
Curso
Machine learning com PySpark
4 h
29.7K
Você já tentou depurar um trabalho do Spark que falhou repentinamente e descobriu que estava completamente perdido por causa da profundidade da toca do coelho do Spark?
Quando trabalhei pela primeira vez com o Apache Spark, pensei que bastava escrever algumas transformações do PySpark e que o Spark seria "magicamente" escalonado no cluster. Eu estava errado. O desempenho do Spark depende inteiramente da compreensão do que está acontecendo nos bastidores.
Este guia é para qualquer pessoa que não queira tratar o Spark como uma caixa preta. Veremos como a arquitetura do Spark foi projetada, desde o modelo de mestre-trabalhador e o fluxo de trabalho de execução até o gerenciamento de memória e os mecanismos de tolerância a falhas.
Se você deseja criar aplicativos de Big Data rápidos, tolerantes a falhas e eficientes, você está no lugar certo!
Antes de você escrever sua primeira linha no PySpark, o Spark já tomou algumas decisões arquitetônicas para você. O Spark não é rápido apenas por causa da computação na memória, mas porque foi desenvolvido em uma arquitetura de mestre-trabalhador que é dimensionada e sobrevive ao caos do mundo real, como falhas de nóshes, problemas com a máquina virtual Java (JVM) e volumes de dados inconsistentes.
Vamos detalhar a arquitetura principal do Spark e por que ele ainda é tão poderoso e presente nos fluxos de trabalho modernos de Big Data.
No centro do Spark está o modelo de mestre-trabalhador . Pense nisso da seguinte forma:
main(), cria o contexto do Spark, lida com o agendamento do DAG e informa ao cluster o que você deve fazer.Essa configuração permite que você se concentre na definição das transformações, e o Spark decide onde e como executá-las em paralelo nos executores.
O que eu gosto nesse design é que ele é independente da implantação. O mesmo código é executado, independentemente de você implantá-lo em seu computador local, no Kubernetes ou no Mesos. Isso facilita o desenvolvimento e o teste local e, em seguida, o dimensionamento para clusters sem que você precise reescrever o código.
E aqui está outro benefício poderoso da separação entre motorista e trabalhador da Spark: Ele melhora o isolamento de falhas. Se um nó de trabalho morrer durante a execução de uma tarefa, o Spark poderá reatribuir essa tarefa a outro trabalhador sem que você tenha que interromper o aplicativo.
Vamos detalhar o que está acontecendo dentro do driver e dos nós.
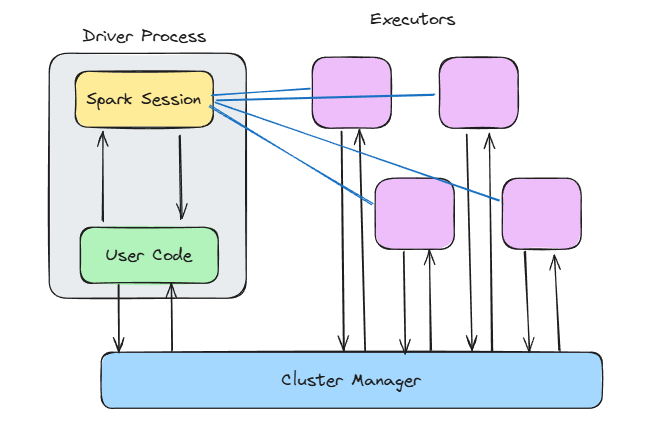
Arquitetura Spark. Imagem do autor.
Quando você chama SparkContext() ou usa SparkSession.builder.getOrCreate(), está abrindo a porta de entrada para toda a magia interna do Spark.
O contexto do Spark:
O Spark constrói um DAG ( Directed Acyclic Graph, gráfico acíclico dirigido ) de transformações nos bastidores. Esse DAG é dividido em estágios e tarefas e, em seguida, executado em paralelo.
O agendador de DAG descobre quais tarefas podem ser executadas juntas e o agendador de tarefas as atribui aos executores. Enquanto isso, o gerenciador de blocos garante que os dados sejam armazenados em cache, embaralhados ou recarregados conforme necessário.
Esse design em camadas torna o Spark incrivelmente flexível, pois você pode ajustar a memória, o armazenamento e a computação de forma independente.
Se você estiver trabalhando com transformações do Spark ou engenharia de recursos, confira o curso Feature Engineering with PySpark para ver essa arquitetura em ação.
Os executores são onde o trabalho é feito.
Cada executor é executado:
Você pode configurar a quantidade de memória que cada executor obtém, quantos núcleos ele usa e se deve gravar no disco quando a memória acabar.
Mas tenha cuidado: Se você não alocar memória suficiente, receberá erros de falta de memória o tempo todo. No entanto, você também deve evitar alocar muita memória, pois isso desperdiça recursos. O monitoramento e o ajuste são essenciais aqui.
Escrever código PySpark é bastante simples. Você filtra um DataFrame, faz uma junção, agrega alguma coisa e executa. Mas, por trás dessa API limpa, o Spark está desenvolvendo discretamente um mecanismo de execução que pode distribuir o trabalho em vários nós.
Vamos ver o que acontece nos bastidores.
Aqui está o que a maioria dos usuários do Spark não percebe no início: Quando você escreve código PySpark, não está executando nada imediatamente. Você está criando um plano, e o Catalyst Optimizer do Spark pega esse plano e o transforma em uma estratégia de execução eficiente.
Ele funciona em quatro fases:
O otimizador de catalisador do Spark. Imagem da Databricks.
Portanto, essa cadeia de .select(), .join() e .groupBy() não está apenas sendo executada linha por linha. Ele está sendo analisado, otimizado e compilado em algo que é executado rapidamente em um cluster.
Confira esta Folha de dicas do PySpark se você quiser uma folha de dicas para os comandos mais úteis do PySpark.
Quando o plano é concluído, o agendador DAG assume o controle.
Ele divide o trabalho em estágios com base em limites de embaralhamento, onde o Spark decide o que acontece sequencialmente e o que pode ser executado em paralelo.
Há dois tipos principais de estágios:
groupBy() ou join(). Os dados são então particionados e enviados pela rede. Esse tipo de estágio é necessário para calcular o ResultStage.Uma coisa importante que aprendi é minimizar os embaralhamentos. Um embaralhamento precisa ocorrer antes do término de um estágio e é caro. Você precisa entender onde eles ocorrem no seu DAG e se pode otimizar ainda mais o seu código para reduzir o número de embaralhamentos.
Depois que o agendador de DAG tiver criado todos os estágios, eles poderão ser executados nos diferentes executores.
O ciclo de vida da execução da tarefa é mais ou menos assim:
Uma pequena dica de minha própria experiência: se o seu trabalho no Spark travar depois de ter funcionado bem antes, isso geralmente se deve a atrasos na coleta de lixo ou na busca aleatória. Sempre verifique seu código e certifique-se de que você entende a arquitetura do Spark para que possa otimizar esses tópicos de forma eficaz.
O gerenciamento de memória do Spark é um tópico muito complexo e pode lhe custar horas de depuração se você não o entender.
Vamos, portanto, dar uma olhada em como o Spark gerencia a memória nos bastidores, para que você esteja ciente disso e possa evitar horas de depuração de código lento ou erros de falta de memória.
Antes do Spark 1.6, a memória era estritamente dividida entre a execução (para embaralhamentos e junções) e o armazenamento (para armazenamento em cache). Isso mudou com o Spark 1.6, que introduziu o modelo de memória unificada.
No modelo de memória unificada, os dados são divididos em três pools principais:
O pool de memória do Spark é dividido em dois pools:
Essa elasticidade permite que o Spark seja mais flexível com volumes de dados imprevisíveis.
No entanto, isso também significa perder um pouco do controle quando você não sabe o que está acontecendo. Por exemplo, se você cache() um DataFrame grande, mas também tiver agregações caras no mesmo estágio, o Spark poderá despejar seus dados em cache para abrir espaço para o embaralhamento.
No armazenamento fora da pilha e em colunas do Spark, o mecanismo Tungsten entra em ação.
O Tungsten introduziu várias otimizações que melhoraram o desempenho do Spark:
E se você estiver trabalhando com DataFrames, já estará usando essas otimizações. Esse é um dos motivos pelos quais incentivo as pessoas a usarem DataFrames e APIs SQL em vez de RDDs brutos. Você obtém toda a potência do Catalyst e do Tungsten sem nenhum ajuste extra.
Se estiver trabalhando com pipelines de limpeza de dados, você verá isso em ação em Cleaning Data with PySpark.
Se você trabalha com sistemas distribuídos, sabe de uma coisa com certeza: Eles falham. Os nós falham. Erros de rede acontecem. Os executores ficam sem memória e são desligados.
Mas o Spark foi desenvolvido para lidar com esses problemas e garantir que você tenha sucesso em seus trabalhos.
Vamos nos aprofundar em como o Spark garante que seus trabalhos ainda sejam bem-sucedidos, mesmo que ocorram algumas instabilidades.
Os RDDs (Resilient Distributed Datasets, conjuntos de dados distribuídos resilientes) são a estrutura de dados fundamental do Spark. E elas são chamadas de resilientes por um motivo.
O Spark usa a linhagem para garantir que cada RDD possa ser recalculado no caso de falha de um nó e perda de dados.
Assim, quando um nó falha, o Spark simplesmente recomputa os dados perdidos usando o gráfico de linhagem.
Veja como isso funciona na prática:
map() ou filter()): O Spark só precisa da partição perdida para recomputar.groupBy() ou join()): Talvez você precise buscar dados em várias partições, pois o Spark pode exigir a saída de vários estágios. O Lineage evita a necessidade de lidar com falhas manualmente. No entanto, se o gráfico de linhagem se tornar muito longo, pois pode conter centenas de transformações, a recomputação dos dados perdidos se tornará cara. É aí que o checkpointing entra em ação.
Quando você se depara com fluxos de trabalho complexos ou trabalhos de streaming, o Spark não pode depender apenas da linhagem. É aí que o checkpointing entra em ação.
Você pode chamar rdd.checkpoint() para manter o estado atual do RDD em um local de armazenamento confiável (como o HDFS).
Em seguida, o Spark trunca a linhagem. Se ocorrer um erro, ele recarrega os dados diretamente em vez de recomputá-los.
No streaming estruturado, o Spark também usa registros de gravação antecipada (WALs) para garantir que os dados não sejam perdidos em trânsito.
É isso que o torna tão estável:
O checkpointing é opcional para trabalhos de processamento em lote, mas obrigatório para pipelines de streaming.
Suponha que você tenha um trabalho do Spark que falhou após 10 horas de execução, mas pode retomar de onde parou, graças ao checkpointing e aos WALs.
Até agora, você já viu como o Spark processa trabalhos e lida com memória e falhas.
Nesta seção, vamos nos aprofundar em algumas das atualizações arquitetônicas avançadas que tornam o Spark mais dinâmico, mais em tempo real e mais adaptável.
O AQE foi introduzido no Spark 3.0 e melhora o desempenho da consulta, ajustando dinamicamente os planos de execução em tempo de execução com base nas estatísticas coletadas durante a execução.
Os recursos do AQE incluem:
Esse recurso é um divisor de águas, pois permite que trabalhos que antes exigiam ajuste manual e tentativa e erro se adaptem em tempo real.
Apenas certifique-se de ativá-lo explicitamente por meio da configuração (spark.sql.adaptive.enabled = true). E se você estiver executando o Spark 3.0+, não há motivo para não fazê-lo.
O Structured Streaming usa o mecanismo do Spark e o estende para o domínio em tempo real, sem exigir que você aprenda uma API totalmente nova.
Nos bastidores, ele ainda aplica o micro-batching. Mas você pode manuseá-lo:
O que é poderoso aqui é como o streaming se parece com o batching. Você escreve um groupBy() ou um filter() e o Spark cuida de todo o resto, tornando a análise de streaming acessível sem uma cadeia de ferramentas especializada.
Se você estiver executando o Spark na produção, especialmente em finanças, saúde ou áreas de negócios semelhantes, precisará saber como o Spark lida com a autenticação, a criptografia e a auditabilidade.
Então, vamos nos aprofundar nesses tópicos e em como o Spark cuida deles.
O Spark tem muitos recursos de segurança que você deve habilitar primeiro. Mas, uma vez ativado, o Spark oferece uma caixa de ferramentas sólida para comunicação e autenticação seguras:
spark.acls.enable=true e spark.ui.view.acls e spark.ui.view.acls.groups para restringi-las.Você pode verificar todos os recursos de segurança na documentação oficial do Spark. Confira e garanta que você habilite os recursos necessários para proteger seus aplicativos Spark.
O registro de quem fez o quê e quando também é fundamental.
O Spark oferece suporte a você:
spark.eventLog.enabled=true), o Spark registra cada trabalho, estágio e evento de tarefa no disco. Você pode usar esses logs para reproduzir o histórico do trabalho ou atender aos requisitos de auditoria.O Spark é bastante poderoso e rápido, e pode ser otimizado para ser ainda mais rápido se você souber onde fazer os ajustes necessários.
Há várias áreas em que você pode tentar otimizar para obter o máximo do Spark. Então, vamos nos aprofundar em cada área.
Se o Spark tem um ponto fraco, é o shuffle. Os embaralhamentos ocorrem quando os dados precisam ser movidos entre partições, geralmente após transformações amplas como groupByKey(), distinct() ou join().
E quando os embaralhamentos dão errado, você pode obter E/S de disco em massa, longas pausas na coleta de lixo ou tarefas distorcidas que nunca terminam.
Veja como você pode melhorar os embaralhamentos:
reduceByKey() a groupByKey(): reduceByKey() agrega localmente antes de embaralhar. groupByKey() envia tudo pela rede..repartition(n) para aumentar o paralelismo ou .coalesce(n) para reduzi-lo. Não deixe que você dependa do particionamento padrão do Spark.spark.sql.autoBroadcastJoinThreshold para controlar o limite de tamanho.collect(): Evite isso sempre que possível, pois a transferência de dados para o driver prejudica o desempenho.Ajustar a memória do Spark pode ser uma ciência e tanto, mas você pode usar a lista de verificação abaixo para facilitar o processo:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.O ajuste da configuração da memória pode ajudar bastante. Certa vez, reduzi um trabalho de 30 minutos para 8 minutos adaptando a configuração da memória, sem alterar uma única linha de código.
Essa é a parte em que a maioria das equipes erra, pois adivinham o tamanho do cluster em vez de estimá-lo corretamente.
Mas você pode fazer melhor usando as fórmulas abaixo:
Por exemplo:
Mas lembre-se: Essa é apenas uma estimativa. Você pode usá-lo como ponto de partida e, em seguida, otimizar ainda mais por meio da criação de perfis.
O Spark já existe há uma década, mas continua bastante atualizado. Ele está evoluindo mais rápido do que nunca, graças às plataformas nativas da nuvem, à aceleração da GPU e à integração mais estreita do ML.
Se você usa o Spark hoje da mesma forma que usava há três anos, provavelmente está deixando o desempenho de lado e perdendo ótimos recursos novos.
Vamos dar uma olhada em alguns dos mais recentes.
Se você trabalha com a Databricks, provavelmente já trabalhou com o Photon e já ouviu falar dele.
Se você quiser saber mais sobre o Databricks, recomendo o curso Introduction to Databricks.
O Photon é o mecanismo de última geração da plataforma Databricks Lakehouse que oferece desempenho de consulta rápido a baixo custo. Ele é compatível com as APIs do Spark, portanto você não precisa adaptar seu código do Spark para usá-lo.
Ele ajuda a melhorar significativamente seu código SQL e PySpark.
O Photon inclui os seguintes recursos:
O sem servidor é fantástico, pois significa que você não precisa gerenciar clusters, pré-provisionar recursos e só paga pelo tempo em que o Spark estiver em execução.
E o serverless para o Spark já está disponível em serviços como o Databricks Serverless, o AWS Glue e o GCP Dataproc Serverless.
E aqui está o motivo pelo qual isso é incrível:
O Spark sem servidor é ideal para análises interativas, trabalhos ad-hoc ou cargas de trabalho imprevisíveis.
Mas tenha cuidado: pipelines consistentes e de longa duração ainda podem ser mais baratos em clusters fixos. Sempre meça o custo e a latência.
Se você está fazendo machine learning em escala e pretende colocar os modelos em produção, o Spark sozinho não é suficiente. Você precisa de princípios de MLOps, como rastreamento de experimentos, versão de modelos e reprodutibilidade. É aí que o MLflow se encaixa.
O MLflow agora se integra ao Spark e traz uma pilha completa de MLOPs para seus pipelines.
Você pode:
mlflow.log_param() e mlflow.log_metric().pyspark.ml ou sklearn diretamente no registro de modelos do MLflow.Você não precisa trocar de ferramenta. Você continua a usar o Spark para treinamento, engenharia de recursos e pontuação, enquanto utiliza o MLflow para tarefas de MLOPs.
Se você não sabe muito sobre o Spark, ele é como uma caixa preta gigante. Você escreve um pouco de código PySpark, pressiona run e espera que funcione.
Às vezes isso funcionava bem para mim, às vezes levava a longas sessões de depuração e a descobrir o que estava errado.
Foi só quando comecei a olhar os bastidores que as coisas fizeram sentido para mim. E demorou um bom tempo para que eu entendesse o que estava acontecendo.
Aqui está o que eu focaria se estivesse começando do zero novamente:
Foi exatamente isso que aprendemos neste artigo.
Se você quiser continuar aprendendo, aqui estão alguns recursos para iniciantes que eu recomendo:
Saiba mais sobre o Spark com estes cursos!
Curso
Curso
Curso
blog
Moez Ali
11 min
blog
Matt Crabtree
9 min
blog
Yuliya Melnik
15 min
Tutorial
Natassha Selvaraj
Tutorial
Tim Lu
Tutorial
Zoumana Keita


