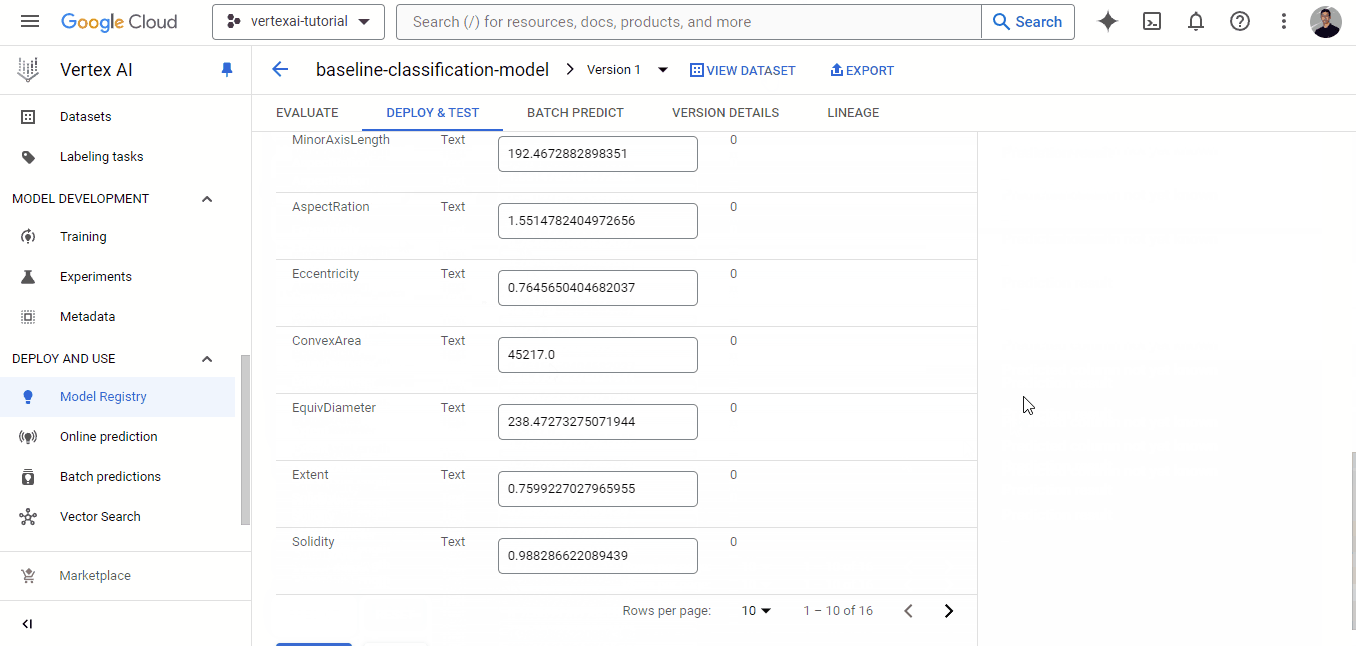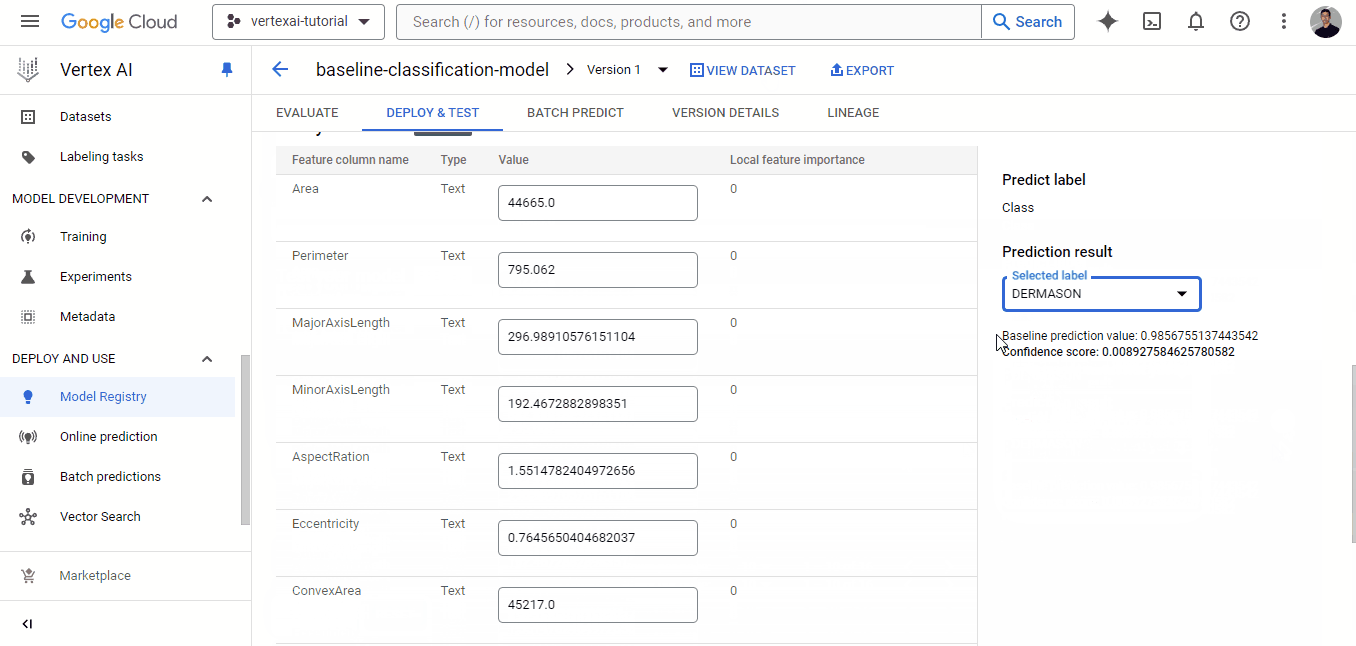
A implantação de modelos personalizados no Vertex AI é mais desafiadora do que a dos modelos AutoML e também custa mais porque haverá alguns contêineres do Docker envolvidos, além das despesas com o Workbench e a implantação. Se você estiver disposto a isso, vamos lá!
O treinamento personalizado envolve começar com um script de treinamento de modelo personalizado. Nesse script, podemos fazer qualquer coisa, desde que você faça isso:
Em seguida, esse script de treinamento deve ser convertido em um contêiner do Docker e, depois, enviado para o Google Container Registry. A partir daí, podemos usar o Vertex AI Python SDK ou o painel para treinar o modelo personalizado.
Primeiro, vamos criar a estrutura de diretórios conforme recomendado por este laboratório de código do Google. Em sua bancada de trabalho, alterne para o terminal iniciando um novo iniciador:
Em seguida, crie um novo diretório chamado "dry-beans" e mude para ele:
$ mkdir dry-beans
$ cd dry-beans/
Dentro de dry-beans, crie outro diretório chamado trainer e, dentro dele, o arquivo Python train.py:
$ mkdir trainer
$ touch trainer/train.py
Em seguida, crie um novo Dockerfile:
$ touch Dockerfile
Abra o arquivo e cole o seguinte conteúdo:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-6
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Install XGBoost
RUN pip install xgboost==1.6.2
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Este Dockerfile usa a imagem oficial de aprendizagem profunda fornecida pelo Google Container Registry com o TensorFlow instalado. O arquivo copia nosso diretório trainer e, em seguida, instala o XGBoost. No final, ele executará nosso script Python.
O script em si deve carregar o conjunto de dados Dry Beans do nosso bucket do GCP, treinar um classificador XGBoost nele e salvar o modelo de volta no bucket. Escrevi um script simples que executa essas tarefas neste gist do GitHub (não estou compartilhando-o aqui para economizar espaço).
Copie/cole o código no gist para train.py. Em seguida, de volta ao terminal, instale o XGBoost, já que ele não vem pré-instalado no Workbench escolhido por você, e execute o script:
$ pip install xgboost==1.6.2
$ python trainer/train.py
Se o script for executado sem erros, continue inserindo essas duas variáveis no terminal:
$ PROJECT_ID='vertexai-tutorial-423010' # Replace with your PROJECT_ID from earlier
$ IMAGE_URI="gcr.io/$PROJECT_ID/dry-beans:v1" # This stays the same
Essas variáveis serão usadas quando construirmos o contêiner, e assim faremos:
$ docker build ./ -t $IMAGE_URI
A construção levará algum tempo. Após a conclusão, execute o contêiner para garantir que tudo esteja funcionando sem problemas:
$ docker run $IMAGE_URI
Model trained successfully!
Model uploaded successfully!
Se você receber as mensagens de sucesso acima, então o contêiner está pronto para ser enviado:
$ docker push $IMAGE_URINesse ponto, a maior parte da batalha está concluída. Agora, podemos ir para o painel e criar um trabalho de treinamento personalizado usando o contêiner que acabamos de enviar. Portanto, vá até a guia "MODEL REGISTRY" (Registro de modelo) e clique em "CREATE" (Criar):
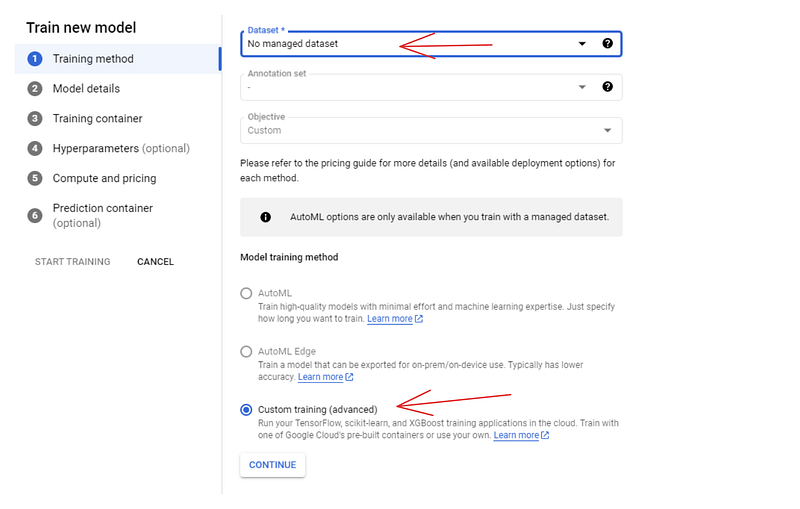
Para o método de treinamento, escolha as opções "Nenhum conjunto de dados gerenciado" e "Treinamento personalizado". No painel seguinte (Detalhes do modelo), dê um nome ao modelo -dry-beans-classifier.
No painel do contêiner de treinamento:
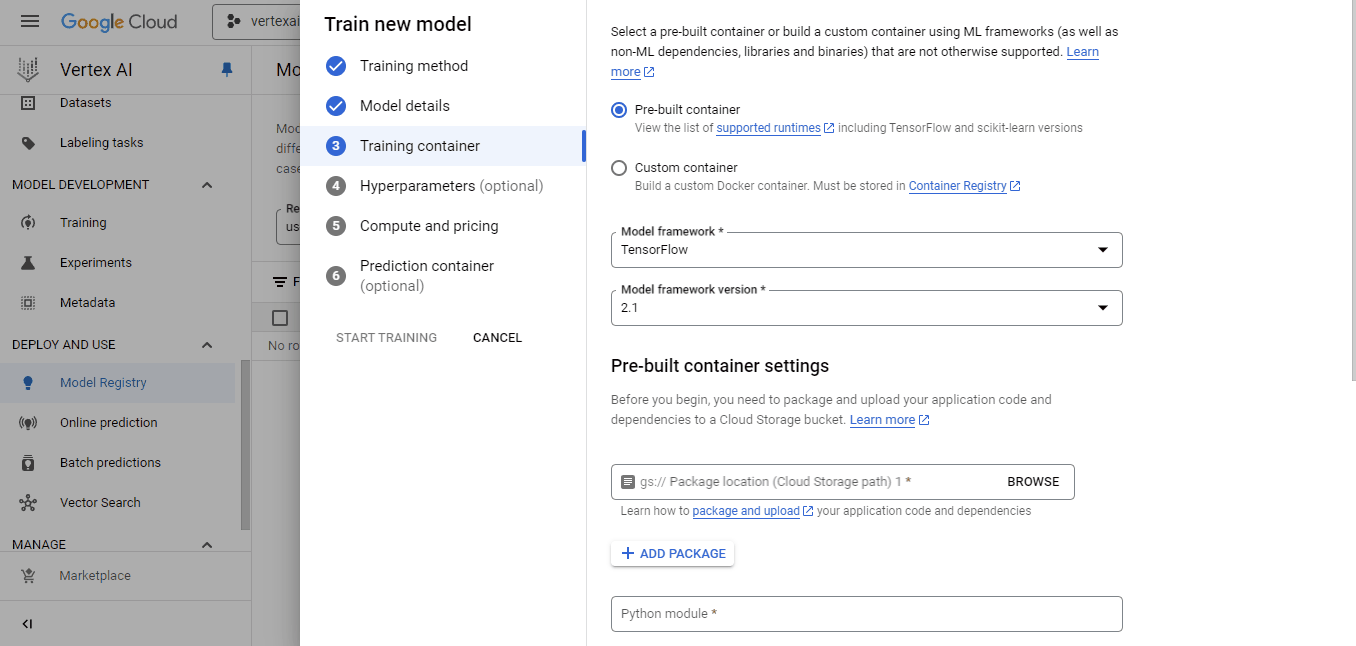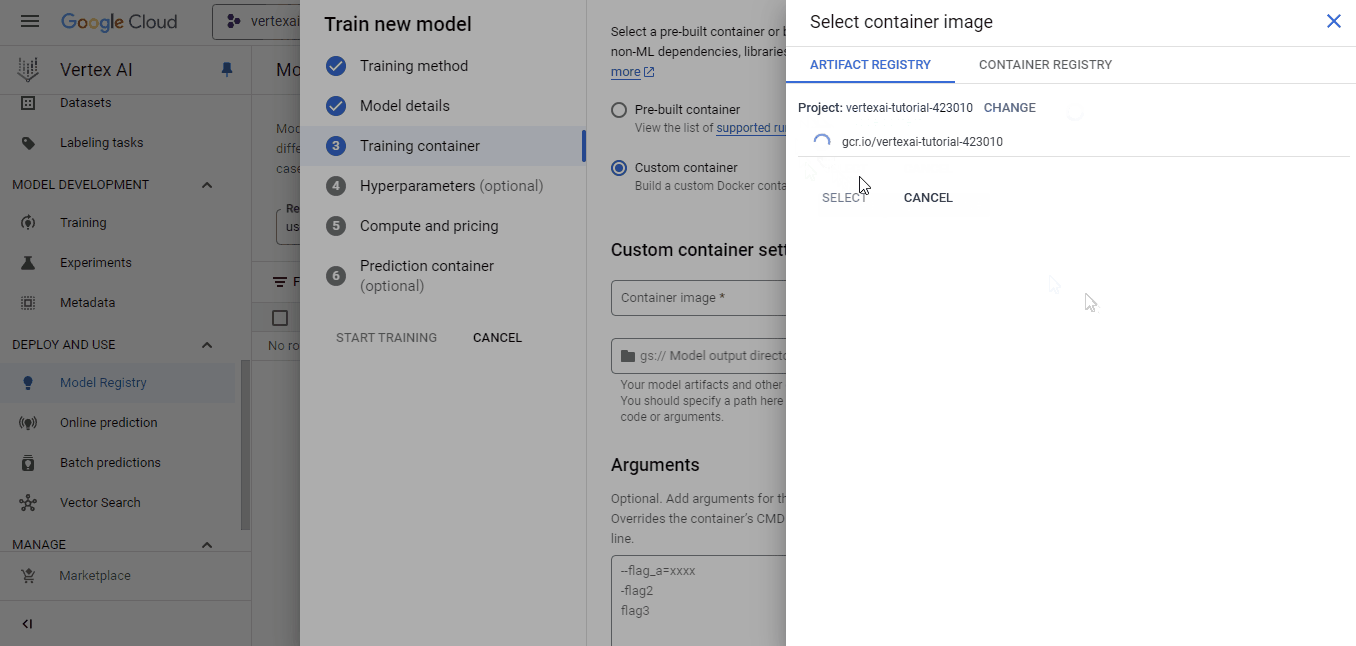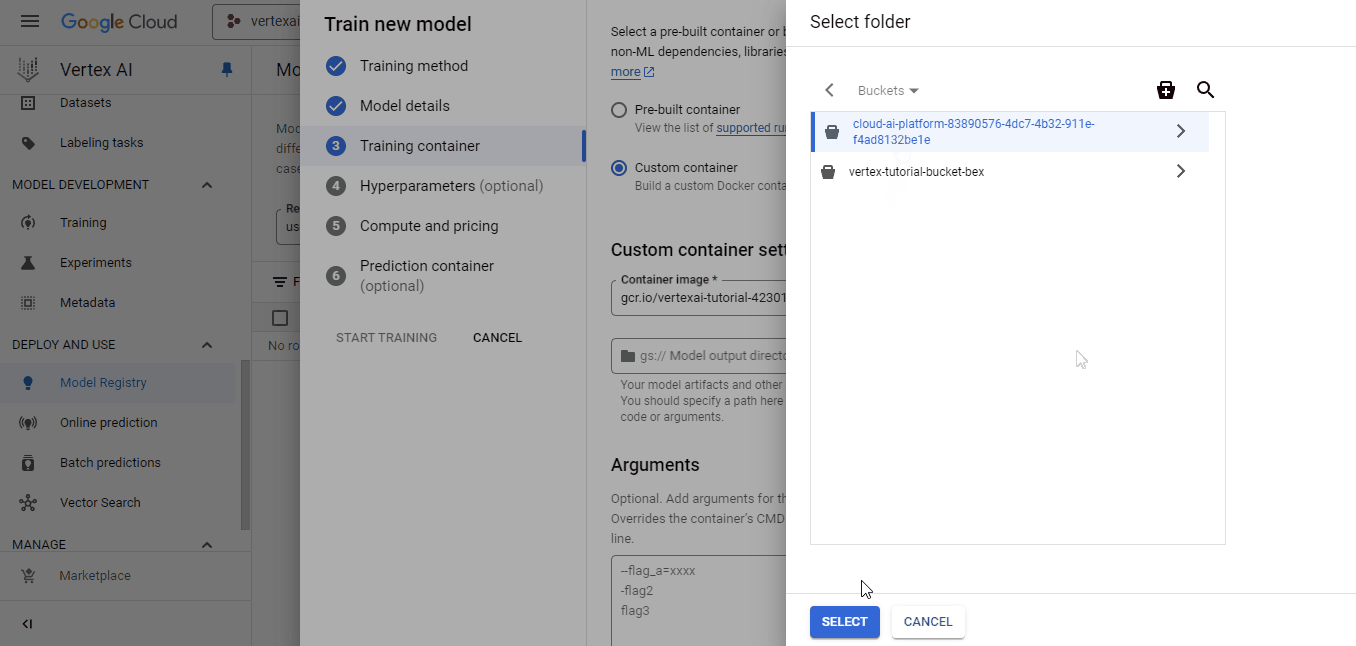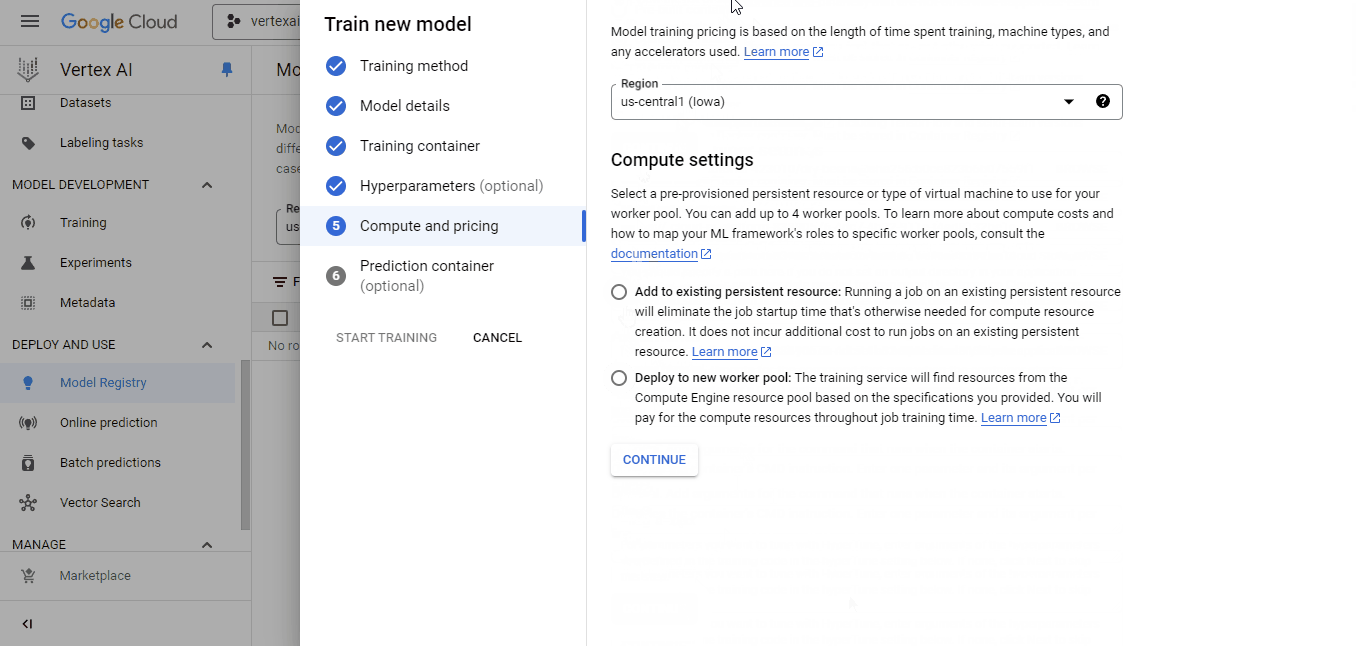
Selecione o contêiner que enviamos para a imagem personalizada e o bucket cloud-ai-platform para a saída do modelo. Em seguida, clique em continuar até que você chegue ao painel "Compute and pricing" (Computação e preços):
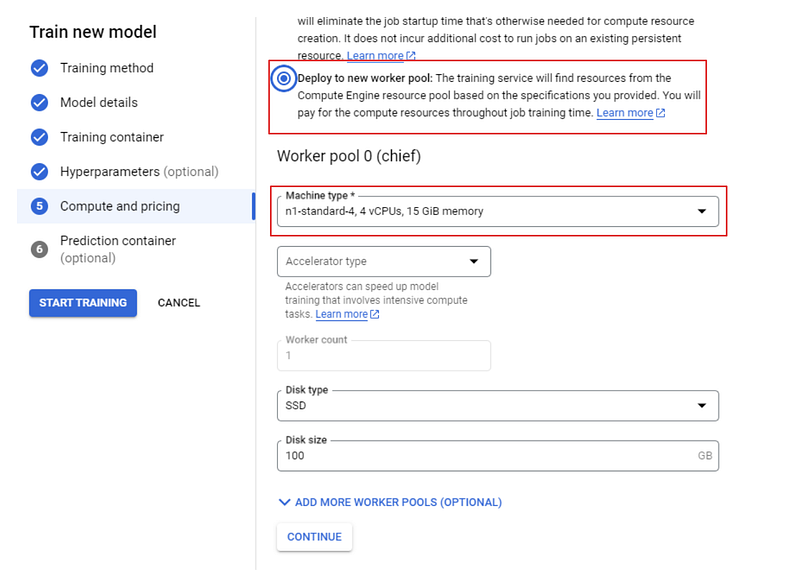
Escolha uma máquina n1 padrão com 4 CPUs e, por fim, clique em "START TRAINING" (Iniciar treinamento). Em seguida, vá para a guia "TRAINING" (Treinamento) do seu painel.
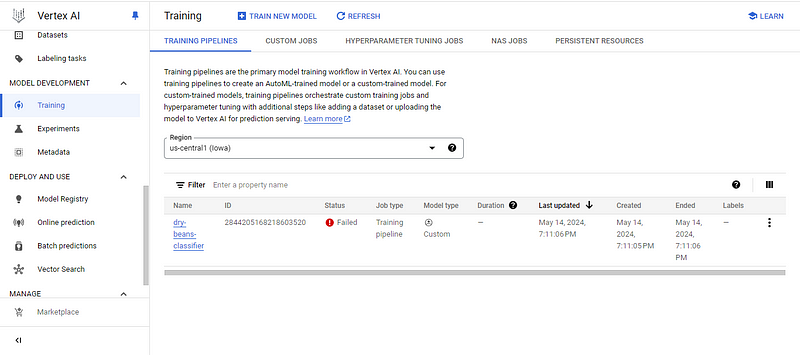
Nesse ponto, você verá uma destas duas coisas:
Eu tenho o primeiro, então vamos investigar o motivo clicando no nome do modelo:
![]()
O erro está me dizendo que excedi o número permitido de CPUs de treinamento personalizadas. Eu me aprofundei no problema e o que encontrei foi muito decepcionante.
Normalmente, o GCP fornece pelo menos 20 cotas de CPU para qualquer região de computação, mas depois de verificar meu perfil, descobri que minha cota era de apenas 1. Isso significa que não pude executar nenhum trabalho de treinamento personalizado, pois todas as máquinas oferecidas pelo Google têm pelo menos duas CPUs.
Tentei aumentar minha cota usando as respostas deste tópico do StackOverflow, mas elas não funcionaram. A mensagem que recebi foi que os novos usuários do Vertex AI só podiam ter uma única unidade de CPU. Se eu quisesse aumentar minha cota, precisaria enviar um tíquete de suporte, que, como se vê, não é gratuito (você precisa de um contrato de suporte pago).
Portanto, se você não tiver sorte como eu, tente as respostas no tópico SO. Elas funcionaram para algumas pessoas, mas se não funcionarem para você, sua única opção é entrar em contato com o suporte.
Mas se você tiver sorte e o treinamento for concluído, poderá implantar o modelo usando as mesmas etapas que descrevi para os modelos AutoML.
A Vertex AI é uma plataforma enorme com muitos recursos. Neste tutorial, mal arranhamos a superfície, mas cobrimos os blocos de construção mais importantes da plataforma. Ao dominar a criação de baldes de armazenamento, bancadas de trabalho e trabalhos de treinamento, você estará bem equipado para explorar o restante da plataforma.
Se você quiser saber mais sobre os serviços do Google Cloud, confira estes recursos relacionados recomendados:
Continue sua jornada de IA hoje mesmo!
Curso
Curso
Curso
blog
Matt Crabtree
11 min
blog
Yuliya Melnik
15 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan




