
Kursus
Machine Learning dengan PySpark
4 Hr
29.8K
Pernah mencoba men-debug job Spark yang tiba-tiba gagal dan merasa benar-benar tersesat karena betapa dalamnya “lubang kelinci” Spark?
Saat pertama kali bekerja dengan Apache Spark, saya pikir saya hanya perlu menulis beberapa transformasi PySpark dan Spark akan “secara ajaib” melakukan skala ke seluruh klaster. Saya keliru. Kinerja Spark sepenuhnya bergantung pada pemahaman apa yang terjadi di balik layar.
Panduan ini untuk siapa pun yang tidak ingin memperlakukan Spark seperti kotak hitam. Kita akan menelusuri bagaimana arsitektur Spark dirancang, mulai dari model master–worker dan alur eksekusi, hingga manajemen memori serta mekanisme toleransi kesalahannya.
Jika Anda ingin membangun aplikasi big data yang cepat, tangguh terhadap kegagalan, dan efisien, Anda berada di tempat yang tepat!
Sebelum Anda menulis baris pertama PySpark, Spark sudah membuat beberapa keputusan arsitektural untuk Anda. Spark tidak hanya cepat karena komputasi in-memory, tetapi juga karena dibangun di atas arsitektur master–worker yang dapat melakukan skala dan bertahan menghadapi kekacauan dunia nyata seperti kerusakan node, crashes, Java Virtual Machine (JVM) issues, dan volume data yang tidak konsisten.
Mari kita uraikan arsitektur inti Spark dan mengapa ia masih begitu kuat dan hadir dalam alur kerja big data modern.
Inti Spark adalah model master–worker. Bayangkan seperti ini:
main() Anda, membuat Spark context, menangani penjadwalan DAG, dan memberi tahu klaster apa yang harus dilakukan.Susunan ini memungkinkan Anda fokus mendefinisikan transformasi, dan Spark yang memutuskan di mana serta bagaimana menjalankannya secara paralel pada executor.
Yang saya sukai dari desain ini adalah sifatnya yang agnostik terhadap deployment. Kode yang sama berjalan apa pun target deployment-nya—di mesin lokal Anda, di Kubernetes, atau Mesos. Ini memudahkan pengembangan dan pengujian lokal, lalu melakukan skala ke klaster tanpa menulis ulang kode.
Dan inilah manfaat kuat lain dari pemisahan driver–worker Spark: Ia meningkatkan isolasi kesalahan. Jika sebuah node worker mati saat mengeksekusi tugas, Spark dapat menetapkan ulang tugas itu ke worker lain tanpa membuat aplikasi Anda crash.
Mari kita uraikan apa yang terjadi di dalam driver dan node.
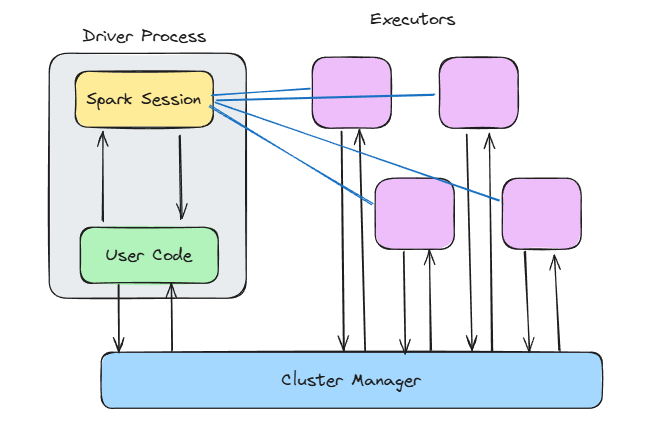
Arsitektur Spark. Gambar oleh penulis.
Saat Anda memanggil SparkContext() atau menggunakan SparkSession.builder.getOrCreate(), Anda membuka gerbang ke seluruh “sihir” internal Spark.
Spark context:
Spark membangun Directed Acyclic Graph (DAG) transformasi di balik layar. DAG itu dipecah menjadi stage dan task, lalu dieksekusi secara paralel.
DAG scheduler menentukan tugas mana yang bisa dijalankan bersamaan, dan Task scheduler menugaskannya ke executor. Sementara itu, Block manager memastikan data di-cache, di-shuffle, atau dimuat ulang sesuai kebutuhan.
Desain berlapis ini membuat Spark sangat fleksibel, karena Anda bisa menyetel memori, penyimpanan, dan komputasi secara independen.
Jika Anda bekerja dengan transformasi Spark atau rekayasa fitur, lihat kursus Feature Engineering with PySpark untuk melihat arsitektur ini beraksi.
Executor adalah tempat pekerjaan dilakukan.
Setiap executor menjalankan:
Anda dapat mengonfigurasi berapa banyak memori yang didapat tiap executor, berapa banyak core yang digunakan, dan apakah harus menulis ke disk saat memori habis.
Namun, hati-hati: Jika Anda tidak mengalokasikan memori yang cukup, Anda akan sering terkena error kehabisan memori. Di sisi lain, mengalokasikan terlalu banyak memori juga membuang sumber daya. Pemantauan dan penyetelan sangat penting di sini.
Menulis kode PySpark terasa cukup sederhana. Anda memfilter DataFrame, melakukan join, mengagregasi sesuatu, lalu menjalankannya. Namun di balik API yang rapi itu, Spark diam-diam memutar mesin eksekusi yang dapat menyebarkan pekerjaan ke beberapa node.
Mari kita telusuri apa yang terjadi di balik layar.
Inilah yang kebanyakan pengguna Spark tidak sadari pada awalnya: Saat Anda menulis kode PySpark, Anda tidak langsung menjalankan apa pun. Anda sedang membangun sebuah rencana, dan Catalyst Optimizer milik Spark mengambil rencana itu dan mengubahnya menjadi strategi eksekusi yang efisien.
Prosesnya berlangsung dalam empat tahap:
Catalyst Optimizer Spark. Gambar oleh Databricks.
Jadi rangkaian .select(), .join(), dan .groupBy() itu tidak hanya berjalan baris demi baris. Ia dianalisis, dioptimalkan, dan dikompilasi menjadi sesuatu yang berjalan cepat di klaster.
Lihat PySpark Cheat Sheet ini jika Anda menginginkan ringkasan perintah PySpark paling berguna.
Saat rencana selesai, DAG scheduler mengambil alih.
Ia memecah job menjadi beberapa stage berdasarkan batas shuffle, di mana Spark memutuskan apa yang terjadi secara berurutan dan apa yang bisa dieksekusi paralel.
Ada dua tipe stage utama:
groupBy() atau join(). Data kemudian dipartisi dan dikirim melalui jaringan. Tipe stage ini diperlukan untuk menghitung ResultStage.Satu hal penting yang saya pelajari adalah meminimalkan shuffle. Shuffle harus terjadi sebelum sebuah stage selesai dan mahal biayanya. Anda perlu memahami di mana shuffle terjadi dalam DAG Anda dan apakah Anda bisa mengoptimalkan kode lebih lanjut untuk mengurangi jumlah shuffle.
Setelah DAG scheduler membuat semua stage, tahap-tahap tersebut dapat dieksekusi pada berbagai executor.
Siklus hidup eksekusi task kira-kira seperti ini:
Sedikit petunjuk dari pengalaman saya sendiri: jika job Spark Anda menggantung setelah sebelumnya berjalan baik, sering kali penyebabnya adalah garbage collection atau keterlambatan fetch shuffle. Selalu periksa kode Anda dan pastikan Anda memahami arsitektur Spark agar dapat mengoptimalkan topik-topik ini secara efektif.
Manajemen memori Spark adalah topik yang sangat kompleks dan dapat menghabiskan berjam-jam debugging jika Anda tidak memahaminya.
Mari kita lihat bagaimana Spark mengelola memori di balik layar agar Anda menyadarinya dan dapat menghindari berjam-jam debugging kode lambat atau error kehabisan memori.
Sebelum Spark 1.6, memori dibagi ketat antara eksekusi (untuk shuffle dan join) dan penyimpanan (untuk caching). Itu berubah dengan Spark 1.6, yang memperkenalkan model memori terpadu.
Dalam model memori terpadu, data dibagi menjadi tiga pool utama:
Pool memori Spark selanjutnya dibagi menjadi dua pool:
Elastisitas ini memungkinkan Spark menjadi lebih fleksibel menghadapi volume data yang tidak dapat diprediksi.
Namun, ini juga berarti sedikit kehilangan kontrol ketika Anda tidak tahu apa yang terjadi. Misalnya, jika Anda melakukan cache() pada DataFrame besar tetapi juga memiliki agregasi mahal dalam stage yang sama, Spark mungkin mengusir data yang di-cache untuk memberi ruang bagi shuffle.
Dalam penyimpanan off-heap dan kolumnar Spark, mesin Tungsten berperan.
Tungsten memperkenalkan beberapa optimasi yang meningkatkan kinerja Spark:
Dan jika Anda bekerja dengan DataFrame, Anda sudah menggunakan optimasi ini di balik layar. Itulah salah satu alasan saya mendorong orang menggunakan DataFrame dan API SQL alih-alih RDD mentah. Anda mendapatkan seluruh kekuatan Catalyst dan Tungsten tanpa penyetelan tambahan.
Jika Anda mengerjakan pipeline pembersihan data, Anda akan melihat ini beraksi di Cleaning Data with PySpark.
Jika Anda bekerja dengan sistem terdistribusi, ada satu hal yang pasti: sistem itu bisa gagal. Node crash. Error jaringan terjadi. Executor kehabisan memori dan mati.
Namun Spark dibangun untuk menangani masalah-masalah ini dan memastikan job Anda tetap berhasil.
Mari kita telusuri lebih dalam bagaimana Spark memastikan job Anda tetap berhasil, bahkan jika terjadi ketidakstabilan.
Resilient Distributed Datasets (RDD) adalah struktur data fundamental di Spark. Dan mereka disebut “resilient” bukan tanpa alasan.
Spark menggunakan lineage untuk memastikan setiap RDD dapat dihitung ulang jika terjadi kegagalan node dan kehilangan data.
Jadi ketika sebuah node gagal, Spark cukup menghitung ulang data yang hilang menggunakan graf lineage.
Begini cara kerjanya dalam praktik:
map() atau filter()): Spark hanya perlu partisi yang hilang untuk menghitung ulang.groupBy() atau join()): Spark mungkin perlu mengambil data dari beberapa partisi, karena bisa memerlukan output dari beberapa stage.Lineage menghindarkan Anda dari perlu menangani kegagalan secara manual. Namun, jika graf lineage Anda menjadi terlalu panjang—misalnya mengandung ratusan transformasi—menghitung ulang data yang hilang menjadi mahal. Di sinilah checkpointing berperan.
Saat Anda menghadapi alur kerja kompleks atau job streaming, Spark tidak bisa hanya bergantung pada lineage. Di situlah checkpointing berperan.
Anda dapat memanggil rdd.checkpoint() untuk menyimpan status RDD saat ini ke lokasi penyimpanan andal (seperti HDFS).
Spark lalu memangkas lineage. Jika terjadi error, Spark memuat ulang data secara langsung alih-alih menghitung ulang.
Dalam structured streaming, Spark juga menggunakan write-ahead log (WAL) untuk memastikan data tidak hilang saat transit.
Inilah yang membuatnya stabil:
Checkpointing bersifat opsional untuk job batch, tetapi wajib untuk pipeline streaming.
Bayangkan Anda memiliki job Spark yang gagal setelah berjalan 10 jam, tetapi Anda dapat melanjutkan dari titik terakhir berkat checkpointing dan WAL.
Sampai di sini, Anda telah melihat bagaimana Spark memproses job serta menangani memori dan kegagalan.
Di bagian ini, kita menyelami beberapa peningkatan arsitektural tingkat lanjut yang membuat Spark lebih dinamis, lebih real-time, dan lebih adaptif.
AQE diperkenalkan di Spark 3.0 dan meningkatkan kinerja kueri dengan menyesuaikan rencana eksekusi secara dinamis saat runtime berdasarkan statistik yang dikumpulkan selama eksekusi.
Fitur AQE meliputi:
Fitur ini mengubah permainan, karena memungkinkan job yang sebelumnya memerlukan penyetelan manual dan coba-coba untuk beradaptasi secara real-time.
Pastikan untuk mengaktifkannya secara eksplisit melalui konfigurasi (spark.sql.adaptive.enabled = true). Dan jika Anda menjalankan Spark 3.0+, tidak ada alasan untuk tidak mengaktifkannya.
Structured Streaming membawa mesin Spark ke ranah real-time, tanpa mengharuskan Anda mempelajari API yang benar-benar baru.
Di balik layar, Spark tetap menerapkan micro-batching. Namun Spark menangani:
Yang kuat di sini adalah bagaimana streaming terasa seperti batch. Anda menulis groupBy() atau filter() dan Spark menangani sisanya, membuat analitik streaming dapat diakses tanpa rantai alat khusus.
Jika Anda menjalankan Spark di produksi, terutama di keuangan, layanan kesehatan, atau area bisnis serupa, Anda perlu tahu bagaimana Spark menangani autentikasi, enkripsi, dan auditabilitas.
Mari kita selami topik-topik ini dan bagaimana Spark menanganinya.
Spark memiliki banyak fitur keamanan yang harus Anda aktifkan terlebih dahulu. Namun setelah diaktifkan, Spark menawarkan perangkat yang solid untuk komunikasi aman dan autentikasi:
spark.acls.enable=true serta spark.ui.view.acls dan spark.ui.view.acls.groups untuk membatasinya.Anda dapat memeriksa semua fitur keamanan di dokumentasi resmi Spark. Tinjau dan pastikan Anda mengaktifkan fitur yang diperlukan untuk mengamankan aplikasi Spark Anda.
Mencatat siapa melakukan apa dan kapan juga sangat penting.
Spark mendukung:
spark.eventLog.enabled=true), Spark mencatat setiap event job, stage, dan task ke disk. Anda dapat menggunakan log ini untuk memutar ulang riwayat job atau memenuhi persyaratan audit.Spark sangat kuat dan cepat, dan dapat dioptimalkan agar lebih cepat lagi jika Anda tahu di mana harus melakukan penyesuaian.
Ada beberapa area tempat Anda bisa mencoba mengoptimalkan untuk memaksimalkan Spark. Mari kita dalami tiap area.
Jika Spark memiliki titik lemah, itu adalah shuffle. Shuffle terjadi saat data perlu dipindahkan antar partisi, biasanya setelah transformasi lebar seperti groupByKey(), distinct(), atau join().
Dan ketika shuffle bermasalah, Anda bisa mengalami I/O disk yang sangat besar, jeda garbage collection yang panjang, atau task skewed yang tak kunjung selesai.
Berikut cara meningkatkan shuffle:
reduceByKey() daripada groupByKey(): reduceByKey() mengagregasi secara lokal sebelum shuffle. groupByKey() mengirim semuanya melalui jaringan..repartition(n) untuk meningkatkan paralelisme, atau .coalesce(n) untuk menguranginya. Jangan biarkan Spark memakai partisi default begitu saja.spark.sql.autoBroadcastJoinThreshold untuk mengendalikan batas ukurannya.collect(): Hindari jika memungkinkan, karena menarik data ke driver akan menghancurkan kinerja.Menyetel memori Spark bisa terasa seperti sains tersendiri, tetapi Anda bisa menggunakan daftar periksa di bawah ini untuk memudahkan:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Menyesuaikan konfigurasi memori bisa sangat membantu. Saya pernah memangkas job 30 menit menjadi 8 menit hanya dengan menyesuaikan konfigurasi memori, tanpa mengubah satu baris kode pun.
Ini adalah bagian yang paling sering keliru, karena banyak tim menebak ukuran klaster alih-alih memperkirakannya dengan benar.
Namun Anda bisa berbuat lebih baik dengan menggunakan rumus di bawah ini:
Contoh:
Namun ingat: Ini hanya perkiraan. Gunakan sebagai titik awal lalu optimalkan lebih lanjut melalui profiling.
Spark telah ada selama satu dekade, tetapi tetap sangat relevan. Spark berkembang lebih cepat dari sebelumnya, berkat platform cloud-native, akselerasi GPU, dan integrasi ML yang lebih erat.
Jika Anda menggunakan Spark hari ini dengan cara yang sama seperti tiga tahun lalu, kemungkinan Anda menyisakan performa dan melewatkan fitur-fitur baru yang hebat.
Mari kita lihat beberapa yang terbaru.
Jika Anda bekerja dengan Databricks, Anda mungkin sudah pernah bekerja dengan dan mendengar tentang Photon.
Jika Anda ingin mempelajari lebih lanjut tentang Databricks, saya merekomendasikan kursus Introduction to Databricks.
Photon adalah mesin generasi berikutnya di platform Databricks Lakehouse yang memberikan kinerja kueri cepat dengan biaya rendah. Photon kompatibel dengan API Spark, sehingga Anda tidak perlu menyesuaikan kode Spark untuk memanfaatkannya.
Photon membantu meningkatkan secara signifikan kode SQL dan PySpark Anda.
Photon mencakup fitur-fitur berikut:
Serverless itu fantastis, karena berarti Anda tidak perlu mengelola klaster, melakukan pra-penyediaan sumber daya, dan Anda hanya membayar saat Spark berjalan.
Dan serverless untuk Spark sudah tersedia di layanan seperti Databricks Serverless, AWS Glue, dan GCP Dataproc Serverless.
Inilah alasannya begitu luar biasa:
Serverless Spark ideal untuk analitik interaktif, job ad-hoc, atau beban kerja yang tidak dapat diprediksi.
Namun hati-hati: pipeline jangka panjang yang konsisten mungkin tetap lebih murah di klaster tetap. Selalu ukur baik biaya maupun latensi.
Saat industri berubah, batas antara rekayasa data dan AI semakin kabur. Seperti yang dibahas Deepak Goyal, CEO & Founder di Azurelib Academy, di podcast DataFramed
Rekayasa data akan memainkan peran penting dan fundamental dalam pergeseran menuju AI yang akan datang.
Deepak Goyal, CEO & Founder at Azurelib Academy
Pelajari lebih lanjut tentang Spark dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
