With the rise of large language models (LLMs) and their applications, we have seen an increase in the popularity of integration tools, LLMOps frameworks, and vector databases. This is because working with LLMs requires a different approach than working with traditional machine learning models.
One of the core enabling technologies for LLMs is vector embeddings. While computers cannot directly understand text, embeddings represent text numerically. All user-provided text is converted to embeddings, which are used to generate responses.
Converting text into embedding is a time-consuming process. To avoid that, we have vector databases explicitly designed for efficient storage and retrieval of vector embeddings.
In this tutorial, I'll walk through vector stores and Chroma DB, an open-source database for storing and managing embeddings. You'll learn how to add and remove documents, perform similarity searches, and convert text into embeddings.

Image by author
TL;DR
- ChromaDB is an open-source vector database for storing and retrieving embeddings—install it with
pip install chromadb - Use
chromadb.PersistentClient(path="./chroma_db")for local persistence orchromadb.EphemeralClient()for in-memory testing - Create a collection (analogous to a table), then
add()documents with optional metadata and IDs - Run semantic similarity search with
collection.query(query_texts=["..."], n_results=5) - Plug in any embedding model—OpenAI, HuggingFace, Google Gemini, or a custom function
- ChromaDB is widely used as the vector store in RAG (Retrieval-Augmented Generation) pipelines
What Are Vector Stores?
Vector stores are databases explicitly designed for efficiently storing and retrieving vector embeddings. They are needed because traditional databases like SQL are not optimized for storing and querying large vector data.
Embeddings represent data (usually unstructured data like text) in numerical vector formats within a high-dimensional space. Traditional relational databases are not well-suited to storing and searching these vector representations.
Vector stores can index and quickly search for similar vectors using similarity algorithms, which allows applications to find related vectors given a target vector query.
For example, in the case of a personalized chatbot, the user inputs a prompt for the generative AI model. Using a similarity search algorithm, the model searches for similar text within a collection of documents. The resulting information is then used to generate a highly personalized and accurate response. This retrieval of information is made possible through embedding and vector indexing within vector stores.
What is Chroma DB?
Chroma DB is an open-source vector store used for storing and retrieving vector embeddings. Its main use is to save embeddings along with metadata to be used later by large language models. Additionally, it can also be used for semantic search engines over text data.
Chroma DB features
- Simple and powerful:
- Install with a simple command:
pip install chromadb. - Quick start with Python SDK, allowing for seamless integration and fast setup.
- Install with a simple command:
- Full-featured:
- Comprehensive retrieval features: Includes vector search, full-text search, document storage, metadata filtering, and multi-modal retrieval.
- Highly scalable: Uses SQLite for local persistent storage and supports a client-server mode for multi-client and production deployments.
- Multi-language support:
- Offers SDKs for popular programming languages, including Python, JavaScript/TypeScript, Ruby, PHP, and Java.
- Integrated:
- Native integration with embedding models from HuggingFace, OpenAI, Google, and more.
- Compatible with Langchain and LlamaIndex, with more tool integrations coming soon.
- Open source:
- Licensed under Apache 2.0.
- Speed and simplicity:
- Focuses on simplicity and speed, designed to make analysis and retrieval efficient while being intuitive to use.
Chroma DB offers a self-hosted server option. If you need a managed or cloud-native vector database, explore our guides on Mastering Vector Databases with Pinecone or Weaviate as alternative solutions.
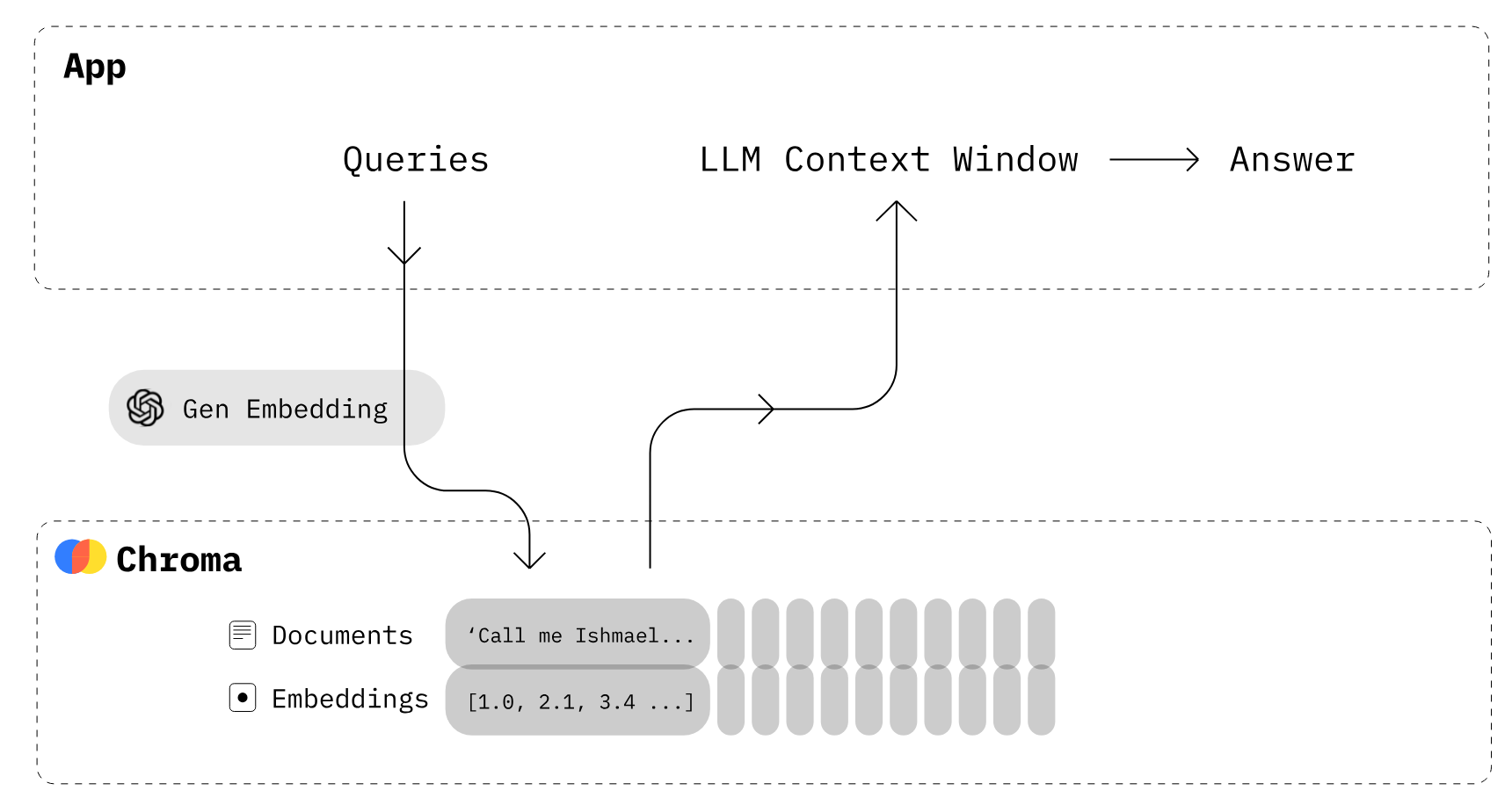
Image from Chroma
How does Chroma DB work?
- First, you have to create a collection similar to the tables in the relations database. By default, Chroma converts the text into the embeddings using
all-MiniLM-L6-v2, but you can modify the collection to use another embedding model. - Add text documents with metadata and a unique ID to the newly created collection. When your collection receives the text, it automatically converts it into embedding.
- Query the collection by text or embedding to receive similar documents. You can also filter out results based on metadata.
Prerequisites
To follow this tutorial, you'll need:
- Python 3.8+ (Python 3.11 recommended for best ChromaDB compatibility)
- pip package manager
- An OpenAI API key (required only for the Embeddings section; the core ChromaDB sections work without it)
- SQLite 3.35 or higher (built into Python 3.11; if you're on an older version and hit issues, use
pip install pysqlite3-binary) - Basic familiarity with Python lists and dictionaries
Getting Started With Chroma DB
In this section, I'll create a vector database, add a collection, load text into it, and run a similarity search query.
First, install chromadb and openai. You'll need an OpenAI API key only for the Embeddings section—the core ChromaDB examples below work without one.
Note: Chroma requires SQLite version 3.35 or higher. If you experience problems, either upgrade to Python 3.11 or install an older version of chromadb.
!pip install chromadb openai Choosing a client mode
ChromaDB provides three client modes depending on your use case:
| Client | Use case | Code |
|---|---|---|
| EphemeralClient | In-memory testing; data lost on exit | chromadb.EphemeralClient() |
| PersistentClient | Local file storage; data persists across restarts | chromadb.PersistentClient(path="./chroma_db") |
| HttpClient | Production; connects to a running ChromaDB server | chromadb.HttpClient(host="localhost", port=8000) |
You can create an in-memory (ephemeral) database for testing using chromadb.EphemeralClient(). This stores data only in memory and resets when the program ends—perfect for quick experiments.
In this example, I'll create a persistent database stored in the ./chroma_db directory. ChromaDB uses SQLite-backed storage in persistent mode—the DuckDB backend was removed in ChromaDB 0.4.0.
import chromadb
client = chromadb.PersistentClient(path="./chroma_db")After that, we will create a collection object using the client. It is similar to creating a table in a traditional database.
collection = client.create_collection(name="Students")To add text to our collection, we will generate random text about a student, club, and university. You can generate random text using ChatGPT.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.
"""Now, we will use the add() function to add text data with metadata and unique IDs. After that, Chroma will automatically download the all-MiniLM-L6-v2 model to convert the text into embeddings and store it in the "Students" collection.
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)To run a similarity search, you can use the query() function and ask questions in natural language. It will convert the query into embedding and use similarity algorithms to generate similar results. In our case, it is returning two similar results.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embeddings
You can use any high-performing embedding model from the embedding list. You can even create your custom embedding functions. For a deep dive into OpenAI's current generation models, see our guide on text-embedding-3-large.
In this section, I'll use OpenAI's text-embedding-3-small model to convert text into embeddings. This is OpenAI's recommended replacement for the legacy text-embedding-ada-002—it delivers better benchmark performance at 5× lower cost.
After creating the OpenAI embedding function, you can add the list of text documents to generate embeddings.
Discover how to use the OpenAI API for Text Embeddings and create text classifiers, information retrieval systems, and semantic similarity detectors.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="YOUR_OPENAI_API_KEY",
model_name="text-embedding-3-small"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Instead of using the default embedding model, I'll load the embeddings already generated directly into a new collection.
- We will use the
get_or_create_collection()function to create a new collection called "Students2". This function is different fromcreate_collection(). It will get a collection or create if it doesn't exist already. - We will now add embedding, text documents, metadata, and IDs to our newly created collection.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)There is another, more straightforward method, too. You can add an OpenAI embedding function while creating or accessing the collection. Apart from OpenAI, you can use Cohere, Google Gemini, HuggingFace, and Instructor models.
In our case, adding new text documents will run an OpenAI embedding function instead of the default model to convert text into embeddings.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Let’s see the difference by running a similar query on the new collection.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsOur results have improved. The similarity search now returns information about the university instead of a club. Additionally, the distance between the vectors is lower than the default embedding model, which is a good thing.

Filtering Query Results
ChromaDB supports metadata filtering to narrow down similarity search results. Use the where parameter with filter operators inside query():
results = collection.query(
query_texts=["What is the student name?"],
n_results=2,
where={"source": "student info"} # only return documents with this metadata
)
# Combine multiple filters with $and / $or
results = collection.query(
query_texts=["university"],
n_results=5,
where={
"$or": [
{"source": "student info"},
{"source": "university info"}
]
}
)Supported operators: $eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $and, $or. You can also filter on document content with where_document={"$contains": "chess"}.
Updating and Removing Data
Just like relational databases, you can update or remove the values from the collections. To update the text and metadata, we will provide the specific ID for the record and new text.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Run a simple query to check if the changes have been made successfully.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsAs we can see, instead of Alexandra, we got Kristiane.

To remove a record from the collection, we will use the delete() function and specify a unique ID.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsThe student information text has been removed; instead of that, we get the next best results.

Collection Management
In this section, I'll cover the collection utility functions for counting, listing, renaming, and deleting collections.
We will create a new collection called "vectordb" and add the information about the Chroma DB cheat sheet, documentation, and JS API with metadata.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)We will use the count() function to check how many records the collection has.
vector_collections.count()3To view all the records from the collection, use the get() function.
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}To change the collection name, use the modify() function. To view all collection names, use list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()It appears that we have effectively renamed "vectordb" as "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]To access any new collection, you can use get_collection() with the collection's name.
vector_collections_new = client.get_collection(name="chroma_info")We can delete a collection using the client function delete_collection() and specify the collection name.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]We can delete the entire database collection by using client.reset(). However, it is not recommended as there is no way to restore the data after deletion.
client.reset()
client.list_collections()[]ChromaDB With LangChain: A RAG Example
One of the most common ChromaDB integrations is with LangChain to build RAG applications. Here's a minimal example using ChromaDB as the vector store:
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
# Initialize embedding model and vector store
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma(
collection_name="rag_docs",
embedding_function=embeddings,
persist_directory="./chroma_db"
)
# Add documents
docs = [
Document(page_content="ChromaDB stores vector embeddings", metadata={"source": "doc1"}),
Document(page_content="LangChain simplifies LLM application development", metadata={"source": "doc2"}),
]
vector_store.add_documents(docs)
# Similarity search
results = vector_store.similarity_search("vector database", k=2)
for doc in results:
print(doc.page_content)For a full production-ready RAG pipeline with FastAPI, see our Building a RAG System with LangChain and FastAPI tutorial. For an example using DeepSeek, see our DeepSeek R1 RAG Chatbot with Chroma tutorial.
Conclusion
Vector stores like Chroma DB are becoming essential components of large language model systems. By providing specialized storage and efficient retrieval of vector embeddings, they enable fast access to relevant semantic information to power LLMs.
In this Chroma DB tutorial, we covered the basics of creating a collection, adding documents, converting text to embeddings, querying for semantic similarity, and managing the collections.
The natural next step is building a Retrieval-Augmented Generation (RAG) application with ChromaDB as the vector store. Start with our Building a RAG System with LangChain and FastAPI tutorial for a production-ready pipeline, or explore Agentic RAG for advanced agent-driven retrieval workflows. You can also use LlamaIndex to ingest private data into LLMs, or follow the LangChain LLM tutorial for full application development.



