
Course
Machine Learning with PySpark
4 hr
29.7K
Have you ever tried to debug a Spark job that suddenly failed and figured out that you are completely lost because of how deep the Spark rabbit hole goes?
When I first worked with Apache Spark, I thought I just had to write a few PySpark transformations and Spark would “magically” scale across the cluster. I was wrong. Spark's performance depends entirely on understanding what’s happening behind the scenes.
This guide is for anyone who doesn’t want to treat Spark like a black box. We’ll walk through how Spark’s architecture is designed, from the master-worker model and execution workflow, to its memory management and fault tolerance mechanisms.
If you want to build fast, fault-tolerant, and efficient big data applications, you’re in the right place!
Before you write your first line of PySpark, Spark has already made some architectural decisions for you. Spark isn’t just fast because of in-memory computing, but because it’s built on a master-worker architecture that scales and survives real-world chaos like node crashes, Java Virtual Machine (JVM) issues, and inconsistent data volumes.
Let’s break down Spark’s core architecture and why it’s still so powerful and present in modern big data workflows.
At the core of Spark is the master-worker model. Think of it like this:
main() function, creates the Spark context, handles DAG scheduling, and tells the cluster what to do.This setup allows you to concentrate on defining transformations, and Spark decides where and how to run them in parallel on the executors.
What I like about this design is that it’s deployment-agnostic. The same code runs, independent of deploying it on your local machine, in Kubernetes or Mesos. That makes it easy to develop and test it locally, then scale to clusters without rewriting your code.
And here is another powerful benefit of Spark’s driver-worker separation: It improves fault isolation. If a worker node dies while executing a task, Spark can reassign that task to another worker without crashing your application.
Let’s break down what’s happening inside the driver and the nodes.
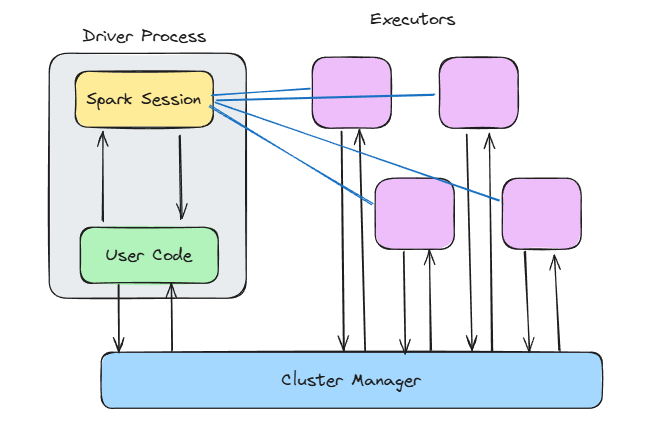
Spark architecture. Image by author.
When you call SparkContext() or use SparkSession.builder.getOrCreate(), you’re opening the gateway to all of Spark’s internal magic.
The Spark context:
Spark builds a Directed Acyclic Graph (DAG) of transformations behind the scenes. That DAG gets broken down into stages and tasks, then executed in parallel.
The DAG scheduler figures out which tasks can be run together, and the Task scheduler assigns them to executors. Meanwhile, the Block manager ensures data is cached, shuffled, or reloaded as needed.
This layered design makes Spark incredibly flexible, as you can fine-tune memory, storage, and compute independently.
If you're working with Spark transformations or feature engineering, check out the Feature Engineering with PySpark course to see this architecture in action.
Executors are where the work gets done.
Each executor runs:
You can configure how much memory each executor gets, how many cores it uses, and whether it should write to disk when memory runs out.
But, be careful: If you don’t allocate enough memory, you’ll hit out-of-memory errors all the time. However, you should also avoid allocating too much memory, as this wastes resources. Monitoring and tuning are essential here.
Writing PySpark code feels quite simple. You filter a DataFrame, do a join, aggregate something, and hit run. But behind that clean API, Spark is quietly spinning up an execution engine that can spread work across several nodes.
Let’s walk through what happens behind the scenes.
Here’s what most Spark users don’t realize at first: When you write PySpark code, you’re not running anything immediately. You’re building a plan, and Spark’s Catalyst Optimizer takes that plan and transforms it into an efficient execution strategy.
It works in four phases:
Spark’s Catalyst Optimizer. Image by Databricks.
So that chain of .select(), .join(), and .groupBy() is not just running line by line. It’s getting analyzed, optimized, and compiled into something that runs fast on a cluster.
Check out this PySpark Cheat Sheet if you want a cheat sheet for the most useful PySpark commands.
When the plan is finished, the DAG scheduler takes over.
It breaks the job down into stages based on shuffle boundaries, where Spark decides what happens sequentially and what can be executed in parallel.
There are two main types of stages:
groupBy() or join(). The data is then partitioned and sent across the network. This stage type is required to compute the ResultStage.One key thing I’ve learned is to minimize shuffles. A shuffle has to take place before a stage finishes and is expensive. You need to understand where they occur in your DAG and whether you can optimize your code further to reduce the number of shuffles.
Once the DAG scheduler has created all stages, they can be executed on the different executors.
The task execution lifecycle looks something like this:
A slight hint from my own experience: if your Spark job hangs after running fine before, it’s often because of garbage collection or shuffle fetch delays. Always check your code and ensure that you understand Spark’s architecture so that you can optimize these topics effectively.
Spark’s memory management is a very complex topic and can cost you hours of debugging if you don’t understand it.
Let’s therefore take a look at how Spark manages memory under the hood so that you are aware of it and can avoid hours of debugging slow code or out-of-memory errors.
Before Spark 1.6, memory was strictly divided between execution (for shuffles and joins) and storage (for caching). That changed with Spark 1.6, introducing the unified memory model.
In the unified memory model, data is split into three key pools:
The Spark memory pool is further divided into two pools:
This elasticity allows Spark to be more flexible with unpredictable data volumes.
However, this also means losing a bit of control when you don’t know what's going on. For example, if you cache() a large DataFrame but also have expensive aggregations in the same stage, Spark might evict your cached data to make room for the shuffle.
In Spark’s off-heap and columnar storage, the Tungsten engine comes into play.
Tungsten introduced several optimizations that improved Spark's performance:
And if you're working with DataFrames, you’re already using these optimizations under the hood. That’s one of the reasons I push people to use DataFrames and SQL APIs over raw RDDs. You get the full power of Catalyst and Tungsten without any extra tuning.
If you're working with data cleaning pipelines, you'll see this in action in Cleaning Data with PySpark.
If you work with distributed systems, you know one thing for a fact: They fail. Nodes crash. Network errors happen. Executors run out of memory and shut down.
But Spark is built to handle these issues and ensures that your jobs still succeed.
Let’s dive deeper into how Spark ensures that your jobs still succeed, even if some instabilities occur.
Resilient Distributed Datasets (RDDs) are the fundamental data structure in Spark. And they are called resilient for a reason.
Spark uses lineage to ensure that each RDD can be recomputed in the event of a node failure and data loss.
So when a node fails, Spark simply recomputes the lost data using the lineage graph.
Here is how it works in practice:
map() or filter()): Spark only needs the lost partition to recompute.groupBy() or join()): Spark may need to fetch data across multiple partitions, as it may require the output of several stages. Lineage avoids the need to handle failures manually. However, if your lineage graph becomes too long, as it may contain hundreds of transformations, recomputing lost data becomes expensive. That’s where checkpointing comes into play.
When you encounter complex workflows or streaming jobs, Spark cannot depend solely on lineage. That’s where checkpointing comes into play.
You can call rdd.checkpoint() to persist the current RDD state to a reliable storage location (like HDFS).
Spark then truncates the lineage. If an error occurs, it reloads the data directly instead of recomputing it.
In structured streaming, Spark also uses write-ahead logs (WALs) to ensure data isn’t lost in transit.
This is what makes it so stable:
Checkpointing is optional for batch processing jobs, but required for streaming pipelines.
Assume you had a Spark job that failed after running 10 hours, but you can resume where you left off, thanks to checkpointing and WALs.
By now, you’ve seen how Spark processes jobs and handles memory and failure.
In this section, we’re diving into some of the advanced architectural upgrades that make Spark more dynamic, more real-time, and more adaptable.
AQE is introduced in Spark 3.0 and enhances query performance by dynamically adjusting execution plans at runtime based on statistics collected during execution.
Features of AQE include:
This feature is a game-changer, as it enables jobs that previously required manual tuning and trial-and-error to adapt in real-time.
Just make sure to enable it explicitly via the configuration (spark.sql.adaptive.enabled = true). And if you’re running on Spark 3.0+, there’s no reason not to.
Structured Streaming takes Spark’s engine and extends it into the real-time domain, without requiring you to learn a whole new API.
Behind the scenes, it still applies micro-batching. But it handles:
What’s powerful here is how streaming feels like batching. You write a groupBy() or a filter() and Spark handles everything else, making streaming analytics accessible without a specialized toolchain.
If you’re running Spark in production, especially in finance, healthcare, or similar business areas, you need to know how Spark handles authentication, encryption, and auditability.
So let’s dive deeper into these topics and how Spark takes care of them.
Spark has many security features that you must first enable. But once enabled, Spark offers a solid toolbox for secure communication and authentication:
spark.acls.enable=true and spark.ui.view.acls and spark.ui.view.acls.groups to restrict it.You can check all security features in the official documentation of Spark. Check it out and ensure that you enable the features you need to secure your Spark applications.
Logging who did what and when is also critical.
Spark supports:
spark.eventLog.enabled=true), Spark records every job, stage, and task event to disk. You can use these logs to replay job history or meet audit requirements.Spark is quite powerful and fast, and it can be optimized to be even faster if you know where to make the necessary adjustments.
There are several areas where you can try to optimize to get the most out of Spark. So let’s dive deeper into each area.
If Spark has a weak point, it's the shuffle. Shuffles happen when data needs to be moved between partitions, typically after wide transformations like groupByKey(), distinct(), or join().
And when shuffles go wrong, you can get massive disk I/O, long garbage collection pauses, or skewed tasks that never finish.
Here’s how you can improve shuffles:
reduceByKey() over groupByKey(): reduceByKey() aggregates locally before shuffling. groupByKey() sends everything over the network..repartition(n) to increase parallelism, or .coalesce(n) to reduce it. Don’t leave it up to Spark’s default partitioning.spark.sql.autoBroadcastJoinThreshold to control the size limit.collect(): Avoid it when possible, as pulling data to the driver kills performance.Tuning Spark’s memory can be quite a science, but you can use the checklist below to make it easier:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction value.Adjusting the memory configuration can help significantly. I once reduced a 30-minute job to 8 minutes by adapting the memory configuration, without changing a single line of code.
This is the part most teams get wrong, because they guess the cluster size instead of estimating it correctly.
But you can do better by using the formulas below:
For example:
But remember: This is only an estimate. You can use it as a starting point and then further optimize through profiling.
Spark has been around for a decade, but it remains quite up to date. It’s evolving faster than ever, thanks to cloud-native platforms, GPU acceleration, and tighter ML integration.
If you’re using Spark today the same way you did three years ago, you’re probably leaving performance on the table and missing out on great new features.
Let’s take a look at some of the newest ones.
If you work with Databricks, you’ve probably already worked with and heard of Photon.
If you want to learn more about Databricks, I recommend the Introduction to Databricks course.
Photon is the next-generation engine on the Databricks Lakehouse platform that provides speedy query performance at low cost. It is compatible with Spark APIs, so you don’t need to adapt your Spark code to make use of it.
It helps to significantly boost your SQL and PySpark code.
Photon includes the following features:
Serverless is fantastic, as it means you don’t have to manage clusters, pre-provision resources, and you only pay for the time Spark is running.
And serverless for Spark is already live in services like Databricks Serverless, AWS Glue, and GCP Dataproc Serverless.
And here’s why it is incredible:
Serverless Spark is ideal for interactive analytics, ad-hoc jobs, or unpredictable workloads.
But be careful: long-running, consistent pipelines may still be cheaper on fixed clusters. Always measure both cost and latency.
As the industry shifts, the line between data engineering and AI is blurring. As Deepak Goyal, CEO & Founder at Azurelib Academy, explored on the DataFramed podcast
Data engineering is going to play a vital and fundamental role in the upcoming shift to AI.
Deepak Goyal, CEO & Founder at Azurelib Academy
Learn more about Spark with these courses!
Course
Course
Course
blog
Ashlyn Brooks
10 min
blog
Bex Tuychiev
cheat-sheet
Karlijn Willems
cheat-sheet
Karlijn Willems
Tutorial
Karlijn Willems
Tutorial
Laiba Siddiqui

