
Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
Nesta breve seção, mostrarei a você como instalar as dependências de todo o sistema e as bibliotecas Python necessárias para visualizar os modelos de aprendizado de máquina.
A única dependência de todo o sistema que você precisará para acompanhar o processo é o Graphviz. Você o usará mais tarde para visualizar uma árvore de decisão, e o código não funcionará sem o Graphviz instalado.
É um software de código aberto usado para criar diagramas, gráficos abstratos e redes. Você não o usará diretamente, apenas por meio do scikit-Learn.
Essa biblioteca Python é amplamente usada para tarefas de aprendizado de máquina em Python.
Neste artigo, você o usará para treinar modelos de aprendizado de máquina, dividir conjuntos de dados, dimensionar recursos numéricos e visualizar o desempenho do modelo. Ele é indispensável, portanto, instale-o com o seguinte comando (dependendo do seu ambiente Python):
pip install scikit-learn
conda install scikit-learnSe você for completamente novo no scikit-learn, recomendamos que assista ao nosso popular curso sobre aprendizado de máquina supervisionado.
A biblioteca SHAP em Python é uma ferramenta popular para explicar as previsões dos modelos de aprendizado de máquina. Ele aproveita os conceitos da teoria dos jogos (por exemplo, Shapely values) para medir a contribuição de cada atributo para a previsão do modelo.
Melhor ainda, ele está repleto de visualizações úteis que ajudam você a entender o funcionamento interno dos seus modelos.
Instale-o com o seguinte comando:
pip install shap
conda install -c conda-forge shapEssa biblioteca Python é usada por muitos quando a explicação de uma previsão de modelo único é crucial. Ele funciona de forma diferente do SHAP. Ele aproxima o modelo original localmente com um modelo interpretável e mais simples. Em seguida, ele mostra a contribuição de cada recurso do conjunto de dados para a previsão.
Você verá como o LIME funciona em um minuto, mas, primeiro, instale-o:
pip install lime
conda install conda-forge::limeSe você estiver criando modelos de rede neural com o TensorFlow, o TensorBoard é uma opção óbvia.
É uma ferramenta de visualização que ajuda você a acompanhar os experimentos de aprendizado de máquina e monitorar as métricas de treinamento (por exemplo, perda e precisão). Ele visualiza e atualiza os gráficos do modelo para você em tempo real e mostra como os parâmetros do modelo mudam durante o treinamento.
O TensorBoard pode ser usado com outras estruturas de aprendizagem profunda, como o PyTorch, mas, neste artigo, vou me concentrar no TensorFlow.
Instale-o executando o seguinte comando:
pip install tensorboard
conda install -c conda-forge tensorboardA etapa final dessa fase de preparação é cuidar dos dados.
Hoje, usarei dois conjuntos de dados: Admissões de MBA para classificação e Seguros para regressão. Ambos são de uso gratuito e estão disponíveis para download na Kaggle.
Para começar, importe essas bibliotecas Python:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitQuanto ao conjunto de dados de classificação, o pré-processamento de dados que fiz foi mínimo. Isso se resume a:
Não se trata, de forma alguma, de um pipeline de pré-processamento de dados abrangente. Se você tiver tempo, sinta-se à vontade para aprimorá-lo.
No entanto, copie essa função para colocar o conjunto de dados de classificação em ordem:
def load_classification_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/taweilo/mba-admission-dataset?resource=download
df = pd.read_csv("MBA.csv")
# Just an arbitrary ID
df = df.drop(["application_id"], axis=1)
# Fill unknown
df["race"] = df["race"].fillna("Unknown")
# Assume these are denied
df["admission"] = df["admission"].fillna("Deny")
# Convert boolean cols to 0/1
df["gender"] = df["gender"].replace({"Male": 0, "Female": 1})
df["international"] = df["international"].replace({False: 0, True: 1})
# Create dummy columns for categorical features
cols_for_dummy = ["major", "race", "work_industry"]
for col in cols_for_dummy:
dummies = pd.get_dummies(df[col], prefix=col)
df = pd.concat([df, dummies], axis=1)
# To drop
cols_to_drop = ["major", "race", "work_industry", "major_Humanities", "race_Unknown", "work_industry_Other"]
df = df.drop(cols_to_drop, axis=1)
return df
load_classification_dataset().sample(5)
Uma amostra do conjunto de dados modificado da MBA. Imagem do autor.
Agora farei o mesmo com o conjunto de dados de regressão.
O conjunto de dados de regressão escolhido contém um valor de seguro ($) como um recurso contínuo que o modelo de aprendizado de máquina tentará prever com base em outros atributos.
O pré-processamento de dados que fiz foi, mais uma vez, mínimo. Isso se resume a:
Se você tiver tempo, sinta-se à vontade para adicionar mais etapas ao pipeline.
Copie a seguinte função para carregar e pré-processar o conjunto de dados de seguro:
def load_regression_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/mirichoi0218/insurance
df = pd.read_csv("MedicalCostPersonal.csv")
# Scale numerical features
cols_to_scale = ["age", "bmi", "children"]
scaler = StandardScaler()
df[cols_to_scale] = scaler.fit_transform(df[cols_to_scale])
# Binary features
df["sex"] = df["sex"].replace({"male": 0, "female": 1})
df["smoker"] = df["smoker"].replace({"no": 0, "yes": 1})
# Dummies
dummies_region = pd.get_dummies(df["region"], prefix="region", drop_first=True)
df = pd.concat([df, dummies_region], axis=1)
df = df.drop("region", axis=1)
return df
load_regression_dataset().sample(5)
Uma amostra do conjunto de dados de seguro modificado. Imagem do autor.
E é isso!
Na seção a seguir, mostrarei a você como começar a visualizar modelos de aprendizado de máquina.
Os modelos baseados em árvores são usados com frequência para classificação, mas a maioria deles também pode lidar com tarefas de regressão.
Nesta seção, mostrarei a você como visualizar uma árvore de decisão, a importância do recurso de um modelo de floresta aleatória e explicações de previsão com SHAP e LIME.
Lembre-se de que os modelos de árvore de decisão e floresta aleatória podem ser difíceis de entender. Temos um curso completo que abrange os fundamentos dos modelos de aprendizado de máquina baseados em árvores em Python.
Para começar, carregue o conjunto de dados de classificação e divida-o em subconjuntos de treinamento e teste:
df = load_classification_dataset()
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)A seguir, vamos visualizar uma árvore de decisão!
Pense em uma árvore de decisão como um conjunto de instruções if aninhadas nas quais as condições são determinadas por um modelo de aprendizado de máquina.
A história tem mais detalhes, mas com essa analogia, você pode ver que a visualização de decisões deve ser um processo simples. E é: a função plot_tree() do site sklearn faz a maior parte do trabalho pesado.
Comece treinando um modelo de árvore de decisão. O parâmetro max_depth é opcional e está aqui apenas para fins de visualização. Sem isso, aárvore ficará muito profunda e você se perderá no grande volume de decisões que o modelo toma, especialmente em conjuntos de dados maiores.
O snippet a seguir treina o modelo de classificação da árvore de decisão no subconjunto de treinamento:
from sklearn import tree
decision_tree = tree.DecisionTreeClassifier(random_state=42, max_depth=4)
decision_tree.fit(X_train, y_train)E para visualização, basta copiar o seguinte trecho. Os parâmetros opcionais filled e feature_names facilitam a interpretação da árvore:
plt.figure(figsize=(12,8))
tree.plot_tree(decision_tree, filled=True, feature_names=X.columns, class_names=y.unique())
plt.title("Decision Tree Visualization", size=20, loc="left", y=1.04, weight="bold")
plt.show()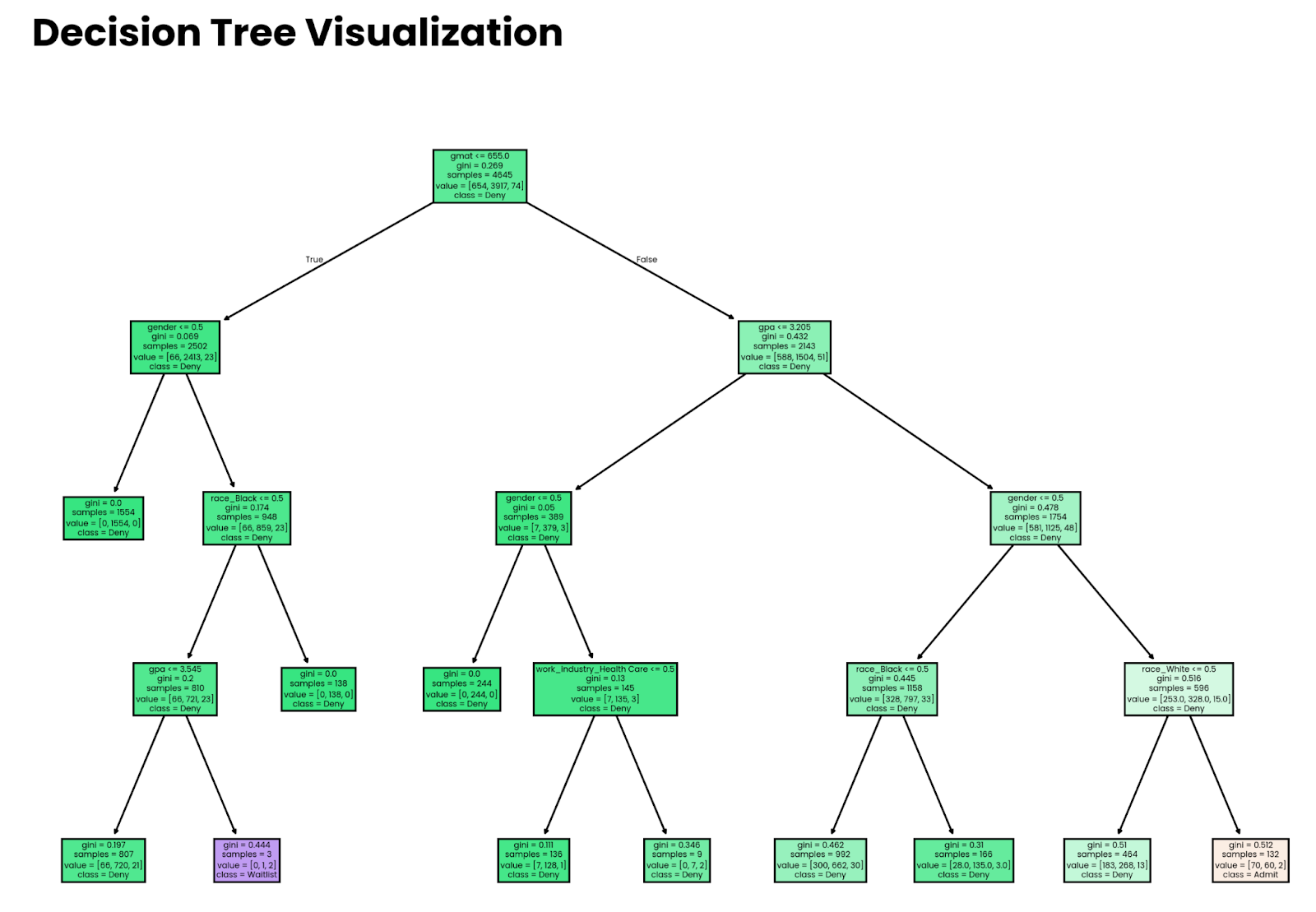
Árvore de decisão profunda de quatro níveis. Imagem do autor.
Observe que as decisões tomadas pelo modelo não significam nada se o modelo não for preciso. Mais adiante neste artigo, mostrarei a você como estimar a precisão.
Você se lembra da analogia com o bolo que fizemos anteriormente? É hora de você colocar isso em prática.
Sempre que você treina um modelo de árvore com sklearn, obtém acesso à propriedade feature_importances_. Combine isso com os nomes dos recursos e você terá todos os dados necessários para ver quais atributos contribuem mais para a previsão.
Vamos ver isso em ação! Primeiro, treine um classificador de floresta aleatória no subconjunto de treinamento:
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)A visualização agora se resume a extrair e classificar as importâncias dos recursos e substituir os índices por nomes de recursos:
importances = random_forest.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
bars = plt.bar(range(X.shape[1]), importances[indices], edgecolor="#008031", linewidth=1)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, height, f"{height:.2f}", ha="center", va="bottom", size=8)
plt.title("Feature Importances", size=20, loc="left", y=1.04, weight="bold")
plt.ylabel("Importance")
plt.xticks(range(X.shape[1]), np.array(X.columns)[indices], rotation=90, size=12)
plt.show()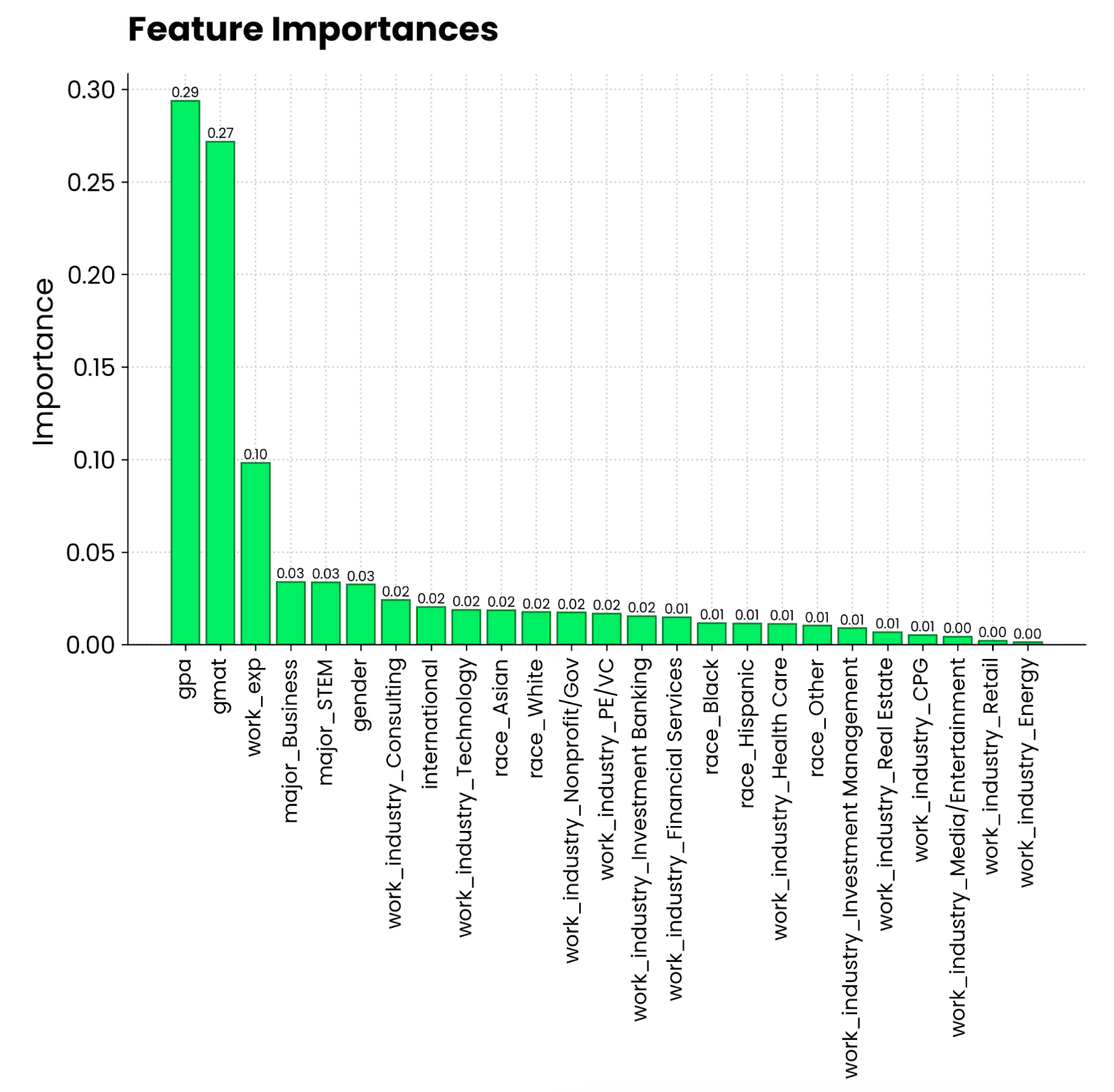
Gráfico de importância de recursos da floresta aleatória. Imagem do autor.
Parece que a média de notas em uma escala de 4,0 e a pontuação no GMAT são as que mais contribuem para que você seja admitido em um programa de MBA. Depois disso, vem a experiência profissional, que é um requisito para os estudos de MBA. O que a pessoa se formou e o setor em que está trabalhando são muito menos relevantes.
A importância dos recursos mostra o quadro geral, mas e se você quiser visualizar os modelos de aprendizado de máquina em um nível de previsão individual?
É aí que entram o SHAP e o LIME. Primeiro, falarei sobre o SHAP. Você já sabe o que é, então vou pular a teoria.
Ajustarei um modelo de aumento de gradiente em nosso conjunto de dados de regressão para ver o impacto que os recursos individuais têm sobre as taxas de seguro. O trecho a seguir mostra a você como ajustar o modelo e calcular os valores de SHAP a partir de um modelo shap.Explainer():
import shap
from xgboost import XGBRegressor
df = load_regression_dataset()
# No need for train-test splits
X = df.drop("charges", axis=1)
y = df["charges"]
model = XGBRegressor().fit(X, y)
# Shap explainer
explainer = shap.Explainer(model)
shap_values = explainer(X)Com o SHAP, há um conjunto de plotagens que você pode fazer.
Começarei com waterfall() e examinarei os valores de SHAP para a primeira previsão:
shap.plots.waterfall(shap_values[0])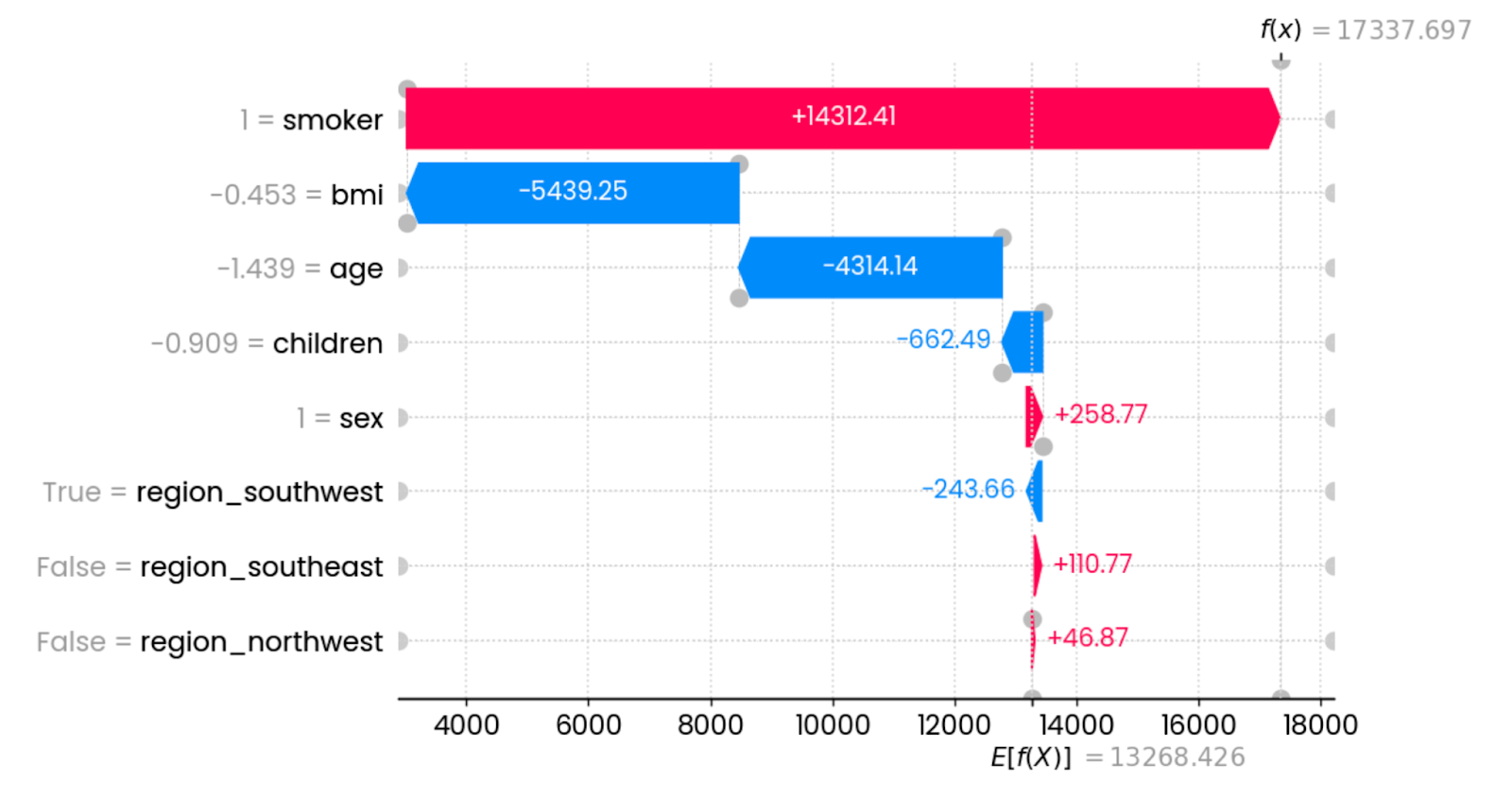
Explicações da primeira previsão. Imagem do autor.
Nesse caso específico, o fato de você ser fumante aumenta drasticamente as taxas de seguro. As características que têm o maior impacto na redução das taxas são o IMC (relacionado ao peso) e a idade. Outros recursos têm impacto mínimo ou nenhum impacto.
Você pode representar o gráfico acima em um formato mais mais compacto:
shap.plots.force(shap_values[0])
Explicações concisas sobre a primeira previsão. Imagem do autor.
A informação ainda é a mesma: os recursos vermelhos aumentam as cobranças e os recursos azuis as reduzem. O ponto em que eles se encontram mostra as taxas de seguro para uma única instância.
O gráfico beeswarm mostra a você quais recursos são mais importantes, plotando os valores SHAP de cada recurso para cada amostra. Os recursos são classificados pela soma das magnitudes do valor SHAP em todas as amostras. A cor representa o valor do recurso (vermelho significa alto e azul significa baixo):
shap.plots.beeswarm(shap_values)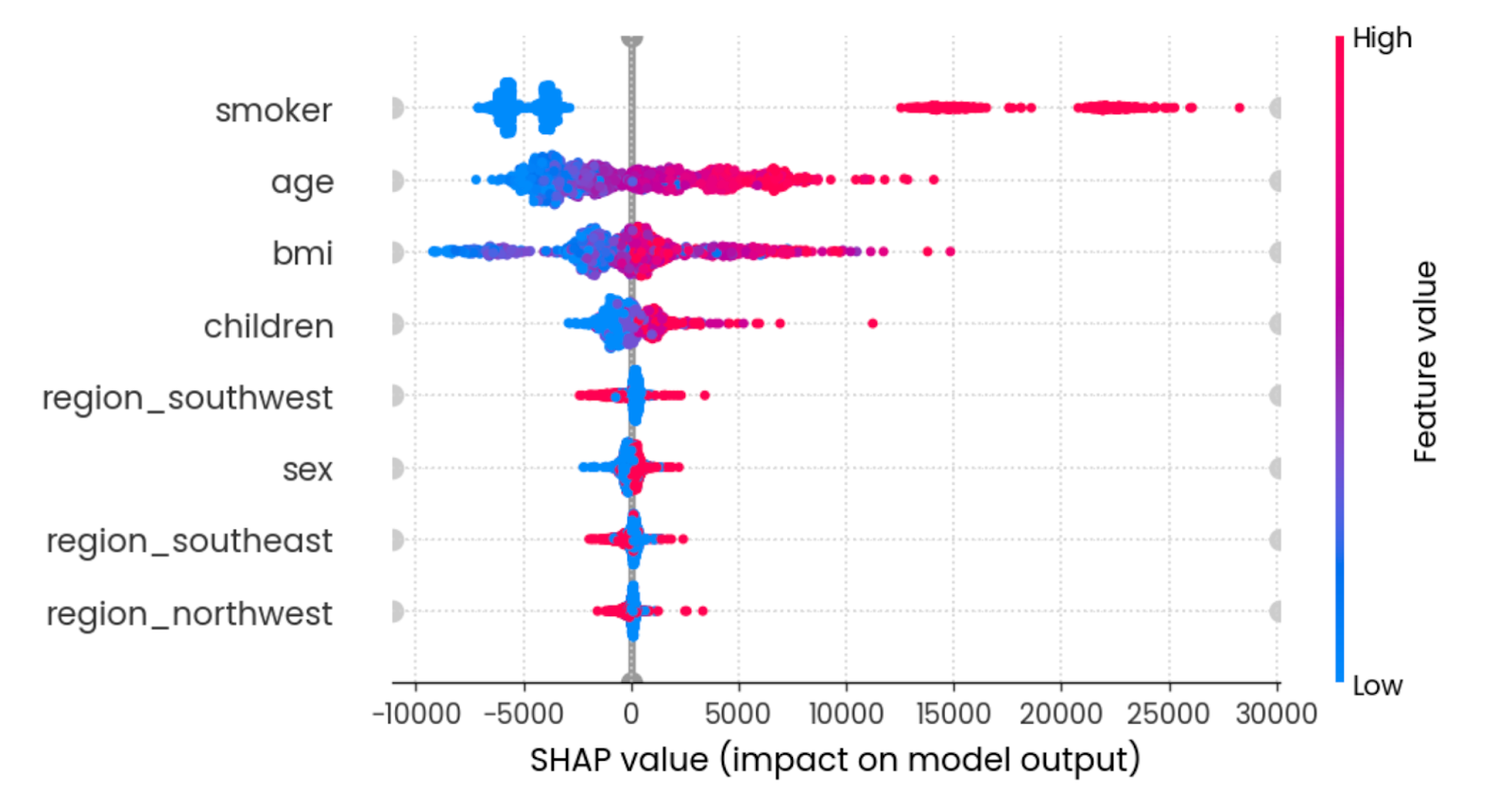
Efeito de resumo de todos os recursos. Imagem do autor.
Para interpretar, ser um jovem não fumante com um IMC razoável reduz as taxas de seguro.
A visualização final do SHAP que quero mostrar é o gráfico de barras devalor absoluto médio . Ele calcula o valor absoluto médio de todos os valores de SHAP para cada recurso:
shap.plots.bar(shap_values)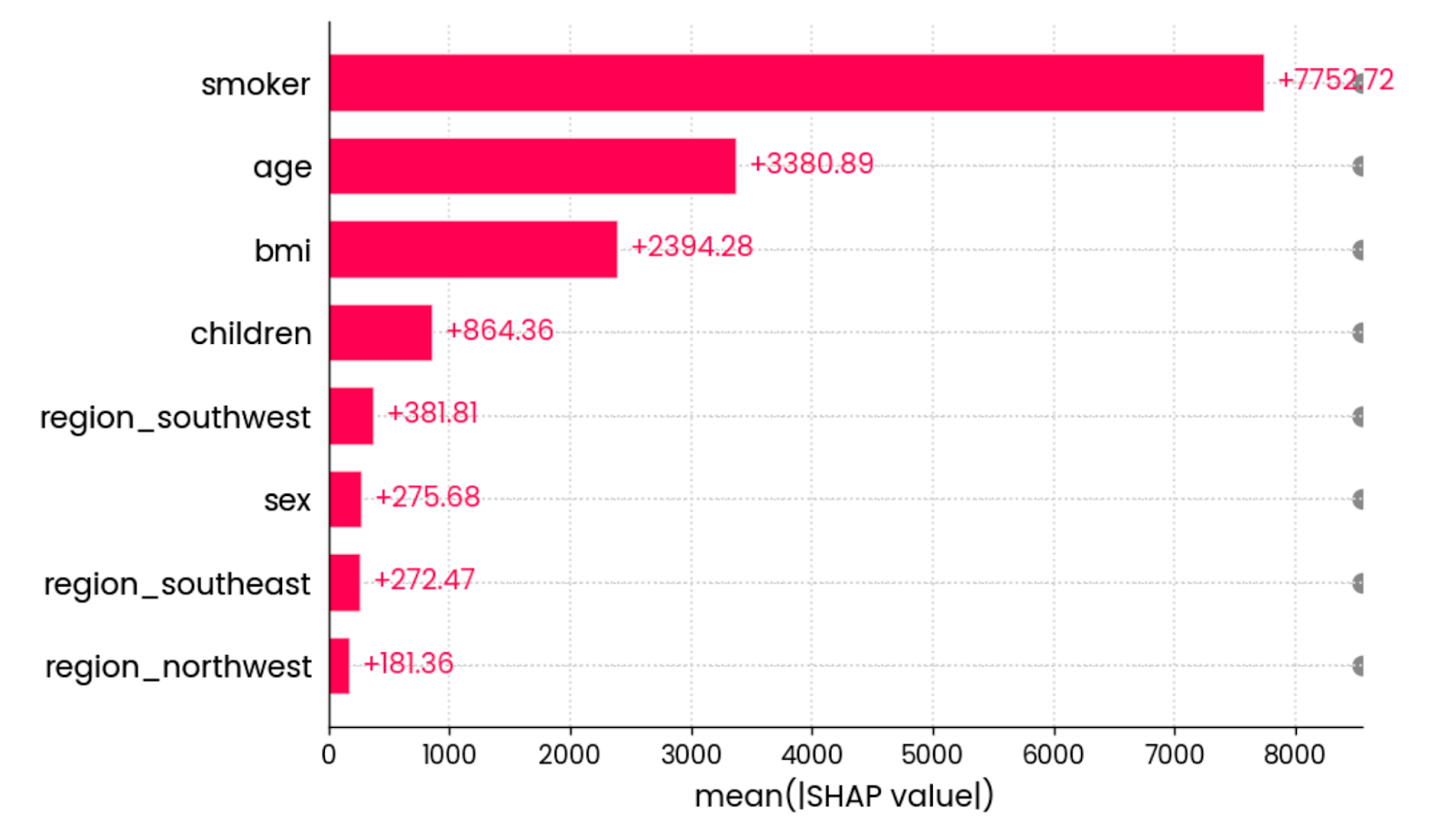
O valor absoluto médio de todos os valores de SHAP para todos os recursos. Imagem do autor.
Em outras palavras, é uma maneira sofisticada de calcular a importância global do recurso - o gráfico não está vinculado a uma previsão individual.
E isso é tudo para o SHAP. Em seguida, mudarei o foco para a LIME.
Assim como o SHAP, o LIME tem tudo a ver com aprendizado de máquina interpretável.
Ele não tem tantos tipos de visualização em seu conjunto de ferramentas, mas faz uma coisa muito bem, pelo menos com conjuntos de dados tabulares.
Para fins de demonstração, carregarei o conjunto de dados de classificação e o converterei em uma tarefa de classificação binária, substituindo as entradas em lista de espera por entradas negadas. Assim, você terá mais facilidade para entender a saída do LIME:
from lime import lime_tabular
df = load_classification_dataset()
# Convert to binary
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train.shape, y_test.shape
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)A classe LimeTabularExplainer() agora recebe dados de treinamento, nomes de colunas, nomes das categorias na variável de destino e o modo de aprendizado de máquina (classificação ou regressão):
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=["Admit", "Deny"],
mode="classification"
)Uma vez feito isso, você pode chamar o método explain_instance() para interpretar uma única previsão com base nas probabilidades de previsão de classe:
exp = explainer.explain_instance(
data_row=X_test.iloc[0],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)
Explicações sobre o LIME (1). Imagem do autor.
O modelo LIME tem 96% de certeza de que essa admissão ao MBA será negada. Recursos como gmat e gender tiveram o maior impacto na decisão.
Vamos agora fazer o mesmo para uma instância que foi admitida no programa de MBA:
exp = explainer.explain_instance(
data_row=X_test.iloc[234],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)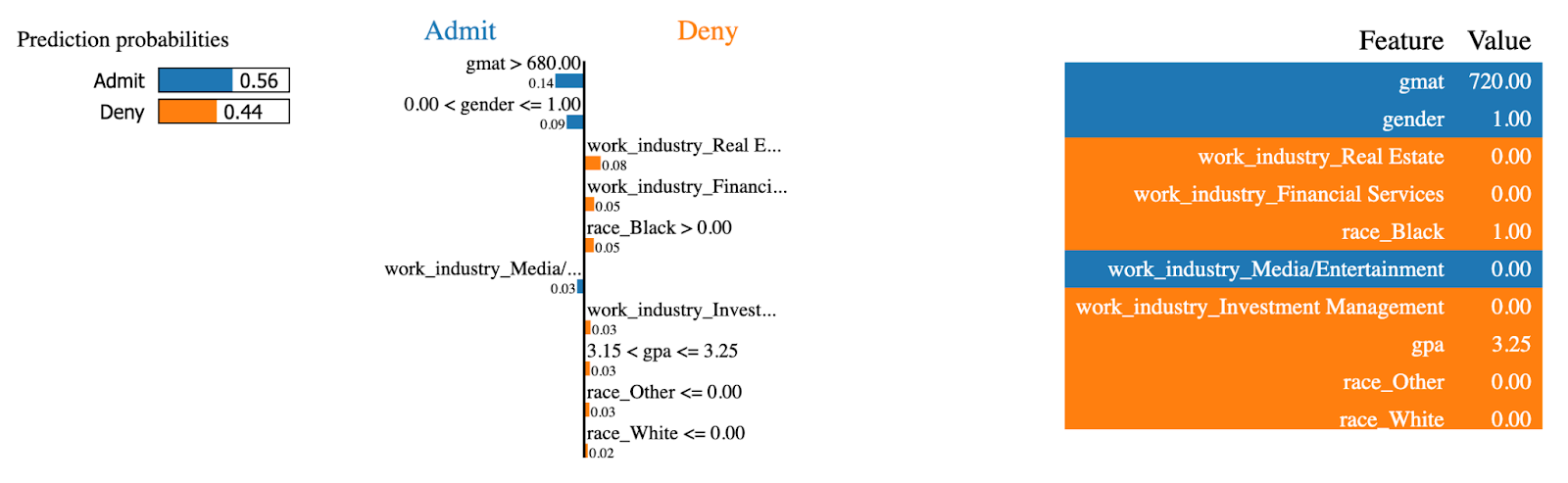
Explicações LIME (2). Imagem do autor.
Os mesmos recursos agora tinham o efeito oposto! Essa pessoa teve uma pontuação alta no site gmat, que é o maior contribuinte para que você seja admitido no programa de MBA.
E isso é tudo para os modelos de árvores! A seguir, você aprenderá a visualizar modelos lineares para tarefas de regressão.
Se você está apenas começando na modelagem preditiva, não há nada mais básico do que a regressão linear. É um modelo simples, fácil de entender e que funciona bem, desde que as relações em seu conjunto de dados sejam lineares.
Existem outros modelos lineares, mas, nesta seção, trabalharei apenas com a regressão linear.
Comece carregando o conjunto de dados de regressão, dividindo-o em subconjuntos de treinamento e teste e ajustando um modelo de regressão linear à parte de treinamento:
from sklearn.linear_model import LinearRegression
df = load_regression_dataset()
X = df.drop("charges", axis=1)
y = df["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = LinearRegression().fit(X_train, y_train)O primeiro tipo de visualização que explorarei são os coeficientes do modelo.
Em termos simples, um modelo de regressão linear se resume a uma única equação. Você deve se lembrar do site y = mx+b do ensino médio - a mesma ideia se aplica.
A equação de regressão se expande para y = w0 + w1_x1 + w2_x2 + … + wn_xn para acomodar vários parâmetros. O objetivo do modelo é encontrar a melhor estimativa de pesos (w) com base no conjunto de recursos de entrada (x).
Então, por que isso é importante?
Como você pode acessar os coeficientes (pesos) depois que o modelo é treinado e analisar sua contribuição, os recursos com um coeficiente maior associado a eles terão uma contribuição maior para a previsão da variável de destino.
Você pode obter os coeficientes acessando o parâmetro coef_ em um modelo treinado.
O snippet a seguir obtém os coeficientes e os plota como um gráfico de barras horizontais:
features = X_train.columns
coefficients = model.coef_
plt.figure(figsize=(10, 4))
bars = plt.barh(y=features, width=coefficients, edgecolor="#008031", linewidth=1)
for bar in bars:
width = bar.get_width()
plt.text(width + 1, bar.get_y() + bar.get_height()/2, f"{width:.2f}",
va="center", ha="left")
plt.xlabel("Coefficient value")
plt.title("Linear Regression Model Coefficients", y=1.05)
plt.show()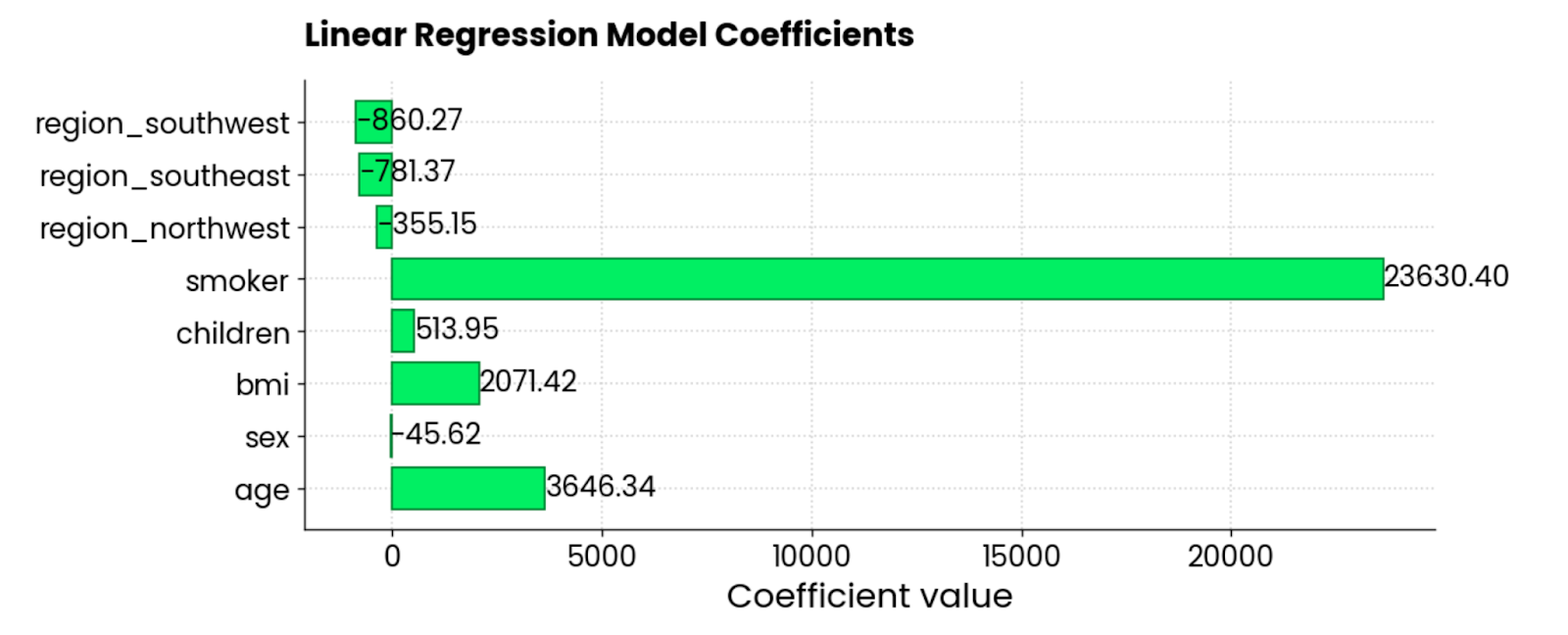
Coeficientes do modelo de regressão linear. Imagem do autor.
Os recursos smoker, BMI e age são os maiores contribuintes positivos para as taxas de seguro - quando eles aumentam, o valor também aumenta. Há também alguns coeficientes negativos, o que significa que eles reduzem o valor total.
O outro tipo comum de visualização de regressão é o gráfico residual. Em linguagem simples, você está fazendo umgráfico de dispersão dos valores previstos no eixo X e dos resíduos (valores reais - valores previstos) no eixo Y.
O ideal é que não haja padrões visíveis nos resíduos e que eles sejam centralizados em torno de 0. Em outras palavras, eles devem ser normalmente distribuídos.
Use esse trecho de código para visualizar os resíduos de um modelo de regressão linear no conjunto de dados de seguros:
y_pred = model.predict(X_test)
residuals = y_test - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, color="#03EF62", alpha=0.6, edgecolors="#008031")
plt.axhline(0, color="red", linestyle="--")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Values", y=1.05)
plt.grid(True)
plt.show()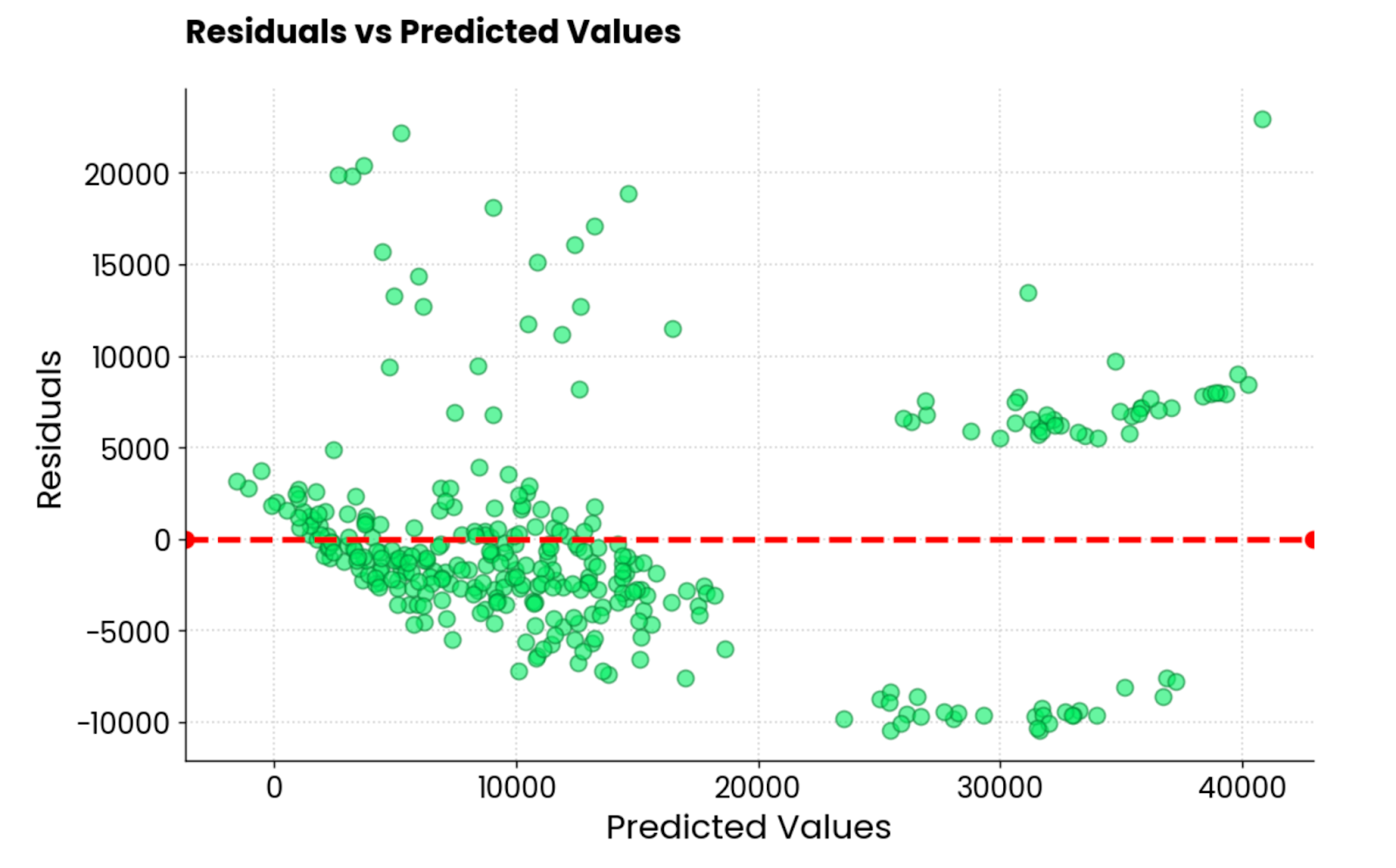
Resíduos do modelo de regressão linear. Imagem do autor.
Não é o melhor enredo residual que já vi. Esteticamente, parece bom, mas os valores estão muito diferentes. Se você for um profissional de aprendizado de máquina e obtiver um gráfico residual semelhante, terá muito trabalho pela frente.
A seguir, mostrarei a você três maneiras de visualizar modelos de redes neurais.
Se há uma área do aprendizado de máquina em que a visualização e a interpretação são mais importantes, essa área é a das redes neurais.
É complexo para você entender, mesmo no nível mais fundamental. Você tem diferentes tipos de camadas, funções de ativação e retropropagação, só para citar alguns. Por esse motivo, as redes neurais geralmente são sinônimos de modelos de caixa preta.
Não precisa ser assim.
Nesta seção, mostrarei a você três maneiras de visualizar redes neurais: gráficos de arquitetura, métricas de treinamento em tempo real e Grad-CAM.
Minha biblioteca preferida é o TensorFlow. Se você nunca ouviu falar dele, temos ove um curso de TensorFlow para iniciantes que o ajudará a começar rapidamente!
Ao visualizar a arquitetura do seu modelo de rede neural, você terá uma coisa desmistificada - formas.
Em outras palavras, você verá como a matriz subjacente se transforma em tamanho ao passar pelas camadas. Esse pode ser um assunto difícil para iniciantes, portanto, qualquer visualização é mais do que bem-vinda.
Para demonstrar, usarei o TensorFlow para criar um modelo básico de rede neural para classificação de dígitos manuscritos. Em seguida, usarei a função plot_model() para salvar a imagem da arquitetura do modelo em um arquivo local.
Dê uma olhada para você:
from tensorflow.keras import layers, models
from tensorflow.keras.utils import plot_model
model = models.Sequential()
model.add(layers.Input(shape=(28, 28, 1)))
model.add(layers.Conv2D(32, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
plot_model(model, to_file="model_architecture.png", show_shapes=True, show_layer_names=True)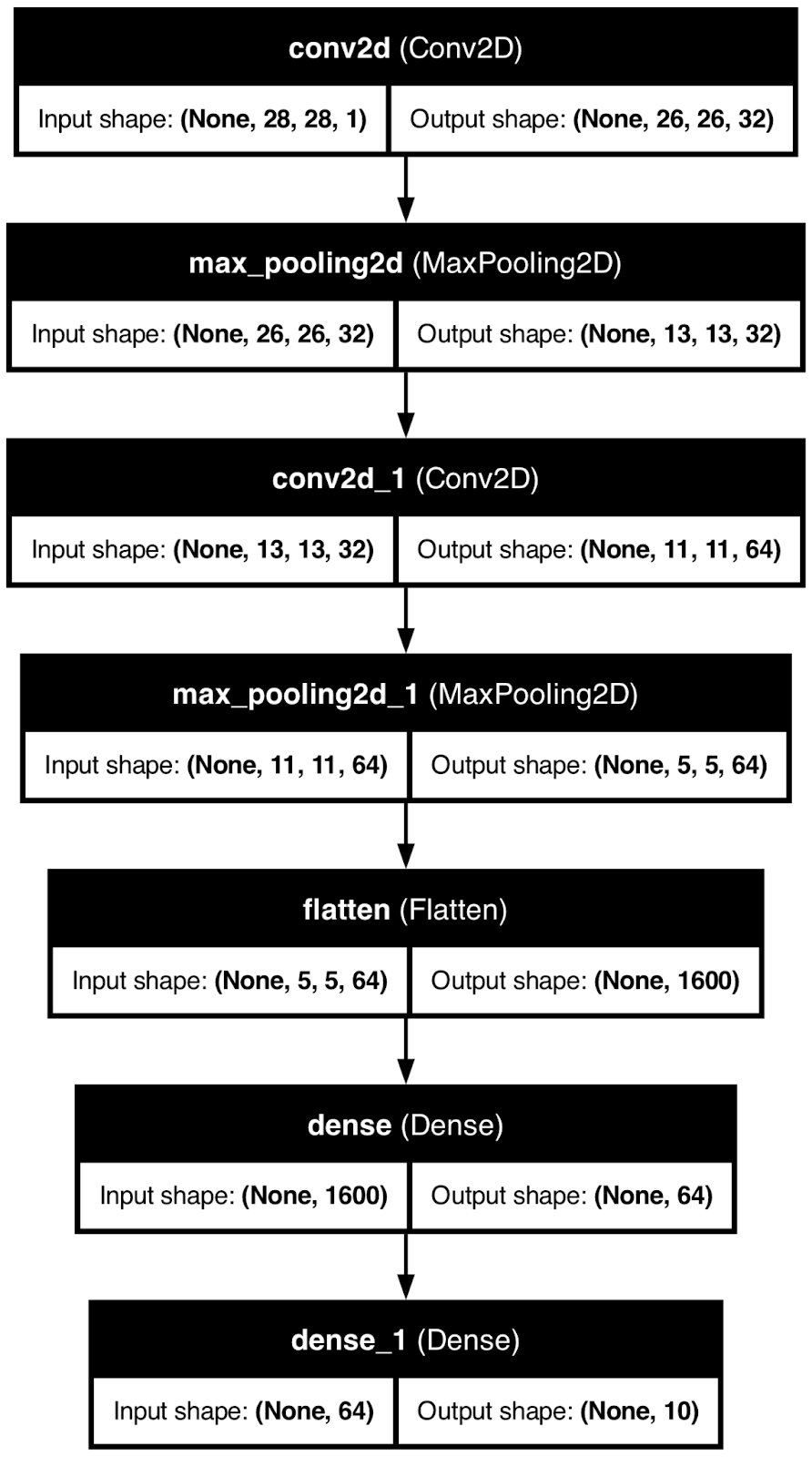
Arquitetura do modelo de rede neural. Imagem do autor.
Embora seja útil, esse tipo de visualização só pode levar você até certo ponto.
Você sabe como os dados se transformam ao longo do caminho, mas não tem ideia de como um modelo de rede neural chega às suas conclusões. É sobre isso que falarei a seguir.
Grad-CAM, ou Mapeamento de ativação de classe de gradiente é uma técnica popular usada para visualizar modelos de redes neurais convolucionais.
Para ser mais preciso, ele ajuda você a entender quais partes de uma imagem de entrada contribuem mais para as previsões do modelo. Pense nisso como um gráfico de importância de um recurso de uma árvore de decisão, mas aumentado para 11.
É uma técnica avançada de interpretabilidade que funciona para todos os modelos convolucionais, independentemente da arquitetura, e ajuda você a entender por que um modelo de rede neural faz uma determinada previsão.
Mas aqui está o problema :não é algo trivial para você implementar em Python. Aqui está uma visão geral de alto nível do algoritmo:
É um processo bastante complexo e, para facilitar as coisas, usarei um modelo ResNet50 pré-treinado que já pode classificar 1.000 tipos de imagens diferentes.
Mas, primeiro, carregue as bibliotecas necessárias e a imagem para a qual você deseja visualizar um Grad-CAM. Estou usando uma imagem de cachorro de estoque:
import cv2
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import load_img
image = np.array(load_img("dog.jpg", target_size=(224, 224, 3)))
plt.grid(False)
plt.imshow(image)
Exemplo de imagem de cachorro. Imagem do autor.
Agora, começa a parte divertida. No trecho de código a seguir, implemento o processo de quatro etapas descrito anteriormente. Você encontrará comentários acima de cada linha de código para facilitar a compreensão:
# Load the pre-trained ResNet50 model
model = ResNet50()
# Extract the output of the last convolutional layer
last_conv_layer = model.get_layer("conv5_block3_out")
# Create a model that outputs the last convolutional layer’s activations
last_conv_layer_model = tf.keras.Model(model.inputs, last_conv_layer.output)
# Prepare the classifier model using the layers after the last convolutional layer
classifier_input = tf.keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in ["avg_pool", "predictions"]:
# Reuse the pooling and prediction layers from the ResNet50 model
x = model.get_layer(layer_name)(x)
# Create a new model that takes in the last conv layer output and returns predictions
classifier_model = tf.keras.Model(classifier_input, x)
# Use a GradientTape to record operations for automatic differentiation
with tf.GradientTape() as tape:
# Prepare the input image and get the activations from the last conv layer
inputs = image[np.newaxis, ...]
last_conv_layer_output = last_conv_layer_model(inputs)
tape.watch(last_conv_layer_output) # Watch the conv layer output
# Get predictions from the classifier model
preds = classifier_model(last_conv_layer_output)
# Get the index of the highest predicted class
top_pred_index = tf.argmax(preds[0])
# Focus on the prediction of the top class
top_class_channel = preds[:, top_pred_index]
# Compute the gradient of the top predicted class with respect to the conv layer output
grads = tape.gradient(top_class_channel, last_conv_layer_output)
# Average the gradients over the width and height dimensions
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# Multiply each channel in the conv layer output by its corresponding gradient
last_conv_layer_output = last_conv_layer_output.numpy()[0]
pooled_grads = pooled_grads.numpy()
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, i] *= pooled_grads[I]
# Compute the Grad-CAM by averaging the channels and apply a ReLU activation
gradcam = np.mean(last_conv_layer_output, axis=-1)
# Normalize the Grad-CAM to be between 0 and 1
gradcam = np.clip(gradcam, 0, np.max(gradcam)) / np.max(gradcam)
# Resize the Grad-CAM heatmap to the size of the original image (224x224)
gradcam = cv2.resize(gradcam, (224, 224))Foi muito, com certeza, mas agora você pode finalmente traçar o mapa de calor produzido pelo algoritmo Grad-CAM:
plt.grid(False)
plt.imshow(gradcam)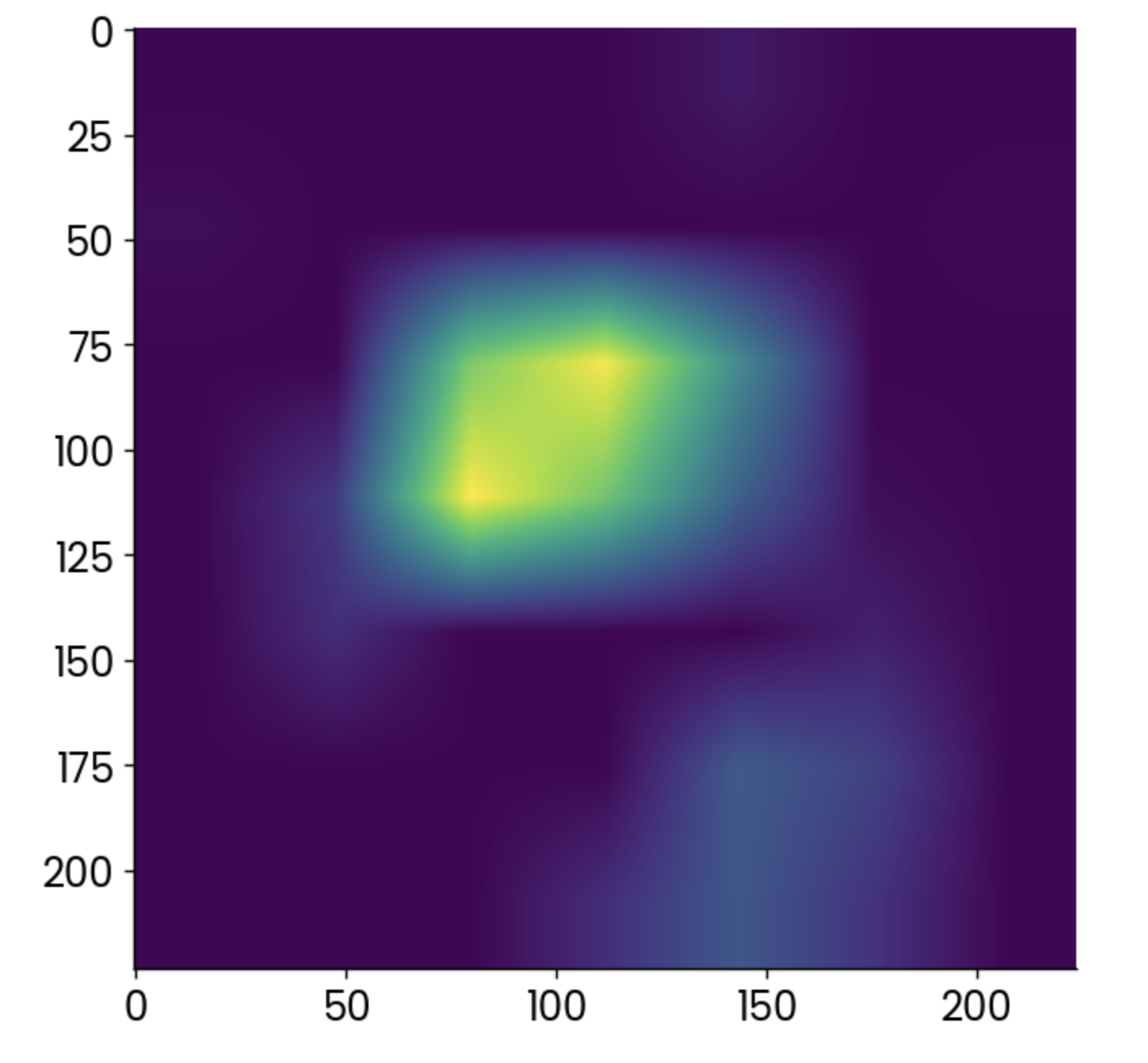
Mapa de calor do Grad-CAM. Imagem do autor.
Os pontos mais claros indicam áreas em que a ativação foi mais alta, mas o mapa de calor sozinho não diz muito a você.
É muito melhor você sobrepor a imagem original e reduzir um pouco a opacidade:
plt.grid(False)
plt.imshow(image)
plt.imshow(gradcam, alpha=0.5)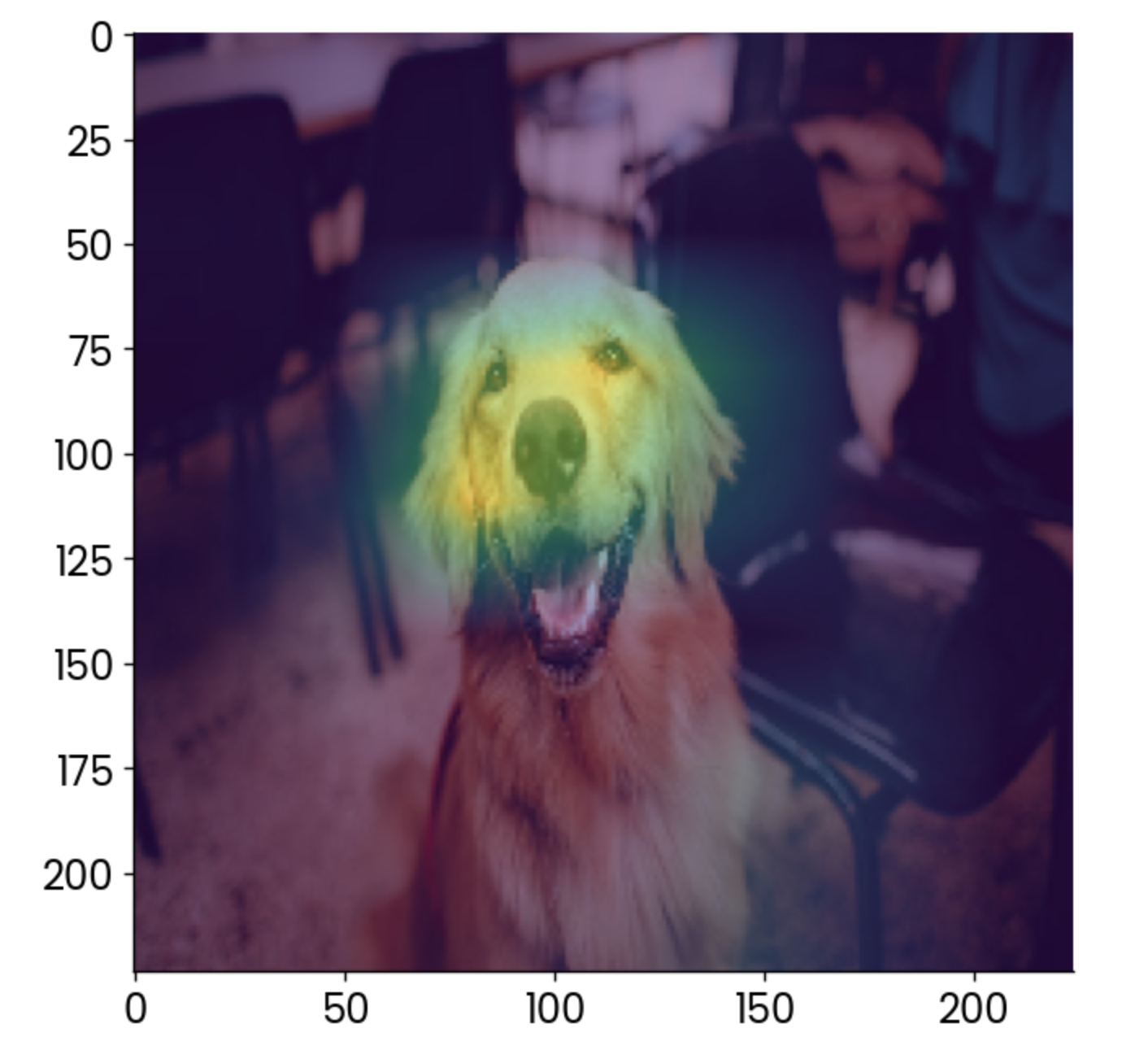
Imagem do cão com uma sobreposição grad-CAM. Imagem do autor.
Para interpretar, o fator que mais contribui para que essa imagem seja classificada como um "golden retriever" é o rosto, o que faz sentido.
Você pode usar o Grad-CAM para garantir que seu modelo esteja fazendo previsões da maneira correta. Nesse caso, imagine que o mapa de calor mostre outra coisa, como a cadeira no fundo, como o fator que mais contribui. Você não confiaria nesse modelo, confiaria?
O treinamento de um modelo de rede neural pode levar muito tempo. O bom é que você não precisa esperar a conclusão do treinamento para ter uma ideia do desempenho do modelo. Bibliotecas como o TensorBoard podem mostrar isso a você em tempo real.
O TensorBoard vem com o TensorFlowe, portanto, você não precisa instalar nada para acompanhá-lo.
Para fins de demonstração, treinarei um modelo básico de classificador de dígitos por 25 épocas. A parte importante é oretorno de chamada -nele, você especifica o caminho e o formato dos registros de treinamento, que o TensorBoard usará em um minuto.
Esse é o código de que você precisará para treinar o modelo e armazenar os registros de treinamento:
import tensorflow as tf
from tensorflow.keras import layers, models
from datetime import datetime
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension (for the Convolutional layer)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# Build a simple CNN model
model = models.Sequential([
layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax")
])
# Compile the model
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
# Set up TensorBoard callback
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Train the model with TensorBoard monitoring
model.fit(
x_train,
y_train,
epochs=25,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]
)
Processo de treinamento de modelos. Imagem do autor.
Enquanto o modelo estiver sendo treinado, execute o TensorBoard no terminal e especifique um caminho para a pasta de registros de treinamento:
tensorboard --logdir=logs/fitPor padrão, o TensorBoard será executado na porta 6006:
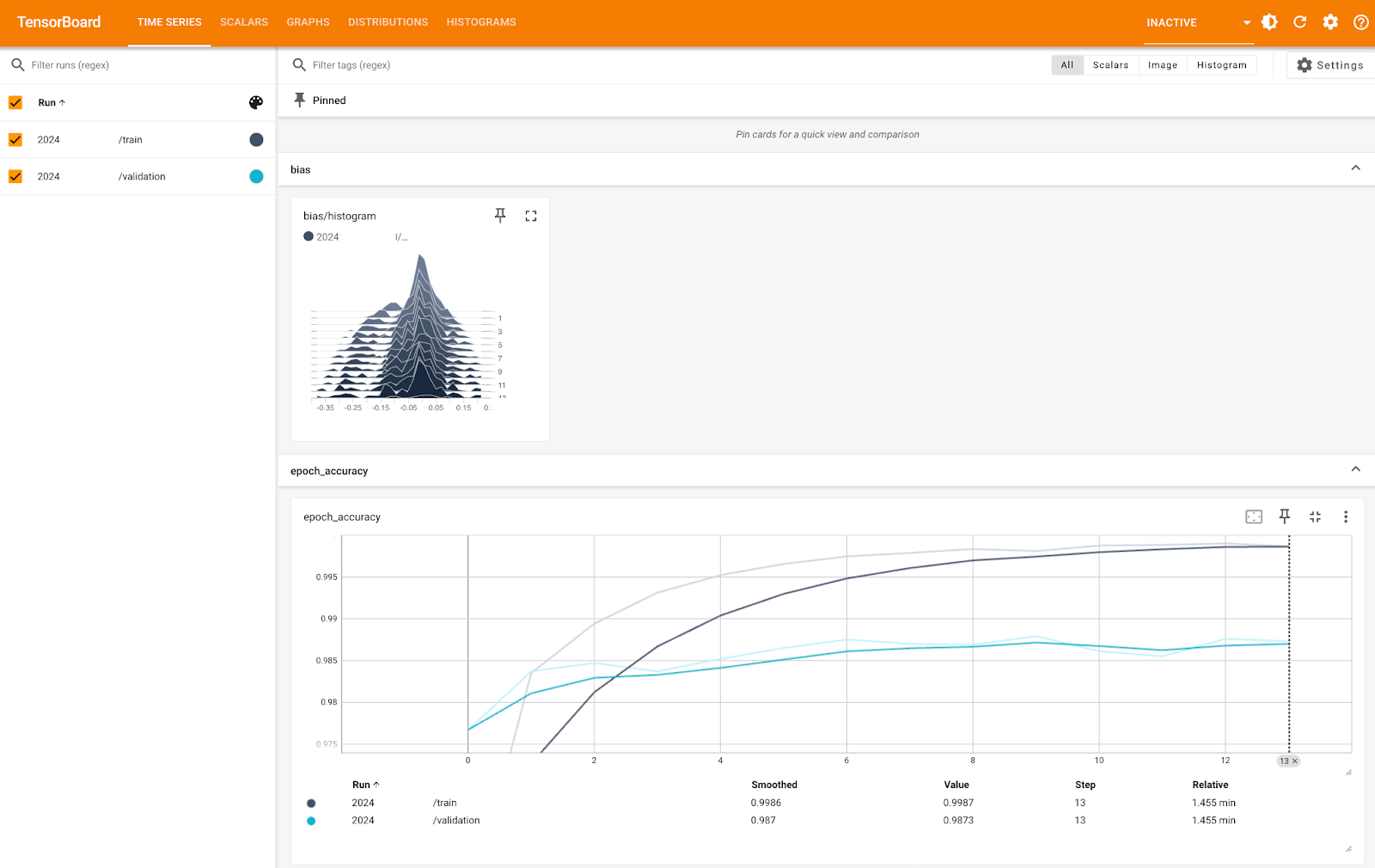
Métricas do TensorBoard (1). Imagem do autor.
A imagem acima mostra a você o histograma de polarização e a precisão por época, tanto para os conjuntos de treinamento quanto para os de validação. Você pode ver que a precisão é muito alta para ambos, perto de 100% - é apenas a escala do eixo Y que é muito pequena.
Outras guias se aprofundarão em métricas mais específicas e permitirão que você ajuste determinados aspectos, como você pode ver abaixo:
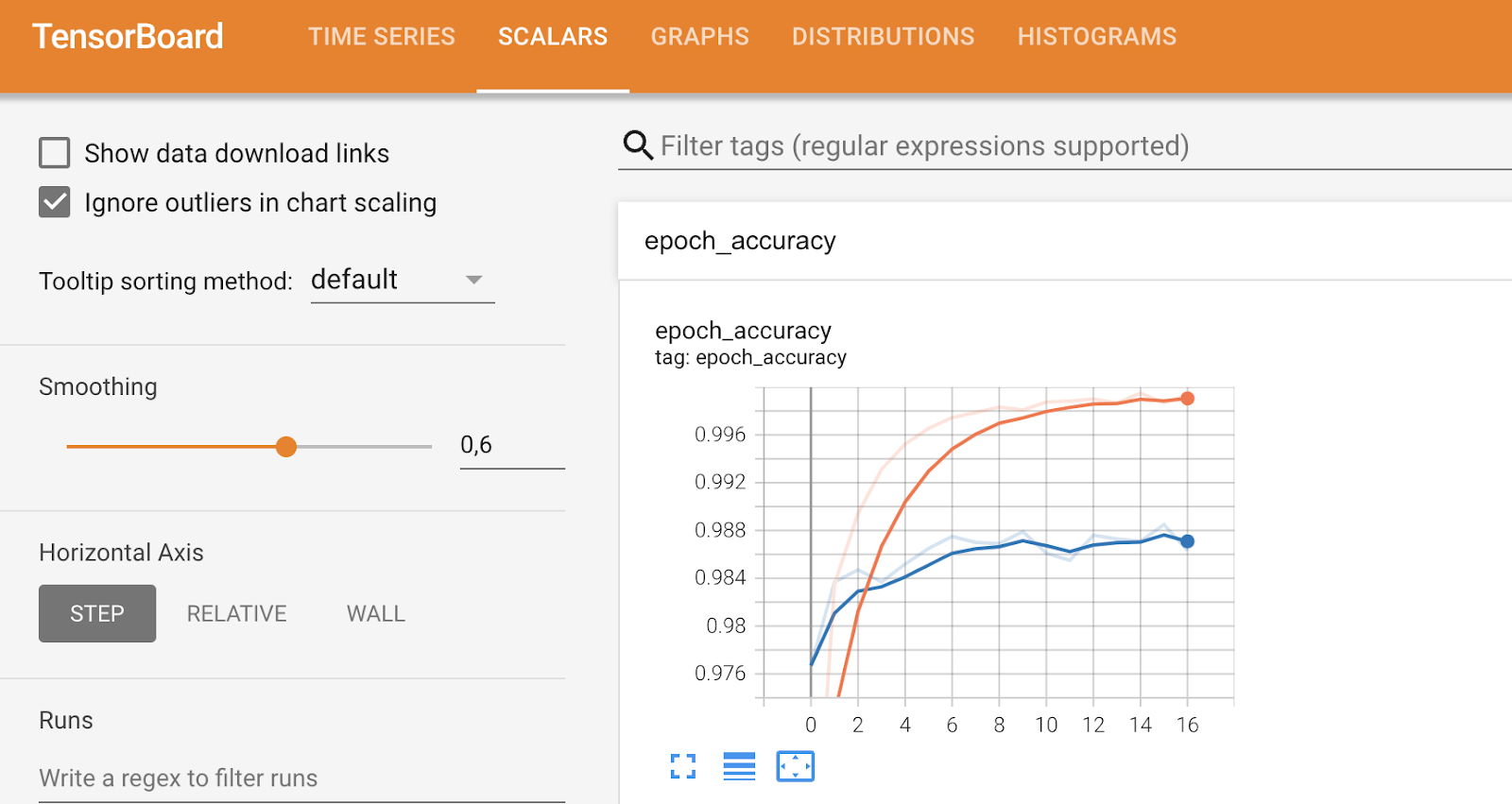
Métricas do TensorBoard (2). Imagem do autor.
Para concluir, o TensorBoard é uma ferramenta de visualização do desempenho do modelo e pode ajudar você a analisar o desempenho enquanto o modelo está sendo treinado.
Nesta última parte, quero dar um passo atrás e mergulhar em métricas de uso mais geral para visualizar o desempenho do modelo.
Você verá três Você verá três deles: matriz de confusão, gráfico da curva ROC e gráfico da curva Precision-Recall.
Como eles estão vinculados a problemas de classificação, você terá de carregar o conjunto de dados do MBAde classificação . Para facilitar as coisas, também o converti em um problema de classificação binária, definindo as entradas em lista de espera como negadas. O restante do snippet de código divide os dados em subconjuntos de treinamento e teste e, primeiro, um modelo de classificação de floresta aleatória:
from sklearn.ensemble import RandomForestClassifier
df = load_classification_dataset()
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
df["admission"] = df["admission"].replace({"Deny": 0, "Admit": 1})
df.rename(columns={"admission": "is_admitted"}, inplace=True)
X = df.drop("is_admitted", axis=1)
y = df["is_admitted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Vamos nos aprofundar na primeira métrica: a matriz de confusão.
Uma matriz de confusão informa a você o desempenho do seu modelo. Em um cenário ideal, os valores em uma diagonal de cima para baixo, da esquerda para a direita, seriam os únicos elementos diferentes de zero, indicando que o modelo não fez nenhuma previsão falsa.
Mas isso não acontece com frequência no mundo real.
Use as seguintes diretrizes para interpretar uma matriz de confusão (para classificação binária):
Não há uma regra geral sobre se você deve se preocupar mais com falsos positivos ou falsos negativos. O anterior é mais doloroso no caso de admissões de MBA, pois o modelo classificou o aluno que está sendo admitido, mas não foi o caso na realidade. Em outros casos, como naprevisão de câncer , é fundamental minimizar o número de falsos negativos, pois você não quer declarar que uma pessoa é saudável quando ela tem câncer.
É aí que entra o conhecimento do domínio.
De qualquer forma, voltemos ao código. O snippet a seguir calcula a matriz de confusão do nosso modelo de floresta aleatória no conjunto de testes e usa a classe ConfusionMatrixDisplay para criar uma visualização:
from sklearn.metrics import confusion_matrix
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
preds = random_forest.predict(X_test)
cm = confusion_matrix(y_true=y_test, y_pred=preds, labels=random_forest.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=random_forest.classes_)
disp.plot()
plt.grid(False)
plt.title("Confusion Matrix", y=1.04)
plt.show()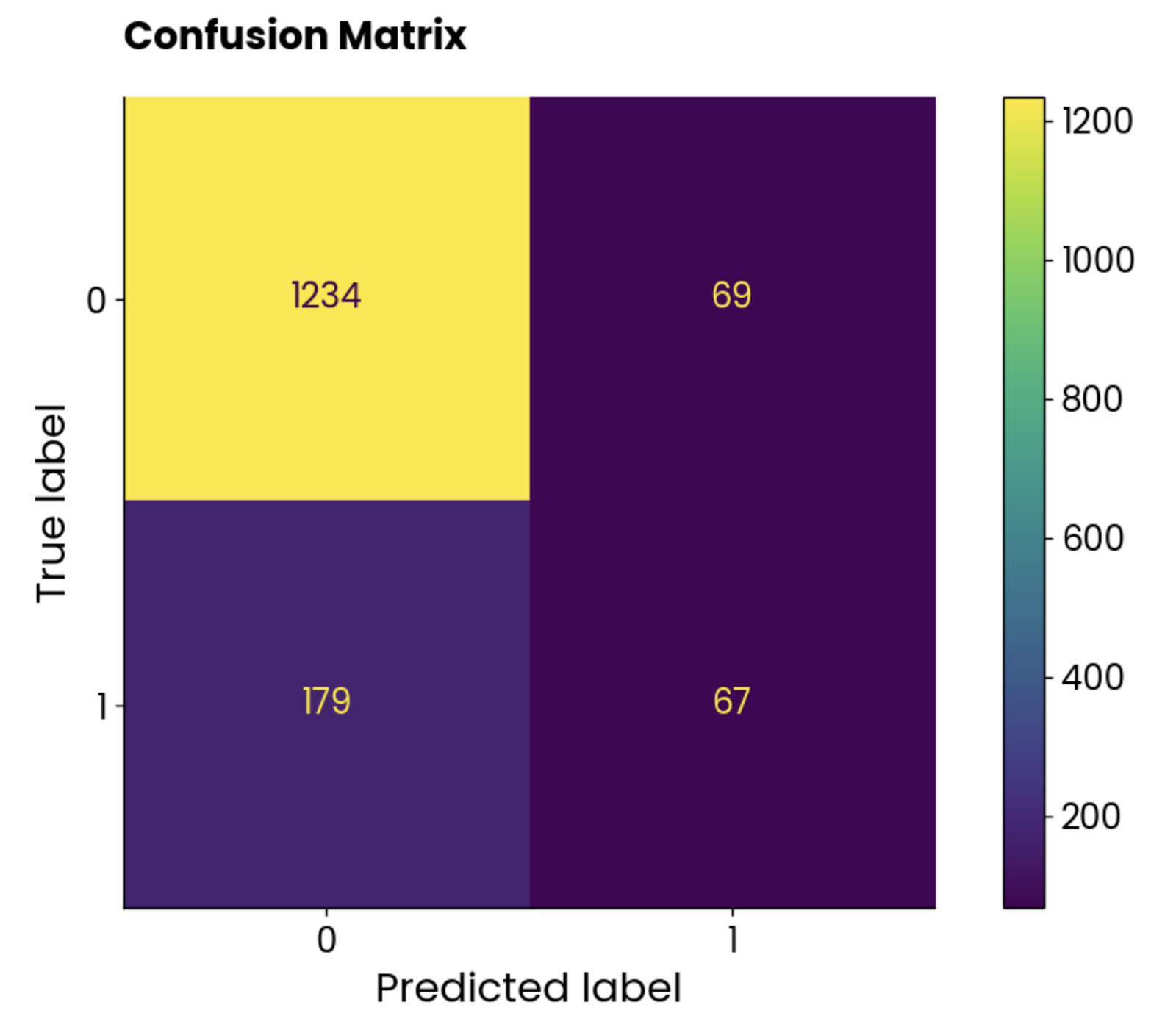
Gráfico da matriz de confusão. Imagem do autor.
As classes não são equilibradas, mas o número de previsões incorretas é surpreendentemente alto.
Vamos ver o que a curva ROC tem a dizer.
ROC significa Receiver Operating Characteristics (Características Operacionais do Receptor), e é uma curva que exibe a avaliação de desempenho de um modelo de classificação binária. No caso da classificação multiclasse, você terá que comparar duas classes ao mesmo tempo.
A curva ROC mostra uma compensação entre uma taxa de verdadeiros positivos (TPR, sensibilidade, recall) e uma taxa de falsos positivos (FPR) em diferentes limites de classificação. O TPR é plotado no eixo Y em relação ao FPR no eixo X. Cada ponto representa um limite diferente para a decisão de classificação (pontuação de probabilidade usada para classificar uma instância como positiva ou negativa).
Normalmente, a curva é plotada em uma diagonal de (0, 0) a (1, 1), que representa um classificador aleatório.
Se a curva estiver acima da diagonal, isso significa que seu modelo tem um desempenho melhor do que um classificador aleatório. Um único valor escalar resume isso. É chamado de AUC (Area Under the Curve) e varia de 0 a 1, sendo que o maior valor é melhor e 0,5 é aleatório.
Em suma, você deseja fazer a curva o mais próximo possível do canto superior esquerdo.
Use o seguinte snippet para calcular ROC e AUC e traçar a curva:
from sklearn.metrics import roc_curve, auc
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
fpr, tpr, roc_thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.2f}")
plt.plot([0, 1], [0, 1], color="navy", linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve", y=1.04)
plt.legend(loc="lower right")
plt.show()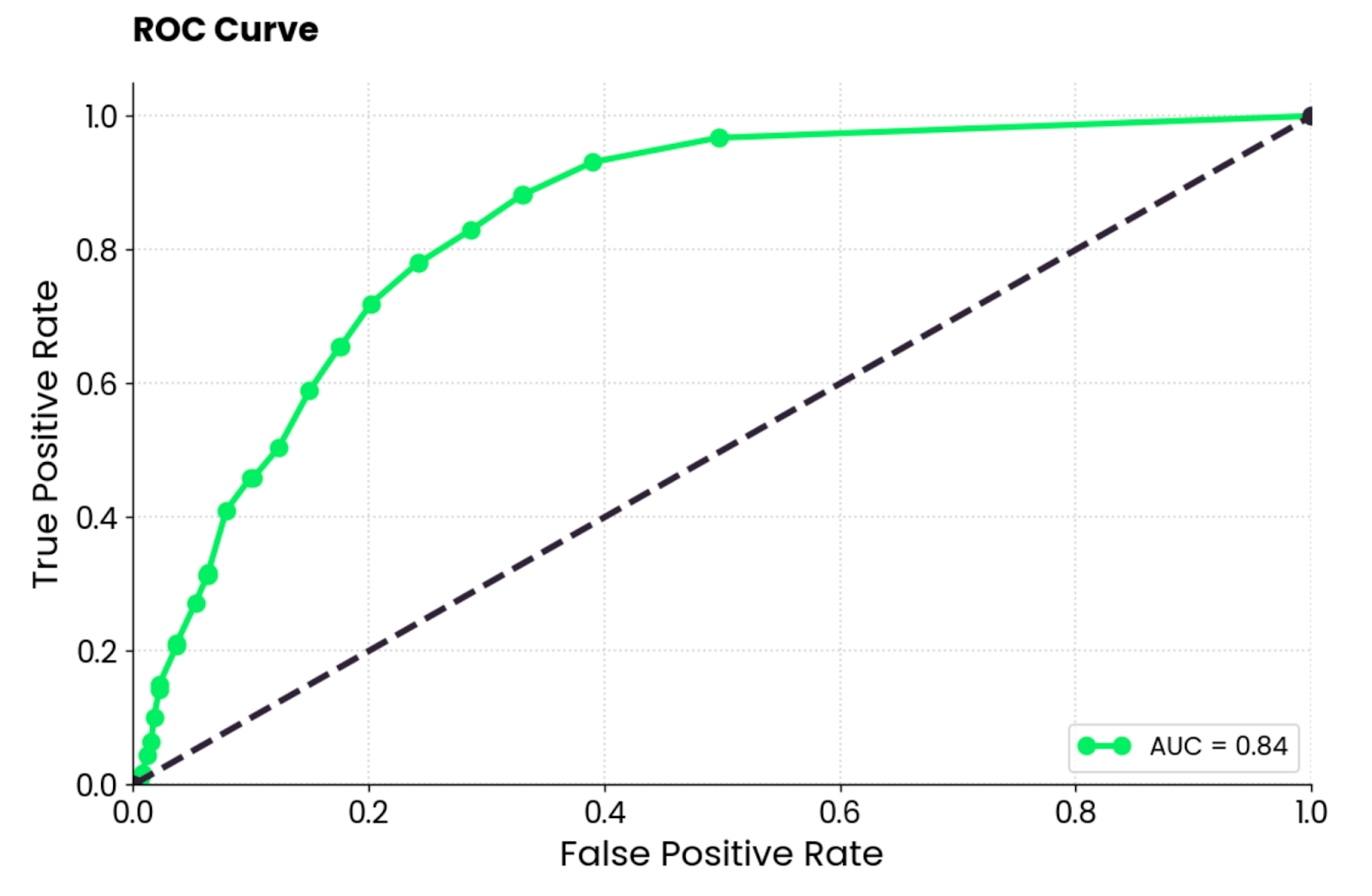
Gráfico da curva ROC. Imagem do autor.
Para interpretar, o modelo de floresta aleatória é muito melhor do que um classificador aleatório e tem um equilíbrio razoável entre positivos verdadeiros e falsos positivos. Ainda há algum grau de classificação incorreta presente, e você deve tentar elevar a curva para cima e para a esquerda otimizando os dados ou escolhendo um modelo de aprendizado de máquina diferente.
Essa curva é semelhante à curva ROC, mas mostra a compensação entre precisão e recuperação para diferentes limites de classificação. Ele mostra a precisão no eixo Y e a recuperação no eixo X e, normalmente, é preferível ao ROC quando as classes são desequilibradas.
Esse é o caso do conjunto de dados de admissões de MBA, portanto, uma curva de RP parece ser uma ótima opção!
É importante observar que as curvas de precisão-recuperação se concentram apenas na classe minoritária e fornecem uma imagem melhor de como o modelo identifica as instâncias mais importantes (alunos admitidos, cânceres detectados e assim por diante).
Use o seguinte snippet para calcular os valores de precisão e recuperação e plotá-los em um gráfico:
from sklearn.metrics import precision_recall_curve
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
# Precision-Recall curve
precision, recall, pr_thresholds = precision_recall_curve(y_test, y_probs)
pr_auc = auc(recall, precision)
plt.plot(recall, precision, label=f"(AUC = {pr_auc:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve", y=1.04)
plt.legend(loc="lower left")
plt.show()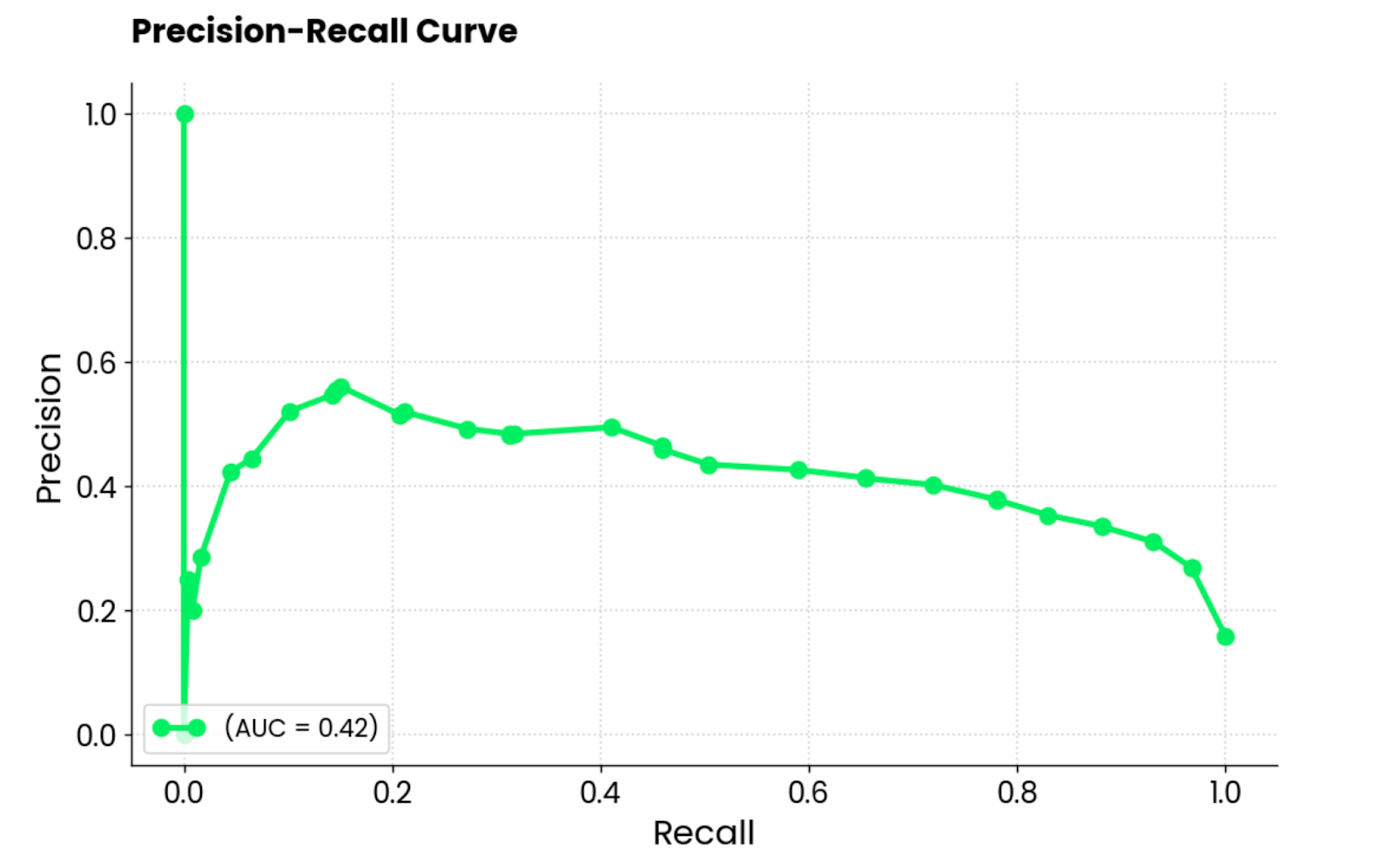
Gráfico da curva de precisão-recall. Imagem do autor.
Para interpretar, o modelo tem um desempenho ruim, indicado pela pontuação AUC de 0,42. Quando o modelo tenta aumentar o recall, ele sacrifica muita precisão, o que leva a muitos falsos positivos. Em resumo, esse modelo não é adequado para esse conjunto de dados, ou o próprio conjunto de dados não foi pré-processado adequadamente.
Para concluir, o campo do aprendizado de máquina é complexo e, muitas vezes, não é intuitivo. Se você for um iniciante, terá dificuldade para entender as grandes ideias. Se você estiver trabalhando com um cliente comercial, ele provavelmente não entenderá o jargão tecnológico.
A visualização de dados ajuda a preencher a lacuna em ambos os cenários.
Hoje, você viu todos os diferentes tipos de gráficos que podem ser usados para visualizar modelos de regressão e classificação, bem como o processo de decisão de redes neurais e a interpretação de previsão única por meio de SHAP e LIME. É muita coisa para processar, portanto, sinta-se à vontade para revisitar este artigo várias vezes!
Se você é completamente novo no assunto, recomendamos que assista ao nosso curso básico de aprendizado de máquina para começar. Depois disso, um curso mais aplicado com Python é uma ótima opção.
Se você tem alguma experiência, mas não entende como tudo isso funciona em uma escala maior, recomendamos que experimente nosso curso de aprendizado de máquina para produção.
Saiba mais sobre aprendizado de máquina com estes cursos!
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Abid Ali Awan
11 min
Tutorial
Avinash Navlani
Tutorial
Moez Ali
Tutorial
Zoumana Keita


