
Courses
Machine Learning với PySpark
4 giờ
29.8K
Bạn đã từng cố gắng debug một job Spark bỗng dưng thất bại rồi nhận ra mình hoàn toàn lạc lối vì “hang thỏ” Spark sâu đến mức nào chưa?
Khi tôi mới làm việc với Apache Spark, tôi nghĩ chỉ cần viết vài phép biến đổi PySpark là Spark sẽ “kỳ diệu” tự mở rộng trên cụm. Tôi đã nhầm. Hiệu năng của Spark phụ thuộc hoàn toàn vào việc hiểu rõ những gì diễn ra phía sau hậu trường.
Bài viết này dành cho bất kỳ ai không muốn coi Spark như một “hộp đen”. Chúng ta sẽ cùng tìm hiểu cách kiến trúc của Spark được thiết kế, từ mô hình master–worker và quy trình thực thi, đến quản lý bộ nhớ và cơ chế chịu lỗi.
Nếu bạn muốn xây dựng các ứng dụng dữ liệu lớn nhanh, chịu lỗi tốt và hiệu quả, bạn đang ở đúng nơi!
Trước khi bạn viết dòng PySpark đầu tiên, Spark đã đưa ra một số quyết định kiến trúc cho bạn. Spark không chỉ nhanh nhờ tính toán trong bộ nhớ, mà còn vì nó được xây dựng trên kiến trúc master–worker có khả năng mở rộng và “sống sót” trước hỗn loạn thực tế như node crashes, Java Virtual Machine (JVM) trục trặc và khối lượng dữ liệu thất thường.
Hãy phân tách kiến trúc cốt lõi của Spark và lý do tại sao nó vẫn mạnh mẽ, hiện diện trong các quy trình dữ liệu lớn hiện đại.
Cốt lõi của Spark là mô hình master–worker . Hãy hình dung như sau:
main() của bạn, tạo Spark context, xử lý lập lịch DAG và chỉ đạo cụm phải làm gì.Thiết lập này cho phép bạn tập trung vào việc định nghĩa các phép biến đổi, còn Spark quyết định chạy chúng ở đâu và như thế nào theo kiểu song song trên các executor.
Điều tôi thích ở thiết kế này là nó trung lập với môi trường triển khai. Cùng một đoạn mã chạy được, bất kể bạn triển khai trên máy cục bộ, trong Kubernetes hay Mesos. Nhờ vậy, bạn dễ phát triển và thử nghiệm cục bộ, rồi mở rộng lên cụm mà không cần viết lại mã.
Và đây là một lợi ích mạnh mẽ khác của sự tách biệt driver–worker: Nó cải thiện khả năng cô lập lỗi. Nếu một worker chết khi đang chạy tác vụ, Spark có thể gán lại tác vụ đó cho worker khác mà không làm sập ứng dụng.
Hãy bóc tách những gì diễn ra bên trong driver và các node.
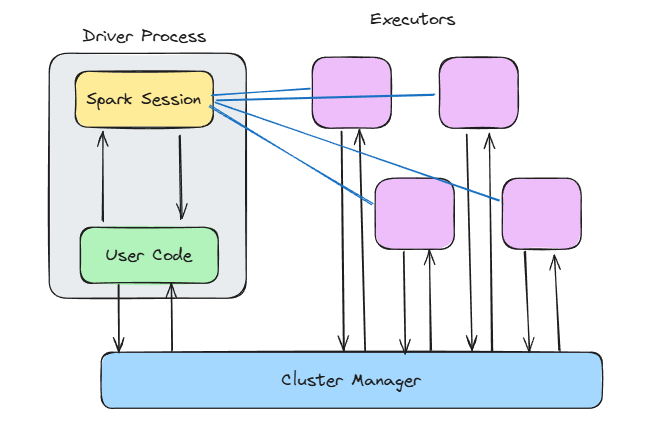
Kiến trúc Spark. Hình minh họa của tác giả.
Khi bạn gọi SparkContext() hoặc dùng SparkSession.builder.getOrCreate(), bạn đang mở cánh cổng vào toàn bộ “phép màu” nội bộ của Spark.
Spark context:
Spark xây dựng một Đồ thị có hướng không chu trình (DAG) các phép biến đổi phía sau hậu trường. DAG đó được chia thành các stage và task, rồi thực thi song song.
Bộ lập lịch DAG xác định những task nào có thể chạy cùng nhau, và Bộ lập lịch Task gán chúng cho các executor. Trong khi đó, Bộ quản lý Block đảm bảo dữ liệu được cache, shuffle hoặc nạp lại khi cần.
Thiết kế phân lớp này giúp Spark vô cùng linh hoạt, vì bạn có thể tinh chỉnh độc lập bộ nhớ, lưu trữ và tính toán.
Nếu bạn đang làm với các phép biến đổi Spark hoặc kỹ thuật đặc trưng, hãy xem khóa Kỹ thuật đặc trưng với PySpark để thấy kiến trúc này vận hành thực tế.
Executors là nơi công việc được thực hiện.
Mỗi executor chạy:
Bạn có thể cấu hình lượng bộ nhớ mỗi executor nhận, số lõi nó dùng, và việc có nên ghi xuống đĩa khi hết bộ nhớ hay không.
Nhưng hãy cẩn thận: Nếu cấp phát không đủ bộ nhớ, bạn sẽ thường xuyên gặp lỗi tràn bộ nhớ. Tuy nhiên, cũng đừng cấp phát quá nhiều vì sẽ lãng phí tài nguyên. Giám sát và tinh chỉnh là tối quan trọng ở đây.
Viết mã PySpark khá đơn giản. Bạn lọc một DataFrame, thực hiện join, tổng hợp gì đó rồi bấm chạy. Nhưng đằng sau API gọn gàng đó, Spark âm thầm khởi động một bộ máy thực thi có thể phân tán công việc lên nhiều node.
Hãy xem điều gì diễn ra phía sau.
Điều đa số người dùng Spark không nhận ra ban đầu: Khi bạn viết mã PySpark, không có gì chạy ngay lập tức. Bạn đang xây dựng một kế hoạch, và Catalyst Optimizer của Spark sẽ lấy kế hoạch đó để biến đổi thành chiến lược thực thi hiệu quả.
Nó hoạt động qua bốn giai đoạn:
Catalyst Optimizer của Spark. Hình từ Databricks.
Vì vậy chuỗi .select(), .join() và .groupBy() không chỉ chạy tuần tự từng dòng. Nó được phân tích, tối ưu và biên dịch thành thứ có thể chạy rất nhanh trên cụm.
Xem PySpark Cheat Sheet nếu bạn muốn một tờ phao cho các lệnh PySpark hữu ích nhất.
Khi kế hoạch hoàn tất, bộ lập lịch DAG tiếp quản.
Nó chia nhỏ job thành các stage dựa trên ranh giới shuffle, nơi Spark quyết định điều gì phải chạy tuần tự và điều gì có thể thực thi song song.
Có hai loại stage chính:
groupBy() hoặc join() gây ra. Dữ liệu sau đó được phân vùng và gửi qua mạng. Loại stage này là tiền đề để tính toán ResultStage.Một điều quan trọng tôi rút ra được là tối thiểu hóa shuffle. Shuffle phải diễn ra trước khi một stage kết thúc và rất tốn kém. Bạn cần hiểu chúng xuất hiện ở đâu trong DAG và liệu bạn có thể tối ưu mã hơn nữa để giảm số lần shuffle không.
Khi bộ lập lịch DAG đã tạo xong các stage, chúng có thể được thực thi trên các executor khác nhau.
Vòng đời thực thi task trông như sau:
Một mẹo nhỏ từ kinh nghiệm của tôi: nếu job Spark của bạn bị treo sau khi trước đó chạy ổn, thường là do thu gom rác hoặc độ trễ khi lấy shuffle. Luôn kiểm tra mã và đảm bảo bạn hiểu kiến trúc Spark để tối ưu hiệu quả các vấn đề này.
Quản lý bộ nhớ của Spark là một chủ đề rất phức tạp và có thể khiến bạn mất hàng giờ debug nếu không hiểu rõ.
Vì vậy, hãy xem Spark quản lý bộ nhớ như thế nào bên dưới “nắp capo” để bạn ý thức được và tránh tốn hàng giờ debug do mã chậm hoặc lỗi tràn bộ nhớ.
Trước Spark 1.6, bộ nhớ được chia cứng giữa thực thi (cho shuffle và join) và lưu trữ (cho cache). Điều đó thay đổi với Spark 1.6, giới thiệu mô hình bộ nhớ hợp nhất.
Trong mô hình hợp nhất, dữ liệu được chia thành ba vùng chính:
Vùng bộ nhớ Spark tiếp tục được chia thành hai vùng:
Tính đàn hồi này cho phép Spark linh hoạt hơn với khối lượng dữ liệu khó đoán.
Tuy nhiên, điều đó cũng đồng nghĩa bạn sẽ mất chút kiểm soát nếu không nắm chuyện gì đang xảy ra. Ví dụ, nếu bạn cache() một DataFrame lớn nhưng cũng có các phép tổng hợp đắt đỏ trong cùng stage, Spark có thể loại bỏ dữ liệu đã cache để nhường chỗ cho shuffle.
Với bộ nhớ off-heap và lưu trữ dạng cột của Spark, động cơ Tungsten bắt đầu phát huy tác dụng.
Tungsten giới thiệu một số tối ưu giúp cải thiện hiệu năng của Spark:
Nếu bạn đang làm việc với DataFrame, bạn đã mặc định hưởng những tối ưu này. Đó là lý do tôi khuyến khích dùng DataFrame và SQL API thay vì RDD thô. Bạn nhận trọn sức mạnh của Catalyst và Tungsten mà không cần tinh chỉnh thêm.
Nếu bạn đang xây dựng pipeline làm sạch dữ liệu, bạn sẽ thấy điều này trong Cleaning Data with PySpark.
Nếu bạn làm với hệ thống phân tán, bạn biết một điều chắc chắn: Chúng sẽ hỏng. Node sập. Lỗi mạng xảy ra. Executor hết bộ nhớ và tắt.
Nhưng Spark được xây dựng để xử lý những vấn đề này và vẫn đảm bảo job của bạn thành công.
Hãy đi sâu hơn vào cách Spark đảm bảo job của bạn vẫn hoàn tất, ngay cả khi có bất ổn xảy ra.
Resilient Distributed Datasets (RDD) là cấu trúc dữ liệu nền tảng trong Spark. Và chúng được gọi là “resilient” (bền bỉ) là có lý do.
Spark sử dụng phả hệ (lineage) để đảm bảo mỗi RDD có thể được tính toán lại khi node lỗi và mất dữ liệu.
Vì vậy khi một node hỏng, Spark đơn giản tính lại dữ liệu bị mất bằng đồ thị phả hệ.
Cách hoạt động trong thực tế:
map() hoặc filter()): Spark chỉ cần partition bị mất để tính lại.groupBy() hoặc join()): Spark có thể cần lấy dữ liệu từ nhiều partition, vì có thể yêu cầu đầu ra của nhiều stage. Lineage giúp bạn không phải xử lý lỗi thủ công. Tuy nhiên, nếu đồ thị phả hệ quá dài, chứa hàng trăm phép biến đổi, việc tính lại dữ liệu bị mất sẽ tốn kém. Khi đó, checkpointing là giải pháp.
Khi gặp workflow phức tạp hoặc job streaming, Spark không thể chỉ dựa vào phả hệ. Đó là lúc checkpointing phát huy tác dụng.
Bạn có thể gọi rdd.checkpoint() để lưu trạng thái RDD hiện tại vào nơi lưu trữ tin cậy (như HDFS).
Spark sau đó cắt ngắn phả hệ. Nếu lỗi xảy ra, nó tải dữ liệu trực tiếp thay vì tính lại.
Trong structured streaming, Spark cũng dùng nhật ký ghi trước (WAL) để đảm bảo dữ liệu không bị mất khi truyền.
Đây là những yếu tố tạo nên độ ổn định:
Checkpointing là tùy chọn với job batch, nhưng bắt buộc đối với pipeline streaming.
Hãy tưởng tượng bạn có một job Spark thất bại sau 10 giờ chạy, nhưng bạn có thể tiếp tục từ chỗ dở dang nhờ checkpointing và WAL.
Đến giờ, bạn đã thấy Spark xử lý job ra sao và cách nó quản lý bộ nhớ, xử lý lỗi.
Trong phần này, chúng ta tìm hiểu một số nâng cấp kiến trúc nâng cao giúp Spark linh hoạt hơn, thời gian thực hơn và thích ứng tốt hơn.
AQE được giới thiệu trong Spark 3.0 và tăng cường hiệu năng truy vấn bằng cách điều chỉnh kế hoạch thực thi động khi chạy, dựa trên thống kê thu thập trong quá trình thực thi.
Các tính năng của AQE gồm:
Tính năng này là “cú nổ” vì cho phép các job vốn cần tinh chỉnh thủ công và thử–sai có thể tự thích ứng theo thời gian thực.
Hãy đảm bảo bật nó rõ ràng qua cấu hình (spark.sql.adaptive.enabled = true). Và nếu bạn chạy Spark 3.0+, không có lý do gì để không bật.
Structured Streaming đưa động cơ của Spark vào miền thời gian thực, mà không buộc bạn học một API hoàn toàn mới.
Phía sau hậu trường, nó vẫn áp dụng micro-batching. Nhưng nó xử lý:
Điểm mạnh ở đây là cảm giác “streaming như batch”. Bạn viết groupBy() hay filter() và Spark lo phần còn lại, giúp phân tích streaming dễ tiếp cận mà không cần chuỗi công cụ chuyên biệt.
Nếu bạn chạy Spark trong môi trường production, đặc biệt là tài chính, y tế hoặc các lĩnh vực tương tự, bạn cần biết Spark xử lý xác thực, mã hóa và khả năng kiểm toán như thế nào.
Hãy đi sâu vào các chủ đề này và cách Spark giải quyết chúng.
Spark có nhiều tính năng bảo mật mà bạn cần bật trước. Nhưng khi đã bật, Spark cung cấp một bộ công cụ vững chắc cho giao tiếp và xác thực an toàn:
spark.acls.enable=true và cấu hình spark.ui.view.acls cùng spark.ui.view.acls.groups để hạn chế truy cập.Bạn có thể xem toàn bộ tính năng bảo mật trong tài liệu chính thức của Spark. Hãy xem và đảm bảo bật các tính năng cần thiết để bảo vệ ứng dụng Spark của bạn.
Ghi lại ai làm gì và khi nào cũng rất quan trọng.
Spark hỗ trợ:
spark.eventLog.enabled=true), Spark ghi mọi sự kiện job, stage, task xuống đĩa. Bạn có thể dùng log này để phát lại lịch sử job hoặc đáp ứng yêu cầu kiểm toán.Spark rất mạnh và nhanh, và có thể tối ưu để còn nhanh hơn nữa nếu bạn biết tinh chỉnh ở đâu.
Có nhiều khu vực bạn có thể tối ưu để khai thác tối đa Spark. Hãy đi sâu vào từng khu vực.
Điểm yếu của Spark, nếu có, là shuffle. Shuffle xảy ra khi dữ liệu cần di chuyển giữa các partition, thường sau các phép biến đổi “rộng” như groupByKey(), distinct() hoặc join().
Và khi shuffle trục trặc, bạn có thể gặp I/O đĩa khổng lồ, các lần dọn rác kéo dài hoặc task bị lệch không bao giờ kết thúc.
Đây là cách bạn có thể cải thiện shuffle:
reduceByKey() thay vì groupByKey(): reduceByKey() tổng hợp cục bộ trước khi shuffle. groupByKey() gửi mọi thứ qua mạng..repartition(n) để tăng song song, hoặc .coalesce(n) để giảm. Đừng phó mặc cho giá trị mặc định của Spark.spark.sql.autoBroadcastJoinThreshold để kiểm soát giới hạn kích thước.collect(): Tránh khi có thể, vì kéo dữ liệu về driver sẽ giết hiệu năng.Tinh chỉnh bộ nhớ của Spark có thể là cả một khoa học, nhưng bạn có thể dùng danh sách kiểm sau để đơn giản hóa:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Điều chỉnh cấu hình bộ nhớ có thể giúp rất nhiều. Tôi từng giảm một job 30 phút xuống còn 8 phút chỉ bằng cách chỉnh cấu hình bộ nhớ, không đổi một dòng mã.
Đây là phần hầu hết các đội làm sai, vì họ đoán kích thước cụm thay vì ước tính đúng.
Bạn có thể làm tốt hơn bằng cách dùng các công thức sau:
Ví dụ:
Nhưng hãy nhớ: Đây chỉ là ước tính. Hãy dùng làm điểm khởi đầu rồi tối ưu tiếp thông qua profiling.
Spark đã tồn tại hơn một thập kỷ, nhưng vẫn rất cập nhật. Nó đang phát triển nhanh hơn bao giờ hết nhờ nền tảng cloud-native, tăng tốc bằng GPU và tích hợp ML chặt chẽ hơn.
Nếu hôm nay bạn dùng Spark giống hệt ba năm trước, có lẽ bạn đang bỏ lỡ hiệu năng và những tính năng mới tuyệt vời.
Hãy xem một vài điểm mới nhất.
Nếu bạn làm với Databricks, có lẽ bạn đã làm việc với và nghe về Photon.
Nếu muốn tìm hiểu thêm về Databricks, tôi khuyên bạn nên học khóa Introduction to Databricks.
Photon là động cơ thế hệ tiếp theo trên nền tảng Databricks Lakehouse, cung cấp hiệu năng truy vấn nhanh với chi phí thấp. Nó tương thích với API Spark, vì vậy bạn không cần chỉnh mã Spark để sử dụng.
Nó giúp tăng tốc đáng kể mã SQL và PySpark của bạn.
Photon bao gồm các tính năng sau:
Serverless thật tuyệt, vì bạn không phải quản lý cụm, không cần cấp phát trước tài nguyên, và chỉ trả tiền cho thời gian Spark chạy.
Serverless cho Spark đã có trên các dịch vụ như Databricks Serverless, AWS Glue và GCP Dataproc Serverless.
Và đây là lý do nó tuyệt vời:
Serverless Spark lý tưởng cho phân tích tương tác, job ad-hoc hoặc tải công việc khó dự đoán.
Nhưng hãy cẩn trọng: pipeline chạy lâu, ổn định có thể vẫn rẻ hơn trên cụm cố định. Luôn đo cả chi phí lẫn độ trễ.
Khi ngành chuyển dịch, ranh giới giữa kỹ thuật dữ liệu và AI đang mờ dần. Như Deepak Goyal, CEO & Founder tại Azurelib Academy, đã bàn trong podcast DataFramed
Kỹ thuật dữ liệu sẽ đóng vai trò cốt lõi và nền tảng trong làn sóng chuyển dịch sang AI sắp tới.
Deepak Goyal, CEO & Founder at Azurelib Academy
Learn more about Spark with these courses!
Courses
Courses
Courses