
Cursus
Machine Learning met PySpark
4 Hr
29.8K
Heb je ooit geprobeerd een Spark-job te debuggen die ineens faalde, om er vervolgens achter te komen dat je compleet verdwaald raakte in het konijnenhol dat Spark heet?
Toen ik voor het eerst met Apache Spark werkte, dacht ik dat ik alleen een paar PySpark-transformaties hoefde te schrijven en dat Spark vervolgens “magisch” zou schalen over het cluster. Ik had het mis. De performance van Spark hangt volledig af van je begrip van wat er achter de schermen gebeurt.
Deze gids is voor iedereen die Spark niet als een black box wil behandelen. We lopen door hoe de architectuur van Spark is ontworpen, van het master-worker-model en de uitvoeringsworkflow tot aan het geheugenbeheer en de fouttolerantiemechanismen.
Als je snelle, fouttolerante en efficiënte bigdata-applicaties wilt bouwen, ben je hier aan het juiste adres!
Nog voordat je je eerste regel PySpark schrijft, heeft Spark al een paar architecturale keuzes voor je gemaakt. Spark is niet alleen snel dankzij in-memory computing, maar ook omdat het is gebouwd op een master-worker-architectuur die schaalt en bestand is tegen echte chaos, zoals node-crashes, Java Virtual Machine (JVM)-problemen en inconsistente datavolumes.
Laten we de kernarchitectuur van Spark ontleden en bekijken waarom die nog steeds zo krachtig is en een vaste waarde in moderne bigdata-workflows.
In de kern van Spark staat het master-worker model. Denk er zo over:
main()-functie uit, maakt de Spark-context, handelt de DAG-scheduling af en vertelt het cluster wat het moet doen.Met deze opzet kun jij je focussen op het definiëren van transformaties, en Spark beslist waar en hoe die parallel op de executors worden uitgevoerd.
Wat ik fijn vind aan dit ontwerp is dat het deployment-agnostisch is. Dezelfde code draait, of je nu lokaal, op Kubernetes of op Mesos uitrolt. Dat maakt lokaal ontwikkelen en testen makkelijk, waarna je kunt opschalen naar clusters zonder je code te herschrijven.
En hier is nog een krachtig voordeel van de scheiding tussen driver en worker: het verbetert foutisolatie. Als een workernode uitvalt tijdens een taak, kan Spark die taak aan een andere worker toewijzen zonder dat je applicatie crasht.
Laten we uitpluizen wat er binnen de driver en de nodes gebeurt.
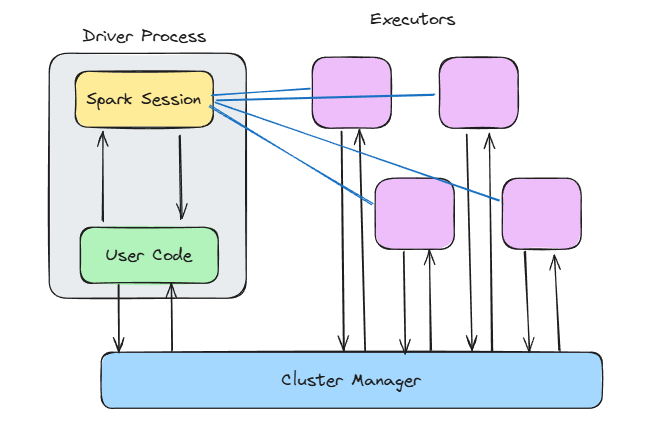
Spark-architectuur. Afbeelding door de auteur.
Wanneer je SparkContext() aanroept of SparkSession.builder.getOrCreate() gebruikt, open je de toegangspoort tot alle interne magie van Spark.
De Spark-context:
Spark bouwt achter de schermen een Directed Acyclic Graph (DAG) van transformaties. Die DAG wordt opgesplitst in stages en taken en vervolgens parallel uitgevoerd.
De DAG-scheduler bepaalt welke taken samen kunnen draaien, en de Task-scheduler wijst ze toe aan executors. Ondertussen zorgt de Block manager ervoor dat data naar behoefte wordt gecachet, geshuffled of opnieuw geladen.
Dit gelaagde ontwerp maakt Spark enorm flexibel, omdat je geheugen, opslag en compute onafhankelijk kunt afstellen.
Werk je met Spark-transformaties of feature engineering, bekijk dan Feature Engineering with PySpark om deze architectuur in actie te zien.
Executors zijn waar het werk gebeurt.
Elke executor draait:
Je kunt configureren hoeveel geheugen elke executor krijgt, hoeveel cores hij gebruikt en of hij naar schijf moet schrijven wanneer het geheugen opraakt.
Maar wees voorzichtig: als je niet genoeg geheugen toewijst, krijg je voortdurend out-of-memory-fouten. Tegelijk moet je ook niet te veel geheugen toewijzen, want dat verspilt resources. Monitoren en tunen zijn hier essentieel.
PySpark-code schrijven voelt vrij eenvoudig. Je filtert een DataFrame, doet een join, aggregeert iets en drukt op run. Maar achter die cleane API start Spark stilletjes een execution engine op die werk over meerdere nodes kan verdelen.
Laten we doorlopen wat er achter de schermen gebeurt.
Dit beseffen de meeste Spark-gebruikers in het begin niet: wanneer je PySpark-code schrijft, draait er niet meteen iets. Je bouwt een plan, en de Catalyst Optimizer van Spark neemt dat plan en zet het om in een efficiënt uitvoeringsplan.
Dat werkt in vier fasen:
Spark’s Catalyst Optimizer. Afbeelding door Databricks.
Die keten van .select(), .join() en .groupBy() draait dus niet simpelweg regel voor regel. Hij wordt geanalyseerd, geoptimaliseerd en gecompileerd tot iets dat snel op een cluster draait.
Bekijk deze PySpark-cheatsheet als je een spiekbrief nodig hebt voor de meest gebruikte PySpark-commando’s.
Wanneer het plan klaar is, neemt de DAG-scheduler het over.
Die breekt de job op in stages op basis van shuffle-grenzen, waarbij Spark bepaalt wat sequentieel moet gebeuren en wat parallel kan worden uitgevoerd.
Er zijn twee hoofdtypen stages:
groupBy() of join(). De data wordt dan gepartitioneerd en over het netwerk verzonden. Dit stagetype is nodig om de ResultStage te berekenen.Eén belangrijk inzicht dat ik heb geleerd: minimaliseer shuffles. Een shuffle moet plaatsvinden voordat een stage eindigt en is duur. Je moet begrijpen waar ze in je DAG voorkomen en of je je code verder kunt optimaliseren om het aantal shuffles te verminderen.
Zodra de DAG-scheduler alle stages heeft aangemaakt, kunnen ze op de verschillende executors worden uitgevoerd.
De levenscyclus van taakuitvoering ziet er ongeveer zo uit:
Een kleine tip uit eigen ervaring: als je Spark-job blijft hangen nadat hij eerder prima draaide, komt dat vaak door garbage collection of shuffle-fetchvertragingen. Controleer altijd je code en zorg dat je de architectuur van Spark begrijpt, zodat je deze onderwerpen effectief kunt optimaliseren.
Het geheugenbeheer van Spark is een zeer complex onderwerp en kan je uren debuggen kosten als je het niet begrijpt.
Laten we daarom bekijken hoe Spark onder de motorkap met geheugen omgaat, zodat je hiervan op de hoogte bent en uren debuggen van trage code of out-of-memory-fouten kunt voorkomen.
Vóór Spark 1.6 was het geheugen strikt verdeeld tussen execution (voor shuffles en joins) en storage (voor caching). Dat veranderde met Spark 1.6, met de introductie van het unified memory model.
In het unified memory model wordt geheugen verdeeld over drie kernpools:
De Spark-geheugenpool is verder opgesplitst in twee pools:
Deze elasticiteit maakt Spark flexibeler bij onvoorspelbare datavolumes.
Maar dit betekent ook dat je wat controle verliest als je niet weet wat er gebeurt. Als je bijvoorbeeld een groot DataFrame cache()t maar in dezelfde stage ook dure aggregaties hebt, kan Spark je gecachete data verdringen om ruimte te maken voor de shuffle.
Bij Spark’s off-heap- en kolomgebaseerde opslag komt de Tungsten-engine om de hoek kijken.
Tungsten introduceerde verschillende optimalisaties die de performance van Spark verbeterden:
En als je met DataFrames werkt, profiteer je hier onder de motorkap al van. Dat is een van de redenen waarom ik mensen aanraad DataFrames en SQL-API’s te gebruiken in plaats van ruwe RDD’s. Je krijgt de volledige kracht van Catalyst en Tungsten zonder extra tuning.
Als je met datacleaning-pijplijnen werkt, zie je dit in actie in Cleaning Data with PySpark.
Als je met gedistribueerde systemen werkt, weet je één ding zeker: ze vallen uit. Nodes crashen. Netwerkfouten gebeuren. Executors raken door geheugen heen en stoppen.
Maar Spark is gebouwd om deze problemen aan te kunnen en ervoor te zorgen dat je jobs toch slagen.
Laten we dieper ingaan op hoe Spark ervoor zorgt dat je jobs slagen, zelfs als er instabiliteiten optreden.
Resilient Distributed Datasets (RDD’s) zijn de fundamentele datastructuur in Spark. En ze heten niet voor niets resilient.
Spark gebruikt lineage om te garanderen dat elke RDD opnieuw kan worden berekend bij node-falen en dataverlies.
Dus wanneer een node faalt, herberekent Spark simpelweg de verloren data met behulp van de lineage-grafiek.
Zo werkt het in de praktijk:
map() of filter()): Spark heeft alleen de verloren partitie nodig om te herberekenen.groupBy() of join()): Spark moet mogelijk data uit meerdere partities ophalen, omdat de output van meerdere stages nodig kan zijn. Lineage voorkomt dat je fouten handmatig moet afhandelen. Als je lineage-grafiek echter te lang wordt, met honderden transformaties, wordt het herberekenen van verloren data duur. Dan komt checkpointing in beeld.
Bij complexe workflows of streaming-jobs kan Spark niet uitsluitend op lineage vertrouwen. Dan gebruik je checkpointing.
Je kunt rdd.checkpoint() aanroepen om de huidige RDD-state op te slaan op een betrouwbare opslaglocatie (zoals HDFS).
Spark kapt vervolgens de lineage af. Als er een fout optreedt, wordt de data direct herladen in plaats van herberekend.
In structured streaming gebruikt Spark ook write-ahead logs (WAL’s) om te zorgen dat data niet verloren gaat tijdens transport.
Dit maakt het zo stabiel:
Checkpointing is optioneel voor batch-jobs, maar vereist voor streaming-pijplijnen.
Stel dat je een Spark-job had die faalde na 10 uur draaien, maar je kunt dankzij checkpointing en WAL’s gewoon doorgaan waar je was gebleven.
Je hebt nu gezien hoe Spark jobs verwerkt en hoe het omgaat met geheugen en fouten.
In deze sectie duiken we in enkele geavanceerde architectuurupgrades die Spark dynamischer, meer realtime en beter aanpasbaar maken.
AQE is geïntroduceerd in Spark 3.0 en verbetert queryperformance door uitvoeringsplannen tijdens runtime dynamisch aan te passen op basis van statistieken die tijdens de uitvoering worden verzameld.
Features van AQE zijn onder meer:
Deze feature is een gamechanger, omdat jobs die eerder handmatige tuning en trial-and-error vereisten nu realtime kunnen aanpassen.
Zorg er wel voor dat je het expliciet inschakelt via de configuratie (spark.sql.adaptive.enabled = true). En als je op Spark 3.0+ draait, is er geen reden om het niet te gebruiken.
Structured Streaming neemt de engine van Spark en breidt die uit naar het realtime-domein, zonder dat je een compleet nieuwe API hoeft te leren.
Achter de schermen past het nog steeds micro-batching toe. Maar het handelt ook af:
Het krachtige hier is dat streaming aanvoelt als batchen. Je schrijft een groupBy() of een filter() en Spark regelt de rest, waardoor streaming-analytics toegankelijk wordt zonder gespecialiseerde toolchain.
Draai je Spark in productie, zeker in finance, healthcare of vergelijkbare sectoren, dan moet je weten hoe Spark authenticatie, encryptie en auditability afhandelt.
Dus laten we dieper in deze onderwerpen duiken en zien hoe Spark ze aanpakt.
Spark heeft veel securityfeatures die je eerst moet inschakelen. Maar eenmaal geactiveerd, biedt Spark een solide toolbox voor veilige communicatie en authenticatie:
spark.acls.enable=true en spark.ui.view.acls en spark.ui.view.acls.groups om dit te beperken.Je kunt alle securityfeatures nalezen in de officiële documentatie van Spark. Bekijk die en zorg dat je de features inschakelt die je Spark-applicaties moeten beveiligen.
Loggen wie wat en wanneer heeft gedaan, is ook cruciaal.
Spark ondersteunt:
spark.eventLog.enabled=true), registreert Spark elk job-, stage- en taktevent op schijf. Je kunt deze logs gebruiken om jobhistorie te reproduceren of aan auditvereisten te voldoen.Spark is behoorlijk krachtig en snel, en kan nog sneller worden geoptimaliseerd als je weet waar je de juiste aanpassingen doet.
Er zijn verschillende gebieden waarop je kunt optimaliseren om het maximale uit Spark te halen. Laten we elk gebied uitdiepen.
Als Spark een zwak punt heeft, is het de shuffle. Shuffles gebeuren wanneer data tussen partities moet worden verplaatst, meestal na brede transformaties zoals groupByKey(), distinct() of join().
En als shuffles misgaan, krijg je enorme schijf-I/O, lange garbage collection-pauzes of scheve taken die nooit afronden.
Zo verbeter je shuffles:
reduceByKey() boven groupByKey(): reduceByKey() aggregeert lokaal vóór de shuffle. groupByKey() stuurt alles over het netwerk..repartition(n) om de paralleliteit te verhogen, of .coalesce(n) om die te verlagen. Laat het niet aan de standaardpartitionering van Spark over.spark.sql.autoBroadcastJoinThreshold in om de groottegrens te bepalen.collect(): Vermijd dit waar mogelijk, want data naar de driver trekken sloopt de performance.Het tunen van het geheugen van Spark is bijna een wetenschap, maar met de checklist hieronder wordt het makkelijker:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Het aanpassen van de geheugenconfiguratie kan enorm helpen. Ik heb ooit een job van 30 minuten teruggebracht naar 8 minuten door de geheugenconfiguratie aan te passen, zonder een enkele regel code te veranderen.
Dit is het onderdeel waar de meeste teams de fout in gaan, omdat ze de clusteromvang gokken in plaats van die correct te schatten.
Maar je kunt beter doen met de onderstaande formules:
Bijvoorbeeld:
Maar onthoud: dit is slechts een schatting. Gebruik het als startpunt en optimaliseer verder via profilering.
Spark bestaat al een decennium, maar is nog steeds actueel. Het evolueert sneller dan ooit dankzij cloud-native platforms, GPU-acceleratie en nauwere ML-integratie.
Als je Spark vandaag nog op dezelfde manier gebruikt als drie jaar geleden, laat je waarschijnlijk performance liggen en mis je mooie nieuwe features.
Laten we enkele van de nieuwste bekijken.
Als je met Databricks werkt, heb je waarschijnlijk al met Photon gewerkt en erover gehoord.
Wil je meer leren over Databricks, dan raad ik de cursus Introduction to Databricks aan.
Photon is de next-gen engine op het Databricks Lakehouse-platform die snelle queryperformance levert tegen lage kosten. Hij is compatibel met Spark-API’s, dus je hoeft je Spark-code niet aan te passen om ervan te profiteren.
Het helpt je SQL- en PySpark-code aanzienlijk te versnellen.
Photon bevat de volgende features:
Serverless is fantastisch, omdat je geen clusters hoeft te beheren, geen resources vooraf hoeft te provisionen en je alleen betaalt voor de tijd dat Spark draait.
En serverless voor Spark is al beschikbaar in diensten zoals Databricks Serverless, AWS Glue en GCP Dataproc Serverless.
En hierom is het geweldig:
Serverless Spark is ideaal voor interactieve analytics, ad-hocjobs of onvoorspelbare workloads.
Maar let op: langlopende, consistente pijplijnen kunnen nog steeds goedkoper zijn op vaste clusters. Meet altijd zowel kosten als latency.
Nu de industrie verschuift, vervaagt de lijn tussen data-engineering en AI. Zoals Deepak Goyal, CEO & Founder bij Azurelib Academy, besprak in de DataFramed-podcast
Data-engineering gaat een vitale en fundamentele rol spelen in de komende verschuiving naar AI.
Deepak Goyal, CEO & Founder at Azurelib Academy
Leer meer over Spark met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
