Cours
Python intermédiaire
4 h
1.4M
L'importante contribution des chercheurs en NLP (Natural Language Processing) au cours des dernières décennies a permis d'obtenir des résultats innovants dans différents domaines. Vous trouverez ci-dessous quelques exemples de traitement du langage naturel dans la pratique :
Ce blog conceptuel vise à couvrir les Transformers, l'un des modèles les plus puissants jamais créés dans le domaine du traitement du langage naturel. Après avoir expliqué leurs avantages par rapport aux réseaux neuronaux récurrents, nous vous aiderons à mieux comprendre Transformers. Ensuite, nous vous présenterons quelques cas concrets d'utilisation des transformateurs Huggingface.
Vous pouvez également en apprendre davantage sur la création d'applications de PNL avec Hugging Face grâce à notre code-along.
Avant de plonger dans le concept de base des transformateurs, comprenons brièvement ce que sont les modèles récurrents et leurs limites.
Les réseaux récurrents utilisent l'architecture codeur-décodeur, et nous les utilisons principalement pour traiter des tâches où l'entrée et les sorties sont des séquences dans un ordre défini. La traduction automatique et la modélisation de données de séries temporelles comptent parmi les applications les plus importantes des réseaux récurrents.
Examinons la traduction en anglais de la phrase française suivante. L'entrée transmise au codeur est la phrase française originale, et la sortie traduite est générée par le décodeur.
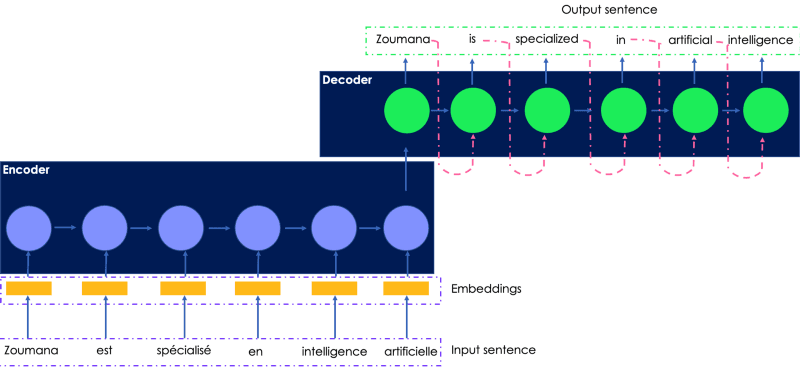
Une illustration simple du réseau récurrent pour la traduction des langues
Ne serait-il pas formidable de disposer d'un modèle qui combine les avantages des réseaux récurrents et rend possible le calcul parallèle ?
C'est là que les transformateurs s'avèrent utiles.
Transformers est la nouvelle architecture de réseau neuronal, simple mais puissante, introduite par Google Brain en 2017 avec son célèbre document de recherche "Attention is all you need" (l 'attention est tout ce dont vous avez besoin). Il est basé sur le mécanisme d'attention et non sur le calcul séquentiel que l'on peut observer dans les réseaux récurrents.
À l'instar des réseaux récurrents, les transformateurs se composent également de deux blocs principaux : le codeur et le décodeur, chacun étant doté d'un mécanisme d'auto-attention. La première version des transformateurs avait une architecture de codeur-décodeur RNN et LSTM, qui a été modifiée par la suite en réseaux d'auto-attention et de feed-forward.
La section suivante donne un aperçu général des principaux composants de chaque bloc de transformateurs.
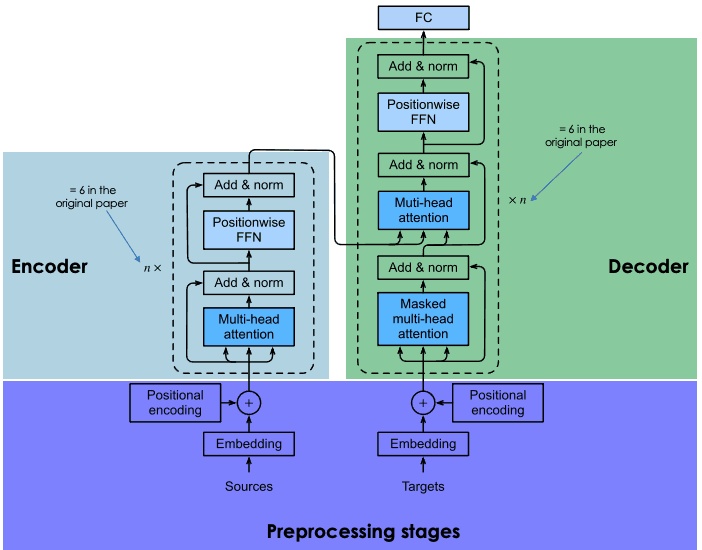
Architecture générale des transformateurs (adapté par l'auteur)
Cette section comporte deux étapes principales : (1) la génération de l'intégration de la phrase d'entrée, et (2) le calcul du vecteur de position de chaque mot dans la phrase d'entrée. Tous les calculs sont effectués de la même manière pour la phrase source (avant le bloc encodeur) et la phrase cible (avant le bloc décodeur).
Avant de générer les intégrations des données d'entrée, nous commençons par effectuer la tokenisation, puis nous créons l'intégration de chaque mot individuel sans prêter attention à leur relation dans la phrase.
La tâche de tokénisation élimine toute notion de relations existant dans la phrase d'entrée. Le codage positionnel tente de créer la nature cyclique originale en générant un vecteur de contexte pour chaque mot.
À la fin de l'étape précédente, nous obtenons pour chaque mot deux vecteurs : (1) l'intégration et (2) son vecteur de contexte. Ces vecteurs sont additionnés pour créer un seul vecteur pour chaque mot, qui est ensuite transmis au codeur.
Comme indiqué précédemment, nous avons perdu toute notion de relation. L'objectif de la couche d'attention est de capturer les relations contextuelles existant entre les différents mots de la phrase d'entrée. Cette étape permet de générer un vecteur d'attention pour chaque mot.
À ce stade, un réseau neuronal de type feed-forward est appliqué à chaque vecteur d'attention pour le transformer dans un format attendu par la couche d'attention multi-têtes suivante dans le décodeur.
Le bloc décodeur se compose de trois couches principales : l'attention multi-têtes masquée, l'attention multi-têtes et un réseau d'anticipation en fonction de la position. Nous comprenons déjà les deux dernières couches, qui sont les mêmes dans le codeur.
Le décodeur entre en jeu lors de la formation du réseau et reçoit deux entrées principales : (1) les vecteurs d'attention de la phrase d'entrée que nous voulons traduire et (2) les phrases cibles traduites en anglais.
Lors de la génération du mot anglais suivant, le réseau est autorisé à utiliser tous les mots du mot français. Cependant, lorsqu'il s'agit d'un mot donné dans la séquence cible (traduction anglaise), le réseau ne doit accéder qu'aux mots précédents, car si les mots suivants sont disponibles, le réseau "trichera" et ne fera pas l'effort d'apprendre correctement. C'est ici que la couche d'attention masquée à plusieurs têtes présente tous ses avantages. Il masque les mots suivants en les transformant en zéros afin qu'ils ne puissent pas être utilisés par le réseau d'attention.
Le résultat de la couche d'attention multi-têtes masquée passe par les autres couches afin de prédire le mot suivant en générant un score de probabilité.
Cette architecture a été couronnée de succès pour les raisons suivantes :
La formation de réseaux neuronaux profonds tels que les transformateurs à partir de zéro n'est pas une tâche facile et peut présenter les défis suivants :
L'utilisation de l'apprentissage par transfert peut présenter de nombreux avantages, tels que la réduction du temps de formation, l'accélération du processus de formation de nouveaux modèles et la réduction du délai de livraison du projet.
Imaginez que vous construisiez un modèle à partir de zéro pour traduire la langue mandingue en wolof, qui sont toutes deux des langues à faibles ressources. La collecte de données relatives à ces langues est coûteuse. Au lieu de relever tous ces défis, il est possible de réutiliser des réseaux neuronaux profonds pré-entraînés comme point de départ pour l'entraînement du nouveau modèle.
Ces modèles ont été entraînés sur un énorme corpus de données, mis à disposition par quelqu'un d'autre (personne morale, organisation, etc.), et évalués comme fonctionnant très bien pour des tâches de traduction de langues telles que le français vers l'anglais.
Si vous êtes nouveau dans le NLP, ce cours d'introduction au traitement du langage naturel en Python peut vous fournir les compétences fondamentales pour effectuer et résoudre des problèmes du monde réel.
Mais qu'entendez-vous par réutilisation des réseaux neuronaux profonds ?
La réutilisation du modèle implique de choisir le modèle pré-entraîné qui est similaire à votre cas d'utilisation, d'affiner les données de la paire entrée-sortie de votre tâche cible et de réentraîner la tête du modèle pré-entraîné en utilisant vos données.
L'introduction des transformateurs a conduit à l'élaboration de modèles d'apprentissage par transfert à la pointe de la technologie, tels que :
Hugging Face est une communauté d'IA et une plateforme de Machine Learning créée en 2016 par Julien Chaumond, Clément Delangue, et Thomas Wolf. Il vise à démocratiser le NLP en fournissant aux Data Scientists, aux praticiens de l'IA et aux ingénieurs un accès immédiat à plus de 20 000 modèles pré-entraînés basés sur l'architecture de transformateurs de pointe. Ces modèles peuvent être appliqués à :
Hugging Face Transformers fournit également près de 2000 ensembles de données et des API en couches, permettant aux programmeurs d'interagir facilement avec ces modèles à l'aide de près de 31 bibliothèques. La plupart d'entre eux sont des outils d'apprentissage profond, tels que Pytorch, Tensorflow, Jax, ONNX, Fastai, Stable-Baseline 3, etc.
Ces cours sont une excellente introduction à l'utilisation de Pytorch et Tensorflow pour construire respectivement des réseaux neuronaux convolutionnels profonds. Les pipelines sont d'autres éléments des transformateurs Hugging Face.
La méthode pipeline() a la structure suivante :
from transformers import pipeline
# To use a default model & tokenizer for a given task(e.g. question-answering)
pipeline("<task-name>")
# To use an existing model
pipeline("<task-name>", model="<model_name>")
# To use a custom model/tokenizer
pipeline('<task-name>', model='<model name>',tokenizer='<tokenizer_name>')Maintenant que vous avez une meilleure compréhension de Transformers, et de la plateforme Hugging Face, nous allons vous guider à travers les scénarios du monde réel suivants : traduction linguistique, classification de séquences avec classification zéro-shot, analyse de sentiments, et réponse à des questions.
Ce jeu de données est disponible sur DataCamp est enrichi par Facebook et a été créé pour prédire la popularité d'un article avant sa publication. L'analyse sera basée sur la colonne de description. Pour illustrer nos exemples, nous n'utiliserons que trois exemples tirés des données.
Vous trouverez ci-dessous une brève description des données. Il comporte 14 colonnes et 1428 lignes.
import pandas as pd
# Load the data from the path
data_path = "datacamp_workspace_export_2022-08-08 07_56_40.csv"
news_data = pd.read_csv(data_path, error_bad_lines=False)
# Show data information
news_data.info()
MariamMT est un cadre efficace de traduction automatique. Il utilise le moteur MarianNMT sous le capot, qui est purement développé en C++ par Microsoft et de nombreuses institutions académiques telles que l'Université d'Edimbourg et l'Université Adam Mickiewicz de Poznań. Le même moteur est actuellement à l'origine du service Microsoft Translator.
Le groupe NLP de l'université d'Helsinki a mis en libre accès plusieurs modèles de traduction sur Hugging Face Transformers, qui se présentent tous sous le format suivant Helsinki-NLP/opus-mt-{src}-{tgt}, où {src} et {tgt} correspondent respectivement à la langue source et à la langue cible.
Ainsi, dans notre cas, la langue source est l'anglais (en) et la langue cible est le français (fr).
MarianMT est l'un de ces modèles précédemment entraînés à l'aide de Marian sur des données parallèles collectées à Opus.
pip install transformers sentencepiece
from transformers import MarianTokenizer, MarianMTModel# Get the name of the model
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Get the tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Instantiate the model
model = MarianMTModel.from_pretrained(model_name)def format_batch_texts(language_code, batch_texts):
formated_bach = [">>{}<< {}".format(language_code, text) for text in
batch_texts]
return formated_bachdef perform_translation(batch_texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts,
return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts# Check the model translation from the original language (English) to French
translated_texts = perform_translation(english_texts, trans_model, trans_model_tkn)
# Create wrapper to properly format the text
from textwrap import TextWrapper
# Wrap text to 80 characters.
wrapper = TextWrapper(width=80)
for text in translated_texts:
print("Original text: \n", text)
print("Translation : \n", text)
print(print(wrapper.fill(text)))
print("")
La plupart du temps, la formation d'un modèle d'apprentissage automatique exige que toutes les étiquettes/cibles candidates soient connues à l'avance, ce qui signifie que si vos étiquettes de formation sont la science, la politique ou l'éducation, vous ne serez pas en mesure de prédire l'étiquette de soins de santé à moins que vous ne reformiez votre modèle en tenant compte de cette étiquette et des données d'entrée correspondantes.
Cette approche puissante permet de prédire la cible d'un texte dans une quinzaine de langues sans avoir vu aucune des étiquettes candidates. Nous pouvons utiliser ce modèle en le chargeant simplement depuis le hub.
L'objectif est ici d'essayer de classer la catégorie de chacune des descriptions précédentes, qu'il s'agisse de technologie, de politique, de sécurité ou de finance.
from transformers import pipelinecandidate_labels = ["tech", "politics", "business", "finance"]my_classifier = pipeline("zero-shot-classification",
model='joeddav/xlm-roberta-large-xnli')#For the first description
prediction = my_classifier(english_texts[0], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)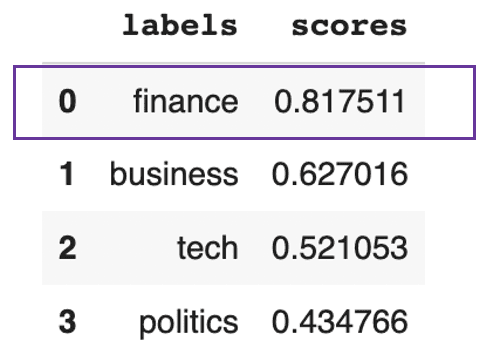
Le texte devrait porter principalement sur la finance
Le résultat précédent montre que le texte porte globalement sur la finance à 81%.
Pour la dernière description, nous obtenons le résultat suivant :
#For the last description
prediction = my_classifier(english_texts[-1], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)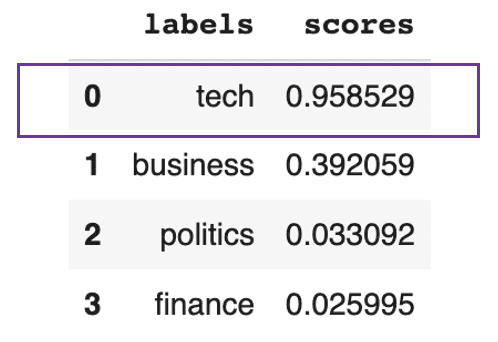
Le texte devrait être principalement axé sur la technologie
Le résultat précédent montre que le texte est globalement à peu près technique à 95%.
La plupart des modèles de classification des sentiments nécessitent une formation adéquate. Le module de pipeline Hugging Face permet d'exécuter facilement des prédictions d'analyse de sentiments en utilisant un modèle spécifique disponible sur le hub en spécifiant son nom.
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)# Run the predictions
distil_bert_model(english_texts[1:])
Le modèle a prédit un sentiment négatif pour le premier texte avec un taux de confiance de 96 %, et un sentiment positif pour le second avec un taux de confiance de 52 %.
Si vous voulez explorer plus sur les tâches d'analyse de sentiment, ce cours d'analyse de sentiment Python vous aidera à obtenir les compétences pour construire votre propre classificateur d'analyse de sentiment à l'aide de Python et comprendre les bases du NLP.
Imaginez que vous ayez à traiter un rapport beaucoup plus long que celui concernant Apple. Et tout ce qui vous intéresse, c'est la date de l'événement mentionné. Au lieu de lire tout le rapport pour trouver l'information clé, nous pouvons utiliser un modèle de question-réponse de Hugging Face qui fournira la réponse qui nous intéresse.
Pour ce faire, il convient de fournir au modèle le contexte approprié (le rapport d'Apple) et la question à laquelle nous souhaitons répondre.
from transformers import AutoModelForQuestionAnswering, AutoTokenizermodel_checkpoint = "deepset/roberta-base-squad2"
task = 'question-answering'
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)QA_input = {
'question': 'when is Apple hosting an event?',
'context': english_texts[-1]
}model_response = QA_model(QA_input)
pd.DataFrame([model_response])
Le modèle a répondu que l'événement Apple aura lieu le 10 septembre avec un niveau de confiance élevé de 97 %.
Dans cet article, nous avons abordé l'évolution de la technologie du langage naturel, des réseaux récurrents aux transformateurs, et la façon dont Hugging Face a démocratisé l'utilisation du NLP grâce à sa plateforme.
Si vous hésitez encore à utiliser des transformateurs, nous pensons qu'il est temps de les essayer et d'ajouter de la valeur à vos cas d'entreprise.
Cours pour Python
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach