Mit dem Aufkommen von Large Language Models (LLMs) und ihren Anwendungen haben wir einen Anstieg der Popularität von Integrationstools, LLMOps-Frameworks und Vektordatenbanken erlebt. Das liegt daran, dass die Arbeit mit LLMs eine andere Herangehensweise erfordert als traditionelle maschinelle Lernmodelle.
Eine der wichtigsten Technologien für LLMs ist die Vektoreinbettung. Während Computer Text nicht direkt verstehen können, stellen Einbettungen Text numerisch dar. Der gesamte vom Nutzer eingegebene Text wird in Einbettungen umgewandelt, die zur Generierung von Antworten verwendet werden.
Die Umwandlung von Text in eine Einbettung ist ein zeitaufwändiger Prozess. Um das zu vermeiden, haben wir Vektordatenbanken, die explizit für die effiziente Speicherung und Abfrage von Vektoreinbettungen entwickelt wurden.
In diesem Tutorial lernen wir etwas über Vektorspeicher und Chroma DB, eine Open-Source-Datenbank zum Speichern und Verwalten von Einbettungen. Außerdem werden wir lernen, wie man Dokumente hinzufügt und entfernt, Ähnlichkeitssuchen durchführt und unseren Text in Einbettungen umwandelt.

Bild vom Autor
Was sind Vector Stores?
Vektorspeicher sind Datenbanken, die speziell für das effiziente Speichern und Abrufen von Vektoreinbettungen entwickelt wurden. Sie werden benötigt, weil herkömmliche Datenbanken wie SQL nicht für die Speicherung und Abfrage großer Vektordaten optimiert sind.
Einbettungen stellen Daten (normalerweise unstrukturierte Daten wie Text) in numerischen Vektorformaten in einem hochdimensionalen Raum dar. Herkömmliche relationale Datenbanken sind für die Speicherung und Suche dieser Vektordarstellungen nicht gut geeignet.
Vektorspeicher können ähnliche Vektoren mit Hilfe von Ähnlichkeitsalgorithmen indizieren und schnell suchen. Sie ermöglicht es Anwendungen, verwandte Vektoren zu finden, wenn sie einen Zielvektor abfragen.
Im Falle eines personalisierten Chatbots gibt der Nutzer eine Aufforderung für das generative KI-Modell ein. Das Modell sucht dann mit einem Ähnlichkeits-Suchalgorithmus nach ähnlichem Text in einer Sammlung von Dokumenten. Die daraus resultierenden Informationen werden dann verwendet, um eine hoch personalisierte und genaue Antwort zu geben. Ermöglicht wird dies durch die Einbettung und Indizierung von Vektoren in Vektorspeicher.
Was ist Chroma DB?
Chroma DB ist ein Open-Source-Vektorspeicher, der zum Speichern und Abrufen von Vektoreinbettungen verwendet wird. Es dient vor allem dazu, Einbettungen zusammen mit Metadaten zu speichern, die später von großen Sprachmodellen verwendet werden können. Außerdem kann sie auch für semantische Suchmaschinen über Textdaten verwendet werden.
Die wichtigsten Merkmale von Chroma DB:
- Unterstützt verschiedene zugrundeliegende Speicheroptionen wie DuckDB für Einzelplatzlösungen oder ClickHouse für Skalierbarkeit.
- Bietet SDKs für Python und JavaScript/TypeScript an.
- Der Schwerpunkt liegt auf Einfachheit, Schnelligkeit und Analysefähigkeit.
Chroma DB bietet eine Option für einen selbst gehosteten Server. Wenn du eine verwaltete Vektordatenbank-Plattform brauchst, schau dir den Pinecone Guide for Mastering Vector Databases an.
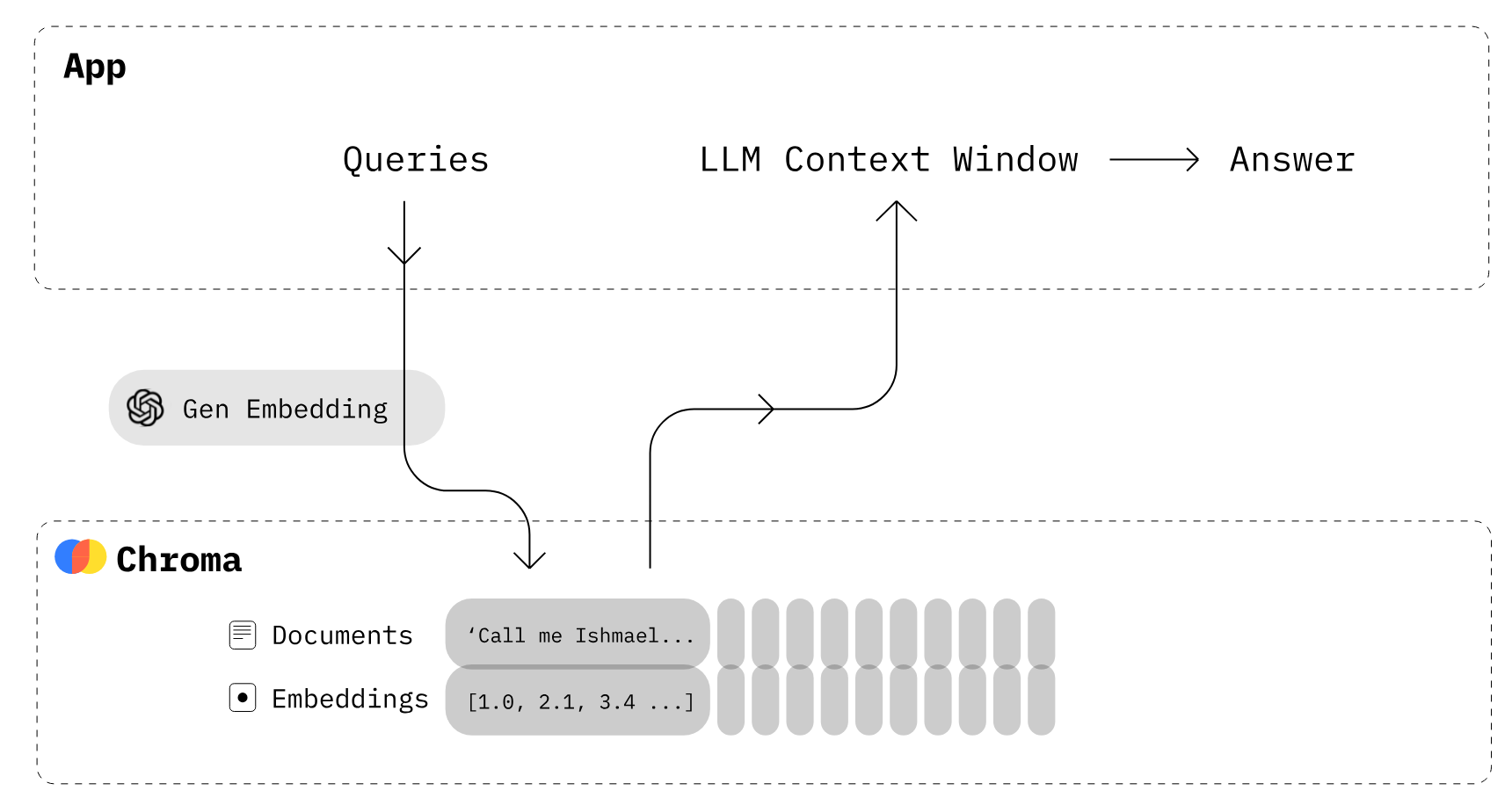
Bild von Chroma
Wie funktioniert Chroma DB?
- Zuerst musst du eine Sammlung erstellen, die den Tabellen in der Beziehungsdatenbank ähnelt. Standardmäßig wandelt Chroma den Text mit
all-MiniLM-L6-v2in die Einbettungen um, aber du kannst die Sammlung ändern, um ein anderes Einbettungsmodell zu verwenden. - Füge der neu erstellten Sammlung Textdokumente mit Metadaten und einer eindeutigen ID hinzu. Wenn deine Sammlung den Text erhält, wandelt sie ihn automatisch in eine Einbettung um.
- Frag die Sammlung nach Text oder Einbettung ab, um ähnliche Dokumente zu erhalten. Du kannst die Ergebnisse auch anhand von Metadaten herausfiltern.
Im nächsten Teil werden wir Chroma und die OpenAI API nutzen, um unsere eigene Vektor-DB zu erstellen.
Erste Schritte mit Chroma DB
In diesem Abschnitt erstellen wir eine Vektordatenbank, fügen Sammlungen hinzu, fügen der Sammlung Text hinzu und führen eine Suchabfrage durch.
Zuerst werden wir chromadb für die Vektordatenbank und openai für ein besseres Einbettungsmodell installieren. Stelle sicher, dass du den OpenAI API-Schlüssel eingerichtet hast.
Hinweis: Chroma erfordert SQLite Version 3.35 oder höher. Wenn du Probleme hast, aktualisiere entweder auf Python 3.11 oder installiere eine ältere Version von chromadb.
!pip install chromadb openai Du kannst eine In-Memory-DB zum Testen erstellen, indem du einen Chroma DB-Client ohne Einstellungen anlegst.
In unserem Fall werden wir eine persistente Datenbank erstellen, die im Verzeichnis "db/" gespeichert wird, und DuckDB im Backend verwenden.
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="db/"
))Danach werden wir ein Sammelobjekt mit dem Client erstellen. Es ist ähnlich wie das Erstellen einer Tabelle in einer herkömmlichen Datenbank.
collection = client.create_collection(name="Students")Um unserer Sammlung einen Text hinzuzufügen, müssen wir einen zufälligen Text über einen Schüler, einen Verein und eine Universität erstellen. Du kannst mit ChatGPT Zufallstext erzeugen. Es ist ganz einfach.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.Jetzt werden wir die Funktion add verwenden, um Textdaten mit Metadaten und eindeutigen IDs hinzuzufügen. Danach lädt Chroma automatisch das Modell all-MiniLM-L6-v2 herunter, um den Text in Einbettungen umzuwandeln und in der Sammlung "Schüler" zu speichern.
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Um eine Ähnlichkeitssuche durchzuführen, kannst du die Funktion query verwenden und Fragen in natürlicher Sprache stellen. Es wandelt die Abfrage in ein Embedding um und verwendet Ähnlichkeitsalgorithmen, um ähnliche Ergebnisse zu finden. In unserem Fall liefert es zwei ähnliche Ergebnisse.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Einbettungen
Du kannst jedes leistungsstarke Einbettungsmodell aus der Einbettungsliste verwenden. Du kannst sogar deine eigenen Einbettungsfunktionen erstellen.
In diesem Abschnitt verwenden wir das OpenAI-Einbettungsmodell mit dem Namen "text-embedding-ada-002", um Text in Einbettungen umzuwandeln.
Nachdem du die OpenAI-Einbettungsfunktion erstellt hast, kannst du die Liste der Textdokumente hinzufügen, die eingebettet werden sollen.
Entdecke, wie du die OpenAI API für Texteinbettungen nutzen und Textklassifizierer, Information Retrieval Systeme und semantische Ähnlichkeitsdetektoren erstellen kannst.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
model_name="text-embedding-ada-002"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Anstatt das standardmäßige Einbettungsmodell zu verwenden, laden wir bereits erstellte Einbettungen direkt in die Sammlungen.
- Wir verwenden die Funktion
get_or_create_collection, um eine neue Sammlung mit dem Namen "Students2" zu erstellen. Diese Funktion unterscheidet sich voncreate_collection. Er holt eine Sammlung oder erstellt sie, wenn sie noch nicht existiert. - Jetzt fügen wir unserer neu erstellten Sammlung Einbettungen, Textdokumente, Metadaten und IDs hinzu.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Es gibt auch eine andere, einfachere Methode. Du kannst bei der Erstellung oder beim Zugriff auf die Sammlung eine OpenAI-Einbettungsfunktion hinzufügen. Neben OpenAI kannst du auch Cohere, Google PaLM, HuggingFace und Instructor-Modelle verwenden.
In unserem Fall wird beim Hinzufügen neuer Textdokumente eine OpenAI-Einbettungsfunktion anstelle des Standardmodells ausgeführt, um Text in Einbettungen umzuwandeln.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Lass uns den Unterschied sehen, indem wir eine ähnliche Abfrage für die neue Sammlung durchführen.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsUnsere Ergebnisse haben sich verbessert. Die Ähnlichkeitssuche liefert jetzt Informationen über die Universität statt über einen Club. Außerdem ist der Abstand zwischen den Vektoren geringer als beim Standard-Einbettungsmodell, was eine gute Sache ist.

Aktualisieren und Entfernen von Daten
Genau wie bei relationalen Datenbanken kannst du die Werte in den Sammlungen aktualisieren oder entfernen. Um den Text und die Metadaten zu aktualisieren, geben wir die spezifische ID für den Datensatz und den neuen Text an.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Führe eine einfache Abfrage durch, um zu prüfen, ob die Änderungen erfolgreich durchgeführt wurden.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsWie wir sehen können, haben wir statt Alexandra Kristiane bekommen.

Um einen Datensatz aus der Sammlung zu entfernen, verwenden wir die Funktion "Löschen" und geben eine eindeutige ID an.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsDer Text mit den Schülerinformationen wurde entfernt; stattdessen erhalten wir die nächstbesten Ergebnisse.

Sammlungsmanagement
In diesem Abschnitt werden wir die Sammlungsfunktion kennenlernen, die uns das Leben sehr erleichtern wird.
Wir erstellen eine neue Sammlung namens "vectordb" und fügen die Informationen über den Chroma DB Spickzettel, die Dokumentation und die JS API mit Metadaten hinzu.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Wir werden die Funktion count() verwenden, um zu prüfen, wie viele Datensätze die Sammlung hat.
vector_collections.count()3Um alle Datensätze der Sammlung anzuzeigen, verwende die Funktion .get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Um den Namen der Sammlung zu ändern, verwende die Funktion modify(). Um alle Sammlungsnamen anzuzeigen, verwende list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Es scheint, dass wir "vectordb" in "chroma_info" umbenannt haben.
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Um auf eine neue Sammlung zuzugreifen, kannst du get_collection mit dem Namen der Sammlung verwenden.
vector_collections_new = client.get_collection(name="chroma_info")Wir können eine Sammlung mit der Client-Funktion delete_collection löschen und den Namen der Sammlung angeben.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Wir können die gesamte Datenbanksammlung löschen, indem wir client.reset() verwenden. Es wird jedoch nicht empfohlen, da es keine Möglichkeit gibt, die Daten nach dem Löschen wiederherzustellen.
client.reset()
client.list_collections()[]Fazit
Vektorspeicher wie Chroma DB werden zu wesentlichen Bestandteilen von großen Sprachmodellsystemen. Durch die spezialisierte Speicherung und den effizienten Abruf von Vektoreinbettungen ermöglichen sie einen schnellen Zugriff auf relevante semantische Informationen, um LLMs zu unterstützen.
In diesem Chroma DB-Tutorial haben wir die Grundlagen des Anlegens einer Sammlung, des Hinzufügens von Dokumenten, der Umwandlung von Text in Einbettungen, der Abfrage nach semantischer Ähnlichkeit und der Verwaltung der Sammlungen behandelt.
Der nächste Schritt im Lernprozess besteht darin, Vektordatenbanken in deine generative KI-Anwendung zu integrieren. Du kannst private und domänenspezifische Daten für deine KI-Anwendung ganz einfach aufnehmen, verwalten und abrufen, indem du dem LlamaIndex-Tutorial folgst, einem Daten-Framework für Large Language Model (LLM)-basierte Anwendungen. Außerdem kannst du dem Tutorial How to Build LLM Applications with LangChain folgen, um in die Welt der LLMOps einzutauchen.
Lass dich für deine Traumrolle als Data Engineer zertifizieren
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.



