programa
Contenedores y virtualización con Docker y Kubernetes
13 h
A medida que las aplicaciones de aprendizaje automático se vuelven más complejas, conseguir que nuestros modelos de aprendizaje automático pasen del desarrollo a la producción no consiste sólo en escribir un buen código. Se trata de garantizar que nuestra aplicación funcione de forma coherente en distintos entornos. Aquí es donde entra en juego la contenedorización. Pero, ¿qué es exactamente la contenedorización y por qué supone un cambio de juego para los flujos de trabajo del aprendizaje automático?
La contenerización es una forma ligera y portátil de empaquetar una aplicación junto con todas sus dependencias, bibliotecas y configuraciones en una única unidad llamada contenedor. A diferencia de las máquinas virtuales (VM) tradicionales, los contenedores comparten el sistema operativo del sistema anfitrión, lo que los hace más rápidos, eficientes y fáciles de escalar.
Para los científicos de datos y los ingenieros de ML, esto significa que puedes construir un modelo en tu máquina local y desplegarlo en cualquier lugar, ya sea en una plataforma en la nube, en un servidor o incluso en el portátil de un colega, sin preocuparte por problemas de compatibilidad.
En este tutorial, veremos cómo contenerizar una aplicación de aprendizaje automático utilizando Docker y Kubernetes. Al final, sabrás cómo hacerlo:
Si eres nuevo en Docker, consulta nuestra guía sobre Cómo aprender Docker desde cero. También puedes realizar nuestro curso Containerización y Virtualización con Docker y Kubernetes.
Antes de sumergirte en él, debes tener conocimientos básicos de Python, de los flujos de trabajo del aprendizaje automático y de cómo trabajar con la línea de comandos. Familiaridad con conceptos de Docker (por ejemplo, imágenes, contenedores, comandos básicos), y conocimientos básicos de Kubernetes es opcional pero útil para el despliegue y el escalado.
Una aplicación en contenedor es una aplicación de software empaquetada con todas sus dependencias, bibliotecas y configuraciones en una única unidad ligera llamada contenedor. Para las aplicaciones de aprendizaje automático, esto significa empaquetar todo, desde tu modelo entrenado hasta las bibliotecas de Python de las que depende, asegurando que tu aplicación se ejecuta de la misma manera en todas partes.
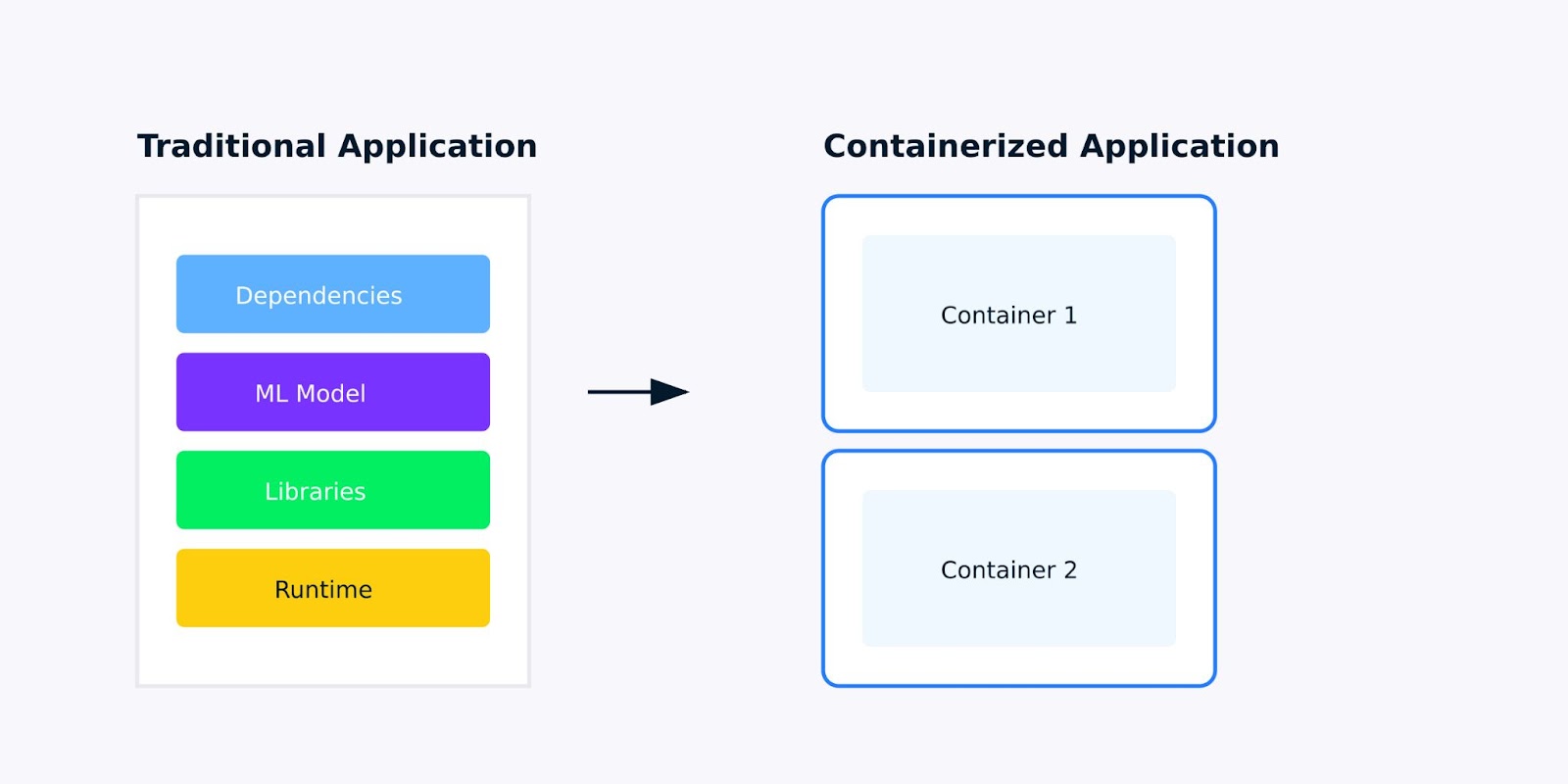
Aplicación tradicional frente a aplicación en contenedor
Cuando desarrollas aplicaciones de aprendizaje automático, probablemente te hayas encontrado con el problema de "funciona en mi máquina". Puede que tu modelo funcione perfectamente en tu portátil pero falle al desplegarlo en la nube, o que un colega no pueda reproducir tus resultados porque tienen instaladas versiones diferentes de scikit-learn o TensorFlow.
La contenedorización resuelve estos problemas creando un entorno coherente y aislado para tu aplicación. Esto es lo que hace que las aplicaciones en contenedores sean mejores para el aprendizaje automático:
Aunque tanto los contenedores como las máquinas virtuales (VM) se utilizan para aislar aplicaciones, difieren significativamente en su funcionamiento y en sus casos de uso. Aquí tienes un desglose de las principales diferencias y ventajas:
|
Aspecto |
Contenedores |
Máquinas virtuales (VM) |
|
Arquitectura |
Comparte el núcleo del SO anfitrión; ligero y aislado. |
Incluyen un SO completo; se ejecutan en un hipervisor. |
|
Rendimiento |
Ligero, de inicio rápido y baja sobrecarga de recursos. |
Arranque más pesado y lento, y mayor uso de recursos debido a la sobrecarga total del SO. |
|
Portabilidad |
Altamente portátil; funciona de forma consistente en todos los entornos. |
Menos portátil debido a las dependencias del sistema operativo; puede tener problemas de compatibilidad. |
|
Escalabilidad |
Fácilmente escalable mediante herramientas de orquestación como Kubernetes. |
Escalable, pero requiere más recursos y esfuerzo de gestión. |
|
Seguridad |
Depende de la seguridad del SO anfitrión; menos aislamiento que las máquinas virtuales. |
Fuerte aislamiento gracias a las instancias separadas del SO; más seguro para las aplicaciones sensibles. |
Para las aplicaciones de aprendizaje automático, estas diferencias son importantes. Cuando necesites escalar tu modelo para manejar más predicciones, o cuando quieras desplegar varias versiones de tu modelo para pruebas A/B, los contenedores te proporcionan la agilidad y la eficiencia de recursos que necesitas.
Para saber más sobre la contenedorización y la virtualización, consulta esta pista de aprendizaje: Containerización y virtualización con Docker y Kubernetes.
En las secciones siguientes, hemos esbozado una guía paso a paso sobre cómo contenerizar una aplicación:
Antes de empezar a contenerizar nuestra aplicación de aprendizaje automático, tenemos que configurar las herramientas necesarias y preparar nuestro entorno. Esta sección te guiará a través de la instalación de Docker y la preparación de una sencilla aplicación de aprendizaje automático para la contenedorización.
Para contenerizar una aplicación de aprendizaje automático, necesitarás las siguientes herramientas:
Empecemos por instalar Docker.
Docker está disponible para Windows, macOS y Linux. A continuación se indican los pasos para instalar Docker en tu sistema.
Para Windows/macOS:
Para Linux (Ubuntu/Debian):
Abre tu terminal y ejecuta los siguientes comandos para instalar Docker:
# Update your package list
sudo apt-get update
# Install required packages to allow apt to use a repository over HTTPS
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
# Add Docker’s official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# Add the Docker repository to your system
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Update your package list again
sudo apt-get update
# Install Docker
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# Verify Docker installation
sudo docker --versionEste proceso de instalación añade el repositorio Docker a tu sistema, verifica su autenticidad con la clave GPG e instala el motor Docker junto con sus herramientas de línea de comandos.
Una vez instalado Docker, comprueba que funciona correctamente ejecutando el siguiente comando en el símbolo del sistema:
# Check Docker version
docker --version
# Run hello-world container
docker run hello-worldEsto extrae una imagen de prueba ligera y la ejecuta como contenedor. Si tiene éxito, verás un mensaje de bienvenida confirmando que la instalación funciona correctamente, como se muestra a continuación:
Hello from Docker!Ahora que Docker está instalado, vamos a preparar una sencilla aplicación de aprendizaje automático para la contenerización. Para este tutorial, utilizaremos un script básico de Python que carga un modelo preentrenado y sirve predicciones a través de una API de Flask.
Crea un nuevo directorio para tu proyecto y añade los siguientes archivos:
Aquí tienes el código de app.py:
# Import required libraries
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from flask import Flask, request, jsonify
import numpy as np
# Initialize Flask app
app = Flask(__name__)
# Load and prepare the model
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
@app.route('/predict', methods=['POST'])
def predict():
# Get features from request
features = request.json['features']
# Make prediction
prediction = model.predict([features])
return jsonify({'prediction': int(prediction[0]),
'class_name': iris.target_names[prediction[0]]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)El código carga el conjunto de datos Iris, entrena un clasificador Random Foresty configura un punto final de la API de Flask que acepta valores de características y devuelve predicciones. Estamos construyendo esto como un servicio web para que sea adecuado para la contenedorización.
Paso 2: Crea requirements.txt
El archivorequirements.txt enumera las bibliotecas Python necesarias para ejecutar el script. Crea este archivo en el mismo directorio que app.py:
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
flask==2.0.1Especifica las versiones exactas de los paquetes de Python que necesita nuestra aplicación. Tener versiones fijas garantiza que nuestra aplicación en contenedores será coherente y reproducible.
Ahora que nuestro entorno está configurado y nuestra aplicación ML está lista, podemos pasar a construir nuestro primer contenedor Docker. En la siguiente sección, escribiremos un Dockerfile y construiremos una imagen Docker para nuestra aplicación ML basada en Flask.
Ahora que nuestra aplicación de aprendizaje automático está lista, el siguiente paso es contenerizarla utilizando Docker. Esto implica crear un Dockerfile, que es un script que contiene instrucciones para construir una imagen Docker. Una vez construida la imagen, podemos ejecutarla como contenedor.
Un Dockerfile es un documento de texto que contiene todos los comandos para montar una imagen. He aquí cómo crear uno para nuestra aplicación ML basada en Flask.
app.py y requirements.txtcrea un nuevo archivo llamado Dockerfile (sin extensión de archivo).Dockerfile:# Use an official Python runtime as the base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install the Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code into the container
COPY . .
# Expose port 5000 for the Flask app
EXPOSE 5000
# Define the command to run the Flask app
CMD ["python", "app.py"]Explicación:
FROM python:3.9-slim: Estamos utilizando la imagen slim oficial de Python 3.9 como imagen base. La versión delgada es ligera e ideal para aplicaciones en contenedores.WORKDIR /app: Esto establece el directorio de trabajo dentro del contenedor en /app. Todos los comandos posteriores se ejecutarán desde este directorio.COPY requirements.txt .: Copia el archivo requirements.txt de tu máquina local al contenedor.RUN pip install --no-cache-dir -r requirements.txt: Instala las dependencias de Python enumeradas en requirements.txt. La bandera --no-cache-dir reduce el tamaño de la imagen al no almacenar la caché.COPY . .: Copia todos los archivos del directorio actual de tu máquina local al directorio /app del contenedor.EXPOSE 5000: Expone el puerto 5000, que es el puerto en el que escucha nuestra aplicación Flask.CMD ["python", "app.py"]: Define el comando para ejecutar la aplicación Flask cuando se inicie el contenedor.Con el Dockerfile en su lugar, ahora podemos construir la imagen Docker y ejecutarla como un contenedor.
Ejecuta el siguiente comando en el terminal para construir la imagen Docker:
docker build -t ml-flask-app .Este comando crea una imagen Docker a partir del archivo Dockerfile del directorio actual. La bandera -t ml-flask-app etiqueta la imagen con el nombre ml-flask-app, facilitando su posterior consulta.
Una vez construida la imagen, ejecútala como contenedor utilizando el siguiente comando:
docker run -p 5000:5000 ml-flask-appEste comando inicia un contenedor desde la imagenml-flask-app. La bandera -p 5000:5000 asigna el puerto 5000 de tu máquina local al puerto 5000 del contenedor, lo que te permite acceder a la aplicación Flask desde tu navegador o desde una herramienta como curl.
Abre una nueva ventana de terminal y envía una petición de prueba a la aplicación Flask que se ejecuta dentro del contenedor:
curl -X POST -H "Content-Type: application/json" -d '{"input": [5.1, 3.5, 1.4, 0.2]}' http://localhost:5000/predictDeberías ver una respuesta como ésta:
{
"prediction": 0
}Esto significa que la aplicación Flask en contenedor se está ejecutando correctamente y está lista para servir predicciones.
Si te encuentras con problemas mientras construyes o ejecutas el contenedor, aquí tienes algunos consejos que te ayudarán a solucionarlos:
Comprueba los registros de Docker:Utiliza el siguiente comando para ver los registros de un contenedor en ejecución:
docker logs <container_id>Verifica la sintaxis del Dockerfile:Comprueba dos veces que el Dockerfile no contenga errores tipográficos o de sintaxis.
Comprueba los conflictos de puertos:Asegúrate de que el puerto 5000 no está ya en uso en tu máquina local. Si es así, puedes asignar el contenedor a un puerto diferente, así
docker run -p 5001:5000 ml-flask-appReconstruye la imagen:
Si realizas cambios en el archivo Docker o en el código de la aplicación, reconstruye la imagen utilizando:
docker build -t ml-flask-app .Ahora que hemos construido y probado con éxito nuestro contenedor Docker, el siguiente paso es aprender a gestionar y escalar la aplicación en contenedor. En la siguiente sección, exploraremos cómo utilizar Kubernetes para desplegar y escalar nuestra aplicación ML.
Echa un vistazo a más proyectos Docker en nuestra guía 10 Ideas de Proyectos Docker: De principiante a avanzado.
Ahora que hemos construido nuestro contenedor Docker, veamos cómo gestionarlo eficazmente. Esta sección te guiará a través de los comandos esenciales de Docker para iniciar, detener e inspeccionar contenedores, así como para trabajar con registros y puertos.
Docker proporciona un conjunto de potentes comandos para gestionar contenedores. Repasemos los más utilizados.
Para iniciar un contenedor desde una imagen, utiliza el comandodocker run. Por ejemplo:
docker run -p 5000:5000 ml-flask-appEste comando inicia un contenedor desde la imagen ml-flask-app y asigna el puerto 5000 de tu máquina local al puerto 5000 del contenedor.
Si quieres ejecutar el contenedor en segundo plano (modo separado), añade la bandera -d bandera:
docker run -d -p 5000:5000 ml-flask-appEsto permite que el contenedor se ejecute en segundo plano, liberando tu terminal.
Para detener un contenedor en ejecución, busca primero su ID de contenedor utilizando:
docker psEnumera todos los contenedores en ejecución junto con sus ID, nombres y otros detalles. Una vez que tengas el ID del contenedor, detén el contenedor con:
docker stop <container_id>Por ejemplo:
docker stop a1b2c3d4e5f6Para ver información detallada sobre un contenedor, utiliza el comando docker inspect comando:
docker inspect <container_id>Esto proporciona una salida JSON con detalles como la configuración de red del contenedor, los volúmenes montados y las variables de entorno.
Para ver todos los contenedores (tanto en ejecución como parados), utiliza
docker ps -aEsto es útil para comprobar el estado de tus contenedores y encontrar los ID de contenedor.
Los logs y los puertos son fundamentales para depurar y acceder a nuestra aplicación en contenedores. Exploremos cómo trabajar con ellos.
Para ver los registros de un contenedor en ejecución, utiliza:
docker logs <container_id>Por ejemplo:
docker logs a1b2c3d4e5f6Muestra la salida de tu aplicación, incluidos los errores o mensajes impresos en la consola. Si quieres seguir los registros en tiempo real (como tail -f ), añade la bandera-f:
docker logs -f <container_id>Al ejecutar un contenedor, puedes asignar los puertos del contenedor a tu máquina local utilizando la bandera-p. Por ejemplo:
docker run -p 5000:5000 ml-flask-appEsto asigna el puerto 5000 del contenedor al puerto 5000 de tu máquina local. Si el puerto 5000 ya está en uso, puedes asignarlo a un puerto diferente, así:
docker run -p 5001:5000 ml-flask-appAhora, tu aplicación Flask estará accesible en http://localhost:5001.
Para ver qué puertos están asignados a un contenedor en ejecución, utiliza
docker port <container_id>Enumera las asignaciones de puertos del contenedor, lo que resulta útil para depurar problemas de conectividad. En la siguiente sección, veremos cómo desplegar nuestra aplicación ML en contenedores en Kubernetes y gestionarla a escala.
Una vez que nuestra aplicación está en contenedores, podemos desplegarla utilizando Kubernetes. Kubernetes automatiza el despliegue, escalado y gestión de aplicaciones en contenedores, facilitando el manejo de cargas de trabajo a gran escala. En esta sección, veremos cómo desplegar nuestra aplicación ML en un clúster Kubernetes.
Kubernetes utiliza archivos YAML para definir el estado deseado de tu aplicación. Estos archivos describen cómo deben desplegarse, escalarse y gestionarse tus contenedores. Empecemos creando un despliegue Kubernetes para nuestra aplicación ML basada en Flask.
Crea un archivo llamado ml-flask-app-deployment.yaml con el siguiente contenido:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: ml-flask-app
template:
metadata:
labels:
app: ml-flask-app
spec:
containers:
- name: ml-flask-app
image: ml-flask-app
ports:
- containerPort: 5000Este archivo YAML define:
ml-flask-app.ml-flask-app que hemos creado antes.Para desplegar la aplicación en Kubernetes, utiliza el comando kubectl apply comando
kubectl apply -f ml-flask-app-deployment.yamlEste comando indica a Kubernetes que cree los recursos definidos en el archivo YAML. Puedes comprobar el estado del despliegue utilizando:
kubectl get deploymentsMuestra el estado de tu despliegue, incluido el número de réplicas en ejecución.
Para que la aplicación sea accesible fuera del clúster Kubernetes, crea un Servicio. Crea un archivo llamado ml-flask-app-service.yaml con el siguiente contenido:
apiVersion: v1
kind: Service
metadata:
name: ml-flask-app-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 5000
selector:
app: ml-flask-appEste archivo YAML define:
ml-flask-app-service.Aplica el Servicio utilizando:
kubectl apply -f ml-flask-app-service.yamlPuedes comprobar el estado del Servicio utilizando:
kubectl get servicesMuestra la dirección IP externa desde la que se puede acceder a tu aplicación.
Kubernetes facilita el escalado de tu aplicación y la supervisión de su rendimiento. Exploremos cómo hacerlo.
Para escalar tu aplicación, actualiza el número de réplicas en la implantación. Por ejemplo, para escalar a 5 réplicas, ejecuta
kubectl scale deployment ml-flask-app --replicas=5También puedes actualizar el campo replicas campo en el archivo YAML y volver a aplicarlo:
spec:
replicas: 5Entonces corre:
kubectl apply -f ml-flask-app-deployment.yamlKubernetes proporciona varias herramientas para monitorizar nuestra aplicación. Veamos algunas herramientas para monitorizar nuestra aplicación.
Utiliza kubectl logs para ver los registros de un pod concreto:
kubectl logs <pod_name>
Utiliza kubectl get pods para comprobar el estado de tus pods:
kubectl get podsUtiliza kubectl top para ver el uso de CPU y memoria:
kubectl top podsKubernetes también admite el Autoescalado Horizontal de Pods (HPA), que escala automáticamente el número de pods en función del uso de CPU o memoria. Para activar el autoescalado, ejecuta
kubectl autoscale deployment ml-flask-app --cpu-percent=50 --min=3 --max=10Esto garantiza que el despliegue escale entre 3 y 10 réplicas en función del uso de la CPU.
Estas son algunas de las mejores prácticas que debes seguir cuando despliegues aplicaciones en Kubernetes.
Define límites de CPU y memoria para tus contenedores, para evitar el agotamiento de recursos:
resources:
limits:
cpu: "1"
memory: "512Mi"Añade comprobaciones de salud para asegurarte de que tu aplicación funciona correctamente:
livenessProbe:
httpGet:
path: /health
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
Organiza tus recursos utilizando espacios de nombres para evitar conflictos:
kubectl create namespace ml-app
kubectl apply -f ml-flask-app-deployment.yaml -n ml-appEn la siguiente sección, veremos consejos para optimizar los archivos Docker, gestionar las dependencias y garantizar la seguridad.
La contenedorización de aplicaciones de aprendizaje automático conlleva su propio conjunto de retos, como gestionar grandes dependencias, garantizar la reproducibilidad y mantener la seguridad. Aquí tienes algunas buenas prácticas que te ayudarán a superar estos retos y a crear sólidas aplicaciones ML en contenedores.
Un Dockerfile bien optimizado puede reducir significativamente los tiempos de compilación y el tamaño de las imágenes. Aquí tienes algunos consejos para optimizar tus archivos Docker:
Las construcciones multietapa nos permiten utilizar varias sentencias FROM en un único archivo Dockerfile. Esto ayuda a reducir el tamaño final de la imagen al descartar archivos innecesarios y dependencias de etapas intermedias. Por ejemplo:
# Stage 1: Build the application
FROM python:3.9-slim as builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --user -r requirements.txt
COPY . .
# Stage 2: Create the final image
FROM python:3.9-slim
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY --from=builder /app .
ENV PATH=/root/.local/bin:$PATH
EXPOSE 5000
CMD ["python", "app.py"]Este Dockerfile:
builder para instalar las dependencias y crear la aplicación.Cada instrucción de un archivo Docker crea una nueva capa. Para minimizar el número de capas y reducir el tamaño de la imagen:
RUN comandos en uno solo utilizando &&.COPY en lugar de ADD a menos que necesites la funcionalidad adicional de ADD.Por ejemplo:
RUN apt-get update && \
apt-get install -y --no-install-recommends build-essential && \
rm -rf /var/lib/apt/lists/*Elige imágenes base ligeras como python:3.9-slim en lugar de otras más grandes como python:3.9. Las imágenes delgadas sólo contienen los paquetes esenciales, reduciendo el tamaño total de la imagen.
La reproducibilidad es fundamental en los flujos de trabajo del aprendizaje automático. He aquí cómo gestionar las dependencias y garantizar la reproducibilidad en tus aplicaciones en contenedores.
Lista todas tus dependencias de Python en un archivo requirements.txt o utiliza pipenv para gestionarlas. Por ejemplo:
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Instala las dependencias en tu Dockerfile:
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txtFija siempre las versiones de tus dependencias para evitar cambios inesperados. Por ejemplo:
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Utiliza variables de entorno para configurar la aplicación en lugar de codificar valores. Esto hace que tu contenedor sea más flexible y fácil de configurar en distintos entornos. Por ejemplo:
ENV MODEL_PATH=/app/models/model.pklA continuación, accede a la variable de entorno en tu aplicación:
import os
model_path = os.getenv('MODEL_PATH')La seguridad es un aspecto crítico de las aplicaciones en contenedores. He aquí algunas buenas prácticas para asegurar tus aplicaciones de ML:
Ejecutar contenedores como usuario deroot puede exponer tu sistema a riesgos de seguridad. En su lugar, crea un usuario que no sea root y ejecuta el contenedor como ese usuario. Por ejemplo:
# Create a non-root user
RUN useradd -m myuser
# Switch to the non-root user
USER myuser
# Set the working directory
WORKDIR /home/myuser/app
# Copy the application code
COPY --chown=myuser:myuser . .
# Run the application
CMD ["python", "app.py"]Utiliza herramientas como Trivy o Clair para escanear tus imágenes Docker en busca de vulnerabilidades. Por ejemplo, para escanear una imagen con Trivy:
trivy image ml-flask-appNunca codifiques información sensible, como claves API o credenciales de bases de datos, en tu archivo Docker o en el código de la aplicación. En su lugar, utiliza Kubernetes Secrets o Docker Secrets para gestionar los datos sensibles. Por ejemplo, en Kubernetes:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
api_key: <base64-encoded-api-key>Luego, monta el secreto como una variable de entorno en tu despliegue:
env:
- name: API_KEY
valueFrom:
secretKeyRef:
name: my-secret
key: api_keyLas pruebas y la depuración son esenciales para garantizar que tu aplicación en contenedores funciona como esperas. Aquí tienes algunos consejos:
Antes de desplegarlo en Kubernetes, prueba tu contenedor localmente utilizando Docker. Por ejemplo:
docker run -p 5000:5000 ml-flask-appUtiliza docker logs o kubectl logs para depurar problemas en tu aplicación en contenedor. Por ejemplo:
docker logs <container_id>
kubectl logs <pod_name>Utiliza canalizaciones CI/CD para automatizar las pruebas y el despliegue de tus aplicaciones en contenedores. Herramientas como GitHub Actions, GitLab CI o Jenkins pueden ayudarnos a establecer flujos de trabajo automatizados.
Siguiendo estas prácticas recomendadas, podemos crear aplicaciones de aprendizaje automático en contenedores eficientes, reproducibles y seguras. Desde optimizar los archivos Docker hasta gestionar las dependencias y garantizar la seguridad, estas estrategias nos ayudarán a agilizar nuestros flujos de trabajo de ML y a desplegar modelos con confianza.
La contenedorización de aplicaciones de aprendizaje automático con Docker y Kubernetes agiliza el despliegue, garantiza la reproducibilidad y mejora la escalabilidad. Siguiendo las mejores prácticas, como optimizar los archivos Docker, gestionar las dependencias y priorizar la seguridad, podemos construir flujos de trabajo de ML robustos, eficientes y seguros.
Para seguir aprendiendo sobre la contenedorización y mejorar tus flujos de trabajo de aprendizaje automático, consulta estos cursos:
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Kurtis Pykes
8 min
blog
Zoumana Keita
14 min
Tutorial
Bex Tuychiev
Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan



