
Curso
Machine learning con modelos basados en árboles en Python
5 h
116.5K
En esta breve sección, te mostraré cómo instalar las dependencias de todo el sistema y las bibliotecas de Python necesarias para visualizar los modelos de aprendizaje automático.
La única dependencia del sistema que necesitarás para seguir adelante es Graphviz. Lo utilizarás más adelante para visualizar un árbol de decisión, y el código no funcionará sin Graphviz instalado.
Es un software de código abierto utilizado para hacer diagramas, gráficos abstractos y redes. No lo utilizarás directamente; sólo a través de scikit-Learn.
Esta biblioteca de Python se utiliza ampliamente para tareas de aprendizaje automático en Python.
En este artículo, lo utilizarás para entrenar modelos de aprendizaje automático, dividir conjuntos de datos, escalar características numéricas y visualizar el rendimiento de los modelos. Es imprescindible, así que instálalo con el siguiente comando (dependiendo de tu entorno Python):
pip install scikit-learn
conda install scikit-learnSi eres completamente nuevo en scikit-learn, te recomendamos que veas nuestro popular curso sobre aprendizaje automático supervisado.
La biblioteca SHAP en Python es una herramienta popular para explicar las predicciones de los modelos de aprendizaje automático. Aprovecha los conceptos de la teoría de juegos (por ejemplo, Shapely values) para medir la contribución de cada atributo a la predicción del modelo.
Y lo que es mejor, está repleto de visualizaciones útiles que te ayudan a comprender el funcionamiento interno de tus modelos.
Instálalo con el siguiente comando:
pip install shap
conda install -c conda-forge shapMuchas personas utilizan esta biblioteca Python cuando es crucial explicar la predicción de un único modelo. Funciona de forma diferente al SHAP. Aproxima localmente el modelo original con un modelo interpretable y más sencillo. A continuación, muestra la contribución de cada característica del conjunto de datos a la predicción.
Verás cómo funciona LIME en un minuto, pero primero, instálalo:
pip install lime
conda install conda-forge::limeSi estás construyendo modelos de redes neuronales con TensorFlow, entonces TensorBoard es una obviedad.
Es una herramienta de visualización que te ayuda a realizar un seguimiento de los experimentos de aprendizaje automático y a controlar las métricas de entrenamiento (por ejemplo, pérdida y precisión). Visualiza y actualiza los gráficos del modelo por ti en tiempo real y muestra cómo cambian los parámetros del modelo durante el entrenamiento.
TensorBoard puede utilizarse con otros marcos de aprendizaje profundo como PyTorch, pero en este artículo me centraré en TensorFlow.
Instálalo ejecutando el siguiente comando:
pip install tensorboard
conda install -c conda-forge tensorboardEl último paso de esta fase de preparación es ocuparse de los datos.
Hoy utilizaré dos conjuntos de datos: MBA para clasificación y Seguros para regresión. Ambos son de uso gratuito y se pueden descargar en Kaggle.
Para empezar, importa estas bibliotecas de Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitEn cuanto al conjunto de datos de clasificación, el preprocesamiento de datos que he realizado es mínimo. Se reduce a:
No es, ni mucho menos, un proceso completo de preprocesamiento de datos. Si tienes tiempo, no dudes en mejorarlo.
No obstante, copia esta función para obtener el conjunto de datos de clasificación en orden:
def load_classification_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/taweilo/mba-admission-dataset?resource=download
df = pd.read_csv("MBA.csv")
# Just an arbitrary ID
df = df.drop(["application_id"], axis=1)
# Fill unknown
df["race"] = df["race"].fillna("Unknown")
# Assume these are denied
df["admission"] = df["admission"].fillna("Deny")
# Convert boolean cols to 0/1
df["gender"] = df["gender"].replace({"Male": 0, "Female": 1})
df["international"] = df["international"].replace({False: 0, True: 1})
# Create dummy columns for categorical features
cols_for_dummy = ["major", "race", "work_industry"]
for col in cols_for_dummy:
dummies = pd.get_dummies(df[col], prefix=col)
df = pd.concat([df, dummies], axis=1)
# To drop
cols_to_drop = ["major", "race", "work_industry", "major_Humanities", "race_Unknown", "work_industry_Other"]
df = df.drop(cols_to_drop, axis=1)
return df
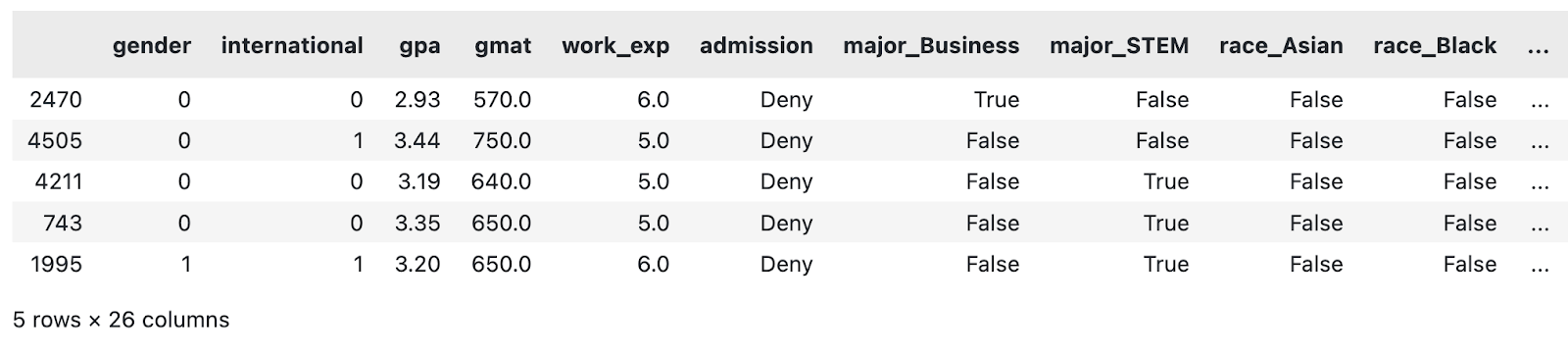
load_classification_dataset().sample(5)
Una muestra del conjunto de datos MBA modificado. Imagen del autor.
Ahora haré lo mismo con el conjunto de datos de regresión.
El conjunto de datos de regresión elegido contiene un importe de seguro ($) como característica continua que el modelo de aprendizaje automático intentará predecir basándose en otros atributos.
El preprocesamiento de datos que he realizado es, una vez más, bastante mínimo. Se reduce a:
Si tienes tiempo, no dudes en añadir más pasos al proceso.
Copia la siguiente función para cargar y preprocesar el conjunto de datos del seguro:
def load_regression_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/mirichoi0218/insurance
df = pd.read_csv("MedicalCostPersonal.csv")
# Scale numerical features
cols_to_scale = ["age", "bmi", "children"]
scaler = StandardScaler()
df[cols_to_scale] = scaler.fit_transform(df[cols_to_scale])
# Binary features
df["sex"] = df["sex"].replace({"male": 0, "female": 1})
df["smoker"] = df["smoker"].replace({"no": 0, "yes": 1})
# Dummies
dummies_region = pd.get_dummies(df["region"], prefix="region", drop_first=True)
df = pd.concat([df, dummies_region], axis=1)
df = df.drop("region", axis=1)
return df
load_regression_dataset().sample(5)
Una muestra del conjunto de datos de seguros modificado. Imagen del autor.
Y ya está.
En la siguiente sección, te mostraré cómo empezar a visualizar modelos de aprendizaje automático.
Los modelos basados en árboles suelen utilizarse para la clasificación, pero la mayoría de ellos también pueden realizar tareas de regresión.
En esta sección, te mostraré cómo visualizar un árbol de decisión, importancia de las características de un modelo de bosque aleatorio, y explicaciones de predicción con SHAP y LIME.
Ten en cuenta que los modelos de árbol de decisión y bosque aleatorio pueden ser difíciles de comprender. Tenemos un curso completo que cubre los fundamentales de los modelos de aprendizaje automático basados en árboles en Python.
Para empezar, carga el conjunto de datos de clasificación y divídelo en subconjuntos de entrenamiento y de prueba:
df = load_classification_dataset()
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)A continuación, ¡vamos a visualizar un árbol de decisión!
Piensa en un árbol de decisión como un conjunto de sentencias anidadas if en las que las condiciones las determina un modelo de aprendizaje automático.
Hay más en la historia, pero con esta analogía, puedes ver que visualizar las decisiones debería ser un proceso sencillo. Y lo es: la función plot_tree() de sklearn se encarga de la mayor parte del trabajo pesado.
Empieza entrenando un modelo de árbol de decisión. El parámetro max_depth es opcional y está aquí sólo a efectos de visualización. Sin ella, elárbol se hará demasiado profundo, y te perderás en el gran volumen de decisiones que toma el modelo, sobre todo para conjuntos de datos más grandes.
El siguiente fragmento entrena el modelo de clasificación del árbol de decisión en el subconjunto de entrenamiento:
from sklearn import tree
decision_tree = tree.DecisionTreeClassifier(random_state=42, max_depth=4)
decision_tree.fit(X_train, y_train)Y para la visualización, sólo tienes que copiar el siguiente fragmento. Los parámetros opcionales filled y feature_names facilitan la interpretación del árbol:
plt.figure(figsize=(12,8))
tree.plot_tree(decision_tree, filled=True, feature_names=X.columns, class_names=y.unique())
plt.title("Decision Tree Visualization", size=20, loc="left", y=1.04, weight="bold")
plt.show()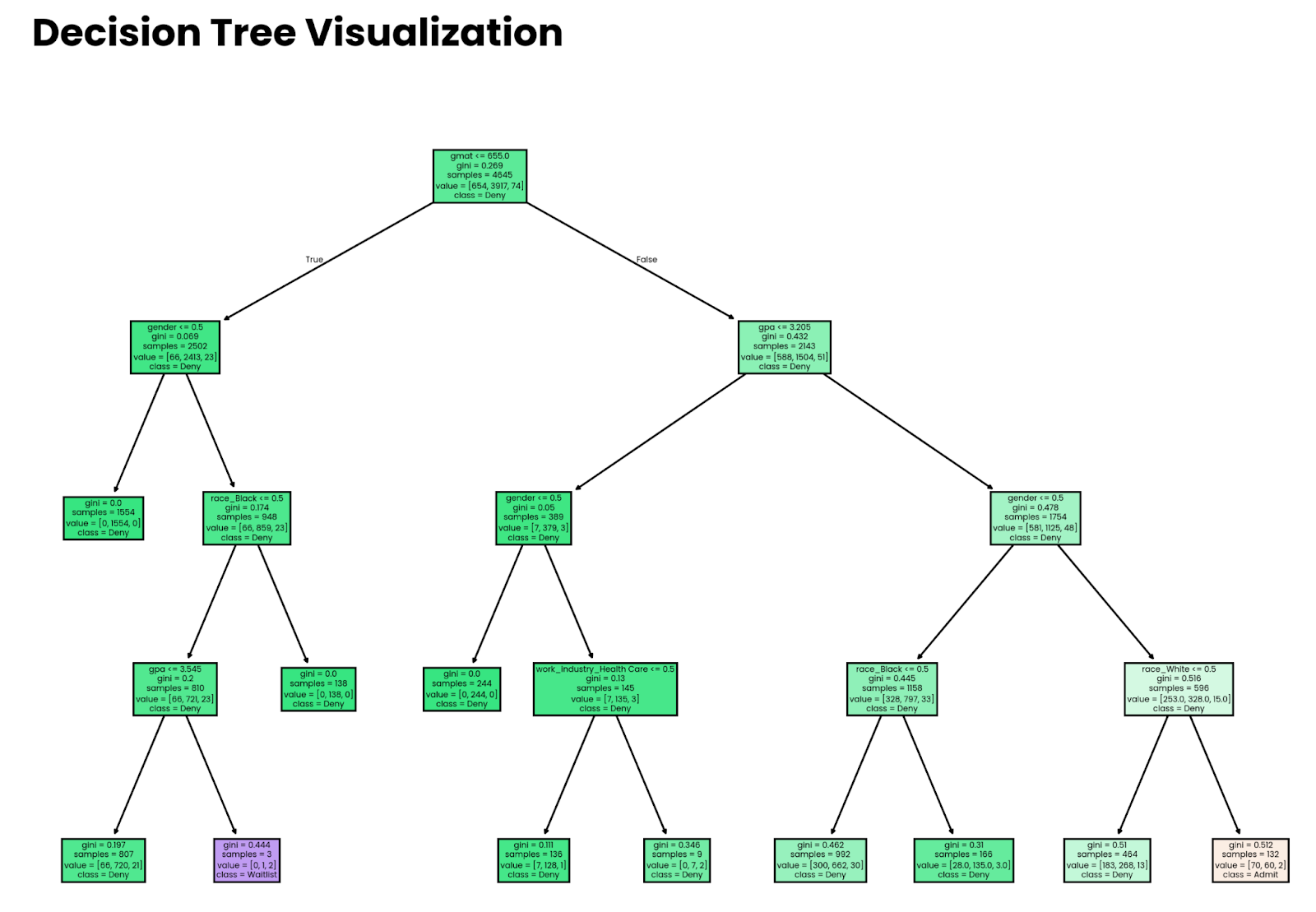
Árbol de decisión profundo de cuatro niveles. Imagen del autor.
Ten en cuenta que las decisiones tomadas por el modelo no significan nada si el modelo no es exacto. Más adelante en el artículo, te mostraré cómo estimar la precisión.
¿Recuerdas la analogía de la tarta de antes? Es hora de ponerlo en práctica.
Cada vez que entrenas un modelo de árbol con sklearn, obtienes acceso a la propiedad feature_importances_. Combínalo con los nombres de las características y tendrás todos los datos necesarios para ver qué atributos contribuyen más a la predicción.
¡Veámoslo en acción! En primer lugar, entrena un clasificador de bosque aleatorio en el subconjunto de entrenamiento:
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)La visualización se reduce ahora a extraer y ordenar las importancias de las características y sustituir los índices por los nombres de las características:
importances = random_forest.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
bars = plt.bar(range(X.shape[1]), importances[indices], edgecolor="#008031", linewidth=1)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, height, f"{height:.2f}", ha="center", va="bottom", size=8)
plt.title("Feature Importances", size=20, loc="left", y=1.04, weight="bold")
plt.ylabel("Importance")
plt.xticks(range(X.shape[1]), np.array(X.columns)[indices], rotation=90, size=12)
plt.show()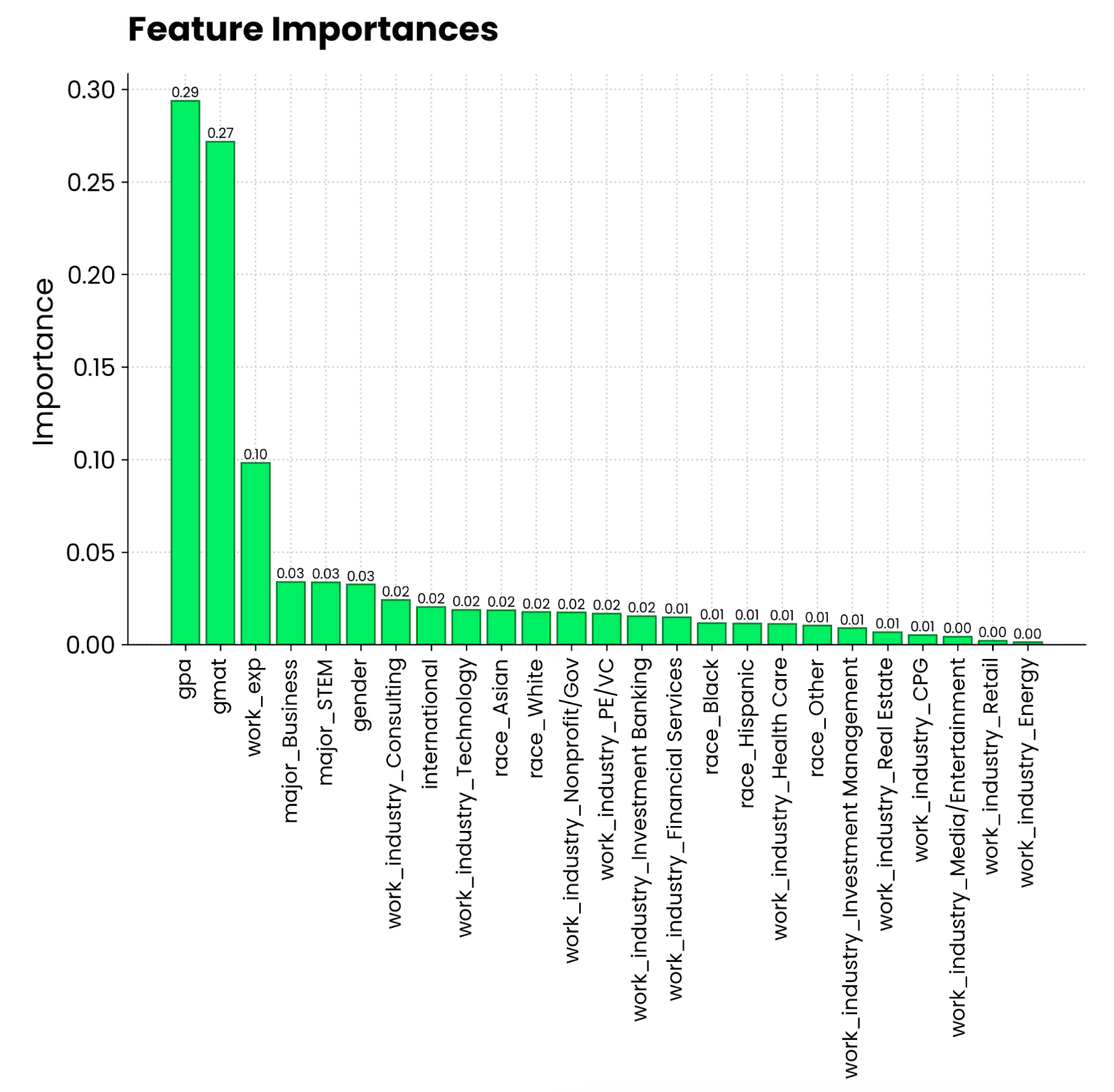
Gráfico de importancia de las características del bosque aleatorio. Imagen del autor.
Parece que la media de notas en una escala de 4,0 y la puntuación en el GMAT son los factores que más contribuyen a ser admitido en un programa de MBA. A continuación está la experiencia laboral, que es un requisito para los estudios de MBA. Lo que la persona haya estudiado y la industria en la que trabaje es mucho menos relevante.
La importancia de las características pinta el panorama general, pero ¿qué pasa si quieres visualizar los modelos de aprendizaje automático a nivel de predicción individual?
Ahí es donde entran en juego SHAP y LIME. Primero hablaré de SHAP. Ya sabes lo que es, así que me saltaré la teoría.
Ajustaré un modelo de aumento de gradiente a nuestro conjunto de datos de regresión para ver el impacto que tienen las características individuales en los gastos del seguro. El siguiente fragmento te muestra cómo ajustar el modelo y calcular los valores SHAP a partir de un modelo shap.Explainer():
import shap
from xgboost import XGBRegressor
df = load_regression_dataset()
# No need for train-test splits
X = df.drop("charges", axis=1)
y = df["charges"]
model = XGBRegressor().fit(X, y)
# Shap explainer
explainer = shap.Explainer(model)
shap_values = explainer(X)Con SHAP, hay un conjunto de tramas que puedes hacer.
Empezaré con waterfall() y examinaré los valores SHAP para la primera predicción:
shap.plots.waterfall(shap_values[0])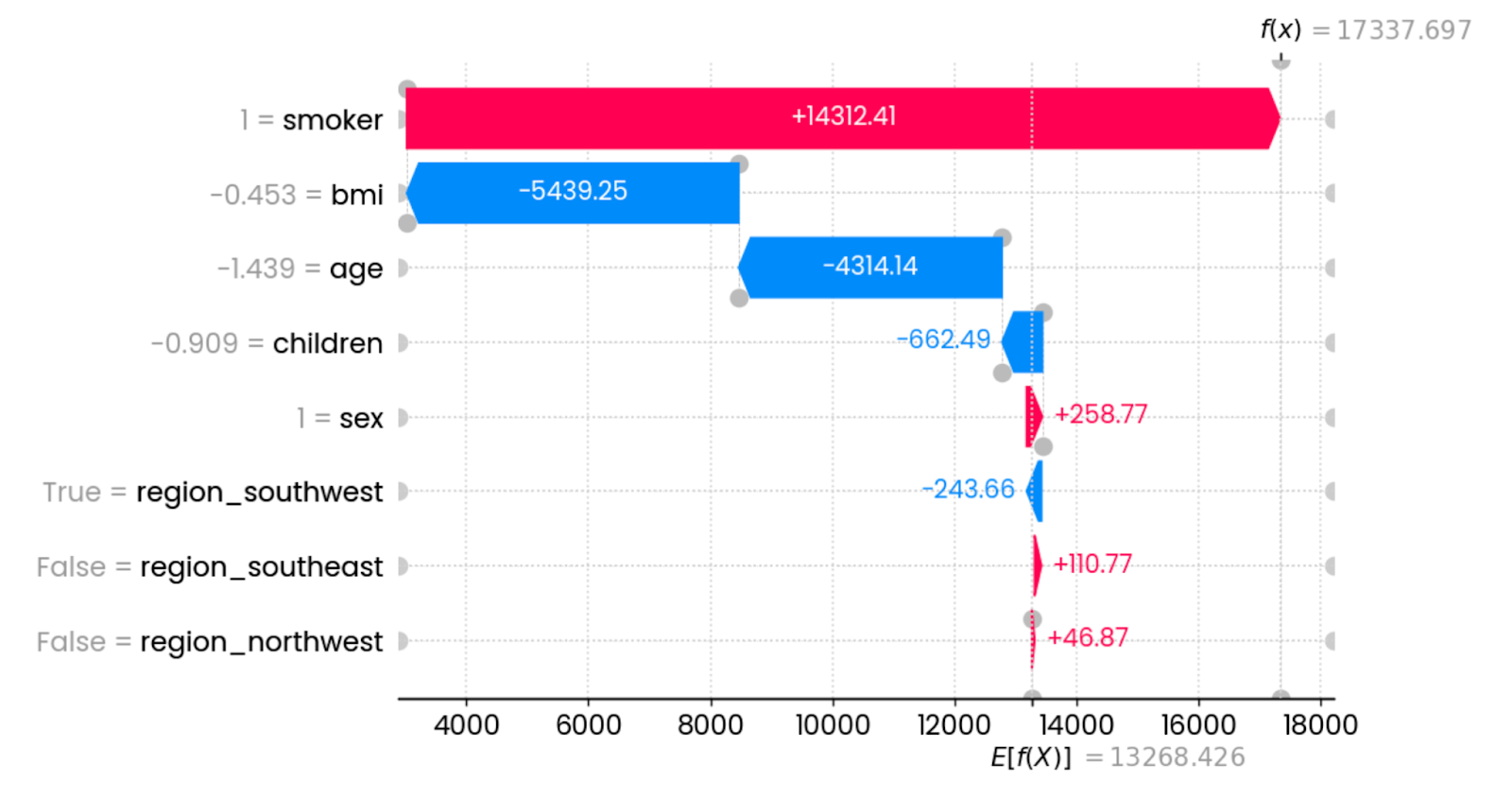
Explicaciones de la primera predicción. Imagen del autor.
En este caso concreto, ser fumador aumenta drásticamente los gastos del seguro. Las características que más influyen en la reducción de las cargas son el IMC (relacionado con el peso) y la edad. Otras características tienen un impacto mínimo o nulo.
Puedes representar el gráfico anterior en un formato más formato más compacto:
shap.plots.force(shap_values[0])
Explicaciones concisas de la primera predicción. Imagen del autor.
La información sigue siendo la misma: los rasgos rojos aumentan las cargas y los rasgos azules las reducen. El punto en el que se encuentran muestra los gastos del seguro para un solo caso.
El diagrama de abejas te muestra qué rasgos son los más importantes trazando los valores SHAP de cada rasgo para cada muestra. Los rasgos se ordenan por la suma de las magnitudes de los valores SHAP de todas las muestras. El color representa el valor de la característica (rojo significa alto y azul bajo):
shap.plots.beeswarm(shap_values)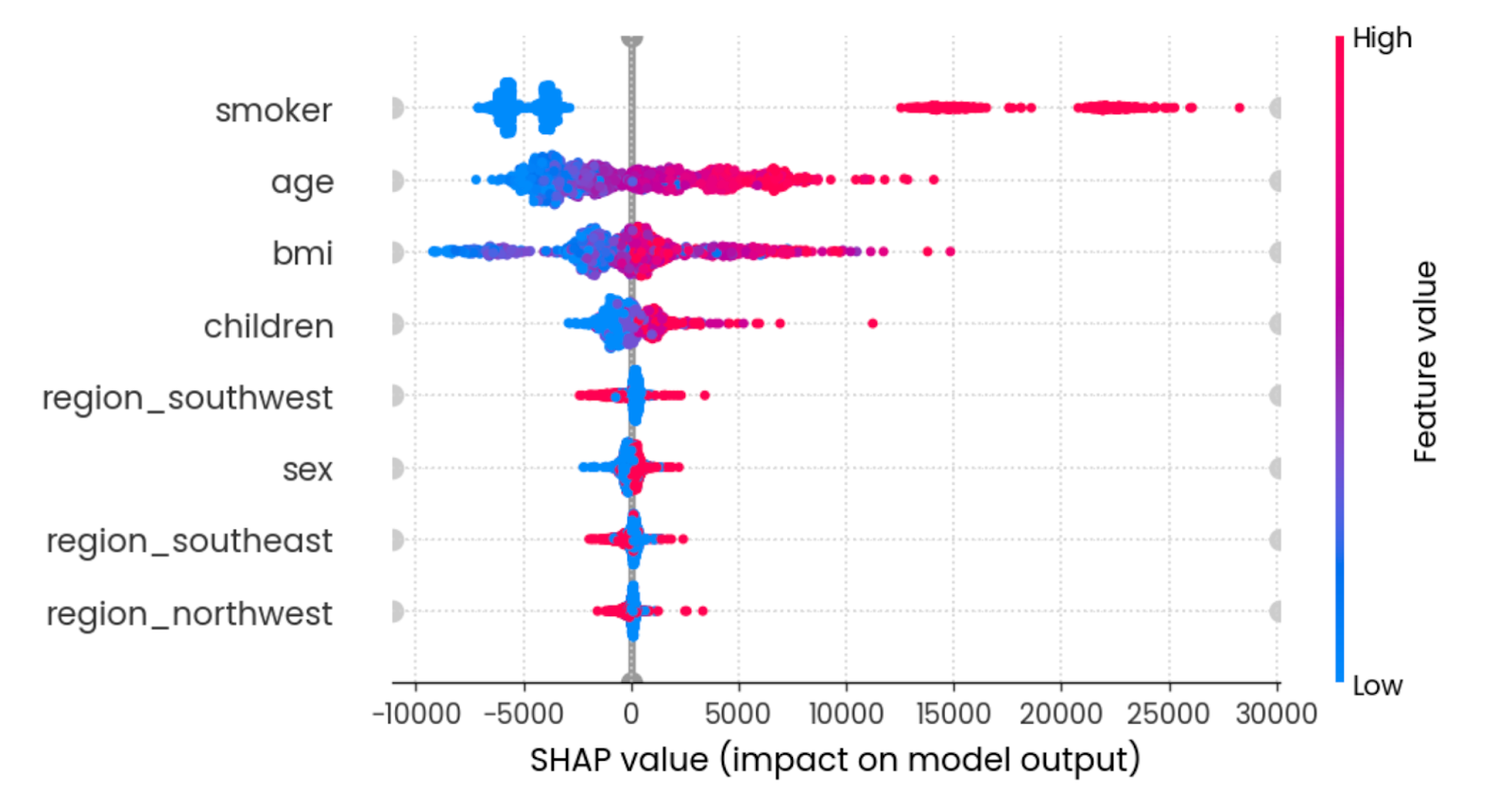
Efecto resumen de todas las funciones. Imagen del autor.
Para interpretarlo, ser un joven no fumador con un IMC razonable reduce los gastos del seguro.
La última visualización SHAP que quiero mostrar es el gráfico de barrasdel valor medio absoluto . Calcula el valor absoluto medio de todos los valores SHAP de cada característica:
shap.plots.bar(shap_values)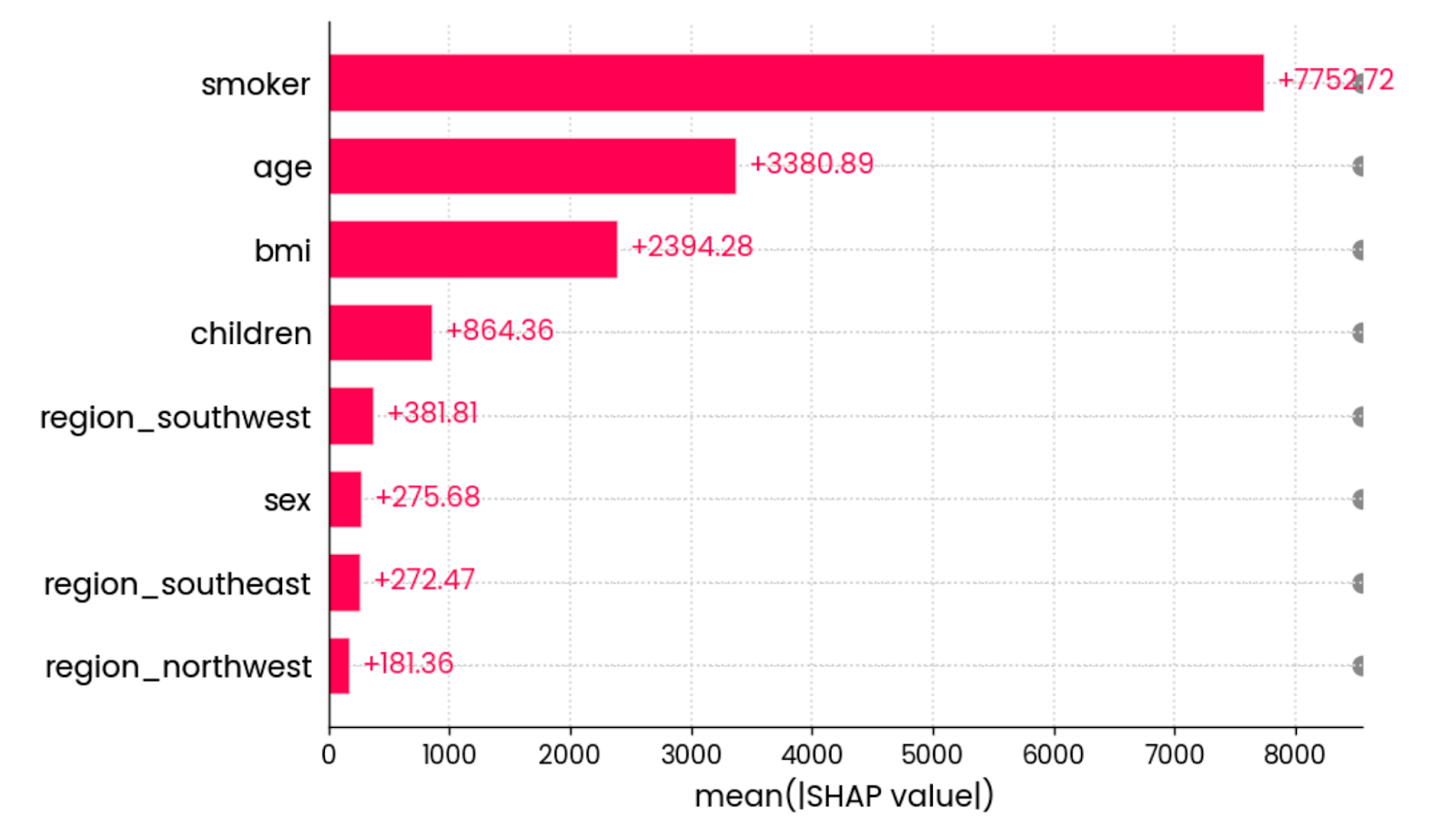
El valor absoluto medio de todos los valores SHAP de todas las características. Imagen del autor.
En otras palabras, es una forma elegante de calcular la importancia global de una característica: el gráfico no está vinculado a una predicción individual.
Y eso es todo para SHAP. A continuación me centraré en LIME.
Al igual que SHAP, LIME trata del aprendizaje automático interpretable.
No tiene tantos tipos de visualización en su haber, pero hace bien una cosa, al menos con conjuntos de datos tabulares.
A efectos de demostración, cargaré el conjunto de datos de clasificación y lo convertiré en una tarea de clasificación binaria sustituyendo las entradas en lista de espera por las denegadas. Así comprenderás mejor el rendimiento de LIME:
from lime import lime_tabular
df = load_classification_dataset()
# Convert to binary
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train.shape, y_test.shape
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)La clase LimeTabularExplainer() recibe ahora los datos de entrenamiento, los nombres de las columnas, los nombres de las categorías de la variable objetivo y el modo de aprendizaje automático (clasificación o regresión):
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=["Admit", "Deny"],
mode="classification"
)Una vez hecho esto, puedes llamar al método explain_instance() para interpretar una única predicción basada en las probabilidades de predicción de clase:
exp = explainer.explain_instance(
data_row=X_test.iloc[0],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)
Explicaciones de CAL (1). Imagen del autor.
El modelo LIME es un 96% seguro de que se denegará la admisión a este MBA. Características como gmat y gender fueron las que más influyeron en la decisión.
Hagamos ahora lo mismo para un caso admitido en el programa MBA:
exp = explainer.explain_instance(
data_row=X_test.iloc[234],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)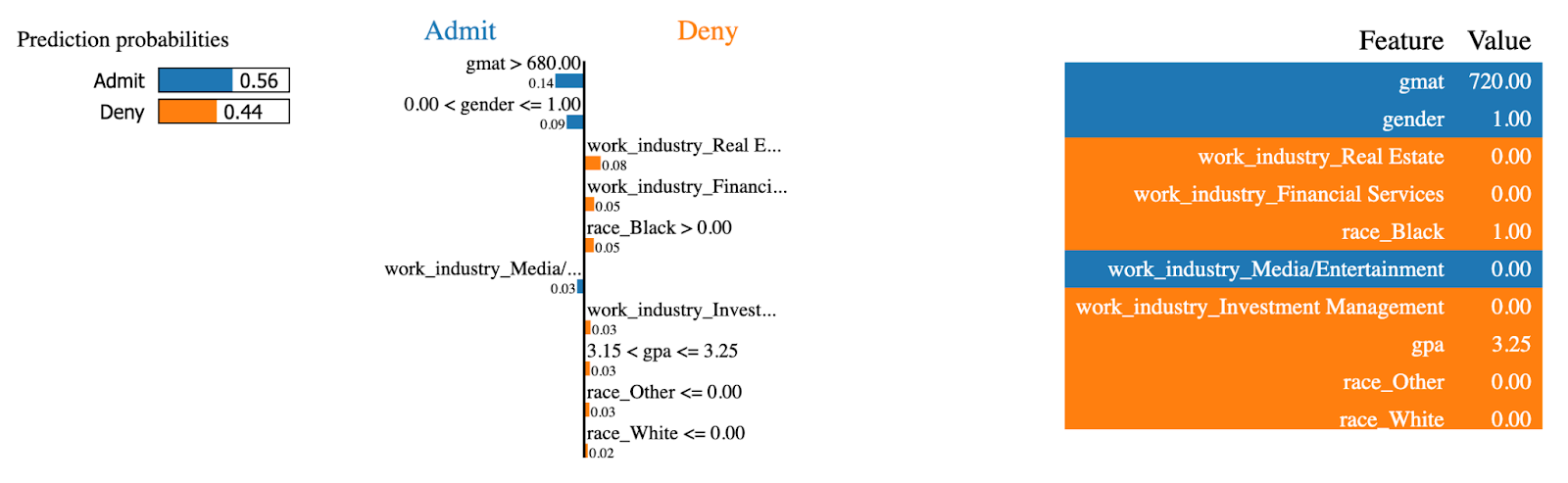
Explicaciones de CAL (2). Imagen del autor.
¡Las mismas características tenían ahora el efecto contrario! Esta persona tenía una puntuación alta en gmat, que es el factor que más contribuye a ser admitido en el programa de MBA.
¡Y eso es todo en cuanto a modelos de árboles! A continuación, aprenderás a visualizar modelos lineales para tareas de regresión.
Si te estás iniciando en el modelado predictivo, no hay nada más básico que la regresión lineal. Es un modelo sencillo, fácil de entender y que funciona bien, siempre que las relaciones de tu conjunto de datos sean lineales.
Ahora bien, existen otros modelos lineales, pero en esta sección sólo trabajaré con la regresión lineal.
Empieza cargando el conjunto de datos de regresión, dividiéndolo en subconjuntos de entrenamiento y de prueba, y ajustando un modelo de regresión lineal a la parte de entrenamiento:
from sklearn.linear_model import LinearRegression
df = load_regression_dataset()
X = df.drop("charges", axis=1)
y = df["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = LinearRegression().fit(X_train, y_train)El primer tipo de visualización que voy a explorar son los coeficientes del modelo.
En lenguaje llano, un modelo de regresión lineal se reduce a una única ecuación. Puede que recuerdes y = mx+b del instituto: la misma idea es válida.
La ecuación de regresión se amplía a y = w0 + w1_x1 + w2_x2 + … + wn_xn para dar cabida a múltiples parámetros. El objetivo del modelo es encontrar la mejor estimación de pesos (w) dado el conjunto de características de entrada (x).
Entonces, ¿por qué es importante?
Como puedes acceder a los coeficientes (pesos) después de entrenar el modelo y analizar su contribución, las características con un coeficiente mayor asociado a ellas tendrán una mayor contribución a la predicción de la variable objetivo.
Puedes obtener los coeficientes accediendo al parámetro coef_ en un modelo entrenado.
El siguiente fragmento obtiene los coeficientes y los representa en un gráfico de barras horizontales:
features = X_train.columns
coefficients = model.coef_
plt.figure(figsize=(10, 4))
bars = plt.barh(y=features, width=coefficients, edgecolor="#008031", linewidth=1)
for bar in bars:
width = bar.get_width()
plt.text(width + 1, bar.get_y() + bar.get_height()/2, f"{width:.2f}",
va="center", ha="left")
plt.xlabel("Coefficient value")
plt.title("Linear Regression Model Coefficients", y=1.05)
plt.show()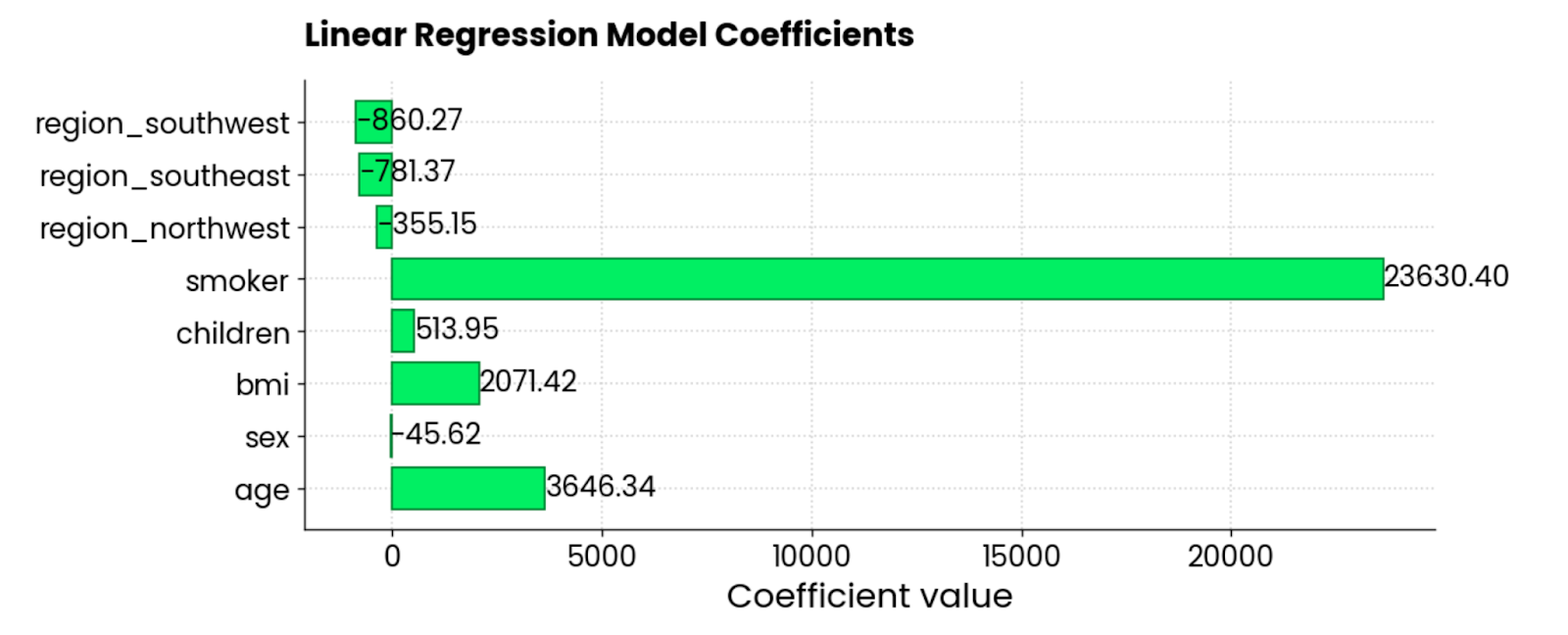
Coeficientes del modelo de regresión lineal. Imagen del autor.
Las características smoker, BMI, y age son las que más contribuyen positivamente a los gastos del seguro: cuando suben, también lo hace el importe. También hay un par de coeficientes negativos, lo que significa que reducen la cantidad total.
El otro tipo habitual de visualización de la regresión es el gráfico de residuos. En pocas palabras, estás haciendo undiagrama de dispersión de valores predichos en el eje X y residuos (valores verdaderos - valores predichos) en el eje Y.
Lo ideal es que no haya patrones visibles en los residuos y que estén centrados en torno a 0. En otras palabras, deben teneruna distribución normal .
Utiliza este fragmento de código para visualizar los residuos de un modelo de regresión lineal en el conjunto de datos de seguros:
y_pred = model.predict(X_test)
residuals = y_test - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, color="#03EF62", alpha=0.6, edgecolors="#008031")
plt.axhline(0, color="red", linestyle="--")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Values", y=1.05)
plt.grid(True)
plt.show()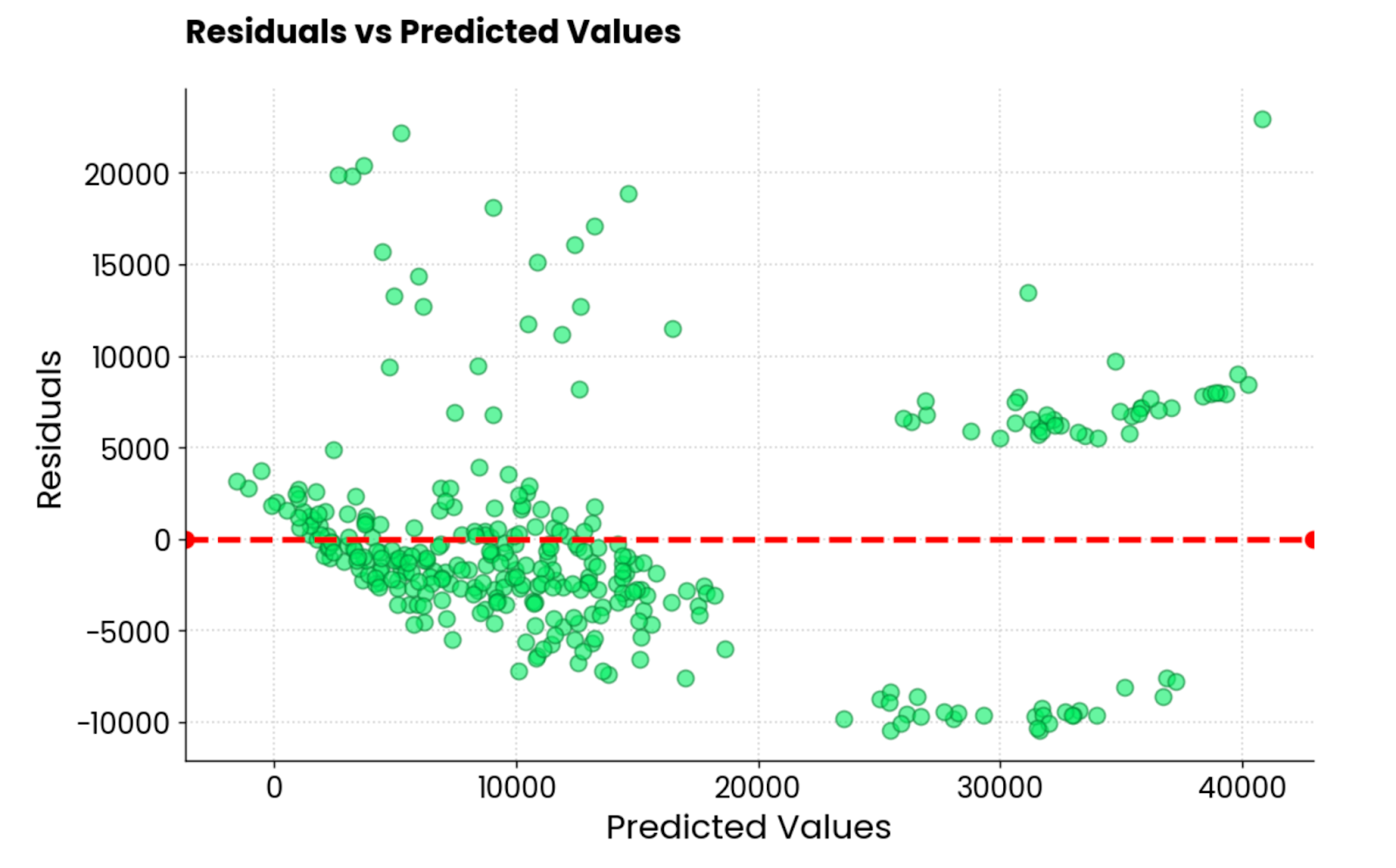
Residuos del modelo de regresión lineal. Imagen del autor.
No es la mejor trama residual que he visto. Estéticamente queda bien, pero los valores están por todas partes. Si eres un profesional del aprendizaje automático y obtienes un gráfico residual similar, tienes mucho trabajo por delante.
A continuación, te mostraré 3 formas de visualizar modelos de redes neuronales.
Si hay un área del aprendizaje automático en la que la visualización y la interpretación importan más, ésa tiene que ser la de las redes neuronales.
Es complejo entenderlos, incluso al nivel más básico. Tienes distintos tipos de capas, funciones de activación y retropropagación, por nombrar algunos. Por esta razón, las redes neuronales son a menudo sinónimos de modelos de caja negra.
No tiene por qué ser así.
En esta sección, te mostraré tres formas de visualizar las redes neuronales: gráficos de arquitectura, métricas de entrenamiento en tiempo real y Grad-CAM.
Mi biblioteca preferida es TensorFlow. Si nunca has oído hablar de él, ¡hemosve un curso de TensorFlow para principiantes que te hará empezar rápidamente!
Cuando visualices la arquitectura de tu modelo de red neuronal, conseguirás desmitificar una cosa: las formas.
En otras palabras, verás cómo se transforma el tamaño de la matriz subyacente al desplazarte por las capas. Puede ser un tema difícil para los recién llegados, así que cualquier visualización es más que bienvenida.
Para demostrarlo, utilizaré TensorFlow para crear un modelo básico de red neuronal para la clasificación de dígitos manuscritos. A continuación, utilizaré la función plot_model() para guardar la imagen de la arquitectura del modelo en un archivo local.
Compruébalo tú mismo:
from tensorflow.keras import layers, models
from tensorflow.keras.utils import plot_model
model = models.Sequential()
model.add(layers.Input(shape=(28, 28, 1)))
model.add(layers.Conv2D(32, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
plot_model(model, to_file="model_architecture.png", show_shapes=True, show_layer_names=True)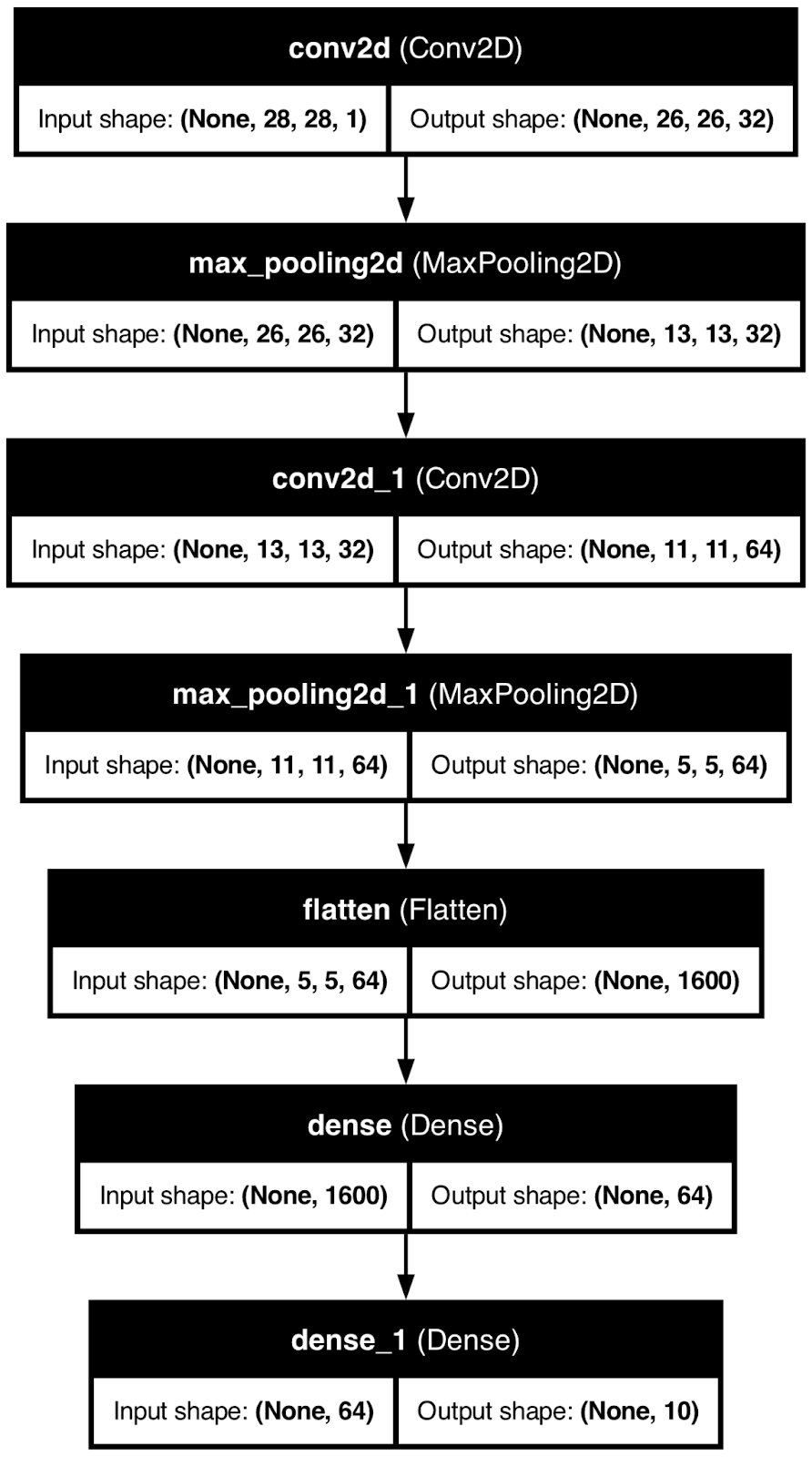
Arquitectura del modelo de red neuronal. Imagen del autor.
Aunque es útil, este tipo de visualización sólo puede llevarte hasta cierto punto.
Sabes cómo se transforman los datos por el camino, pero no tienes ni idea de cómo llega a sus conclusiones un modelo de red neuronal. Eso es lo que trataré a continuación.
Grad-CAM, o Mapeo de Activación de Clases de Gradiente es una técnica muy utilizada para visualizar modelos de redes neuronales convolucionales.
Para ser más precisos, te ayuda a comprender qué partes de una imagen de entrada contribuyen más a las predicciones del modelo. Piénsalo como un diagrama de importancia de características de un árbol de decisión, pero elevado al 11.
Es una técnica avanzada de interpretabilidad que funciona para todos los modelos convolucionales, independientemente de la arquitectura, y te ayuda a entender por qué un modelo de red neuronal hace una determinada predicción.
Pero aquí está el problema: no es algo trivial implementarlo en Python. Aquí tienes una visión general del algoritmo:
Es un proceso bastante complicado y, para facilitar las cosas, utilizaré un modelo preentrenado de ResNet50 que ya puede clasificar 1000 tipos de imágenes diferentes.
Pero antes, carga las bibliotecas necesarias y la imagen para la que quieras ver una Grad-CAM. Estoy utilizando una imagen de perro de stock:
import cv2
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import load_img
image = np.array(load_img("dog.jpg", target_size=(224, 224, 3)))
plt.grid(False)
plt.imshow(image)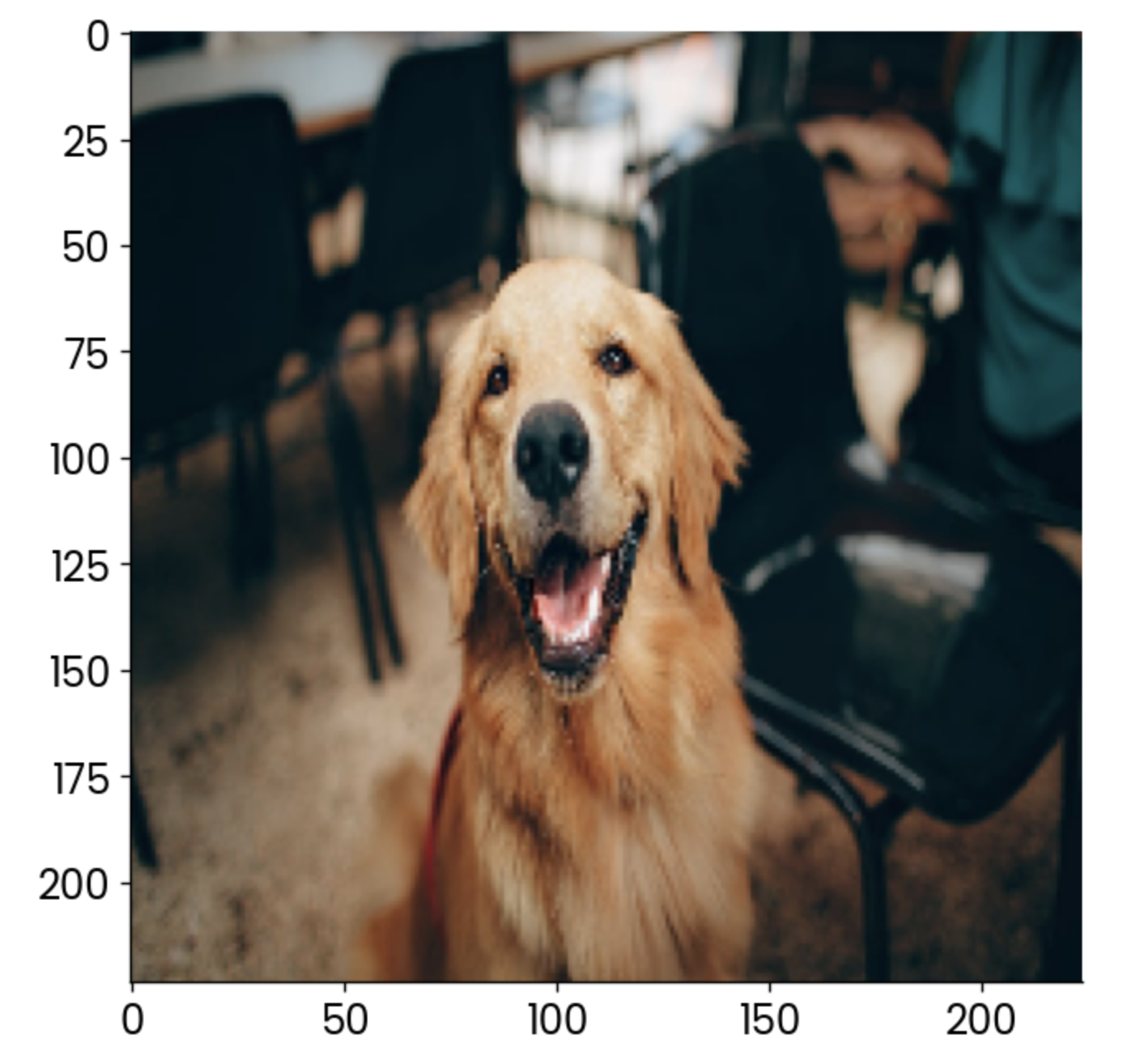
Ejemplo de imagen de perro. Imagen del autor.
Ahora empieza la parte divertida. En el siguiente fragmento de código, aplico el proceso de cuatro pasos descrito anteriormente. Encontrarás comentarios encima de cada línea de código para facilitar la comprensión:
# Load the pre-trained ResNet50 model
model = ResNet50()
# Extract the output of the last convolutional layer
last_conv_layer = model.get_layer("conv5_block3_out")
# Create a model that outputs the last convolutional layer’s activations
last_conv_layer_model = tf.keras.Model(model.inputs, last_conv_layer.output)
# Prepare the classifier model using the layers after the last convolutional layer
classifier_input = tf.keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in ["avg_pool", "predictions"]:
# Reuse the pooling and prediction layers from the ResNet50 model
x = model.get_layer(layer_name)(x)
# Create a new model that takes in the last conv layer output and returns predictions
classifier_model = tf.keras.Model(classifier_input, x)
# Use a GradientTape to record operations for automatic differentiation
with tf.GradientTape() as tape:
# Prepare the input image and get the activations from the last conv layer
inputs = image[np.newaxis, ...]
last_conv_layer_output = last_conv_layer_model(inputs)
tape.watch(last_conv_layer_output) # Watch the conv layer output
# Get predictions from the classifier model
preds = classifier_model(last_conv_layer_output)
# Get the index of the highest predicted class
top_pred_index = tf.argmax(preds[0])
# Focus on the prediction of the top class
top_class_channel = preds[:, top_pred_index]
# Compute the gradient of the top predicted class with respect to the conv layer output
grads = tape.gradient(top_class_channel, last_conv_layer_output)
# Average the gradients over the width and height dimensions
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# Multiply each channel in the conv layer output by its corresponding gradient
last_conv_layer_output = last_conv_layer_output.numpy()[0]
pooled_grads = pooled_grads.numpy()
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, i] *= pooled_grads[I]
# Compute the Grad-CAM by averaging the channels and apply a ReLU activation
gradcam = np.mean(last_conv_layer_output, axis=-1)
# Normalize the Grad-CAM to be between 0 and 1
gradcam = np.clip(gradcam, 0, np.max(gradcam)) / np.max(gradcam)
# Resize the Grad-CAM heatmap to the size of the original image (224x224)
gradcam = cv2.resize(gradcam, (224, 224))Era mucho, seguro, pero ahora por fin puedes trazar el mapa de calor producido por el algoritmo Grad-CAM:
plt.grid(False)
plt.imshow(gradcam)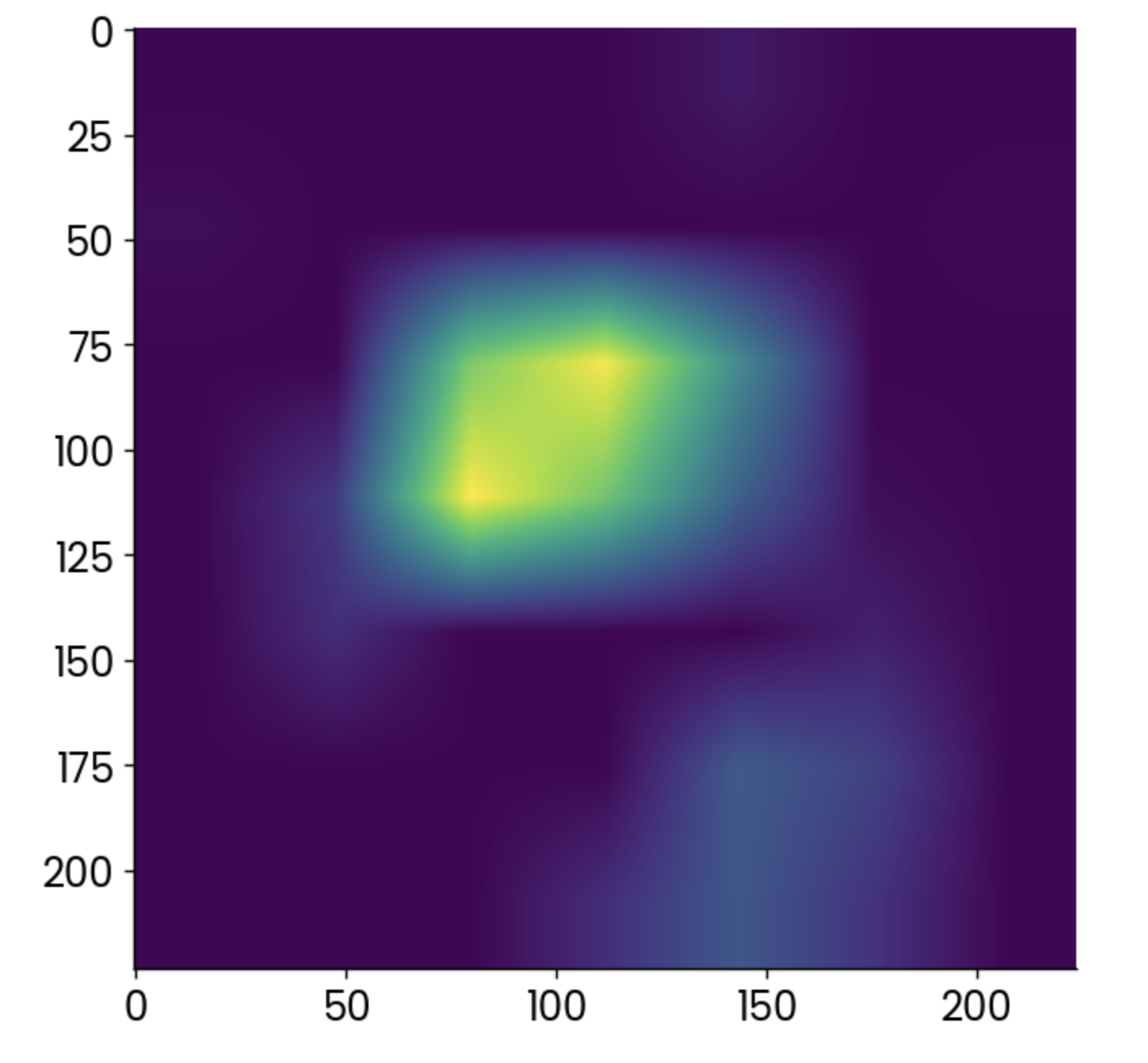
Mapa de calor Grad-CAM. Imagen del autor.
Los puntos más claros indican las zonas en las que la activación fue mayor, pero el mapa de calor por sí solo no te dice mucho.
Es mucho mejor que la superpongas sobre la imagen original y reduzcas ligeramente la opacidad:
plt.grid(False)
plt.imshow(image)
plt.imshow(gradcam, alpha=0.5)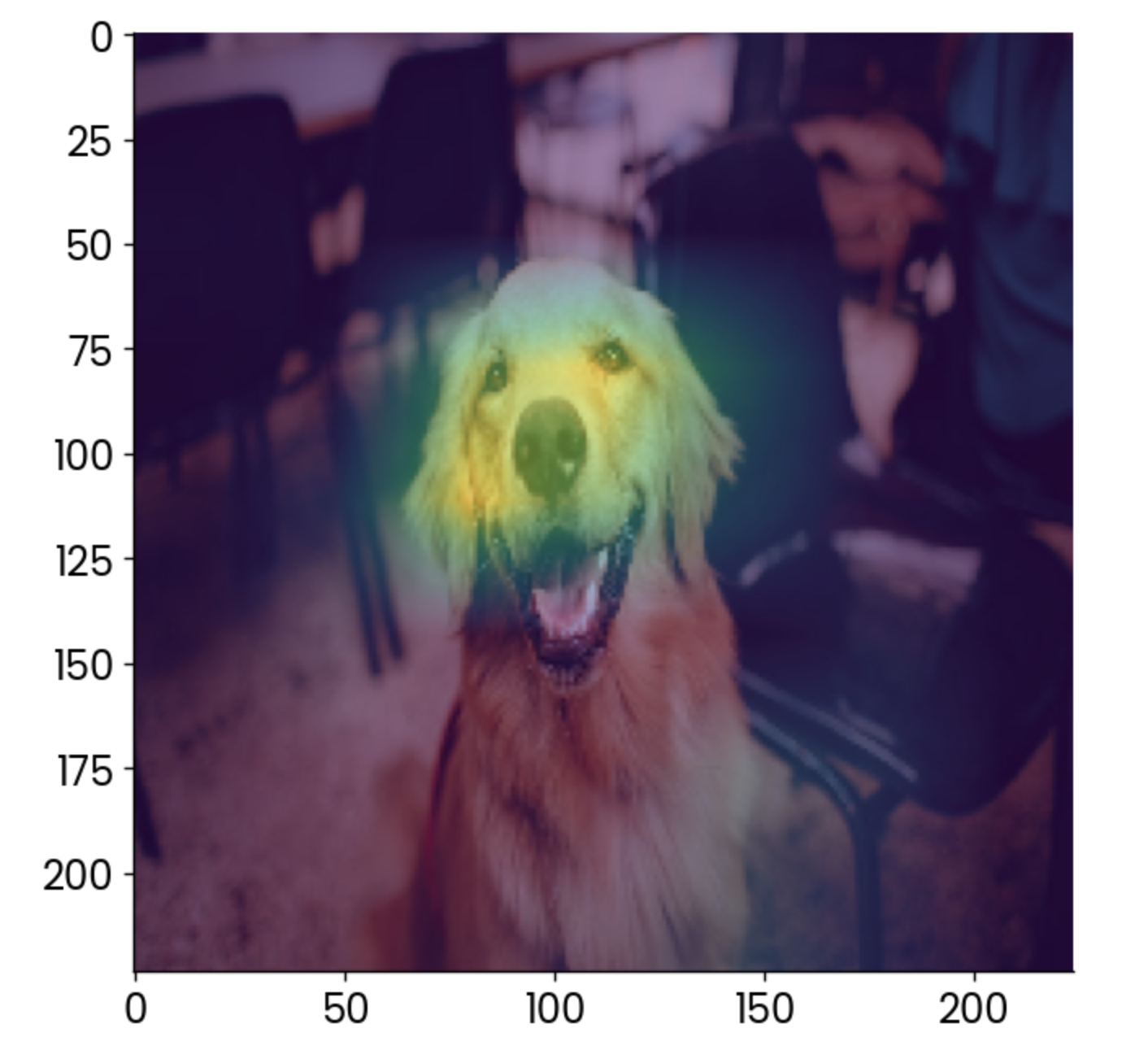
Imagen de un perro con una superposición de grad-CAM. Imagen del autor.
Para interpretarlo, lo que más contribuye a que esta imagen se clasifique como "golden retriever" es la cara, lo cual tiene sentido.
Puedes utilizar Grad-CAM para asegurarte de que tu modelo está haciendo predicciones de la forma correcta. En este caso, imagina que el mapa de calor muestra otra cosa, como la silla del fondo, como el factor que más contribuye. No te fiarías de ese modelo, ¿verdad?
Entrenar un modelo de red neuronal puede llevar mucho tiempo. Lo bueno es que no tienes que esperar a que termine el entrenamiento para echar un vistazo al rendimiento del modelo. Bibliotecas como TensorBoard pueden mostrártelo en tiempo real.
TensorBoard viene con TensorFlowpor lo que no tienes que instalar nada para seguirlo.
A modo de demostración, entrenaré un modelo clasificador de dígitos básico durante 25 épocas. La parte importante es lallamada a , enla que debes especificar la ruta y el formato de los registros de entrenamiento, que TensorBoard utilizará dentro de un minuto.
Este es el código que necesitarás para entrenar el modelo y almacenar los registros de entrenamiento:
import tensorflow as tf
from tensorflow.keras import layers, models
from datetime import datetime
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension (for the Convolutional layer)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# Build a simple CNN model
model = models.Sequential([
layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax")
])
# Compile the model
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
# Set up TensorBoard callback
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Train the model with TensorBoard monitoring
model.fit(
x_train,
y_train,
epochs=25,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]
)
Proceso de entrenamiento del modelo. Imagen del autor.
Mientras el modelo se está entrenando, ejecuta TensorBoard desde el terminal y especifica una ruta a la carpeta de registros de entrenamiento:
tensorboard --logdir=logs/fitTensorBoard se ejecutará en el puerto 6006 por defecto:
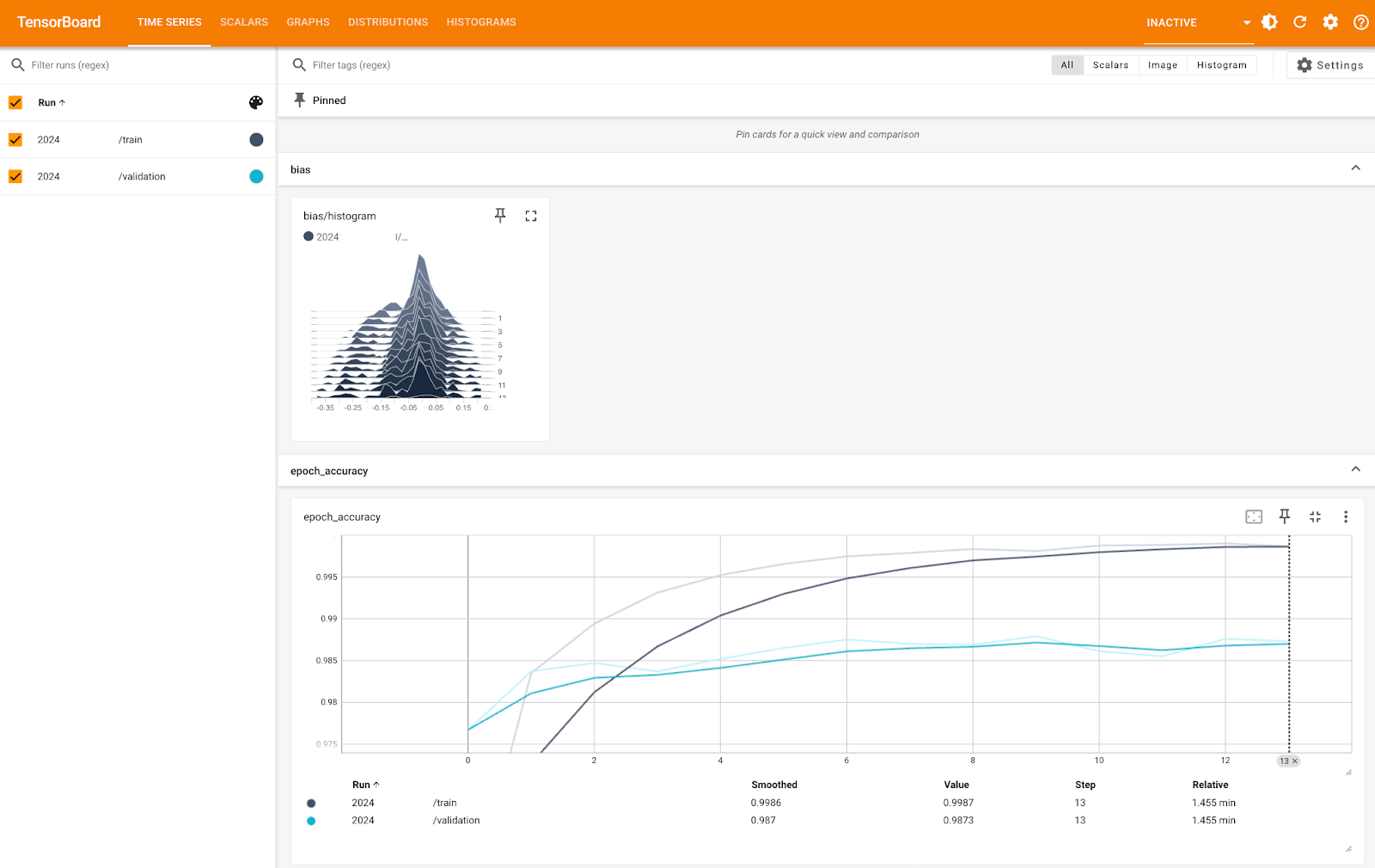
Métricas de TensorBoard (1). Imagen del autor.
La imagen de arriba te muestra el histograma de sesgo y la precisión por época, tanto para los conjuntos de entrenamiento como de validación. Puedes ver que la precisión es muy alta en ambos casos, cercana al 100%; sólo la escala del eje Y es demasiado pequeña.
Otras pestañas profundizarán en métricas más específicas y te permitirán ajustar ciertas cosas, como puedes ver a continuación:
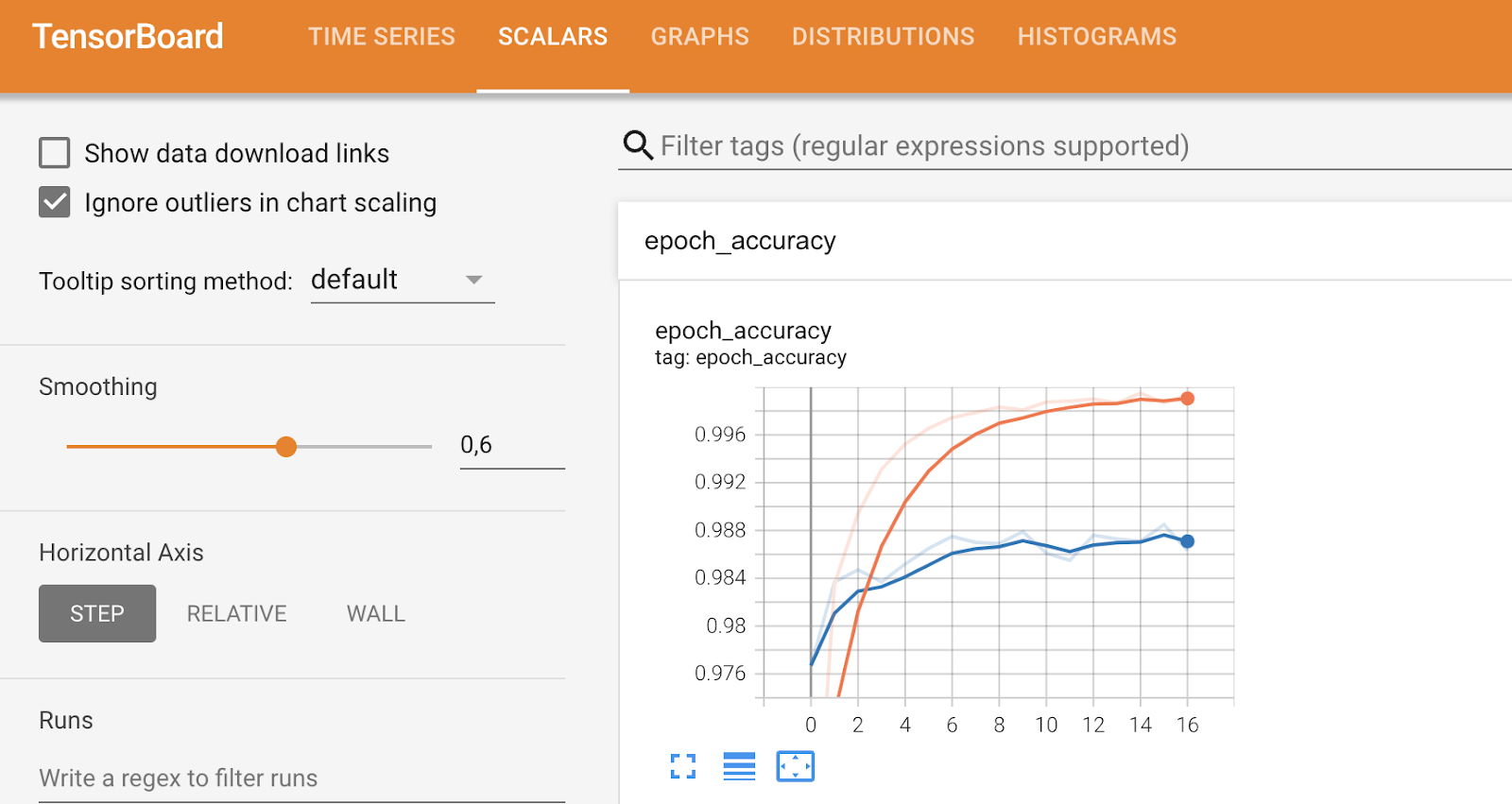
Métricas de TensorBoard (2). Imagen del autor.
Para concluir, TensorBoard es una herramienta de visualización del rendimiento del modelo muy útil y puede ayudarte a analizar el rendimiento mientras el modelo se está entrenando.
En esta última parte, quiero dar un paso atrás y sumergirme en métricas más generales para visualizar el rendimiento del modelo.
Verás tres de ellos: matriz de confusión, gráfico de la curva ROC y gráfico de la curva Precisión-Recuperación.
Como están vinculados a problemas de clasificación, tendrás que cargar el conjunto de datos declasificación MBA. Para facilitar las cosas, también lo he convertido en un problema de clasificación binaria estableciendo las entradas en lista de espera como denegadas. El resto del fragmento de código divide los datos en subconjuntos de entrenamiento y de prueba, y primero un modelo de clasificación de bosque aleatorio:
from sklearn.ensemble import RandomForestClassifier
df = load_classification_dataset()
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
df["admission"] = df["admission"].replace({"Deny": 0, "Admit": 1})
df.rename(columns={"admission": "is_admitted"}, inplace=True)
X = df.drop("is_admitted", axis=1)
y = df["is_admitted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Sumerjámonos en la primera métrica: la matriz de confusión.
Una matriz de confusión te indica el rendimiento de tu modelo. En un escenario ideal, los valores de la diagonal superior izquierda a la inferior derecha serían los únicos elementos distintos de cero, lo que indicaría que el modelo no hizo ninguna predicción falsa.
Pero eso no ocurre a menudo en el mundo real.
Utiliza las siguientes pautas para interpretar una matriz de confusión (para clasificación binaria):
No hay una regla general sobre si debes preocuparte más por los falsos positivos o por los falsos negativos. Lo anterior es más doloroso en el caso de las admisiones de MBA, ya que el modelo clasificaba al alumno admitido, pero no era así en la realidad. En otros casos, comola predicción del cáncer , es vital minimizar el número de falsos negativos, ya que no quieres declarar a alguien sano cuando tiene cáncer.
Ahí es donde entra en juego el conocimiento del dominio.
En fin, volvamos al código. El siguiente fragmento de código calcula la matriz de confusión de nuestro modelo de bosque aleatorio en el conjunto de pruebas y utiliza la clase ConfusionMatrixDisplay para crear una visualización:
from sklearn.metrics import confusion_matrix
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
preds = random_forest.predict(X_test)
cm = confusion_matrix(y_true=y_test, y_pred=preds, labels=random_forest.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=random_forest.classes_)
disp.plot()
plt.grid(False)
plt.title("Confusion Matrix", y=1.04)
plt.show()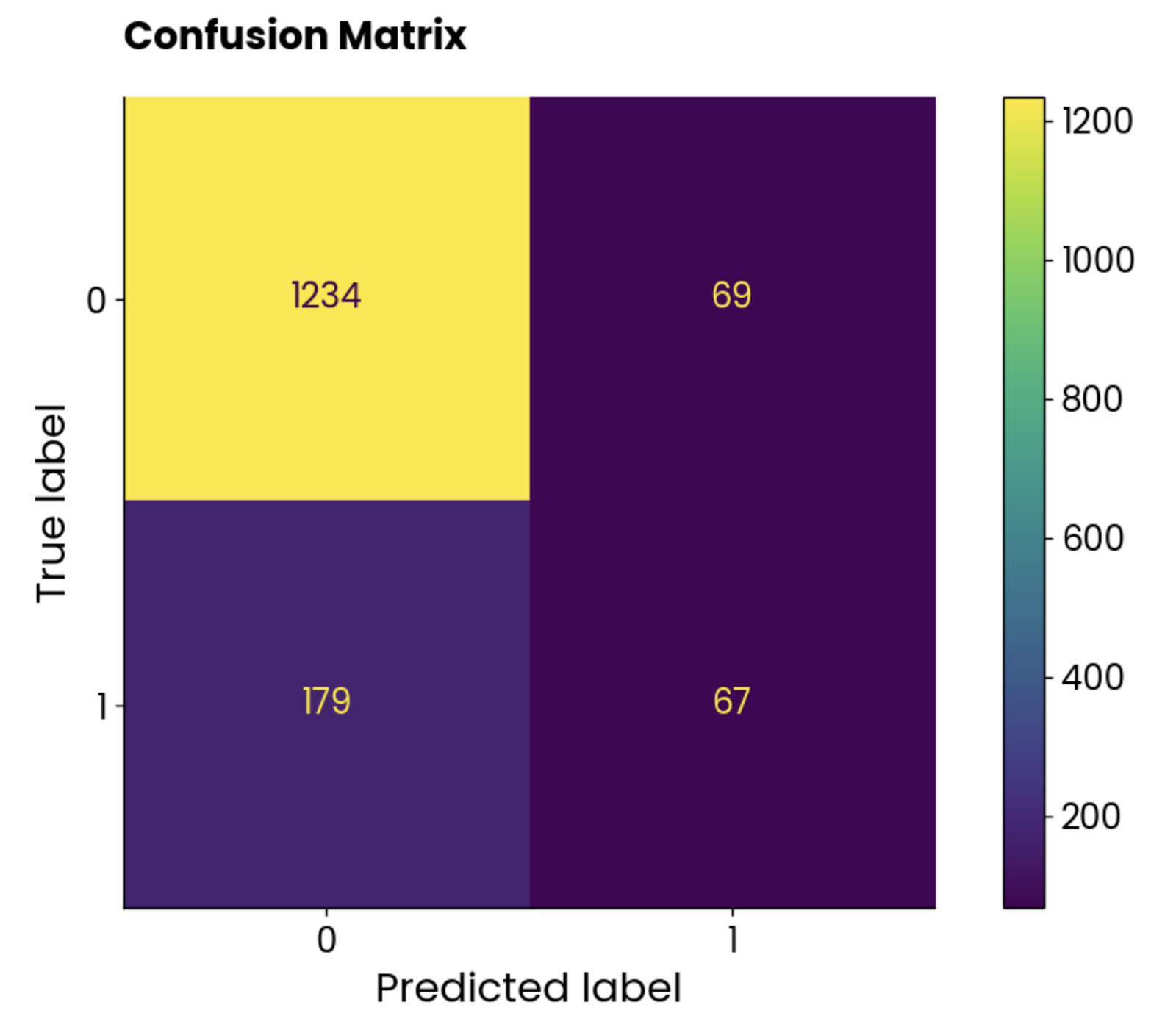
Diagrama de matriz de confusión. Imagen del autor.
Las clases no están equilibradas, pero el número de predicciones incorrectas es asombrosamente alto.
Veamos qué dice la curva ROC.
ROC significa Receiver Operating Characteristics, y es una curva que muestra la evaluación del rendimiento de un modelo de clasificación binaria. En el caso de la clasificación multiclase, tendrás que comparar dos clases a la vez.
La curva ROC muestra un equilibrio entre una tasa de verdaderos positivos (TPR, sensibilidad, recuerdo) y una tasa de falsos positivos (FPR) a través de diferentes umbrales de clasificación. El TPR se representa en el eje Y frente al FPR en el eje X. Cada punto representa un umbral diferente para la decisión de clasificación (puntuación de probabilidad utilizada para clasificar una instancia como positiva o negativa).
La curva suele trazarse contra una diagonal de (0, 0) a (1, 1), que representa un clasificador aleatorio.
Si la curva está por encima de la diagonal, significa que tu modelo funciona mejor que un clasificador aleatorio. Un único valor escalar lo resume. Se llama AUC (Área bajo la curva) y oscila entre 0 y 1, siendo mayor mejor y 0,5 aleatorio.
En resumen, quieres curvarte lo más cerca posible de la esquina superior izquierda.
Utiliza el siguiente fragmento para calcular el ROC y el AUC y trazar la curva:
from sklearn.metrics import roc_curve, auc
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
fpr, tpr, roc_thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.2f}")
plt.plot([0, 1], [0, 1], color="navy", linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve", y=1.04)
plt.legend(loc="lower right")
plt.show()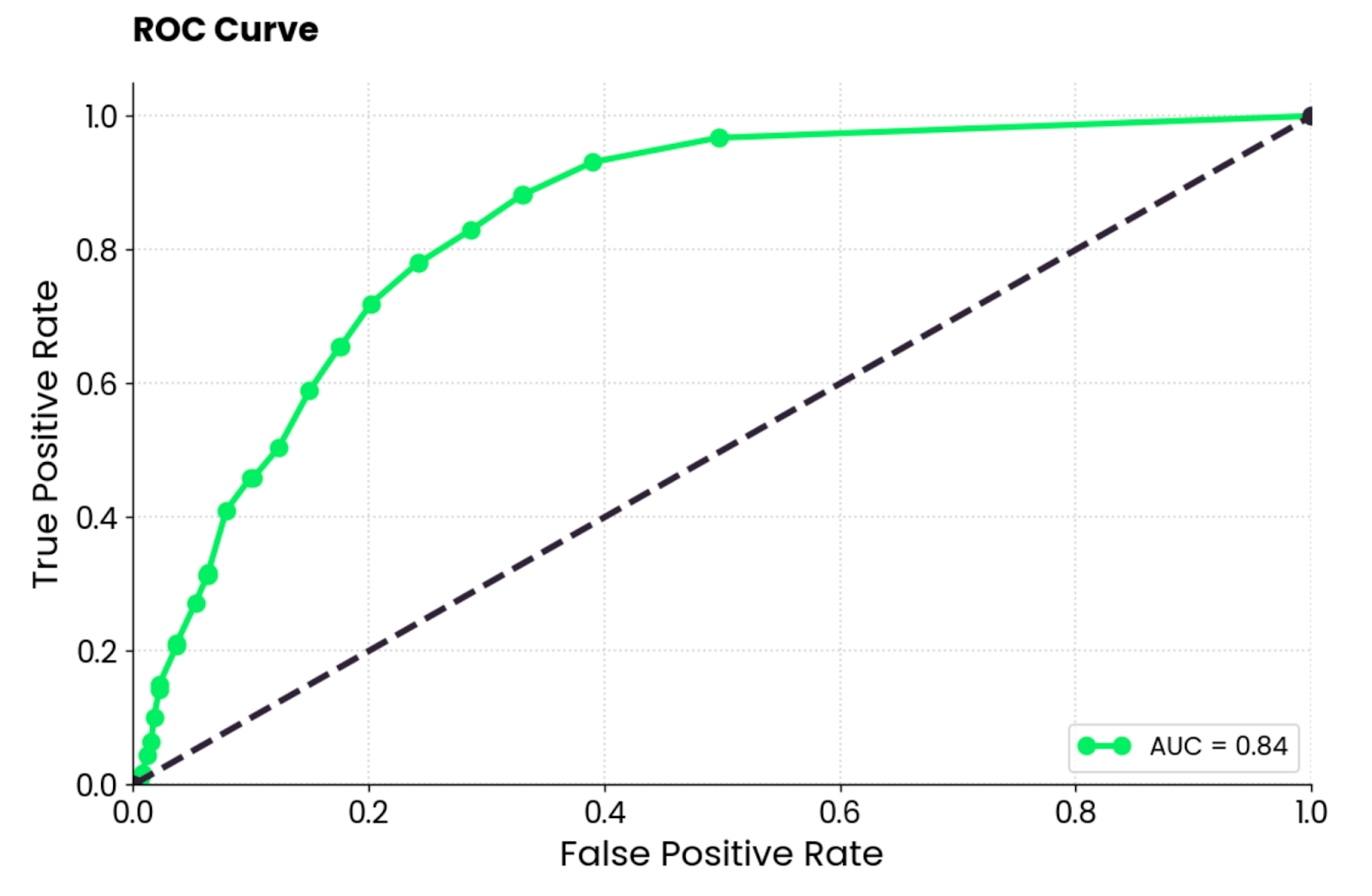
Gráfico de la curva ROC. Imagen del autor.
Para interpretarlo, el modelo de bosque aleatorio es mucho mejor que un clasificador aleatorio y tiene un equilibrio razonable entre verdaderos positivos y falsos positivos. Sigue habiendo cierto grado de clasificación errónea, y debes intentar elevar la curva hacia arriba y hacia la izquierda optimizando los datos o eligiendo un modelo de aprendizaje automático diferente.
Esta curva es similar a la curva ROC, pero muestra el compromiso entre precisión y recuerdo para distintos umbrales de clasificación. Muestra la precisión en el eje Y y la recuperación en el eje X, y suele preferirse al ROC cuando las clases están desequilibradas.
Esto es lo que ocurre en el conjunto de datos de las admisiones a los MBA, ¡así que una curva de relaciones públicas parece encajar perfectamente!
Es importante señalar que las curvas de precisión-recuerdo se centran sólo en la clase minoritaria y proporcionan una mejor imagen de lo bien que el modelo identifica las instancias que más importan (estudiantes admitidos, cánceres detectados, etc.).
Utiliza el siguiente fragmento para calcular los valores de precisión y recuperación y representarlos en un gráfico:
from sklearn.metrics import precision_recall_curve
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
# Precision-Recall curve
precision, recall, pr_thresholds = precision_recall_curve(y_test, y_probs)
pr_auc = auc(recall, precision)
plt.plot(recall, precision, label=f"(AUC = {pr_auc:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve", y=1.04)
plt.legend(loc="lower left")
plt.show()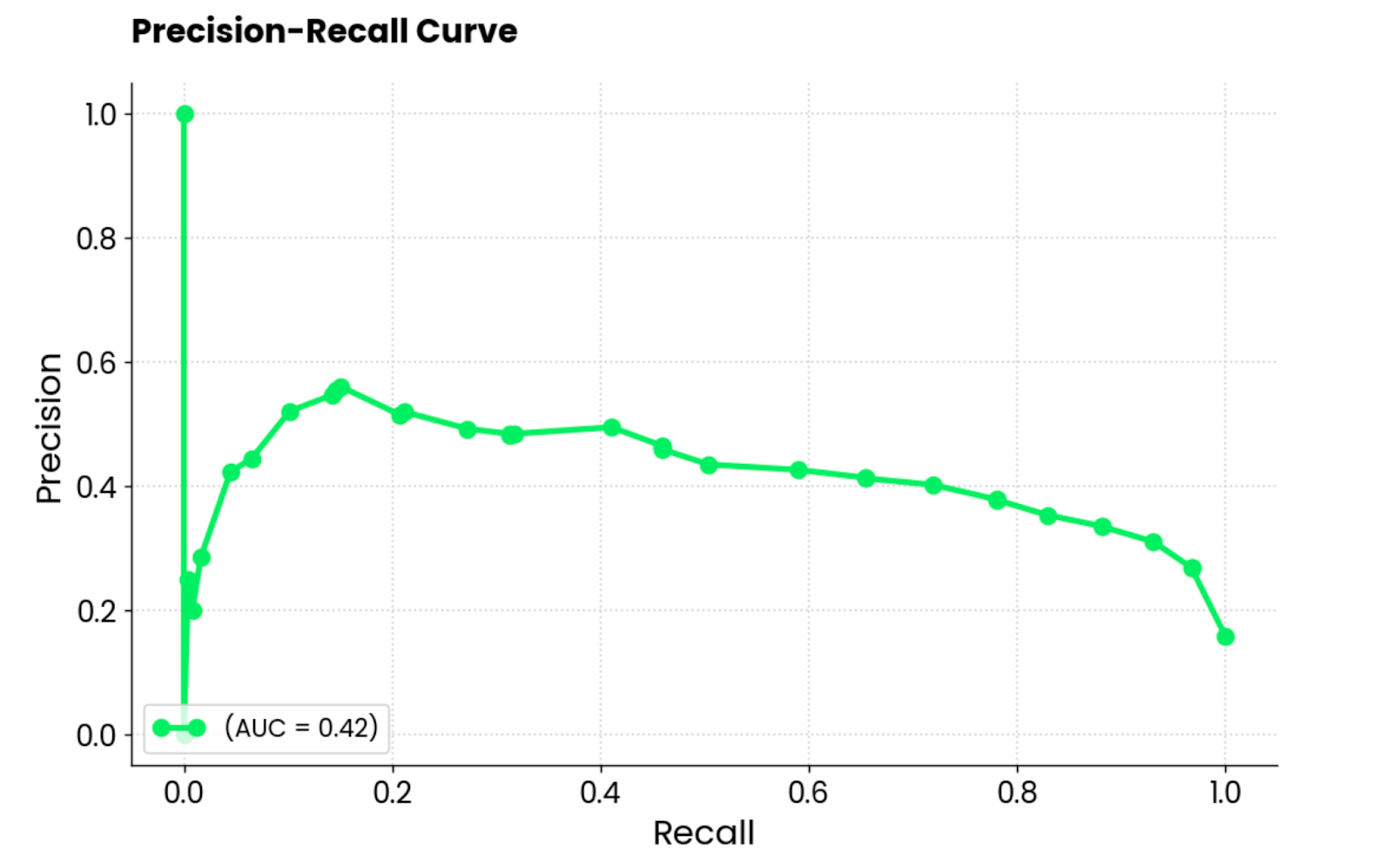
Gráfico de la curva de precisión-recuerdo. Imagen del autor.
Para interpretarlo, el modelo funciona mal, como indica la puntuación AUC de 0,42. Cuando el modelo intenta aumentar el recuerdo, sacrifica demasiada precisión, lo que da lugar a muchos falsos positivos. En resumen, este modelo no está bien adaptado a este conjunto de datos, o el propio conjunto de datos no está preprocesado adecuadamente.
Para concluir, el campo del aprendizaje automático es complejo y a menudo poco intuitivo. Si eres principiante, te costará asimilar las grandes ideas. Si trabajas con un cliente empresarial, es probable que no entienda la jerga tecnológica.
La visualización de datos ayuda a salvar las distancias en ambos escenarios.
Hoy has visto los distintos tipos de gráficos que puedes utilizar para visualizar modelos de regresión y clasificación, así como el proceso de decisión de las redes neuronales y la interpretación de predicciones únicas mediante SHAP y LIME. Es mucho que procesar, así que no dudes en volver a leer este artículo varias veces.
Si eres completamente nuevo en el tema, te recomendamos que veas nuestro curso de fundamentos del aprendizaje automático para empezar. Después, un curso más aplicado con Python es una gran opción.
Si tienes algo de experiencia pero no entiendes cómo funciona todo a gran escala, te animamos a que pruebes nuestro curso de aprendizaje automático para producción.
Aprende más sobre aprendizaje automático con estos cursos
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
Tutorial
Avinash Navlani
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
