
Qu'est-ce que l'apprentissage profond ?
L'apprentissage en profondeur est un type d'apprentissage automatique qui apprend aux ordinateurs à effectuer des tâches en apprenant à partir d'exemples, comme le font les humains. Imaginez que vous appreniez à un ordinateur à reconnaître les chats : au lieu de lui dire de chercher des moustaches, des oreilles et une queue, vous lui montrez des milliers de photos de chats. L'ordinateur trouve tout seul les motifs communs et apprend à identifier un chat. C'est l'essence même de l'apprentissage en profondeur.
En termes techniques, l'apprentissage profond utilise ce que l'on appelle des "réseaux neuronaux", qui s'inspirent du cerveau humain. Ces réseaux sont constitués de couches de nœuds interconnectés qui traitent l'information. Plus il y a de couches, plus le réseau est "profond", ce qui lui permet d'apprendre des caractéristiques plus complexes et d'effectuer des tâches plus sophistiquées.
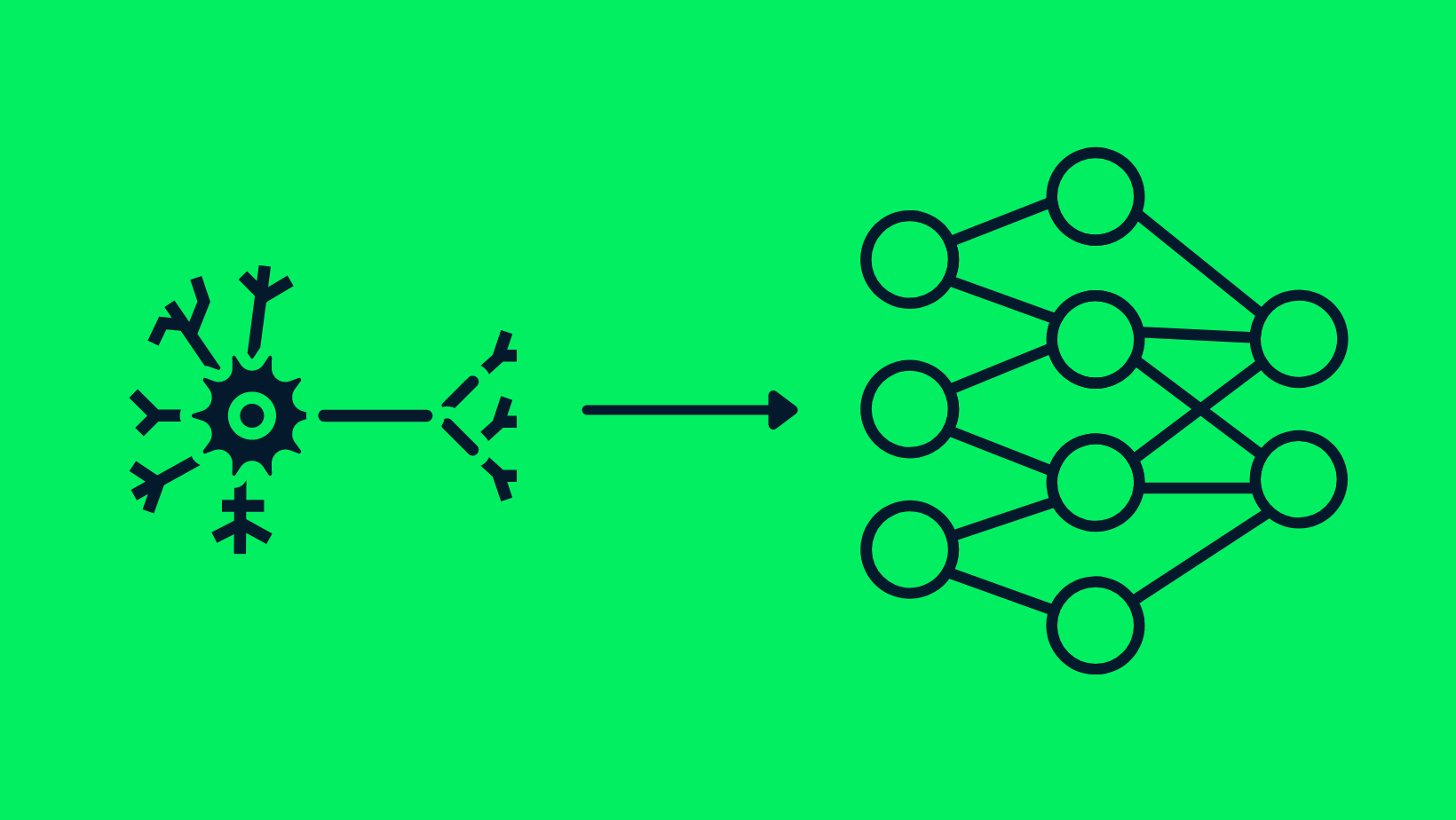
La similitude entre les neurones et les réseaux neuronaux
L'évolution de l'apprentissage automatique vers l'apprentissage profond
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique est lui-même un sous-ensemble de l'intelligence artificielle (IA) qui permet aux ordinateurs d'apprendre à partir de données et de prendre des décisions sans programmation explicite. Elle englobe diverses techniques et algorithmes qui permettent aux systèmes de reconnaître des modèles, de faire des prédictions et d'améliorer les performances au fil du temps. Vous pouvez étudier la différence entre l'apprentissage automatique et l'IA dans un autre article.
En quoi l'apprentissage profond diffère de l'apprentissage automatique traditionnel
Si l'apprentissage automatique est une technologie transformatrice en soi, l'apprentissage profond va encore plus loin en automatisant de nombreuses tâches qui requièrent généralement l'expertise humaine.
L'apprentissage profond est essentiellement un sous-ensemble spécialisé de l'apprentissage automatique, qui se distingue par l'utilisation de réseaux neuronaux à trois couches ou plus. Ces réseaux neuronaux tentent de simuler le comportement du cerveau humain - bien qu'ils soient loin d'égaler ses capacités - afin d'"apprendre" à partir de grandes quantités de données. Vous pouvez explorer plus en détail l'apprentissage automatique et l'apprentissage profond dans un autre article.
L'importance de l'ingénierie des fonctionnalités
L'ingénierie des caractéristiques est le processus de sélection, de transformation ou de création des variables les plus pertinentes, appelées "caractéristiques", à partir de données brutes pour les utiliser dans des modèles d'apprentissage automatique.
Par exemple, si vous construisez un modèle de prévision météorologique, les données brutes peuvent inclure la température, l'humidité, la vitesse du vent et la pression barométrique. L'ingénierie des caractéristiques consisterait à déterminer lesquelles de ces variables sont les plus importantes pour la prévision du temps et éventuellement à les transformer (par exemple, en convertissant la température de Fahrenheit en Celsius) afin de les rendre plus utiles pour le modèle.
Dans l'apprentissage automatique traditionnel, l'ingénierie des caractéristiques est souvent un processus manuel et fastidieux qui nécessite une expertise dans le domaine. Cependant, l'un des avantages de l'apprentissage profond est qu'il permet d'apprendre automatiquement les caractéristiques pertinentes à partir des données brutes, ce qui réduit la nécessité d'une intervention manuelle.
Pourquoi l'apprentissage profond est-il important ?
Les raisons pour lesquelles l'apprentissage profond est devenu la norme du secteur :
- Traitement des données non structurées : Les modèles formés sur des données structurées peuvent facilement apprendre à partir de données non structurées, ce qui réduit le temps et les ressources nécessaires à la normalisation des ensembles de données.
- Traitement de données volumineuses : Grâce à l'introduction des unités de traitement graphique (GPU), les modèles d'apprentissage profond peuvent traiter de grandes quantités de données à une vitesse fulgurante.
- Haute précision : Les modèles d'apprentissage profond fournissent les résultats les plus précis dans les domaines de la vision par ordinateur, du traitement du langage naturel (NLP) et du traitement audio.
- Reconnaissance des formes : La plupart des modèles nécessitent l'intervention d'un ingénieur en apprentissage automatique, mais les modèles d'apprentissage profond peuvent détecter toutes sortes de modèles automatiquement.
Dans ce tutoriel, nous allons plonger dans le monde de l'apprentissage profond et découvrir tous les concepts clés nécessaires pour commencer une carrière dans l'intelligence artificielle (IA). Si vous cherchez à apprendre avec des exercices pratiques, consultez notre cours, Une introduction au Deep Learning en Python.
Concepts fondamentaux de l'apprentissage profond
Avant de plonger dans les subtilités des algorithmes d'apprentissage profond et de leurs applications, il est essentiel de comprendre les concepts fondamentaux qui rendent cette technologie si révolutionnaire. Cette section vous présente les éléments constitutifs de l'apprentissage profond : les réseaux neuronaux, les réseaux neuronaux profonds et les fonctions d'activation.
Réseaux neuronaux
Au cœur de l'apprentissage profond se trouvent les réseaux neuronaux, qui sont des modèles informatiques inspirés du cerveau humain. Ces réseaux sont constitués de nœuds interconnectés, ou "neurones", qui travaillent ensemble pour traiter les informations et prendre des décisions. Tout comme notre cerveau possède différentes régions pour différentes tâches, un réseau neuronal possède des couches désignées pour des fonctions spécifiques.
Nous avons un guide complet, Qu'est-ce que les réseaux neuronaux, qui couvre les points essentiels de manière plus détaillée.
Réseaux neuronaux profonds
Ce qui rend un réseau neuronal "profond", c'est le nombre de couches qu'il comporte entre l'entrée et la sortie. Un réseau neuronal profond comporte plusieurs couches, ce qui lui permet d'apprendre des caractéristiques plus complexes et de faire des prédictions plus précises. La "profondeur" de ces réseaux est à l'origine du nom de l'apprentissage profond et de sa capacité à résoudre des problèmes complexes.
Notre tutoriel d'introduction aux réseaux neuronaux profonds couvre l'importance des réseaux neuronaux profonds dans l'apprentissage profond et l'intelligence artificielle.
Fonctions d'activation
Dans un réseau neuronal, les fonctions d'activation sont comme les décideurs. Ils déterminent quelles informations doivent être transmises à la couche suivante. Ces fonctions ajoutent un niveau de complexité, permettant au réseau d'apprendre à partir des données et de prendre des décisions nuancées.
Comment fonctionne l'apprentissage profond ?
L'apprentissage profond utilise l'extraction de caractéristiques pour reconnaître les caractéristiques similaires d'une même étiquette, puis utilise les limites de décision pour déterminer quelles caractéristiques représentent précisément chaque étiquette. Dans la classification des chats et des chiens, les modèles d'apprentissage profond extraient des informations telles que les yeux, le visage et la forme du corps des animaux et les divisent en deux classes.
Le modèle d'apprentissage profond se compose de réseaux neuronaux profonds. Le réseau neuronal simple se compose d'une couche d'entrée, d'une couche cachée et d'une couche de sortie. Les modèles d'apprentissage profond se composent de plusieurs couches cachées, avec des couches supplémentaires que la précision du modèle a améliorées.
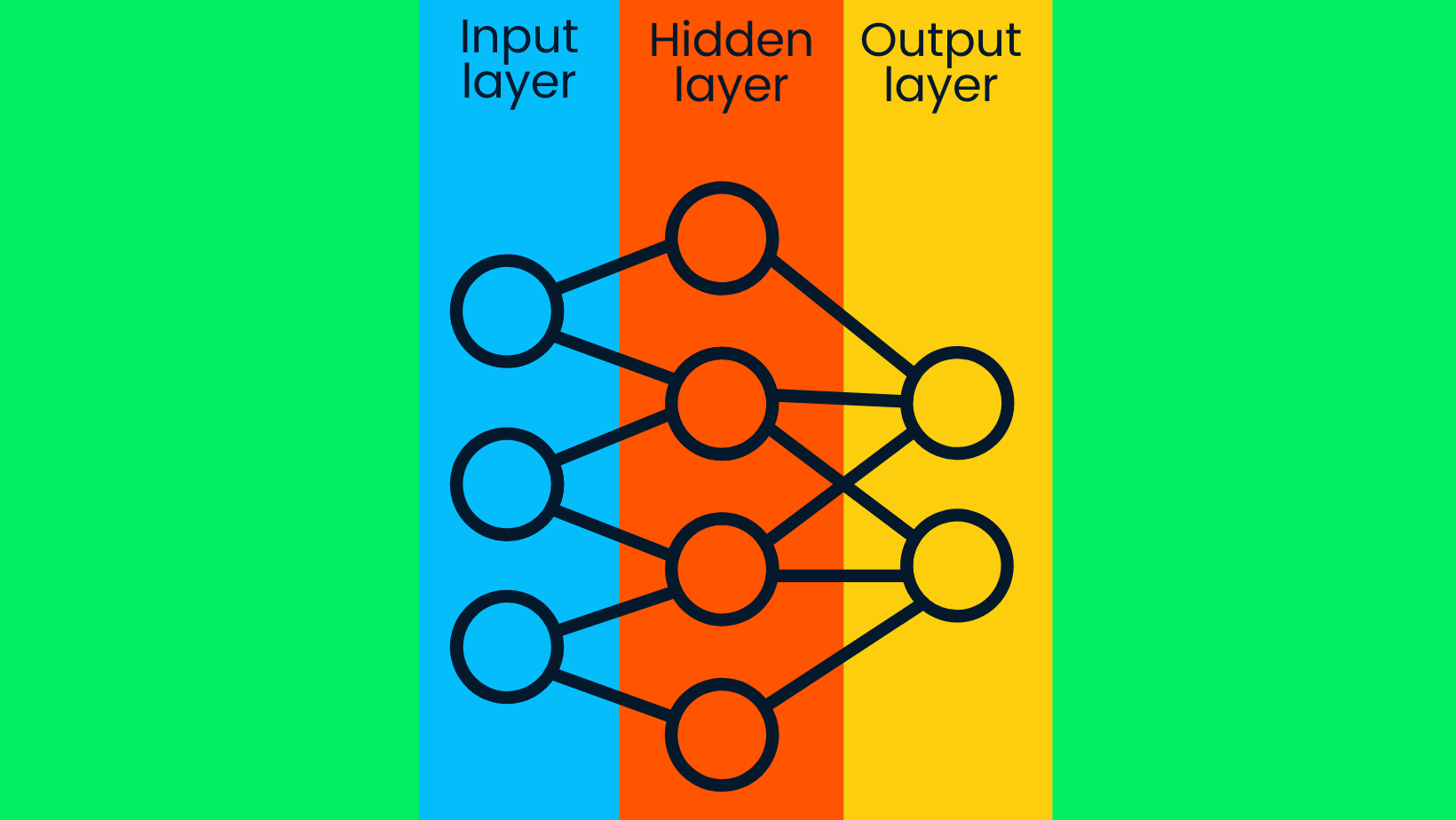 Réseau neuronal simple
Réseau neuronal simple
Les couches d'entrée contiennent des données brutes et les transfèrent aux nœuds des couches cachées. Les nœuds des couches cachées classent les points de données sur la base d'informations cibles plus larges et, avec chaque couche suivante, la portée de la valeur cible se réduit pour produire des hypothèses précises. La couche de sortie utilise les informations de la couche cachée pour sélectionner l'étiquette la plus probable. Dans notre cas, il s'agit de prédire avec précision l'image d'un chien plutôt que celle d'un chat.
Intelligence artificielle vs. Apprentissage profond
Répondons à l'une des questions les plus fréquemment posées sur l'internet : "L'apprentissage profond est-il une intelligence artificielle ? La réponse courte est oui. L'apprentissage profond est un sous-ensemble de l'apprentissage automatique, et l'apprentissage automatique est un sous-ensemble de l'IA.
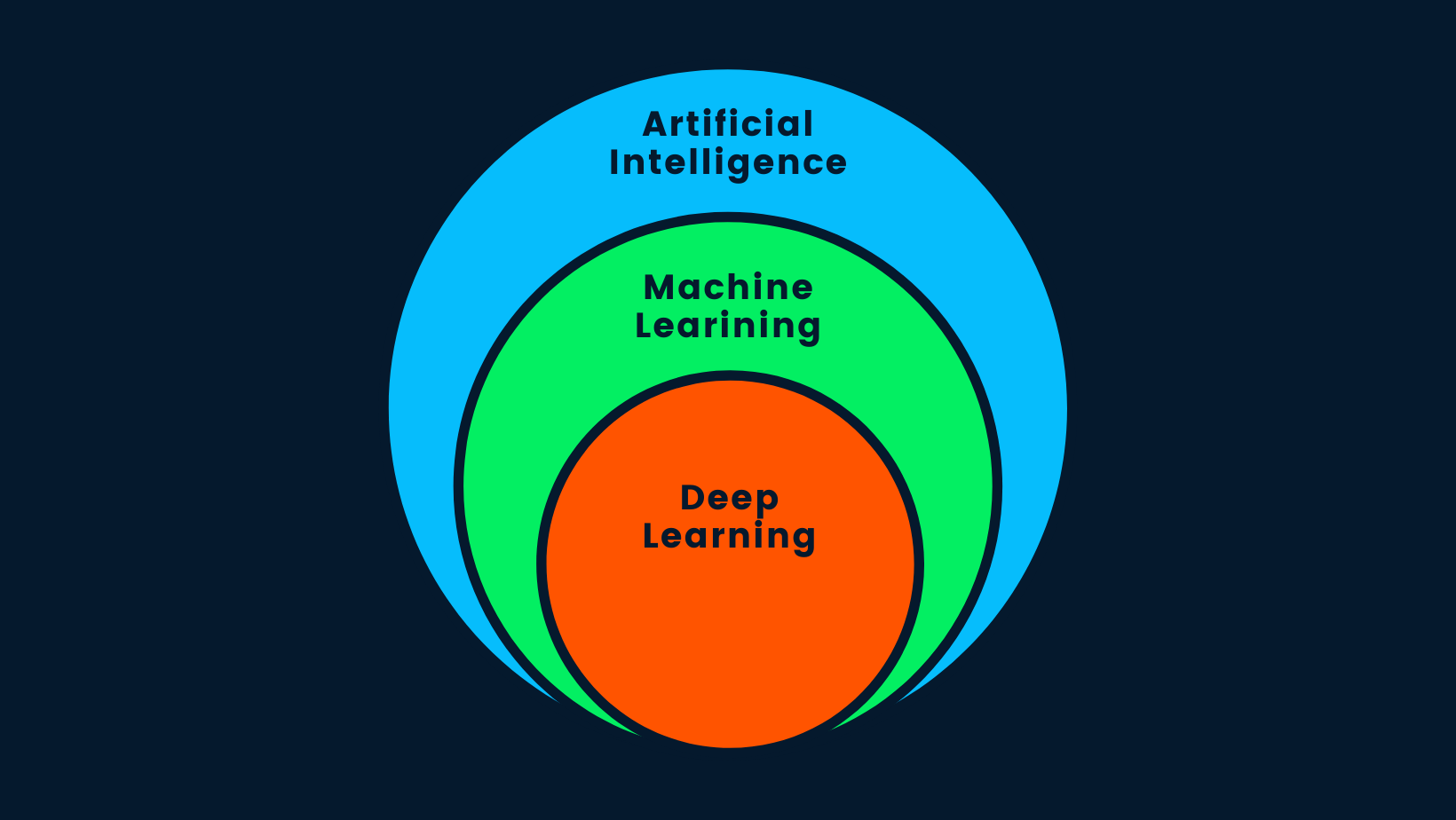 AI vs. ML vs. DL
AI vs. ML vs. DL
L'intelligence artificielle est le concept selon lequel des machines intelligentes peuvent être construites pour imiter le comportement humain ou dépasser l'intelligence humaine. L'IA utilise des méthodes d'apprentissage automatique et d'apprentissage profond pour accomplir des tâches humaines. En bref, l'IA est l'apprentissage profond, car il s'agit de l'algorithme le plus avancé capable de prendre des décisions intelligentes.
À quoi sert l'apprentissage profond ?
Récemment, le monde de la technologie a connu une montée en puissance des applications d'intelligence artificielle, et elles sont toutes alimentées par des modèles d'apprentissage profond. Les applications vont de la recommandation de films sur Netflix aux systèmes de gestion des entrepôts d'Amazon.
Dans cette section, nous allons découvrir quelques-unes des applications les plus célèbres construites à l'aide de l'apprentissage profond. Cela vous permettra d'exploiter pleinement le potentiel des réseaux neuronaux profonds.
Vision par ordinateur
La vision par ordinateur est utilisée dans les voitures autonomes pour détecter les objets et éviter les collisions. Il est également utilisé pour la reconnaissance des visages, l'estimation de la pose, la classification des images et la détection des anomalies.
 Reconnaissance des visages
Reconnaissance des visages
Reconnaissance automatique de la parole
La reconnaissance automatique de la parole (ASR) est utilisée par des milliards de personnes dans le monde. Il se trouve dans nos téléphones et est généralement activé en disant "Hey, Google" ou "Hi, Siri". Ces applications audio sont également utilisées pour la synthèse vocale, la classification audio et la détection de l'activité vocale.
 Reconnaissance des formes de la parole
Reconnaissance des formes de la parole
IA générative
L'IA générative a connu une forte augmentation de la demande, comme en témoigne la vente de CryptoPunk NFT pour 1 million de dollars. CryptoPunk est une collection d'art génératif créée à l'aide de modèles d'apprentissage profond. L'introduction du modèle GPT-4 par OpenAI a révolutionné le domaine de la génération de texte avec son puissant outil ChatGPT ; désormais, vous pouvez apprendre aux modèles à écrire un roman entier ou même à écrire du code pour vos projets de science des données.
 Art génératif
Art génératif
Translation
La traduction par apprentissage profond ne se limite pas à la traduction linguistique, puisque nous sommes désormais en mesure de traduire des photos en texte en utilisant l'OCR, ou de traduire du texte en images en utilisant NVIDIA GauGAN2.
 Traduction linguistique
Traduction linguistique
Prévision des séries temporelles
Les prévisions de séries temporelles sont utilisées pour prévoir les krachs boursiers, les prix des actions et les changements météorologiques. Le secteur financier survit grâce à la spéculation et aux projections futures. L'apprentissage profond et les modèles de séries temporelles sont plus efficaces que les humains pour détecter des modèles et sont donc des outils essentiels dans ce secteur et d'autres secteurs similaires.
 Prévision des séries temporelles
Prévision des séries temporelles
Automatisation
L'apprentissage profond est utilisé pour automatiser des tâches, par exemple pour former des robots à la gestion d'entrepôts. L'application la plus populaire consiste à jouer à des jeux vidéo et à s'améliorer dans la résolution d'énigmes. Récemment, Dota AI d'OpenAI a battu l'équipe professionnelle OG, ce qui a choqué le monde entier, car les gens ne s'attendaient pas à ce que les cinq robots soient plus malins que les champions du monde.
 Un bras robotisé grâce à l'apprentissage par renforcement
Un bras robotisé grâce à l'apprentissage par renforcement
Commentaires des clients
L'apprentissage en profondeur est utilisé pour traiter les commentaires et les réclamations des clients. Il est utilisé dans toutes les applications de chatbot pour fournir des services à la clientèle sans faille.
 Commentaires des clients
Commentaires des clients
Biomédical
C'est ce domaine qui a le plus bénéficié de l'introduction de l'apprentissage profond. Le DL est utilisé en biomédecine pour détecter les cancers, construire des médicaments stables, détecter les anomalies dans les radiographies du thorax et assister les équipements médicaux.
 Analyse des séquences d'ADN
Analyse des séquences d'ADN
Modèles d'apprentissage profond
Découvrons les différents types de modèles d'apprentissage profond et leur fonctionnement.
Apprentissage supervisé
L'apprentissage supervisé utilise un ensemble de données étiquetées pour former des modèles permettant de classer des données ou de prédire des valeurs. L'ensemble de données contient des caractéristiques et des étiquettes cibles, qui permettent à l'algorithme d'apprendre au fil du temps en minimisant la perte entre les étiquettes prédites et les étiquettes réelles. L'apprentissage supervisé peut être divisé en problèmes de classification et de régression.
Classification
L'algorithme de classification divise l'ensemble de données en plusieurs catégories sur la base d'extractions de caractéristiques. Les modèles d'apprentissage profond les plus populaires sont ResNet50 pour la classification des images et BERT (modèle de langage)) pour la classification des textes.
 Classification
Classification
Régression
Au lieu de diviser l'ensemble des données en catégories, le modèle de régression apprend la relation entre les variables d'entrée et de sortie pour prédire le résultat. Les modèles de régression sont couramment utilisés pour l'analyse prédictive, les prévisions météorologiques et la prévision des performances boursières. LSTM et RNN sont des modèles de régression d'apprentissage profond très répandus.
 Régression linéaire
Régression linéaire
Apprentissage non supervisé
Les algorithmes d'apprentissage non supervisé apprennent le modèle au sein d'un ensemble de données non étiquetées et créent des grappes. Les modèles d'apprentissage profond peuvent apprendre des modèles cachés sans intervention humaine et ces modèles sont souvent utilisés dans les moteurs de recommandation.
L'apprentissage non supervisé est utilisé pour le regroupement de diverses espèces, l'imagerie médicale et les études de marché. Le modèle d'apprentissage profond le plus courant pour le regroupement est l'algorithme de regroupement intégré profond.
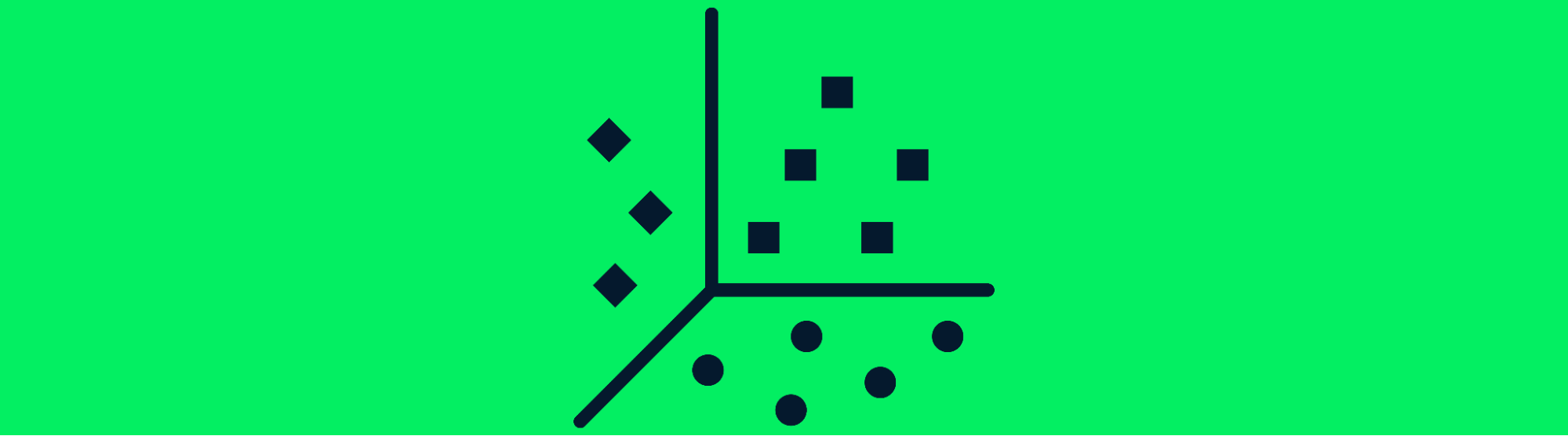 Regroupement de données
Regroupement de données
Apprentissage par renforcement
L'apprentissage par renforcement (RL) est une méthode d'apprentissage automatique dans laquelle les agents apprennent divers comportements à partir de l'environnement. Cet agent effectue des actions aléatoires et reçoit des récompenses. L'agent apprend à atteindre ses objectifs par essais et erreurs dans un environnement complexe sans intervention humaine.
Tout comme un bébé qui apprend à marcher grâce aux encouragements de ses parents, l'IA apprend à effectuer certaines tâches en maximisant les récompenses, et c'est le concepteur qui définit la politique de récompenses. Récemment, RL a connu une forte demande d'automatisation en raison des progrès réalisés dans le domaine de la robotique, des voitures autonomes, de la victoire sur des joueurs professionnels et de l'atterrissage de fusées sur la terre.
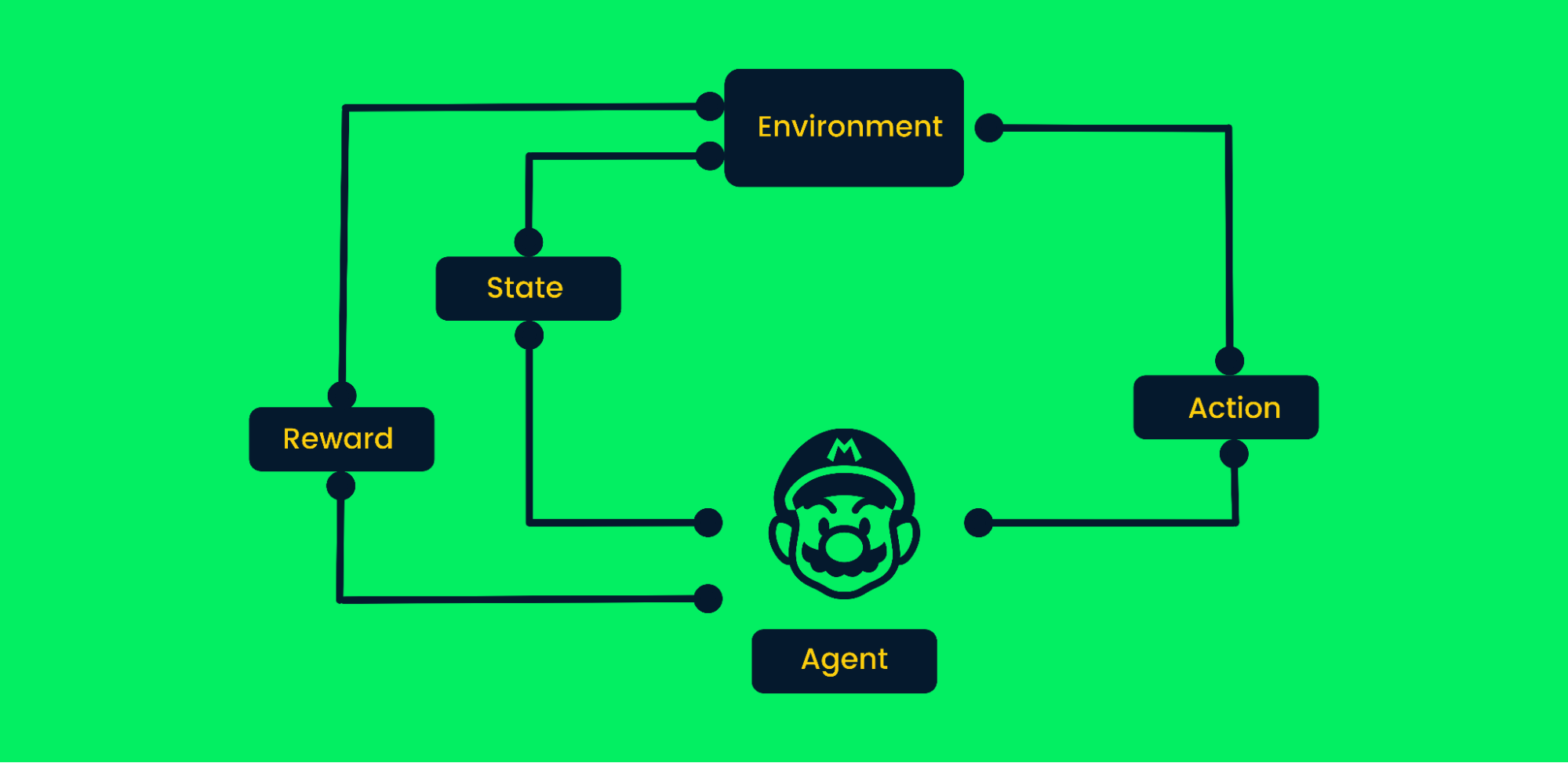 Cadre d'apprentissage par renforcement
Cadre d'apprentissage par renforcement
Prenons l'exemple du jeu vidéo Mario :
- Au départ, l'agent (personnage de Mario) reçoit l'état zéro de l'environnement.
- En fonction de l'état, un agent prendra une mesure, dans notre cas, Mario s'est déplacé vers la droite.
- Aujourd'hui, l'état a changé et le personnage se trouve dans un nouveau cadre.
- L'agent reçoit une récompense, car en se déplaçant vers la droite, le personnage n'est pas mort. Notre objectif principal est de maximiser les récompenses.
L'agent continuera à agir et à maximiser les récompenses jusqu'à ce qu'il atteigne la fin de l'étape ou qu'il meure. Pour en savoir plus, consultez la page Introduction à l'apprentissage par renforcement.
Réseaux adverbiaux génératifs
Les réseaux adversaires génératifs (GAN) utilisent deux réseaux neuronaux qui, ensemble, produisent des instances synthétiques de données originales. Les GAN ont gagné en popularité ces dernières années car ils sont capables d'imiter certains grands artistes pour produire des chefs-d'œuvre. Ils sont largement utilisés pour générer des œuvres d'art, des vidéos, de la musique et des textes synthétiques. Pour en savoir plus sur les applications réelles, consultez le didacticiel sur les réseaux adversoriels génératifs.
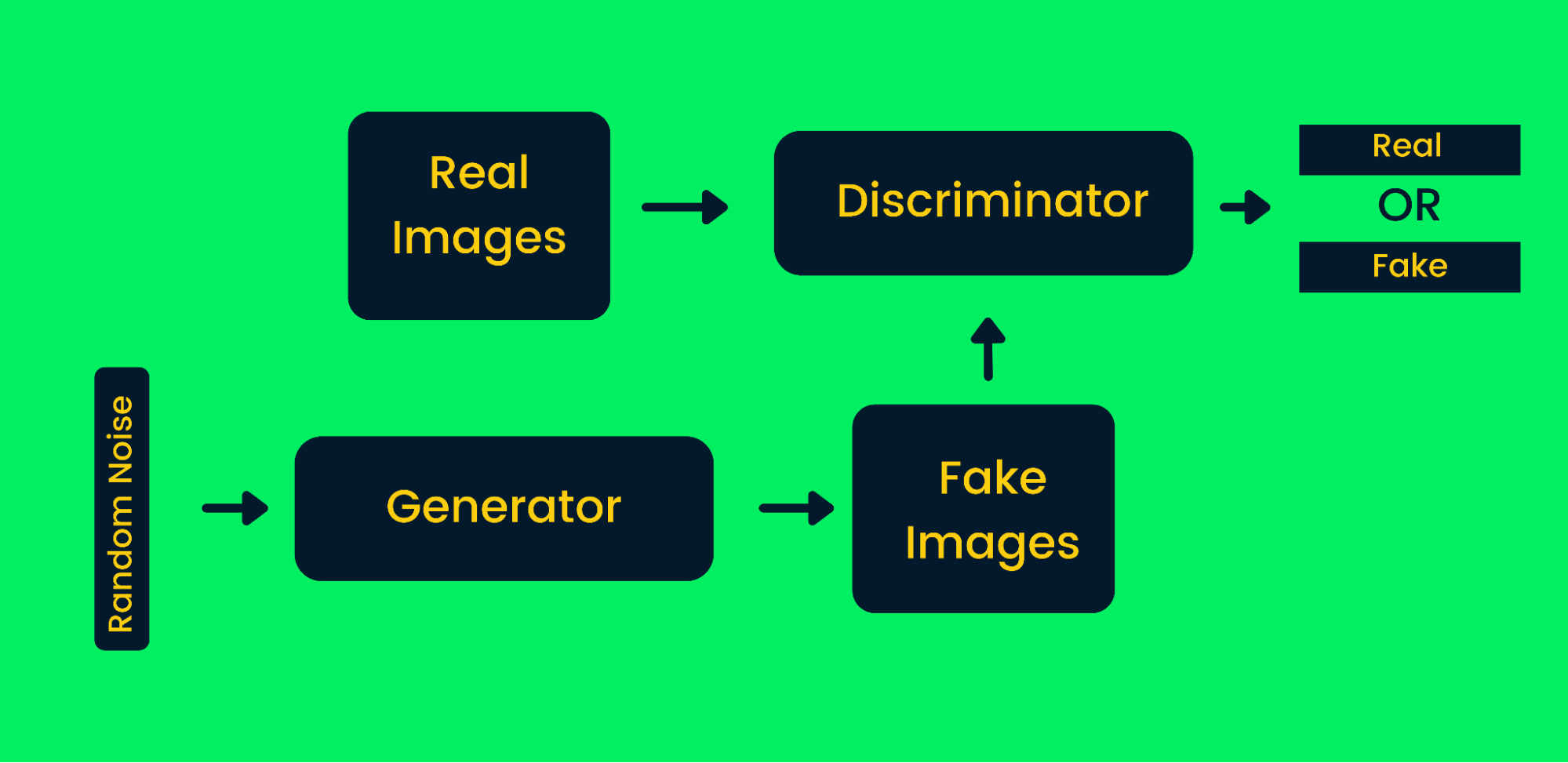 Cadre pour les réseaux adverbiaux génératifs
Cadre pour les réseaux adverbiaux génératifs
Comment les GAN fonctionnent dans la génération d'images synthétiques :
- Tout d'abord, les réseaux générateurs prennent en entrée un bruit aléatoire et génèrent de fausses images.
- Les images générées et les images réelles sont introduites dans le discriminateur.
- Le discriminateur décide si l'image générée est réelle ou non. Il renvoie des probabilités de zéro à un, où zéro représente une image fausse et un une image authentique. L'architecture des GAN comporte deux boucles de rétroaction. Le discriminateur est dans une boucle de rétroaction avec des images réelles, tandis que le générateur est dans une boucle de rétroaction avec un discriminateur. Ils travaillent en synchronisation pour produire des images plus authentiques.
Réseau neuronal graphique
Un graphe est une structure de données composée d'arêtes et de sommets. Les arêtes peuvent être dirigées s'il existe des dépendances directionnelles entre les sommets(nœuds), également connues sous le nom de graphes dirigés. Les cercles verts dans le diagramme ci-dessous sont des nœuds, et les flèches représentent les arêtes.
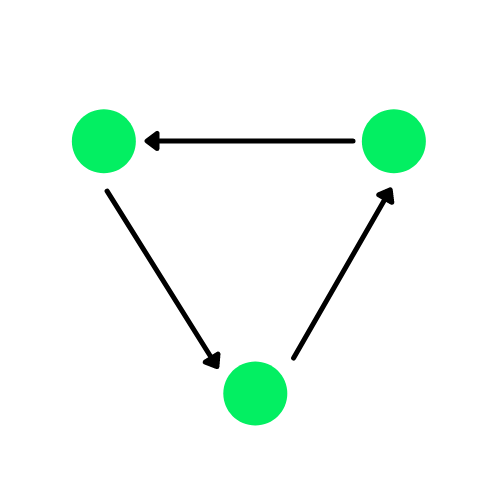
Un graphe orienté
Un réseau neuronal graphique (GNN) est un type d'architecture d'apprentissage profond qui opère directement sur les structures graphiques. Les GNN sont appliqués à l'analyse de grands ensembles de données, aux systèmes de recommandation et aux visions d'ordinateur.
 Un réseau graphique
Un réseau graphique
Ils sont également utilisés pour la classification des nœuds, la prédiction des liens et le regroupement. Dans certains cas, les réseaux neuronaux graphiques ont obtenu de meilleurs résultats que les réseaux neuronaux à convolution, par exemple pour la reconnaissance d'objets et la prédiction de relations sémantiques.
Traitement du langage naturel
Le traitement du langage naturel (NLP) utilise la technologie de l'apprentissage profond pour aider les ordinateurs à apprendre un langage humain naturel. Le NLP utilise l'apprentissage profond pour lire, déchiffrer et comprendre le langage humain. Il est largement utilisé pour le traitement de la parole, du texte et des images. L'introduction de l'apprentissage par transfert a fait passer la PNL à la vitesse supérieure, car nous sommes en mesure d'affiner le modèle avec quelques échantillons et d'obtenir des performances de pointe.
 Sous-catégories de la PNL
Sous-catégories de la PNL
La PNL peut être divisée en plusieurs domaines :
- Traduction: traduction de langues, de structures moléculaires et d'équations mathématiques
- Résumer: résumer de grandes parties de texte en quelques lignes tout en conservant les informations essentielles.
- Classification: diviser le texte en différentes catégories.
- Génération: génération de texte à texte ; elle peut être utilisée pour générer des essais entiers à partir d'une seule ligne de texte.
- Conversationnel: Assistant virtuel, conservant les connaissances antérieures de la conversation et imitant les conversations humaines.
- Répondre aux questions: L'IA répond aux questions en utilisant les données des questions-réponses.
- Extraction de caractéristiques: pour détecter des modèles dans le texte ou extraire des informations telles que la "reconnaissance de noms et d'entités" et la "partie du discours".
- Similitudes des phrases: évaluer les similitudes entre différents textes.
- Synthèse vocale: conversion d'un texte en parole audible.
- Reconnaissance automatique de la parole: comprendre différents sons et les convertir en texte.
- Reconnaissance optique de caractères: extraction de données textuelles à partir d'images.
Si vous voulez tester toutes les différentes applications de la PNL, essayez Hugging Face Spaces. Les Espaces hébergent toutes sortes d'applications web avec lesquelles vous pouvez jouer pour trouver l'inspiration pour votre projet de PNL.
Un regard plus approfondi sur les concepts de l'apprentissage profond (Deep Learning)
Fonctions d'activation
Dans les réseaux neuronaux, la fonction d'activation produit des limites de décision en sortie et est utilisée pour améliorer les performances du modèle. La fonction d'activation est une expression mathématique qui décide si l'entrée doit passer par un neurone ou non en fonction de son importance. Il confère également une non-linéarité aux réseaux. Sans fonction d'activation, le réseau neuronal devient un simple modèle de régression linéaire.
Il existe plusieurs types de fonctions d'activation :
- Tanh
- ReLU
- Sigmoid
- Linéaire
- Softmax
- Swish
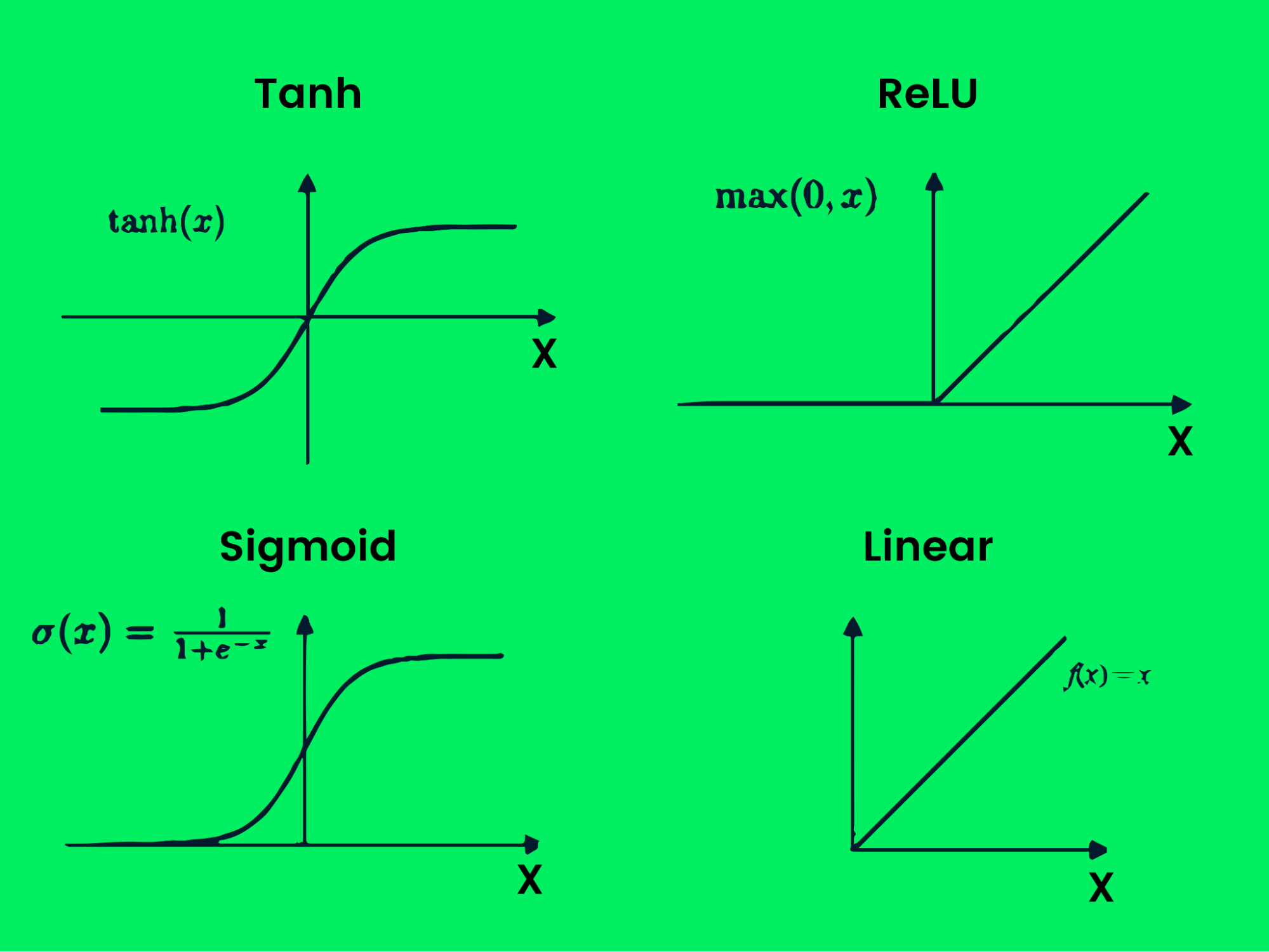 Fonction d'activation
Fonction d'activation
Ces fonctions produisent différentes limites de sortie, comme le montre l'image ci-dessus. Avec plusieurs couches et fonctions d'activation, vous pouvez résoudre n'importe quel problème complexe. En savoir plus sur les fonctions d'activation dans l'apprentissage profond (deep learning).
Fonction de perte
La fonction de perte est la différence entre les valeurs réelles et les valeurs prédites. Il permet aux réseaux neuronaux de suivre les performances globales du modèle. En fonction des problèmes spécifiques, nous avons choisi un certain type de fonction, par exemple l'erreur quadratique moyenne.
Perte = Somme (Prévue - Réalisée)²
Les fonctions de perte les plus utilisées dans l'apprentissage profond sont les suivantes :
- Entropie croisée binaire
- Charnière catégorielle
- Erreur quadratique moyenne
- Huber
- Entropie croisée catégorielle éparse
Backpropagation
Dans la propagation par transfert, nous initialisons notre réseau neuronal avec des entrées aléatoires afin de produire une sortie également aléatoire. Pour améliorer les performances de notre modèle, nous ajustons les poids de manière aléatoire à l'aide de la rétropropagation. Pour curer les performances du modèle, nous avons besoin d'une fonction de perte qui trouvera des minima globaux afin de maximiser la précision du modèle.
Descente stochastique de gradient
La descente de gradient est utilisée pour optimiser la fonction de perte en modifiant les poids de manière contrôlée afin d'obtenir une perte minimale. Nous avons maintenant un objectif, mais nous avons besoin d'indications pour savoir s'il faut augmenter ou diminuer les poids afin d'obtenir de meilleures performances. La dérivée de la fonction de perte nous donne une direction et nous pouvons l'utiliser pour mettre à jour les poids du réseau.
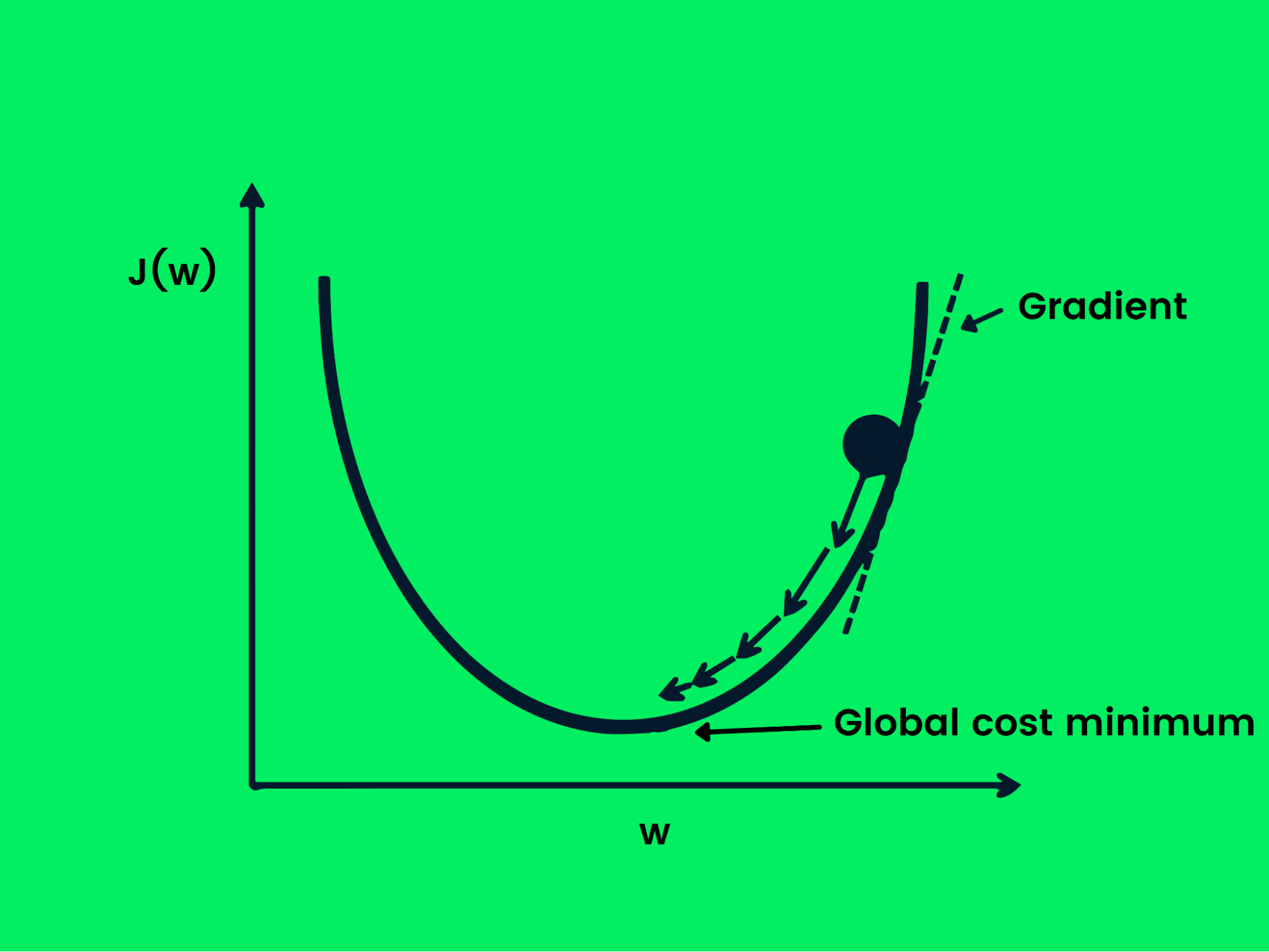 Descente en gradient
Descente en gradient
L'équation ci-dessous montre comment les poids sont mis à jour à l'aide de la descente de gradient.
w = w -Jw
Dans la descente de gradient stochastique, les échantillons sont divisés en lots au lieu d'utiliser l'ensemble des données pour optimiser la descente de gradient. C'est utile si vous voulez atteindre une perte minimale plus rapidement et optimiser la puissance de calcul.
Hyperparamètre
Les hyperparamètres sont les paramètres réglables avant l'exécution du processus de formation. Ces paramètres affectent directement les performances du modèle et vous aident à atteindre plus rapidement les minima globaux.
Liste des hyperparamètres les plus utilisés :
- Taux d'apprentissage : taille du pas de chaque itération, réglable de 0,1 à 0,0001. En bref, il détermine la vitesse à laquelle le modèle apprend.
- Taille du lot : nombre d'échantillons passant par un réseau neuronal à la fois.
- Nombre d'époques : itération du nombre de fois que le modèle change de poids. Un trop grand nombre d'époques peut entraîner une suradaptation des modèles et un trop petit nombre peut entraîner une sous-adaptation des modèles, c'est pourquoi nous devons choisir un nombre moyen.
Pour en savoir plus sur le fonctionnement de ces composants, consultez le didacticiel Keras à l'adresse : L'apprentissage profond en Python.
Algorithmes populaires
Réseaux neuronaux convolutifs
Le réseau neuronal convolutif (CNN) est un réseau neuronal feed-forward capable de traiter un ensemble structuré de données. Il est largement utilisé pour les applications de vision par ordinateur telles que la classification d'images.
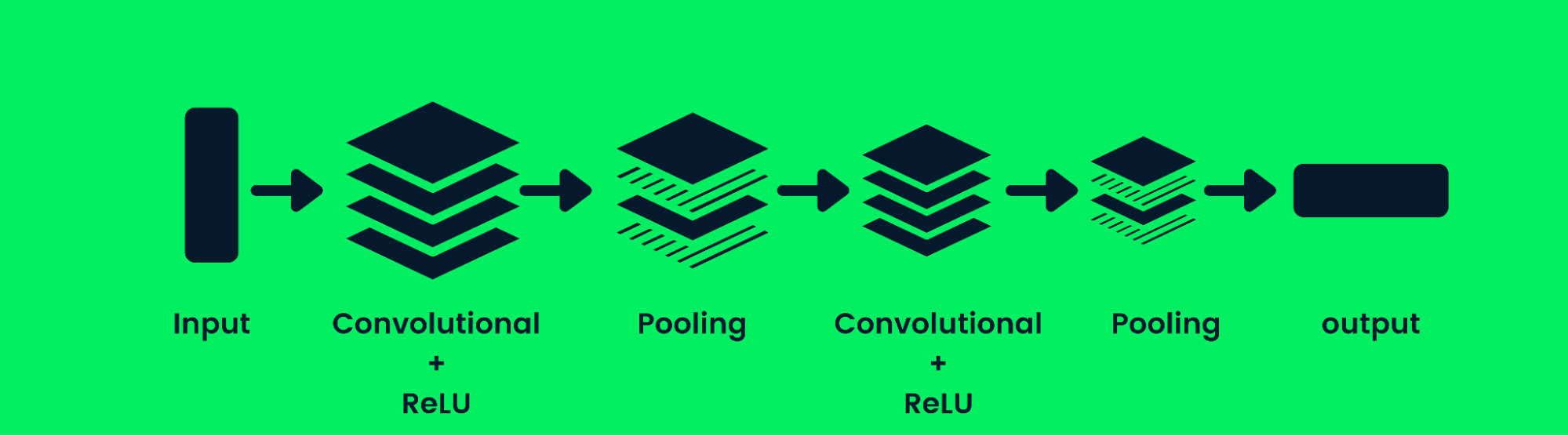 Architecture des réseaux neuronaux à convolution
Architecture des réseaux neuronaux à convolution
Les CNN sont capables de reconnaître des modèles, des lignes et des formes. Le CNN se compose d'une couche convolutive, d'une couche de mise en commun et d'une couche de sortie (couches entièrement connectées). Les modèles de classification d'images contiennent généralement plusieurs couches de convolution, suivies de couches de mise en commun, car des couches supplémentaires augmentent la précision du modèle. Pour en savoir plus sur les couches convolutives, cliquez ici : Réseaux neuronaux convolutifs en Python.
Réseaux neuronaux récurrents
Les réseaux neuronaux récurrents (RNN) sont différents des réseaux à progression directe, car la sortie de la couche est réinjectée dans l'entrée pour prédire la sortie de la couche. Cela lui permet d'être plus performant avec les données séquentielles, car il peut stocker les informations des échantillons précédents pour prédire les échantillons futurs. Pour en savoir plus, consultez le site Recurrent Neural Network (RNN) Tutorial : Types et exemples.
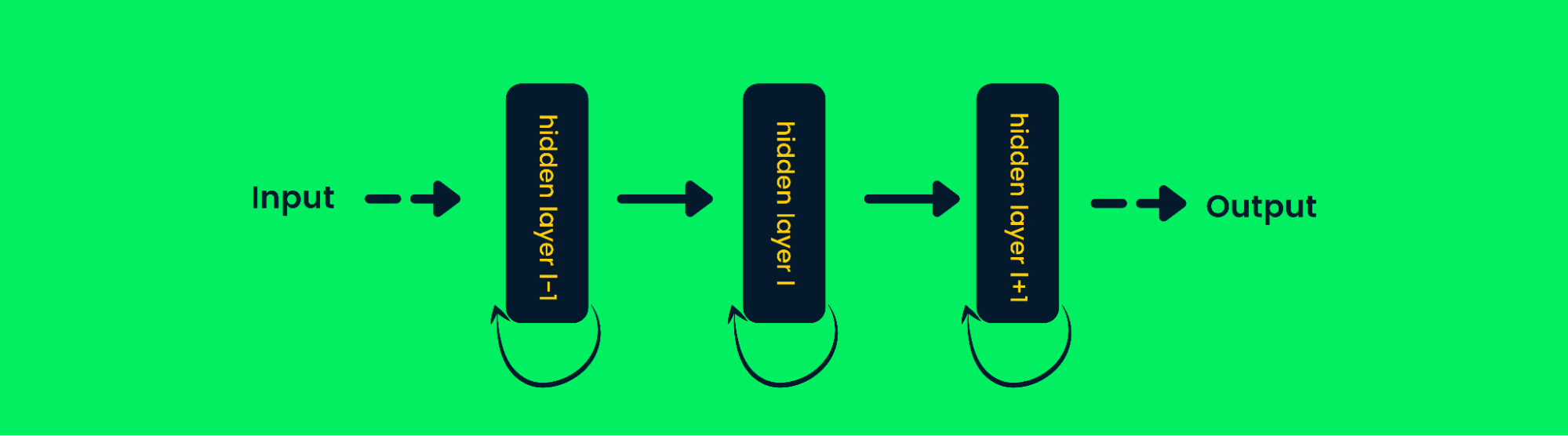 Architecture des réseaux neuronaux récurrents
Architecture des réseaux neuronaux récurrents
Dans les réseaux neuronaux traditionnels, la sortie des couches est calculée sur la base des valeurs d'entrée actuelles, mais dans les RNN, la sortie est également calculée sur la base des entrées précédentes. Cela lui permet de prédire le prochain mot, de prévoir les cours de la bourse, de s'intégrer dans les chatbots d'IA et de détecter les anomalies.
Réseaux de mémoire à long terme et à court terme
Les réseaux de mémoire à long terme (LSTM) sont des types avancés de réseaux neuronaux récurrents qui peuvent retenir davantage d'informations sur les valeurs passées. Il résout les problèmes de gradient de disparition qui existent dans les RNN simples.
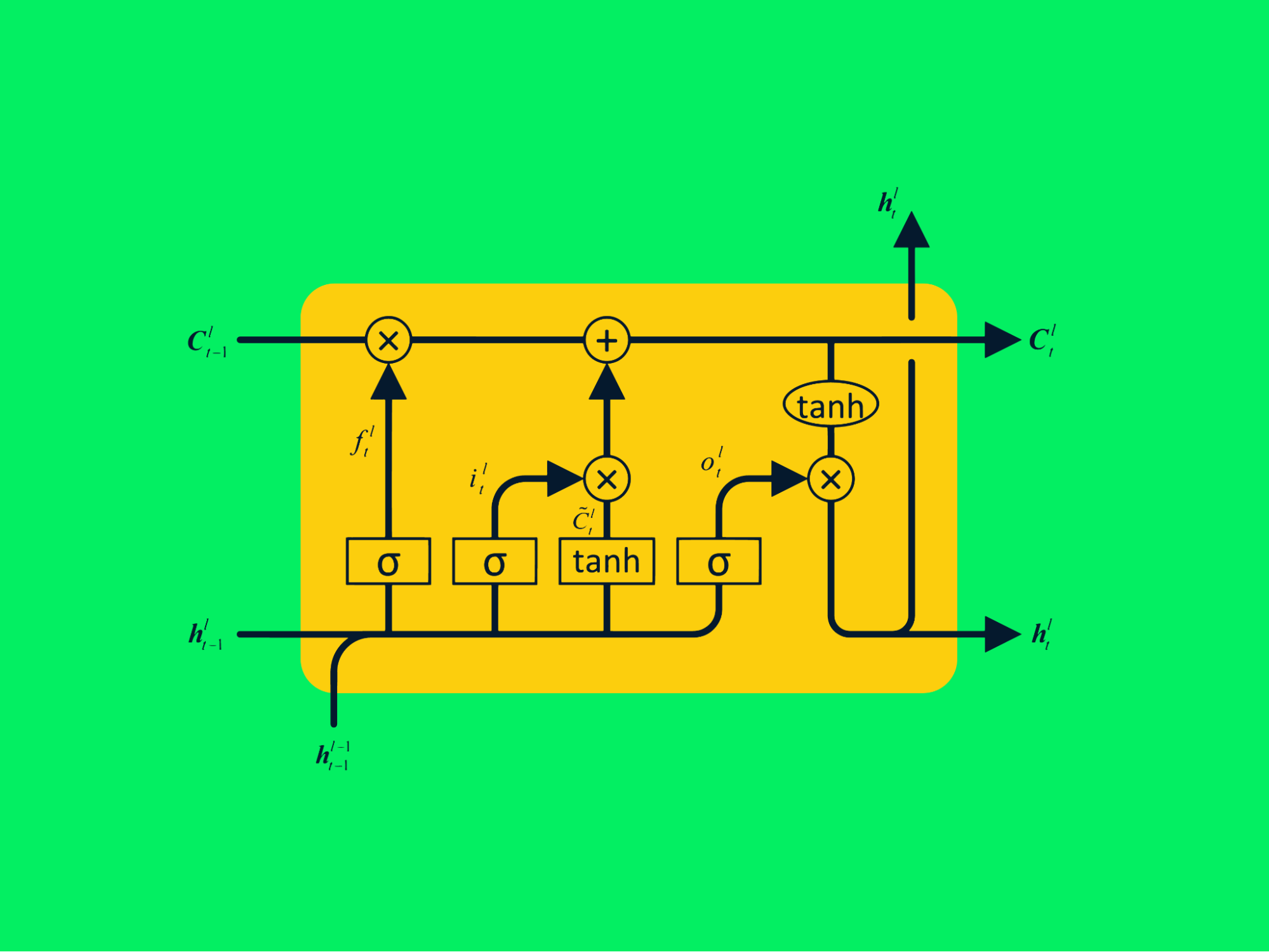 Architecture LSTM
Architecture LSTM
Le RNN typique se compose de réseaux neuronaux répétitifs avec une seule couche de tanh, tandis que la LSTM se compose de quatre couches interactives qui communiquent pour traiter de grandes séquences de données.
Vous pouvez acquérir une expérience pratique grâce au didacticiel suivant : : LSTM pour les prévisions boursières ou le cours d'apprentissage profond avancé avec Keras si vous souhaitez en savoir plus sur les modèles d'apprentissage profond.
Cadres d'apprentissage profond
Il existe de nombreux cadres d'apprentissage profond, tels que MxNet, CNTK et Caffe2, mais nous allons nous familiariser avec les cadres les plus populaires.
Tensorflow
Tensorflow (TF) est une bibliothèque open-source utilisée pour créer des applications d'apprentissage profond. Il comprend tous les outils nécessaires pour vous permettre d'expérimenter et de développer des produits d'IA commerciaux. Il prend en charge à la fois le CPU, le GPU et le TPU pour la formation de modèles complexes. TF a été développé à l'origine par l'équipe Google AI pour un usage interne et est maintenant disponible pour le public.
L'API Tensorflow est disponible pour les applications basées sur un navigateur, les appareils mobiles, et TensorFlow Extended est idéal pour la production. TF est aujourd'hui devenu le standard de l'industrie, et il est utilisé à la fois pour la recherche académique et pour le déploiement de modèles d'apprentissage profond en production.
TF est également livré avec Tensorboard, un tableau de bord capable d'analyser vos expériences d'apprentissage automatique. Récemment, les développeurs de Tensorflow ont intégré Keras dans son cadre, qui est populaire pour le développement de réseaux neuronaux profonds. Pour en savoir plus, consultez le cours d'introduction à TensorFlow en Python.
Keras
Keras est un framework de réseau neuronal écrit en Python et capable de fonctionner sur plusieurs frameworks tels que Tensorflow et Theano. Keras est une bibliothèque open-source développée pour permettre une expérimentation rapide de l'apprentissage profond afin que vous puissiez facilement convertir vos concepts en applications d'IA fonctionnelles.
La documentation est assez facile à comprendre, et l'API est similaire à Numpy, ce qui vous permet de l'intégrer facilement à n'importe quel projet de science des données. Tout comme TF, Keras peut également fonctionner sur le CPU, le GPU et le TPU, en fonction du matériel disponible. Pour en savoir plus, consultez la page Introduction à l'apprentissage profond avec Keras.
PyTorch
PyTorch est le cadre d'apprentissage profond le plus populaire et le plus simple. Il utilise des tenseurs au lieu de tableaux Numpy pour effectuer des calculs numériques rapides avec l'aide du GPU. PyTorch est principalement utilisé pour l'apprentissage profond et le développement de modèles complexes d'apprentissage automatique.
Les chercheurs universitaires préfèrent utiliser PyTorch en raison de sa flexibilité et de sa facilité d'utilisation. Il est écrit en C++ et en Python, et il est également doté d'une accélération des GPU et des TPU. Il est devenu une solution unique pour tous les problèmes d'apprentissage en profondeur. Si vous souhaitez en savoir plus sur PyTorch, essayez de suivre le cours Introduction à l'apprentissage profond avec PyTorch.
Conclusion
Dans ce tutoriel, nous avons abordé ce qu'est l'apprentissage profond, certaines de ses bases, son fonctionnement et ses applications. Nous avons également appris comment fonctionnent les réseaux neuronaux profonds et quels sont les différents types de modèles d'apprentissage profond. Enfin, nous vous avons présenté quelques cadres d'apprentissage profond populaires.
Ce tutoriel vous a fourni toutes les informations clés nécessaires pour vous lancer dans le domaine de l'apprentissage profond. Pour approfondir votre apprentissage, le cursus Deep Learning in Python vous préparera à travailler sur des projets concrets. Vous pouvez également découvrir l'apprentissage profond avec Keras dans R si vous êtes à l'aise avec le langage de programmation R.

