

Cours
Machine learning avec des modèles arborescents en Python
5 h
116.5K
Dans cette brève section, je vous montrerai comment installer les dépendances à l'échelle du système et les bibliothèques Python nécessaires à la visualisation des modèles d'apprentissage automatique.
La seule dépendance du système dont vous aurez besoin pour suivre le processus est Graphviz. Vous l'utiliserez plus tard pour visualiser un arbre de décision, et le code ne fonctionnera pas si Graphviz n'est pas installé.
Il s'agit d'un logiciel libre utilisé pour créer des diagrammes, des graphiques abstraits et des réseaux. Vous ne l'utiliserez pas directement, mais uniquement par l'intermédiaire de scikit-Learn.
Cette bibliothèque Python est largement utilisée pour les tâches d'apprentissage automatique en Python.
Dans cet article, vous l'utiliserez pour entraîner des modèles d'apprentissage automatique, diviser des ensembles de données, mettre à l'échelle des caractéristiques numériques et visualiser les performances des modèles. C'est un incontournable, alors installez-le avec la commande suivante (en fonction de votre environnement Python) :
pip install scikit-learn
conda install scikit-learnSi vous êtes totalement novice en matière de scikit-learn, nous vous recommandons de suivre notre très populaire sur l'apprentissage automatique supervisé.
La bibliothèque SHAP en Python est un outil populaire pour expliquer les prédictions des modèles d'apprentissage automatique. Il s'appuie sur les concepts de la théorie des jeux (par exemple, Shapely values) pour mesurer la contribution de chaque attribut à la prédiction du modèle.
Mieux encore, il regorge de visualisations utiles qui vous aident à comprendre le fonctionnement interne de vos modèles.
Installez-le à l'aide de la commande suivante :
pip install shap
conda install -c conda-forge shapCette bibliothèque Python est utilisée par de nombreuses personnes lorsqu'il est crucial d'expliquer la prédiction d'un modèle unique. Il fonctionne différemment de SHAP. Il s'agit d'une approximation locale du modèle original à l'aide d'un modèle plus simple et plus facile à interpréter. Il montre ensuite la contribution de chaque caractéristique de l'ensemble de données à la prédiction.
Vous verrez comment LIME fonctionne dans une minute, mais d'abord, installez-le :
pip install lime
conda install conda-forge::limeSi vous construisez des modèles de réseaux neuronaux avec TensorFlow, TensorBoard est une évidence.
C'est un outil de visualisation qui vous aide à suivre les expériences d'apprentissage automatique et à surveiller les métriques de formation (par exemple, la perte et la précision). Il visualise et met à jour pour vous les graphiques du modèle en temps réel et montre comment les paramètres du modèle changent pendant l'entraînement.
TensorBoard peut être utilisé avec d'autres frameworks d'apprentissage profond comme PyTorch, mais je me concentrerai sur TensorFlow dans cet article.
Installez-le en exécutant la commande suivante :
pip install tensorboard
conda install -c conda-forge tensorboardLa dernière étape de cette phase de préparation consiste à s'occuper des données.
J'utiliserai deux ensembles de données aujourd'hui : Admissions au MBA pour la classification et Assurance pour la régression. Les deux sont gratuits et peuvent être téléchargés sur Kaggle.
Pour commencer, importez ces bibliothèques Python :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitEn ce qui concerne l'ensemble de données de classification, le prétraitement des données que j'ai effectué est minime. La question se résume à ceci :
Il ne s'agit en aucun cas d'un pipeline complet de prétraitement des données. Si vous avez le temps, n'hésitez pas à l'améliorer.
Néanmoins, copiez cette fonction pour mettre de l'ordre dans l'ensemble des données de classification :
def load_classification_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/taweilo/mba-admission-dataset?resource=download
df = pd.read_csv("MBA.csv")
# Just an arbitrary ID
df = df.drop(["application_id"], axis=1)
# Fill unknown
df["race"] = df["race"].fillna("Unknown")
# Assume these are denied
df["admission"] = df["admission"].fillna("Deny")
# Convert boolean cols to 0/1
df["gender"] = df["gender"].replace({"Male": 0, "Female": 1})
df["international"] = df["international"].replace({False: 0, True: 1})
# Create dummy columns for categorical features
cols_for_dummy = ["major", "race", "work_industry"]
for col in cols_for_dummy:
dummies = pd.get_dummies(df[col], prefix=col)
df = pd.concat([df, dummies], axis=1)
# To drop
cols_to_drop = ["major", "race", "work_industry", "major_Humanities", "race_Unknown", "work_industry_Other"]
df = df.drop(cols_to_drop, axis=1)
return df
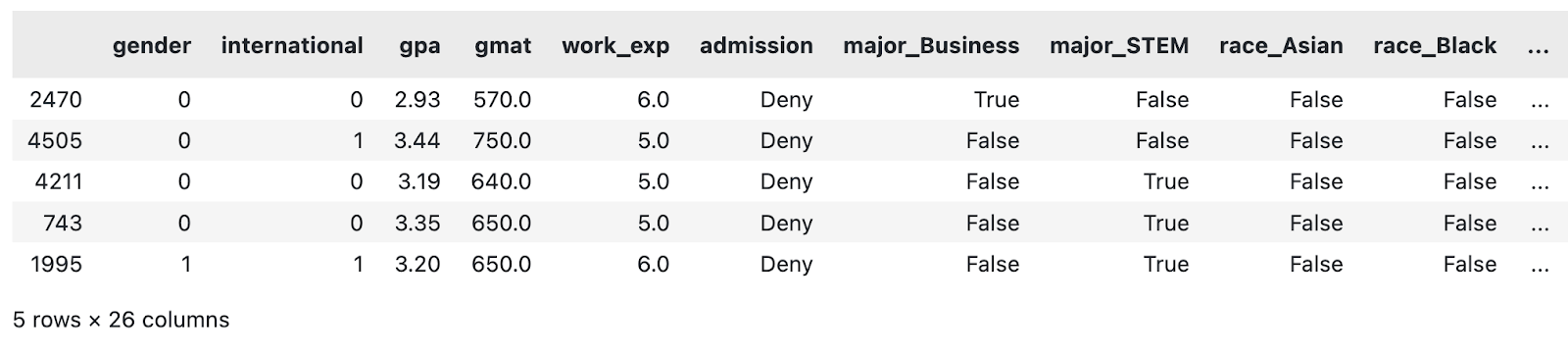
load_classification_dataset().sample(5)
Un échantillon de l'ensemble de données MBA modifié. Image par l'auteur.
Je vais maintenant faire la même chose pour l'ensemble de données de régression.
L'ensemble de données de régression choisi contient un montant d'assurance ($) en tant que caractéristique continue que le modèle d'apprentissage automatique tentera de prédire en fonction d'autres attributs.
Le prétraitement des données que j'ai effectué est, une fois de plus, relativement minime. La question se résume à ceci :
Si vous avez le temps, n'hésitez pas à ajouter d'autres étapes à la filière.
Copiez la fonction suivante pour charger et prétraiter l'ensemble de données d'assurance :
def load_regression_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/mirichoi0218/insurance
df = pd.read_csv("MedicalCostPersonal.csv")
# Scale numerical features
cols_to_scale = ["age", "bmi", "children"]
scaler = StandardScaler()
df[cols_to_scale] = scaler.fit_transform(df[cols_to_scale])
# Binary features
df["sex"] = df["sex"].replace({"male": 0, "female": 1})
df["smoker"] = df["smoker"].replace({"no": 0, "yes": 1})
# Dummies
dummies_region = pd.get_dummies(df["region"], prefix="region", drop_first=True)
df = pd.concat([df, dummies_region], axis=1)
df = df.drop("region", axis=1)
return df
load_regression_dataset().sample(5)
Un échantillon de l'ensemble de données modifié sur les assurances. Image par l'auteur.
Et c'est tout !
Dans la section suivante, je vous montrerai comment commencer à visualiser les modèles d'apprentissage automatique.
Les modèles à base d'arbres sont souvent utilisés pour la classification, mais la plupart d'entre eux peuvent également traiter des tâches de régression.
Dans cette section, je vous montrerai comment visualiser un arbre de décision, l'importance des caractéristiques d'un modèle de forêt aléatoire, et les explications de prédiction avec SHAP et LIME.
Gardez à l'esprit que les modèles d'arbres de décision et de forêts aléatoires peuvent être difficiles à comprendre. Nous avons un cours complet qui couvre les fondamentauxmentaux des modèles d'apprentissage automatique basés sur les arbres en Python.
Pour commencer, chargez l'ensemble de données de classification et divisez-le en sous-ensembles d'entraînement et de test :
df = load_classification_dataset()
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)Visualisons maintenant un arbre de décision !
Considérez un arbre de décision comme un ensemble d'instructions imbriquées if dans lesquelles les conditions sont déterminées par un modèle d'apprentissage automatique.
L'histoire ne s'arrête pas là, mais cette analogie vous permet de comprendre que la visualisation des décisions devrait être un processus simple. Et c'est le cas : la fonction plot_tree() de sklearn s'occupe de la plupart des tâches lourdes.
Commencez par former un modèle d'arbre de décision. Le paramètre max_depth est facultatif et n'est utilisé qu'à des fins de visualisation. Sans cela, l'arbre deviendra trop profond et vous vous perdrez dans le volume des décisions prises par le modèle, en particulier pour les grands ensembles de données.
L'extrait suivant entraîne le modèle de classification par arbre de décision sur le sous-ensemble d'apprentissage :
from sklearn import tree
decision_tree = tree.DecisionTreeClassifier(random_state=42, max_depth=4)
decision_tree.fit(X_train, y_train)Et pour la visualisation, copiez simplement l'extrait suivant. Les paramètres optionnels filled et feature_names facilitent l'interprétation de l'arbre :
plt.figure(figsize=(12,8))
tree.plot_tree(decision_tree, filled=True, feature_names=X.columns, class_names=y.unique())
plt.title("Decision Tree Visualization", size=20, loc="left", y=1.04, weight="bold")
plt.show()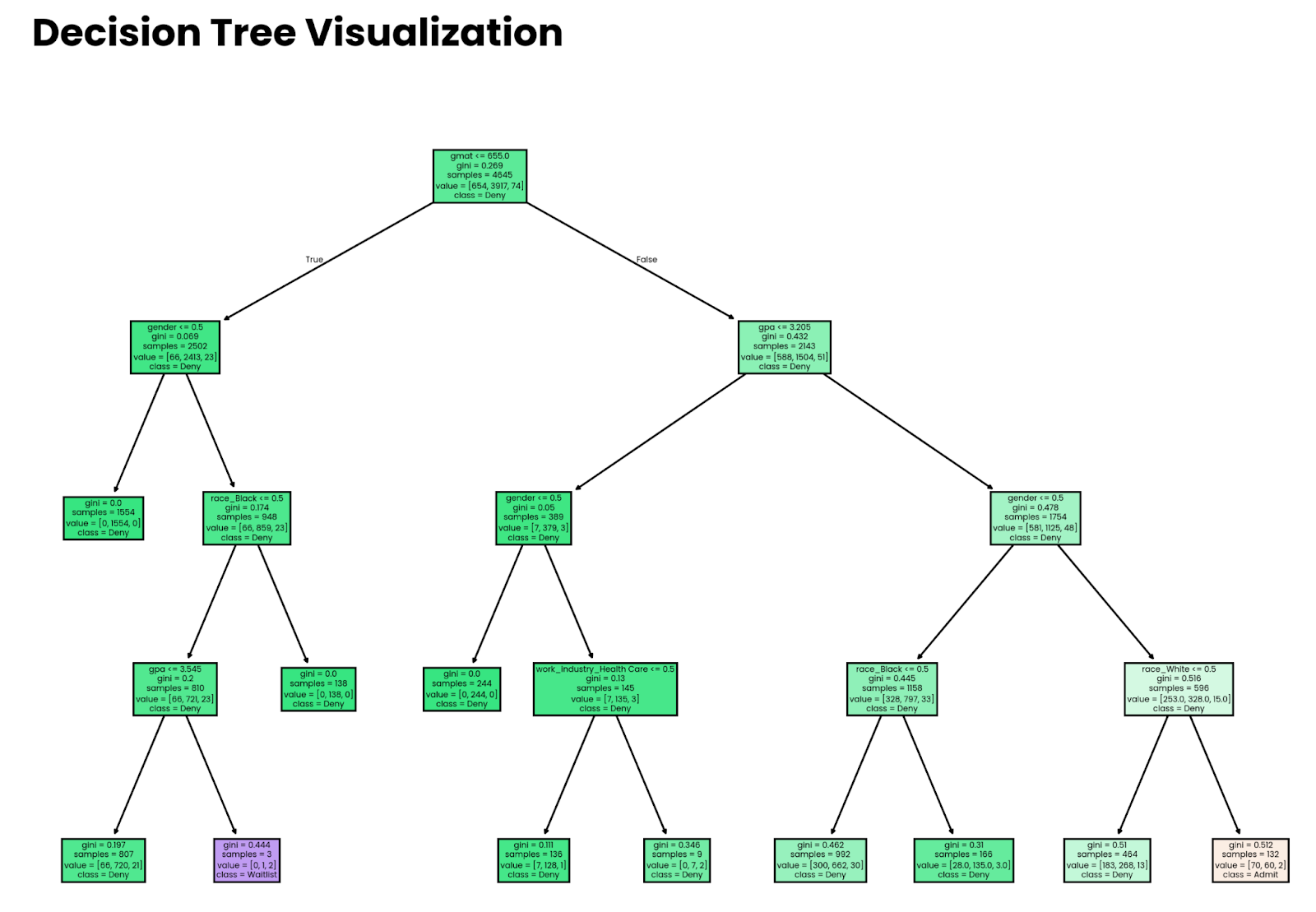
Arbre de décision profond à quatre niveaux. Image par l'auteur.
Notez que les décisions prises par le modèle ne signifient rien si le modèle n'est pas précis. Plus loin dans l'article, je vous montrerai comment estimer la précision.
Vous vous souvenez de l'analogie avec le gâteau de tout à l'heure ? Il est temps de le mettre en pratique.
Chaque fois que vous entraînez un modèle d'arbre avec sklearn, vous avez accès à la propriété feature_importances_. Associez-les aux noms des caractéristiques et vous disposez de toutes les données nécessaires pour déterminer les attributs qui contribuent le plus à la prédiction.
Voyons-le en action ! Commencez par former un classificateur de forêt aléatoire sur le sous-ensemble d'apprentissage :
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)La visualisation se résume maintenant à extraire et trier les importances des caractéristiques et à remplacer les indices par des noms d'entités :
importances = random_forest.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
bars = plt.bar(range(X.shape[1]), importances[indices], edgecolor="#008031", linewidth=1)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, height, f"{height:.2f}", ha="center", va="bottom", size=8)
plt.title("Feature Importances", size=20, loc="left", y=1.04, weight="bold")
plt.ylabel("Importance")
plt.xticks(range(X.shape[1]), np.array(X.columns)[indices], rotation=90, size=12)
plt.show()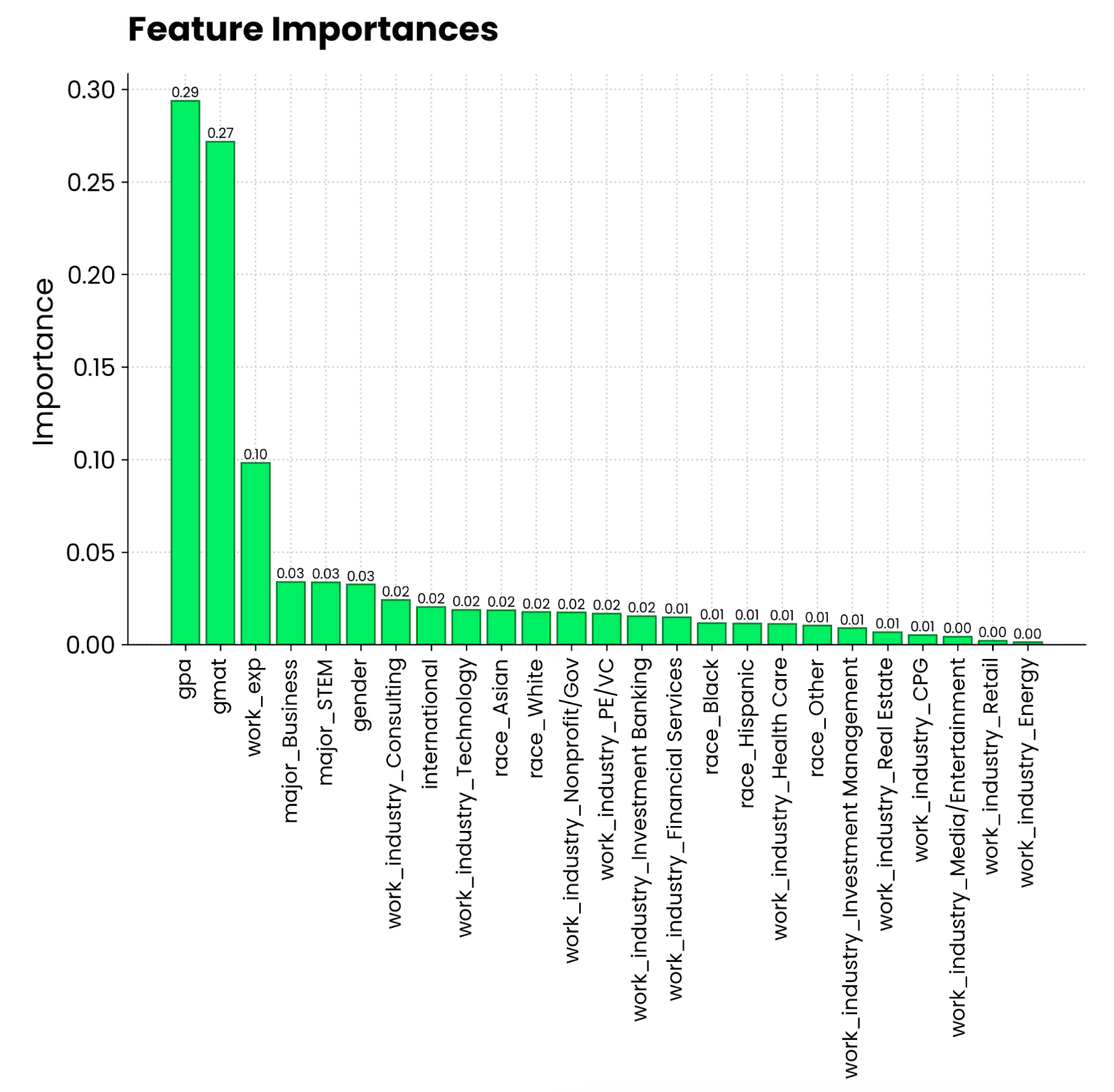
Graphique de l'importance des caractéristiques de la forêt aléatoire. Image par l'auteur.
Il semble que la moyenne générale sur une échelle de 4,0 et le score au GMAT contribuent le plus à l'admission dans un programme de MBA. Vient ensuite l'expérience professionnelle, qui est une condition préalable à l'obtention d'un MBA. La spécialité de la personne et le secteur d'activité dans lequel elle travaille sont beaucoup moins pertinents.
L'importance des caractéristiques donne une image globale, mais qu'en est-il si vous souhaitez visualiser les modèles d'apprentissage automatique au niveau de la prédiction individuelle ? prédiction individuelle?
C'est là que SHAP et LIME entrent en jeu. Je parlerai d'abord du SHAP. Vous savez déjà de quoi il s'agit, je ne vais donc pas m'étendre sur la théorie.
J'appliquerai un modèle de gradient de croissance à notre ensemble de données de régression pour voir l'impact des caractéristiques individuelles sur les frais d'assurance. L'extrait suivant vous montre comment ajuster le modèle et calculer les valeurs SHAP à partir d'un modèle shap.Explainer():
import shap
from xgboost import XGBRegressor
df = load_regression_dataset()
# No need for train-test splits
X = df.drop("charges", axis=1)
y = df["charges"]
model = XGBRegressor().fit(X, y)
# Shap explainer
explainer = shap.Explainer(model)
shap_values = explainer(X)Avec SHAP, vous disposez d'une série de tracés que vous pouvez réaliser.
Je commencerai par waterfall() et j'examinerai les valeurs SHAP pour la première prédiction :
shap.plots.waterfall(shap_values[0])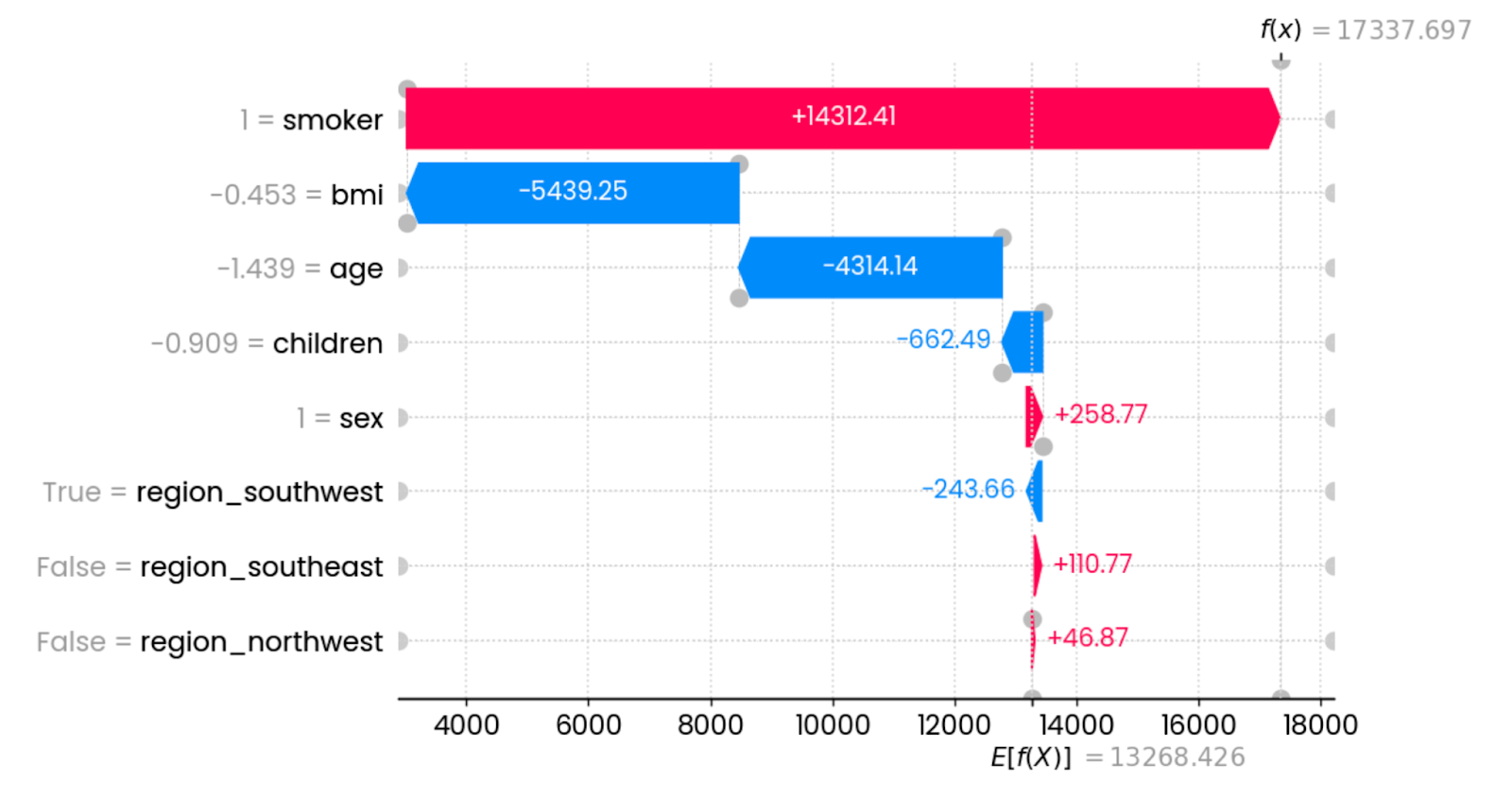
Explications de la première prédiction. Image par l'auteur.
Dans ce cas précis, le fait d'être fumeur augmente considérablement les frais d'assurance. Les caractéristiques qui ont le plus d'impact sur la réduction des frais sont l'IMC (lié au poids) et l'âge. D'autres caractéristiques ont un impact minime ou nul.
Vous pouvez représenter le graphique ci-dessus dans un format plus format plus compact:
shap.plots.force(shap_values[0])
Explications concises sur les premières prédictions. Image par l'auteur.
L'information reste la même : les éléments rouges augmentent les charges et les éléments bleus les réduisent. Le point de rencontre entre les deux indique les frais d'assurance pour un seul cas.
Le graphique beeswarm vous montre quelles sont les caractéristiques les plus importantes en traçant les valeurs SHAP de chaque caractéristique pour chaque échantillon. Les caractéristiques sont triées en fonction de la somme des valeurs SHAP de tous les échantillons. La couleur représente la valeur de la caractéristique (rouge signifiant élevée et bleu signifiant faible) :
shap.plots.beeswarm(shap_values)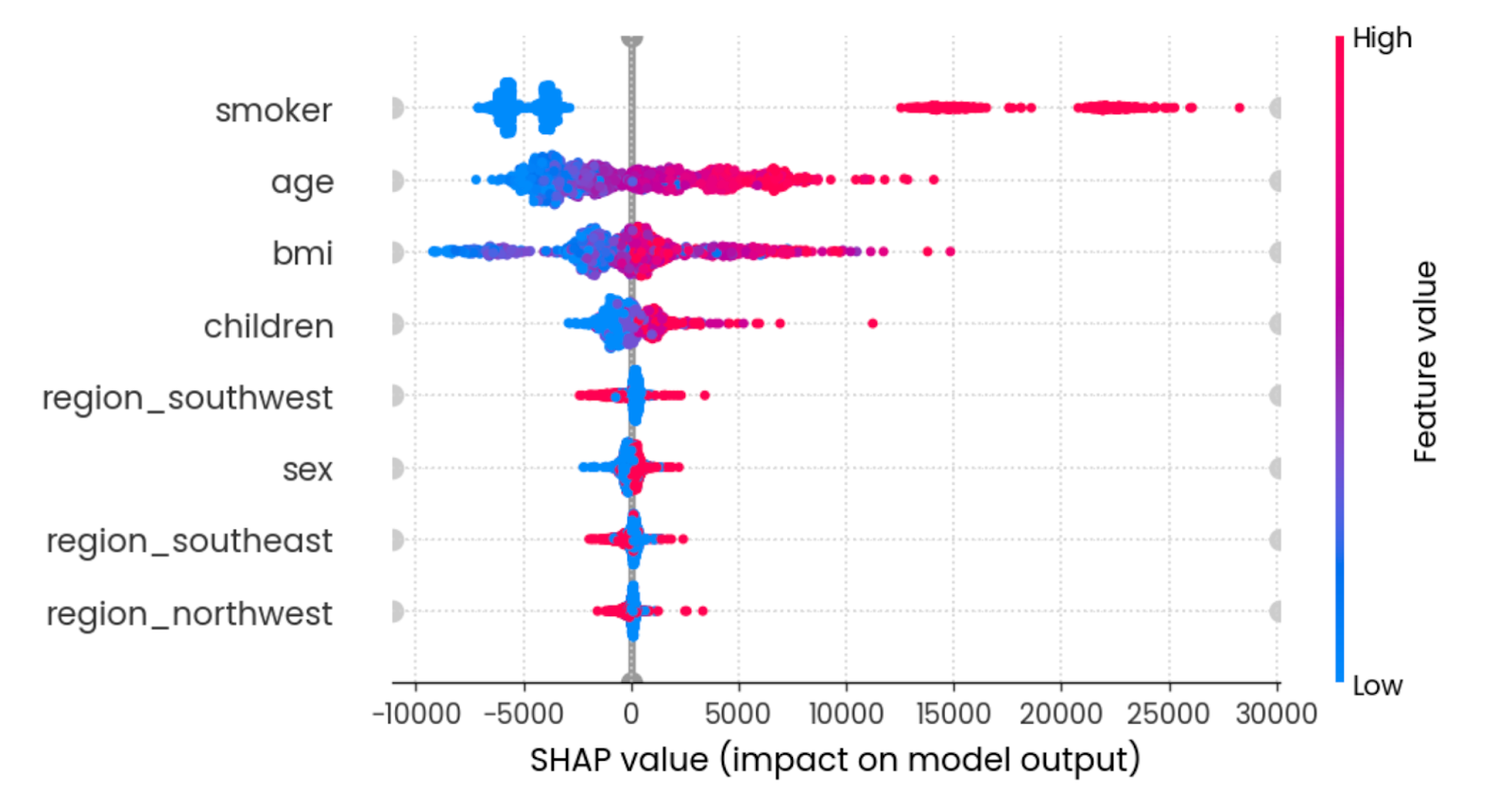
Effet récapitulatif de toutes les caractéristiques. Image par l'auteur.
Pour interpréter, le fait d'être un jeune non-fumeur avec un IMC raisonnable réduit les frais d'assurance.
La dernière visualisation SHAP que je souhaite montrer est le diagramme à barres dela valeur absolue moyenne . Il calcule la valeur absolue moyenne de toutes les valeurs SHAP pour chaque élément :
shap.plots.bar(shap_values)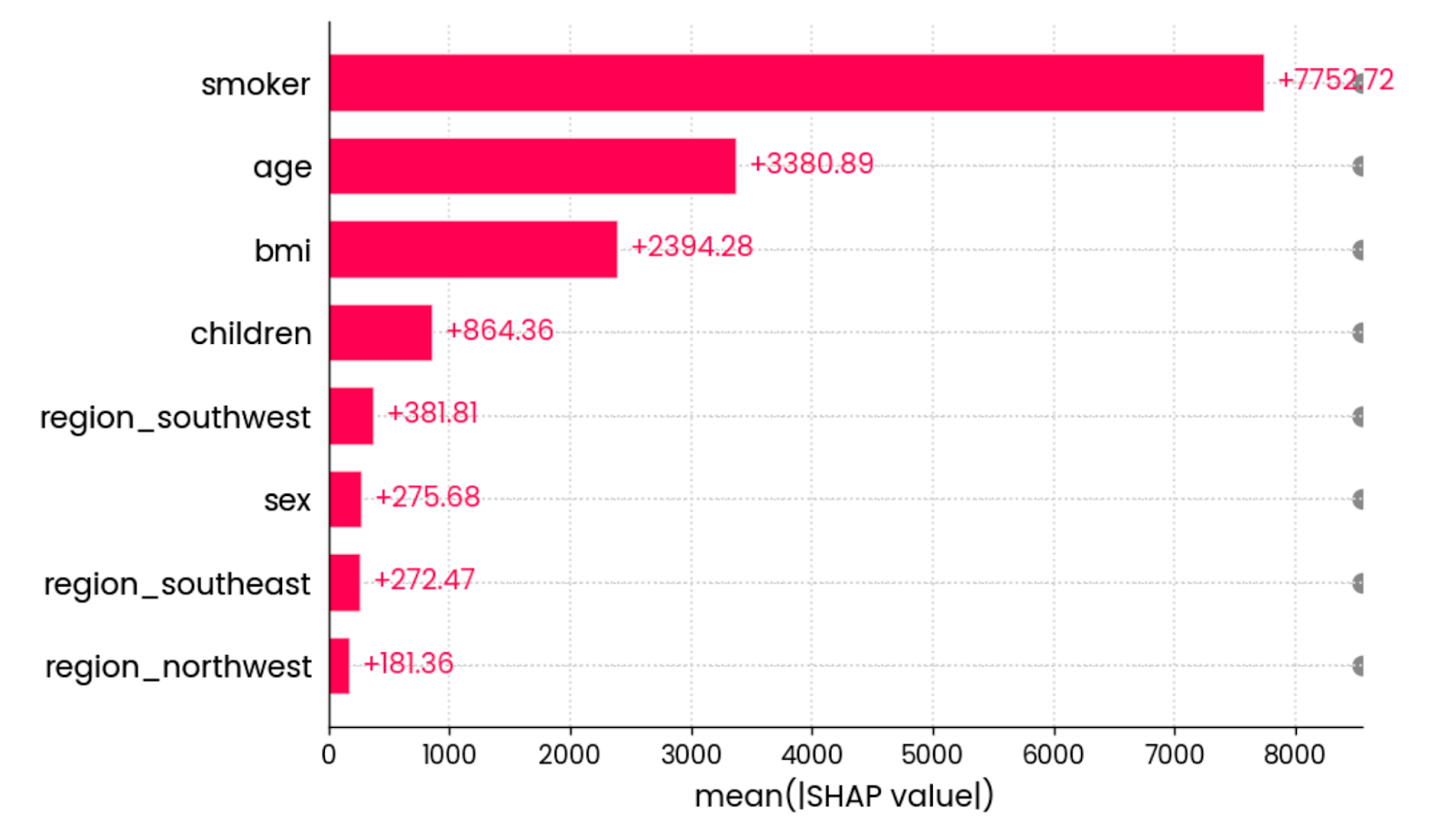
La valeur absolue moyenne de toutes les valeurs SHAP pour toutes les caractéristiques. Image par l'auteur.
En d'autres termes, il s'agit d'une façon élégante de calculer l'importance globale d'une caractéristique - le graphique n'est pas lié à une prédiction individuelle.
Voilà pour le SHAP. Je me concentrerai ensuite sur LIME.
Tout comme SHAP, LIME est axé sur l'apprentissage automatique interprétable.
Il n'a pas autant de types de visualisation à sa disposition, mais il fait bien une chose, au moins avec les ensembles de données tabulaires.
À des fins de démonstration, je vais charger l'ensemble de données de classification et le convertir en une tâche de classification binaire en remplaçant les entrées en liste d'attente par des entrées refusées. Cela vous permettra de mieux comprendre la production de LIME :
from lime import lime_tabular
df = load_classification_dataset()
# Convert to binary
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train.shape, y_test.shape
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)La classe LimeTabularExplainer() reçoit maintenant les données d'apprentissage, les noms des colonnes, les noms des catégories de la variable cible et le mode d'apprentissage automatique (classification ou régression) :
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=["Admit", "Deny"],
mode="classification"
)Une fois cela fait, vous pouvez appeler la méthode explain_instance() pour interpréter une prédiction unique sur la base des probabilités de prédiction des classes :
exp = explainer.explain_instance(
data_row=X_test.iloc[0],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)
Explications sur le LIME (1). Image par l'auteur.
Le modèle LIME est sûr à 96% que l'admission à ce MBA sera refusée. Les caractéristiques telles que gmat et gender ont eu le plus d'impact sur la décision.
Faisons maintenant la même chose pour un cas qui a été admis au programme MBA :
exp = explainer.explain_instance(
data_row=X_test.iloc[234],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)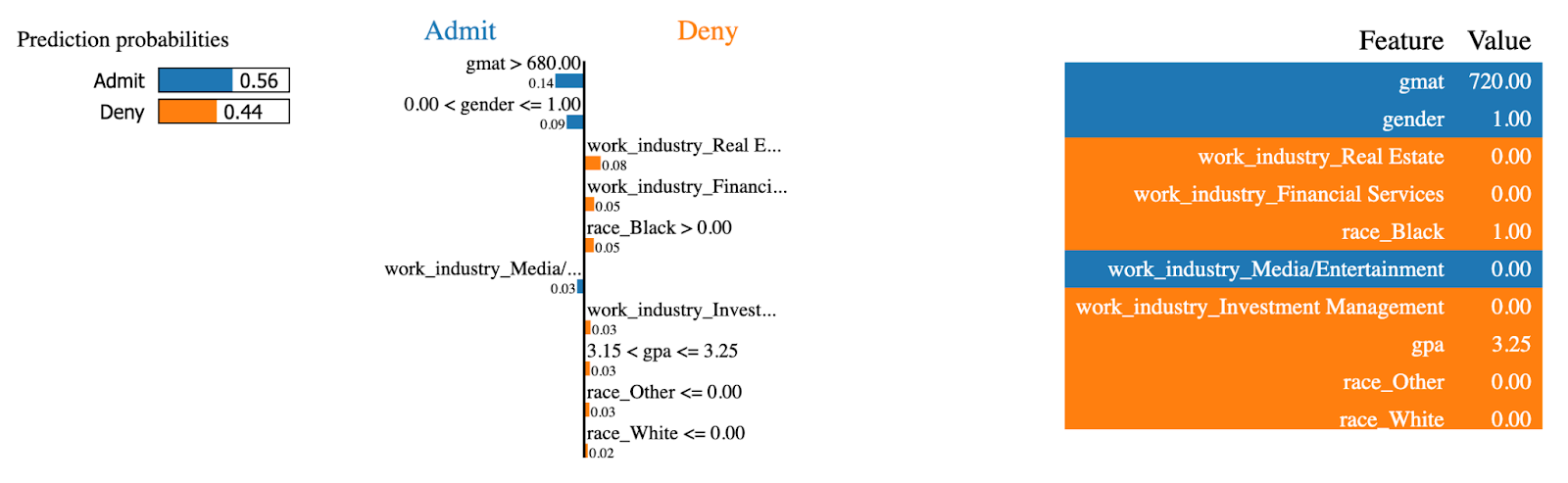
Explications sur le LIME (2). Image par l'auteur.
Les mêmes caractéristiques ont maintenant l'effet inverse ! Cette personne avait un score élevé sur gmat, qui est le principal facteur d'admission au programme MBA.
Et voilà pour les modèles d'arbres ! Vous apprendrez ensuite à visualiser les modèles linéaires pour les tâches de régression.
Si vous débutez dans la modélisation prédictive, il n'y a rien de plus basique que la régression linéaire. Il s'agit d'un modèle simple, facile à comprendre et qui fonctionne bien, à condition que les relations dans votre ensemble de données soient linéaires.
Il existe d'autres modèles linéaires, mais dans cette section, je ne travaillerai qu'avec la régression linéaire.
Commencez par charger l'ensemble de données de régression, divisez-le en sous-ensembles d'entraînement et de test, et ajustez un modèle de régression linéaire à la partie d'entraînement :
from sklearn.linear_model import LinearRegression
df = load_regression_dataset()
X = df.drop("charges", axis=1)
y = df["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = LinearRegression().fit(X_train, y_train)Le premier type de visualisation que j'explorerai est celui des coefficients de modèle.
En termes simples, un modèle de régression linéaire se résume à une seule équation. Vous vous souvenez peut-être de y = mx+b au lycée - l'idée est la même.
L'équation de régression s'étend à y = w0 + w1_x1 + w2_x2 + … + wn_xn pour tenir compte des paramètres multiples. L'objectif du modèle est de trouver la meilleure estimation des poids (w) compte tenu de l'ensemble des caractéristiques d'entrée (x).
Pourquoi est-ce important ?
Comme vous pouvez accéder aux coefficients (poids) après l'apprentissage du modèle et analyser leur contribution, les caractéristiques associées à un coefficient plus élevé contribueront davantage à la prédiction de la variable cible.
Vous pouvez obtenir les coefficients en accédant au paramètre coef_ d'un modèle entraîné.
L'extrait suivant permet d'obtenir les coefficients et de les représenter sous la forme d'un diagramme à barres horizontal :
features = X_train.columns
coefficients = model.coef_
plt.figure(figsize=(10, 4))
bars = plt.barh(y=features, width=coefficients, edgecolor="#008031", linewidth=1)
for bar in bars:
width = bar.get_width()
plt.text(width + 1, bar.get_y() + bar.get_height()/2, f"{width:.2f}",
va="center", ha="left")
plt.xlabel("Coefficient value")
plt.title("Linear Regression Model Coefficients", y=1.05)
plt.show()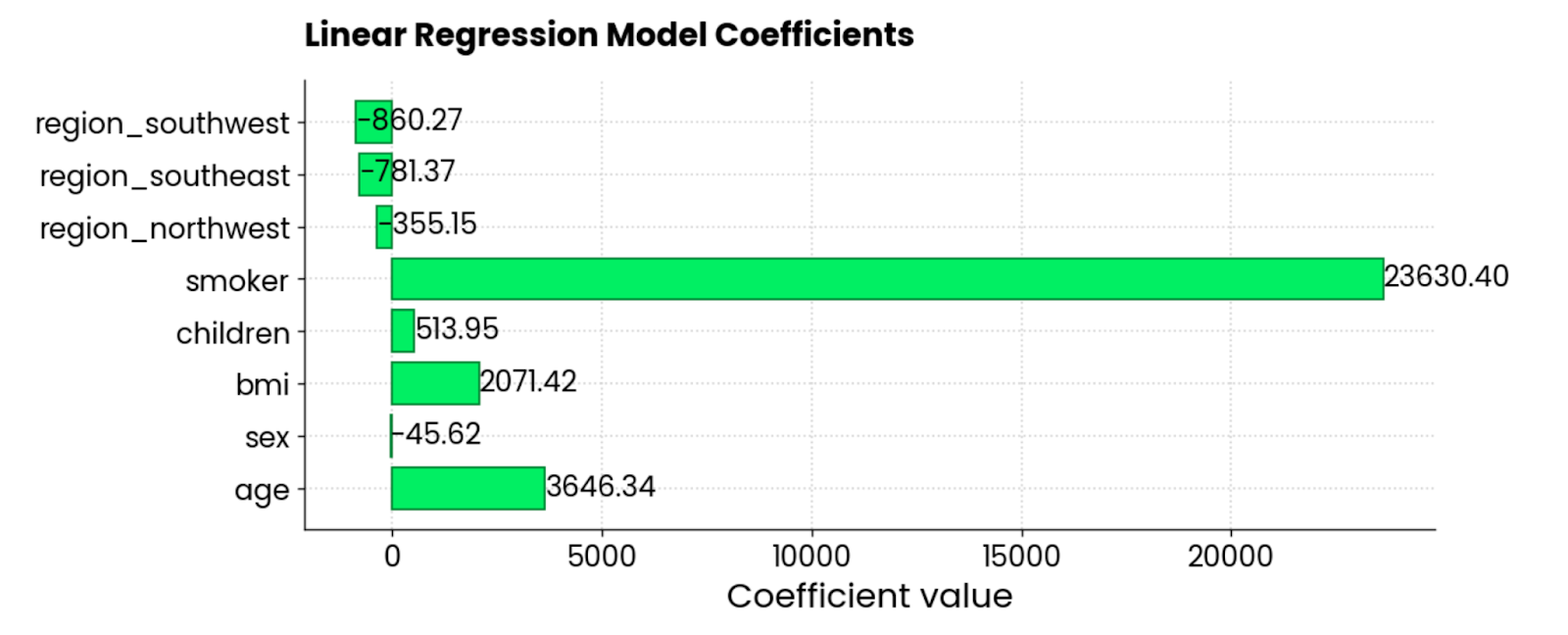
Coefficients du modèle de régression linéaire. Image par l'auteur.
Les caractéristiques smoker, BMI et age sont celles qui contribuent le plus aux frais d'assurance - lorsqu'elles augmentent, le montant augmente également. Il y a également quelques coefficients négatifs, ce qui signifie qu'ils réduisent le montant global.
L'autre type courant de visualisation de la régression est le graphique des résidus. En clair, vous réalisez undiagramme de dispersion des valeurs prédites sur l'axe X et des résidus (valeurs réelles - valeurs prédites) sur l'axe Y.
Idéalement, les résidus ne devraient pas présenter de motifs visibles et devraient être centrés autour de 0. En d'autres termes, ils doivent être normalement distribués.
Utilisez cet extrait de code pour visualiser les résidus d'un modèle de régression linéaire sur l'ensemble des données d'assurance :
y_pred = model.predict(X_test)
residuals = y_test - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, color="#03EF62", alpha=0.6, edgecolors="#008031")
plt.axhline(0, color="red", linestyle="--")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Values", y=1.05)
plt.grid(True)
plt.show()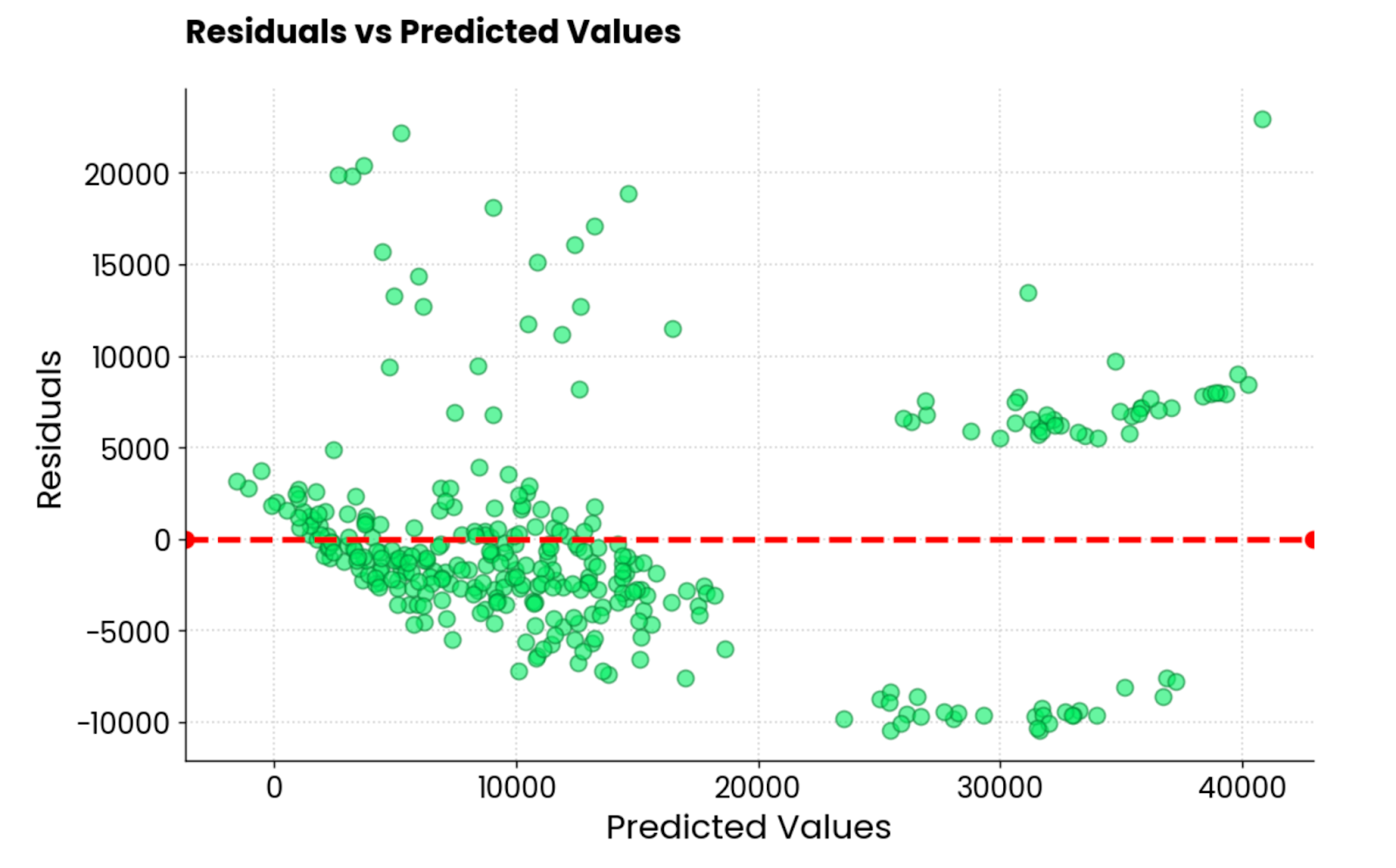
Résidus du modèle de régression linéaire. Image par l'auteur.
Ce n'est pas la meilleure intrigue résiduelle que j'ai vue. L'esthétique est bonne, mais les valeurs sont très disparates. Si vous êtes un praticien de l'apprentissage automatique et que vous obtenez un graphique résiduel similaire, vous avez beaucoup de travail devant vous.
Je vais maintenant vous présenter trois façons de visualiser les modèles de réseaux neuronaux.
S'il est un domaine de l'apprentissage automatique où la visualisation et l'interprétation sont les plus importantes, c'est bien celui des réseaux neuronaux.
Il est difficile de s'y retrouver, même au niveau le plus fondamental. Vous disposez de différents types de couches, de fonctions d'activation et de rétropropagation, pour n'en citer que quelques-uns. C'est pourquoi les réseaux neuronaux sont souvent synonymes demodèles de boîte noire .
Il n'est pas nécessaire qu'il en soit ainsi.
Dans cette section, je vous présenterai trois méthodes de visualisation des réseaux neuronaux : les tracés d'architecture, les mesures de formation en temps réel et Grad-CAM.
Ma bibliothèque de prédilection est TensorFlow. Si vous n'en avez jamais entendu parler, nous avonsve un cours TensorFlow pour débutants qui vous permettra de commencer rapidement !
Lorsque vous visualisez l'architecture de votre modèle de réseau neuronal, une chose est démystifiée - les les formes.
En d'autres termes, vous verrez comment la matrice sous-jacente se transforme en taille en passant d'une couche à l'autre. Il peut s'agir d'un sujet difficile pour les nouveaux arrivants, c'est pourquoi toute visualisation est la bienvenue.
Pour le démontrer, j'utiliserai TensorFlow pour créer un modèle de réseau neuronal de base pour la classification des chiffres manuscrits. Ensuite, j'utiliserai la fonction plot_model() pour enregistrer l'image de l'architecture du modèle dans un fichier local.
Jetez-y un coup d'œil :
from tensorflow.keras import layers, models
from tensorflow.keras.utils import plot_model
model = models.Sequential()
model.add(layers.Input(shape=(28, 28, 1)))
model.add(layers.Conv2D(32, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
plot_model(model, to_file="model_architecture.png", show_shapes=True, show_layer_names=True)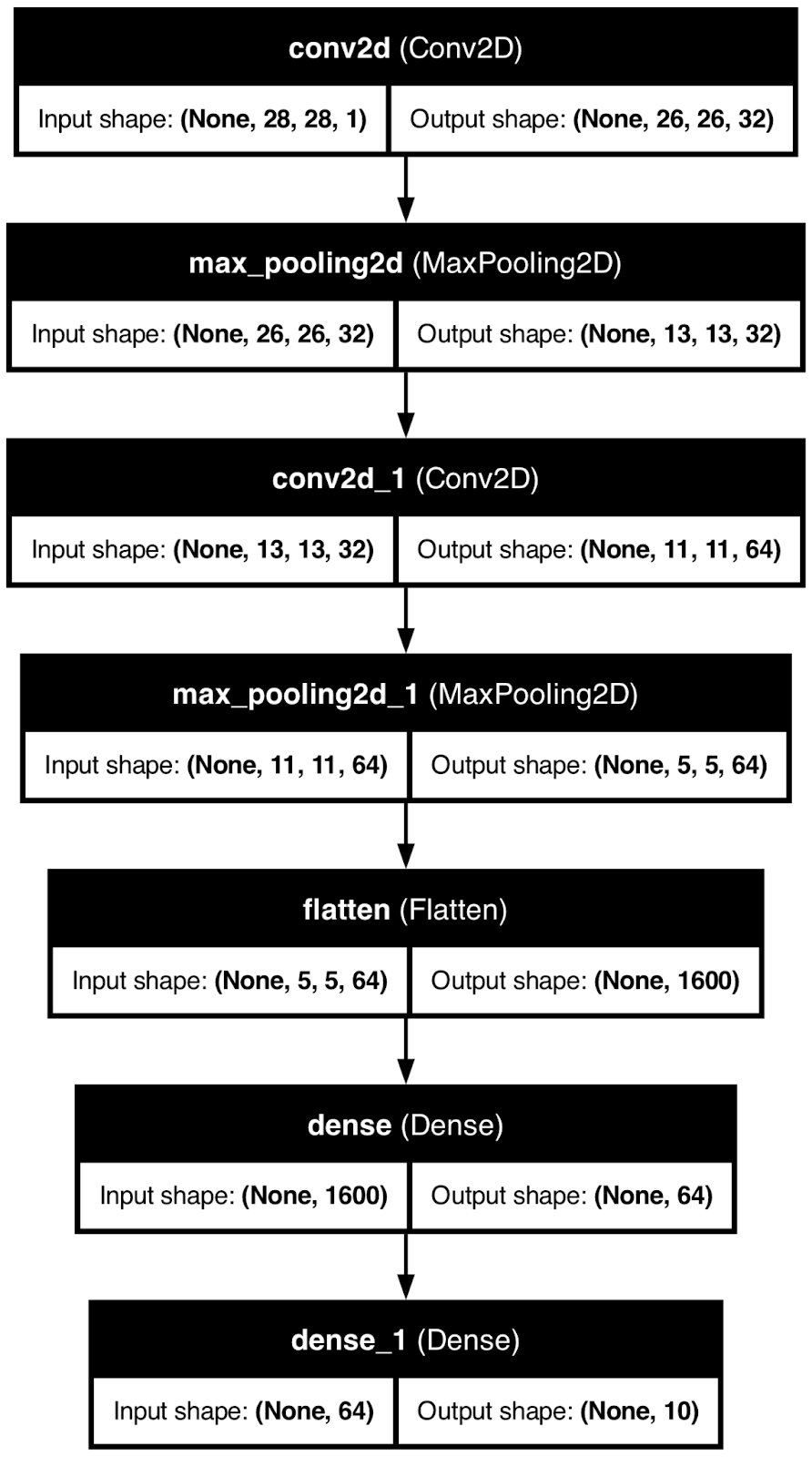
Architecture du modèle de réseau neuronal. Image par l'auteur.
Bien qu'utile, ce type de visualisation ne vous mènera pas très loin.
Vous savez comment les données se transforment en cours de route, mais vous n'avez aucune idée de la manière dont un modèle de réseau neuronal parvient à ses conclusions. C'est ce que j'aborderai ensuite.
Grad-CAM, ou Gradient Class Activation Mapping (cartographie d'activation de classe de gradient) est une technique populaire utilisée pour visualiser les modèles de réseaux neuronaux convolutifs.
Plus précisément, il vous aide à comprendre quelles parties d'une image d'entrée contribuent le plus aux prédictions du modèle. Il s'agit d'une représentation graphique de l'importance des caractéristiques d'un arbre de décision, mais portée à 11.
Il s'agit d'une technique d'interprétation avancée qui fonctionne pour tous les modèles convolutifs, quelle que soit leur architecture, et qui vous aide à comprendre pourquoi un modèle de réseau neuronal produit une certaine prédiction.
Mais voilà le problème - ce n'est pas une chose triviale à mettre en œuvre en Python. Voici une vue d'ensemble de l'algorithme :
Il s'agit d'un processus assez complexe et, pour faciliter les choses, j'utiliserai un modèle pré-entraîné ResNet50 qui peut déjà classer 1000 types d'images différents.
Mais d'abord, chargez les bibliothèques nécessaires et l'image pour laquelle vous souhaitez afficher un Grad-CAM. J'utilise une image de chien en stock:
import cv2
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import load_img
image = np.array(load_img("dog.jpg", target_size=(224, 224, 3)))
plt.grid(False)
plt.imshow(image)
Exemple d'image de chien. Image par l'auteur.
C'est maintenant que commence la partie la plus amusante. Dans l'extrait de code suivant, je mets en œuvre le processus en quatre étapes décrit précédemment. Vous trouverez des commentaires au-dessus de chaque ligne de code pour faciliter la compréhension :
# Load the pre-trained ResNet50 model
model = ResNet50()
# Extract the output of the last convolutional layer
last_conv_layer = model.get_layer("conv5_block3_out")
# Create a model that outputs the last convolutional layer’s activations
last_conv_layer_model = tf.keras.Model(model.inputs, last_conv_layer.output)
# Prepare the classifier model using the layers after the last convolutional layer
classifier_input = tf.keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in ["avg_pool", "predictions"]:
# Reuse the pooling and prediction layers from the ResNet50 model
x = model.get_layer(layer_name)(x)
# Create a new model that takes in the last conv layer output and returns predictions
classifier_model = tf.keras.Model(classifier_input, x)
# Use a GradientTape to record operations for automatic differentiation
with tf.GradientTape() as tape:
# Prepare the input image and get the activations from the last conv layer
inputs = image[np.newaxis, ...]
last_conv_layer_output = last_conv_layer_model(inputs)
tape.watch(last_conv_layer_output) # Watch the conv layer output
# Get predictions from the classifier model
preds = classifier_model(last_conv_layer_output)
# Get the index of the highest predicted class
top_pred_index = tf.argmax(preds[0])
# Focus on the prediction of the top class
top_class_channel = preds[:, top_pred_index]
# Compute the gradient of the top predicted class with respect to the conv layer output
grads = tape.gradient(top_class_channel, last_conv_layer_output)
# Average the gradients over the width and height dimensions
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# Multiply each channel in the conv layer output by its corresponding gradient
last_conv_layer_output = last_conv_layer_output.numpy()[0]
pooled_grads = pooled_grads.numpy()
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, i] *= pooled_grads[I]
# Compute the Grad-CAM by averaging the channels and apply a ReLU activation
gradcam = np.mean(last_conv_layer_output, axis=-1)
# Normalize the Grad-CAM to be between 0 and 1
gradcam = np.clip(gradcam, 0, np.max(gradcam)) / np.max(gradcam)
# Resize the Grad-CAM heatmap to the size of the original image (224x224)
gradcam = cv2.resize(gradcam, (224, 224))C'était beaucoup, certes, mais vous pouvez enfin tracer la carte thermique produite par l'algorithme Grad-CAM :
plt.grid(False)
plt.imshow(gradcam)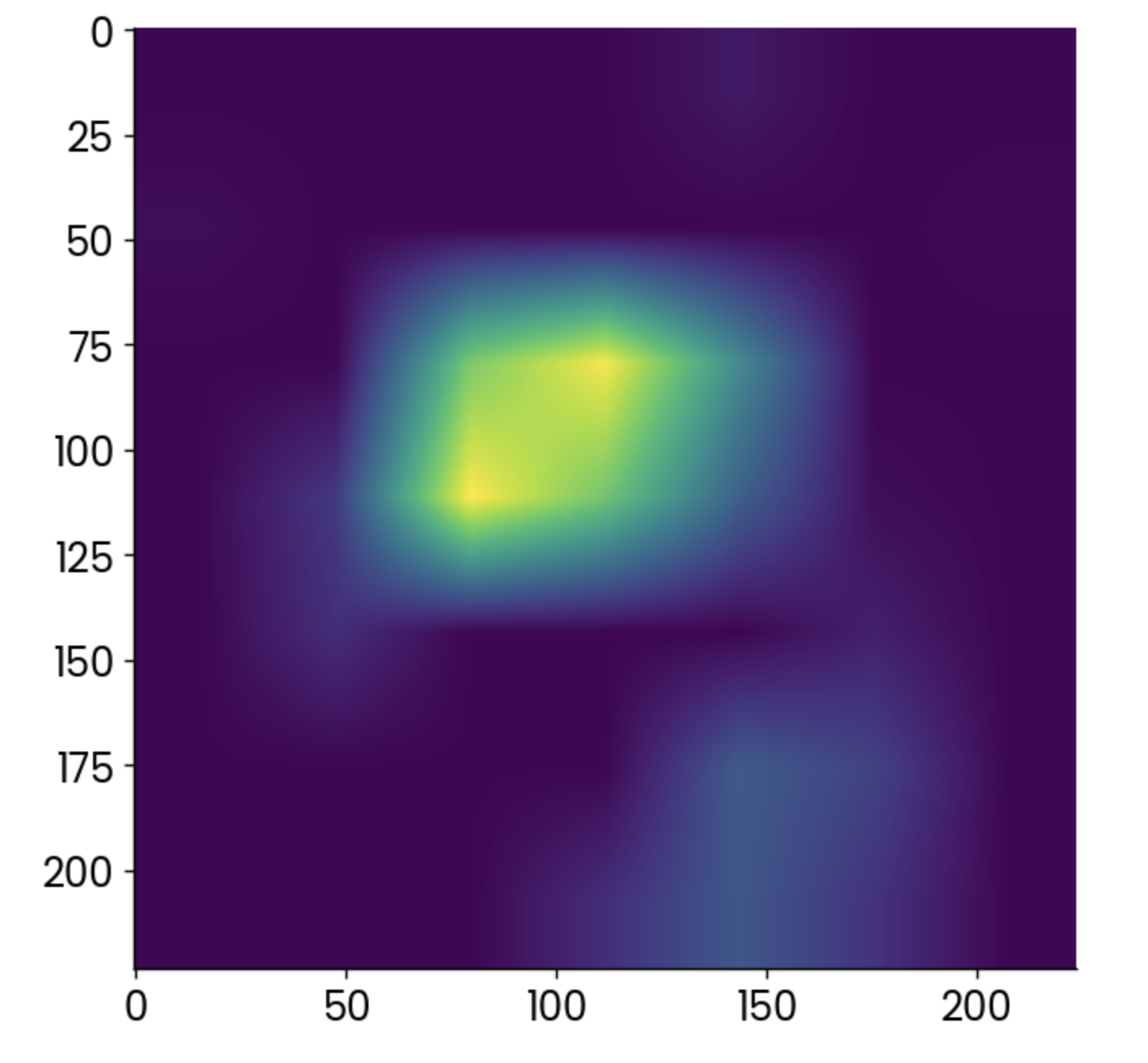
Carte thermique Grad-CAM. Image par l'auteur.
Les points plus clairs indiquent les zones dans lesquelles l'activation a été la plus forte, mais la carte thermique seule ne vous apprend pas grand-chose.
Il est préférable de la superposer à l'image originale et de réduire légèrement l'opacité :
plt.grid(False)
plt.imshow(image)
plt.imshow(gradcam, alpha=0.5)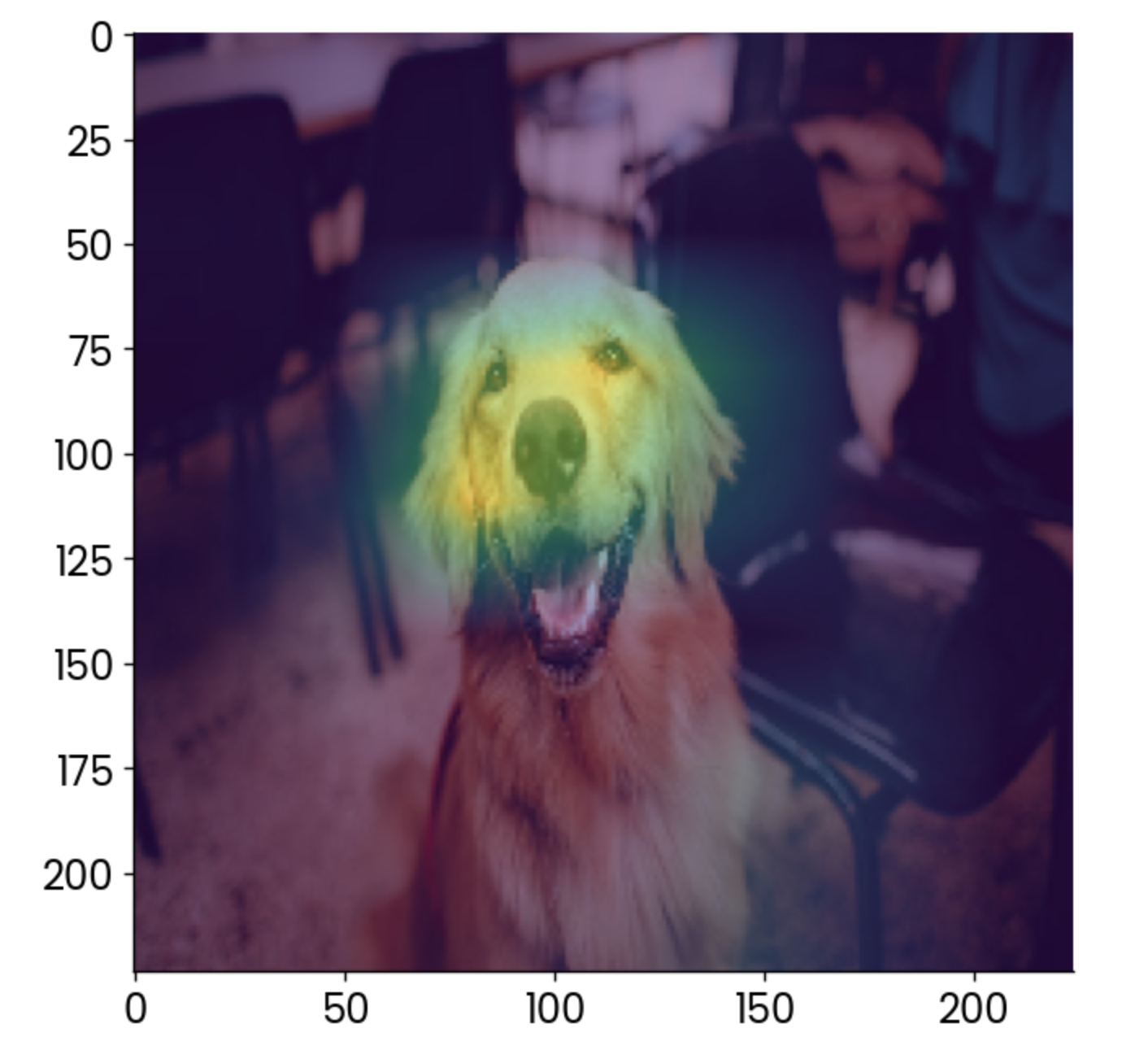
Image de chien avec une superposition grad-CAM. Image par l'auteur.
Selon l'interprétation, le facteur qui contribue le plus à classer cette image dans la catégorie des "golden retrievers" est le visage, ce qui est logique.
Vous pouvez utiliser Grad-CAM pour vous assurer que votre modèle effectue les prédictions de la bonne manière. Dans ce cas, imaginez que la carte thermique montre que quelque chose d'autre, comme la chaise à l'arrière-plan, est le facteur le plus important. Vous ne feriez pas confiance à ce modèle, n'est-ce pas ?
La formation d'un modèle de réseau neuronal peut prendre beaucoup de temps. L'avantage est que vous n'avez pas besoin d'attendre la fin de la formation pour avoir un aperçu des performances du modèle. Des bibliothèques comme TensorBoard peuvent vous le montrer en temps réel.
TensorBoard est livré avec TensorFlowvous n'avez donc pas besoin d'installer quoi que ce soit pour le suivre.
À des fins de démonstration, j'entraînerai un modèle de classificateur de chiffres de base pendant 25 époques. La partie importante est lerappel -vous y spécifiez le chemin et le format des journaux d'entraînement, que TensorBoard utilisera dans une minute.
Il s'agit du code dont vous aurez besoin pour entraîner le modèle et stocker les journaux d'entraînement :
import tensorflow as tf
from tensorflow.keras import layers, models
from datetime import datetime
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension (for the Convolutional layer)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# Build a simple CNN model
model = models.Sequential([
layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax")
])
# Compile the model
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
# Set up TensorBoard callback
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Train the model with TensorBoard monitoring
model.fit(
x_train,
y_train,
epochs=25,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]
)
Modéliser le processus de formation. Image par l'auteur.
Pendant que le modèle s'entraîne, lancez TensorBoard à partir du terminal et indiquez un chemin vers le dossier des journaux d'entraînement :
tensorboard --logdir=logs/fitTensorBoard fonctionnera par défaut sur le port 6006 :
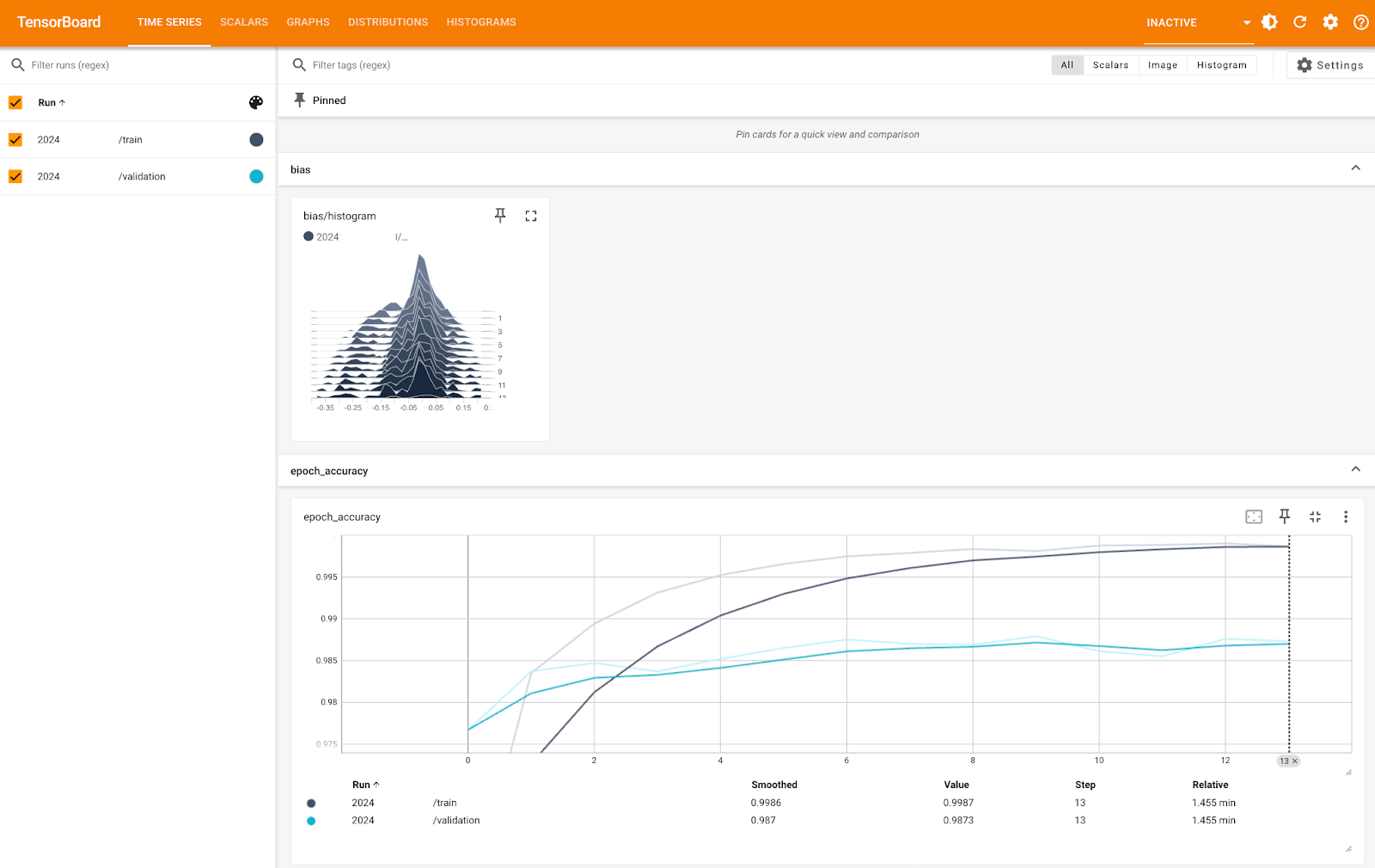
Métriques TensorBoard (1). Image par l'auteur.
L'image ci-dessus vous montre l'histogramme de biais et la précision par période, à la fois pour les ensembles de formation et de validation. Vous pouvez constater que la précision est très élevée pour les deux, proche de 100 % - c'est juste l'échelle de l'axe Y qui est trop petite.
D'autres onglets sont consacrés à des mesures plus spécifiques et vous permettent de modifier certaines choses, comme vous pouvez le voir ci-dessous :
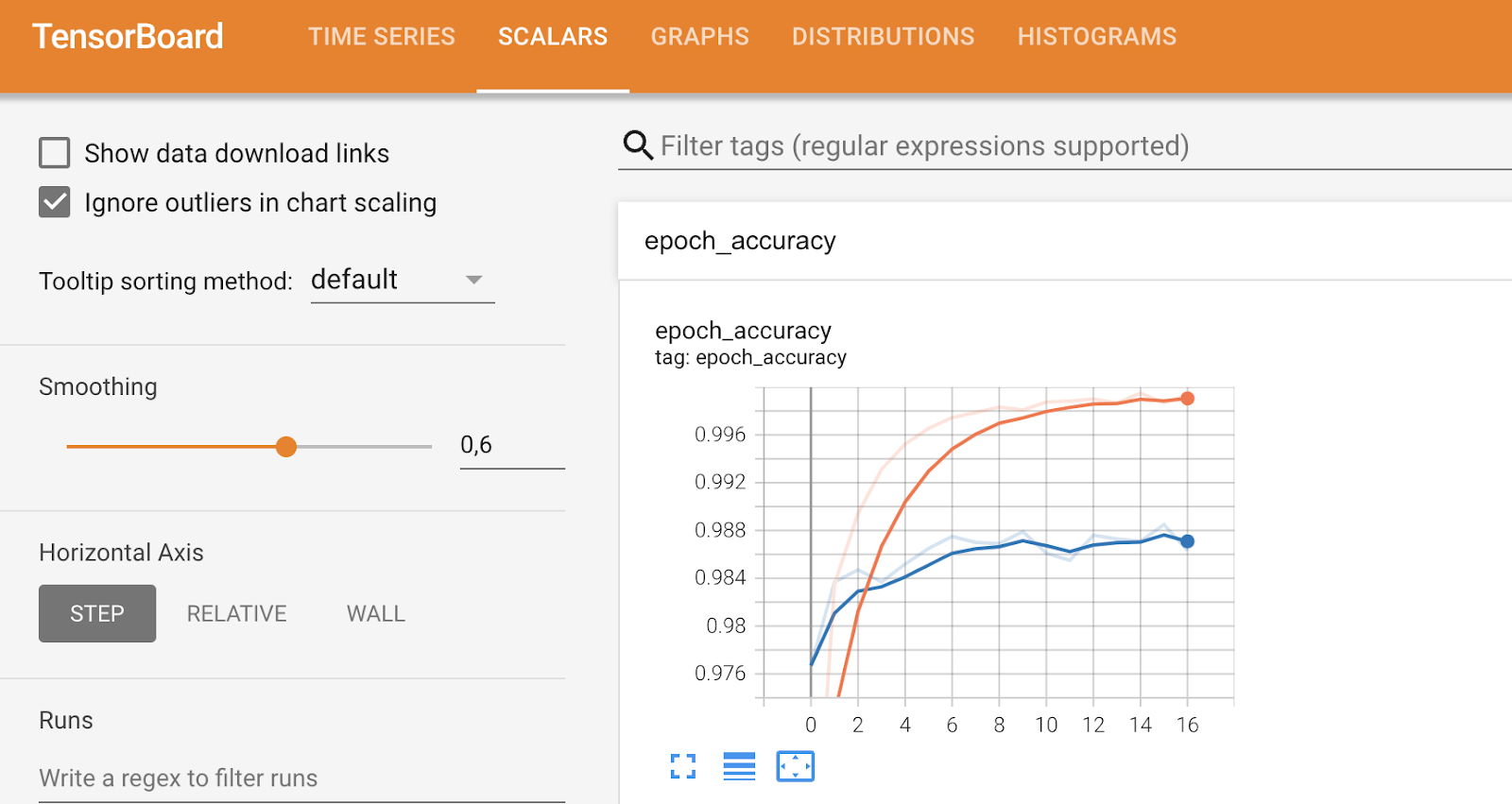
Métriques TensorBoard (2). Image par l'auteur.
En conclusion, TensorBoard est un outil de visualisation des performances du modèle qui peut vous aider à analyser les performances pendant l'entraînement du modèle.
Dans cette dernière partie, je souhaite prendre du recul et me plonger dans des mesures plus générales permettant de visualiser les performances du modèle.
Vous verrez trois Vous en verrez trois : la matrice de confusion, le tracé de la courbe ROC et le tracé de la courbe Précision-Recall.
Comme ils sont liés à des problèmes de classification, vous devrez charger le jeu de données MBAde classification . Pour faciliter les choses, j'ai également converti le problème en un problème de classification binaire en définissant les entrées en liste d'attente comme étant refusées. Le reste de l'extrait de code divise les données en sous-ensembles d'apprentissage et de test et commence par un modèle de classification de forêt aléatoire :
from sklearn.ensemble import RandomForestClassifier
df = load_classification_dataset()
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
df["admission"] = df["admission"].replace({"Deny": 0, "Admit": 1})
df.rename(columns={"admission": "is_admitted"}, inplace=True)
X = df.drop("is_admitted", axis=1)
y = df["is_admitted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Examinons la première mesure - la matrice de confusion.
Une matrice de confusion vous indique la performance de votre modèle. Dans un scénario idéal, les valeurs situées sur une diagonale allant du haut à gauche au bas à droite seraient les seuls éléments non nuls, ce qui indiquerait que le modèle n'a pas fait de fausses prédictions.
Mais cela n'arrive pas souvent dans le monde réel.
Utilisez les lignes directrices suivantes pour interpréter une matrice de confusion (pour une classification binaire) :
Il n'existe pas de règle générale permettant de déterminer si vous devez vous préoccuper davantage des faux positifs ou des faux négatifs. L'antériorité est plus douloureuse dans le cas des admissions en MBA puisque le modèle classait l'étudiant admis, ce qui n'était pas le cas dans la réalité. Dans d'autres cas, comme laprédiction du cancer sur le site , il est essentiel de minimiser le nombre de faux négatifs, car vous ne voulez pas déclarer qu'une personne est en bonne santé alors qu'elle est atteinte d'un cancer.
C'est là qu'intervient la connaissance du domaine.
Quoi qu'il en soit, revenons au code. L'extrait suivant calcule la matrice de confusion de notre modèle de forêt aléatoire sur l'ensemble de test et utilise la classe ConfusionMatrixDisplay pour créer une visualisation :
from sklearn.metrics import confusion_matrix
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
preds = random_forest.predict(X_test)
cm = confusion_matrix(y_true=y_test, y_pred=preds, labels=random_forest.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=random_forest.classes_)
disp.plot()
plt.grid(False)
plt.title("Confusion Matrix", y=1.04)
plt.show()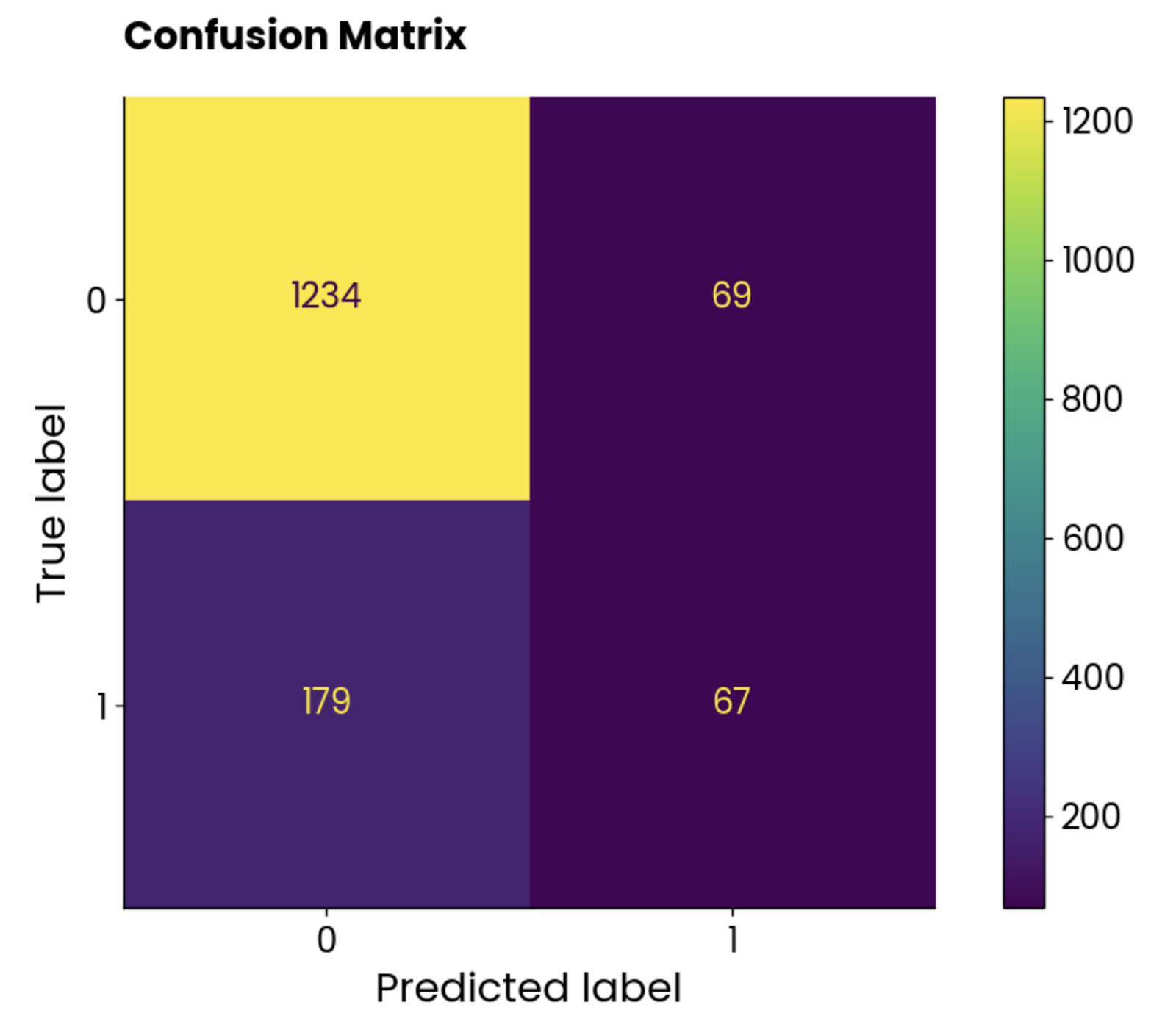
Représentation graphique de la matrice de confusion. Image par l'auteur.
Les classes ne sont pas équilibrées, mais le nombre de prédictions incorrectes est étonnamment élevé.
Voyons ce que dit la courbe ROC.
ROC signifie Receiver Operating Characteristics (caractéristiques de fonctionnement du récepteur), et il s'agit d'une courbe qui affiche l'évaluation des performances d'un modèle de classification binaire. Dans le cas de la classification multi-classes, vous devrez comparer deux classes à la fois.
La courbe ROC montre un compromis entre un taux de vrais positifs (TPR, sensibilité, rappel) et un taux de faux positifs (FPR) pour différents seuils de classification. Le TPR est représenté sur l'axe Y en fonction du FPR sur l'axe X. Chaque point représente un seuil différent pour la décision de classification (score de probabilité utilisé pour classer une instance comme positive ou négative).
La courbe est généralement tracée par rapport à une diagonale allant de (0, 0) à (1, 1), qui représente un classificateur aléatoire.
Si la courbe est supérieure à la diagonale, cela signifie que votre modèle est plus performant qu'un classificateur aléatoire. Une seule valeur scalaire résume cela. Elle est appelée AUC (Area Under the Curve) et varie de 0 à 1, une valeur plus élevée étant meilleure et une valeur de 0,5 étant aléatoire.
En bref, vous voulez que la courbe soit aussi proche que possible du coin supérieur gauche.
Utilisez l'extrait suivant pour calculer le ROC et l'AUC et tracer la courbe :
from sklearn.metrics import roc_curve, auc
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
fpr, tpr, roc_thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.2f}")
plt.plot([0, 1], [0, 1], color="navy", linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve", y=1.04)
plt.legend(loc="lower right")
plt.show()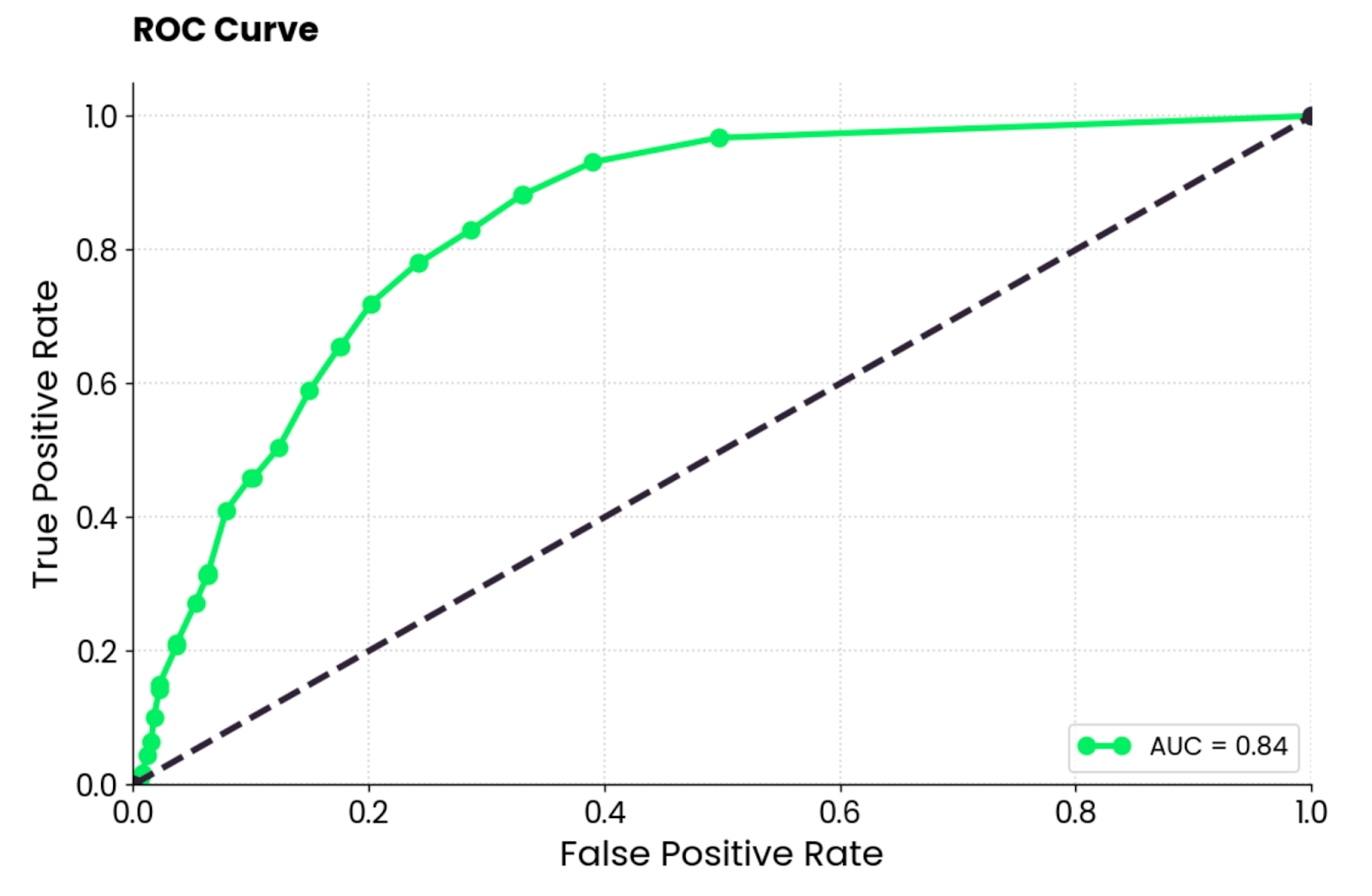
Courbe ROC. Image par l'auteur.
Pour l'interprétation, le modèle de forêt aléatoire est bien meilleur qu'un classificateur aléatoire et présente un équilibre raisonnable entre les vrais et les faux positifs. Un certain degré d'erreur de classification est toujours présent et vous devez chercher à relever la courbe vers le haut et la gauche en optimisant les données ou en choisissant un modèle d'apprentissage automatique différent.
Cette courbe est similaire à la courbe ROC mais montre le compromis entre la précision et le rappel pour différents seuils de classification. Il indique la précision sur l'axe Y et le rappel sur l'axe X. Il est généralement préféré au ROC lorsque les classes sont déséquilibrées.
Il se trouve que c'est le cas dans l'ensemble des données relatives aux admissions en MBA, et une courbe PR semble donc tout à fait adaptée !
Il est important de noter que les courbes de précision-rappel se concentrent uniquement sur la classe minoritaire et donnent une meilleure idée de la manière dont le modèle identifie les cas les plus importants (étudiants admis, cancers détectés, etc.).
Utilisez l'extrait suivant pour calculer les valeurs de précision et de rappel et les représenter sur un graphique :
from sklearn.metrics import precision_recall_curve
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
# Precision-Recall curve
precision, recall, pr_thresholds = precision_recall_curve(y_test, y_probs)
pr_auc = auc(recall, precision)
plt.plot(recall, precision, label=f"(AUC = {pr_auc:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve", y=1.04)
plt.legend(loc="lower left")
plt.show()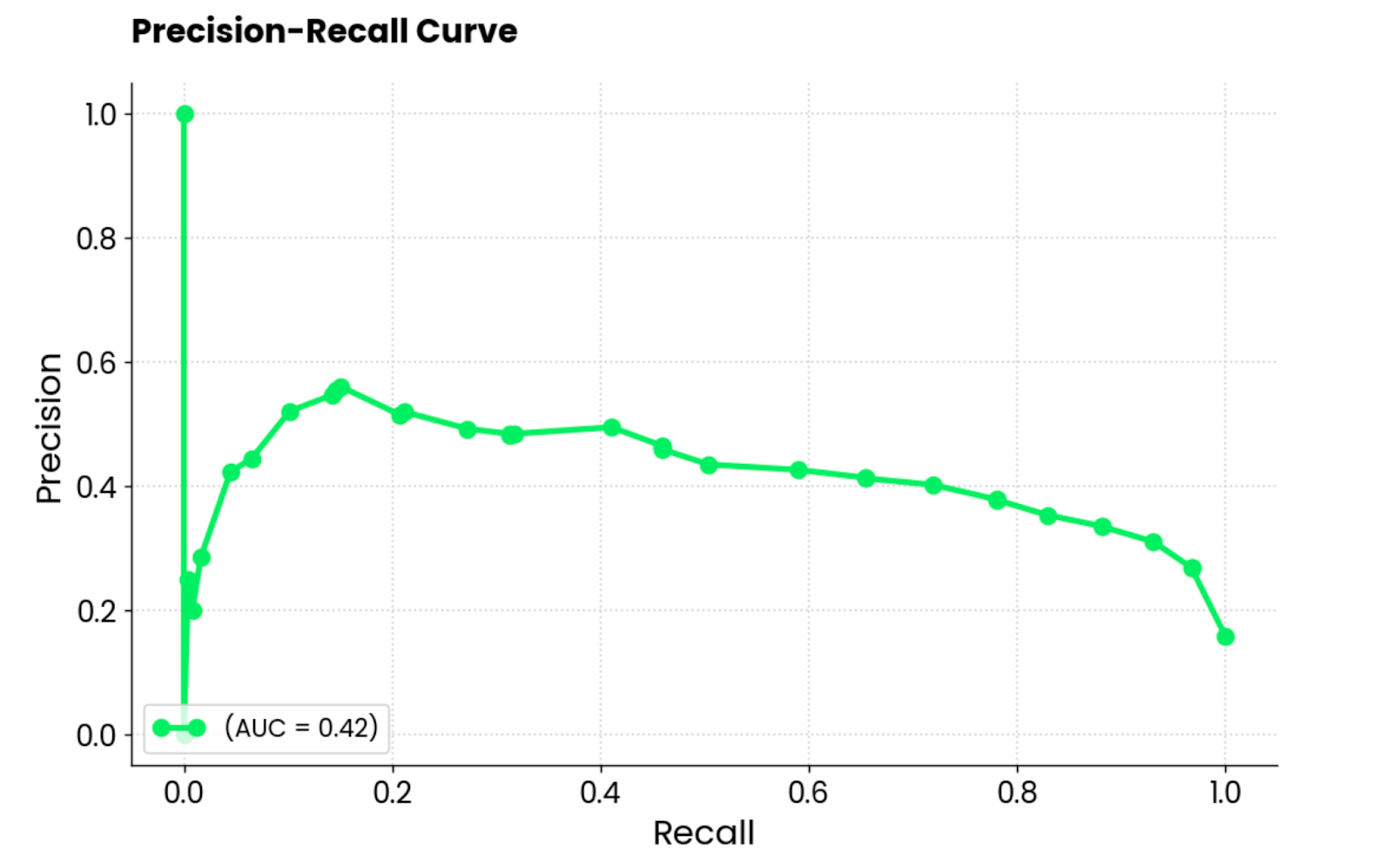
Courbe de précision et de rappel. Image par l'auteur.
Pour l'interprétation, le modèle est peu performant, comme l'indique le score AUC de 0,42. Lorsque le modèle tente d'augmenter le rappel, il sacrifie trop de précision, ce qui entraîne de nombreux faux positifs. En bref, ce modèle n'est pas bien adapté à cet ensemble de données, ou l'ensemble de données lui-même n'est pas prétraité de manière adéquate.
En conclusion, le domaine de l'apprentissage automatique est complexe et souvent peu intuitif. Si vous êtes débutant, vous aurez du mal à comprendre les grandes idées. Si vous travaillez avec un client professionnel, il est probable qu'il ne comprendra pas le jargon technique.
La visualisation des données permet de combler le fossé dans les deux cas.
Aujourd'hui, vous avez vu tous les différents types de graphiques que vous pouvez utiliser pour visualiser les modèles de régression et de classification, ainsi que le processus de décision des réseaux neuronaux et l'interprétation de la prédiction unique grâce à SHAP et LIME. C'est beaucoup de choses à assimiler, alors n'hésitez pas à consulter cet article plusieurs fois !
Si vous êtes totalement novice en la matière, nous vous recommandons de suivre notre cours sur les principes fondamentaux de l'apprentissage automatique pour commencer. Après cela, un cours plus appliqué avec Python vous conviendra parfaitement.
Si vous avez une certaine expérience mais que vous ne comprenez pas comment tout cela fonctionne à plus grande échelle, nous vous encourageons à essayer notre cours sur l'apprentissage automatique pour la production.
Apprenez-en plus sur l'apprentissage automatique grâce à ces cours !
Cours
Cours
Cours