
Cursus
Développer des applications d'IA
21 h
Avec l'essor des grands modèles de langage (LLM) et de leurs applications, nous avons constaté une augmentation de la popularité des outils d'intégration, des cadres LLMOps et des bases de données vectorielles. En effet, travailler avec des LLM nécessite une approche différente de celle des modèles traditionnels d'apprentissage automatique.
L'une des principales technologies habilitantes pour les LLM est l'intégration de vecteurs. Alors que les ordinateurs ne peuvent pas comprendre directement le texte, les embeddings représentent le texte de manière numérique. Tout le texte fourni par l'utilisateur est converti en enchâssements, qui sont utilisés pour générer des réponses.
La conversion d'un texte en un document incorporé est un processus qui prend du temps. Pour éviter cela, nous disposons de bases de données vectorielles explicitement conçues pour le stockage et l'extraction efficaces d'intégrations vectorielles.
Dans ce tutoriel, nous allons nous familiariser avec les magasins de vecteurs et Chroma DB, une base de données open-source pour le stockage et la gestion des embeddings. Nous apprendrons également à ajouter et à supprimer des documents, à effectuer des recherches de similarité et à convertir notre texte en embeddings.

Image de l'auteur
Les magasins de vecteurs sont des bases de données explicitement conçues pour stocker et récupérer efficacement les intégrations de vecteurs. Elles sont nécessaires parce que les bases de données traditionnelles comme SQL ne sont pas optimisées pour le stockage et l'interrogation de grandes données vectorielles.
Les embeddings représentent des données (généralement des données non structurées telles que du texte) sous forme de vecteurs numériques dans un espace à haute dimension. Les bases de données relationnelles traditionnelles ne sont pas adaptées au stockage et à la recherche de ces représentations vectorielles.
Les magasins de vecteurs peuvent indexer et rechercher rapidement des vecteurs similaires à l'aide d'algorithmes de similarité, ce qui permet aux applications de trouver des vecteurs apparentés à partir d'une requête de vecteur cible.
Par exemple, dans le cas d'un chatbot personnalisé, l'utilisateur saisit une invite pour le modèle d'IA génératif. À l'aide d'un algorithme de recherche de similitudes, le modèle recherche des textes similaires dans une collection de documents. Les informations obtenues sont ensuite utilisées pour générer une réponse hautement personnalisée et précise. Cette recherche d'informations est rendue possible par l'intégration et l'indexation des vecteurs dans les entrepôts de vecteurs.
Chroma DB est une base de données vectorielles open-source utilisée pour le stockage et la récupération d'embeddings vectoriels. Sa principale utilité est d'enregistrer des encastrements avec des métadonnées qui seront utilisés ultérieurement par de grands modèles de langage. En outre, il peut également être utilisé pour les moteurs de recherche sémantique sur des données textuelles.
pip install chromadb.Chroma DB propose une option de serveur auto-hébergé. Si vous avez besoin d'une plateforme de base de données vectorielles gérée, consultez Pinecone et le Guide Pinecone pour la maîtrise des bases de données vectorielles.
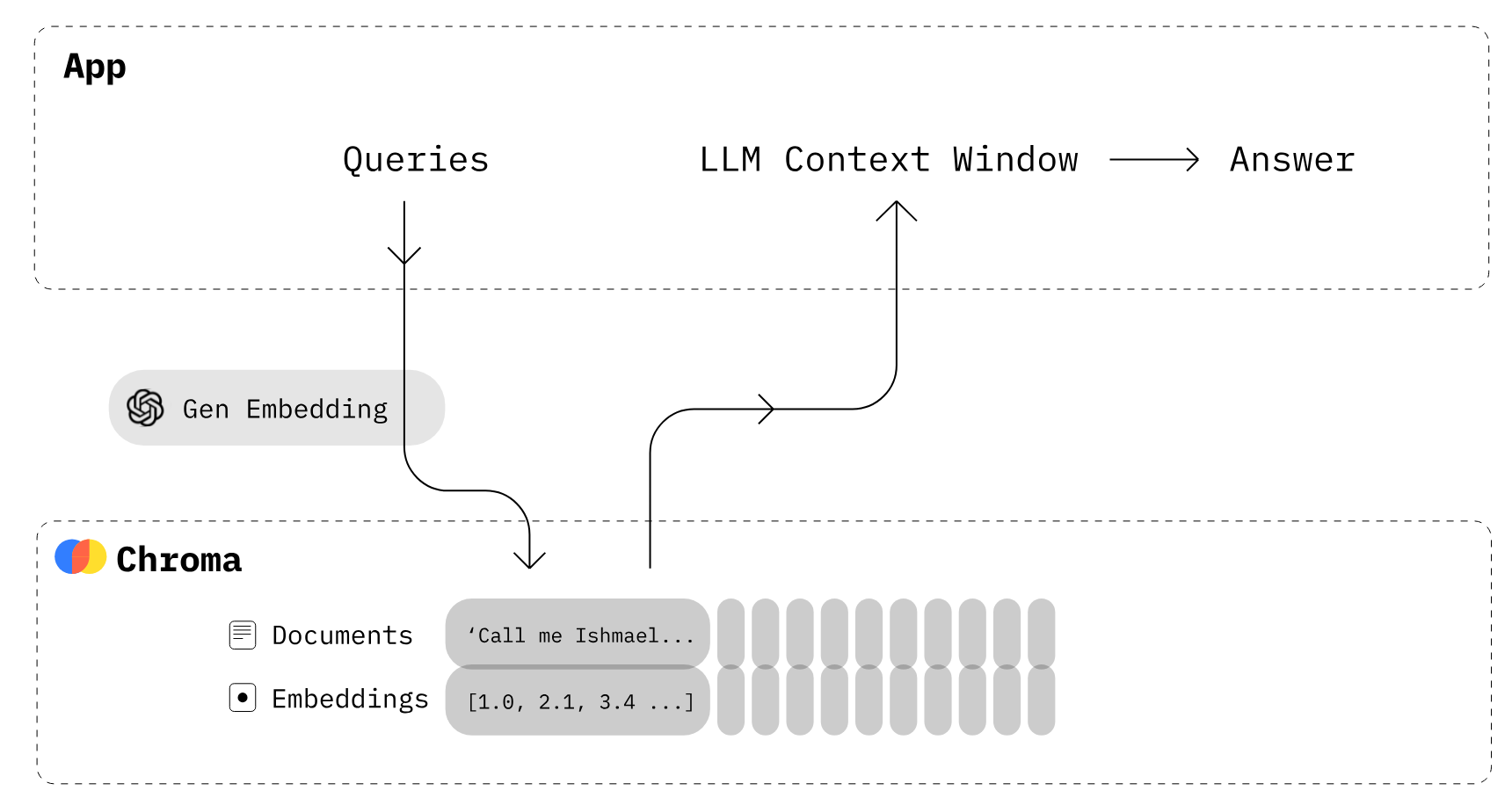
Image de Chroma
all-MiniLM-L6-v2, mais vous pouvez modifier la collection pour utiliser un autre modèle d'embedding.Dans cette section, nous allons créer une base de données vectorielle, ajouter des collections, ajouter du texte à la collection et effectuer une requête de recherche.
Tout d'abord, nous installerons chromadb pour la base de données vectorielle et openai pour un meilleur modèle d'intégration. Assurez-vous d'avoir configuré la clé API OpenAI.
Note : Chroma nécessite SQLite version 3.35 ou supérieure. Si vous rencontrez des problèmes, mettez à jour vers Python 3.11 ou installez une version plus ancienne de chromadb.
!pip install chromadb openai Vous pouvez créer une base de données en mémoire à des fins de test en créant un client Chroma sans paramètres.
Dans notre cas, nous allons créer une base de données persistante qui sera stockée dans le répertoire db/ et utiliser DuckDB en arrière-plan.
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="db/"
))Ensuite, nous créerons un objet collection à l'aide du client. Elle est similaire à la création d'une table dans une base de données traditionnelle.
collection = client.create_collection(name="Students")Pour ajouter du texte à notre collection, nous allons générer un texte aléatoire sur un étudiant, un club et une université. Vous pouvez générer un texte aléatoire à l'aide de ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Nous allons maintenant utiliser la fonction add() pour ajouter des données textuelles avec des métadonnées et des identifiants uniques. Ensuite, Chroma téléchargera automatiquement le modèle all-MiniLM-L6-v2 pour convertir le texte en encastrements et le stocker dans la collection "Students".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Pour effectuer une recherche de similitudes, vous pouvez utiliser la fonction query() et poser des questions en langage naturel. Il convertira la requête en données intégrées et utilisera des algorithmes de similarité pour générer des résultats similaires. Dans notre cas, il renvoie deux résultats similaires.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Vous pouvez utiliser n'importe quel modèle d'encastrement performant de la liste des encastrements. Vous pouvez même créer vos propres fonctions d'intégration.
Dans cette section, nous utiliserons le modèle d'intégration de ligne OpenAI appelé "text-embedding-ada-002" pour convertir le texte en intégration.
Après avoir créé la fonction d'intégration OpenAI, vous pouvez ajouter la liste des documents textuels pour générer des intégrations.
Découvrez comment utiliser l'API OpenAI pour les Text Embeddings et créer des classificateurs de texte, des systèmes de recherche d'informations et des détecteurs de similarité sémantique.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
model_name="text-embedding-ada-002"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Au lieu d'utiliser le modèle d'intégration par défaut, nous chargerons l'intégration déjà créée directement dans les collections.
get_or_create_collection() pour créer une nouvelle collection appelée "Students2". Cette fonction est différente de create_collection(). Il récupère une collection ou la crée si elle n'existe pas déjà.collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Il existe également une autre méthode, plus simple. Vous pouvez ajouter une fonction d'intégration OpenAI lors de la création ou de l'accès à la collection. Outre OpenAI, vous pouvez utiliser Cohere, Google PaLM, HuggingFace et les modèles des instructeurs.
Dans notre cas, l'ajout de nouveaux documents textuels exécutera une fonction d'intégration OpenAI au lieu du modèle par défaut pour convertir le texte en intégrations.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Voyons la différence en exécutant une requête similaire sur la nouvelle collection.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsNos résultats se sont améliorés. La recherche par similarité renvoie désormais des informations sur l'université au lieu d'un club. En outre, la distance entre les vecteurs est inférieure à celle du modèle d'intégration par défaut, ce qui est une bonne chose.

Tout comme les bases de données relationnelles, vous pouvez mettre à jour ou supprimer les valeurs des collections. Pour mettre à jour le texte et les métadonnées, nous vous fournirons l'identifiant spécifique de l'enregistrement et le nouveau texte.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Exécutez une simple requête pour vérifier si les modifications ont été effectuées avec succès.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsComme on peut le voir, au lieu d'Alexandra, nous avons obtenu Kristiane.

Pour supprimer un enregistrement de la collection, nous utiliserons la fonction delete() et spécifierons un identifiant unique.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsLe texte d'information sur les étudiants a été supprimé ; à la place, nous obtenons les meilleurs résultats suivants.

Dans cette section, nous allons découvrir la fonction d'utilité de la collecte qui nous facilitera grandement la vie.
Nous allons créer une nouvelle collection appelée "vectordb" et ajouter les informations sur l'aide-mémoire de Chroma DB, la documentation et l'API JS avec les métadonnées.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Nous utiliserons la fonction count() pour vérifier le nombre d'enregistrements de la collection.
vector_collections.count()3Pour afficher tous les enregistrements de la collection, utilisez la fonction get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Pour modifier le nom de la collection, utilisez la fonction modify(). Pour afficher tous les noms de collection, utilisez list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Il semble que nous ayons renommé "vectordb" en "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Pour accéder à une nouvelle collection, vous pouvez utiliser get_collection() avec le nom de la collection.
vector_collections_new = client.get_collection(name="chroma_info")Nous pouvons supprimer une collection en utilisant la fonction client delete_collection() et en spécifiant le nom de la collection.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Nous pouvons supprimer l'ensemble de la collection de bases de données en utilisant client.reset(). Cependant, cette méthode n'est pas recommandée car il n'existe aucun moyen de restaurer les données après leur suppression.
client.reset()
client.list_collections()[]Les magasins de vecteurs tels que Chroma DB deviennent des composants essentiels des grands systèmes de modèles linguistiques. En fournissant un stockage spécialisé et une récupération efficace des vecteurs intégrés, ils permettent un accès rapide aux informations sémantiques pertinentes pour alimenter les LLM.
Dans ce tutoriel sur Chroma DB, nous avons abordé les bases de la création d'une collection, de l'ajout de documents, de la conversion de texte en embeddings, de la recherche de similarités sémantiques et de la gestion des collections.
L'étape suivante du processus d'apprentissage consiste à intégrer des bases de données vectorielles dans votre application d'IA générative. Vous pouvez facilement ingérer, gérer et récupérer des données privées et spécifiques à un domaine pour votre application d'IA en suivant le tutoriel LlamaIndex, qui est un cadre de données pour les applications basées sur le Large Language Model (LLM). En outre, vous pouvez suivre le tutoriel Comment construire des applications LLM avec LangChain pour plonger dans le monde des LLMOps.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Apprenez-en plus sur l'intelligence artificielle grâce aux cours suivants !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Sejal Jaiswal
Tutoriel
Matt Crabtree
Tutoriel
DataCamp Team
Tutoriel
Samuel Shaibu

