
Cours
Apprentissage automatique avec PySpark
4 h
29.7K
Avez-vous déjà essayé de déboguer un job Spark qui a soudainement échoué et compris que vous êtes complètement perdu à cause de la profondeur du trou de lapin de Spark ?
Lorsque j'ai travaillé pour la première fois avec Apache Spark, je pensais qu'il suffisait d'écrire quelques transformations PySpark et que Spark se mettrait " magiquement " à l'échelle du cluster. Je me suis trompé. Les performances de Spark dépendent entièrement de la compréhension de ce qui se passe en coulisses.
Ce guide s'adresse à tous ceux qui ne veulent pas traiter Spark comme une boîte noire. Nous verrons comment l'architecture de Spark est conçue, du modèle maître-ouvrier et du flux d'exécution, à sa gestion de la mémoire et à ses mécanismes de tolérance aux pannes.
Si vous souhaitez créer des applications big data rapides, tolérantes aux pannes et efficaces, vous êtes au bon endroit !
Avant que vous n'écriviez votre première ligne de PySpark, Spark a déjà pris certaines décisions architecturales pour vous. Spark n'est pas seulement rapide grâce au calcul en mémoire, mais parce qu'il est construit sur une architecture maître-ouvrier qui évolue et survit au chaos du monde réel, comme les crashs de nœudshes, les problèmes de machine virtuelle Java (JVM) et les volumes de données incohérents.
Décortiquons l'architecture de base de Spark et expliquons pourquoi il est toujours aussi puissant et présent dans les flux de travail big data modernes.
Au cœur de Spark se trouve le modèle maître d'œuvre . Pensez-y comme suit :
main(), crée le contexte Spark, gère la planification du DAG et indique au cluster ce qu'il doit faire.Cette configuration vous permet de vous concentrer sur la définition des transformations, et Spark décide où et comment les exécuter en parallèle sur les exécuteurs.
Ce que j'apprécie dans cette conception, c'est qu'elle est agnostique en termes de déploiement. Le même code s'exécute, indépendamment de son déploiement sur votre machine locale, dans Kubernetes ou Mesos. Il est donc facile de le développer et de le tester localement, puis de le faire évoluer vers des clusters sans réécrire votre code.
Et voici un autre avantage puissant de la séparation conducteur-travailleur de Spark : Il améliore l'isolation des fautes. Si un nœud de travailleur meurt pendant l'exécution d'une tâche, Spark peut réaffecter cette tâche à un autre travailleur sans faire planter votre application.
Décortiquons ce qui se passe à l'intérieur du pilote et des nœuds.
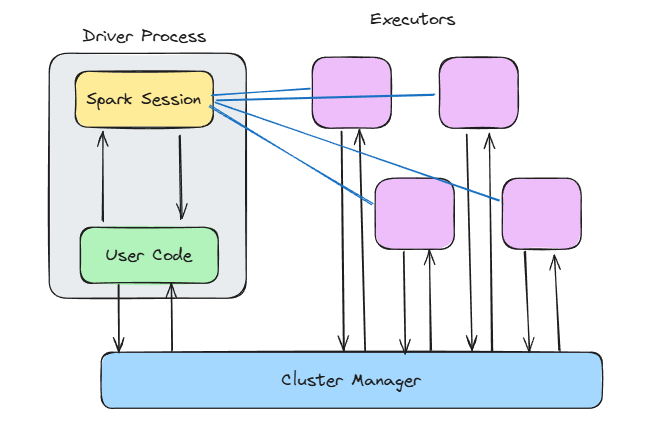
Architecture Spark. Image de l'auteur.
Lorsque vous appelez SparkContext() ou utilisez SparkSession.builder.getOrCreate(), vous ouvrez la porte à toute la magie interne de Spark.
Le contexte Spark :
Spark construit un graphe acyclique dirigé (DAG) des transformations en coulisse. Ce DAG est décomposé en étapes et en tâches, puis exécuté en parallèle.
Le planificateur DAG détermine les tâches qui peuvent être exécutées ensemble, et le planificateur de tâches les affecte aux exécuteurs. Pendant ce temps, le gestionnaire de blocs veille à ce que les données soient mises en cache, mélangées ou rechargées en fonction des besoins.
Cette conception en couches rend Spark incroyablement flexible, car vous pouvez ajuster la mémoire, le stockage et le calcul indépendamment.
Si vous travaillez avec les transformations Spark ou l'ingénierie des fonctionnalités, consultez le cours Feature Engineering with PySpark pour voir cette architecture en action.
Les exécutants sont là où le travail est fait.
Chaque exécuteur s'exécute :
Vous pouvez configurer la quantité de mémoire dont dispose chaque exécuteur, le nombre de cœurs qu'il utilise et s'il doit écrire sur le disque lorsque la mémoire est épuisée.
Mais attention : Si vous n'allouez pas suffisamment de mémoire, vous serez constamment confronté à des erreurs de mémoire. Cependant, vous devez également éviter d'allouer trop de mémoire, car cela gaspille des ressources. Le suivi et l'ajustement sont essentiels ici.
L'écriture du code PySpark est assez simple. Vous filtrez un DataFrame, effectuez une jointure, agrègez quelque chose et lancez l'exécution. Mais derrière cette API épurée, Spark met discrètement en place un moteur d'exécution capable de répartir le travail sur plusieurs nœuds.
Voyons ce qui se passe en coulisses.
Voici ce que la plupart des utilisateurs de Spark ne réalisent pas au premier abord : Lorsque vous écrivez du code PySpark, vous n'exécutez rien immédiatement. Vous élaborez un plan, et le Catalyst Optimizer de Spark prend ce plan et le transforme en une stratégie d'exécution efficace.
Il fonctionne en quatre phases :
Optimiseur de catalyseur de Spark. Image par Databricks.
Cette chaîne de .select(), .join() et .groupBy() ne se déroule donc pas simplement ligne par ligne. Il est analysé, optimisé et compilé en quelque chose qui fonctionne rapidement sur un cluster.
Consultez l'aide-mémoire PySpark si vous voulez une aide-mémoire pour les commandes PySpark les plus utiles.
Lorsque le plan est terminé, l'ordonnanceur DAG prend le relais.
Il décompose le travail en étapes basées sur les frontières de brassage, où Spark décide de ce qui se passe séquentiellement et de ce qui peut être exécuté en parallèle.
Il existe deux grands types d'étapes :
groupBy() ou join(). Les données sont ensuite divisées et envoyées sur le réseau. Ce type d'étape est nécessaire pour calculer l'étape de résultat.Une chose essentielle que j'ai apprise est de minimiser les mélanges. Un brassage doit avoir lieu avant la fin d'une étape et est coûteux. Vous devez comprendre où ils se produisent dans votre DAG et si vous pouvez optimiser votre code pour réduire le nombre de mélanges.
Une fois que l'ordonnanceur DAG a créé toutes les étapes, celles-ci peuvent être exécutées sur les différents exécuteurs.
Le cycle de vie de l'exécution de la tâche ressemble à ceci :
Un petit conseil tiré de ma propre expérience : si votre travail Spark se bloque alors qu'il s'était bien déroulé auparavant, c'est souvent à cause du garbage collection ou des retards de shuffle fetch. Vérifiez toujours votre code et assurez-vous de comprendre l'architecture de Spark afin d'optimiser efficacement ces sujets.
La gestion de la mémoire de Spark est un sujet très complexe et peut vous coûter des heures de débogage si vous ne la comprenez pas.
Voyons donc comment Spark gère la mémoire sous le capot afin que vous en soyez conscient et que vous puissiez éviter des heures de débogage de code lent ou d'erreurs hors mémoire.
Avant Spark 1.6, la mémoire était strictement divisée entre l'exécution (pour les mélanges et les jointures) et le stockage (pour la mise en cache). Cela a changé avec la version 1.6 de Spark, qui a introduit le modèle de mémoire unifiée.
Dans le modèle de mémoire unifiée, les données sont réparties en trois groupes principaux :
Le pool de mémoire de Spark est lui-même divisé en deux pools :
Cette élasticité permet à Spark d'être plus flexible avec des volumes de données imprévisibles.
Toutefois, cela signifie aussi que vous perdez un peu le contrôle lorsque vous ne savez pas ce qui se passe. Par exemple, si vous cache() un DataFrame de grande taille mais que vous avez également des agrégations coûteuses dans la même étape, Spark pourrait évincer vos données mises en cache pour faire de la place pour le mélange.
Dans le stockage hors tas et en colonnes de Spark, c'est le moteur Tungsten qui entre en jeu.
Tungsten a introduit plusieurs optimisations qui ont permis d'améliorer les performances de Spark :
Et si vous travaillez avec des DataFrame, vous utilisez déjà ces optimisations sous le capot. C'est l'une des raisons pour lesquelles je pousse les gens à utiliser les DataFrame et les API SQL plutôt que les RDD bruts. Vous bénéficiez de toute la puissance de Catalyst et de Tungsten sans aucun réglage supplémentaire.
Si vous travaillez avec des pipelines de nettoyage de données, vous verrez cela en action dans Cleaning Data with PySpark.
Si vous travaillez avec des systèmes distribués, vous êtes sûr d'une chose : Ils échouent. Les nœuds se bloquent. Des erreurs de réseau se produisent. Les exécuteurs manquent de mémoire et s'arrêtent.
Mais Spark est conçu pour gérer ces problèmes et garantit que vos emplois réussissent quand même.
Plongeons plus profondément dans la façon dont Spark s'assure que vos travaux réussissent toujours, même si certaines instabilités se produisent.
Les ensembles de données distribués résilients (RDD) constituent la structure de données fondamentale de Spark. Et ce n'est pas pour rien qu'on les appelle résilients.
Spark utilise le lignage pour s'assurer que chaque RDD peut être recalculé en cas de défaillance d'un nœud et de perte de données.
Ainsi, lorsqu'un nœud tombe en panne, Spark recalcule simplement les données perdues à l'aide du graphe de lignage.
Voici comment cela fonctionne en pratique :
map() ou filter()) : Spark n'a besoin que de la partition perdue pour recalculer.groupBy() ou join()) : Spark peut avoir besoin de récupérer des données sur plusieurs partitions, car il peut avoir besoin de la sortie de plusieurs étapes. Lineage évite d'avoir à gérer manuellement les défaillances. Cependant, si votre graphe de lignée devient trop long, car il peut contenir des centaines de transformations, le recalcul des données perdues devient coûteux. C'est là que le point de contrôle entre en jeu.
Lorsque vous rencontrez des flux de travail complexes ou des tâches en continu, Spark ne peut pas dépendre uniquement du lignage. C'est là que le point de contrôle entre en jeu.
Vous pouvez appeler rdd.checkpoint() pour conserver l'état actuel du RDD dans un emplacement de stockage fiable (comme HDFS).
Spark tronque ensuite la lignée. En cas d'erreur, il recharge directement les données au lieu de les recalculer.
Dans le cadre de la diffusion en continu structurée, Spark utilise également des journaux en avance sur l'écriture (WAL) pour s'assurer que les données ne sont pas perdues en cours de route.
C'est ce qui le rend si stable :
Le point de contrôle est facultatif pour les travaux de traitement par lots, mais obligatoire pour les pipelines de diffusion en continu.
Supposons qu'un travail Spark ait échoué après 10 heures d'exécution, mais que vous puissiez reprendre là où vous vous étiez arrêté, grâce aux points de contrôle et aux WAL.
À ce stade, vous avez vu comment Spark traite les jobs et gère la mémoire et les échecs.
Dans cette section, nous allons nous pencher sur certaines des améliorations architecturales avancées qui rendent Spark plus dynamique, plus en temps réel et plus adaptable.
L'AQE est introduit dans Spark 3.0 et améliore les performances des requêtes en ajustant dynamiquement les plans d'exécution au moment de l'exécution en fonction des statistiques collectées pendant l'exécution.
Les caractéristiques de l'AQE sont les suivantes
Cette fonction change la donne, car elle permet d'adapter en temps réel des travaux qui nécessitaient auparavant des réglages manuels et des essais-erreurs.
Veillez simplement à l'activer explicitement via la configuration (spark.sql.adaptive.enabled = true). Et si vous utilisez Spark 3.0+, il n'y a aucune raison de ne pas le faire.
Structured Streaming reprend le moteur de Spark et l'étend au domaine du temps réel, sans vous obliger à apprendre une toute nouvelle API.
En coulisses, il applique toujours le micro-batching. Mais il est maniable :
Ce qui est frappant ici, c'est que la diffusion en continu ressemble à la mise en lots. Vous écrivez un groupBy() ou un filter() et Spark s'occupe de tout le reste, ce qui rend l'analyse en continu accessible sans chaîne d'outils spécialisée.
Si vous utilisez Spark en production, en particulier dans les domaines de la finance, de la santé ou d'autres secteurs d'activité similaires, vous devez savoir comment Spark gère l'authentification, le chiffrement et l'auditabilité.
Nous allons donc nous pencher plus en détail sur ces sujets et sur la manière dont Spark s'en occupe.
Spark possède de nombreuses fonctions de sécurité que vous devez d'abord activer. Mais une fois activé, Spark offre une solide boîte à outils pour la communication et l'authentification sécurisées :
spark.acls.enable=true et spark.ui.view.acls et spark.ui.view.acls.groups pour la restreindre.Vous pouvez vérifier toutes les caractéristiques de sécurité dans la documentation officielle de Spark. Consultez-le et assurez-vous d'activer les fonctionnalités dont vous avez besoin pour sécuriser vos applications Spark.
Il est également essentiel d'enregistrer qui a fait quoi et quand.
Spark prend en charge :
spark.eventLog.enabled=true), Spark enregistre chaque tâche, étape et événement de tâche sur le disque. Vous pouvez utiliser ces journaux pour rejouer l'historique des tâches ou répondre à des exigences d'audit.Spark est assez puissant et rapide, et il peut être optimisé pour être encore plus rapide si vous savez où faire les ajustements nécessaires.
Il existe plusieurs domaines dans lesquels vous pouvez essayer d'optimiser pour tirer le meilleur parti de Spark. Nous allons donc nous pencher sur chacun de ces domaines.
Si Spark a un point faible, c'est bien le brassage. Les mélanges se produisent lorsque les données doivent être déplacées entre les partitions, généralement après des transformations importantes telles que groupByKey(), distinct() ou join().
Et lorsque les mélanges ne se déroulent pas correctement, vous pouvez obtenir des E/S de disque massives, de longues pauses de collecte de déchets ou des tâches asymétriques qui ne se terminent jamais.
Voici comment vous pouvez améliorer les mélanges :
reduceByKey() à groupByKey(): reduceByKey() agrège localement avant de mélanger. groupByKey() envoie tout sur le réseau..repartition(n) pour augmenter le parallélisme ou .coalesce(n) pour le réduire. Ne vous en remettez pas au partitionnement par défaut de Spark.spark.sql.autoBroadcastJoinThreshold pour contrôler la limite de taille.collect(): Évitez-le dans la mesure du possible, car le transfert de données vers le conducteur nuit aux performances.Le réglage de la mémoire de Spark peut être une véritable science, mais vous pouvez utiliser la liste de contrôle ci-dessous pour vous faciliter la tâche :
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.L'ajustement de la configuration de la mémoire peut s'avérer très utile. J'ai déjà réduit un travail de 30 minutes à 8 minutes en adaptant la configuration de la mémoire, sans changer une seule ligne de code.
C'est la partie où la plupart des équipes se trompent, parce qu'elles devinent la taille de la grappe au lieu de l'estimer correctement.
Mais vous pouvez faire mieux en utilisant les formules ci-dessous :
Par exemple :
Mais n'oubliez pas : Il s'agit uniquement d'une estimation. Vous pouvez l'utiliser comme point de départ et l'optimiser ensuite grâce au profilage.
Spark existe depuis une dizaine d'années, mais il reste tout à fait d'actualité. Elle évolue plus rapidement que jamais, grâce aux plateformes cloud-natives, à l'accélération GPU et à une intégration plus étroite du ML.
Si vous utilisez Spark aujourd'hui de la même manière qu'il y a trois ans, vous laissez probablement des performances sur le tableau et vous passez à côté de nouvelles fonctionnalités intéressantes.
Jetons un coup d'œil à quelques-uns des plus récents d'entre eux.
Si vous travaillez avec Databricks, vous avez probablement déjà travaillé avec Photon et en avez entendu parler.
Si vous souhaitez en savoir plus sur Databricks, je vous recommande le cours Introduction à Databricks.
Photon est le moteur de nouvelle génération de la plateforme Lakehouse de Databricks qui fournit des performances de requête rapides à faible coût. Il est compatible avec les API de Spark, vous n'avez donc pas besoin d'adapter votre code Spark pour l'utiliser.
Il permet d'améliorer considérablement votre code SQL et PySpark.
Photon comprend les fonctionnalités suivantes :
Serverless est fantastique, car cela signifie que vous n'avez pas à gérer des clusters, à pré-provisionner des ressources, et que vous ne payez que pour le temps d'exécution de Spark.
Et le serverless pour Spark est déjà en direct dans des services comme Databricks Serverless, AWS Glue et GCP Dataproc Serverless.
Et voici pourquoi c'est incroyable :
Spark sans serveur est idéal pour les analyses interactives, les tâches ad hoc ou les charges de travail imprévisibles.
Mais attention : les pipelines cohérents et de longue durée peuvent toujours être moins coûteux sur les clusters fixes. Mesurez toujours le coût et la latence.
Si vous faites de l'apprentissage automatique à grande échelle et que vous visez la mise en production de modèles, Spark seul ne suffit pas. Vous avez besoin des principes MLOps, tels que le cursus des expériences, le versionnage des modèles et la reproductibilité. C'est là que MLflow intervient.
MLflow s'intègre désormais à Spark et apporte une pile complète de MLOPs à vos pipelines.
Vous pouvez le faire :
mlflow.log_param() et mlflow.log_metric().pyspark.ml ou sklearn directement dans le registre de modèles de MLflow.Vous n'avez pas besoin de changer d'outil. Vous continuez à utiliser Spark pour l'entraînement, l'ingénierie des fonctionnalités et le scoring, tout en utilisant MLflow pour les tâches de MLOPs.
Si vous ne connaissez pas bien Spark, il ressemble à une gigantesque boîte noire. Vous écrivez du code PySpark, vous appuyez sur run et vous espérez que cela fonctionne.
Parfois, cela fonctionnait bien pour moi, parfois cela menait à de longues sessions de débogage et à la recherche de ce qui n'allait pas.
Ce n'est que lorsque j'ai commencé à regarder derrière les coulisses que les choses ont pris un sens pour moi. Il m'a fallu un certain temps pour comprendre ce qui se passait.
Voici ce sur quoi je me concentrerais si je devais repartir de zéro :
C'est précisément ce que nous avons appris dans cet article.
Si vous souhaitez continuer à apprendre, voici quelques ressources pour débutants que je vous recommande :
Apprenez-en plus sur Spark avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
Tutoriel
Matt Crabtree
Tutoriel
