
Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.4K
In diesem kurzen Abschnitt zeige ich dir, wie du systemweite Abhängigkeiten und Python-Bibliotheken installierst, die für die Visualisierung von Machine Learning-Modellen benötigt werden.
Die einzige systemweite Abhängigkeit, die du brauchst, um mitzumachen, ist Graphviz. Du wirst ihn später verwenden, um einen Entscheidungsbaum zu visualisieren, und der Code wird ohne Graphviz nicht funktionieren.
Es ist eine Open-Source-Software, mit der du Diagramme, abstrakte Graphen und Netzwerke erstellen kannst. Du wirst es nicht direkt verwenden, sondern nur über scikit-Learn.
Diese Python-Bibliothek wird häufig für Aufgaben des maschinellen Lernens in Python verwendet.
In diesem Artikel lernst du, wie du damit Modelle für maschinelles Lernen trainierst, Datensätze aufteilst, numerische Merkmale skalierst und die Modellleistung visualisierst. Es ist ein Muss, also installiere es mit dem folgenden Befehl (abhängig von deiner Python-Umgebung):
pip install scikit-learn
conda install scikit-learnWenn du ganz neu in scikit-learn bist, empfehlen wir dir unseren beliebten Kurs zum überwachten maschinellen Lernen.
Die SHAP-Bibliothek in Python ist ein beliebtes Werkzeug, um die Vorhersagen von Machine-Learning-Modellen zu erklären. Es nutzt spieltheoretische Konzepte (z.B. Shapely-Werte), um den Beitrag jedes Attributs zur Vorhersage des Modells zu messen.
Noch besser: Sie ist vollgepackt mit nützlichen Visualisierungen, die dir helfen, die Funktionsweise deiner Modelle zu verstehen.
Installiere sie mit dem folgenden Befehl:
pip install shap
conda install -c conda-forge shapDiese Python-Bibliothek wird von vielen genutzt, wenn es darum geht, eine einzelne Modellvorhersage zu erklären. Es funktioniert anders als SHAP. Es approximiert das ursprüngliche Modell lokal mit einem interpretierbaren, einfacheren Modell. Dann wird der Beitrag jedes Merkmals des Datensatzes zur Vorhersage angezeigt.
Wie LIME funktioniert, erfährst du in einer Minute, aber zuerst musst du ihn installieren:
pip install lime
conda install conda-forge::limeWenn du neuronale Netzwerkmodelle mit TensorFlow entwickelst, dann ist TensorBoard ein Muss für dich.
Es ist ein Visualisierungstool, mit dem du Experimente zum maschinellen Lernen verfolgen und Trainingskennzahlen (z. B. Verlust und Genauigkeit) überwachen kannst. Es visualisiert und aktualisiert Modellgrafiken für dich in Echtzeit und zeigt, wie sich die Modellparameter während des Trainings verändern.
TensorBoard kann auch mit anderen Deep-Learning-Frameworks wie PyTorch verwendet werden, aber in diesem Artikel werde ich mich auf TensorFlow konzentrieren.
Installiere sie, indem du den folgenden Befehl ausführst:
pip install tensorboard
conda install -c conda-forge tensorboardDer letzte Schritt in dieser Vorbereitungsphase besteht darin, sich um die Daten zu kümmern.
Ich werde heute zwei Datensätze verwenden: MBA-Zulassungen für die Klassifizierung und Insurance für die Regression. Beide sind kostenlos und stehen auf Kaggle zum Download bereit.
Um zu beginnen, importiere diese Python-Bibliotheken:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_splitWas den Klassifizierungsdatensatz angeht, so habe ich nur minimale Vorverarbeitungen an den Daten vorgenommen. Es läuft auf Folgendes hinaus:
Es handelt sich keineswegs um eine umfassende Pipeline zur Datenvorverarbeitung. Wenn du die Zeit hast, kannst du sie gerne verbessern.
Kopiere diese Funktion trotzdem, um den Klassifizierungsdatensatz in Ordnung zu bringen:
def load_classification_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/taweilo/mba-admission-dataset?resource=download
df = pd.read_csv("MBA.csv")
# Just an arbitrary ID
df = df.drop(["application_id"], axis=1)
# Fill unknown
df["race"] = df["race"].fillna("Unknown")
# Assume these are denied
df["admission"] = df["admission"].fillna("Deny")
# Convert boolean cols to 0/1
df["gender"] = df["gender"].replace({"Male": 0, "Female": 1})
df["international"] = df["international"].replace({False: 0, True: 1})
# Create dummy columns for categorical features
cols_for_dummy = ["major", "race", "work_industry"]
for col in cols_for_dummy:
dummies = pd.get_dummies(df[col], prefix=col)
df = pd.concat([df, dummies], axis=1)
# To drop
cols_to_drop = ["major", "race", "work_industry", "major_Humanities", "race_Unknown", "work_industry_Other"]
df = df.drop(cols_to_drop, axis=1)
return df
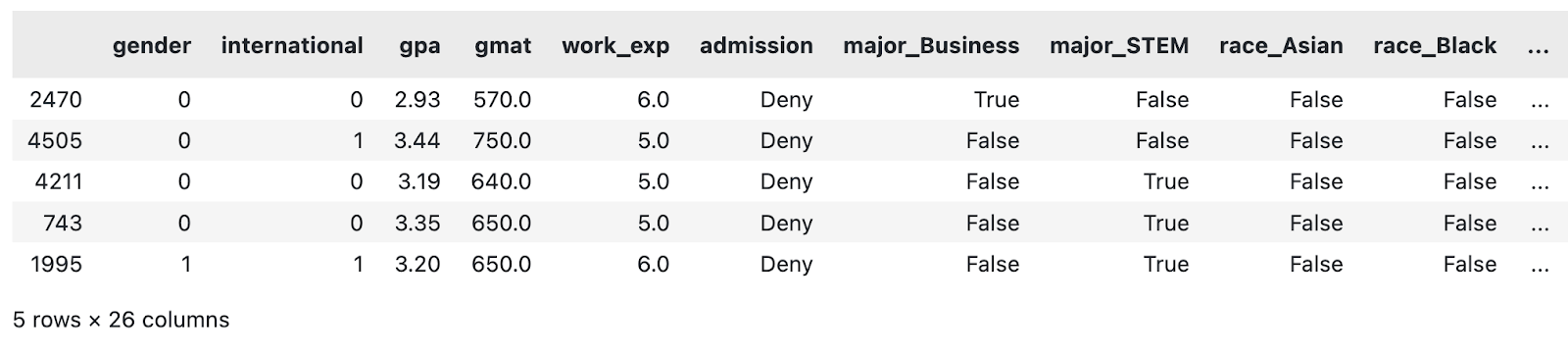
load_classification_dataset().sample(5)
Ein Beispiel für den geänderten MBA-Datensatz. Bild vom Autor.
Das Gleiche mache ich jetzt mit dem Regressionsdatensatz.
Der gewählte Regressionsdatensatz enthält einen Versicherungsbetrag ($) als kontinuierliches Merkmal, das das maschinelle Lernmodell auf der Grundlage anderer Attribute vorherzusagen versucht.
Die Datenvorverarbeitung, die ich vorgenommen habe, ist wieder einmal ziemlich minimal. Es läuft auf Folgendes hinaus:
Wenn du Zeit hast, kannst du gerne weitere Schritte in die Pipeline einbauen.
Kopiere die folgende Funktion, um den Versicherungsdatensatz zu laden und vorzuverarbeiten:
def load_regression_dataset() -> pd.DataFrame:
# https://www.kaggle.com/datasets/mirichoi0218/insurance
df = pd.read_csv("MedicalCostPersonal.csv")
# Scale numerical features
cols_to_scale = ["age", "bmi", "children"]
scaler = StandardScaler()
df[cols_to_scale] = scaler.fit_transform(df[cols_to_scale])
# Binary features
df["sex"] = df["sex"].replace({"male": 0, "female": 1})
df["smoker"] = df["smoker"].replace({"no": 0, "yes": 1})
# Dummies
dummies_region = pd.get_dummies(df["region"], prefix="region", drop_first=True)
df = pd.concat([df, dummies_region], axis=1)
df = df.drop("region", axis=1)
return df
load_regression_dataset().sample(5)
Ein Beispiel für den geänderten Versicherungsdatensatz. Bild vom Autor.
Und das war's!
Im folgenden Abschnitt zeige ich dir, wie du anfängst, Modelle für maschinelles Lernen zu visualisieren.
Baumbasierte Modelle werden oft für die Klassifizierung verwendet, aber die meisten von ihnen können auch Regressionsaufgaben bewältigen.
In diesem Abschnitt zeige ich dir, wie du einen Entscheidungsbaum visualisierst, die Bedeutung der Merkmale aus einem Random Forest Modell und Erklärungen zur Vorhersage mit SHAP und LIME.
Denke daran, dass Entscheidungsbaum- und Random-Forest-Modelle schwer zu verstehen sein können. Wir haben einen kompletten Kurs, der die Grundlagenvon baumbasierten maschinellen Lernmodellen in Python abdeckt.
Um loszulegen, lädst du den Klassifizierungsdatensatz und teilst ihn in Trainings- und Testteilmengen auf:
df = load_classification_dataset()
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)Als Nächstes wollen wir einen Entscheidungsbaum visualisieren!
Stell dir einen Entscheidungsbaum als eine Reihe von verschachtelten if Anweisungen vor, in denen die Bedingungen durch ein maschinelles Lernmodell bestimmt werden.
Die Geschichte hat noch mehr zu bieten, aber anhand dieser Analogie kannst du sehen, dass die Visualisierung von Entscheidungen ein einfacher Prozess sein sollte. Und das ist es auch: Die Funktion plot_tree() von sklearn übernimmt den größten Teil der schweren Arbeit.
Beginne mit dem Training eines Entscheidungsbaummodells. Der Parameter max_depth ist optional und dient nur zur Veranschaulichung. Ohne sie wird der Baum zu tief und du verlierst dich in der schieren Menge der Entscheidungen, die das Modell trifft, vor allem bei größeren Datensätzen.
Das folgende Snippet trainiert das Entscheidungsbaum-Klassifizierungsmodell auf der Trainingsuntermenge:
from sklearn import tree
decision_tree = tree.DecisionTreeClassifier(random_state=42, max_depth=4)
decision_tree.fit(X_train, y_train)Und zur Visualisierung kopierst du einfach den folgenden Ausschnitt. Die optionalen Parameter filled und feature_names machen den Baum einfacher zu interpretieren:
plt.figure(figsize=(12,8))
tree.plot_tree(decision_tree, filled=True, feature_names=X.columns, class_names=y.unique())
plt.title("Decision Tree Visualization", size=20, loc="left", y=1.04, weight="bold")
plt.show()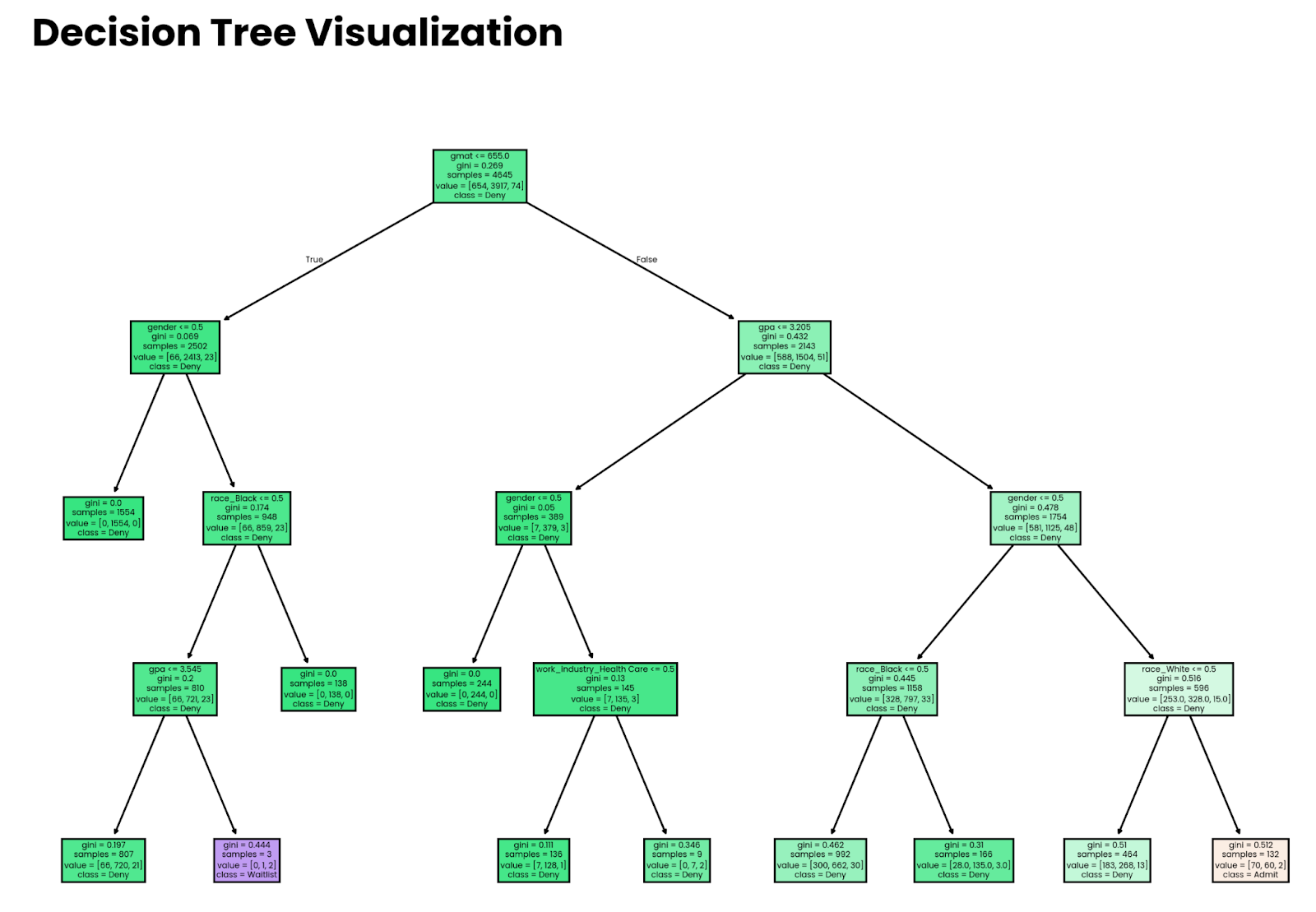
Vierstufiger tiefer Entscheidungsbaum. Bild vom Autor.
Beachte, dass die Entscheidungen, die das Modell trifft, nichts bedeuten, wenn das Modell nicht genau ist. Später im Artikel zeige ich dir, wie du die Genauigkeit einschätzen kannst.
Erinnerst du dich an den Vergleich mit dem Kuchen von vorhin? Es ist an der Zeit, sie in die Praxis umzusetzen.
Jedes Mal, wenn du ein Baummodell mit sklearn trainierst, erhältst du Zugriff auf die Eigenschaft feature_importances_. Verbinde das mit den Namen der Merkmale und du hast alle Daten, die du brauchst, um herauszufinden, welche Merkmale am meisten zur Vorhersage beitragen.
Lass es uns in Aktion sehen! Trainiere zunächst einen Random-Forest-Klassifikator auf der Trainingsuntermenge:
from sklearn.ensemble import RandomForestClassifier
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Die Visualisierung läuft nun darauf hinaus das Extrahieren und Sortieren von Merkmalsbedeutungen und die Indizes durch die Namen der Merkmale zu ersetzen:
importances = random_forest.feature_importances_
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(10,6))
bars = plt.bar(range(X.shape[1]), importances[indices], edgecolor="#008031", linewidth=1)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, height, f"{height:.2f}", ha="center", va="bottom", size=8)
plt.title("Feature Importances", size=20, loc="left", y=1.04, weight="bold")
plt.ylabel("Importance")
plt.xticks(range(X.shape[1]), np.array(X.columns)[indices], rotation=90, size=12)
plt.show()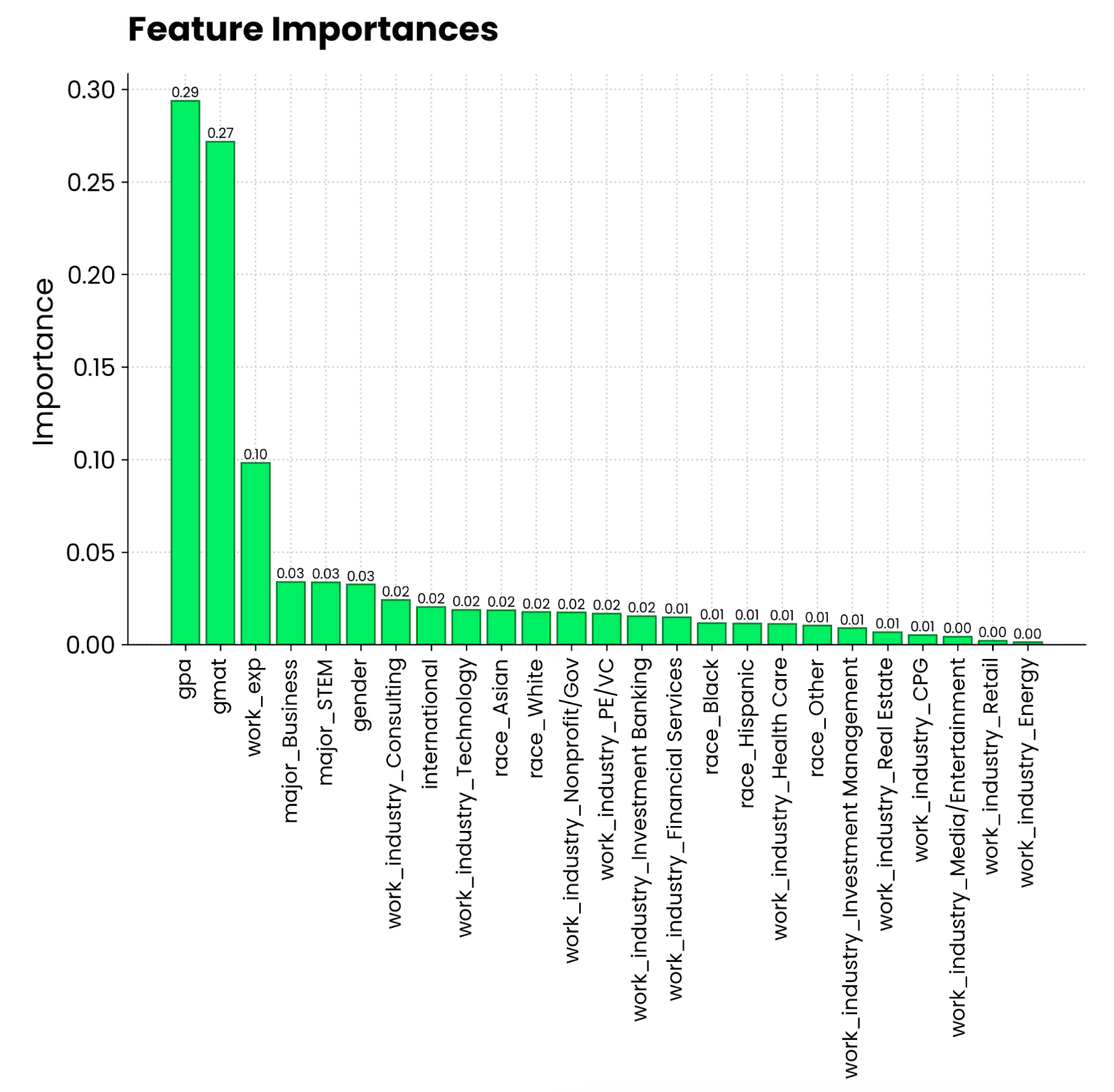
Random Forest Feature Importance Plot. Bild vom Autor.
Es sieht so aus, als würden ein Notendurchschnitt von 4,0 und ein GMAT-Ergebnis am meisten dazu beitragen, zu einem MBA-Programm zugelassen zu werden. Danach folgt die Berufserfahrung, die eine Voraussetzung für das MBA-Studium ist. Was die Person studiert hat und in welcher Branche sie arbeitet, ist weit weniger wichtig.
Die Bedeutung von Merkmalen vermittelt ein Gesamtbild, aber was ist, wenn du Modelle für maschinelles Lernen auf der Ebene einzelner Vorhersagen visualisieren willst? einzelnen Vorhersage?
Hier kommen SHAP und LIME ins Spiel. Ich werde zuerst über SHAP sprechen. Du weißt schon, was es ist, also überspringe ich die Theorie.
Ich werde ein Gradient-Boosting-Modell auf unseren Regressionsdatensatz anwenden, um zu sehen, welchen Einfluss einzelne Merkmale auf die Versicherungskosten haben. Das folgende Snippet zeigt dir, wie du das Modell anpasst und die SHAP-Werte aus einem shap.Explainer() Modell berechnest:
import shap
from xgboost import XGBRegressor
df = load_regression_dataset()
# No need for train-test splits
X = df.drop("charges", axis=1)
y = df["charges"]
model = XGBRegressor().fit(X, y)
# Shap explainer
explainer = shap.Explainer(model)
shap_values = explainer(X)Mit SHAP gibt es eine Reihe von Plots, die du machen kannst.
Ich beginne mit waterfall() und untersuche die SHAP-Werte für die erste Vorhersage:
shap.plots.waterfall(shap_values[0])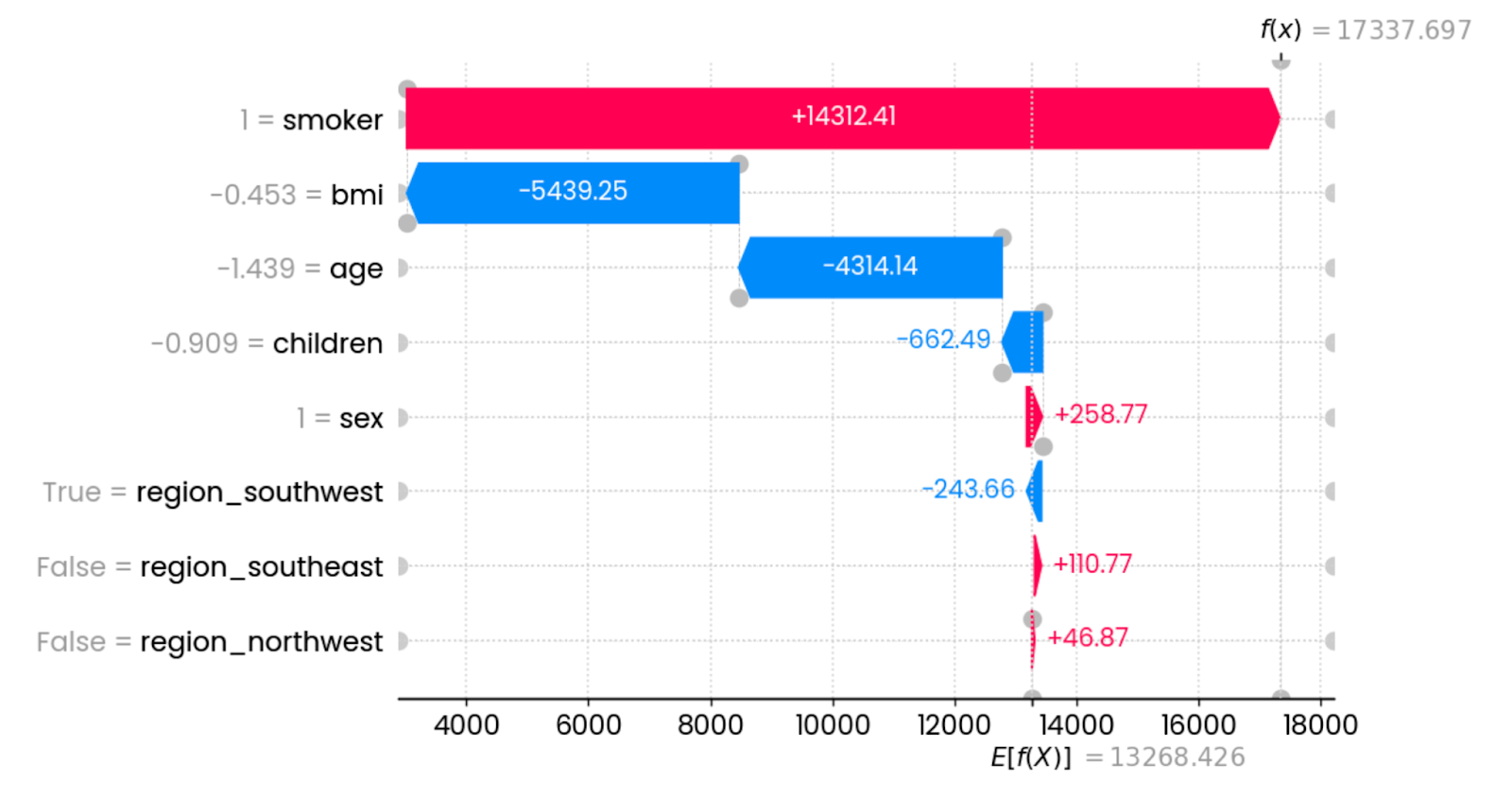
Erste Erklärungen zur Vorhersage. Bild vom Autor.
In diesem speziellen Fall erhöht das Rauchen die Versicherungskosten drastisch. Die Merkmale, die sich am stärksten auf die Senkung der Kosten auswirken, sind der BMI (in Verbindung mit dem Gewicht) und das Alter. Andere Funktionen haben nur minimale oder gar keine Auswirkungen.
Du kannst die obige Tabelle in einem kompakteren Format darstellen kompakteren Format darstellen:
shap.plots.force(shap_values[0])
Prägnante Erklärungen zur ersten Vorhersage. Bild vom Autor.
Die Information ist immer noch dieselbe: Rote Merkmale erhöhen die Gebühren und blaue Merkmale verringern sie. Der Punkt, an dem sie sich treffen, zeigt die Versicherungskosten für einen einzelnen Fall an.
Der Beeswarm Plot zeigt dir, welche Merkmale am wichtigsten sind, indem er die SHAP-Werte jedes Merkmals für jede Probe aufzeichnet. Die Merkmale werden nach der Summe der SHAP-Werte über alle Stichproben sortiert. Die Farbe steht für den Wert des Merkmals (rot bedeutet hoch und blau niedrig):
shap.plots.beeswarm(shap_values)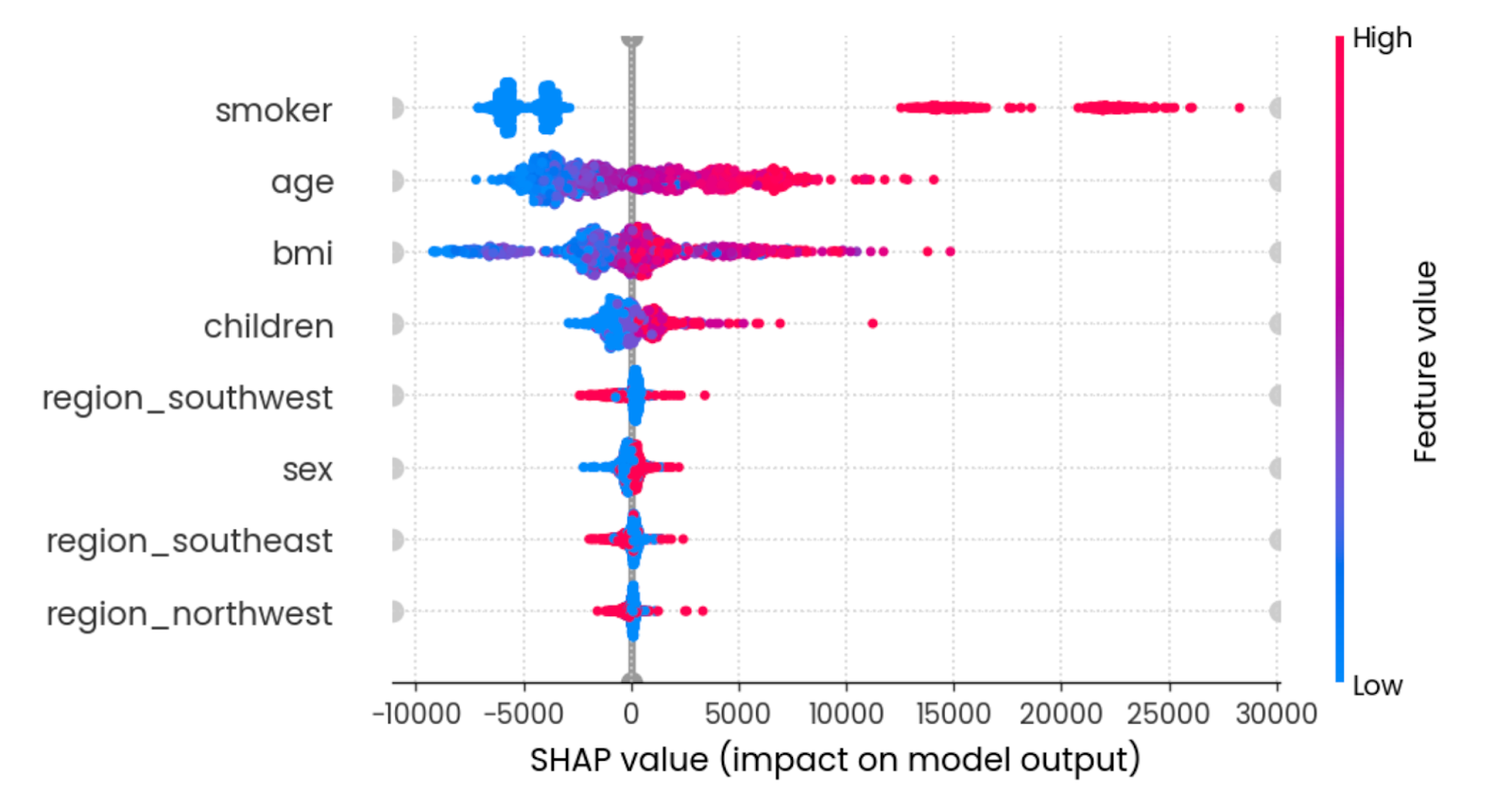
Zusammenfassende Wirkung aller Merkmale. Bild vom Autor.
Wenn du ein junger Nichtraucher mit einem angemessenen BMI bist, senkt das die Versicherungskosten.
Die letzte SHAP-Visualisierung, die ich zeigen möchte, ist das Balkendiagrammdes mittleren absoluten Werts . Sie berechnet den mittleren absoluten Wert aller SHAP-Werte für jedes Merkmal:
shap.plots.bar(shap_values)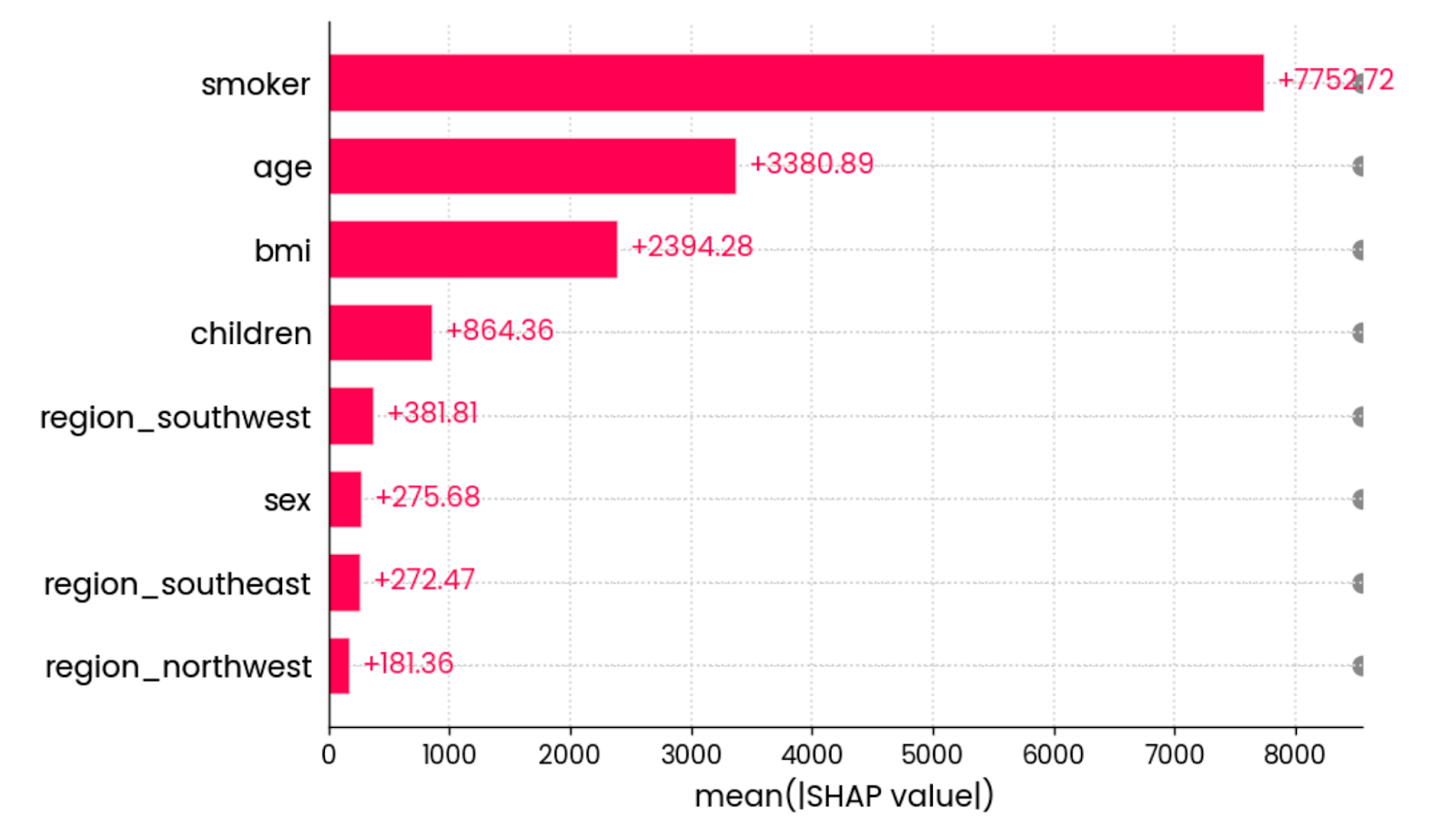
Der mittlere absolute Wert aller SHAP-Werte für alle Merkmale. Bild vom Autor.
Mit anderen Worten: Es ist eine schicke Art, die globale Bedeutung von Merkmalen zu berechnen - die Grafik ist nicht an eine einzelne Vorhersage gebunden.
Und das war's dann für SHAP. Als Nächstes werde ich den Fokus auf LIME legen.
Genau wie bei SHAP dreht sich bei LIME alles um interpretierbares maschinelles Lernen.
Es hat zwar nicht so viele Visualisierungsarten in seinem Werkzeuggürtel, aber es macht eine Sache gut - zumindest bei tabellarischen Datensätzen.
Zu Demonstrationszwecken lade ich den Klassifizierungsdatensatz und wandle ihn in eine binäre Klassifizierungsaufgabe um, indem ich die Einträge auf der Warteliste durch abgelehnte Einträge ersetze. So kannst du die Leistung von LIME leichter verstehen:
from lime import lime_tabular
df = load_classification_dataset()
# Convert to binary
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
X = df.drop("admission", axis=1)
y = df["admission"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
X_train.shape, y_test.shape
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Die Klasse LimeTabularExplainer() erhält nun Trainingsdaten, Spaltennamen, Namen der Kategorien in der Zielvariable und den Modus für maschinelles Lernen (Klassifizierung oder Regression):
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=["Admit", "Deny"],
mode="classification"
)Sobald dies geschehen ist, kannst du die Methode explain_instance() aufrufen, um eine einzelne Vorhersage zu interpretieren basierend auf den Wahrscheinlichkeiten der Klassenvorhersage zu interpretieren:
exp = explainer.explain_instance(
data_row=X_test.iloc[0],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)
LIME Erklärungen (1). Bild vom Autor.
Das LIME-Modell ist zu 96% sicher, dass diese MBA-Zulassung verweigert wird. Merkmale wie gmat und gender hatten den größten Einfluss auf die Entscheidung.
Machen wir nun dasselbe für einen Fall, der zum MBA-Programm zugelassen wurde:
exp = explainer.explain_instance(
data_row=X_test.iloc[234],
predict_fn=random_forest.predict_proba
)
exp.show_in_notebook(show_table=True)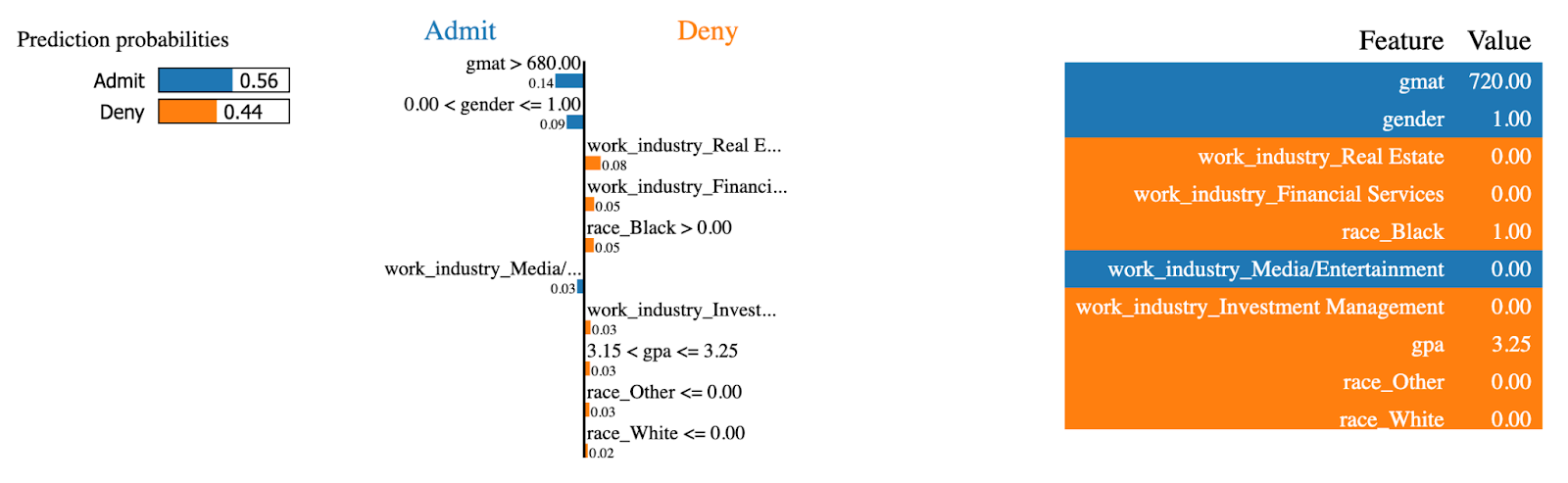
LIME Erklärungen (2). Bild vom Autor.
Die gleichen Merkmale hatten nun den gegenteiligen Effekt! Diese Person hatte eine hohe gmat Punktzahl, die am meisten dazu beiträgt, zum MBA-Programm zugelassen zu werden.
Und das war's dann mit den Baummodellen! Als Nächstes lernst du, wie du lineare Modelle für Regressionsaufgaben visualisieren kannst.
Wenn du gerade erst mit der prädiktiven Modellierung anfängst, geht es nicht einfacher als mit der linearen Regression. Es ist ein einfaches Modell, das leicht zu verstehen ist und gut funktioniert, wenn die Beziehungen in deinem Datensatz linear sind.
Es gibt noch andere lineare Modelle, aber in diesem Abschnitt werde ich nur mit der linearen Regression arbeiten.
Beginne damit, den Regressionsdatensatz zu laden, ihn in eine Trainings- und eine Testgruppe aufzuteilen und ein lineares Regressionsmodell an den Trainingsteil anzupassen:
from sklearn.linear_model import LinearRegression
df = load_regression_dataset()
X = df.drop("charges", axis=1)
y = df["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
model = LinearRegression().fit(X_train, y_train)Die erste Visualisierungsart, die ich untersuchen werde, sind die Modellkoeffizienten.
Im Klartext bedeutet das, dass ein lineares Regressionsmodell auf eine einzige Gleichung hinausläuft. Vielleicht erinnerst du dich an y = mx+b aus der Schulzeit - die Idee ist die gleiche.
Die Regressionsgleichung lässt sich auf y = w0 + w1_x1 + w2_x2 + … + wn_xn erweitern, um mehrere Parameter zu berücksichtigen. Das Ziel des Modells ist es, die beste Schätzung der Gewichte (w) zu finden, wenn die Menge der Eingangsmerkmale (x) gegeben ist.
Warum ist das also wichtig?
Da du auf die Koeffizienten (Gewichte) zugreifen kannst, nachdem das Modell trainiert wurde, und ihren Beitrag analysieren kannst, haben Merkmale mit einem größeren Koeffizienten einen höheren Beitrag zur Vorhersage der Zielvariablen.
Du kannst die Koeffizienten erhalten, indem du den Parameter coef_ eines trainierten Modells aufrufst.
Das folgende Snippet ermittelt die Koeffizienten und stellt sie in einem horizontalen Balkendiagramm dar:
features = X_train.columns
coefficients = model.coef_
plt.figure(figsize=(10, 4))
bars = plt.barh(y=features, width=coefficients, edgecolor="#008031", linewidth=1)
for bar in bars:
width = bar.get_width()
plt.text(width + 1, bar.get_y() + bar.get_height()/2, f"{width:.2f}",
va="center", ha="left")
plt.xlabel("Coefficient value")
plt.title("Linear Regression Model Coefficients", y=1.05)
plt.show()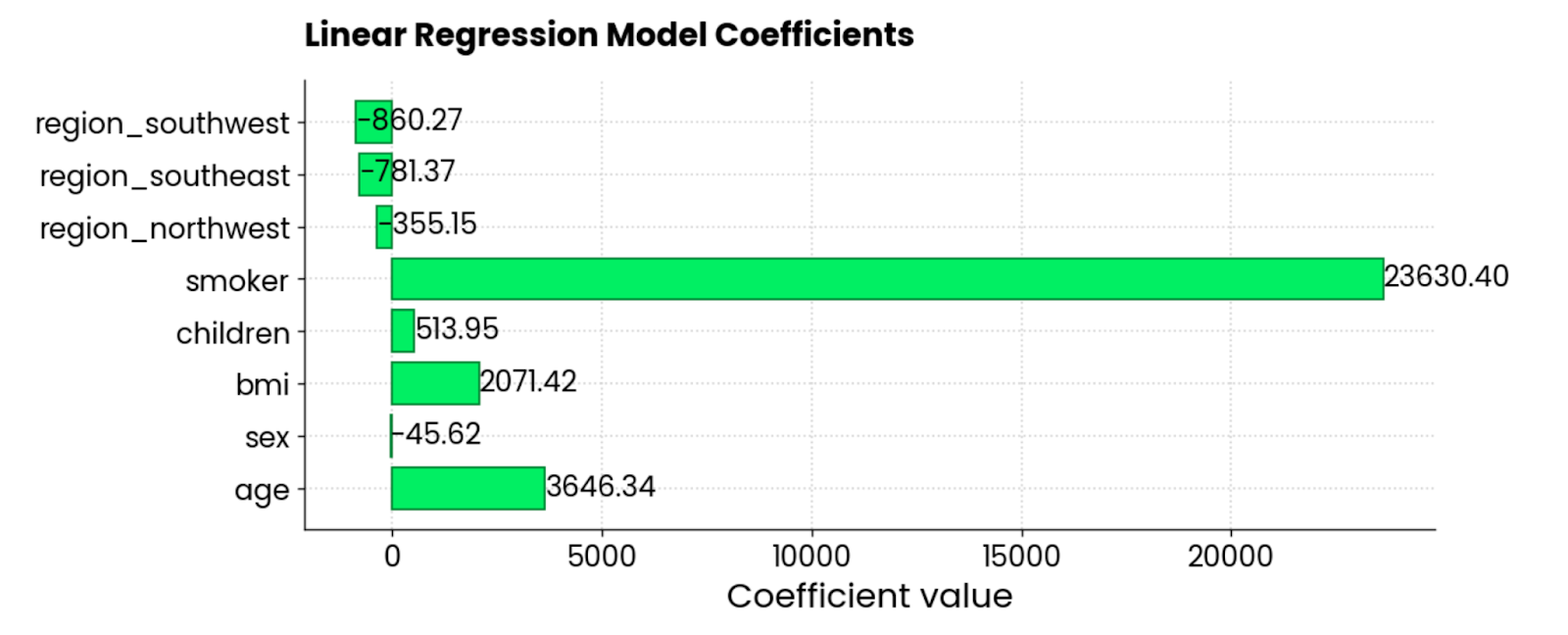
Koeffizienten des linearen Regressionsmodells. Bild vom Autor.
Die Merkmale smoker, BMI und age tragen am meisten zu den Versicherungskosten bei - wenn sie steigen, steigt auch der Betrag. Es gibt auch ein paar negative Koeffizienten, die den Gesamtbetrag verringern.
Die andere gängige Art der Regressionsdarstellung ist der Residual Plot. Im Klartext: Du erstellst ein Streudiagramm mit vorhergesagten Werten auf der X-Achse und Residuen (wahre Werte - vorhergesagte Werte) auf der Y-Achse.
Im Idealfall sollten in den Residuen keine Muster zu sehen sein und sie sollten um 0 herum zentriert sein. Mit anderen Worten: Sie sollten normal verteilt sein.
Verwende dieses Codeschnipsel, um die Residuen eines linearen Regressionsmodells für den Versicherungsdatensatz zu visualisieren:
y_pred = model.predict(X_test)
residuals = y_test - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, color="#03EF62", alpha=0.6, edgecolors="#008031")
plt.axhline(0, color="red", linestyle="--")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.title("Residuals vs Predicted Values", y=1.05)
plt.grid(True)
plt.show()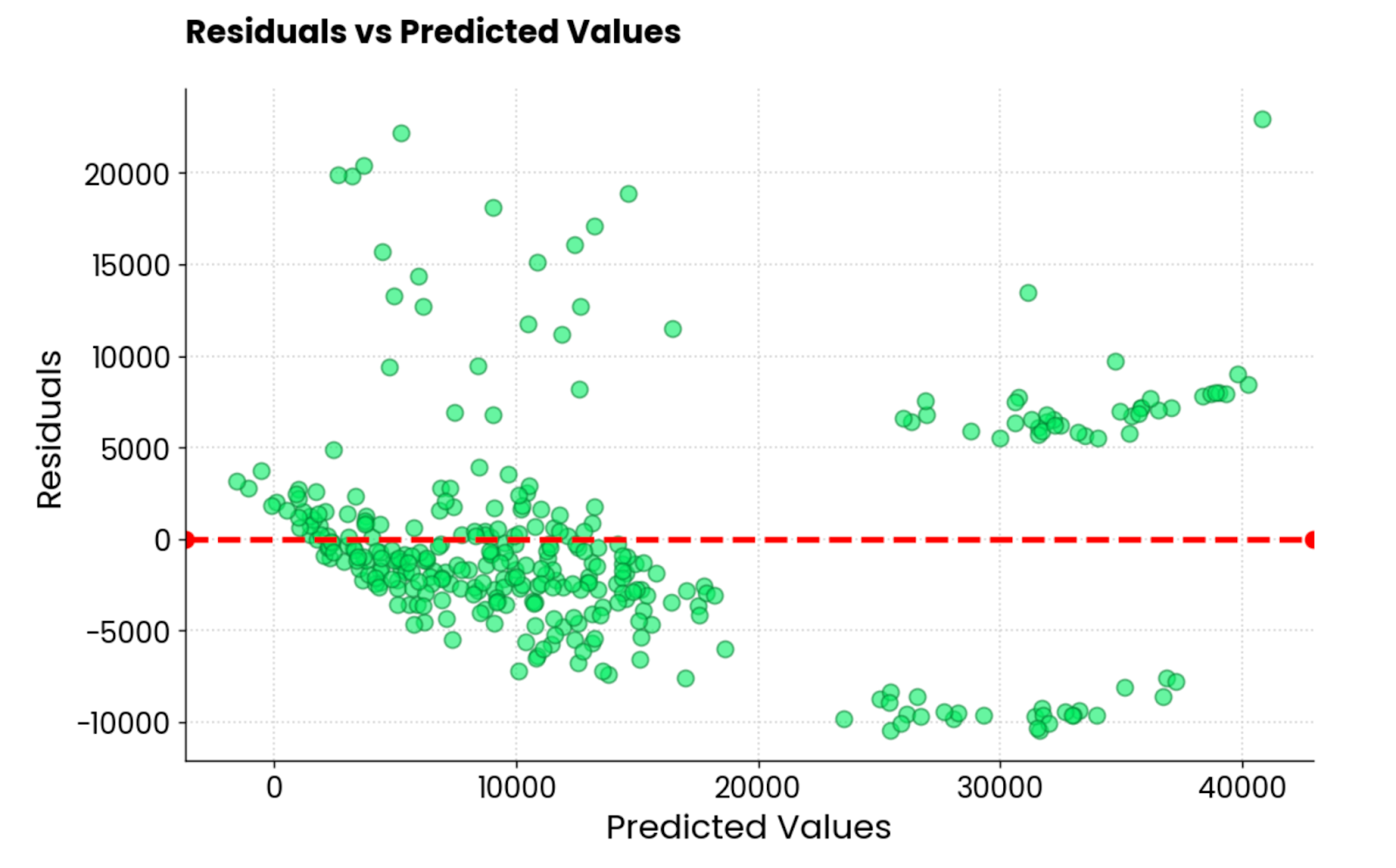
Residuen des linearen Regressionsmodells. Bild vom Autor.
Es ist nicht der beste Restplot, den ich je gesehen habe. Ästhetisch sieht es gut aus, aber die Werte sind total durcheinander. Wenn du ein/e Praktiker/in für maschinelles Lernen bist und ein ähnliches Residualdiagramm erhältst, hast du noch eine Menge Arbeit vor dir.
Als Nächstes zeige ich dir 3 Möglichkeiten, neuronale Netzwerkmodelle zu visualisieren.
Wenn es einen Bereich des maschinellen Lernens gibt, in dem Visualisierung und Interpretation am wichtigsten sind, dann sind es die neuronalen Netze.
Diese sind selbst auf der grundlegendsten Ebene kompliziert zu begreifen. Es gibt verschiedene Ebenentypen, Aktivierungsfunktionen und Backpropagation - um nur ein paar zu nennen. Aus diesem Grund werden neuronale Netze oft als Synonym für Blackbox-Modelle verwendet.
Das muss nicht so sein.
In diesem Abschnitt zeige ich dir drei Möglichkeiten, neuronale Netze zu visualisieren: Architekturdiagramme, Echtzeit-Trainingsmetriken und Grad-CAM.
Meine Bibliothek der Wahl ist TensorFlow. Wenn du noch nie etwas davon gehört hast, findest du untereinen Kurs "TensorFlow für Anfänger" , der dir den Einstieg erleichtern wird.
Wenn du die Architektur deines neuronalen Netzmodells visualisierst, wird dir eine Sache entmystifiziert - Formen.
Mit anderen Worten: Du wirst sehen, wie sich die Größe der zugrunde liegenden Matrix verändert, wenn du dich durch die Ebenen bewegst. Für Neulinge kann das ein schwieriges Thema sein, deshalb ist jede Visualisierung mehr als willkommen.
Zur Demonstration verwende ich TensorFlow, um ein grundlegendes neuronales Netzwerkmodell für die Klassifizierung von handgeschriebenen Ziffern zu erstellen. Dann verwende ich die Funktion plot_model(), um das Bild der Modellarchitektur in einer lokalen Datei zu speichern.
Sieh es dir selbst an:
from tensorflow.keras import layers, models
from tensorflow.keras.utils import plot_model
model = models.Sequential()
model.add(layers.Input(shape=(28, 28, 1)))
model.add(layers.Conv2D(32, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
plot_model(model, to_file="model_architecture.png", show_shapes=True, show_layer_names=True)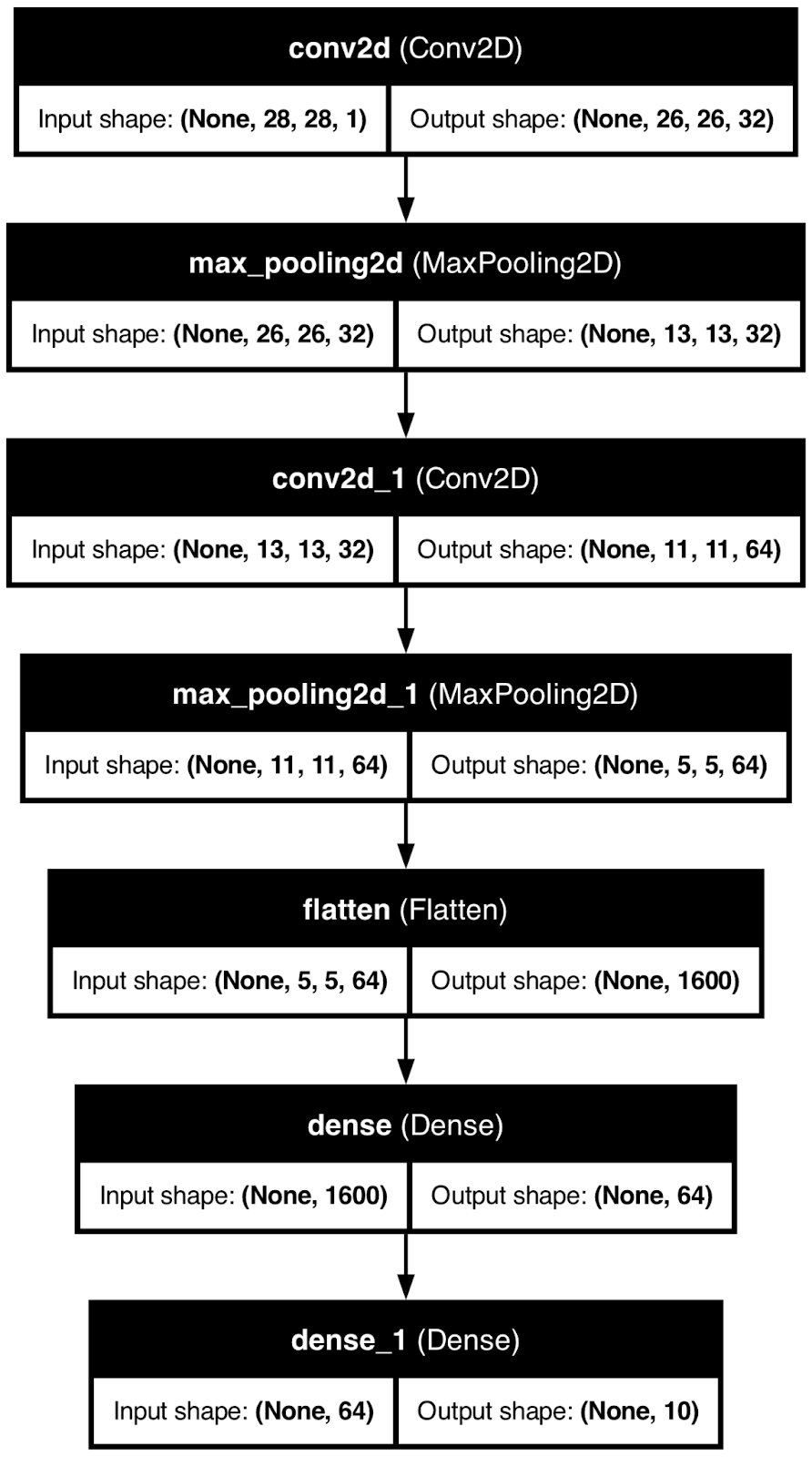
Architektur des neuronalen Netzes. Bild vom Autor.
Diese Art der Visualisierung ist zwar hilfreich, aber sie bringt dich nur bedingt weiter.
Du weißt, wie sich die Daten im Laufe der Zeit verändern, aber du hast keine Vorstellung davon, wie ein neuronales Netzwerkmodell zu seinen Schlussfolgerungen kommt. Das werde ich als Nächstes behandeln.
Grad-CAM, oder Gradient Class Activation Mapping ist eine beliebte Technik zur Visualisierung von Modellen für faltige neuronale Netze.
Genauer gesagt, hilft es dir zu verstehen , welche Teile eines Eingangsbildes am meisten zu den Vorhersagen des Modells beitragen. Stell dir vor, dass es sich dabei um die Darstellung der Wichtigkeit eines Entscheidungsbaums handelt, nur eben auf 11.
Es ist eine fortschrittliche Interpretationsmethode, die für alle Faltungsmodelle unabhängig von ihrer Architektur funktioniert und dir hilft zu verstehen, warum ein neuronales Netzwerkmodell eine bestimmte Vorhersage trifft.
Aber hier ist das Problem - es ist nicht trivial in Python zu implementieren. Hier ist ein grober Überblick über den Algorithmus:
Das ist ein ziemlich komplizierter Prozess, und um die Sache zu vereinfachen, verwende ich ein vortrainiertes ResNet50 Modell, das bereits 1000 verschiedene Bildtypen klassifizieren kann.
Aber zuerst lädst du die notwendigen Bibliotheken und das Bild, für das du eine Grad-CAM anzeigen möchtest. Ich verwende ein Bild von einem Hund:
import cv2
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing.image import load_img
image = np.array(load_img("dog.jpg", target_size=(224, 224, 3)))
plt.grid(False)
plt.imshow(image)
Beispielbild eines Hundes. Bild vom Autor.
Jetzt beginnt der spaßige Teil. Im folgenden Codeschnipsel implementiere ich den oben beschriebenen vierstufigen Prozess. Zum besseren Verständnis findest du Kommentare über jeder Codezeile:
# Load the pre-trained ResNet50 model
model = ResNet50()
# Extract the output of the last convolutional layer
last_conv_layer = model.get_layer("conv5_block3_out")
# Create a model that outputs the last convolutional layer’s activations
last_conv_layer_model = tf.keras.Model(model.inputs, last_conv_layer.output)
# Prepare the classifier model using the layers after the last convolutional layer
classifier_input = tf.keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in ["avg_pool", "predictions"]:
# Reuse the pooling and prediction layers from the ResNet50 model
x = model.get_layer(layer_name)(x)
# Create a new model that takes in the last conv layer output and returns predictions
classifier_model = tf.keras.Model(classifier_input, x)
# Use a GradientTape to record operations for automatic differentiation
with tf.GradientTape() as tape:
# Prepare the input image and get the activations from the last conv layer
inputs = image[np.newaxis, ...]
last_conv_layer_output = last_conv_layer_model(inputs)
tape.watch(last_conv_layer_output) # Watch the conv layer output
# Get predictions from the classifier model
preds = classifier_model(last_conv_layer_output)
# Get the index of the highest predicted class
top_pred_index = tf.argmax(preds[0])
# Focus on the prediction of the top class
top_class_channel = preds[:, top_pred_index]
# Compute the gradient of the top predicted class with respect to the conv layer output
grads = tape.gradient(top_class_channel, last_conv_layer_output)
# Average the gradients over the width and height dimensions
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
# Multiply each channel in the conv layer output by its corresponding gradient
last_conv_layer_output = last_conv_layer_output.numpy()[0]
pooled_grads = pooled_grads.numpy()
for i in range(pooled_grads.shape[-1]):
last_conv_layer_output[:, :, i] *= pooled_grads[I]
# Compute the Grad-CAM by averaging the channels and apply a ReLU activation
gradcam = np.mean(last_conv_layer_output, axis=-1)
# Normalize the Grad-CAM to be between 0 and 1
gradcam = np.clip(gradcam, 0, np.max(gradcam)) / np.max(gradcam)
# Resize the Grad-CAM heatmap to the size of the original image (224x224)
gradcam = cv2.resize(gradcam, (224, 224))Das war zwar viel, aber jetzt kannst du endlich die Heatmap zeichnen, die der Grad-CAM-Algorithmus erzeugt:
plt.grid(False)
plt.imshow(gradcam)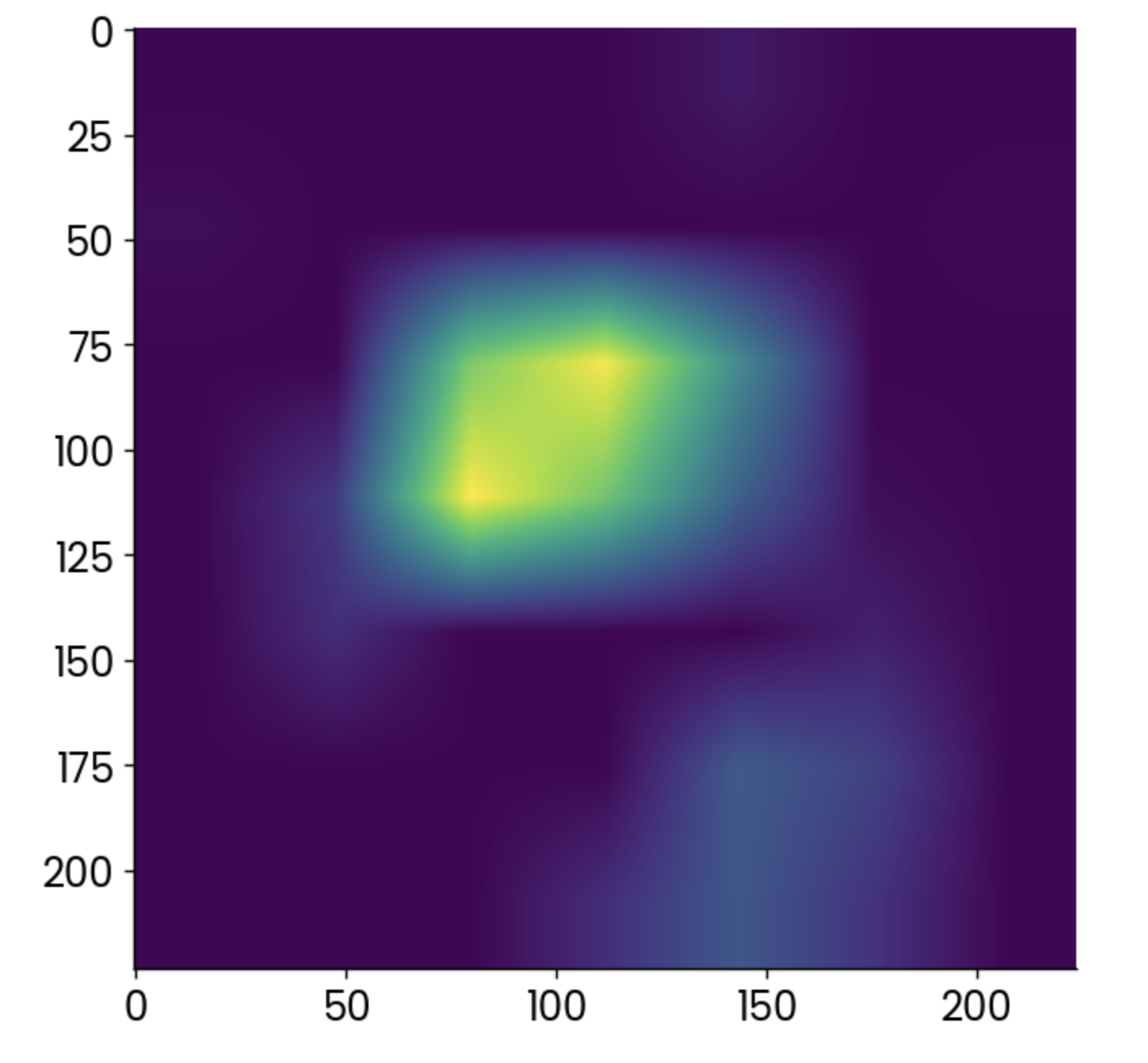
Grad-CAM Heatmap. Bild vom Autor.
Hellere Punkte zeigen Bereiche an, in denen die Aktivierung am höchsten war, aber die Heatmap allein sagt dir nicht viel.
Es ist viel besser, wenn du es über das Originalbild legst und die Deckkraft etwas reduzierst:
plt.grid(False)
plt.imshow(image)
plt.imshow(gradcam, alpha=0.5)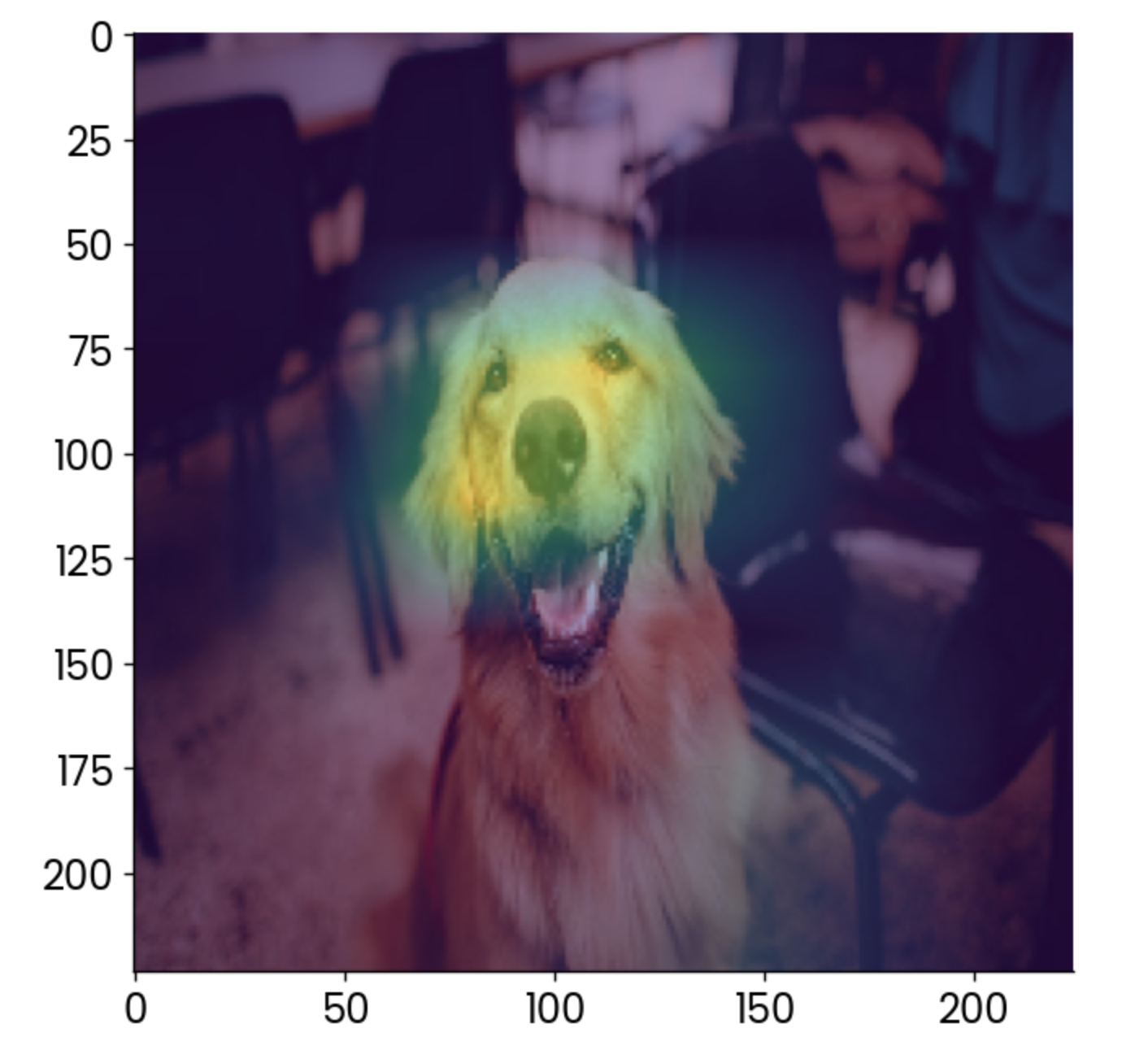
Hundebild mit einem Grad-CAM-Overlay. Bild vom Autor.
Für die Interpretation trägt vor allem das Gesicht dazu bei, dass dieses Bild als "Golden Retriever" eingestuft wird, was auch Sinn macht.
Mit Grad-CAM kannst du sicherstellen, dass dein Modell die richtigenVorhersagen macht . In diesem Fall stell dir vor, dass die Heatmap etwas anderes, wie zum Beispiel den Stuhl im Hintergrund, als den wichtigsten Faktor anzeigt. Du würdest diesem Modell nicht trauen, oder?
Das Training eines neuronalen Netzwerks kann sehr lange dauern. Das Gute daran ist, dass du nicht warten musst, bis das Training abgeschlossen ist, um einen Einblick in die Leistung des Modells zu bekommen. Bibliotheken wie TensorBoard können dir das in Echtzeit zeigen.
TensorBoard wird mit TensorFlowso dass du nichts installieren musst, um mitzumachen.
Zu Demonstrationszwecken trainiere ich ein einfaches Ziffernklassifizierungsmodell für 25 Epochen. Der wichtige Teil ist der Rückruf -dort gibst du den Pfad und das Format für die Trainingsprotokolle an, die TensorBoard in einer Minute verwenden wird.
Dies ist der Code, den du brauchst, um das Modell zu trainieren und die Trainingsprotokolle zu speichern:
import tensorflow as tf
from tensorflow.keras import layers, models
from datetime import datetime
# Load MNIST dataset
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values between 0 and 1
x_train, x_test = x_train / 255.0, x_test / 255.0
# Add a channels dimension (for the Convolutional layer)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
# Build a simple CNN model
model = models.Sequential([
layers.Conv2D(32, kernel_size=(3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax")
])
# Compile the model
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
# Set up TensorBoard callback
log_dir = "logs/fit/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Train the model with TensorBoard monitoring
model.fit(
x_train,
y_train,
epochs=25,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback]
)
Prozess der Modellbildung. Bild vom Autor.
Während das Modell trainiert, starte TensorBoard vom Terminal aus und gib einen Pfad zum Ordner mit den Trainingsprotokollen an:
tensorboard --logdir=logs/fitTensorBoard läuft standardmäßig auf Port 6006:
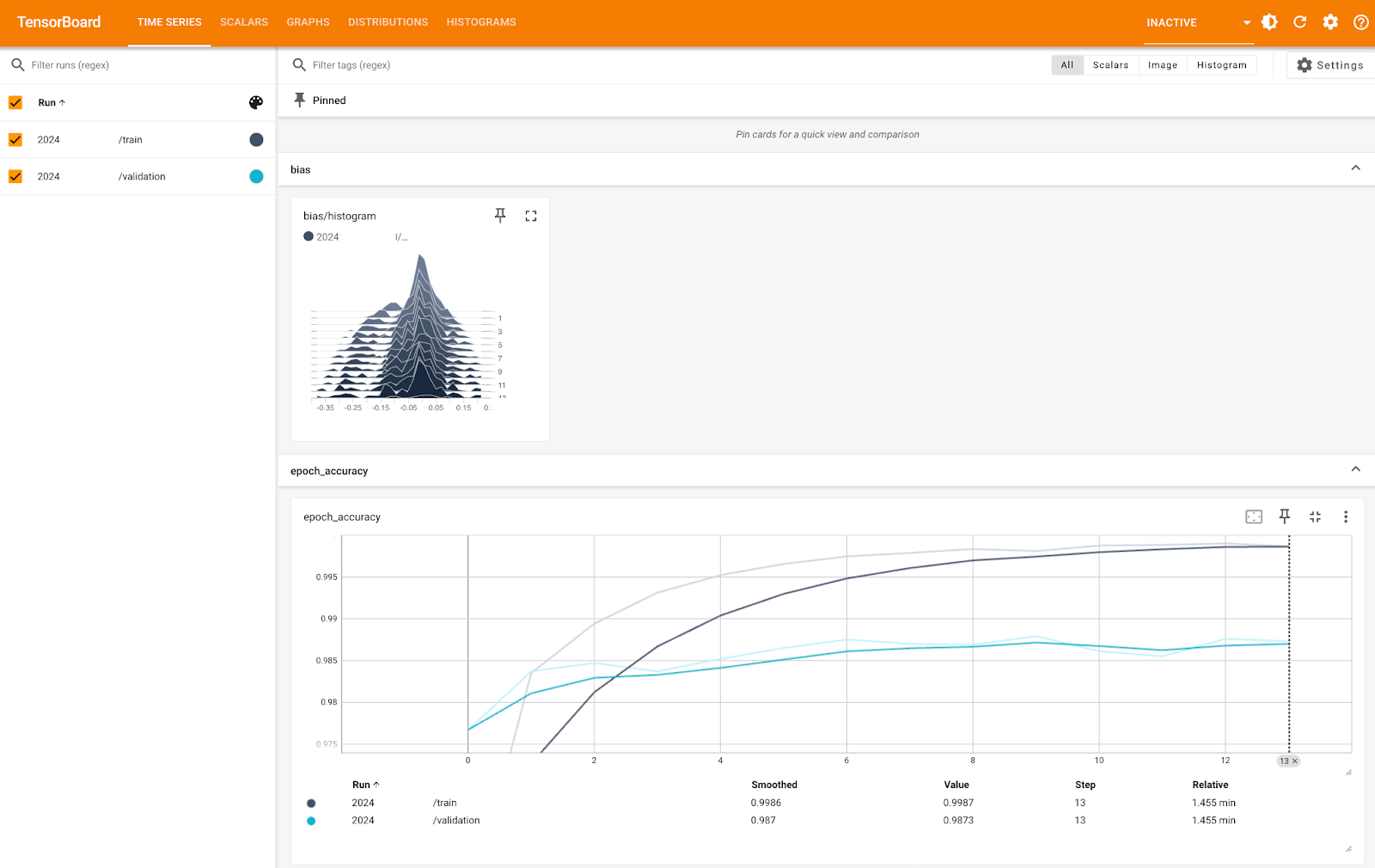
TensorBoard Metriken (1). Bild vom Autor.
Das Bild oben zeigt dir das Bias-Histogramm und die Genauigkeit pro Epoche, sowohl für die Trainings- als auch für die Validierungsmenge. Du kannst sehen, dass die Genauigkeit bei beiden sehr hoch ist, fast 100 % - nur die Skala der Y-Achse ist zu klein.
Andere Registerkarten befassen sich mit spezifischeren Metriken und ermöglichen es dir, bestimmte Dinge zu optimieren, wie du unten sehen kannst:
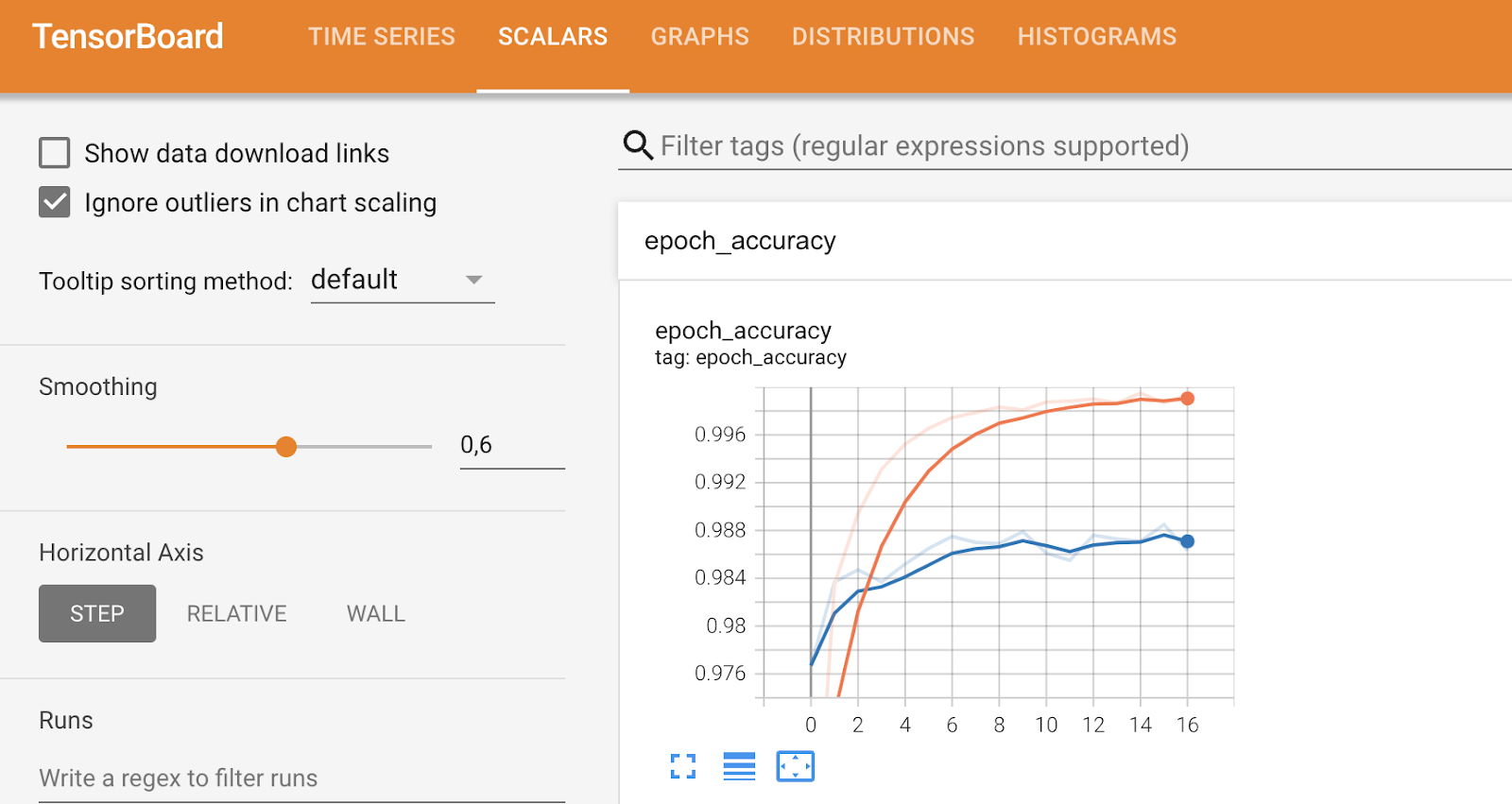
TensorBoard-Metriken (2). Bild vom Autor.
Zusammenfassend lässt sich sagen, dass TensorBoard ein ordentliches Werkzeug zur Visualisierung der Modellleistung ist und dir helfen kann, die Leistung zu analysieren, während das Modell trainiert wird.
In diesem letzten Teil möchte ich einen Schritt zurückgehen und auf allgemeinere Metriken zur Visualisierung der Leistung des Modells eingehen.
Du wirst sehen drei Konfusionsmatrix, ROC-Kurvendiagramm und Precision-Recall-Kurvendiagramm.
Da sie mit Klassifizierungsproblemen verbunden sind, musst du den Klassifizierungs-MBA-Datensatzladen . Um die Sache einfacher zu machen, habe ich es auch in ein binäres Klassifizierungsproblem umgewandelt, indem ich die Einträge auf der Warteliste auf "verweigert" gesetzt habe. Der Rest des Codeschnipsels teilt die Daten in Trainings- und Testteilmengen auf und erstellt zunächst ein Random-Forest-Klassifizierungsmodell:
from sklearn.ensemble import RandomForestClassifier
df = load_classification_dataset()
df["admission"] = df["admission"].replace({"Waitlist": "Deny"})
df["admission"] = df["admission"].replace({"Deny": 0, "Admit": 1})
df.rename(columns={"admission": "is_admitted"}, inplace=True)
X = df.drop("is_admitted", axis=1)
y = df["is_admitted"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
random_forest = RandomForestClassifier(n_estimators=25, random_state=42)
random_forest.fit(X_train, y_train)Lass uns in die erste Metrik eintauchen - die Konfusionsmatrix.
Eine Konfusionsmatrix zeigt dir, wie gut dein Modell abschneidet. Im Idealfall wären die Werte auf der Diagonale von links oben nach rechts unten die einzigen Elemente, die nicht Null sind, was bedeutet, dass das Modell keine falschen Vorhersagen getroffen hat.
Aber das passiert in der realen Welt nicht oft.
Nutze die folgenden Richtlinien, um eine Konfusionsmatrix (für binäre Klassifizierung) zu interpretieren:
Es gibt keine allgemeine Regel dafür, ob du dich mehr um falsch-positive oder falsch-negative Ergebnisse kümmern solltest. Bei MBA-Zulassungen ist der Prior schmerzhafter, da das Modell den zuzulassenden Studenten klassifiziert hat, aber das war in der Realität nicht der Fall. In anderen Fällen, wie z. B. bei der Krebsvorhersage, ist es wichtig, die Anzahl der falsch-negativen Ergebnisse zu minimieren, denn du willst nicht, dass jemand als gesund eingestuft wird, obwohl er Krebs hat.
Hier kommt das Fachwissen ins Spiel.
Wie auch immer, zurück zum Code. Das folgende Snippet berechnet die Konfusionsmatrix unseres Random-Forest-Modells für die Testmenge und verwendet die Klasse ConfusionMatrixDisplay, um eine Visualisierung zu erstellen:
from sklearn.metrics import confusion_matrix
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
preds = random_forest.predict(X_test)
cm = confusion_matrix(y_true=y_test, y_pred=preds, labels=random_forest.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=random_forest.classes_)
disp.plot()
plt.grid(False)
plt.title("Confusion Matrix", y=1.04)
plt.show()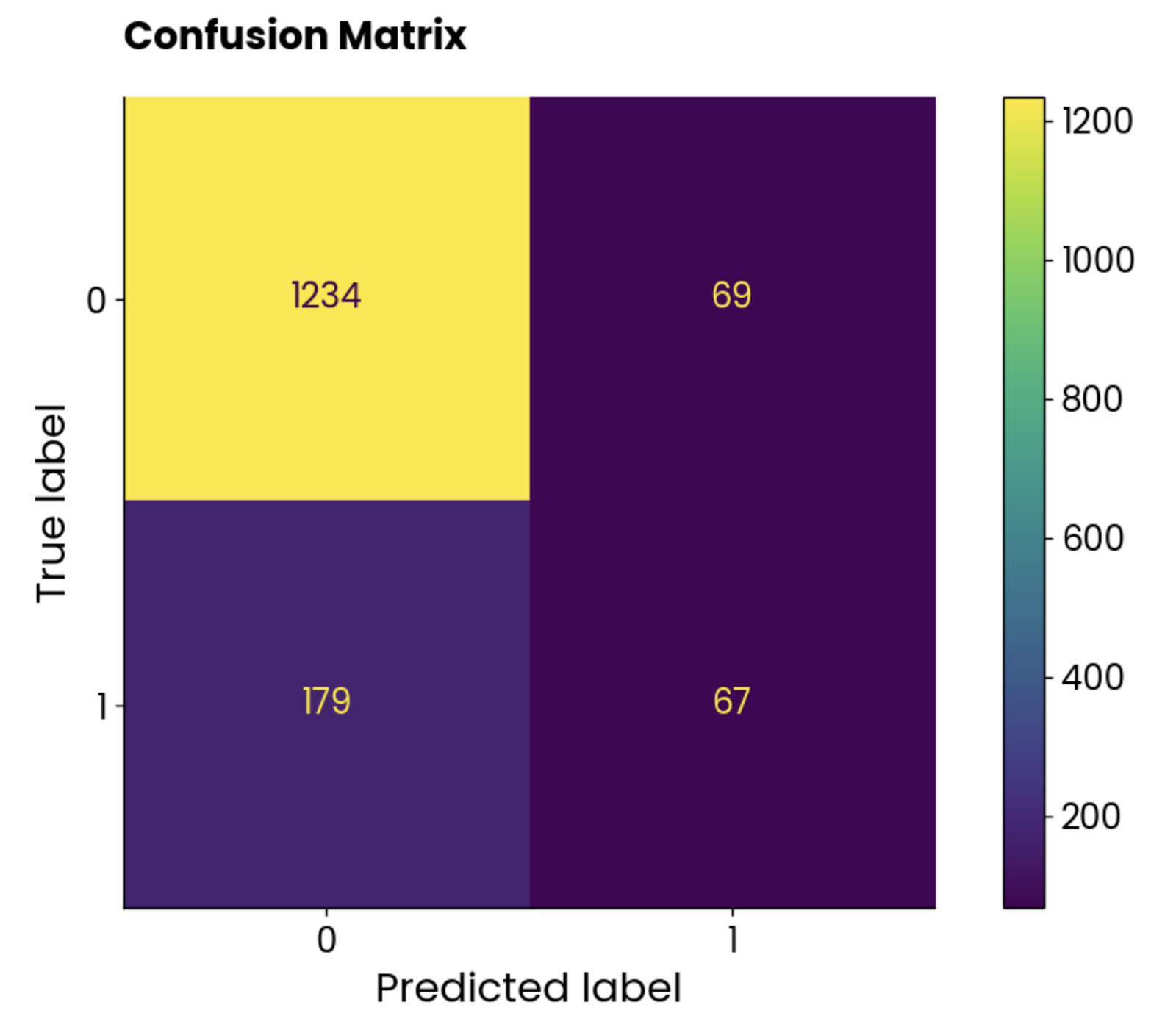
Konfusionsmatrix-Plot. Bild vom Autor.
Die Klassen sind nicht ausgeglichen, aber die Zahl der falschen Vorhersagen ist erstaunlich hoch.
Schauen wir mal, was die ROC-Kurve zu sagen hat.
ROC steht für Receiver Operating Characteristics und ist eine Kurve, die die Leistungsbewertung eines binären Klassifikationsmodells anzeigt. Bei der Mehrklassen-Klassifizierung musst du zwei Klassen gleichzeitig vergleichen.
Die ROC-Kurve zeigt einen Kompromiss zwischen der wahr-positiven Rate (TPR, Sensitivität, Recall) und der falsch-positiven Rate (FPR) bei verschiedenen Klassifizierungsschwellenwerten. Die TPR wird auf der Y-Achse gegen die FPR auf der X-Achse aufgetragen. Jeder Punkt steht für einen anderen Schwellenwert für die Klassifizierungsentscheidung (Wahrscheinlichkeitswert, mit dem eine Instanz als positiv oder negativ eingestuft wird).
Die Kurve wird normalerweise gegen eine Diagonale von (0, 0) bis (1, 1) aufgetragen, die einen zufälligen Klassifikator darstellt.
Wenn die Kurve oberhalb der Diagonale liegt, bedeutet das, dass dein Modell besser abschneidet als ein zufälliger Klassifikator. Ein einziger skalarer Wert fasst das zusammen. Sie wird AUC (Area Under the Curve) genannt und reicht von 0 bis 1, wobei ein höherer Wert besser ist und 0,5 zufällig ist.
Kurz gesagt, du willst die Kurve so nah wie möglich an der oberen linken Ecke haben.
Verwende das folgende Snippet, um ROC und AUC zu berechnen und die Kurve darzustellen:
from sklearn.metrics import roc_curve, auc
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
fpr, tpr, roc_thresholds = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, label=f"AUC = {roc_auc:.2f}")
plt.plot([0, 1], [0, 1], color="navy", linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve", y=1.04)
plt.legend(loc="lower right")
plt.show()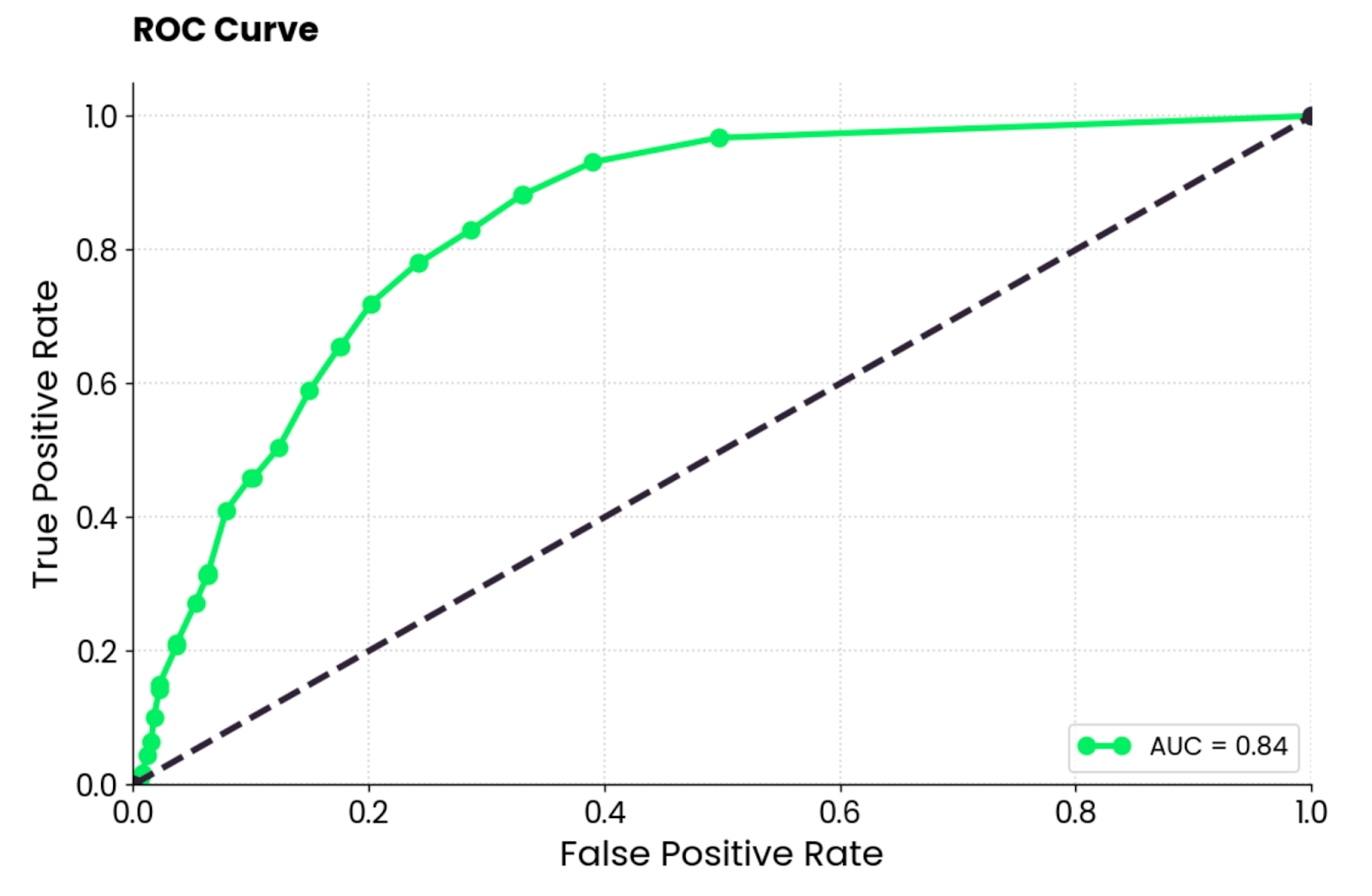
ROC-Kurven-Diagramm. Bild vom Autor.
Für die Interpretation ist das Random-Forest-Modell viel besser als ein zufälliger Klassifikator und hat ein vernünftiges Gleichgewicht zwischen wahren Positiven und falschen Positiven. Es ist immer noch ein gewisses Maß an Fehlklassifizierung vorhanden, und du solltest versuchen, die Kurve nach oben und nach links zu verschieben, indem du die Daten optimierst oder ein anderes maschinelles Lernmodell wählst.
Diese Kurve ähnelt der ROC-Kurve, zeigt aber den Kompromiss zwischen Präzision und Recall für verschiedene Klassifizierungsschwellenwerte. Sie zeigt die Genauigkeit auf der Y-Achse und die Wiedererkennung auf der X-Achse an und wird in der Regel dem ROC vorgezogen, wenn die Klassen unausgewogen sind.
Das ist auch bei den MBA-Zulassungsdaten der Fall, also klingt eine PR-Kurve nach einer guten Lösung!
Es ist wichtig zu beachten, dass sich die Kurven für die Genauigkeit des Abrufs nur auf die Minderheitenklasse konzentrieren und ein besseres Bild davon vermitteln, wie gut das Modell die wichtigsten Fälle (zugelassene Schüler, entdeckte Krebsfälle usw.) identifiziert.
Verwende das folgende Snippet, um die Precision- und Recall-Werte zu berechnen und sie in einem Diagramm darzustellen:
from sklearn.metrics import precision_recall_curve
# Get predicted probabilities for the positive class
y_probs = random_forest.predict_proba(X_test)[:, 1]
# Precision-Recall curve
precision, recall, pr_thresholds = precision_recall_curve(y_test, y_probs)
pr_auc = auc(recall, precision)
plt.plot(recall, precision, label=f"(AUC = {pr_auc:.2f})")
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve", y=1.04)
plt.legend(loc="lower left")
plt.show()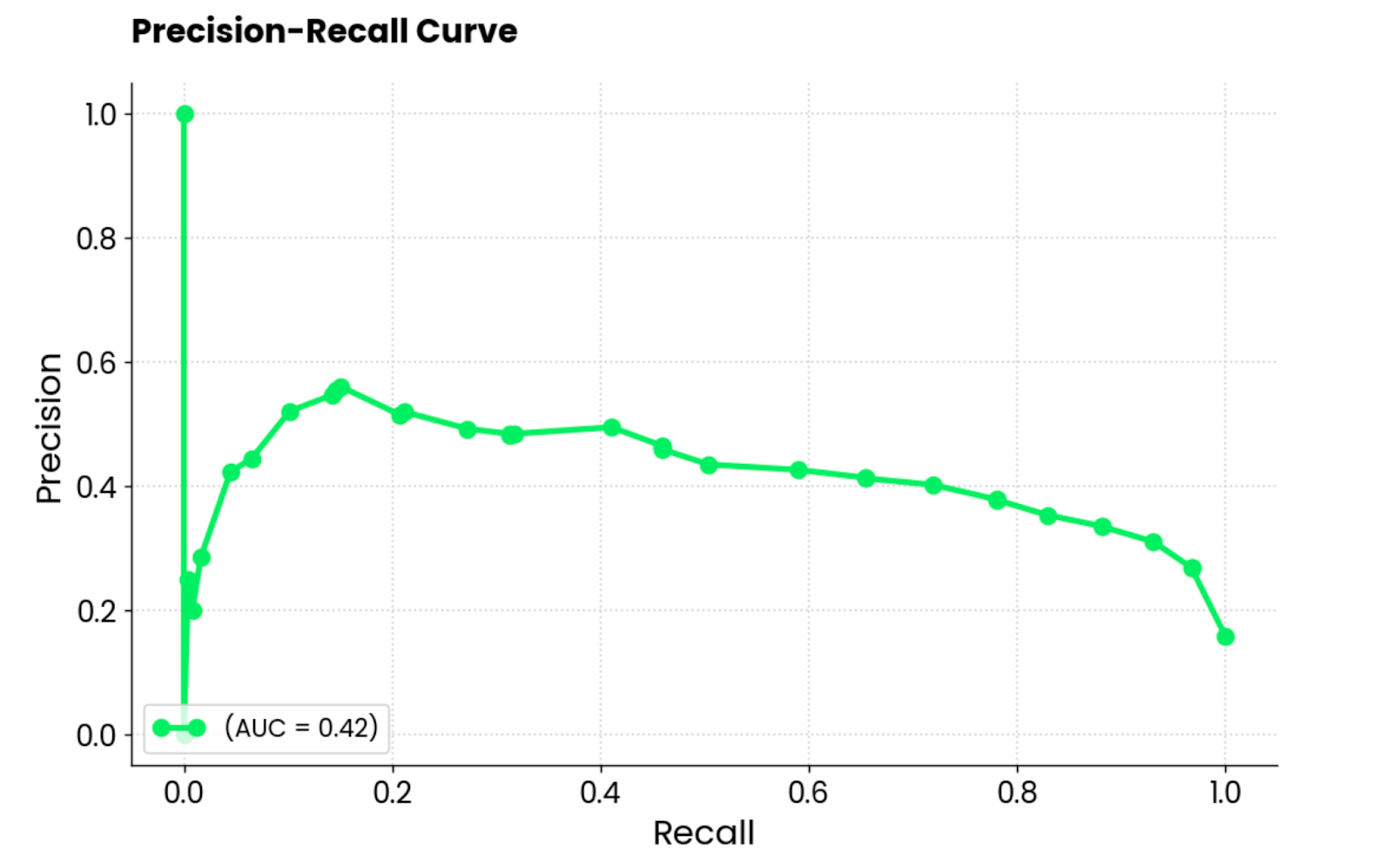
Kurve für die Genauigkeit und den Abruf. Bild vom Autor.
Zur Interpretation: Das Modell schneidet schlecht ab, wie der AUC-Wert von 0,42 zeigt. Wenn das Modell versucht, die Aufklärungsquote zu erhöhen, opfert es zu viel Präzision, was zu vielen falsch positiven Ergebnissen führt. Kurz gesagt, dieses Modell ist nicht gut für diesen Datensatz geeignet oder der Datensatz selbst ist nicht ausreichend aufbereitet.
Abschließend lässt sich sagen, dass der Bereich des maschinellen Lernens komplex und oft nicht intuitiv ist. Wenn du ein Anfänger bist, wird es dir schwer fallen, die großen Ideen zu verstehen. Wenn du mit einem Geschäftskunden zusammenarbeitest, wird er wahrscheinlich den Fachjargon nicht verstehen.
Datenvisualisierung hilft, die Lücke in beiden Szenarien zu schließen.
Heute hast du all die verschiedenen Diagrammtypen gesehen, die du zur Visualisierung von Regressions- und Klassifizierungsmodellen verwenden kannst, sowie den Entscheidungsprozess von neuronalen Netzen und die Interpretation einzelner Vorhersagen durch SHAP und LIME. Das ist eine Menge, also kannst du dir diesen Artikel ruhig mehrmals ansehen!
Wenn du ganz neu auf dem Gebiet bist, empfehlen wir dir für den Einstieg unseren Kurs "Grundlagen des maschinellen Lernens ". Danach ist ein anwendungsorientierter Kurs mit Python genau das Richtige.
Wenn du schon etwas Erfahrung hast, aber nicht verstehst, wie das Ganze in einem größeren Maßstab funktioniert, empfehlen wir dir, unseren Kurs zum maschinellen Lernen für die Produktion auszuprobieren.
Lerne mehr über maschinelles Lernen mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
