
Kurs
Marketing Analytics: Predicting Customer Churn in Python
4 Std.
18.4K
Dieses Jahr war ein Jahr der Innovationen im Bereich der Datenwissenschaft, wobei künstliche Intelligenz und maschinelles Lernen die Schlagzeilen beherrschten. Obwohl es keinen Zweifel an den Fortschritten im Jahr 2023 gibt, ist es wichtig zu erkennen, dass viele dieser Fortschritte beim maschinellen Lernen nur durch die richtigen Bewertungsprozesse möglich waren, die die Modelle durchlaufen. Datenpraktiker/innen müssen sicherstellen, dass die Leistung eines maschinellen Lernmodells genau bewertet und gemessen wird. Das ist nicht vorteilhaft, sondern unerlässlich.
Wenn du die Kunst der Datenwissenschaft verstehen willst, führt dich dieser Artikel durch die entscheidenden Schritte der Modellevaluierung mit Hilfe der Konfusionsmatrix, einem relativ einfachen, aber leistungsstarken Werkzeug, das bei der Modellevaluierung häufig eingesetzt wird.
Also lass uns eintauchen und mehr über die Verwirrungsmatrix erfahren.
Die Konfusionsmatrix ist ein Instrument zur Bewertung der Leistung eines Modells und wird visuell in Form einer Tabelle dargestellt. Sie bietet Datenpraktikern einen tieferen Einblick in die Leistung, Fehler und Schwächen des Modells. So können die Datenpraktiker ihr Modell durch Feinabstimmung weiter analysieren.
Lasst uns die Grundstruktur einer Verwirrungsmatrix am Beispiel der Identifizierung einer E-Mail als Spam oder Nicht-Spam kennenlernen.
Um das Konzept einer Verwirrungsmatrix wirklich zu verstehen, schau dir die folgende Visualisierung an:
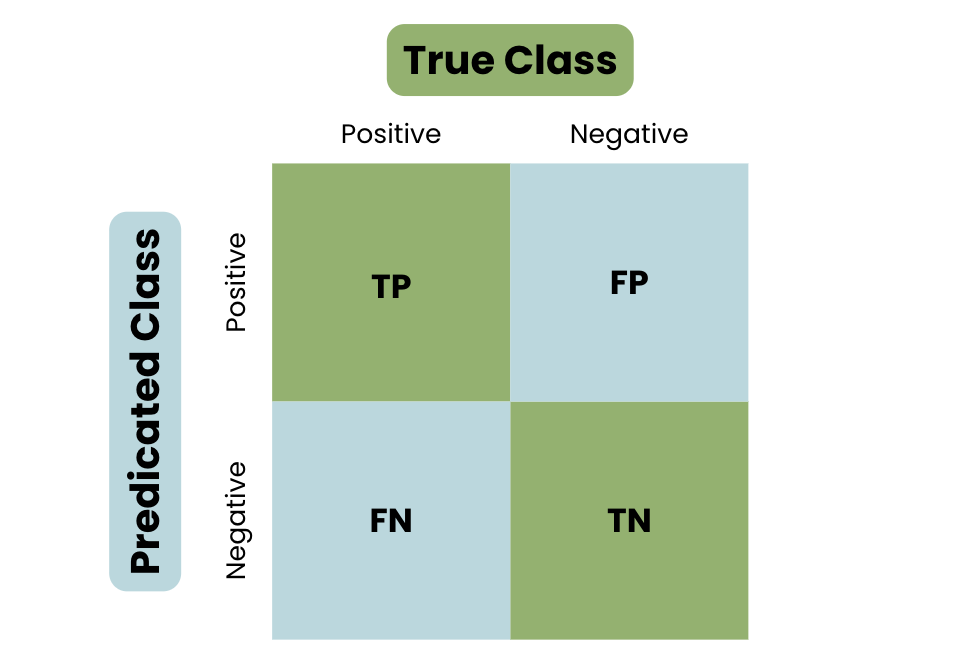
Die Grundstruktur einer Konfusionsmatrix
Um die Konfusionsmatrix genau zu verstehen, ist es wichtig, die wichtigen Metriken zu kennen, die zur Messung der Leistung eines Modells verwendet werden.
Definieren wir wichtige Messgrößen:
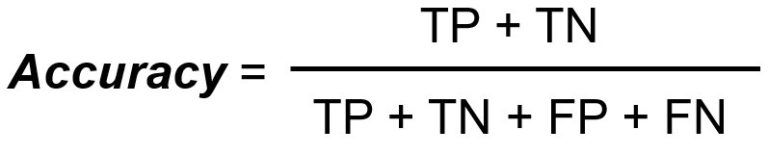
Die Genauigkeit misst die Gesamtzahl der richtigen Klassifizierungen geteilt durch die Gesamtzahl der Fälle.
Recall/Sensitivity misst die Gesamtzahl der echten Positiven dividiert durch die Gesamtzahl der tatsächlichen Positiven.
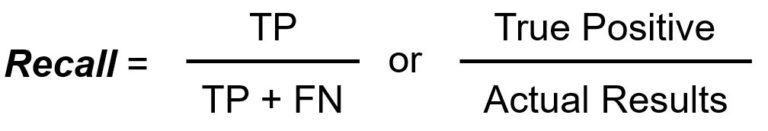
Die Präzision misst die Gesamtzahl der richtigen positiven Ergebnisse geteilt durch die Gesamtzahl der vorhergesagten positiven Ergebnisse.

Die Spezifität misst die Gesamtzahl der echten Negative geteilt durch die Gesamtzahl der tatsächlichen Negative.
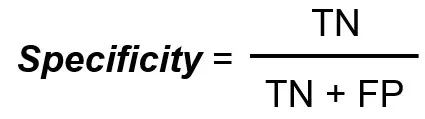
Der F1 Score ist eine einzelne Metrik, die ein harmonisches Mittel aus Precision und Recall ist.

Um die Verwirrungsmatrix besser zu verstehen, musst du wissen, was das Ziel ist und warum sie häufig verwendet wird.
Wenn es darum geht, die Leistung eines Modells oder generell etwas zu messen, konzentrieren sich die Menschen auf die Genauigkeit. Wenn du dich jedoch stark auf die Genauigkeitskennzahl verlässt, kann das zu falschen Entscheidungen führen. Um dies zu verstehen, werden wir die Grenzen der Genauigkeit als eigenständige Kennzahl erläutern.
Wie oben definiert, misst die Genauigkeit die Gesamtzahl der richtigen Klassifizierungen geteilt durch die Gesamtzahl der Fälle. Die Verwendung dieser Kennzahl als eigenständige Kennzahl ist jedoch mit Einschränkungen verbunden, z. B:
Durch diese Einschränkungen bietet die Konfusionsmatrix zusammen mit der Vielzahl von Metriken einen detaillierteren Einblick, wie die Leistung eines Modells verbessert werden kann.
Wie in der Grundstruktur einer Konfusionsmatrix zu sehen ist, werden die Vorhersagen in vier Kategorien unterteilt: Richtig Positiv, Richtig Negativ, Falsch Positiv und Falsch Negativ.
Diese detaillierte Aufschlüsselung bietet wertvolle Einblicke und Lösungen zur Verbesserung der Leistung eines Modells:
Nachdem wir nun ein gutes Verständnis der grundlegenden Konfusionsmatrix, ihrer Terminologie und ihrer Verwendung haben, wollen wir uns nun der manuellen Berechnung einer Konfusionsmatrix widmen, gefolgt von einem praktischen Beispiel.
Hier findest du eine Schritt-für-Schritt-Anleitung, wie du eine Konfusionsmatrix manuell berechnen kannst.
Der erste Schritt besteht darin, die beiden möglichen Ergebnisse deiner Aufgabe zu ermitteln: Positiv oder Negativ.
Sobald die möglichen Ergebnisse definiert sind, werden im nächsten Schritt alle Vorhersagen des Modells gesammelt, einschließlich der Anzahl der Vorhersagen für jede Klasse und deren Vorkommen.
Wenn alle Vorhersagen zusammengetragen wurden, ist der nächste Schritt, die Ergebnisse in die vier Kategorien einzuordnen:
Sobald die Ergebnisse klassifiziert sind, werden sie in einer Tabelle dargestellt, die anhand verschiedener Kennzahlen analysiert wird.
Lass uns ein praktisches Beispiel durchgehen, um diesen Prozess zu demonstrieren.
Bleiben wir bei dem Beispiel, eine E-Mail als Spam oder Nicht-Spam zu identifizieren, und erstellen wir einen hypothetischen Datensatz, in dem Spam positiv und Nicht-Spam negativ ist. Wir haben die folgenden Daten:
An diesem Punkt haben wir das Ergebnis definiert und die Daten gesammelt; der nächste Schritt besteht darin, die Ergebnisse in die vier Kategorien einzuordnen:
Der nächste Schritt ist, daraus eine Verwirrungsmatrix zu machen:
|
Tatsächliche / Vorhergesagte |
Spam (positiv) |
Kein Spam (Negativ) |
|
Spam (positiv) |
60 (TP) |
20 (FN) |
|
Kein Spam (Negativ) |
20 (FP) |
100 (TN) |
Was sagt uns also die Verwirrungsmatrix?
Mit dieser Konfusionsmatrix können wir die verschiedenen Metriken berechnen: Genauigkeit, Recall/Sensitivität, Präzision, Spezifität und der F1-Score.

Ausgabe der Konfusionsmatrix-Metriken
Du fragst dich vielleicht, warum der F1-Score Präzision und Recall in seiner Formel enthält. Die F1-Kennzahl ist entscheidend, wenn du mit unausgewogenen Daten zu tun hast oder wenn du einen Kompromiss zwischen Präzision und Recall finden willst.
Die Präzision misst die Genauigkeit der positiven Vorhersage. Sie beantwortet die Frage: "Wenn das Modell WAHR vorhergesagt hat, wie oft lag es richtig?". Präzision ist vor allem dann wichtig, wenn die Kosten für ein falsches Positiv hoch sind.
Der Recall oder die Sensitivität misst die Anzahl der tatsächlich positiven Ergebnisse, die das Modell korrekt identifiziert hat. Sie beantwortet die Frage: "Wenn die Klasse tatsächlich WAHR war, wie oft lag der Klassifikator richtig?
Der Wiedererkennungswert ist wichtig, wenn sich herausstellt, dass das Übersehen einer positiven Instanz (FN) deutlich schlechter ist als die falsche Kennzeichnung negativer Instanzen als positiv.
Um dies zu verdeutlichen, erstellen wir mit Scikit-learn in Python eine Konfusionsmatrix mit einem Random Forest Klassifikator.
Der erste Schritt besteht darin, die benötigten Bibliotheken zu importieren und deinen synthetischen Datensatz zu erstellen.
# Import Libraries
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# Synthetic Dataset
X, y = make_classification(n_samples=1000, n_features=20,
n_classes=2, random_state=42)
# Split into Training and Test Sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)Der nächste Schritt ist das Trainieren des Modells mit einem einfachen Random Forest Classifier
# Train the Model
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)Wie im praktischen Beispiel müssen wir die Ergebnisse klassifizieren und in eine Konfusionsmatrix umwandeln. Wir tun dies, indem wir zunächst Vorhersagen für die Testdaten treffen und dann eine Konfusionsmatrix erstellen:
# Predict on the Test Data
y_pred = model.predict(X_test)
# Generate the confusion matrix
cm = confusion_matrix(y_test, y_pred)Jetzt wollen wir eine visuelle Darstellung der Konfusionsmatrix erstellen:
# Create a Confusion Matrix
plt.figure(figsize=(8, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Greens')
plt.title('Confusion Matrix')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()Das ist die Ausgabe:
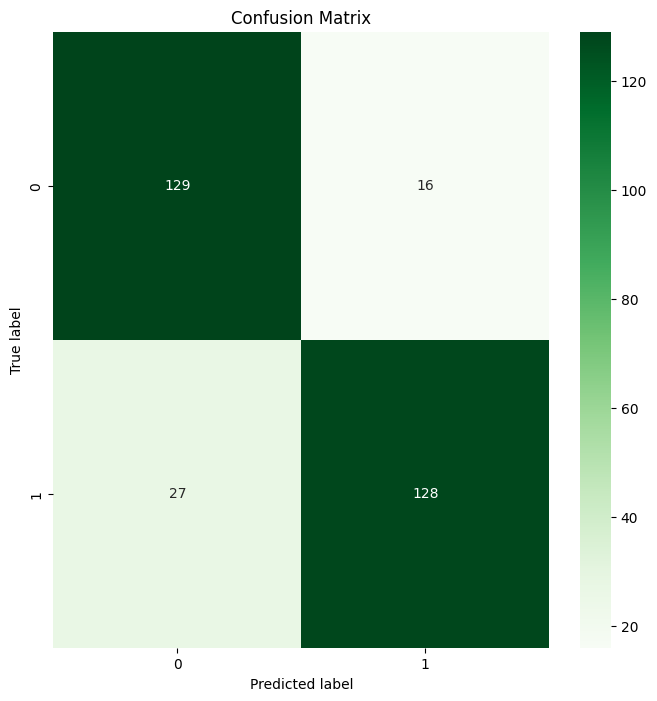
Random Forest Konfusionsmatrix Ausgabe
Tada 🎉 Du hast erfolgreich deine erste Konfusionsmatrix mit Scikit-learn erstellt!
In diesem Artikel haben wir uns mit der Definition einer Konfusionsmatrix, wichtigen Begriffen rund um das Bewertungsinstrument sowie den Grenzen und der Bedeutung der verschiedenen Metriken beschäftigt. Die Fähigkeit, eine Konfusionsmatrix manuell zu berechnen, ist wichtig für dein Data Science-Wissen, ebenso wie die Fähigkeit, sie mit Bibliotheken wie Scikit-learn auszuführen.
Wenn du tiefer in die Konfusionsmatrix eintauchen möchtest, kannst du mit Understanding Confusion Matrix in R Konfusionsmatrizen üben. In unserem Kurs "Modellvalidierung in Python " lernst du die Grundlagen der Modellvalidierung und Validierungstechniken kennen und kannst damit beginnen, validierte und leistungsstarke Modelle zu erstellen.
Erfahre mehr über die Konfusionsmatrix
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
