Cours
Python intermédiaire
4 h
1.4M

Dans ce tutoriel PyTorch, nous aborderons les fonctions de base qui alimentent les réseaux neuronaux et nous construirons les nôtres à partir de zéro. L'objectif principal de cet article est de démontrer les bases de PyTorch, une bibliothèque tensorielle optimisée pour l'apprentissage profond, tout en vous fournissant un contexte détaillé sur le fonctionnement des réseaux neuronaux.
Note: Consultez cet espace de travail DataCamp pour suivre le code écrit dans cet article.
Les réseaux neuronaux sont également appelés réseaux neuronaux artificiels (RNA). L'architecture constitue la base de l'apprentissage profond, qui est simplement un sous-ensemble de l'apprentissage automatique concernant les algorithmes qui s'inspirent de la structure et de la fonction du cerveau humain. En d'autres termes, les réseaux neuronaux constituent la base des architectures qui imitent la manière dont les neurones biologiques se signalent les uns aux autres.
Par conséquent, vous trouverez souvent des ressources qui consacrent les cinq premières minutes à la représentation de la structure neuronale du cerveau humain pour vous aider à conceptualiser visuellement le fonctionnement d'un réseau neuronal. Mais lorsque vous ne disposez pas de cinq minutes supplémentaires, il est plus facile de définir un réseau neuronal comme une fonction qui associe des entrées à des sorties souhaitées.
L'architecture générique du réseau neuronal se compose des éléments suivants :
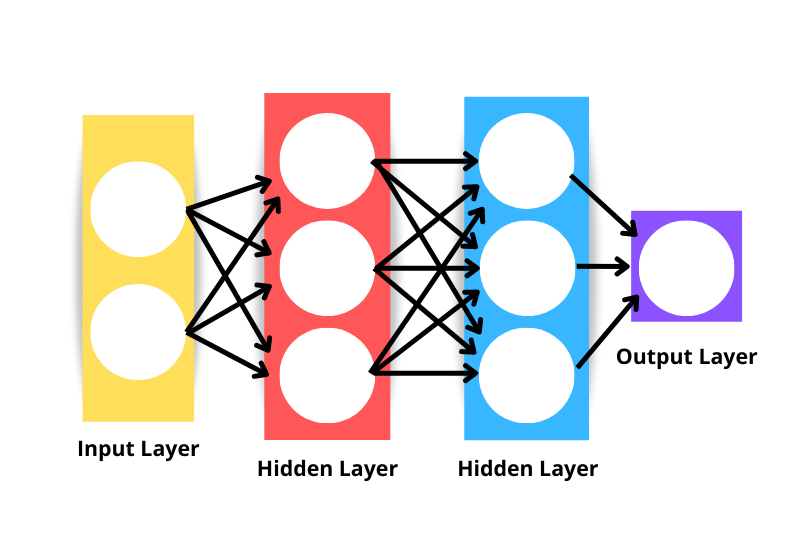
Notez que le réseau neuronal affiché dans l'image ci-dessus serait considéré comme un réseau neuronal à trois couches et non à quatre - ceci parce que nous n'incluons pas la couche d'entrée comme une couche. Ainsi, le nombre de couches d'un réseau est le nombre de couches cachées plus la couche de sortie.
Décomposons l'algorithme en éléments plus petits pour mieux comprendre le fonctionnement des réseaux neuronaux.
L'initialisation des poids est le premier élément de l'architecture du réseau neuronal. Les poids initiaux sont fixés pour définir le point de départ du processus d'optimisation du modèle de réseau neuronal.
La manière dont nous définissons nos poids est importante, en particulier lorsque nous construisons des réseaux profonds. En effet, les réseaux profonds sont plus susceptibles de souffrir du problème d'explosion ou de disparition du gradient. Les problèmes de disparition et d'explosion du gradient sont deux concepts qui dépassent le cadre de cet article, mais ils décrivent tous deux un scénario dans lequel l'algorithme ne parvient pas à apprendre.
Bien que l'initialisation des poids ne résolve pas complètement le problème de l'évanouissement ou de l'explosion du gradient, elle contribue certainement à le prévenir.
Voici quelques approches courantes de l'initialisation des poids :
L'initialisation zéro signifie que les poids sont initialisés à zéro. Ce n'est pas une bonne solution car notre réseau neuronal ne parviendrait pas à briser la symétrie - il n'apprendrait pas.
Lorsqu'une valeur constante est utilisée pour initialiser les poids d'un réseau neuronal, on peut s'attendre à ce que ses performances soient médiocres, car toutes les couches apprendront la même chose. Si toutes les sorties des unités cachées ont la même influence sur le coût, les gradients seront identiques.
L'initialisation aléatoire brise la symétrie, ce qui signifie qu'elle est meilleure que l'initialisation zéro, mais certains facteurs peuvent dicter la qualité globale du modèle.
Par exemple, si les poids sont initialisés de manière aléatoire avec des valeurs élevées, on peut s'attendre à ce que chaque multiplication de la matrice aboutisse à une valeur significativement plus élevée. Lorsqu'une fonction d'activation sigmoïde est appliquée dans de tels scénarios, le résultat est une valeur proche de un, ce qui ralentit le taux d'apprentissage.
Un autre scénario dans lequel l'initialisation aléatoire peut poser des problèmes est celui où les poids sont initialisés aléatoirement à de petites valeurs. Dans ce cas, chaque multiplication de la matrice produira des valeurs nettement plus petites, et l'application d'une fonction sigmoïde produira une valeur plus proche de zéro, ce qui ralentit également le taux d'apprentissage.
L'initialisation Xavier ou Glorot - quel que soit le nom - est une approche heuristique utilisée pour initialiser les poids. Cette approche d'initialisation est fréquente lorsqu'une fonction d'activation tanh ou sigmoïde est appliquée à la moyenne pondérée. L'approche a été proposée pour la première fois en 2010 dans un document de recherche intitulé Understanding the difficulty of training deep feedforward neural networks par Xavier Glorot et Yoshua Bengio. Cette technique d'initialisation vise à maintenir la variance du réseau égale afin d'éviter que les gradients n'explosent ou ne disparaissent.
L'initialisation He ou Kaiming est une autre approche heuristique. La différence avec les heuristiques He et Xavier est que l'initialisation He utilise un facteur d'échelle différent pour les poids qui prend en compte la non-linéarité des fonctions d'activation.
Ainsi, lorsque la fonction d'activation ReLU est utilisée dans les couches, l'initialisation He est l'approche recommandée. Pour en savoir plus sur cette approche, consultez le site Delving Deep into Rectifiers : Surpasser les performances humaines dans la classification d'ImageNet par He et al.
Les réseaux neuronaux fonctionnent en prenant une moyenne pondérée plus un terme de biais et en appliquant une fonction d'activation pour ajouter une transformation non linéaire. Dans la formule de la moyenne pondérée, chaque poids détermine l'importance de chaque caractéristique (c'est-à-dire sa contribution à la prédiction de la sortie).
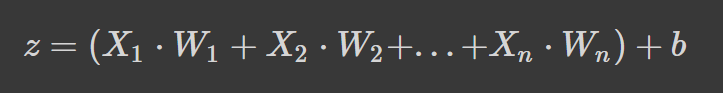
La formule ci-dessus est la moyenne pondérée plus un terme de biais où,
Si la formule vous semble familière, c'est parce qu'il s'agit d'une régression linéaire. Sans introduire de non-linéarité dans les neurones, nous aurions une régression linéaire, qui est un modèle simple. La transformation non linéaire permet à notre réseau neuronal d'apprendre des modèles complexes.
Nous avons déjà fait allusion à certaines fonctions d'activation dans la section sur l'initialisation des poids, mais vous connaissez maintenant leur importance dans l'architecture d'un réseau neuronal.
Approfondissons certaines fonctions d'activation courantes que vous êtes susceptible de voir lorsque vous lisez des articles de recherche et le code d'autres personnes.
La fonction sigmoïde se caractérise par une courbe en forme de "S" limitée entre les valeurs zéro et un. Il s'agit d'une fonction différentiable, ce qui signifie que la pente de la courbe peut être trouvée en deux points quelconques, et monotone, ce qui signifie qu'elle n'est ni entièrement croissante ni entièrement décroissante. Vous utilisez généralement la fonction d'activation sigmoïde pour les problèmes de classification binaire.
Voici comment vous pouvez visualiser votre propre fonction sigmoïde à l'aide de Python :
# Sigmoid function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = 1/(1 + np.exp(-x))
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()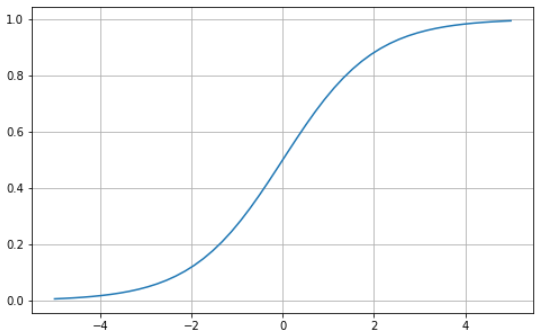
La tangente hyperbolique (tanh) a la même courbe en forme de "S" que la fonction sigmoïde, sauf que les valeurs sont limitées entre -1 et 1. Ainsi, les petites entrées sont rapprochées de -1, et les grandes entrées sont rapprochées de 1.
Voici un exemple de fonction tanh visualisée à l'aide de Python :
# tanh function in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = np.tanh(x)
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()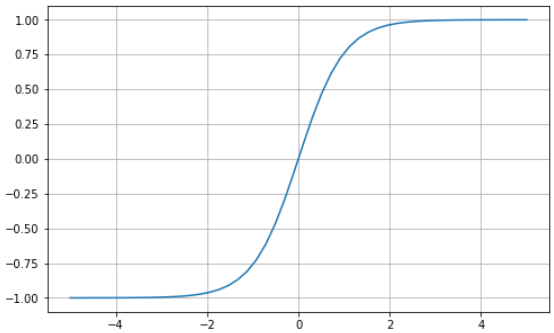
La fonction softmax est généralement utilisée comme fonction d'activation dans la couche de sortie. Il s'agit d'une généralisation de la fonction sigmoïde à plusieurs dimensions. Il est donc utilisé dans les réseaux neuronaux pour prédire l'appartenance à une classe à partir de plus de deux étiquettes.
L'utilisation de la fonction sigmoïde ou tanh pour construire des réseaux neuronaux profonds est risquée car ils sont plus susceptibles de souffrir du problème du gradient de disparition. La fonction d'activation de l'unité linéaire rectifiée (ReLU) est apparue comme une solution à ce problème et est souvent la fonction d'activation par défaut de plusieurs réseaux neuronaux.
Voici un exemple visuel de la fonction ReLU à l'aide de Python :
# ReLU in Python
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
z = [max(0, i) for i in x]
plt.subplots(figsize=(8, 5))
plt.plot(x, z)
plt.grid()
plt.show()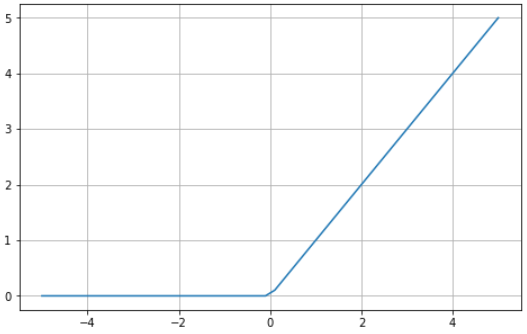
ReLU est limité entre zéro et l'infini : notez que pour les valeurs d'entrée inférieures ou égales à zéro, la fonction renvoie zéro, et pour les valeurs supérieures à zéro, la fonction renvoie la valeur d'entrée fournie (c'est-à-dire que si vous entrez deux, la fonction renvoie deux). En fin de compte, la fonction ReLU se comporte de manière extrêmement similaire à une fonction linéaire, ce qui la rend beaucoup plus facile à optimiser et à mettre en œuvre.
Le processus qui va de la couche d'entrée à la couche de sortie est connu sous le nom de "forward pass" ou "forward propagation". Au cours de cette phase, les sorties générées par le modèle sont utilisées pour calculer une fonction de coût afin de déterminer les performances du réseau neuronal après chaque itération. Ces informations sont ensuite transmises au modèle pour corriger les poids de manière à ce que le modèle puisse faire de meilleures prédictions dans un processus connu sous le nom de rétropropagation.
À la fin de la première passe avant, le réseau fait des prédictions en utilisant les poids initialisés, qui ne sont pas ajustés. Il est donc très probable que les prévisions du modèle ne soient pas exactes. À l'aide de la perte calculée par la propagation vers l'avant, nous transmettons des informations au réseau afin d'affiner les poids dans le cadre d'un processus connu sous le nom de rétropropagation.
En fin de compte, nous utilisons la fonction d'optimisation pour nous aider à identifier les poids qui peuvent réduire le taux d'erreur, rendant le modèle plus fiable et augmentant sa capacité de généralisation à de nouvelles instances. Les mathématiques de ce fonctionnement dépassent le cadre de cet article, mais le lecteur intéressé peut en apprendre davantage sur la rétropropagation dans notre cours Introduction à l'apprentissage profond en Python.
Dans cette section de l'article, nous allons construire un modèle simple de réseau neuronal artificiel à l'aide de la bibliothèque PyTorch. Consultez l'espace de travail de DataCamp pour suivre le code.
PyTorch est l'une des bibliothèques les plus populaires pour l'apprentissage profond. Il offre une expérience de débogage beaucoup plus directe que TensorFlow. Il présente plusieurs autres avantages tels que la formation distribuée, un écosystème robuste, la prise en charge du cloud, vous permettant d'écrire du code prêt pour la production, etc. Vous pouvez en apprendre davantage sur PyTorch dans le cursus de compétences Introduction à l'apprentissage profond avec PyTorch.
Commençons par le tutoriel.
L'ensemble de données que nous utiliserons dans notre tutoriel est make_circles de scikit-learn - voir la documentation. Il s'agit d'un jeu de données contenant un grand cercle avec un cercle plus petit dans un plan bidimensionnel et deux caractéristiques. Pour notre démonstration, nous avons utilisé 10 000 échantillons et ajouté un écart-type de 0,05 de bruit gaussien aux données.
Avant de construire notre réseau neuronal, il est conseillé de diviser nos données en ensembles de formation et de test afin d'évaluer les performances du modèle sur des données inédites.
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
# Create a dataset with 10,000 samples.
X, y = make_circles(n_samples = 10000,
noise= 0.05,
random_state=26)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.33, random_state=26)
# Visualize the data.
fig, (train_ax, test_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(10, 5))
train_ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Spectral)
train_ax.set_title("Training Data")
train_ax.set_xlabel("Feature #0")
train_ax.set_ylabel("Feature #1")
test_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
test_ax.set_xlabel("Feature #0")
test_ax.set_title("Testing data")
plt.show()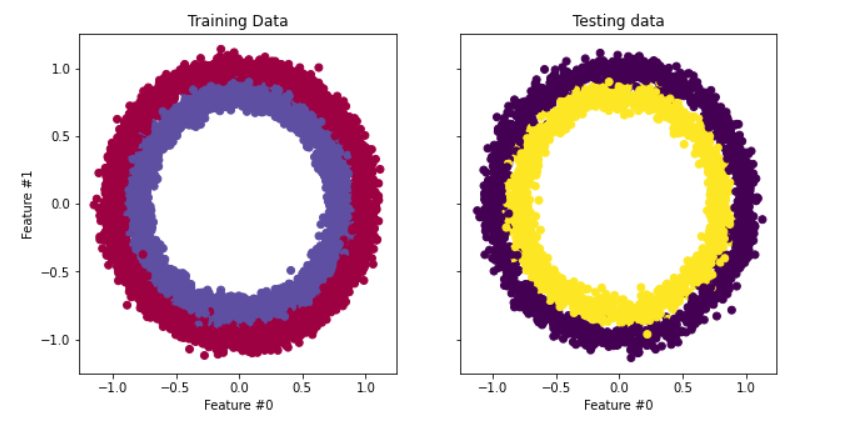
L'étape suivante consiste à convertir les données d'entraînement et de test des tableaux NumPy en tenseurs PyTorch. Pour ce faire, nous allons créer un ensemble de données personnalisé pour nos fichiers de formation et de test. Nous allons également utiliser le module Dataloader de PyTorch afin de pouvoir entraîner nos données par lots. Voici le code :
import warnings
warnings.filterwarnings("ignore")
!pip install torch -q
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
# Convert data to torch tensors
class Data(Dataset):
def __init__(self, X, y):
self.X = torch.from_numpy(X.astype(np.float32))
self.y = torch.from_numpy(y.astype(np.float32))
self.len = self.X.shape[0]
def __getitem__(self, index):
return self.X[index], self.y[index]
def __len__(self):
return self.len
batch_size = 64
# Instantiate training and test data
train_data = Data(X_train, y_train)
train_dataloader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_data = Data(X_test, y_test)
test_dataloader = DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
# Check it's working
for batch, (X, y) in enumerate(train_dataloader):
print(f"Batch: {batch+1}")
print(f"X shape: {X.shape}")
print(f"y shape: {y.shape}")
break
"""
Batch: 1
X shape: torch.Size([64, 2])
y shape: torch.Size([64])
"""Passons maintenant à la mise en œuvre et à l'entraînement de notre réseau neuronal.
Nous allons mettre en œuvre un réseau neuronal simple à deux couches qui utilise la fonction d'activation ReLU (torch.nn.functional.relu). Pour ce faire, nous allons créer une classe appelée NeuralNetwork qui hérite de nn.Module, la classe de base de tous les modules de réseaux neuronaux construits dans PyTorch.
Voici le code :
import torch
from torch import nn
from torch import optim
input_dim = 2
hidden_dim = 10
output_dim = 1
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.layer_1 = nn.Linear(input_dim, hidden_dim)
nn.init.kaiming_uniform_(self.layer_1.weight, nonlinearity="relu")
self.layer_2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.nn.functional.relu(self.layer_1(x))
x = torch.nn.functional.sigmoid(self.layer_2(x))
return x
model = NeuralNetwork(input_dim, hidden_dim, output_dim)
print(model)
"""
NeuralNetwork(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=1, bias=True)
)
"""Et c'est tout.
Pour entraîner le modèle, nous devons définir une fonction de perte à utiliser pour calculer les gradients et un optimiseur pour mettre à jour les paramètres. Pour notre démonstration, nous allons utiliser l'entropie croisée binaire et la descente de gradient stochastique avec un taux d'apprentissage de 0,1.
learning_rate = 0.1
loss_fn = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=leaEntraînons notre modèle
num_epochs = 100
loss_values = []
for epoch in range(num_epochs):
for X, y in train_dataloader:
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
pred = model(X)
loss = loss_fn(pred, y.unsqueeze(-1))
loss_values.append(loss.item())
loss.backward()
optimizer.step()
print("Training Complete")
"""
Training Complete
"""Puisque nous avons effectué le cursus des valeurs de perte, nous pouvons visualiser la perte du modèle au fil du temps.
step = range(len(loss_values))
fig, ax = plt.subplots(figsize=(8,5))
plt.plot(step, np.array(loss_values))
plt.title("Step-wise Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()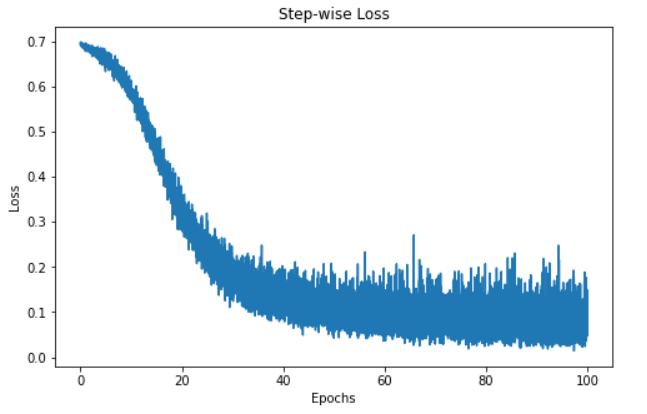
La visualisation ci-dessus montre la perte de notre modèle sur 100 époques. Au départ, la perte est de 0,7 et diminue progressivement, ce qui nous indique que notre modèle a amélioré ses prédictions au fil du temps. Toutefois, le modèle semble plafonner autour de la marque des 60 époques, ce qui peut s'expliquer par diverses raisons, comme le fait que le modèle se trouve dans la région d'un minimum local ou global de la fonction de perte.
Néanmoins, le modèle a été entraîné et est prêt à faire des prédictions sur de nouvelles instances - nous verrons comment le faire dans la section suivante.
Il est assez simple de faire des prédictions avec notre réseau neuronal PyTorch.
import itertools # Import this at the top of your script
# Initialize required variables
y_pred = []
y_test = []
correct = 0
total = 0
"""
We're not training so we don't need to calculate the gradients for our outputs
"""
with torch.no_grad():
for X, y in test_dataloader:
outputs = model(X) # Get model outputs
predicted = np.where(outputs.numpy() < 0.5, 0, 1) # Convert to NumPy and apply threshold
predicted = list(itertools.chain(*predicted)) # Flatten predictions
y_pred.append(predicted) # Append predictions
y_test.append(y.numpy()) # Append true labels as NumPy
total += y.size(0) # Increment total count
correct += (predicted == y.numpy()).sum().item() # Count correct predictions
print(f'Accuracy of the network on the 3300 test instances: {100 * correct // total}%')
"""
Accuracy of the network on the 3300 test instances: 97%
"""
Note: Chaque exécution du code produira un résultat différent, il se peut donc que vous n'obteniez pas les mêmes résultats.
Le code ci-dessus parcourt en boucle les lots de tests, qui sont stockés dans la variable test_dataloader, sans calculer les gradients. Nous prédisons ensuite les instances du lot et stockons les résultats dans une variable appelée "outputs". Ensuite, nous déterminons que toutes les valeurs inférieures à 0,5 sont fixées à 0 et celles qui sont égales ou supérieures à 0,5 sont fixées à 1. Ces valeurs sont ensuite ajoutées à une liste pour nos prédictions.
Ensuite, nous ajoutons les prédictions réelles des instances du lot à une variable appelée total. Nous calculons ensuite le nombre de prédictions correctes en identifiant le nombre de prédictions correspondant aux classes réelles et en les totalisant. Le nombre total de prédictions correctes pour chaque lot est incrémenté et stocké dans notre variable correct.
Pour calculer la précision du modèle global, nous multiplions le nombre de prédictions correctes par 100 (pour obtenir un pourcentage), puis nous le divisons par le nombre d'instances de notre ensemble de test. Notre modèle a une précision de 97 %. Nous approfondissons la question en utilisant la matrice de confusion et le rapport de classification de scikit-learn pour mieux comprendre les performances de notre modèle.
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import seaborn as sns
y_pred = list(itertools.chain(*y_pred))
y_test = list(itertools.chain(*y_test))
print(classification_report(y_test, y_pred))
"""
precision recall f1-score support
0.0 0.98 0.97 0.98 1635
1.0 0.98 0.98 0.98 1665
accuracy 0.98 3300
macro avg 0.98 0.98 0.98 3300
weighted avg 0.98 0.98 0.98 3300
"""
cf_matrix = confusion_matrix(y_test, y_pred)
plt.subplots(figsize=(8, 5))
sns.heatmap(cf_matrix, annot=True, cbar=False, fmt="g")
plt.show()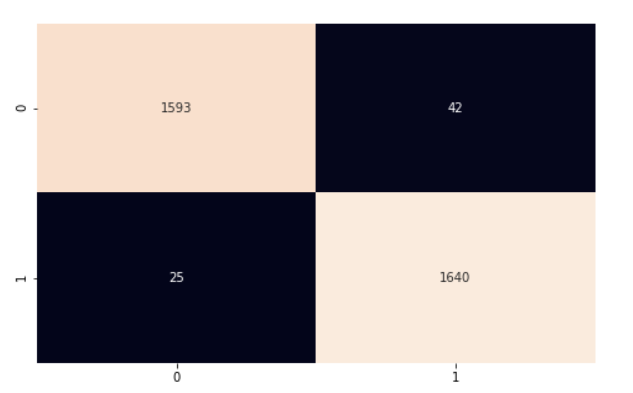
Notre modèle fonctionne plutôt bien. Je vous encourage à explorer le code et à y apporter des modifications afin de rendre plus efficace ce que nous avons abordé dans cet article.
Dans ce tutoriel PyTorch, nous avons abordé les bases fondamentales des réseaux neuronaux et utilisé PyTorch, une bibliothèque Python pour l'apprentissage profond, pour mettre en œuvre notre réseau. Nous avons utilisé l'ensemble de données du cercle de scikit-learn pour entraîner un réseau neuronal à deux couches pour la classification. Nous avons ensuite fait des prédictions sur les données et évalué nos résultats à l'aide de la métrique de précision.
Cours pour Python
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach