
Kurs
PySpark ile Machine Learning
4 sa
29.7K
Hiç aniden başarısız olan bir Spark işini hata ayıklamaya çalışıp, Spark tavşan deliğinin ne kadar derin olduğunu fark ederek tamamen kaybolduğunuz oldu mu?
İlk kez Apache Spark ile çalıştığımda, birkaç PySpark dönüşümü yazmam gerektiğini ve Spark’ın kümeye “büyülü” bir şekilde ölçekleneceğini düşündüm. Yanılmışım. Spark’ın performansı, perde arkasında neler olduğunun anlaşılmasına tamamen bağlıdır.
Bu rehber, Spark’ı bir kara kutu gibi görmek istemeyen herkes için. Spark’ın mimarisinin nasıl tasarlandığını; ana-işçi modelinden yürütme iş akışına, bellek yönetiminden hata toleransı mekanizmalarına kadar adım adım inceleyeceğiz.
Hızlı, hataya dayanıklı ve verimli büyük veri uygulamaları geliştirmek istiyorsanız doğru yerdesiniz!
İlk PySpark satırınızı yazmadan önce bile Spark sizin için bazı mimari kararlar almış olur. Spark yalnızca bellek içi hesaplama sayesinde hızlı değildir; aynı zamanda, düğüm çöküşleri, Java Virtual Machine (JVM) sorunları ve tutarsız veri hacimleri gibi gerçek dünya kaosuna dayanabilen, ölçeklenen bir ana-işçi mimarisi üzerine kuruludur.
Spark’ın çekirdek mimarisini ve modern büyük veri iş akışlarında neden hâlâ bu kadar güçlü ve yaygın olduğunu parçalayalım.
Spark’ın merkezinde ana-işçi modeli vardır. Şöyle düşünün:
main() fonksiyonunuzu çalıştırır, Spark bağlamını oluşturur, DAG zamanlamasını yönetir ve kümeye ne yapacağını söyler.Bu kurulum sayesinde dönüşümleri tanımlamaya odaklanırsınız; Spark ise bunları yürütücüler üzerinde paralel olarak nerede ve nasıl çalıştıracağını belirler.
Bu tasarımda sevdiğim şeylerden biri, dağıtımdan bağımsız olmasıdır. Aynı kod, yerel makinenizde, Kubernetes ya da Mesos üzerinde dağıtmanızdan bağımsız olarak çalışır. Bu da yerelde geliştirme ve test etmeyi kolaylaştırır, ardından kodunuzu yeniden yazmadan kümelere ölçeklemenize imkân tanır.
Spark’ın sürücü-işçi ayrımının bir diğer güçlü faydası: Hata yalıtımını iyileştirir. Bir işçi düğümü bir görevi yürütürken ölürse, Spark uygulamanızı çökertmeden o görevi başka bir işçiye yeniden atayabilir.
Sürücüde ve düğümlerde neler olduğuna bakalım.
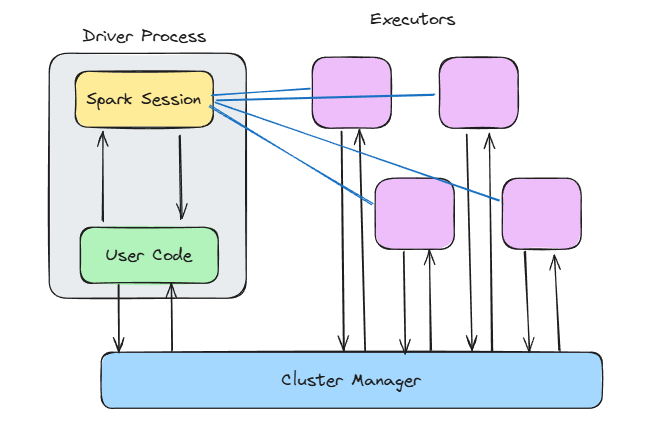
Spark mimarisi. Görsel: yazar.
SparkContext() çağırdığınızda veya SparkSession.builder.getOrCreate() kullandığınızda, Spark’ın tüm iç sihrine açılan kapıyı aralarsınız.
Spark bağlamı şunları yapar:
Spark, perde arkasında bir Yönlendirilmiş Çevrimsiz Grafik (DAG) oluşturur. Bu DAG, aşamalara ve görevlere bölünür ve ardından paralel olarak yürütülür.
DAG zamanlayıcı, hangi görevlerin birlikte çalıştırılabileceğini bulur; Görev zamanlayıcı ise bunları yürütücülere atar. Bu sırada Blok yöneticisi, verinin gerektiğinde önbelleğe alınmasını, shuffle edilmesini veya yeniden yüklenmesini sağlar.
Bu katmanlı tasarım, belleği, depolamayı ve hesaplamayı bağımsız olarak ince ayar yapabilmenizi sağlayarak Spark’ı inanılmaz esnek kılar.
Spark dönüşümleri veya özellik mühendisliği ile çalışıyorsanız, bu mimariyi iş başında görmek için PySpark ile Özellik Mühendisliği kursuna göz atın.
İşin yapıldığı yer yürütücülerdir.
Her yürütücü şunları çalıştırır:
Her yürütücünün ne kadar bellek alacağını, kaç çekirdek kullanacağını ve bellek tükendiğinde diske yazıp yazmayacağını yapılandırabilirsiniz.
Ancak dikkatli olun: Yeterince bellek ayırmazsanız sürekli bellek yetersiz hataları alırsınız. Öte yandan çok fazla bellek ayırmak da kaynak israfıdır. İzleme ve ayarlama burada kritik önemdedir.
PySpark kodu yazmak oldukça basit hissettirir. Bir DataFrame’i filtrelersiniz, bir join yaparsınız, bir şeyleri toplarsınız ve çalıştırırsınız. Ancak o temiz API’nin arkasında Spark, işi birden fazla düğüme yayabilen bir yürütme motorunu sessizce ayağa kaldırır.
Perde arkasında neler olduğuna birlikte bakalım.
Çoğu Spark kullanıcısının başlangıçta fark etmediği şey şu: PySpark kodu yazdığınızda, hemen hiçbir şey çalışmıyor. Bir plan inşa ediyorsunuz ve Spark’ın Catalyst Optimize Edicisi bu planı alıp verimli bir yürütme stratejisine dönüştürüyor.
Dört aşamada çalışır:
Spark’ın Catalyst Optimize Edicisi. Görsel: Databricks.
Yani o .select(), .join() ve .groupBy() zinciri satır satır çalışmıyor. Analiz ediliyor, optimize ediliyor ve kümede hızlı çalışacak şekilde derleniyor.
En kullanışlı PySpark komutları için bir kopya kâğıdına ihtiyacınız varsa, şu PySpark Kopya Kâğıdına göz atın.
Plan tamamlandığında, işi DAG zamanlayıcı devralır.
İşi, shuffle sınırlarına göre aşamalara böler; burada Spark, sırayla ne olacağına ve paralel olarak neyin yürütülebileceğine karar verir.
İki ana aşama türü vardır:
groupBy() veya join() gibi geniş dönüşümlerin tetiklediği bir shuffle içerir. Veri bölümlenir ve ağ üzerinden gönderilir. Bu aşama türü, ResultStage’i hesaplamak için gereklidir.Öğrendiğim temel şeylerden biri shuffle’ları en aza indirmektir. Bir aşama bitmeden önce bir shuffle gerçekleşmek zorundadır ve pahalıdır. DAG’inizde nerede ortaya çıktıklarını ve shuffle sayısını azaltmak için kodunuzu daha fazla optimize edip edemeyeceğinizi anlamanız gerekir.
DAG zamanlayıcı tüm aşamaları oluşturduktan sonra, bunlar farklı yürütücüler üzerinde yürütülebilir.
Görev yürütme yaşam döngüsü kabaca şöyledir:
Kendi deneyimimden küçük bir ipucu: Spark işiniz daha önce iyi çalışırken bir anda takılı kalırsa, çoğunlukla çöp toplama veya shuffle getirme gecikmelerindendir. Kodunuzu her zaman kontrol edin ve bu konuları etkili şekilde optimize edebilmek için Spark mimarisini anladığınızdan emin olun.
Spark’ın bellek yönetimi oldukça karmaşık bir konudur ve anlamazsanız saatlerinizi hata ayıklamaya mal edebilir.
Bu yüzden Spark’ın kaputun altında belleği nasıl yönettiğine bakalım ki bunun farkında olun ve yavaş kod ya da bellek yetersiz hataları için saatler harcamaktan kaçının.
Spark 1.6’dan önce bellek, yürütme (shuffle ve join’ler için) ve depolama (önbellekleme için) arasında katı şekilde bölünmüştü. Spark 1.6 ile birleşik bellek modeli geldi ve bu değişti.
Birleşik bellek modelinde, bellek üç ana havuza ayrılır:
Spark bellek havuzu iki alt havuza daha ayrılır:
Bu esneklik, öngörülemeyen veri hacimleriyle Spark’ın daha esnek olmasını sağlar.
Ancak bu aynı zamanda, perde arkasında ne olduğunu bilmediğinizde biraz kontrol kaybı demektir. Örneğin, büyük bir DataFrame’i cache() ettiğinizde fakat aynı aşamada pahalı toplulaştırmalar da varsa, Spark shuffle için yer açmak adına önbelleğe aldığınız veriyi tahliye edebilir.
Spark’ın yığın dışı ve kolonar depolamasında Tungsten motoru devreye girer.
Tungsten, Spark’ın performansını iyileştiren birkaç optimizasyon getirmiştir:
Ve DataFrame’lerle çalışıyorsanız, bu optimizasyonları zaten perde arkasında kullanıyorsunuz. Bu yüzden insanları ham RDD’ler yerine DataFrame ve SQL API’lerine yönlendirmemin sebeplerinden biri de budur. Ek bir ayara gerek kalmadan Catalyst ve Tungsten’in tüm gücünden yararlanırsınız.
Veri temizleme hatlarıyla çalışıyorsanız, bunu PySpark ile Veri Temizleme kursunda uygulamalı olarak göreceksiniz.
Dağıtık sistemlerle çalışıyorsanız bir gerçeği bilirsiniz: Arızalanırlar. Düğümler çöker. Ağ hataları olur. Yürütücüler belleksiz kalır ve kapanır.
Ancak Spark, bu sorunları ele alacak şekilde inşa edilmiştir ve işlerinizin yine de başarıyla tamamlanmasını sağlar.
Hadi, bazı dengesizlikler oluşsa bile Spark’ın işlerinizi nasıl başarıyla tamamladığını daha derinlemesine inceleyelim.
Dayanıklı Dağıtılmış Veri Kümeleri (RDD’ler), Spark’taki temel veri yapısıdır. Ve dayanıklı olarak anılmalarının bir nedeni vardır.
Spark, bir düğüm hatası ve veri kaybı durumunda her RDD’nin yeniden hesaplanabilmesini sağlamak için soyağacı bilgisini kullanır.
Yani bir düğüm başarısız olduğunda Spark, soyağacı grafiğini kullanarak kaybolan veriyi basitçe yeniden hesaplar.
Pratikte nasıl çalıştığı şöyledir:
map() veya filter()): Spark yalnızca kaybolan bölümü yeniden hesaplamak zorundadır.groupBy() veya join()): Birden çok bölümden veri almak gerekebilir; çünkü birden fazla aşamanın çıktısı gerekebilir. Soyağacı, hataları elle ele alma ihtiyacını ortadan kaldırır. Ancak soyağacı grafiğiniz çok uzarsa—yüzlerce dönüşüm içerebilir—kaybolan veriyi yeniden hesaplamak pahalı hâle gelir. İşte burada checkpointing devreye girer.
Karmaşık iş akışları veya akış (streaming) işleriyle karşılaştığınızda Spark yalnızca soyağaçına güvenemez. Burada checkpointing devreye girer.
rdd.checkpoint() çağırarak mevcut RDD durumunu güvenilir bir depolama konumuna (HDFS gibi) kalıcı hâle getirebilirsiniz.
Spark sonra soyağacını kısaltır. Bir hata olursa, yeniden hesaplamak yerine veriyi doğrudan yeniden yükler.
Yapılandırılmış akışta Spark, verinin aktarım sırasında kaybolmamasını sağlamak için write-ahead logları (WAL) da kullanır.
Onu bu kadar sağlam yapan da budur:
Batch işlemleri için checkpointing isteğe bağlıdır; ancak akış hatlarında zorunludur.
Düşünün ki bir Spark işiniz 10 saat çalıştıktan sonra başarısız oldu; ancak checkpointing ve WAL’lar sayesinde kaldığınız yerden devam edebiliyorsunuz.
Şimdiye kadar Spark’ın işleri nasıl işlediğini, bellek ve hataları nasıl ele aldığını gördünüz.
Bu bölümde, Spark’ı daha dinamik, daha gerçek zamanlı ve daha uyarlanabilir kılan bazı gelişmiş mimari yükseltmelere dalıyoruz.
AQE, Spark 3.0’da tanıtıldı ve yürütme sırasında toplanan istatistiklere dayanarak yürütme planlarını çalışma anında dinamik olarak ayarlayarak sorgu performansını artırır.
AQE’nin özellikleri şunlardır:
Bu özellik oyunun kurallarını değiştirir; çünkü önceden manuel ayar ve deneme-yanılma gerektiren işler, gerçek zamanlı uyum sağlayabilir.
Sadece yapılandırmadan açıkça etkinleştirdiğinizden emin olun (spark.sql.adaptive.enabled = true). Ve Spark 3.0+ kullanıyorsanız bunu kapalı tutmak için bir neden yok.
Structured Streaming, Spark’ın motorunu yeni bir API öğrenmenizi gerektirmeden gerçek zamanlı alana genişletir.
Perde arkasında hâlâ mikro-batch uygular. Ancak şunları ele alır:
Burada güçlü olan, akışın batch gibi hissettirmesidir. Bir groupBy() ya da filter() yazarsınız, Spark gerisini halleder; böylece uzmanlaşmış bir araç zincirine gerek kalmadan akış analitiği erişilebilir olur.
Spark’ı üretimde çalıştırıyorsanız—özellikle finans, sağlık veya benzeri alanlarda—Spark’ın kimlik doğrulama, şifreleme ve denetlenebilirliği nasıl ele aldığını bilmeniz gerekir.
Haydi bu konulara ve Spark’ın bunları nasıl sağladığına daha yakından bakalım.
Spark’ın önce etkinleştirmeniz gereken birçok güvenlik özelliği vardır. Fakat etkinleştirdikten sonra, güvenli iletişim ve kimlik doğrulama için sağlam bir araç seti sunar:
spark.acls.enable=true ve spark.ui.view.acls ile spark.ui.view.acls.groups ayarlarını yapılandırarak erişimi kısıtlayın.Tüm güvenlik özelliklerini Spark’ın resmî dokümantasyonunda inceleyebilirsiniz. Göz atın ve Spark uygulamalarınızı güvenceye almak için ihtiyaç duyduğunuz özellikleri etkinleştirdiğinizden emin olun.
Kimin neyi ne zaman yaptığını kaydetmek de kritik önemdedir.
Spark şunları destekler:
spark.eventLog.enabled=true) Spark, her iş, aşama ve görev olayını diske kaydeder. Bu logları iş geçmişini yeniden oynatmak veya denetim gerekliliklerini karşılamak için kullanabilirsiniz.Spark oldukça güçlü ve hızlıdır; nerede gerekli ayarları yapacağınızı bilirseniz daha da hızlandırılabilir.
Spark’tan en iyi verimi almak için optimize etmeyi deneyebileceğiniz birkaç alan vardır. Gelin her birine daha yakından bakalım.
Spark’ın zayıf noktası varsa, o da shuffle’dır. Shuffle, verinin bölümler arasında taşınması gerektiğinde gerçekleşir; genellikle groupByKey(), distinct() veya join() gibi geniş dönüşümlerin ardından.
Shuffle’lar ters giderse devasa disk I/O, uzun çöp toplama duraklamaları veya asla bitmeyen eğik görevler yaşayabilirsiniz.
Shuffle’ları şöyle iyileştirebilirsiniz:
groupByKey() yerine reduceByKey(): reduceByKey() shuffle’dan önce yerelde toplar. groupByKey() her şeyi ağa gönderir..repartition(n) veya azaltmak için .coalesce(n) kullanın. Varsayılan bölümlemeyi Spark’a bırakmayın.spark.sql.autoBroadcastJoinThreshold ayarlayın.collect(): Mümkün olduğunca kaçının; veriyi sürücüye çekmek performansı öldürür.Spark’ın belleğini ayarlamak başlı başına bir bilim olabilir; ancak aşağıdaki kontrol listesini kullanarak işi kolaylaştırabilirsiniz:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction değerini artırın.Bellek yapılandırmasını ayarlamak ciddi fark yaratabilir. Bir keresinde tek satır kod değiştirmeden, yalnızca bellek yapılandırmasını uyarlayarak 30 dakikalık bir işi 8 dakikaya indirdim.
Ekiplerin çoğu bu kısmı yanlış yapar; çünkü doğru tahmin etmek yerine küme boyutunu kafadan atarlar.
Ancak aşağıdaki formülleri kullanarak daha iyisini yapabilirsiniz:
Örneğin:
Ama unutmayın: Bu yalnızca bir tahmindir. Bir başlangıç noktası olarak kullanın ve sonra profilleyerek daha fazla optimize edin.
Spark on yıldır hayatımızda; ancak hâlâ oldukça güncel. Bulut-yerel platformlar, GPU hızlandırma ve daha sıkı ML entegrasyonu sayesinde her zamankinden hızlı evriliyor.
Spark’ı bugün üç yıl önce kullandığınız gibi kullanıyorsanız, muhtemelen hem performans kaybediyor hem de harika yeni özellikleri kaçırıyorsunuz.
En yenilerine bir göz atalım.
Databricks ile çalışıyorsanız muhtemelen Photon ile çalıştınız ve duydunuz.
Databricks hakkında daha fazla bilgi edinmek isterseniz Introduction to Databricks kursunu öneririm.
Photon, Databricks Lakehouse platformunda düşük maliyetle hızlı sorgu performansı sunan yeni nesil motordur. Spark API’leriyle uyumludur; dolayısıyla ondan yararlanmak için Spark kodunuzu uyarlamanız gerekmez.
SQL ve PySpark kodunuzu önemli ölçüde hızlandırmaya yardımcı olur.
Photon şu özellikleri içerir:
Sunucusuz harikadır; çünkü kümeleri yönetmek, kaynakları önceden sağlamak zorunda kalmazsınız ve yalnızca Spark çalıştığı süre için ödeme yaparsınız.
Ve Spark için sunucusuz yaklaşım Databricks Serverless, AWS Glue ve GCP Dataproc Serverless gibi servislerde hâlihazırda mevcuttur.
Ve işte neden etkileyici olduğuna dair birkaç nokta:
Sunucusuz Spark, etkileşimli analitik, ad-hoc işler veya öngörülemeyen iş yükleri için idealdir.
Ancak dikkat: Uzun süreli, tutarlı hatlar sabit kümelerde hâlâ daha ucuz olabilir. Hem maliyeti hem gecikmeyi mutlaka ölçün.
Endüstri dönüşürken veri mühendisliği ile yapay zekâ arasındaki çizgi bulanıklaşıyor. DataFramed podcastte Azurelib Academy’nin CEO’su & Kurucusu Deepak Goyal’ın da incelediği gibi
Veri mühendisliği, yakında gerçekleşecek yapay zekâ dönüşümünde hayati ve temel bir rol oynayacak.
Deepak Goyal, CEO & Founder at Azurelib Academy
Bu kurslarla Spark hakkında daha fazla bilgi edinin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
