
Cursus
Principes fondamentaux de l'IA
10 h
L'intégration de texte (identique à l'intégration de mots) est une technique de transformation du traitement du langage naturel (NLP) qui a amélioré la façon dont les machines comprennent et traitent le langage humain.
L'incorporation de texte convertit le texte brut en vecteurs numériques, ce qui permet aux ordinateurs de mieux le comprendre.
La raison en est simple : les ordinateurs ne pensent qu'en termes de chiffres et ne peuvent pas comprendre les mots humains de manière indépendante. Grâce à l'intégration de textes, les ordinateurs peuvent plus facilement lire et comprendre les textes et fournir des réponses plus précises aux requêtes.
Dans cet article, nous allons disséquer la signification de l'intégration de texte, son importance, son évolution, les cas d'utilisation, les principaux modèles et l'intuition.
Les text embeddings sont un moyen de convertir des mots ou des phrases d'un texte en données numériques compréhensibles par une machine. Il s'agit de transformer un texte en une liste de chiffres, où chaque chiffre capture une partie du sens du texte. Cette technique permet aux machines de saisir le contexte et les relations entre les mots.
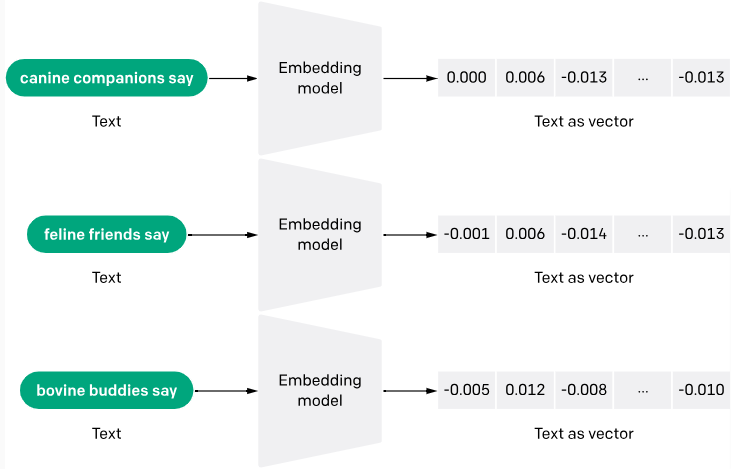
Le processus de génération de text embeddings implique souvent des réseaux neuronaux qui apprennent à encoder la signification sémantique des mots dans des vecteurs denses de nombres réels. Des méthodes telles que Word2Vec et GloVe sont très répandues pour générer ces ancrages en analysant la cooccurrence des mots dans de grands morceaux de texte.
Vous pouvez en savoir plus sur les incorporations de texte avec l'API OpenAI et voir une application pratique dans un autre article.
Les modèles linguistiques classiques considèrent les mots comme des unités indépendantes. L'intégration de mots répond à ce problème en positionnant les mots qui partagent des significations ou des contextes à proximité les uns des autres dans un espace multidimensionnel.
Voici d'autres raisons pour lesquelles les incorporations de texte sont importantes :
Les encastrements aident les modèles à mieux généraliser les mots ou les phrases nouveaux, non vus, en utilisant le contexte appris à partir des données d'apprentissage. Ceci est particulièrement utile dans les langues dynamiques où de nouveaux mots apparaissent fréquemment.
Les embeddings sont largement utilisés comme caractéristiques dans diverses tâches d'apprentissage automatique, telles que la classification de documents, l'analyse des sentiments et la traduction automatique. Ils améliorent les performances des algorithmes en fournissant une forme riche et condensée de données qui capture les propriétés textuelles de base.
Les text embeddings sont capables de traiter plusieurs langues en identifiant et en représentant les similitudes sémantiques entre ces différentes langues. Un exemple est le modèle LaBSE (Language-agnostic BERT Sentence Embedding), qui a démontré des capacités remarquables dans la production d'enchâssements de phrases multilingues couvrant 109 langues.
Les méthodes traditionnelles telles que l'encodage à une touche peuvent générer des données éparses (notamment parce que la plupart des observations ont une valeur de 0) et des vecteurs à haute dimension, ce qui est inefficace pour les vocabulaires volumineux. Les emboîtements réduisent la dimensionnalité et la complexité informatique, ce qui les rend plus adaptés au traitement de données textuelles volumineuses.
Les text embeddings sont des représentations vectorielles denses de données textuelles, où les mots et les documents ayant des significations similaires sont représentés par des vecteurs similaires dans un espace vectoriel à haute dimension.
L'intuition derrière les text embeddings est de capturer les relations sémantiques et contextuelles entre les éléments du texte, permettant aux modèles d'apprentissage automatique de raisonner et de traiter les données textuelles de manière plus efficace.
L'une des principales intuitions à l'origine de l'intégration de textes est l'hypothèse de distribution, selon laquelle les mots ou les phrases qui apparaissent dans des contextes similaires tendent à avoir des significations similaires.
Prenons par exemple les mots "roi" et "reine". Bien qu'ils ne soient pas synonymes, ils partagent un contexte similaire lié à la royauté et à la monarchie. Les text embeddings visent à capturer cette similarité sémantique en représentant ces mots par des vecteurs proches les uns des autres dans l'espace vectoriel.
L'idée des opérations dans l'espace vectoriel est une autre intuition qui sous-tend l'intégration de textes. En représentant le texte sous forme de vecteurs numériques, nous pouvons utiliser les opérations de l'espace vectoriel telles que l'addition, la soustraction et la similitude de cosinus pour capturer et manipuler les relations sémantiques entre les mots et les phrases. Prenons l'exemple suivant :
roi - homme + femme ≈ reine
Dans cet exemple, l'opération vectorielle "roi - homme + femme" peut aboutir à un vecteur très proche de l'intégration de "reine", ce qui traduit la relation analogique entre ces mots.
Une autre intuition que j'aimerais souligner est la réduction de la dimensionnalité dans l'incorporation de texte. Les représentations de texte clairsemées traditionnelles, telles que le codage à une touche, peuvent avoir une dimensionnalité extrêmement élevée (égale à la taille du vocabulaire). Les encastrements de texte, quant à eux, ont généralement une dimensionnalité plus faible (par exemple, 300 dimensions), ce qui leur permet de capturer les caractéristiques les plus saillantes du texte tout en réduisant le bruit et la complexité de calcul.
J'utiliserai l'exemple d'un restaurant pour illustrer l'intuition générale des enchâssements de mots :
Imaginez que vous disposiez d'un corpus d'avis sur des restaurants et que vous souhaitiez créer un système permettant de classer automatiquement le sentiment de chaque avis comme positif ou négatif. Je vous recommande d'utiliser les text embeddings pour représenter chaque avis sous la forme d'un vecteur dense, afin de capturer le sens sémantique et le sentiment exprimés dans le texte.
Prenons deux examens :
Révision 1: "La nourriture était délicieuse et le service excellent. Je recommande vivement ce restaurant".
Examen 2: "La nourriture était médiocre et le service médiocre. Je n'y retournerai pas."
Même si ces critiques ne partagent pas beaucoup de mots, leurs enregistrements devraient être éloignés les uns des autres dans l'espace vectoriel, reflétant ainsi les sentiments contrastés exprimés. Les mots de sentiment positif tels que "délicieux" et "excellent" dans le commentaire 1 auraient des ancrages plus proches de la région positive de l'espace vectoriel, tandis que les mots de sentiment négatif tels que "médiocre" et "mauvais" dans le commentaire 2 auraient des ancrages plus proches de la région négative.
En formant un modèle d'apprentissage automatique sur ces enchâssements de texte, il peut apprendre à mettre en correspondance les modèles sémantiques et les informations sur le sentiment encodées dans les enchâssements avec les étiquettes de sentiment correspondantes (positives ou négatives), ce qui permet de classer avec précision les nouveaux avis non vus.
Selon le livre "Embeddings in Natural Language Processing : Theory and Advances in Vector Representations of Meaning" - par Mohammad Taher Pilehvar et Jose Camacho-Collados, les text embeddings étaient..,
"principalement popularisé après 2013, avec l'introduction de Word2vec".
Cette année a en effet été marquée par une avancée majeure dans le domaine de l'intégration de textes. Cependant, la recherche sur les enchâssements de texte remonte aux années 1950. Bien que cette section ne soit pas exhaustive, je couvrirai certaines des principales étapes de l'évolution des encastrements de texte.
Dans les années 1950-2000, les méthodes telles que l'encodage à une touche et les sacs de mots (BoW) étaient la norme. Malheureusement, ces méthodes n'étaient pas suffisantes et posaient certains problèmes :
Le TF-IDF (Term Frequency-Inverse Document Frequency) a été une autre tentative, dans les années 70, de capturer les textes sous forme de nombres. Cette approche calcule le poids de chaque mot non seulement en fonction de sa fréquence dans un document spécifique, mais aussi en fonction de sa fréquence dans l'ensemble des documents, en attribuant des valeurs plus élevées aux mots moins courants. Bien qu'elle ait amélioré l'encodage à une touche en offrant plus d'informations, elle n'a toujours pas réussi à saisir la signification sémantique des mots.
Selon IBM, les années 2000 ont commencé avec les chercheurs,
"explorer les modèles de langage neuronaux (NLM), qui utilisent des réseaux neuronaux pour modéliser les relations entre les mots dans un espace continu. Ces premiers modèles ont jeté les bases du développement ultérieur de l'intégration des mots".
Un premier exemple est l'introduction des "modèles de langage probabilistes neuronaux" par Bengio et al. vers 2000, qui visaient à apprendre des représentations distribuées des mots.
Plus tard, en 2013, Word2Vec est apparu comme le modèle révolutionnaire qui a introduit l'idée de transformer les mots en vecteurs numériques. Ces vecteurs capturent les similitudes sémantiques, de sorte que les mots ayant des significations similaires se rapprochent dans l'espace vectoriel. C'était comme créer une carte des mots en fonction de leurs relations.
En 2014, GloVe a été présenté dans un document de recherche intitulé "Glove : Global Vectors for Word Representation" par Jeffery Pennington et ses co-auteurs. GloVe a amélioré Word2Vec en permettant de mieux comprendre le sens des mots en tenant compte à la fois du contexte immédiat d'un mot et de son usage général dans le corpus.
Au cours de cette période, des méthodes telles que les mécanismes d'attention (2017) et l'apprentissage par transfert et contexte (2018) ont vu le jour.
Les mécanismes d'attention ont permis aux modèles de se concentrer sur des parties spécifiques d'une phrase et de leur attribuer des poids différents en fonction de leur importance. Cela a permis au modèle de comprendre les relations entre les mots et la façon dont ils contribuent à leur signification.
Par exemple, dans la phrase suivante : "Le renard brun et rapide saute par-dessus le chien paresseux", le mécanisme d'attention pourrait prêter plus d'attention à "rapide" et "saute" lorsqu'il prédit le mot suivant, qu'à "le" ou "brun".
En revanche, l'apprentissage par transfert et le contexte ont favorisé l'utilisation de modèles pré-entraînés. Des techniques comme ULMFiT et BERT ont permis d'affiner ces modèles pré-entraînés pour des tâches spécifiques. Cela signifie que moins de données et de puissance de calcul sont nécessaires pour obtenir des performances élevées.
L'intégration d'API est une approche récente de l'intégration de texte. Si elle est récente, son émergence progressive remonte aux années 2010, lorsque les solutions d'IA basées sur le cloud et les avancées en matière de modèles pré-entraînés se sont généralisées.
Avance rapide jusqu'aux années 2020. L'adoption des API a connu une croissance massive au sein de la communauté des développeurs, tout comme l'intégration des API. Une API d'intégration facilite l'obtention de textes grâce à des modèles préformés.
L'API d'intégration OpenAI est un bon exemple d'API d 'intégration. OpenAI a introduit son API d'intégration avec des mises à jour significatives en décembre 2022. Cette API propose un modèle unifié connu sous le nom de text-embedding-ada-002, qui intègre les capacités de plusieurs modèles précédents en un seul modèle. Ce modèle a été conçu pour exceller dans des tâches telles que la recherche de texte, la recherche de code et la similarité des phrases.
Examinons quelques-uns des cas d'utilisation des incorporations de texte.
L'intégration de mots permet aux moteurs de recherche de comprendre le sens sous-jacent de votre requête et de trouver des documents pertinents, même s'ils ne contiennent pas les mots exacts que vous avez utilisés. Cette fonction est particulièrement utile pour les recherches ambiguës ou pour trouver des contenus similaires.
Les plateformes de commerce électronique, les plateformes de médias sociaux et les services de diffusion en continu sont des exemples courants d'applications qui utilisent l'intégration de texte pour recommander des produits ou des contenus en fonction de vos préférences passées. En analysant les descriptions et les commentaires des articles avec lesquels vous avez interagi, ils peuvent vous suggérer des articles similaires susceptibles de vous intéresser.
Meta (Facebook) utilise les enchâssements de texte pour sa recherche sociale. Vous trouverez plus d'informations à ce sujet dans ce résumé.
Les incorporations de texte vont au-delà de la traduction de mots un à un. Ils tiennent compte du contexte et du sens du texte, ce qui permet d'obtenir des traductions plus précises et plus naturelles.
Les chatbots fonctionnant grâce à des éléments de texte peuvent comprendre l'intention qui se cache derrière vos questions et y répondre de manière plus raisonnable et plus engageante. Ils peuvent analyser le sentiment de votre message et adapter leur style de communication en conséquence.
Les incorporations de mots peuvent être utilisées pour générer différents formats de texte créatifs, tels que des descriptions de produits ou des messages sur les médias sociaux. Les marques peuvent également utiliser les text embeddings pour analyser les conversations sur les médias sociaux et comprendre le sentiment des clients à l'égard de leurs produits ou services.
Voici un aperçu des principaux modèles d'intégration de texte, y compris les options à code source ouvert et à code source fermé :
Comme nous l'avons déjà mentionné, Word2Vec est l'un des modèles pionniers d'intégration de texte. Il a été développé par Tomas Mikolov et ses collègues de Google. Word2Vec utilise des réseaux neuronaux peu profonds pour générer des vecteurs de mots qui capturent les similarités sémantiques.
Word2Vec utilise deux architectures de modèles : Sacs de mots continus (CBOW) et Skip-Gram. CBOW prédit un mot en fonction de son contexte environnant, tandis que Skip-Gram prédit les mots environnants en fonction d'un mot donné. Ce processus permet d'encoder les relations sémantiques entre les mots.
Des bibliothèques NLP populaires comme Gensim et spaCY proposent des implémentations de Word2Vec. Vous pouvez trouver la version open-source de Word2vec hébergée par Google et publiée sous la licence Apache 2.0.
GloVe de Stanford est un autre modèle largement utilisé. Il s'attache à saisir le contexte local et global en analysant les statistiques de cooccurrence des mots dans un vaste corpus de textes. GloVe construit une matrice de cooccurrence des mots, puis la factorise pour obtenir des vecteurs de mots. Ce processus prend en compte les cooccurrences de mots proches et éloignés, ce qui permet une compréhension globale du sens des mots.
GloVe est également un logiciel libre. Des vecteurs GloVe pré-entraînés peuvent être téléchargés, et des implémentations sont également disponibles dans des bibliothèques telles que Gensim.
FastText, développé par Facebook (aujourd'hui Meta), est une extension de Word2Vec qui résout le problème de la non prise en compte des mots hors vocabulaire (OOV). Il intègre des informations sur les sous-mots pour représenter les mots, ce qui lui permet de créer des enchâssements pour les mots non vus.
FastText décompose les mots en n-grammes de caractères (sous-mots). Similaire à Word2Vec, il forme des vecteurs de mots basés sur ces unités de sous-mots. Cela permet au modèle de représenter de nouveaux mots sur la base du sens des sous-mots qui les composent.
FastText est open-source et disponible via la bibliothèque FastText. Des vecteurs FastText pré-entraînés peuvent également être téléchargés pour différentes langues.
L'intégration v3 (Text-embedding-3) est la dernière version des modèles d'intégration d'OpenAIs. Les modèles sont classés en deux catégories : text-embedding-3-small (le plus petit modèle) et text-embedding-3-large (le plus grand modèle). Ils sont fermés et vous devez payer une API pour y avoir accès.
Les modèles d'intégration de texte-3 transforment le texte en représentations numériques en le décomposant d'abord en tokens (mots ou sous-mots). Chaque jeton est associé à un vecteur dans un espace à haute dimension. Un codeur Transformer analyse ensuite ces vecteurs, en tenant compte du contexte de chaque mot en fonction de son environnement.
Enfin, le modèle produit un vecteur unique représentant l'ensemble du texte, capturant son sens global et les relations entre les mots qu'il contient. La grande version est dotée d'une architecture plus complexe et d'une dimensionnalité plus élevée pour une précision potentiellement meilleure, tandis que la petite version privilégie la rapidité et l'efficacité avec une architecture plus simple et une dimensionnalité plus faible.
Pour en savoir plus sur les encastrements OpenAI, consultez notre guide : Exploration de l'intégration de textes-3-Large : Un guide complet des nouveaux Embeddings d'OpenAI.
USE est un modèle d'intégration de phrases à code source fermé créé par Google AI. Il convertit les textes en encastrements à haute dimension qui reflètent les significations sémantiques des phrases ou des courts paragraphes.
Contrairement aux modèles qui intègrent des mots individuels, USE traite des phrases entières à l'aide d'un réseau neuronal profond pré-entraîné sur un corpus de texte diversifié. Cette conception lui permet de saisir efficacement les relations sémantiques, en produisant des vecteurs de taille fixe pour des phrases de longueur variable, ce qui améliore l'efficacité des calculs.
Google fournit un accès via son référentiel TensorFlow Hub.
Dans ce guide, nous vous proposons une introduction complète aux text embeddings, à leur signification, à leur importance et aux grandes étapes de leur évolution. Nous avons également examiné les cas d'utilisation de l'incorporation de texte et les principaux modèles d'incorporation de texte.
Pour en savoir plus sur l'IA, le NLP et les incorporations de texte, consultez les ressources suivantes :
En savoir plus sur l'IA avec DataCamp
Cursus
Cours
Cours