
Curso
Machine learning con PySpark
4 h
29.7K
¿Has intentado alguna vez depurar un trabajo de Spark que ha fallado de repente y te has dado cuenta de que estás completamente perdido debido a lo profundo que llega la madriguera del conejo de Spark?
Cuando trabajé por primera vez con Apache Spark, pensé que sólo tenía que escribir unas cuantas transformaciones PySpark y Spark escalaría "mágicamente" a través del clúster. Me equivoqué. El rendimiento de Spark depende por completo de comprender lo que ocurre entre bastidores.
Esta guía es para cualquiera que no quiera tratar a Spark como una caja negra. Repasaremos cómo está diseñada la arquitectura de Spark, desde el modelo de trabajador maestro y el flujo de trabajo de ejecución, hasta sus mecanismos de gestión de memoria y tolerancia a fallos.
Si quieres crear aplicaciones de big data rápidas, tolerantes a fallos y eficientes, ¡estás en el lugar adecuado!
Antes de que escribas tu primera línea en PySpark, Spark ya ha tomado algunas decisiones arquitectónicas por ti. Spark no sólo es rápido gracias a la computación en memoria, sino porque está construido sobre una arquitectura de trabajador maestro que escala y sobrevive al caos del mundo real, como las caídas de nodoshes, los problemas de la Máquina Virtual Java (JVM) y los volúmenes de datos inconsistentes.
Desglosemos la arquitectura central de Spark y por qué sigue siendo tan potente y está tan presente en los flujos de trabajo modernos de big data.
En el núcleo de Spark está el modelo de maestro-trabajador . Piénsalo así:
main(), crea el contexto Spark, gestiona la programación del DAG y le dice al clúster lo que tiene que hacer.Esta configuración te permite concentrarte en definir las transformaciones, y Spark decide dónde y cómo ejecutarlas en paralelo en los ejecutores.
Lo que me gusta de este diseño es que es independiente del despliegue. El mismo código se ejecuta, independientemente de que lo despliegues en tu máquina local, en Kubernetes o en Mesos. Esto hace que sea fácil desarrollarlo y probarlo localmente, y luego escalarlo a clusters sin reescribir tu código.
Y he aquí otra poderosa ventaja de la separación conductor-trabajador de Spark: Mejora el aislamiento de fallos. Si un nodo trabajador muere mientras ejecuta una tarea, Spark puede reasignar esa tarea a otro trabajador sin bloquear tu aplicación.
Vamos a desglosar lo que ocurre dentro del controlador y los nodos.
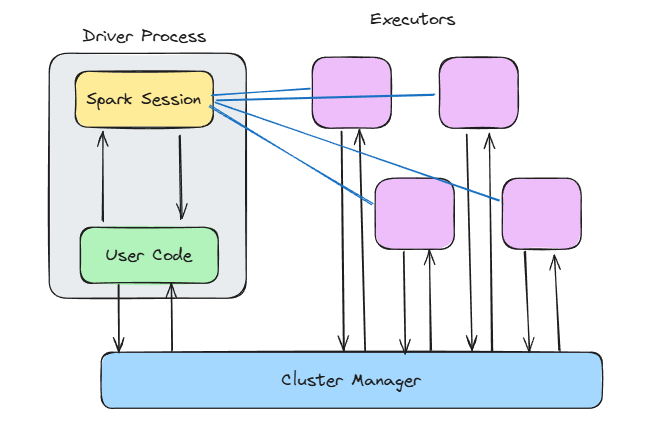
Arquitectura Spark. Imagen del autor.
Cuando llamas a SparkContext() o utilizas SparkSession.builder.getOrCreate(), estás abriendo la puerta a toda la magia interna de Spark.
El contexto Spark:
Spark construye un grafo acíclico dirigido (DAG) de transformaciones entre bastidores. Ese DAG se descompone en etapas y tareas, y luego se ejecuta en paralelo.
El programador de DAG averigua qué tareas pueden ejecutarse juntas, y el programador de Tareas las asigna a los ejecutores. Mientras tanto, el Gestor de Bloques garantiza que los datos se almacenen en caché, se barajen o se recarguen según sea necesario.
Este diseño en capas hace que Spark sea increíblemente flexible, ya que puedes ajustar la memoria, el almacenamiento y el cálculo de forma independiente.
Si trabajas con transformaciones Spark o ingeniería de características, consulta el curso Ingeniería de características con PySpark para ver esta arquitectura en acción.
Los ejecutores están donde se hace el trabajo.
Cada ejecutor se ejecuta:
Puedes configurar cuánta memoria obtiene cada ejecutor, cuántos núcleos utiliza y si debe escribir en disco cuando se agote la memoria.
Pero, ten cuidado: Si no asignas suficiente memoria, te encontrarás continuamente con errores de falta de memoria. Sin embargo, también debes evitar asignar demasiada memoria, ya que esto desperdicia recursos. La supervisión y el ajuste son esenciales en este caso.
Escribir código PySpark es bastante sencillo. Filtras un DataFrame, haces una unión, agregas algo y le das a ejecutar. Pero detrás de esa limpia API, Spark está poniendo en marcha silenciosamente un motor de ejecución que puede repartir el trabajo entre varios nodos.
Veamos qué ocurre entre bastidores.
Esto es de lo que la mayoría de los usuarios de Spark no se dan cuenta al principio: Cuando escribes código PySpark, no estás ejecutando nada inmediatamente. Estás construyendo un plan, y el Optimizador de Catalizadores de Spark toma ese plan y lo transforma en una estrategia de ejecución eficiente.
Funciona en cuatro fases:
Optimizador de catalizadores de Spark. Imagen de Databricks.
Así que esa cadena de .select(), .join(), y .groupBy() no se ejecuta simplemente línea a línea. Se analiza, se optimiza y se compila en algo que se ejecuta rápidamente en un clúster.
Echa un vistazo a esta Hoja de Trucos de PySpark si quieres una hoja de trucos con los comandos más útiles de PySpark.
Cuando termina el plan, el programador DAG toma el relevo.
Divide el trabajo en etapas basadas en los límites de barajado, donde Spark decide qué ocurre secuencialmente y qué puede ejecutarse en paralelo.
Hay dos tipos principales de etapas:
groupBy() o join(). A continuación, los datos se dividen y se envían a través de la red. Este tipo de etapa es necesario para calcular la EtapaResultado.Una cosa clave que he aprendido es a minimizar los barajados. Una barajada tiene que tener lugar antes de que termine una etapa y es costosa. Tienes que saber dónde se producen en tu DAG y si puedes optimizar más tu código para reducir el número de barajadas.
Una vez que el programador DAG ha creado todas las etapas, pueden ejecutarse en los distintos ejecutores.
El ciclo de vida de la ejecución de la tarea tiene este aspecto:
Una pequeña pista por experiencia propia: si tu trabajo Spark se bloquea después de haber funcionado bien antes, a menudo se debe a retrasos en la recogida de basura o en la obtención aleatoria. Comprueba siempre tu código y asegúrate de que entiendes la arquitectura de Spark para poder optimizar estos temas de forma eficaz.
La gestión de la memoria de Spark es un tema muy complejo y puede costarte horas de depuración si no lo entiendes.
Por lo tanto, echemos un vistazo a cómo Spark gestiona la memoria bajo el capó para que seas consciente de ello y puedas evitar horas de depuración de código lento o errores de falta de memoria.
Antes de Spark 1.6, la memoria se dividía estrictamente entre ejecución (para mezclas y uniones) y almacenamiento (para caché). Eso cambió con Spark 1.6, que introdujo el modelo de memoria unificada.
En el modelo de memoria unificada, los datos se dividen en tres pools clave:
El pool de memoria de Spark se divide a su vez en dos pools:
Esta elasticidad permite a Spark ser más flexible con volúmenes de datos impredecibles.
Sin embargo, esto también significa perder un poco el control cuando no sabes lo que está pasando. Por ejemplo, si cache() un DataFrame grande pero también tiene agregaciones costosas en la misma etapa, Spark podría desalojar tus datos almacenados en caché para hacer sitio a la agregación.
En el almacenamiento fuera del montón y columnar de Spark, entra en juego el motor de Tungsteno.
Tungsteno introdujo varias optimizaciones que mejoraron el rendimiento de Spark:
Y si trabajas con DataFrames, ya estás utilizando estas optimizaciones bajo el capó. Esa es una de las razones por las que insisto en que la gente utilice DataFrames y APIs SQL en lugar de RDDs en bruto. Obtendrás toda la potencia de Catalizador y Tungsteno sin ningún ajuste adicional.
Si trabajas con pipelines de limpieza de datos, verás esto en acción en Limpieza de datos con PySpark.
Si trabajas con sistemas distribuidos, sabes una cosa a ciencia cierta: Fracasan. Los nodos se bloquean. Los errores de red ocurren. Los ejecutores se quedan sin memoria y se apagan.
Pero Spark está construido para manejar estos problemas y garantiza que tus trabajos sigan teniendo éxito.
Profundicemos en cómo Spark garantiza que tus trabajos sigan teniendo éxito, aunque se produzcan algunas inestabilidades.
Los Conjuntos de Datos Distribuidos Resistentes (RDD) son la estructura de datos fundamental en Spark. Y se llaman resistentes por una razón.
Spark utiliza el linaje para garantizar que cada RDD pueda volver a calcularse en caso de fallo de un nodo y pérdida de datos.
Así, cuando un nodo falla, Spark simplemente vuelve a calcular los datos perdidos utilizando el gráfico de linaje.
Así es como funciona en la práctica:
map() o filter()): Spark sólo necesita la partición perdida para volver a calcular.groupBy() o join()): Spark puede necesitar obtener datos de varias particiones, ya que puede necesitar la salida de varias etapas. Lineage evita la necesidad de gestionar los fallos manualmente. Sin embargo, si tu gráfico de linaje se hace demasiado largo, ya que puede contener cientos de transformaciones, volver a calcular los datos perdidos resulta caro. Ahí es donde entra en juego el punto de control.
Cuando te encuentres con flujos de trabajo complejos o trabajos de streaming, Spark no puede depender únicamente del linaje. Ahí es donde entra en juego el punto de control.
Puedes llamar a rdd.checkpoint() para persistir el estado actual del RDD en una ubicación de almacenamiento fiable (como HDFS).
A continuación, Spark trunca el linaje. Si se produce un error, recarga los datos directamente en lugar de volver a calcularlos.
En el streaming estructurado, Spark también utiliza registros de escritura anticipada (WAL) para garantizar que los datos no se pierdan en tránsito.
Esto es lo que la hace tan estable:
El punto de control es opcional para los trabajos de procesamiento por lotes, pero necesario para los procesos de flujo.
Supongamos que tienes un trabajo Spark que ha fallado después de 10 horas de ejecución, pero puedes reanudarlo donde lo dejaste, gracias a los puntos de control y a los WAL.
A estas alturas, ya has visto cómo Spark procesa los trabajos y gestiona la memoria y los fallos.
En esta sección, nos sumergiremos en algunas de las mejoras arquitectónicas avanzadas que hacen que Spark sea más dinámico, más en tiempo real y más adaptable.
AQE se introduce en Spark 3.0 y mejora el rendimiento de las consultas ajustando dinámicamente los planes de ejecución en tiempo de ejecución basándose en las estadísticas recopiladas durante la ejecución.
Entre las características de AQE se incluyen:
Esta función cambia las reglas del juego, ya que permite adaptar en tiempo real trabajos que antes requerían ajustes manuales y ensayo y error.
Sólo asegúrate de activarlo explícitamente a través de la configuración (spark.sql.adaptive.enabled = true). Y si utilizas Spark 3.0+, no hay razón para no hacerlo.
El Streaming Estructurado toma el motor de Spark y lo amplía al dominio del tiempo real, sin que tengas que aprender una API completamente nueva.
Entre bastidores, sigue aplicando la micromezcla. Pero se maneja:
Lo poderoso aquí es cómo el streaming se parece a la dosificación. Tú escribes un groupBy() o un filter() y Spark se encarga de todo lo demás, haciendo accesible el análisis de flujos sin una cadena de herramientas especializada.
Si estás ejecutando Spark en producción, especialmente en finanzas, sanidad o áreas de negocio similares, necesitas saber cómo gestiona Spark la autenticación, el cifrado y la auditabilidad.
Así que vamos a profundizar en estos temas y en cómo Spark se ocupa de ellos.
Spark tiene muchas funciones de seguridad que primero debes activar. Pero una vez activado, Spark ofrece una sólida caja de herramientas para la comunicación y la autenticación seguras:
spark.acls.enable=true y spark.ui.view.acls y spark.ui.view.acls.groups para restringirla.Puedes consultar todas las funciones de seguridad en la documentación oficial de Spark. Compruébalo y asegúrate de que activas las funciones que necesitas para proteger tus aplicaciones Spark.
También es fundamental registrar quién hizo qué y cuándo.
Compatible con Spark:
spark.eventLog.enabled=true), Spark graba en disco cada evento de trabajo, etapa y tarea. Puedes utilizar estos registros para reproducir el historial de trabajos o cumplir requisitos de auditoría.Spark es bastante potente y rápido, y se puede optimizar para que sea aún más rápido si sabes dónde hacer los ajustes necesarios.
Hay varias áreas en las que puedes intentar optimizar para sacar el máximo partido a Spark. Así que vamos a profundizar en cada área.
Si Spark tiene un punto débil, es la mezcla. Las barajadas se producen cuando hay que mover datos entre particiones, normalmente después de transformaciones amplias como groupByKey(), distinct(), o join().
Y cuando las mezclas van mal, puedes tener una E/S masiva del disco, largas pausas en la recogida de basura o tareas desviadas que nunca terminan.
He aquí cómo puedes mejorar las barajadas:
reduceByKey() a groupByKey(): reduceByKey() agrega localmente antes de barajar. groupByKey() envía todo por la red..repartition(n) para aumentar el paralelismo, o .coalesce(n) para reducirlo. No lo dejes en manos de la partición por defecto de Spark.spark.sql.autoBroadcastJoinThreshold para controlar el límite de tamaño.collect(): Evítalo siempre que sea posible, ya que llevar los datos al conductor mata el rendimiento.Ajustar la memoria de Spark puede ser toda una ciencia, pero puedes utilizar la siguiente lista de comprobación para hacerlo más fácil:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Ajustar la configuración de la memoria puede ayudar significativamente. Una vez reduje un trabajo de 30 minutos a 8 minutos adaptando la configuración de la memoria, sin cambiar una sola línea de código.
Esta es la parte en la que la mayoría de los equipos se equivocan, porque adivinan el tamaño del grupo en lugar de estimarlo correctamente.
Pero puedes hacerlo mejor utilizando las fórmulas siguientes:
Por ejemplo:
Pero recuerda: Esto es sólo una estimación. Puedes utilizarlo como punto de partida y luego optimizarlo aún más mediante la elaboración de perfiles.
Spark existe desde hace una década, pero sigue siendo bastante actual. Está evolucionando más rápido que nunca, gracias a las plataformas nativas de la nube, la aceleración de la GPU y una mayor integración del ML.
Si hoy utilizas Spark de la misma forma que hace tres años, probablemente estés dejando el rendimiento sobre la mesa y perdiéndote nuevas funciones geniales.
Veamos algunas de las más recientes.
Si trabajas con Databricks, probablemente ya hayas trabajado con Photon y hayas oído hablar de él.
Si quieres saber más sobre Databricks, te recomiendo el curso Introducción a Databricks.
Photon es el motor de nueva generación de la plataforma Lakehouse de Databricks que proporciona un rendimiento de consulta rápido a bajo coste. Es compatible con las API de Spark, por lo que no necesitas adaptar tu código Spark para utilizarlo.
Ayuda a potenciar significativamente tu código SQL y PySpark.
Photon incluye las siguientes funciones:
Sin servidor es fantástico, ya que significa que no tienes que gestionar clusters, preaprovisionar recursos, y sólo pagas por el tiempo que Spark está funcionando.
Y los servicios sin servidor para Spark ya están en marcha, como Databricks Serverless, AWS Glue y GCP Dataproc Serverless.
Y he aquí por qué es increíble:
Spark sin servidor es ideal para análisis interactivos, trabajos ad hoc o cargas de trabajo impredecibles.
Pero ten cuidado: los pipelines consistentes y de larga duración pueden seguir siendo más baratos en clusters fijos. Mide siempre tanto el coste como la latencia.
Si estás haciendo machine learning a escala y tu objetivo es llevar los modelos a producción, Spark por sí solo no es suficiente. Necesitas principios MLOps, como el seguimiento de experimentos, el versionado de modelos y la reproducibilidad. Ahí es donde encaja MLflow.
MLflow se integra ahora con Spark y aporta una pila completa de MLOPs a tus pipelines.
Puedes hacerlo:
mlflow.log_param() y mlflow.log_metric().pyspark.ml o sklearn directamente en el registro de modelos de MLflow.No necesitas cambiar de herramienta. Sigues utilizando Spark para el entrenamiento, la ingeniería de características y la puntuación, mientras utilizas MLflow para las tareas MLOPs.
Si no sabes mucho sobre Spark, es como una gigantesca caja negra. Escribes algo de código PySpark, le das a ejecutar y esperas que funcione.
A veces me funcionaba bien, otras me llevaba a largas sesiones de depuración y de averiguar qué fallaba.
No fue hasta que empecé a mirar entre bastidores que las cosas cobraron sentido para mí. Y tardé bastante en entender lo que pasaba.
Esto es en lo que me centraría si volviera a empezar de cero:
Eso es precisamente lo que hemos aprendido en este artículo.
Si quieres seguir aprendiendo, aquí tienes algunos recursos para principiantes que te recomiendo:
¡Aprende más sobre Spark con estos cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
Tutorial
Natassha Selvaraj
Tutorial
Olivia Smith
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Tim Lu
