
Cursus
Fondations Snowflake
7 h
À mesure que les équipes de données modernes adoptent des piles analytiques de plus en plus complexes, on observe une évolution vers la création de pratiques standardisées dans les workflows d'ingénierie des données. Les outils tels que dbt (Data Build Tool) constituent un cadre open source qui intègre les meilleures pratiques en matière d'ingénierie logicielle, telles que le contrôle de version, les tests et la documentation, aux flux de travail analytiques.
La combinaison de dbt et Snowflake (un entrepôt de données natif du cloud) s'est imposée comme la pierre angulaire des workflows d'ingénierie analytique. Ce guide explore les concepts fondamentaux, la configuration et les stratégies de mise en œuvre avancées pour l'intégration de dbt avec Snowflake, aidant ainsi les équipes chargées des données à obtenir des pipelines de données plus faciles à maintenir, plus sécurisés et plus performants.
Si vous débutez avec ces outils, je vous recommande de suivre notre cursus de compétences Snowflake Foundations et notre cours Introduction à dbt.
Examinons comment dbt et Snowflake fonctionnent ensemble. Cette section présente les fonctionnalités de dbt et met en avant sa compatibilité avec Snowflake ainsi que les avantages de leur intégration conjointe.
dbt (Data Build Tool) est un framework open source qui permet aux équipes chargées des données de transformer, tester et documenter les données directement dans leur entrepôt à l'aide de SQL amélioré avec les modèles Jinja.
dbt n'est pas un langage de programmation en soi ; il agit comme un compilateur, prenant des modèles SQL modulaires et les convertissant en requêtes SQL exécutables qui s'exécutent dans l'entrepôt (par exemple, Snowflake).
En intégrant le contrôle de version, les tests automatisés et la documentation, dbt apporte des pratiques éprouvées d'ingénierie logicielle à l'ingénierie analytique, rendant les pipelines de transformation plus fiables, plus faciles à maintenir et plus évolutifs dans le cadre d'un workflow ELT.
Ses composants principaux comprennent un compilateur et un exécuteur. Voici leurs fonctions :
Pour que dbt fonctionne, plusieurs composants sous-jacents contribuent à la fluidité du processus :
select s principales sont enregistrées sous forme de fichiers .sql.Pour plus de détails sur dbt, je recommande cette excellente introduction au cours dbt.
En utilisant les modèles Jinja de dbt combinés aux puissants types de données de Snowflake, tels que Streams, nous pouvons faire preuve d'une grande créativité dans nos workflows de transformation.
Par exemple, nous souhaitons peut-être transformer uniquement les données récemment chargées ou effectuer des transformations différentes dans nos tableaux de transit par rapport à nos tableaux de production afin de pouvoir effectuer des contrôles de l'intégrité des données.
Ces deux éléments deviennent rapidement une combinaison courante pour aider les ingénieurs de données à mieux contrôler et à assouplir leurs pipelines de données, de plus en plus d'entreprises adoptant régulièrement dbt.
La méthodologie DBT présente de nombreux avantages : méthodologie traditionnelle de développement logiciel, tests automatisés et amélioration de la productivité.
Nous pouvons traiter nos données et notre SQL davantage comme du code traditionnel. Cela nous permet de bénéficier de la modularité, de la testabilité et du contrôle de version. En tirant parti des modèles et des instructions de contrôle de flux Python, nous bénéficions de fonctionnalités puissantes offertes par dbt.
Grâce à la configuration intégrée dbt d'data_test, nous pouvons régulièrement effectuer des tests sur nos données sans avoir recours à des pipelines SQL complexes. En réalité, dbt est déjà fourni avec des tests de base puissants que nous pouvons facilement implémenter dans nos fichiers de configuration.
Dbt comprend des éléments tels que des générateurs de documentation et des visualiseurs de pipeline. Les nouveaux membres de l'équipe peuvent être intégrés plus rapidement et les membres existants acquièrent une meilleure compréhension des flux de données. Cela contribue à réduire le temps de mise en route et améliore la compréhension globale du flux de travail par tous les participants.
L'utilisation de la plateforme cloud de Snowflake présente de nombreux avantages. Il présente une architecture remarquable qui sépare les ressources de stockage et de calcul afin de minimiser les conflits de ressources et d'optimiser les coûts. Il utilise le clonage sans copie, qui permet aux utilisateurs de créer des clones de bases de données sans stockage supplémentaire.
De plus, il prend en charge certains types de données de tableaux complexes, tels que les tableaux dynamiques et les flux, qui permettent une logique de rafraîchissement incrémentiel. Pour plus d'informations sur la plateforme Snowflake, veuillez consulter cet article qui explique son fonctionnement.
Plus important encore, ces fonctionnalités sont parfaitement complémentaires à dbt. Nous pouvons tirer parti de l'actualisation incrémentielle pour aider dbt à déclencher des transformations basées sur de nouvelles données. Nous pouvons également tirer parti de la séparation entre calcul et stockage offerte par Snowflake, qui permet à dbt d'effectuer des transformations plus gourmandes en ressources informatiques sans affecter la capacité à télécharger et à stocker des données.
Tout cela est rendu possible grâce à la capacité de Snowflake à évoluer rapidement et à son modèle de tarification à l'utilisation. À mesure que la complexité de nos scripts dbt augmente, nous pouvons facilement adapter la taille de nos entrepôts de données Snowflake afin de répondre à ces exigences. Parallèlement, nous pouvons utiliser la surveillance de Snowflake pour optimiser nos entrepôts et utiliser dbt pour améliorer les performances de nos requêtes.
Lorsqu'ils sont combinés, Snowflake et dbt se complètent parfaitement. L'optimisation constante de Snowflake contribue à maintenir les coûts liés au cloud à un niveau bas. dbt peut tirer parti des méthodes de partitionnement des tableaux, telles que les clés de clustering et la mise en cache de Snowflake, afin d'améliorer la charge de travail liée aux données.
Snowflake ne se prête pas facilement à une gestion à l'aide d'outils tels que Git. Étant donné que dbt repose sur les mêmes principes que les autres langages de programmation, nous pouvons utiliser des workflows basés sur Git pour faciliter la gestion de nos processus de développement à l'aide d'éléments tels que les pipelines CI/CD. Cela peut faciliter le contrôle des versions de nos pipelines, ce qui serait difficile à réaliser entièrement dans Snowflake.
Afin de faciliter la collaboration entre développeurs, dbt dispose également d'une interface utilisateur qui regroupe toutes vos tâches dbt en un seul endroit. Cela permet aux équipes de suivre ensemble le cursus des processus et de s'assurer qu'ils fonctionnent correctement. De plus, dbt a récemment lancé un IDE Studio qui facilite l'intégration de Git et des bases de données aux workflows de test. Certaines équipes peuvent même choisir d'utiliser l'interface utilisateur de Snowflake pour une intégration complète.
De nombreuses équipes chargées des données ont commencé à utiliser conjointement dbt et Snowflake afin de tirer le meilleur parti de leurs bases de données. Continuez à approfondir vos connaissances sur dbt grâce à cette introduction pratique à dbt destinée aux ingénieurs de données et découvrez le fonctionnement de la modélisation des données Snowflake dans le cadre de ce cours.
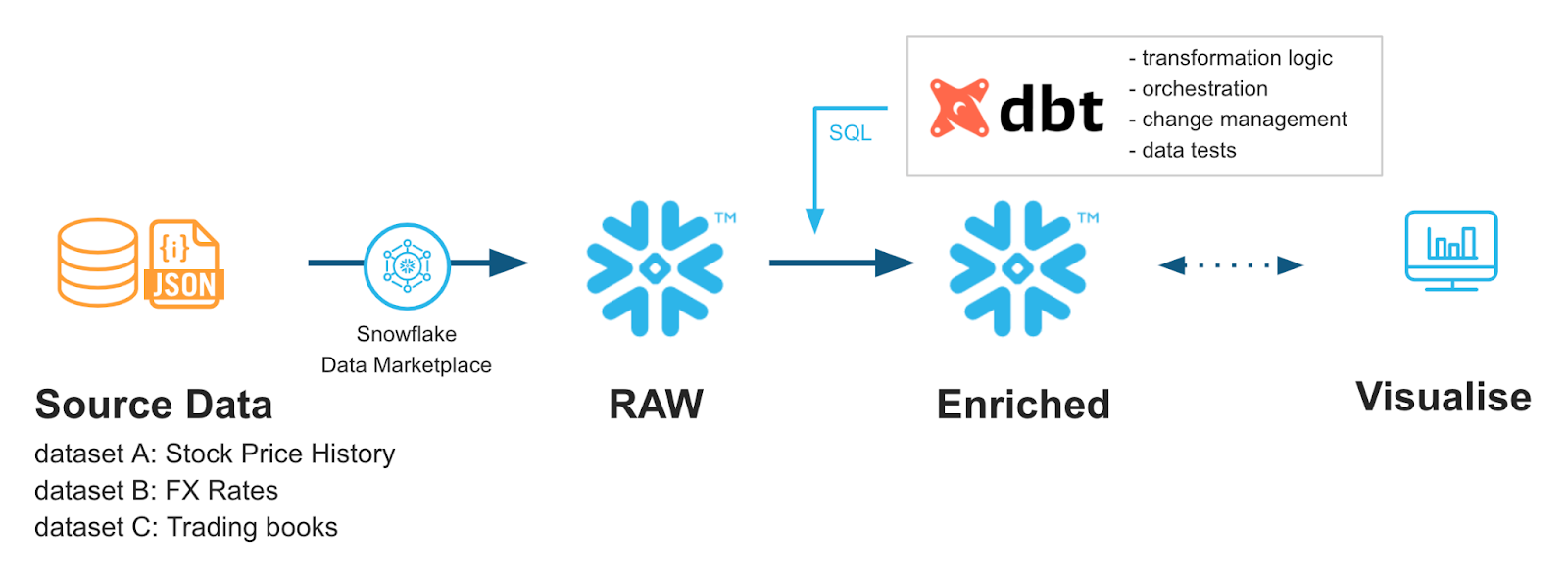
Extrait de Snowflake Quickstarts : Accélérer avec dbt Core et Snowflake
Examinons quelques notions de base sur la configuration de Snowflake et dbt pour une intégration adéquate. Nous aborderons également quelques principes fondamentaux relatifs aux meilleures pratiques en matière de conception de la structure d'un projet.
Nous commencerons par la configuration de la base de données Snowflake, puis nous passerons à la configuration de dbt.
Vous aurez besoin d'une base de données dédiée, d'un schéma et d'un entrepôt virtuel pour stocker vos données dbt. De plus, il est nécessaire de disposer d'un rôle utilisateur dbt spécifique auquel dbt peut accéder. Lors de la configuration de dbt, vous devrez fournir les informations d'identification de cet utilisateur afin qu'il puisse communiquer avec Snowflake. Dans cette section, je vais vous fournir quelques directives de base, mais pour plus de détails sur la gestion des bases de données Snowflake et des rôles utilisateur, je vous invite à suivre le cours Introduction à Snowflake.
CREATE DATABASE analytics_db;
CREATE SCHEMA analytics_db.transformations;
CREATE WAREHOUSE dbt_wh
WITH WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE ROLE dbt_role;
GRANT USAGE ON WAREHOUSE dbt_wh TO ROLE dbt_role;
GRANT USAGE ON DATABASE analytics_db TO ROLE dbt_role;
GRANT USAGE, CREATE SCHEMA ON DATABASE analytics_db TO ROLE dbt_role;
GRANT ALL PRIVILEGES ON SCHEMA analytics_db.transformations TO ROLE dbt_role;
CREATE USER dbt_user PASSWORD='StrongPassword123'
DEFAULT_ROLE = dbt_role
DEFAULT_WAREHOUSE = dbt_wh
DEFAULT_NAMESPACE = analytics_db.transformations;
GRANT ROLE dbt_role TO USER dbt_user;
Afin d'exécuter dbt, il est nécessaire de l'installer à l'aide de la commande ` pip `, puis de configurer le fichier ` profiles.yml `.
dbt-core et dbt-snowflake.pip install dbt-core dbt-snowflakeprofiles.yml et l'enregistrer dans ~/.dbt/profiles.ymlsnowflake-db:
target:dev
outputs:
dev:
type: snowflake
account: [account_id from earlier]
user: [dbt_user]
password: [dbt_pw]
role: [dbt_role]
warehouse:[dbt_warehouse]
database: [dbt_database]
schema: [dbt_schema]
threads: 4
client_session_keep_alive: False
query_tag: [anything]dbt init --profile snowflake-dbdbt init snowflake-profile-nameCela entraînera une initialisation étape par étape qui générera un fichier profiles.yml si nécessaire.
debug:dbt debug --connectionCette commande vérifiera si vos paramètres de connexion sont valides et générera une erreur s'ils ne le sont pas.
À prendre en considération : au lieu d'enregistrer votre nom d'utilisateur et votre mot de passe directement dans le fichier profiles.yml, nous vous recommandons d'utiliser des variables d'environnement. Par exemple, l'adresse dbt_password pourrait être enregistrée dans une variable d'environnement SNOWFLAKE_PASSWORD. Ensuite, dans le fichier profiles.yml, veuillez saisir password: “{{env_var(‘SNOWFLAKE_PASSWORD’)}}”. Cela permet d'empêcher les personnes de voir les identifiants dans le fichier de configuration et ajoute un niveau de sécurité supplémentaire.
En vous connectant à Git, vous pourrez tirer le meilleur parti de votre configuration dbt. Les étapes exactes peuvent varier si vous effectuez cette opération dans le cadre de votre entreprise. Le principe général est toutefois simple. Veuillez créer un référentiel sur une plateforme telle que GitHub ou GitLab. Veuillez ensuite associer votre compte dbt à votre compte GitHub/GitLab. Une fois cela effectué, vous pouvez git clone votre référentiel. Pour plus d'informations sur la connexion de Git à dbt, veuillez consulter la documentation Git de dbt. documentation Git de dbt pour votre plateforme spécifique.
Une structure de projet cohérente et basée sur des modèles permet de démarrer plus rapidement les nouveaux projets en fournissant des emplacements fixes où tout doit être rangé.
Organisez votre projet en dossiers entre les phases de préparation, intermédiaire et de commercialisation. Au sein de chacune d'elles, il est possible de définir différents départements, chacun disposant de ses propres modèles et SQL.
models/
│ ├── intermediate
│ │ └── finance
│ │ ├── _int_finance__models.yml
│ │ └── int_payments_pivoted_to_orders.sql
│ ├── marts
│ │ ├── finance
│ │ │ ├── _finance__models.yml
│ │ │ ├── orders.sql
│ │ │ └── payments.sql
│ │ └── marketing
│ │ ├── _marketing__models.yml
│ │ └── customers.sql
│ ├── staging
│ │ ├── jaffle_shop
│ │ │ ├── _jaffle_shop__docs.md
│ │ │ ├── _jaffle_shop__models.yml
│ │ │ ├── _jaffle_shop__sources.yml
│ │ │ ├── base
│ │ │ │ ├── base_jaffle_shop__customers.sql
│ │ │ │ └── base_jaffle_shop__deleted_customers.sql
│ │ │ ├── stg_jaffle_shop__customers.sql
│ │ │ └── stg_jaffle_shop__orders.sql
│ │ └── stripe
│ │ ├── _stripe__models.yml
│ │ ├── _stripe__sources.yml
│ │ └── stg_stripe__payments.sql
│ └── utilities
│ └── all_dates.sql/Chaque dossier dans les modèles a une fonction spécifique :
Pour chacun des fichiers de configuration des modèles staging, intermediate et marts, il est recommandé de définir la configuration +materialized afin de déterminer comment la sortie SQL est créée dans Snowflake. Nous pouvons choisir entre des vues, des tableaux ou des ensembles de données incrémentiels.
Cela pourrait ressembler à ceci :
# The following dbt_project.yml configures a project that looks like this:
# .
# └── models
# ├── csvs
# │ ├── employees.sql
# │ └── goals.sql
# └── events
# ├── stg_event_log.sql
# └── stg_event_sessions.sql
name: my_project
version: 1.0.0
config-version: 2
models:
my_project:
events:
# materialize all models in models/events as tables
+materialized: table
csvs:
# this is redundant, and does not need to be set
+materialized: viewL'un des principaux avantages de l'intégration de dbt et Snowflake réside dans le fait que nous bénéficions des optimisations offertes par les deux plateformes. Pour Snowflake, nous pouvons employer différentes méthodes de traitement des requêtes afin d'accélérer leur exécution. Pour le dbt, nous pouvons optimiser notre codage à l'aide de macros et de techniques de matérialisation.
Il existe certaines fonctionnalités uniques de Snowflake dont nous pouvons tirer parti pour améliorer les performances de nos requêtes.
Les deux principales méthodes d'optimisation que nous utilisons dans Snowflake sont le prédicat pushdown et les clés de clustering.
Le prédicat pushdown consiste à modifier le moment où Snowflake effectue le filtrage afin de réduire la quantité de données lues. Par exemple, imaginons que nous interrogions nos données avec deux niveaux de filtrage : un filtre de sécurité et un filtre catégoriel.
Le filtre de sécurité détermine qui peut consulter certaines parties de notre tableau en fonction des rôles de sécurité. Le filtre catégorique se trouve dans notre instruction « WHERE » dans la requête. Snowflake sélectionnera le filtre qui sera appliqué en premier, celui qui nécessitera la lecture du plus petit volume de données.
Pour faciliter cette réduction du prédicat, nous pourrions envisager de regrouper les clés. Bien que Snowflake effectue un travail satisfaisant en matière de regroupement des tableaux, lorsque les données atteignent plusieurs téraoctets, il devient difficile pour Snowflake de maintenir des partitions pertinentes.
En définissant des clés de regroupement, nous pouvons aider Snowflake à partitionner les données d'une manière qui correspond à la façon dont nous interrogeons fréquemment les tableaux. Par exemple, nous pourrions sélectionner deux colonnes qui vont toujours ensemble, telles que les dates et les types de propriétés. Chaque type de propriété peut avoir un nombre de dates suffisamment restreint pour que le repartitionnement soit judicieux et l'emplacement des données efficace.
La combinaison des clés de clustering avec l'optimisation du prédicat pushdown de Snowflake peut rendre la navigation dans les grands tableaux beaucoup plus efficace.
L'utilisation des ressources dans un système de paiement à l'utilisation tel que Snowflake est essentielle. Il est important de respecter quelques principes simples :
auto-suspend de Snowflake pour suspendre les entrepôts lorsque vos pipelines sont hors ligne pendant une période prolongée.auto-resume vous permettra de redémarrer l'entrepôt si nécessaire.Ces ajustements simples de l'entrepôt rendront votre utilisation de Snowflake plus efficace à long terme.
Du côté dbt, nous pouvons exploiter les tableaux dynamiques et les modèles incrémentiels pour simplifier la logique de mise à jour.
Les tableaux dynamiques sont un type de tableau Snowflake qui se rafraîchit automatiquement en fonction des délais définis. dbt a la capacité de matérialiser des tableaux dynamiques dans le cadre de sa configuration et de les configurer de la même manière que dans Snowflake.
models:
<resource-path>:
+materialized: dynamic_table
+on_configuration_change: apply | continue | fail
+target_lag: downstream | <time-delta>
+snowflake_warehouse: <warehouse-name>
+refresh_mode: AUTO | FULL | INCREMENTAL
+initialize: ON_CREATE | ON_SCHEDULECeci est pratique pour disposer de pipelines de transfert de données simples qui ne nécessitent pas de SQL complexe. Le plus grand avantage est que nous pouvons nous connecter à ces tableaux dynamiques et disposer de données actualisées selon nos besoins.
Une autre méthode flexible pour créer des tableaux consiste à utiliser le modèle incrémental. Lors de la rédaction de notre SQL, nous filtrons sur une colonne qui nous permet de déterminer quelles données sont nouvelles. Ensuite, nous utilisons la macro ` is_incremental() ` pour indiquer à dbt de n'utiliser ce filtre que lorsque nous configurons un tableau incrémentiel matérialisé.
Votre exemple de SQL pourrait ressembler à ceci, d'après la documentation DBT : documentation dbt:
{{
config(
materialized='incremental'
)
}}
select
*,
my_slow_function(my_column)
from {{ ref('app_data_events') }}
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
-- (uses >= to include records whose timestamp occurred since the last run of this model)
-- (If event_time is NULL or the table is truncated, the condition will always be true and load all records)
where event_time >= (select coalesce(max(event_time),'1900-01-01') from {{ this }} )
{% endif %}Vous m'avez entendu faire référence à un concept appelé « macro ». Il s'agit de fragments de code réutilisables dans dbt. Il peut s'agir de calculs qui sont réutilisés ou de transformations qui se produisent fréquemment.
Nous créons des macros à l'aide du système de modèles Jinja. Un cas d'utilisation courant peut être de cloner des bases de données avant de les manipuler.
{% macro clone_tables(table_to_clone) -%}
–- shows all tables within a schema
{% set all_tables_query %}
show tables in schema {{ clone_tables }}
{% endset %}
-- take the set results and use the run_query macro
{% set results = run_query(all_tables_query) %}
{{ "create or replace schema " ~ generate_schema_name(var("custom_tables_list")) ~ ";" }}
--execute the cloning function
{% if execute %}
{% for result_row in results %}
{{ log("create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";") }}
{{ "create table " ~ generate_schema_name(var("custom_tables_list")) ~ "." ~ result_row[1] ~ " clone " ~ clone_tables~ "." ~ result_row[1] ~ ";" }}
{% endfor %}
{% endif %}
{%- endmacro %}Ce modèle utilise un schéma fourni, génère une liste de tableaux, puis les clone vers l'entrepôt/schéma spécifié dans votre configuration dbt. Vous pouvez ensuite utiliser cette macro dans votre code dbt ou lors du démarrage de dbt.
Pour approfondir vos connaissances de Jinja dans dbt, je vous recommande vivement cette étude de cas sur la création de modèles de données e-commerce avec dbt. étude de cas sur la création de modèles de données e-commerce avec dbt. Il vous guide à travers certains modèles Jinja complexes avec dbt et vous permet d'acquérir une expérience pratique assez avancée.
Dans le cadre de notre travail avec les informations clients, il est possible que nous ayons accès à des informations personnelles identifiables (PII) et que nous devions les masquer dans notre base de données. C'est très simple à réaliser avec Snowflake. Nous pouvons utiliser CREATE MASKING POLICY pour indiquer à Snowflake quelles colonnes et quels types de données doivent être masqués lors de l'exécution des requêtes. Ces politiques garantissent qu'aucune information personnelle identifiable n'est divulguée lors de la recherche d'informations sensibles.
Nous pouvons ensuite utiliser l'tests e dbt avec un SQL personnalisé qui vérifie que les tableaux sont correctement masqués. Par exemple, si nous définissons une politique de masquage qui autorise uniquement le rôle ANALYST à consulter les informations personnelles identifiables, comme suit :
CREATE OR REPLACE MASKING POLICY email_mask AS (val string) returns string ->
CASE
WHEN current_role() IN ('ANALYST') THEN VAL
ELSE '*********'
END;Ensuite, en utilisant notre rôle utilisateur dbt_account pour interroger les données, nous devrions obtenir une chaîne de caractères '*********'.
Si notre test effectue une opération simple telle que :
SELECT *
FROM schema.table
WHERE email <> '*********'Si ce test renvoie des résultats, il doit être considéré comme un échec. Aucun e-mail ne devrait être renvoyé sous une forme autre que la chaîne masquée. Nous devrions ensuite vérifier la politique de masquage sur Snowflake et continuer à effectuer des tests jusqu'à ce qu'elle fonctionne correctement.
Comme toujours, la sécurité est un pilier essentiel de l'accès au cloud. Dans cette section, nous aborderons quelques notions fondamentales relatives à la sécurité et à la protection des données.
Le principal cadre de sécurité de Snowflake repose sur le contrôle d'accès basé sur les rôles (RBAC) et l'utilisation de comptes de service.
La définition des privilèges RBAC nous permet d'appliquer des paramètres de sécurité à un large groupe d'utilisateurs sans avoir à les attribuer manuellement à chacun d'entre eux. Cela facilite la maintenance.
Comme indiqué précédemment, nous créons des rôles à l'aide de l'instruction ` CREATE ROLE `. Pour accorder des autorisations, nous utilisons GRANT … TO ROLE et, de même, pour les supprimer, nous utilisons REVOKE … FROM ROLE.
Voici quelques bonnes pratiques :
dbt_reader, l'accès à la création de tableaux à dbt_writer et l'accès à la suppression uniquement à un compte administrateur tel que dbt_admin.Les comptes de service sont des comptes spéciaux basés sur des machines qui interagissent sans intervention humaine. Ces comptes ne disposent pas de noms d'utilisateur ni de mots de passe. Au lieu de cela, ils utilisent des clés publiques et des restrictions réseau pour minimiser les risques.
La création d'un compte de service pourrait ressembler à ceci :
CREATE USER dbt_service
RSA_PUBLIC_KEY = <keysring>De cette manière, vous disposez d'un compte unique géré par les administrateurs et vous n'avez plus à vous soucier des utilisateurs individuels. Il est recommandé de changer régulièrement les clés afin d'éviter toute fuite. De plus, veuillez surveiller attentivement l'activité réseau à l'aide de l'outil Snowflake LOGIN_HISTORY.
Veuillez protéger vos données et vos identifiants de connexion. Bien que nous ayons codé en dur nos identifiants à titre d'exemple, il s'agit en réalité d'une pratique peu recommandée. Veuillez utiliser des gestionnaires de secrets tels qu'AWS Secrets Manager ou GitHub Secrets pour conserver les informations d'identification importantes.
Ces derniers vous permettent de stocker en ligne des informations d'identification qui ne sont accessibles qu'aux utilisateurs disposant des clés RSA/Security appropriées. Personne ne peut voir la valeur réelle et la rotation des mots de passe/clés est simplifiée grâce à leur gestion automatisée.
Veuillez vous assurer que toutes les connexions sont correctement sécurisées et que les utilisateurs se trouvent sur le réseau d'entreprise approprié pour accéder aux données. Cela est généralement mis en place à l'aide de VPN tels que GlobalProtect. Étant donné que nous nous connectons à Snowflake, une grande partie du chiffrement de bout en bout est gérée par le cloud. Un autre avantage d'être sur Snowflake !
Enfin, nous souhaitons procéder à un audit de nos activités. Snowflake dispose d'un système de journalisation des requêtes via des tableaux tels que QUERY_HISTORY et QUERY_HISTORY_BY_USER. Nous pouvons surveiller l'utilisation, les erreurs et tout abus de sécurité dans ces journaux. Grâce à dbt, nous pouvons suivre le cursus des nouvelles exécutions, des modifications ou des corrections apportées aux projets en utilisant nos pipelines de contrôle de version.
Le contrôle de version et les modèles de codage facilitent le suivi du cursus des modifications et la conformité. Tout problème introduit par les modifications peut être facilement détecté lors des demandes d'extraction obligatoires et résolu avant qu'il ne devienne préoccupant.
Discutons des moyens de réaliser des économies. Dans dbt, bien entendu. Il est essentiel de surveiller les performances de notre modèle. Les modèles qui fonctionnaient auparavant sans problème peuvent facilement devenir plus lents et moins performants à mesure que la taille des tableaux augmente.
Avec dbt, la meilleure façon de surveiller les performances consiste à utiliser des packages intégrés tels qu'dbt-snowflake-monitoring, ou des outils externes tels que Looker et Datafold pour faciliter la visualisation et la comparaison des données.
Il est très facile de commencer à utiliser dbt-snowflake-monitoring. Dans votre fichier dbt packages.yml, veuillez ajouter ce qui suit :
packages:
- package: get-select/dbt_snowflake_monitoring
version: [">=5.0.0", "<6.0.0"] # We'll never make a breaking change without creating a new major version.Ensuite, dans le fichier YAML de chaque projet, veuillez ajouter ce qui suit :
dispatch:
- macro_namespace: dbt
search_order:
- <YOUR_PROJECT_NAME>
- dbt_snowflake_monitoring
- dbt
query-comment:
comment: '{{ dbt_snowflake_monitoring.get_query_comment(node) }}'
append: true # Snowflake removes prefixed comments.Vous êtes désormais prêt à utiliser le package pour surveiller des éléments tels que l'utilisation de votre entrepôt, la durée des requêtes et les modèles défaillants. Il utilise l'accès existant de votre utilisateur dbt pour écrire des tableaux dans Snowflake, qui contiennent des informations utiles. Par exemple, si je souhaitais consulter mes dépenses mensuelles liées à l'entrepôt, je pourrais utiliser le code SQL suivant :
select
date_trunc(month, date)::date as month,
warehouse_name,
sum(spend_net_cloud_services) as spend
from daily_spend
where service in ('Compute', 'Cloud Services')
group by 1, 2Des outils externes tels que Looker ou Tableau peuvent être directement intégrés à dbt pour faciliter la visualisation des données et des performances. Pour les alertes, dbt peut envoyer des e-mails ou des notifications Slack.
Pour des comparaisons plus approfondies, des piles externes telles que Datafold offrent un aperçu plus détaillé de l'impact des changements sur la qualité des données. Datafold automatise les comparaisons de données à chaque modification de code que vous effectuez. Cela permet aux autres membres de l'équipe d'examiner facilement votre code et l'impact qu'il aura sur les données. Ce type de tests de régression automatisés nous permet de maintenir la qualité des données sans devoir constamment créer de nouveaux contrôles et outils.
Nous ne pouvons pas éviter d'exécuter nos processus ETL, mais nous pouvons certainement planifier à l'avance afin de minimiser l'impact financier du calcul et du stockage. Grâce à la conception divisée de Snowflake, nous pouvons optimiser nos entrepôts et notre stockage séparément afin d'offrir un environnement plus flexible et optimisé en termes de coûts.
Pour les entrepôts, la meilleure approche consiste à réduire au minimum les temps d'inactivité. Répartissez autant que possible vos pipelines automatisés afin de réduire les temps d'inactivité, les pics de besoins informatiques et les conflits entre les ressources.
Veuillez surveiller régulièrement l'utilisation des ressources à l'aide des tableaux disponibles aux adresses WAREHOUSE_LOAD_HISTORY et QUERY_HISTORY afin de mieux comprendre comment elles sont utilisées. Il est recommandé de commencer par XS. Si les requêtes s'exécutent trop lentement, il est temps de procéder à une mise à niveau en fonction du SLA de votre équipe.
En matière de stockage, la meilleure pratique consiste à éliminer les tableaux inutiles. Bien que Snowflake ne dispose pas en soi de niveaux de stockage à faible activité comme AWS et Google, il est possible de transférer vos données de Snowflake vers AWS/Google pour ces niveaux de stockage à faible activité et ainsi réduire les coûts de stockage.
Les politiques de conservation des données peuvent définir clairement un calendrier pour les tableaux rarement utilisés et déterminer quand ils seront transférés vers un stockage à froid.
Pour les tableaux volumineux qui augmentent fréquemment, veuillez les surveiller de près. À mesure qu'ils deviennent plus volumineux, la capacité de Snowflake à partitionner automatiquement et efficacement diminue. Veuillez tirer parti du regroupement automatique mentionné ci-dessus pour aider Snowflake à mieux partitionner vos données. De meilleures partitions permettent de réduire le temps de lecture du stockage et donc de réaliser des économies.
Grâce à l'intégration native de dbt avec le contrôle de version, le CI/CD et les pipelines automatisés sont simplifiés. Nous aborderons certaines options d'orchestration automatisée et les meilleures pratiques en matière de tests.
Avec dbt Cloud, nous pouvons utiliser Snowflake Tasks pour déclencher l'exécution planifiée de nos projets dbt. Le processus consiste à créer d'abord un projet dbt dans Snowflake à l'aide de notre référentiel Git, puis à créer une tâche qui exécute ce projet dbt.
Par exemple, nous pourrions procéder comme suit pour créer un projet dbt :
CREATE DBT PROJECT sales_db.dbt_projects_schema.sales_model
FROM '@sales_db.integrations_schema.sales_dbt_git_stage/branches/main'
COMMENT = 'generates sales data models';Ensuite, nous utilisons le code suivant pour exécuter ce projet :
CREATE OR ALTER TASK sales_db.dbt_projects_schema.run_dbt_project
WAREHOUSE = sales_warehouse
SCHEDULE = '6 hours'
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.sales_model args='run --target prod';En réalité, il est si complet que nous pouvons même effectuer des tests a posteriori pour nous assurer que le projet s'est déroulé correctement :
CREATE OR ALTER TASK sales_db.dbt_projects_schema.test_dbt_project
WAREHOUSE = sales_warehouse
AFTER run_dbt_project
AS
EXECUTE DBT PROJECT sales_db.dbt_projects_schema.test_dbt_project args='test --target prod';Pour la planification, nous avons la possibilité de définir une heure fixe, comme 60 MINUTES et 12 HOURS, ou d'utiliser cron, comme USING CRON 0 9 * * * UTC.
Nos modèles restent toutefois rarement statiques, et nous devons souvent les réviser. La construction manuelle de chaque élément de notre pipeline peut prendre beaucoup de temps. C'est là que GitHub Actions intervient. Nous utilisons fréquemment GitHub Actions dans les pipelines CI/CD afin d'automatiser les tests et la compilation du code.
Les actions GitHub sont conçues à l'aide de fichiers YAML situés dans le dossier « .github/workflows » du référentiel. Nous pouvons les déclencher à chaque fois que nous effectuons une demande de modification, de manière à exécuter certains tests dbt.
name: dbt pull test
# CRON job to run dbt at midnight UTC(!) everyday
on:
pull_request:
types:
openedreopened
# Setting some Env variables to work with profiles.yml
# This should be your snowflake secrets
env:
DBT_PROFILE_TARGET: prod
DBT_PROFILE_USER: ${{ secrets.DBT_PROFILE_USER }}
DBT_PROFILE_PASSWORD: ${{ secrets.DBT_PROFILE_PASSWORD }}
jobs:
dbt_run:
name: dbt testing on pull request
runs-on: ubuntu-latest
timeout-minutes: 90
# Steps of the workflow:
steps:
- name: Setup Python environment
uses: actions/setup-python@v4
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
python -m pip install -r requirements.txt
- name: Install dbt packages
run: dbt deps
# optionally use this parameter
# to set a main directory of dbt project:
# working-directory: ./my_dbt_project
- name: Run tests
run: dbt test
# working-directory: ./my_dbt_projectConfigurer correctement vos automatisations peut vous faciliter considérablement la vie et aider d'autres développeurs à consulter vos modèles testés. Cela permet de rationaliser le processus de développement en réduisant le besoin de tests manuels.
dbt est fourni avec une suite de tests performante. Il est fourni avec quelques tests de données génériques prêts à l'emploi qui peuvent être configurés directement sur votre modèle et permettent une logique SQL personnalisée. Les tests génériques sont définis sur des colonnes spécifiques de votre modèle et vérifient si ces colonnes spécifiques satisfont au test. Les tests prêts à l'emploi sont les suivants :
unique: chaque valeur de cette colonne doit être unique.not_null: il ne devrait y avoir aucune valeur nulle dans la colonne.accepted_values: vérifie si les valeurs figurent dans une liste de valeurs acceptéesrelationships: vérifie si les valeurs de cette colonne sont présentes dans un autre tableau associé.Voici un exemple d'utilisation de ces relations (extrait de la documentation dbt sur les tests) :
version: 2
models:
- name: orders
columns:
- name: order_id
data_tests:
# makes sure this column is unique and has no nulls
- unique
- not_null
- name: status
data_tests:
#makes sure this column only has the below values
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
data_tests:
# makes sure that the customer ids in this column are ids in the customers table
- relationships:
to: ref('customers')
field: idNous pouvons utiliser du SQL personnalisé pour créer des tests plus spécifiques et génériques. L'objectif ici est que les tests renvoient des lignesd'échec . Par conséquent, si des résultats apparaissent, le test est considéré comme ayant échoué. Ces fichiers SQL personnalisés se trouvent dans notre répertoire tests.
Par exemple, si nous souhaitions déterminer si certaines ventes étaient négatives, nous pourrions utiliser ce qui suit :
select
order_id,
sum(amount) as total_amount
from {{ ref('sales') }}
group by 1
having total_amount < 0Nous ferions ensuite référence à ce test dans notre fichier schema.yml situé dans notre dossier de test :
version: 2
data_tests:
- name: assert_sales_amount_is_positive
description: >
Sales should always be positive and are not inclusive of refunds
Si nous souhaitions appliquer ce type de vérification à davantage de tableaux et de colonnes, nous pourrions envisager de transformer cela en un test générique. Cela pourrait ressembler à ceci :
{% test negative_values(model, group,sum_column) %}
select {{group}},
sum({{sum_column}}) as total_amt
from {{ model }}
group by 1
having total_amt < 0
{% endtest %}Nous pouvons désormais utiliser ce test dans le fichier YAML de nos modèles, tout comme les autres tests génériques fournis par dbt. Vous pourriez vérifier s'il y a des passagers négatifs lors d'un voyage ou des bénéfices négatifs, etc. Les possibilités sont infinies.
Afin de rendre ces tests plus fluides et plus simples, nous pouvons tirer parti du clonage sans copie de Snowflake. Ensuite, tous vos tests et votre intégration continue peuvent être effectués sur l'objet cloné. L'avantage est que nous n'avons pas besoin d'espace de stockage supplémentaire pour disposer d'un environnement de test sécurisé. De plus, lorsque nous avons besoin de plus d'espace de test, nous pouvons créer davantage d'environnements de test grâce à ce clonage instantané. Examinons les améliorations et les tendances futures proposées par dbt et Snowflake. dbt améliore constamment son intégration tant avec son produit phare qu'avec l'IA. Dans Snowflake, nous pouvons utiliser Snowsight comme interface utilisateur pour faciliter la gestion de nos espaces de travail dbt. En nous intégrant de manière plus transparente à notre environnement Snowflake, nous réduisons au minimum la nécessité de travailler sur des modèles dbt en externe. Au lieu de cela, nous pouvons centraliser nos flux de travail en permettant aux équipes de modifier et de collaborer via l'interface utilisateur de Snowflake. Afin d'accélérer le développement, dbt propose un assistant alimenté par l'intelligence artificielle appelé dbt Copilot. Cet assistant est accessible via l'IDE dbt Studio, Canvas ou Insights et utilise le traitement du langage naturel pour accélérer les étapes les plus chronophages du développement de modèles, telles que la rédaction de documentation et la création de tests. Le dbt Copilot peut également être utilisé pour faciliter l'intégration de nouveaux analystes en leur fournissant des résumés concis des projets et des modèles. Utilisez ces deux outils pour accélérer votre mise en production et réduire le temps de développement, permettant ainsi à votre équipe de s'attaquer aux problèmes de données les plus complexes et les plus difficiles au sein de votre organisation. Les pipelines d'apprentissage automatique nécessitent des données cohérentes, propres et bien conçues. dbt est l'outil idéal pour les pipelines de transformation de données qui alimentent les modèles d'apprentissage automatique. Nous pouvons tirer parti de la flexibilité et de la puissance de dbt pour automatiser les transformations de données qui s'intègrent de manière transparente dans nos pipelines d'apprentissage automatique. Par exemple, nous pouvons convertir nos données directement en un entrepôt d'apprentissage automatique. Ces données peuvent ensuite être utilisées avec l'IA Cortex de Snowflake pour obtenir des informations plus approfondies. Si nous disposons de plusieurs modèles nécessitant des transformations similaires, les modèles de dbt peuvent simplifier la manière dont nous nettoyons nos données et offrir une plus grande cohérence et une gouvernance des données plus facile. Pour mieux comprendre les outils d'IA de Snowflake, je vous invite à consulter ce guide sur Snowflake Arctic. nous vous invitons à consulter ce guide sur Snowflake Arctic, qui est le LLM de Snowflake. Grâce à la prise en charge native de Python par Snowflake et à l'API Snowpark pour Python, nous pouvons exécuter du code localement sans avoir à déplacer les données hors de Snowflake. L'étape suivante consiste à utiliser Snowpark Containers, qui n'est actuellement (à la date de rédaction) disponible que dans les régions AWS et Azure, pour exécuter notre code dbt de manière totalement isolée. Pour ce faire, nous intégrons nos modèles et notre environnement dbt dans un conteneur, qui est ensuite stocké dans le référentiel d'images de Snowflake. Nous pouvons ensuite utiliser facilement ce projet dbt conteneurisé dans Snowpark. Quel est le principal avantage ? La possibilité d'utiliser plus facilement les ressources de Snowflake pour les transformations de données complexes basées sur Python et l'intégration des transformations dbt dans l'environnement Snowflake plus large. Si vous souhaitez en savoir plus sur Snowpark, veuillez consulter ces informations qui décrivent en détail le Snowpark Snowflake. Snowflake Snowpark en détail. L'intégration de dbt à Snowflake permet aux équipes chargées des données de créer des pipelines de transformation modulaires, contrôlés et évolutifs. Grâce à des fonctionnalités telles que les tests automatisés, les workflows CI/CD basés sur Git et une évolutivité transparente, cette pile est idéale pour les opérations de données modernes. Pour rester compétitives, les équipes chargées des données doivent établir les priorités suivantes : À mesure que ces deux outils continuent de se développer, l'intégration dbt + Snowflake ne fera que gagner en puissance pour les équipes d'ingénierie des données. Si vous souhaitez en savoir plus sur dbt ou Snowflake, veuillez consulter les ressources suivantes :CREATE TABLE CLONE , de Snowflake, permet de créer un clone sans copie dans votre environnement de développement/test.
Tendances émergentes et perspectives d'avenir
Développements d'intégration native
Intégration de l'apprentissage automatique
Exécution conteneurisée
Conclusion
Meilleurs cours DataCamp
Cursus
Cursus
Cours