Cursus
Conteneurisation et virtualisation avec Docker et Kubernetes
13 h
Les applications d'apprentissage automatique devenant de plus en plus complexes, faire passer nos modèles d'apprentissage automatique du développement à la production ne se résume pas à écrire un bon code. Il s'agit de s'assurer que notre application fonctionne de manière cohérente dans différents environnements. C'est là que la conteneurisation entre en jeu. Mais qu'est-ce que la conteneurisation exactement, et pourquoi change-t-elle la donne pour les flux de travail d'apprentissage automatique ?
La conteneurisation est un moyen léger et portable d'empaqueter une application avec toutes ses dépendances, bibliothèques et configurations dans une unité unique appelée conteneur. Contrairement aux machines virtuelles (VM) traditionnelles, les conteneurs partagent le système d'exploitation du système hôte, ce qui les rend plus rapides, plus efficaces et plus facilement extensibles.
Pour les data scientists et les ingénieurs ML, cela signifie que vous pouvez construire un modèle sur votre machine locale et le déployer n'importe où, que ce soit sur une plateforme cloud, un serveur ou même l'ordinateur portable d'un collègue, sans vous soucier des problèmes de compatibilité.
Dans ce tutoriel, nous allons voir comment conteneuriser une application d'apprentissage automatique à l'aide de Docker et de Kubernetes. À la fin, vous saurez comment :
Si vous êtes novice en matière de Docker, consultez notre guide sur les sujets suivants Comment apprendre Docker à partir de zéro. Vous pouvez également suivre notre cours, Conteneurisation et virtualisation avec Docker et Kubernetes.
Avant de plonger, vous devez avoir une compréhension de base de Python, des flux de travail d'apprentissage automatique et du travail avec la ligne de commande. Familiarité avec concepts Docker (par exemple, images, conteneurs, commandes de base) est recommandée, et des des connaissances de base de Kubernetes est facultative mais utile pour le déploiement et la mise à l'échelle.
Une application conteneurisée est une application logicielle emballée avec toutes ses dépendances, bibliothèques et configurations dans une unité unique et légère appelée conteneur. Pour les applications d'apprentissage automatique, cela signifie qu'il faut tout empaqueter, de votre modèle entraîné aux bibliothèques Python dont il dépend, afin que votre application s'exécute partout de la même manière.
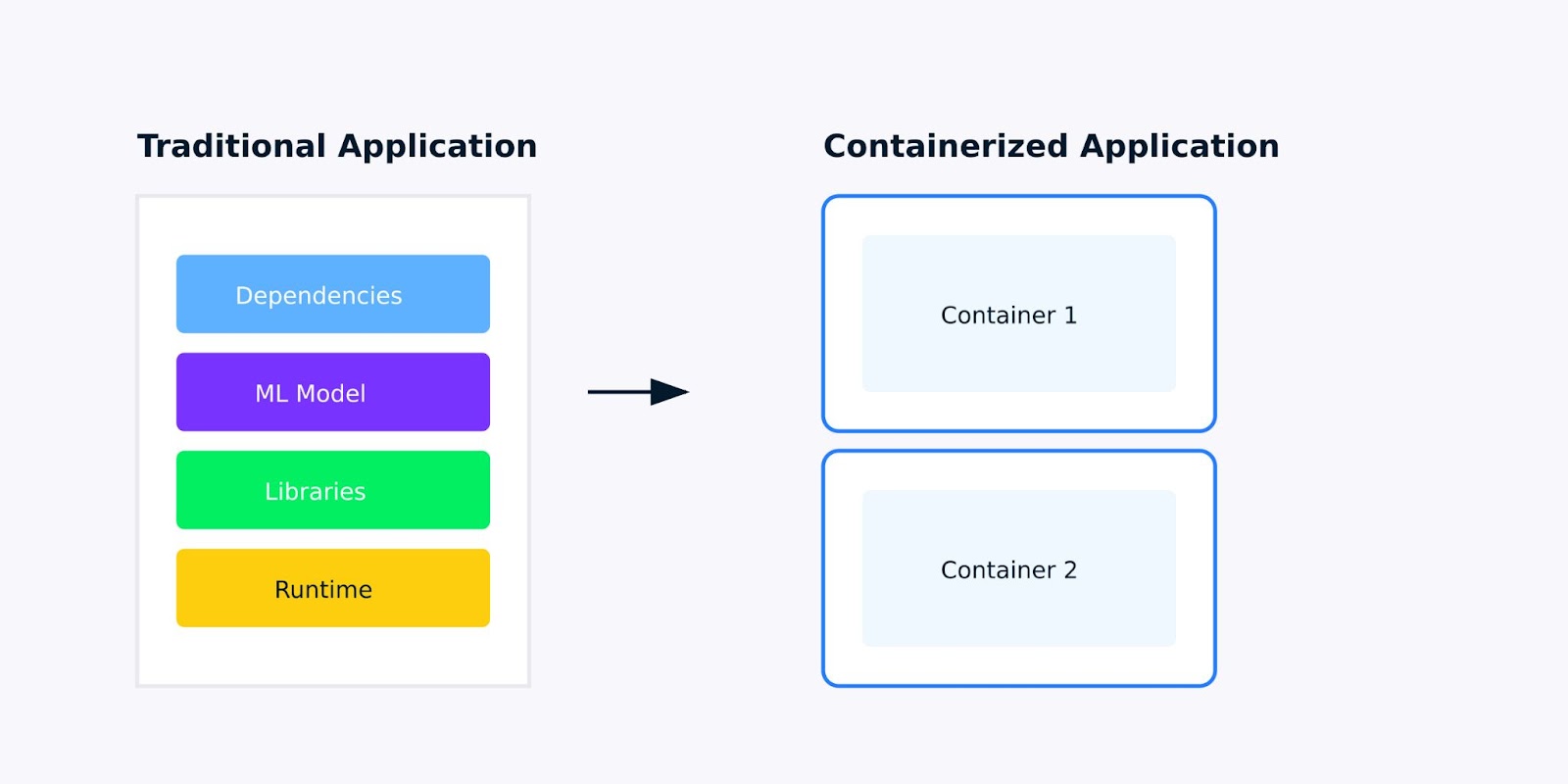
Application traditionnelle contre application conteneurisée
Lorsque vous développez des applications d'apprentissage automatique, vous avez probablement rencontré le problème du "ça marche sur ma machine". Peut-être que votre modèle fonctionne parfaitement sur votre ordinateur portable mais échoue lorsqu'il est déployé sur le cloud, ou qu'un collègue ne peut pas reproduire vos résultats parce qu'il a installé différentes versions de scikit-learn ou de TensorFlow.
La conteneurisation résout ces problèmes en créant un environnement cohérent et isolé pour votre application. Voici ce qui rend les applications conteneurisées plus adaptées à l'apprentissage automatique :
Si les conteneurs et les machines virtuelles (VM) sont tous deux utilisés pour isoler les applications, ils diffèrent considérablement dans leur mode de fonctionnement et leurs cas d'utilisation. Voici une analyse des principales différences et des avantages :
|
Aspect |
Conteneurs |
Machines virtuelles (VM) |
|
L'architecture |
Partage du noyau du système d'exploitation hôte ; léger et isolé. |
Inclure un système d'exploitation complet ; fonctionner sur un hyperviseur. |
|
Performance |
Léger, démarrage rapide et faible consommation de ressources. |
Plus lourd, démarrage plus lent et utilisation plus importante des ressources en raison de la surcharge totale du système d'exploitation. |
|
Portabilité |
Hautement portable ; fonctionne de manière cohérente dans tous les environnements. |
Moins portable en raison des dépendances du système d'exploitation ; peut être confronté à des problèmes de compatibilité. |
|
Évolutivité |
Facilement extensible à l'aide d'outils d'orchestration tels que Kubernetes. |
Evolutif mais nécessite plus de ressources et d'efforts de gestion. |
|
Sécurité |
S'appuie sur la sécurité du système d'exploitation de l'hôte ; moins d'isolation que les VM. |
Forte isolation grâce à des instances de système d'exploitation distinctes ; plus sûr pour les applications sensibles. |
Pour les applications d'apprentissage automatique, ces différences sont importantes. Lorsque vous devez faire évoluer votre modèle pour traiter davantage de prédictions, ou lorsque vous souhaitez déployer plusieurs versions de votre modèle pour des tests A/B, les conteneurs vous apportent l'agilité et l'efficacité des ressources dont vous avez besoin.
Pour en savoir plus sur la conteneurisation et la virtualisation, consultez ce cursus d'apprentissage : Conteneurisation et virtualisation avec Docker et Kubernetes.
Dans les sections ci-dessous, nous avons décrit un guide étape par étape sur la façon de conteneuriser une application :
Avant de commencer à conteneuriser notre application d'apprentissage automatique, nous devons mettre en place les outils nécessaires et préparer notre environnement. Cette section vous guidera dans l'installation de Docker et la préparation d'une application simple d'apprentissage automatique pour la conteneurisation.
Pour conteneuriser une application d'apprentissage automatique, vous aurez besoin des outils suivants :
Commençons par installer Docker.
Docker est disponible pour Windows, macOS et Linux. Vous trouverez ci-dessous les étapes à suivre pour installer Docker sur votre système.
Pour Windows/macOS :
Pour Linux (Ubuntu/Debian) :
Ouvrez votre terminal et exécutez les commandes suivantes pour installer Docker :
# Update your package list
sudo apt-get update
# Install required packages to allow apt to use a repository over HTTPS
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
# Add Docker’s official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# Add the Docker repository to your system
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Update your package list again
sudo apt-get update
# Install Docker
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# Verify Docker installation
sudo docker --versionCe processus d'installation ajoute le dépôt Docker à votre système, vérifie son authenticité à l'aide de la clé GPG et installe le moteur Docker ainsi que ses outils de ligne de commande.
Une fois Docker installé, vérifiez qu'il fonctionne correctement en exécutant la commande suivante dans l'invite de commande :
# Check Docker version
docker --version
# Run hello-world container
docker run hello-worldCela permet d'obtenir une image de test légère et de l'exécuter en tant que conteneur. Si vous réussissez, vous verrez apparaître un message de bienvenue confirmant que votre installation fonctionne correctement, comme indiqué ci-dessous :
Hello from Docker!Maintenant que Docker est installé, préparons une simple application d'apprentissage automatique pour la conteneurisation. Pour ce tutoriel, nous utiliserons un script Python de base qui charge un modèle pré-entraîné et sert les prédictions via une API Flask.
Créez un nouveau répertoire pour votre projet et ajoutez les fichiers suivants :
Voici le code de app.py :
# Import required libraries
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from flask import Flask, request, jsonify
import numpy as np
# Initialize Flask app
app = Flask(__name__)
# Load and prepare the model
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
@app.route('/predict', methods=['POST'])
def predict():
# Get features from request
features = request.json['features']
# Make prediction
prediction = model.predict([features])
return jsonify({'prediction': int(prediction[0]),
'class_name': iris.target_names[prediction[0]]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)Le code charge l'ensemble de données Iris, entraîne un classificateur de type Random Forestet met en place un point d'accès à l'API Flask qui accepte les valeurs des caractéristiques et renvoie les prédictions. Nous le construisons comme un service web pour qu'il soit adapté à la conteneurisation.
Étape 2 : Créer requirements.txt
Le fichierrequirements.txt dresse la liste des bibliothèques Python nécessaires à l'exécution du script. Créez ce fichier dans le même répertoire que app.py :
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
flask==2.0.1Cela permet de spécifier les versions exactes des paquets Python dont notre application a besoin. Le fait d'avoir des versions fixes garantit que notre application conteneurisée sera cohérente et reproductible.
Maintenant que notre environnement est configuré et que notre application ML est prête, nous pouvons passer à la construction de notre premier conteneur Docker. Dans la section suivante, nous allons écrire une page Dockerfile et construire une image Docker pour notre application ML basée sur Flask.
Maintenant que notre application d'apprentissage automatique est prête, l'étape suivante consiste à la conteneuriser à l'aide de Docker. Cela implique la création d'un Dockerfile, qui est un script contenant des instructions pour la construction d'une image Docker. Une fois l'image construite, nous pouvons l'exécuter en tant que conteneur.
Un Dockerfile est un document texte qui contient toutes les commandes pour assembler une image. Voici comment en créer un pour notre application ML basée sur Flask.
app.py et requirements.txtcréez un nouveau fichier nommé Dockerfile (sans extension).Dockerfile:# Use an official Python runtime as the base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install the Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code into the container
COPY . .
# Expose port 5000 for the Flask app
EXPOSE 5000
# Define the command to run the Flask app
CMD ["python", "app.py"]Explication :
FROM python:3.9-slim: Nous utilisons l'image officielle de Python 3.9 slim comme image de base. La version mince est légère et idéale pour les applications en conteneur.WORKDIR /app: Le répertoire de travail à l'intérieur du conteneur est alors /app. Toutes les commandes suivantes seront exécutées à partir de ce répertoire.COPY requirements.txt .: Copie le fichier requirements.txt de votre machine locale vers le conteneur.RUN pip install --no-cache-dir -r requirements.txt: Installe les dépendances Python listées dans requirements.txt. L' option --no-cache-dir réduit la taille de l'image en ne stockant pas le cache.COPY . .: Copie tous les fichiers du répertoire actuel de votre machine locale dans le répertoire /app du conteneur.EXPOSE 5000: Expose le port 5000, qui est le port sur lequel notre application Flask écoute.CMD ["python", "app.py"]: Définit la commande d'exécution de l'application Flask au démarrage du conteneur.Avec le fichier Docker en place, nous pouvons maintenant construire l'image Docker et l'exécuter en tant que conteneur.
Exécutez la commande suivante dans le terminal pour construire l'image Docker :
docker build -t ml-flask-app .Cette commande construit une image Docker à partir du fichier Dockerfile dans le répertoire actuel. Le drapeau -t ml-flask-app marque l'image avec le nom ml-flask-app, ce qui permet de s'y référer plus facilement par la suite.
Une fois l'image construite, exécutez-la en tant que conteneur à l'aide de la commande suivante :
docker run -p 5000:5000 ml-flask-appCette commande permet de démarrer un conteneur à partir de l'imageml-flask-app. Le drapeau -p 5000:5000 fait correspondre le port 5000 de votre machine locale au port 5000 du conteneur, ce qui vous permet d'accéder à l'application Flask à partir de votre navigateur ou d'un outil tel que curl.
Ouvrez une nouvelle fenêtre de terminal et envoyez une requête de test à l'application Flask qui s'exécute dans le conteneur :
curl -X POST -H "Content-Type: application/json" -d '{"input": [5.1, 3.5, 1.4, 0.2]}' http://localhost:5000/predictVous devriez obtenir une réponse de ce type :
{
"prediction": 0
}Cela signifie que l'application Flask conteneurisée fonctionne correctement et qu'elle est prête à servir des prédictions.
Si vous rencontrez des problèmes lors de la construction ou de l'exécution du conteneur, voici quelques conseils pour vous aider à résoudre le problème :
Vérifiez les journaux Docker :Utilisez la commande suivante pour afficher les journaux d'un conteneur en cours d'exécution :
docker logs <container_id>Vérifiez la syntaxe du fichier Docker :Vérifiez que le fichier Docker ne contient pas de fautes de frappe ou d'erreurs de syntaxe.
Vérifiez les conflits de port :Assurez-vous que le port 5000 n'est pas déjà utilisé sur votre machine locale. Si c'est le cas, vous pouvez affecter le conteneur à un port différent, comme ceci :
docker run -p 5001:5000 ml-flask-appReconstruire l'image :
Si vous apportez des modifications au fichier Docker ou au code de l'application, reconstruisez l'image en utilisant :
docker build -t ml-flask-app .Maintenant que nous avons construit et testé avec succès notre conteneur Docker, l'étape suivante consiste à apprendre comment gérer et faire évoluer l'application conteneurisée. Dans la section suivante, nous allons explorer comment utiliser Kubernetes pour déployer et mettre à l'échelle notre application ML.
Découvrez d'autres projets Docker dans notre guide 10 idées de projets Docker : Du débutant au confirmé.
Maintenant que nous avons construit notre conteneur Docker, voyons comment le gérer efficacement. Cette section vous guidera à travers les commandes Docker essentielles pour démarrer, arrêter et inspecter les conteneurs, ainsi que pour travailler avec les journaux et les ports.
Docker fournit un ensemble de commandes puissantes pour gérer les conteneurs. Passons en revue les plus couramment utilisés.
Pour démarrer un conteneur à partir d'une image, utilisez la commandedocker run. Par exemple :
docker run -p 5000:5000 ml-flask-appCette commande démarre un conteneur à partir de l'image ml-flask-app et fait correspondre le port 5000 de votre machine locale au port 5000 du conteneur.
Si vous souhaitez exécuter le conteneur en arrière-plan (mode détaché), ajoutez l'option -d à l'aide d'un drapeau :
docker run -d -p 5000:5000 ml-flask-appCela permet au conteneur de fonctionner en arrière-plan, libérant ainsi votre terminal.
Pour arrêter un conteneur en cours d'exécution, recherchez d'abord son ID de conteneur à l'aide de la commande
docker psElle répertorie tous les conteneurs en cours d'exécution avec leur identifiant, leur nom et d'autres détails. Une fois que vous avez l'ID du conteneur, arrêtez le conteneur avec :
docker stop <container_id>Par exemple :
docker stop a1b2c3d4e5f6Pour afficher des informations détaillées sur un conteneur, utilisez la commande docker inspect pour afficher des informations détaillées sur un conteneur :
docker inspect <container_id>Vous obtiendrez une sortie JSON contenant des détails tels que les paramètres réseau du conteneur, les volumes montés et les variables d'environnement.
Pour voir tous les conteneurs (en cours d'exécution et arrêtés), utilisez :
docker ps -aCette fonction est utile pour vérifier l'état de vos conteneurs et trouver les identifiants des conteneurs.
Les journaux et les ports sont essentiels pour déboguer et accéder à notre application conteneurisée. Voyons comment travailler avec eux.
Pour afficher les journaux d'un conteneur en cours d'exécution, utilisez :
docker logs <container_id>Par exemple :
docker logs a1b2c3d4e5f6Elle affiche la sortie de votre application, y compris les erreurs ou les messages imprimés sur la console. Si vous souhaitez suivre les journaux en temps réel (comme tail -f ), ajoutez le drapeau-f:
docker logs -f <container_id>Lors de l'exécution d'un conteneur, vous pouvez faire correspondre les ports du conteneur à votre machine locale à l'aide de l'option-p. Par exemple :
docker run -p 5000:5000 ml-flask-appCela permet de faire correspondre le port 5000 du conteneur au port 5000 de votre machine locale. Si le port 5000 est déjà utilisé, vous pouvez l'affecter à un autre port, comme suit :
docker run -p 5001:5000 ml-flask-appMaintenant, votre application Flask sera accessible à l'adresse http://localhost:5001.
Pour voir quels ports sont mappés à un conteneur en cours d'exécution, utilisez :
docker port <container_id>Cette liste énumère les mappages de ports pour le conteneur, ce qui est utile pour déboguer les problèmes de connectivité. Dans la section suivante, nous verrons comment déployer notre application ML conteneurisée sur Kubernetes et la gérer à l'échelle.
Une fois notre application conteneurisée, nous pouvons la déployer à l'aide de Kubernetes. Kubernetes automatise le déploiement, la mise à l'échelle et la gestion des applications conteneurisées, ce qui facilite la gestion des charges de travail à grande échelle. Dans cette section, nous allons voir comment déployer notre application ML sur un cluster Kubernetes.
Kubernetes utilise des fichiers YAML pour définir l'état souhaité de votre application. Ces fichiers décrivent comment vos conteneurs doivent être déployés, mis à l'échelle et gérés. Commençons par créer un déploiement Kubernetes pour notre application ML basée sur Flask.
Créez un fichier nommé ml-flask-app-deployment.yaml avec le contenu suivant :
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: ml-flask-app
template:
metadata:
labels:
app: ml-flask-app
spec:
containers:
- name: ml-flask-app
image: ml-flask-app
ports:
- containerPort: 5000Ce fichier YAML définit :
ml-flask-app.ml-flask-app que nous avons construite précédemment.Pour déployer l'application sur Kubernetes, utilisez la commande kubectl apply commande :
kubectl apply -f ml-flask-app-deployment.yamlCette commande indique à Kubernetes de créer les ressources définies dans le fichier YAML. Vous pouvez vérifier l'état du déploiement à l'aide de :
kubectl get deploymentsElle indique l'état de votre déploiement, y compris le nombre de répliques en cours d'exécution.
Pour rendre l'application accessible en dehors du cluster Kubernetes, créez un service. Créez un fichier nommé ml-flask-app-service.yaml avec le contenu suivant :
apiVersion: v1
kind: Service
metadata:
name: ml-flask-app-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 5000
selector:
app: ml-flask-appCe fichier YAML définit :
ml-flask-app-service.Appliquer le service en utilisant :
kubectl apply -f ml-flask-app-service.yamlVous pouvez vérifier l'état du service en utilisant :
kubectl get servicesElle indique l'adresse IP externe à laquelle votre application est accessible.
Kubernetes facilite la mise à l'échelle de votre application et le contrôle de ses performances. Voyons comment procéder.
Pour faire évoluer votre application, mettez à jour le nombre de répliques dans le déploiement. Par exemple, pour passer à 5 répliques, exécutez :
kubectl scale deployment ml-flask-app --replicas=5Vous pouvez également mettre à jour le champ replicas dans le fichier YAML et l'appliquer à nouveau :
spec:
replicas: 5Ensuite, courez :
kubectl apply -f ml-flask-app-deployment.yamlKubernetes fournit plusieurs outils pour surveiller notre application. Examinons quelques-uns des outils permettant de surveiller notre application.
Utilisez kubectl logs pour afficher les journaux d'un module spécifique :
kubectl logs <pod_name>
Utilisez kubectl get pods pour vérifier l'état de vos modules :
kubectl get podsUtilisez kubectl top pour visualiser l'utilisation du processeur et de la mémoire :
kubectl top podsKubernetes prend également en charge Horizontal Pod Autoscaler (HPA), qui adapte automatiquement le nombre de pods en fonction de l'utilisation du processeur ou de la mémoire. Pour activer la mise à l'échelle automatique, exécutez :
kubectl autoscale deployment ml-flask-app --cpu-percent=50 --min=3 --max=10Cela garantit que le déploiement évolue entre 3 et 10 répliques en fonction de l'utilisation de l'unité centrale.
Voici quelques bonnes pratiques à suivre lors du déploiement d'applications sur Kubernetes.
Définissez des limites de CPU et de mémoire pour vos conteneurs afin d'éviter l'épuisement des ressources :
resources:
limits:
cpu: "1"
memory: "512Mi"Ajoutez des contrôles de santé pour vous assurer que votre application fonctionne correctement :
livenessProbe:
httpGet:
path: /health
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
Organisez vos ressources en utilisant des espaces de noms pour éviter les conflits :
kubectl create namespace ml-app
kubectl apply -f ml-flask-app-deployment.yaml -n ml-appDans la section suivante, nous aborderons des conseils pour optimiser les Dockerfiles, gérer les dépendances et assurer la sécurité.
La conteneurisation des applications d'apprentissage automatique s'accompagne de son propre lot de défis, tels que la gestion de dépendances importantes, la garantie de la reproductibilité et le maintien de la sécurité. Voici quelques bonnes pratiques qui vous aideront à surmonter ces difficultés et à créer des applications ML conteneurisées robustes.
Un fichier Docker bien optimisé peut réduire considérablement les temps de construction et la taille des images. Voici quelques conseils pour optimiser vos Dockerfiles :
Les constructions en plusieurs étapes nous permettent d'utiliser plusieurs déclarations FROM dans un seul fichier Docker. Cela permet de réduire la taille de l'image finale en éliminant les fichiers inutiles et les dépendances des étapes intermédiaires. Par exemple :
# Stage 1: Build the application
FROM python:3.9-slim as builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --user -r requirements.txt
COPY . .
# Stage 2: Create the final image
FROM python:3.9-slim
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY --from=builder /app .
ENV PATH=/root/.local/bin:$PATH
EXPOSE 5000
CMD ["python", "app.py"]Ce fichier Docker :
builder pour installer les dépendances et construire l'application.Chaque instruction d'un fichier Docker crée une nouvelle couche. Pour minimiser le nombre de couches et réduire la taille de l'image :
RUN Combinez plusieurs commandes en une seule en utilisant &&.COPY au lieu de ADD à moins que vous n'ayez besoin de la fonctionnalité supplémentaire de ADD.Par exemple :
RUN apt-get update && \
apt-get install -y --no-install-recommends build-essential && \
rm -rf /var/lib/apt/lists/*Choisissez des images de base légères comme python:3.9-slim plutôt que des images plus grandes comme python:3.9. Les images allégées ne contiennent que les paquets essentiels, ce qui réduit la taille globale de l'image.
La reproductibilité est essentielle dans les flux de travail d'apprentissage automatique. Voici comment gérer les dépendances et assurer la reproductibilité de vos applications conteneurisées.
Listez toutes vos dépendances Python dans un fichier requirements.txt ou utilisez pipenv pour les gérer. Par exemple :
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Installez les dépendances dans votre fichier Docker :
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txtVérifiez toujours les versions de vos dépendances afin d'éviter des changements inattendus. Par exemple :
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Utilisez les variables d'environnement pour configurer l'application au lieu de coder des valeurs en dur. Cela rend votre conteneur plus flexible et plus facile à configurer dans différents environnements. Par exemple :
ENV MODEL_PATH=/app/models/model.pklAccédez ensuite à la variable d'environnement dans votre application :
import os
model_path = os.getenv('MODEL_PATH')La sécurité est un aspect essentiel des applications conteneurisées. Voici quelques bonnes pratiques pour sécuriser vos applications de ML :
L'exécution de conteneurs en tant qu'utilisateurroot peut exposer votre système à des risques de sécurité. Au lieu de cela, créez un utilisateur non root et exécutez le conteneur sous cet utilisateur. Par exemple :
# Create a non-root user
RUN useradd -m myuser
# Switch to the non-root user
USER myuser
# Set the working directory
WORKDIR /home/myuser/app
# Copy the application code
COPY --chown=myuser:myuser . .
# Run the application
CMD ["python", "app.py"]Utilisez des outils tels que Trivy ou Clair pour analyser vos images Docker à la recherche de vulnérabilités. Par exemple, pour numériser une image avec Trivy :
trivy image ml-flask-appNe codifiez jamais en dur des informations sensibles telles que des clés d'API ou des identifiants de base de données dans votre fichier Docker ou dans le code de votre application. Utilisez plutôt Kubernetes Secrets ou Docker Secrets pour gérer les données sensibles. Par exemple, dans Kubernetes :
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
api_key: <base64-encoded-api-key>Ensuite, montez le secret en tant que variable d'environnement dans votre déploiement :
env:
- name: API_KEY
valueFrom:
secretKeyRef:
name: my-secret
key: api_keyLes tests et le débogage sont essentiels pour s'assurer que votre application conteneurisée fonctionne comme prévu. Voici quelques conseils :
Avant de le déployer sur Kubernetes, testez votre conteneur localement à l'aide de Docker. Par exemple :
docker run -p 5000:5000 ml-flask-appUtilisez docker logs ou kubectl logs pour déboguer les problèmes de votre application conteneurisée. Par exemple :
docker logs <container_id>
kubectl logs <pod_name>Utilisez les pipelines CI/CD pour automatiser les tests et le déploiement de vos applications conteneurisées. Des outils tels que GitHub Actions, GitLab CI ou Jenkins peuvent nous aider à mettre en place des flux de travail automatisés.
En suivant ces bonnes pratiques, nous pouvons créer des applications d'apprentissage automatique conteneurisées efficaces, reproductibles et sécurisées. De l'optimisation des fichiers Docker à la gestion des dépendances et à la garantie de la sécurité, ces stratégies nous aideront à rationaliser nos flux de travail ML et à déployer des modèles en toute confiance.
La conteneurisation des applications d'apprentissage automatique avec Docker et Kubernetes rationalise le déploiement, garantit la reproductibilité et améliore l'évolutivité. En suivant les meilleures pratiques telles que l'optimisation des fichiers Docker, la gestion des dépendances et la priorité donnée à la sécurité, nous pouvons construire des flux de travail de ML robustes, efficaces et sécurisés.
Pour continuer à vous familiariser avec la conteneurisation et améliorer vos flux de travail d'apprentissage automatique, consultez ces cours :
Les meilleurs cours de DataCamp
Cursus
Cours
Cours