
Cours
Comprendre le cloud
2 h
235.2K
Il existe de nombreuses façons de définir l'informatique de pointe, mais le concept de base est assez simple. L'informatique en périphérie rapproche le calcul et le stockage des données de l'utilisateur afin de réduire les temps de latence par rapport aux centres de données centralisés.
Cela conduit à des conceptions architecturales différentes en fonction du type d'application que vous construisez. En fait, l'informatique de pointe est un terme large qui englobe de nombreux domaines technologiques.
Par exemple, dans les cas d'utilisation industriels ou de fabrication, le calcul est poussé vers les appareils IoT et les passerelles de périphérie pour agréger ou prétraiter les données avant de les pousser vers le cloud. Dans d'autres secteurs, tels que la santé, le commerce de détail ou l'automobile, vous trouverez des applications similaires qui poussent la logique informatique critique vers des dispositifs portables, des caméras intelligentes ou des véhicules autonomes. Dans tous ces cas d'utilisation, les calculs doivent être effectués rapidement à la périphérie, en évitant les retards dus aux allers-retours du réseau vers des centres de données éloignés.
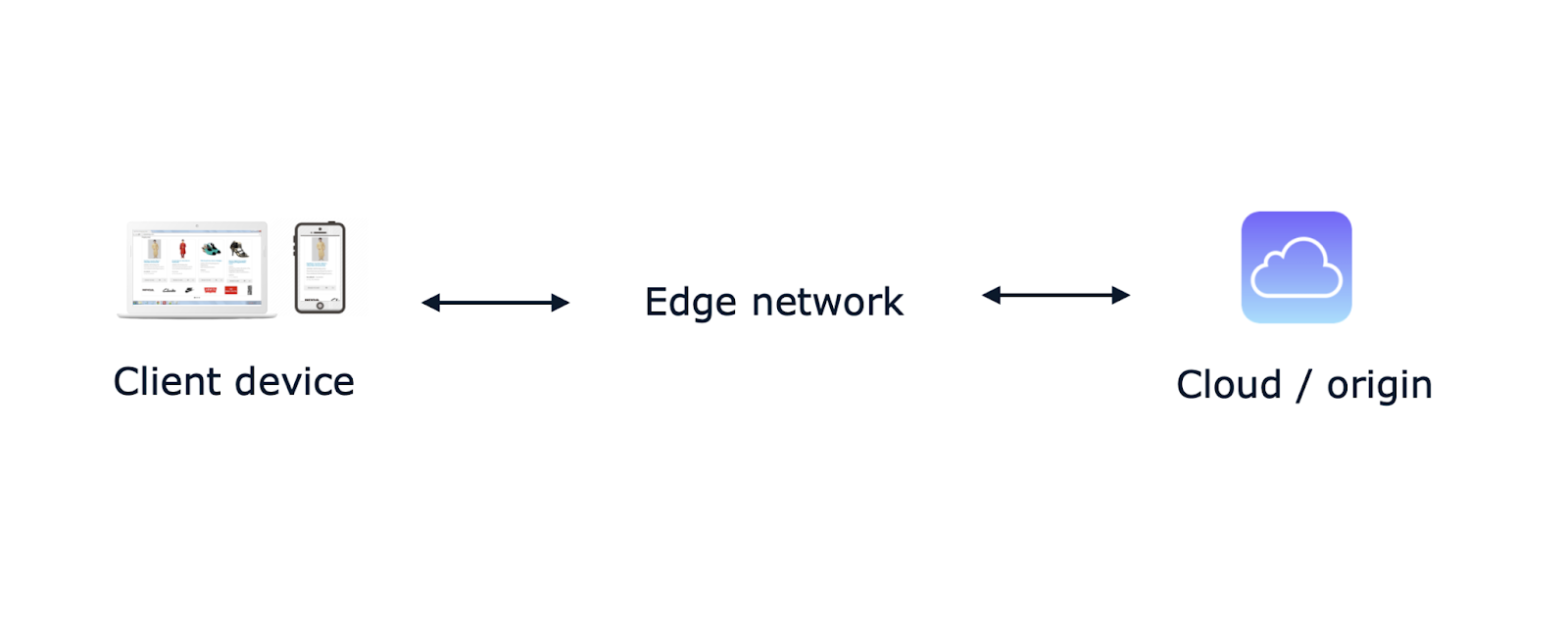
Dans cet article, nous nous concentrerons sur l'edge computing basé sur le CDN, qui est le type d'edge qui vous intéresse si vous utilisez quotidiennement des services web et cloud pour créer des applications web.
Pour comprendre l'edge computing basé sur le CDN et son objectif, nous devons explorer l'évolution du web et du cloud au fil des ans. Ce contexte est essentiel, car l'informatique en périphérie est la clé de cette évolution.
Voyons rapidement comment est né le web et comment il a conduit au cloud :
Le début des années 2000 est aussi celui de la naissance du cloud. Passons en revue quelques étapes spécifiques de ces 20 dernières années :
En moins d'une décennie, la technologie des applications web est passée de la virtualisation du matériel brutà des machines virtuelles accessiblesle en quelques minutes via l'API. Puis jusqu'à l'orchestration de conteneurs et les fonctions sans serveur qui tournent en quelques secondes (voire dizaines de millisecondes), avec des options de facturation à la seconde (voire à la milliseconde) et une quantité incroyable d'automatisation intégrée.

Et cela ne concerne que l'aspect informatique. Il existe littéralement des centaines de services gérés en matière de stockage, de réseau, de bases de données, d'analyse, etc. Les bases de données gérées sont particulièrement intéressantes car vous pouvez trouver de nombreuses options (y compris vos moteurs open-source préférés), et elles automatisent souvent les parties les plus fastidieuses de l'exploitation d'une base de données en production.
Certains affirment que les services cloud ont rendu la création d'applications web plus facile et plus rapide que jamais, tandis que d'autres estiment que c'était plus simple et plus direct il y a 10 ou 20 ans. La réalité est assez subjective et dépend de ce que vous construisez et des objectifs et priorités de votre entreprise.
Pour en revenir à notre rapide analyse historique, il s'est produit quelque chose d'autre - presque silencieusement - au cours de la dernière décennie. Les réseaux de diffusion de contenu ont connu une évolution similaire, conduisant à ce que j'ai appelé précédemment "l'informatique périphérique basée sur le CDN".
Un réseau de diffusion de contenu (CDN) est un réseau mondial de serveurs proxy répartis dans le monde entier pour améliorer les performances des sites web. En termes simples, un CDN aide les propriétaires de contenu à fournir du contenu aux internautes en accélérant le transfert et en mettant en cache le contenu sur des centaines de serveurs périphériques. Placé devant votre site web, un CDN peut également protéger l'origine des attaques DDoS et d'autres vulnérabilités.
Mais ce n'est plus le cas aujourd'hui. Voyons comment ils ont également évolué au cours des dix dernières années.
Initialement axés sur la mise en cache et la protection des serveurs d'origine, les CDN ont commencé à évoluer avec l' essor de l'informatique sans serveur. Une nouvelle idée s'est rapidement imposée : les développeurs pouvaient définir une "fonction" atomique qui s'exécute à la demande en réponse à un événement, tel qu'un nouveau téléchargement d'image ou un nouvel enregistrement dans une base de données, sans avoir à posséder et à entretenir l'infrastructure physique ou virtuelle sous-jacente.
AWS Lambda a été le premier exemple de ce nouveau paradigme en 2015. AWS Lambda@Edge a suivi en 2016, vous permettant d'adopter la même approche avec des fonctions s'exécutant au-dessus d'Amazon CloudFront - le service CDN d'AWS.
Les CDN populaires ont suivi le mouvement, en introduisant des services tels que CloudFlare Workers en 2017, Fastly Compute@Edge en 2019, et Akamai EdgeWorkers en 2019.
Et ils ne se sont pas arrêtés là ! Comme nous l'avons dit au début de cet article, l'informatique de périphérie ne consiste pas seulement à apporter des capacités de calcul à la périphérie. Dans la plupart des cas, vous avez également besoin d'une forme de stockage des données. Les CDN ont donc continué à évoluer et à proposer de nouveaux services de pointe tels que les magasins de valeurs clés, le stockage d'objets, les bases de données SQL, le redimensionnement d'images, l'inférence de l'IA, et bien d'autres encore !
Par exemple :
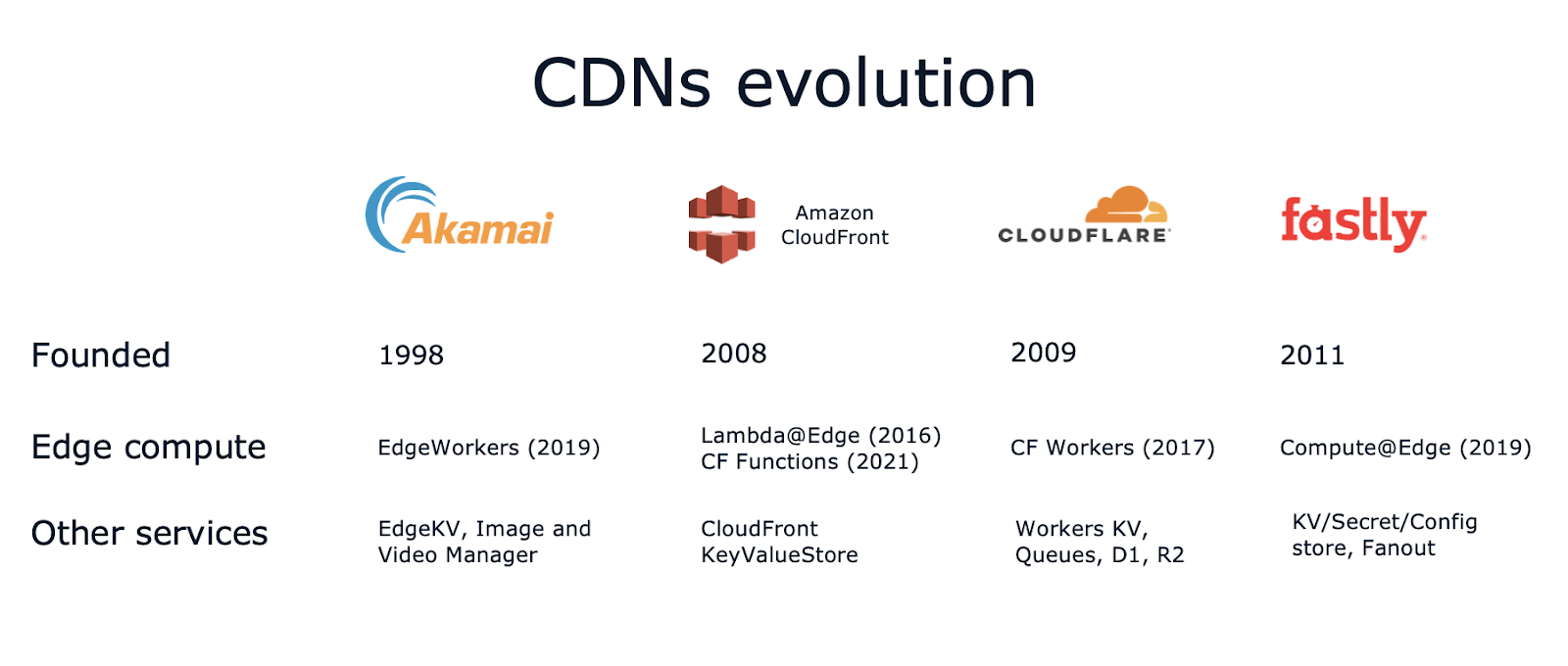
Aujourd'hui, les CDN offrent des services dont vous vous attendez normalement à ce qu'ils ne fonctionnent que dans une région cloud (ou un centre de données), des fonctions sans serveur aux magasins de valeurs clés en passant par le stockage d'objets, les files d'attente et les bases de données relationnelles. Par coïncidence, les files d'attente, le stockage d'objets et la capacité de calcul ont été les tout premiers services du cloud annoncés en 2006, qui font aujourd'hui leur apparition à la périphérie, de manière distribuée à l'échelle mondiale.
Sous le capot, ces nouvelles plateformes de calcul utilisent différentes technologies et prennent en charge différents langages de programmation. Par exemple, CloudFlare utilise le moteur Chrome V8, qui ne prenait initialement en charge que JavaScript, mais qui a commencé à intégrer WebAssembly en 2018. D'autre part, Fastly a décidé d'utiliser WebAssembly dès le début pour son environnement sandboxing afin d'éviter certaines des limitations de latence de démarrage de V8. Cela permet à Fastly de prendre en charge de nombreux langages de programmation, tels que TypeScript, Rust, Go, .NET, Ruby et Swift.
Ouvrons une parenthèse rapide sur WebAssembly.
WebAssembly (ou Wasm en abrégé) pourrait être le développement le plus intéressant dans ce domaine. Depuis qu'il a été annoncé en 2017 puis qu'il est devenu une recommandation du W3C en 2019, beaucoup de gens en parlent pour l'exécution dans le navigateur des binaires Wasm, mais il y a aussi beaucoup de potentiel pour l'exécution côté serveur, y compris l'edge.
Wasm vous permet d'écrire une logique commerciale dans divers langages pris en charge et de la compiler dans un fichier binaire qui s'exécute sur des runtimes Wasm tels que wasmtime de Bytecode Alliance.
Avec WASI (WebAssembly System Interface), il vous permet de composer des logiciels écrits dans différents langages avec une interface standardisée par le W3C.
Si cela vous semble familier à quelque chose de très populaire dans le monde du cloud, consultez ce tweet de 2019 du fondateur de Docker:
Si WASM+WASI existait en 2008, nous n'aurions pas eu besoin de créer Docker. C'est dire son importance. WebAssembly sur le serveur est l'avenir de l'informatique. Une interface standardisée du système était le chaînon manquant. Espérons que la WASI sera à la hauteur !
Apprenez-en plus sur le cloud computing avec les cours suivants !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min