Programa
Containerização e virtualização com o Docker e o Kubernetes
13 h
À medida que os aplicativos de aprendizado de máquina se tornam mais complexos, fazer com que nossos modelos de aprendizado de máquina passem do desenvolvimento para a produção não se trata apenas de escrever um bom código. Trata-se de garantir que nosso aplicativo seja executado de forma consistente em diferentes ambientes. É nesse ponto que a conteinerização entra em ação. Mas o que é exatamente a conteinerização e por que ela muda o jogo para os fluxos de trabalho de aprendizado de máquina?
A conteinerização é uma forma leve e portátil de empacotar um aplicativo juntamente com todas as suas dependências, bibliotecas e configurações em uma única unidade chamada contêiner. Diferentemente das máquinas virtuais (VMs) tradicionais, os contêineres compartilham o sistema operacional do sistema host, o que os torna mais rápidos, mais eficientes e mais fáceis de dimensionar.
Para cientistas de dados e engenheiros de ML, isso significa que você pode criar um modelo em sua máquina local e implantá-lo em qualquer lugar, seja em uma plataforma de nuvem, um servidor ou até mesmo no laptop de um colega, sem se preocupar com problemas de compatibilidade.
Neste tutorial, veremos como colocar em contêineres um aplicativo de aprendizado de máquina usando o Docker e o Kubernetes. Ao final, você saberá como fazê-lo:
Se você é novo no Docker, confira nosso guia sobre Como aprender a usar o Docker do zero. Você também pode fazer nosso curso, Containerização e virtualização com Docker e Kubernetes.
Antes de começar, você deve ter um conhecimento básico de Python, fluxos de trabalho de aprendizado de máquina e trabalho com a linha de comando. Familiaridade com conceitos do Docker (por exemplo, imagens, contêineres, comandos básicos) é recomendada, e conhecimento básico do Kubernetes é opcional, mas útil para implantação e dimensionamento.
Um aplicativo em contêiner é um aplicativo de software empacotado com todas as suas dependências, bibliotecas e configurações em uma unidade única e leve chamada contêiner. Para aplicativos de aprendizado de máquina, isso significa empacotar tudo, desde o modelo treinado até as bibliotecas Python das quais ele depende, garantindo que o aplicativo seja executado da mesma forma em todos os lugares.
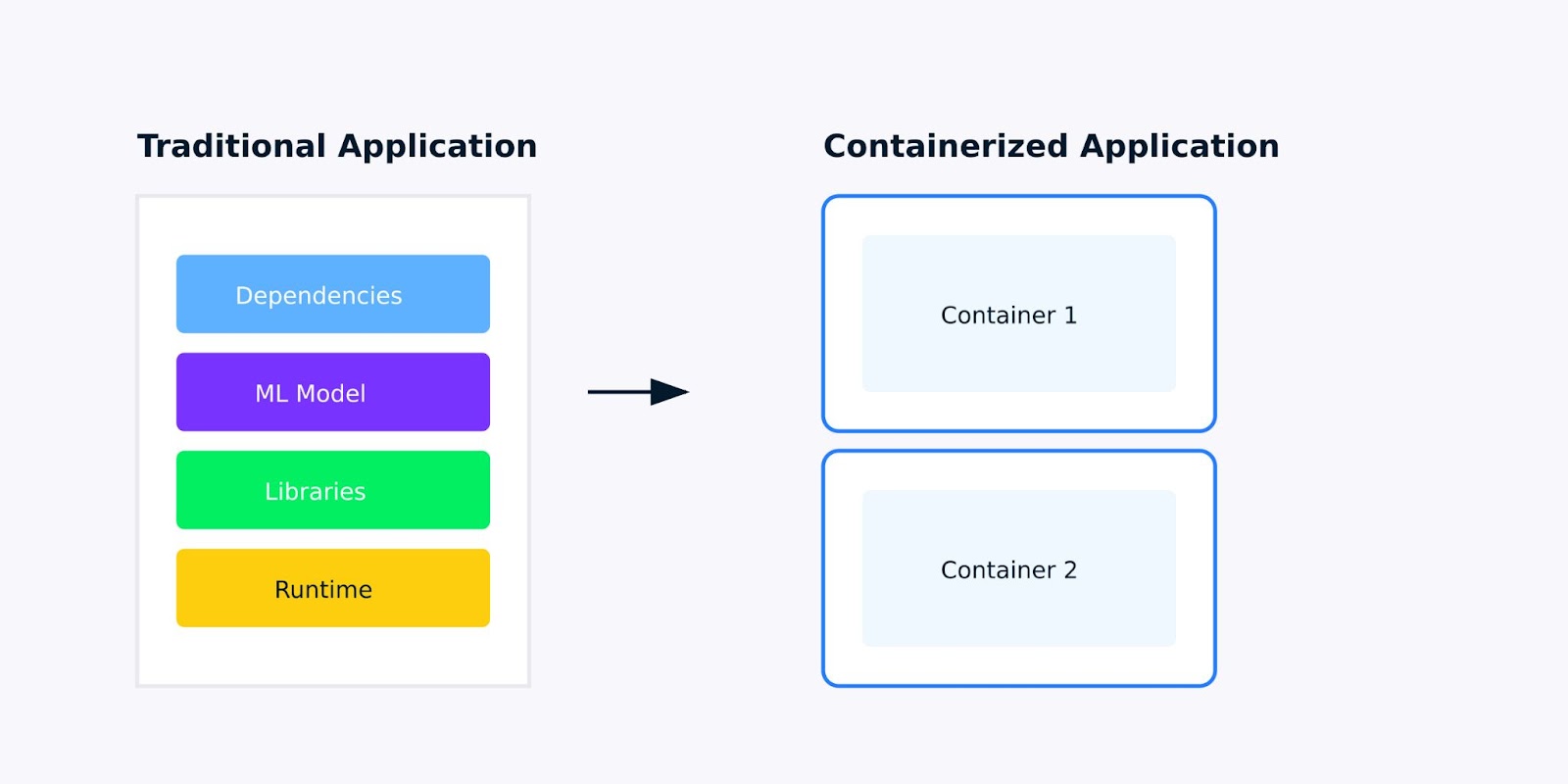
Aplicativo tradicional versus aplicativo em contêiner
Ao desenvolver aplicativos de aprendizado de máquina, você provavelmente já se deparou com o problema "isso funciona na minha máquina". Talvez seu modelo seja executado perfeitamente em seu laptop, mas falhe quando implantado na nuvem, ou um colega não consiga reproduzir seus resultados porque ele tem versões diferentes do scikit-learn ou do TensorFlow instaladas.
A conteinerização resolve esses problemas criando um ambiente consistente e isolado para o seu aplicativo. Veja o que torna os aplicativos em contêineres melhores para o aprendizado de máquina:
Embora tanto os contêineres quanto as máquinas virtuais (VMs) sejam usados para isolar aplicativos, eles diferem significativamente na forma como operam e em seus casos de uso. Aqui você encontra um resumo das principais diferenças e vantagens:
|
Aspecto |
Contêineres |
Máquinas virtuais (VM) |
|
Arquitetura |
Compartilhe o kernel do sistema operacional host; leve e isolado. |
Incluir um sistema operacional completo; ser executado em um hipervisor. |
|
Desempenho |
Leve, de inicialização rápida e com baixa sobrecarga de recursos. |
Inicialização mais pesada, mais lenta e maior uso de recursos devido à sobrecarga total do sistema operacional. |
|
Portabilidade |
Altamente portátil; é executado de forma consistente em todos os ambientes. |
Menos portátil devido às dependências do sistema operacional; você pode ter problemas de compatibilidade. |
|
Escalabilidade |
Facilmente dimensionável usando ferramentas de orquestração como o Kubernetes. |
Escalável, mas requer mais recursos e esforço de gerenciamento. |
|
Segurança |
Depende da segurança do sistema operacional do host; menos isolamento do que as VMs. |
Forte isolamento devido a instâncias separadas do sistema operacional; mais seguro para aplicativos confidenciais. |
Para aplicativos de aprendizado de máquina, essas diferenças são importantes. Quando você precisa dimensionar o modelo para lidar com mais previsões ou quando deseja implantar várias versões do modelo para testes A/B, os contêineres oferecem a agilidade e a eficiência de recursos de que você precisa.
Para saber mais sobre conteinerização e virtualização, confira esta trilha de aprendizado: Containerização e virtualização com Docker e Kubernetes.
Nas seções abaixo, descrevemos um guia passo a passo sobre como conteinerizar um aplicativo:
Antes de começarmos a conteinerizar nosso aplicativo de aprendizado de máquina, precisamos configurar as ferramentas necessárias e preparar nosso ambiente. Esta seção guiará você na instalação do Docker e na preparação de um aplicativo simples de aprendizado de máquina para conteinerização.
Para conteinerizar um aplicativo de aprendizado de máquina, você precisará das seguintes ferramentas:
Vamos começar instalando o Docker.
O Docker está disponível para Windows, macOS e Linux. Abaixo estão as etapas para instalar o Docker em seu sistema.
Para Windows/macOS:
Para Linux (Ubuntu/Debian):
Abra seu terminal e execute os seguintes comandos para instalar o Docker:
# Update your package list
sudo apt-get update
# Install required packages to allow apt to use a repository over HTTPS
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
# Add Docker’s official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# Add the Docker repository to your system
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Update your package list again
sudo apt-get update
# Install Docker
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# Verify Docker installation
sudo docker --versionEsse processo de instalação adiciona o repositório do Docker ao seu sistema, verifica sua autenticidade com a chave GPG e instala o mecanismo do Docker junto com suas ferramentas de linha de comando.
Depois que o Docker estiver instalado, verifique se ele está funcionando corretamente executando o seguinte comando no prompt de comando:
# Check Docker version
docker --version
# Run hello-world container
docker run hello-worldIsso extrai uma imagem de teste leve e a executa como um contêiner. Se for bem-sucedido, você verá uma mensagem de boas-vindas confirmando que a instalação está funcionando corretamente, conforme mostrado abaixo:
Hello from Docker!Agora que o Docker está instalado, vamos preparar um aplicativo simples de aprendizado de máquina para a conteinerização. Para este tutorial, usaremos um script Python básico que carrega um modelo pré-treinado e fornece previsões por meio de uma API do Flask.
Crie um novo diretório para seu projeto e adicione os seguintes arquivos:
Aqui está o código do app.py:
# Import required libraries
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from flask import Flask, request, jsonify
import numpy as np
# Initialize Flask app
app = Flask(__name__)
# Load and prepare the model
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
@app.route('/predict', methods=['POST'])
def predict():
# Get features from request
features = request.json['features']
# Make prediction
prediction = model.predict([features])
return jsonify({'prediction': int(prediction[0]),
'class_name': iris.target_names[prediction[0]]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)O código carrega o conjunto de dados Iris, treina um classificador classificador Random Foreste configura um ponto de extremidade da API do Flask que aceita valores de recursos e retorna previsões. Estamos construindo isso como um serviço da Web para torná-lo adequado à conteinerização.
Etapa 2: Criar requirements.txt
O arquivorequirements.txt lista as bibliotecas Python necessárias para executar o script. Crie esse arquivo no mesmo diretório que app.py:
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
flask==2.0.1Isso especifica as versões exatas dos pacotes Python de que nosso aplicativo precisa. Ter versões fixas garante que nosso aplicativo em contêiner seja consistente e reproduzível.
Agora que nosso ambiente está configurado e nosso aplicativo de ML está pronto, podemos prosseguir com a criação do nosso primeiro contêiner do Docker. Na próxima seção, escreveremos um Dockerfile e criaremos uma imagem do Docker para nosso aplicativo de ML baseado em Flask.
Agora que nosso aplicativo de aprendizado de máquina está pronto, a próxima etapa é colocá-lo em contêineres usando o Docker. Isso envolve a criação de um Dockerfile, que é um script que contém instruções para criar uma imagem do Docker. Depois que a imagem é criada, podemos executá-la como um contêiner.
Um Dockerfile é um documento de texto que contém todos os comandos para montar uma imagem. Veja como criar um para nosso aplicativo de ML baseado no Flask.
app.py e requirements.txtcrie um novo arquivo chamado Dockerfile (sem extensão de arquivo).Dockerfile:# Use an official Python runtime as the base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt .
# Install the Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code into the container
COPY . .
# Expose port 5000 for the Flask app
EXPOSE 5000
# Define the command to run the Flask app
CMD ["python", "app.py"]Explicação:
FROM python:3.9-slim: Estamos usando a imagem oficial do Python 3.9 slim como imagem base. A versão slim é leve e ideal para aplicações em contêineres.WORKDIR /app: Isso define o diretório de trabalho dentro do contêiner como /app. Todos os comandos subsequentes serão executados a partir desse diretório.COPY requirements.txt .: Copia o arquivo requirements.txt do seu computador local para o contêiner.RUN pip install --no-cache-dir -r requirements.txt: Instala as dependências do Python listadas em requirements.txt. O sinalizador --no-cache-dir reduz o tamanho da imagem por não armazenar o cache.COPY . .: Copia todos os arquivos do diretório atual em seu computador local para o diretório /app no contêiner.EXPOSE 5000: Expõe a porta 5000, que é a porta em que nosso aplicativo Flask escuta.CMD ["python", "app.py"]: Define o comando para executar o aplicativo Flask quando o contêiner é iniciado.Com o Dockerfile pronto, agora podemos criar a imagem do Docker e executá-la como um contêiner.
Execute o seguinte comando no terminal para criar a imagem do Docker:
docker build -t ml-flask-app .Esse comando cria uma imagem do Docker a partir do Dockerfile no diretório atual. O sinalizador -t ml-flask-app marca a imagem com o nome ml-flask-app, facilitando a referência posterior.
Depois que a imagem for criada, execute-a como um contêiner usando o seguinte comando:
docker run -p 5000:5000 ml-flask-appEsse comando inicia um contêiner a partir da imagemml-flask-app. O sinalizador -p 5000:5000 mapeia a porta 5000 na sua máquina local para a porta 5000 no contêiner, permitindo que você acesse o aplicativo Flask a partir do seu navegador ou de uma ferramenta como curl.
Abra uma nova janela de terminal e envie uma solicitação de teste para o aplicativo Flask em execução dentro do contêiner:
curl -X POST -H "Content-Type: application/json" -d '{"input": [5.1, 3.5, 1.4, 0.2]}' http://localhost:5000/predictVocê deve ver uma resposta como esta:
{
"prediction": 0
}Isso significa que o aplicativo Flask em contêiner está sendo executado com êxito e está pronto para atender às previsões.
Se você tiver problemas ao criar ou executar o contêiner, aqui estão algumas dicas para ajudá-lo a solucionar o problema:
Verifique os registros do Docker:Use o seguinte comando para visualizar os logs de um contêiner em execução:
docker logs <container_id>Verifique a sintaxe do Dockerfile:Verifique novamente se há erros de digitação ou de sintaxe no Dockerfile.
Verifique os conflitos de portas:Certifique-se de que a porta 5000 não esteja em uso em seu computador local. Se for, você pode mapear o contêiner para uma porta diferente, assim:
docker run -p 5001:5000 ml-flask-appReconstruir a imagem:
Se você fizer alterações no Dockerfile ou no código do aplicativo, reconstrua a imagem usando:
docker build -t ml-flask-app .Agora que criamos e testamos com sucesso nosso contêiner do Docker, a próxima etapa é aprender a gerenciar e dimensionar o aplicativo em contêiner. Na próxima seção, exploraremos como usar o Kubernetes para implantar e dimensionar nosso aplicativo de ML.
Confira mais projetos do Docker em nosso guia 10 ideias de projetos do Docker: Do iniciante ao avançado.
Agora que criamos nosso contêiner do Docker, vamos ver como gerenciá-lo com eficiência. Esta seção guiará você pelos comandos essenciais do Docker para iniciar, parar e inspecionar contêineres, além de trabalhar com logs e portas.
O Docker oferece um conjunto de comandos avançados para gerenciar contêineres. Vamos examinar os mais comumente usados.
Para iniciar um contêiner a partir de uma imagem, use o comandodocker run. Por exemplo:
docker run -p 5000:5000 ml-flask-appEsse comando inicia um contêiner a partir da imagem ml-flask-app e mapeia a porta 5000 em sua máquina local para a porta 5000 no contêiner.
Se você quiser executar o contêiner em segundo plano (modo desanexado), adicione o sinalizador -d sinalizador:
docker run -d -p 5000:5000 ml-flask-appIsso permite que o contêiner seja executado em segundo plano, liberando o seu terminal.
Para interromper um contêiner em execução, primeiro encontre seu ID de contêiner usando:
docker psIsso lista todos os contêineres em execução, juntamente com seus IDs, nomes e outros detalhes. Quando você tiver o ID do contêiner, pare o contêiner com:
docker stop <container_id>Por exemplo:
docker stop a1b2c3d4e5f6Para exibir informações detalhadas sobre um contêiner, use o comando docker inspect comando:
docker inspect <container_id>Isso fornece uma saída JSON com detalhes como as configurações de rede do contêiner, volumes montados e variáveis de ambiente.
Para ver todos os contêineres (em execução e parados), use:
docker ps -aIsso é útil para verificar o status dos seus contêineres e encontrar IDs de contêineres.
Os logs e as portas são essenciais para a depuração e o acesso ao nosso aplicativo em contêiner. Vamos explorar como você pode trabalhar com eles.
Para visualizar os logs de um contêiner em execução, use:
docker logs <container_id>Por exemplo:
docker logs a1b2c3d4e5f6Exibe a saída do seu aplicativo, incluindo quaisquer erros ou mensagens impressas no console. Se você quiser acompanhar os logs em tempo real (como tail -f ), adicione o sinalizador-f:
docker logs -f <container_id>Ao executar um contêiner, você pode mapear as portas do contêiner para a sua máquina local usando o sinalizador-p. Por exemplo:
docker run -p 5000:5000 ml-flask-appIsso mapeia a porta 5000 no contêiner para a porta 5000 no seu computador local. Se a porta 5000 já estiver em uso, você poderá mapeá-la para uma porta diferente, da seguinte forma:
docker run -p 5001:5000 ml-flask-appAgora, seu aplicativo Flask estará acessível em http://localhost:5001.
Para ver quais portas estão mapeadas para um contêiner em execução, use:
docker port <container_id>Lista os mapeamentos de porta do contêiner, o que é útil para depurar problemas de conectividade. Na próxima seção, veremos como implantar nosso aplicativo de ML em contêiner no Kubernetes e gerenciá-lo em escala.
Quando nosso aplicativo estiver em contêineres, poderemos implantá-lo usando o Kubernetes. O Kubernetes automatiza a implantação, o dimensionamento e o gerenciamento de aplicativos em contêineres, facilitando o manuseio de cargas de trabalho em grande escala. Nesta seção, veremos como implantar nosso aplicativo de ML em um cluster do Kubernetes.
O Kubernetes usa arquivos YAML para definir o estado desejado do seu aplicativo. Esses arquivos descrevem como os contêineres devem ser implantados, dimensionados e gerenciados. Vamos começar criando uma implantação do Kubernetes para nosso aplicativo de ML baseado em Flask.
Crie um arquivo chamado ml-flask-app-deployment.yaml com o seguinte conteúdo:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: ml-flask-app
template:
metadata:
labels:
app: ml-flask-app
spec:
containers:
- name: ml-flask-app
image: ml-flask-app
ports:
- containerPort: 5000Esse arquivo YAML define:
ml-flask-app.ml-flask-app que criamos anteriormente.Para implantar o aplicativo no Kubernetes, use o comando kubectl apply comando:
kubectl apply -f ml-flask-app-deployment.yamlEsse comando diz ao Kubernetes para criar os recursos definidos no arquivo YAML. Você pode verificar o status da implantação usando:
kubectl get deploymentsIsso mostra o status da sua implementação, incluindo o número de réplicas em execução.
Para tornar o aplicativo acessível fora do cluster do Kubernetes, crie um serviço. Crie um arquivo chamado ml-flask-app-service.yaml com o seguinte conteúdo:
apiVersion: v1
kind: Service
metadata:
name: ml-flask-app-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 5000
selector:
app: ml-flask-appEsse arquivo YAML define:
ml-flask-app-service.Aplique o serviço usando:
kubectl apply -f ml-flask-app-service.yamlVocê pode verificar o status do serviço usando:
kubectl get servicesIsso mostra o endereço IP externo ao qual você pode acessar o aplicativo.
O Kubernetes facilita o dimensionamento de seu aplicativo e o monitoramento de seu desempenho. Vamos explorar como você pode fazer isso.
Para dimensionar seu aplicativo, atualize o número de réplicas na implantação. Por exemplo, para escalonar para 5 réplicas, execute:
kubectl scale deployment ml-flask-app --replicas=5Você também pode atualizar o campo replicas no arquivo YAML e aplicá-lo novamente:
spec:
replicas: 5Então corra:
kubectl apply -f ml-flask-app-deployment.yamlO Kubernetes fornece várias ferramentas para monitorar nosso aplicativo. Vamos dar uma olhada em algumas das ferramentas para monitorar nosso aplicativo.
Use kubectl logs para visualizar os logs de um pod específico:
kubectl logs <pod_name>
Use kubectl get pods para verificar o status de seus pods:
kubectl get podsUse o site kubectl top para visualizar o uso da CPU e da memória:
kubectl top podsO Kubernetes também oferece suporte ao Horizontal Pod Autoscaler (HPA), que dimensiona automaticamente o número de pods com base no uso da CPU ou da memória. Para ativar o dimensionamento automático, execute:
kubectl autoscale deployment ml-flask-app --cpu-percent=50 --min=3 --max=10Isso garante que a implantação seja dimensionada entre 3 e 10 réplicas com base no uso da CPU.
Aqui estão algumas práticas recomendadas que você deve seguir ao implantar aplicativos no Kubernetes.
Defina limites de CPU e memória para seus contêineres para evitar o esgotamento de recursos:
resources:
limits:
cpu: "1"
memory: "512Mi"Adicione verificações de integridade para garantir que seu aplicativo esteja sendo executado corretamente:
livenessProbe:
httpGet:
path: /health
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 5000
initialDelaySeconds: 5
periodSeconds: 10
Organize seus recursos usando namespaces para evitar conflitos:
kubectl create namespace ml-app
kubectl apply -f ml-flask-app-deployment.yaml -n ml-appNa próxima seção, abordaremos dicas para otimizar Dockerfiles, gerenciar dependências e garantir a segurança.
A colocação de aplicativos de aprendizado de máquina em contêineres traz seu próprio conjunto de desafios, como gerenciar grandes dependências, garantir a reprodutibilidade e manter a segurança. Aqui estão algumas práticas recomendadas para ajudar você a superar esses desafios e criar aplicativos robustos de ML em contêineres.
Um Dockerfile bem otimizado pode reduzir significativamente o tempo de compilação e o tamanho das imagens. Aqui estão algumas dicas para você otimizar seus Dockerfiles:
As compilações em vários estágios nos permitem usar várias instruções FROM em um único Dockerfile. Isso ajuda a reduzir o tamanho da imagem final, descartando arquivos desnecessários e dependências de estágios intermediários. Por exemplo:
# Stage 1: Build the application
FROM python:3.9-slim as builder
WORKDIR /app
COPY requirements.txt .
RUN pip install --user -r requirements.txt
COPY . .
# Stage 2: Create the final image
FROM python:3.9-slim
WORKDIR /app
COPY --from=builder /root/.local /root/.local
COPY --from=builder /app .
ENV PATH=/root/.local/bin:$PATH
EXPOSE 5000
CMD ["python", "app.py"]Este Dockerfile:
builder para instalar dependências e criar o aplicativo.Cada instrução em um Dockerfile cria uma nova camada. Para minimizar o número de camadas e reduzir o tamanho da imagem:
RUN Combine vários comandos em um único comando usando &&.COPY em vez de ADD a menos que você precise da funcionalidade adicional do ADD.Por exemplo:
RUN apt-get update && \
apt-get install -y --no-install-recommends build-essential && \
rm -rf /var/lib/apt/lists/*Escolha imagens de base leves como python:3.9-slim em vez de imagens maiores como python:3.9. As imagens finas contêm apenas os pacotes essenciais, reduzindo o tamanho total da imagem.
A reprodutibilidade é fundamental nos fluxos de trabalho de aprendizado de máquina. Veja como gerenciar dependências e garantir a reprodutibilidade em seus aplicativos em contêineres.
Liste todas as dependências do Python em um arquivo requirements.txt ou use pipenv para gerenciá-las. Por exemplo:
# requirements.txt
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Instale as dependências em seu Dockerfile:
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txtSempre fixe as versões de suas dependências para evitar alterações inesperadas. Por exemplo:
scikit-learn==1.3.0
numpy==1.24.3
Flask==2.3.2Use variáveis de ambiente para configurar o aplicativo em vez de codificar valores. Isso torna o seu contêiner mais flexível e mais fácil de configurar em diferentes ambientes. Por exemplo:
ENV MODEL_PATH=/app/models/model.pklEm seguida, acesse a variável de ambiente em seu aplicativo:
import os
model_path = os.getenv('MODEL_PATH')A segurança é um aspecto essencial dos aplicativos em contêineres. Aqui estão algumas práticas recomendadas para proteger seus aplicativos de ML:
Executar contêineres como o usuárioroot pode expor seu sistema a riscos de segurança. Em vez disso, crie um usuário não raiz e execute o contêiner como esse usuário. Por exemplo:
# Create a non-root user
RUN useradd -m myuser
# Switch to the non-root user
USER myuser
# Set the working directory
WORKDIR /home/myuser/app
# Copy the application code
COPY --chown=myuser:myuser . .
# Run the application
CMD ["python", "app.py"]Use ferramentas como Trivy ou Clair para verificar se há vulnerabilidades em suas imagens do Docker. Por exemplo, para digitalizar uma imagem com o Trivy:
trivy image ml-flask-appNunca codifique informações confidenciais como chaves de API ou credenciais de banco de dados em seu Dockerfile ou código de aplicativo. Em vez disso, use Kubernetes Secrets ou Docker Secrets para gerenciar dados confidenciais. Por exemplo, no Kubernetes:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
api_key: <base64-encoded-api-key>Em seguida, monte o segredo como uma variável de ambiente em sua implantação:
env:
- name: API_KEY
valueFrom:
secretKeyRef:
name: my-secret
key: api_keyO teste e a depuração são essenciais para garantir que o aplicativo em contêiner funcione conforme o esperado. Aqui estão algumas dicas:
Antes de fazer a implantação no Kubernetes, teste seu contêiner localmente usando o Docker. Por exemplo:
docker run -p 5000:5000 ml-flask-appUse docker logs ou kubectl logs para depurar problemas em seu aplicativo em contêiner. Por exemplo:
docker logs <container_id>
kubectl logs <pod_name>Use pipelines de CI/CD para automatizar o teste e a implantação de seus aplicativos em contêineres. Ferramentas como GitHub Actions, GitLab CI ou Jenkins podem nos ajudar a configurar fluxos de trabalho automatizados.
Ao seguir essas práticas recomendadas, podemos criar aplicativos de aprendizado de máquina em contêineres eficientes, reproduzíveis e seguros. Desde a otimização de Dockerfiles até o gerenciamento de dependências e a garantia de segurança, essas estratégias nos ajudarão a otimizar nossos fluxos de trabalho de ML e a implementar modelos com confiança.
A colocação em contêiner de aplicativos de aprendizado de máquina com o Docker e o Kubernetes agiliza a implantação, garante a reprodutibilidade e aumenta a escalabilidade. Ao seguir as práticas recomendadas, como otimizar Dockerfiles, gerenciar dependências e priorizar a segurança, podemos criar fluxos de trabalho de ML robustos, eficientes e seguros.
Para continuar aprendendo sobre conteinerização e aprimorar seus fluxos de trabalho de aprendizado de máquina, confira estes cursos:
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Kurtis Pykes
8 min
Tutorial
Bex Tuychiev
Tutorial
Kevin Babitz
Tutorial
Bex Tuychiev
Tutorial
Moez Ali



