
Kurs
Maschinelles Lernen mit PySpark
4 Std.
29.7K
Hast du schon einmal versucht, einen Spark-Job zu debuggen, der plötzlich fehlgeschlagen ist, und festgestellt, dass du völlig verloren bist, weil der Spark-Kaninchenbau so tief geht?
Als ich zum ersten Mal mit Apache Spark gearbeitet habe, dachte ich, ich müsste nur ein paar PySpark-Transformationen schreiben und Spark würde auf "magische Weise" über den Cluster skalieren. Ich habe mich geirrt. Die Leistung von Spark hängt ganz davon ab, dass du verstehst, was hinter den Kulissen passiert.
Dieser Leitfaden ist für alle, die Spark nicht wie eine Blackbox behandeln wollen. Wir gehen die Architektur von Spark durch, vom Master-Worker-Modell und dem Ausführungsworkflow bis hin zur Speicherverwaltung und den Fehlertoleranzmechanismen.
Wenn du schnelle, fehlertolerante und effiziente Big-Data-Anwendungen erstellen willst, bist du hier genau richtig!
Bevor du deine erste Zeile in PySpark schreibst, hat Spark bereits einige Architekturentscheidungen für dich getroffen. Spark ist nicht nur wegen des In-Memory-Computings schnell, sondern auch, weil es auf einer Master-Worker-Architektur basiert, die skalierbar ist und Chaos wie Knotenabstürzehes, Probleme mit der Java Virtual Machine (JVM) und inkonsistente Datenmengen übersteht.
Schauen wir uns die Kernarchitektur von Spark an und warum es in modernen Big-Data-Workflows immer noch so leistungsstark und präsent ist.
Das Herzstück von Spark ist das Master-Worker-Modell . Stell dir das folgendermaßen vor:
main() Funktion aus, erstellt den Spark-Kontext, kümmert sich um die DAG-Planung und sagt dem Cluster, was er tun soll.So kannst du dich auf die Definition der Transformationen konzentrieren, und Spark entscheidet, wo und wie sie parallel auf den Executors ausgeführt werden.
Was mir an diesem Design gefällt, ist, dass es einsatzunabhängig ist. Derselbe Code läuft, unabhängig davon, ob du ihn auf deinem lokalen Rechner, in Kubernetes oder Mesos einsetzt. Das macht es einfach, sie lokal zu entwickeln und zu testen und dann auf Cluster zu skalieren, ohne deinen Code neu zu schreiben.
Und hier zeigt sich ein weiterer großer Vorteil der Trennung von Fahrer und Arbeiter bei Spark: Sie verbessert die Fehlerisolierung. Wenn ein Worker-Knoten während der Ausführung einer Aufgabe stirbt, kann Spark diese Aufgabe einem anderen Worker zuweisen, ohne dass deine Anwendung abstürzt.
Schauen wir uns an, was innerhalb des Treibers und der Knotenpunkte passiert.
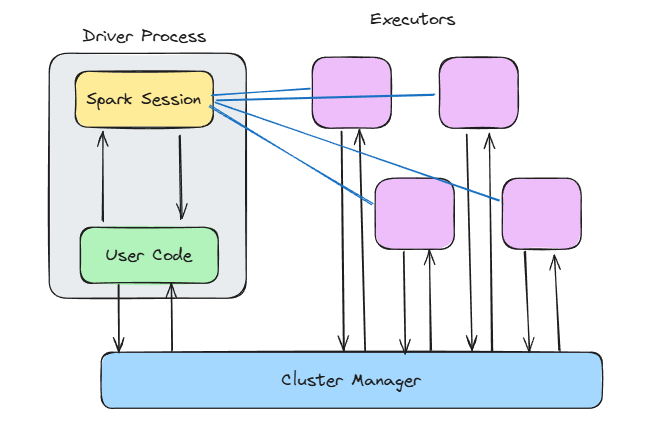
Spark-Architektur. Bild vom Autor.
Wenn du SparkContext() aufrufst oder SparkSession.builder.getOrCreate() verwendest, öffnest du das Tor zu allen internen Zaubereien von Spark.
Der Spark-Kontext:
Spark erstellt im Hintergrund einen gerichteten azyklischen Graphen (DAG) von Transformationen. Diese DAG wird in Phasen und Aufgaben unterteilt und dann parallel ausgeführt.
Der DAG-Scheduler findet heraus, welche Aufgaben zusammen ausgeführt werden können, und der Task-Scheduler weist sie den Ausführenden zu. In der Zwischenzeit sorgt der Blockmanager dafür, dass die Daten je nach Bedarf zwischengespeichert, umgeschichtet oder neu geladen werden.
Dieses mehrschichtige Design macht Spark unglaublich flexibel, da du Arbeitsspeicher, Speicher und Rechenleistung unabhängig voneinander feinabstimmen kannst.
Wenn du mit Spark-Transformationen oder Feature Engineering arbeitest, solltest du dir den Kurs Feature Engineering mit PySpark ansehen, um diese Architektur in Aktion zu erleben.
Die Ausführenden sind der Ort, an dem die Arbeit erledigt wird.
Jeder Executor läuft:
Du kannst konfigurieren, wie viel Arbeitsspeicher jeder Executor bekommt, wie viele Kerne er verwendet und ob er auf die Festplatte schreiben soll, wenn der Speicher knapp wird.
Aber sei vorsichtig: Wenn du nicht genug Arbeitsspeicher zuweist, bekommst du ständig Out-of-Memory-Fehler. Allerdings solltest du auch vermeiden, zu viel Speicher zuzuweisen, da dies Ressourcen verschwendet. Überwachung und Optimierung sind hier unerlässlich.
Das Schreiben von PySpark-Code fühlt sich ganz einfach an. Du filterst einen DataFrame, führst einen Join durch, aggregierst etwas und drückst auf "Run". Aber hinter dieser sauberen API entwickelt Spark im Stillen eine Ausführungsmaschine, die die Arbeit auf mehrere Knotenpunkte verteilen kann.
Schauen wir uns an, was hinter den Kulissen passiert.
Was die meisten Spark-Nutzer zunächst nicht wissen, ist Folgendes: Wenn du PySpark-Code schreibst, führst du nicht sofort etwas aus. Du erstellst einen Plan, und der Catalyst Optimizer von Spark wandelt diesen Plan in eine effiziente Ausführungsstrategie um.
Es funktioniert in vier Phasen:
Spark's Catalyst Optimizer. Bild von Databricks.
Die Kette aus .select(), .join() und .groupBy() läuft also nicht einfach Zeile für Zeile ab. Die Daten werden analysiert, optimiert und zu etwas kompiliert, das auf einem Cluster schnell läuft.
Schau dir das PySpark Cheat Sheet an, wenn du einen Spickzettel mit den nützlichsten PySpark-Befehlen brauchst.
Wenn der Plan fertig ist, übernimmt der DAG-Scheduler.
Es unterteilt den Job in Phasen, die auf Shuffle Boundaries basieren, wobei Spark entscheidet, was sequentiell und was parallel ausgeführt werden kann.
Es gibt zwei Haupttypen von Stufen:
groupBy() oder join() verursacht wird. Die Daten werden dann aufgeteilt und über das Netzwerk gesendet. Dieser Stufentyp wird benötigt, um die ResultStage zu berechnen.Eine wichtige Sache, die ich gelernt habe, ist, so wenig wie möglich zu mischen. Ein Shuffle muss stattfinden, bevor eine Etappe beendet ist und ist teuer. Du musst verstehen, wo sie in deiner DAG vorkommen und ob du deinen Code weiter optimieren kannst, um die Anzahl der Shuffles zu reduzieren.
Sobald der DAG-Scheduler alle Phasen erstellt hat, können sie auf den verschiedenen Executors ausgeführt werden.
Der Lebenszyklus der Aufgabenausführung sieht in etwa so aus:
Ein kleiner Tipp aus eigener Erfahrung: Wenn dein Spark-Job nicht mehr läuft, obwohl er vorher gut lief, liegt das oft an Verzögerungen bei der Garbage Collection oder beim Shuffle Fetch. Überprüfe immer deinen Code und stelle sicher, dass du die Architektur von Spark verstehst, damit du diese Themen effektiv optimieren kannst.
Die Speicherverwaltung von Spark ist ein sehr komplexes Thema und kann dich stundenlanges Debugging kosten, wenn du es nicht verstehst.
Schauen wir uns also an, wie Spark den Speicher unter der Haube verwaltet, damit du das weißt und stundenlanges Debuggen von langsamem Code oder Out-of-Memory-Fehlern vermeiden kannst.
Vor Spark 1.6 war der Speicher streng zwischen der Ausführung (für Shuffles und Joins) und der Speicherung (für das Caching) aufgeteilt. Das änderte sich mit Spark 1.6, als das Unified Memory Model eingeführt wurde.
Im einheitlichen Speichermodell werden die Daten in drei wichtige Pools aufgeteilt:
Der Spark-Speicherpool ist in zwei weitere Pools unterteilt:
Dank dieser Elastizität kann Spark flexibler auf unvorhersehbare Datenmengen reagieren.
Das bedeutet aber auch, dass du ein bisschen die Kontrolle verlierst, wenn du nicht weißt, was vor sich geht. Wenn du zum Beispiel cache() einen großen DataFrame hast, aber in der gleichen Phase auch teure Aggregationen durchführst, kann es sein, dass Spark deine zwischengespeicherten Daten verdrängt, um Platz für den Shuffle zu schaffen.
Bei der Off-Heap- und Columnar-Speicherung von Spark kommt die Tungsten-Engine ins Spiel.
Mit Tungsten wurden mehrere Optimierungen eingeführt, die die Leistung von Spark verbessern:
Und wenn du mit DataFrames arbeitest, nutzt du diese Optimierungen bereits unter der Haube. Das ist einer der Gründe, warum ich darauf dränge, DataFrames und SQL-APIs anstelle von rohen RDDs zu verwenden. Du bekommst die volle Leistung von Catalyst und Tungsten ohne zusätzliches Tuning.
Wenn du mit Datenbereinigungspipelines arbeitest, wirst du dies in Cleaning Data with PySpark in Aktion sehen.
Wenn du mit verteilten Systemen arbeitest, weißt du eines ganz genau: Sie scheitern. Knotenpunkte stürzen ab. Netzwerkfehler passieren. Die Executors haben keinen Speicher mehr und werden abgeschaltet.
Aber Spark ist dafür gemacht, mit diesen Problemen umzugehen und stellt sicher, dass deine Jobs trotzdem erfolgreich sind.
Wir wollen uns genauer ansehen, wie Spark sicherstellt, dass deine Jobs auch dann noch erfolgreich sind, wenn einige Instabilitäten auftreten.
Resilient Distributed Datasets (RDDs) sind die grundlegende Datenstruktur in Spark. Und sie werden nicht umsonst als widerstandsfähig bezeichnet.
Spark verwendet Lineage, um sicherzustellen, dass jedes RDD im Falle eines Knotenausfalls und Datenverlusts neu berechnet werden kann.
Wenn also ein Knoten ausfällt, berechnet Spark die verlorenen Daten einfach anhand des Abstammungsgraphen neu.
So funktioniert es in der Praxis:
map() oder filter()): Spark braucht nur die verlorene Partition zur Neuberechnung.groupBy() oder join()): Spark muss möglicherweise Daten über mehrere Partitionen hinweg abrufen, da es die Ausgabe mehrerer Stufen benötigt. Lineage vermeidet die Notwendigkeit, Fehler manuell zu behandeln. Wenn dein Abstammungsdiagramm jedoch zu lang wird, da es Hunderte von Transformationen enthalten kann, wird die Neuberechnung der verlorenen Daten teuer. Hier kommt das Checkpointing ins Spiel.
Bei komplexen Workflows oder Streaming-Jobs kann sich Spark nicht allein auf die Abstammung verlassen. Hier kommt das Checkpointing ins Spiel.
Du kannst rdd.checkpoint() aufrufen, um den aktuellen RDD-Zustand an einem zuverlässigen Speicherort (wie HDFS) zu persistieren.
Spark schneidet dann den Stammbaum ab. Wenn ein Fehler auftritt, lädt es die Daten direkt neu, anstatt sie neu zu berechnen.
Beim strukturierten Streaming verwendet Spark außerdem Write-Ahead-Logs (WALs), um sicherzustellen, dass die Daten während der Übertragung nicht verloren gehen.
Das macht sie so stabil:
Checkpointing ist optional für Stapelverarbeitungsaufträge, aber erforderlich für Streaming-Pipelines.
Angenommen, ein Spark-Job ist nach 10 Stunden Laufzeit fehlgeschlagen, aber du kannst dank Checkpointing und WALs dort weitermachen, wo du aufgehört hast.
Inzwischen hast du gesehen, wie Spark Jobs verarbeitet und mit Speicher und Fehlern umgeht.
In diesem Abschnitt gehen wir auf einige der fortschrittlichen Architektur-Upgrades ein, die Spark dynamischer, echtzeitfähiger und anpassungsfähiger machen.
AQE wurde in Spark 3.0 eingeführt und verbessert die Abfrageleistung, indem es die Ausführungspläne zur Laufzeit auf der Grundlage der während der Ausführung gesammelten Statistiken dynamisch anpasst.
Zu den Merkmalen von AQE gehören:
Diese Funktion ist ein entscheidender Vorteil, denn sie ermöglicht die Anpassung von Aufgaben in Echtzeit, die bisher manuelles Abstimmen und Ausprobieren erforderten.
Achte nur darauf, dass du es explizit über die Konfiguration aktivierst (spark.sql.adaptive.enabled = true). Und wenn du mit Spark 3.0+ arbeitest, gibt es keinen Grund, dies nicht zu tun.
Structured Streaming nutzt die Spark-Engine und erweitert sie auf den Echtzeitbereich, ohne dass du eine neue API lernen musst.
Hinter den Kulissen wird immer noch Micro-Batching angewendet. Aber es funktioniert:
Der Clou dabei ist, dass sich Streaming wie Batching anfühlt. Du schreibst eine groupBy() oder eine filter() und Spark kümmert sich um alles andere, so dass Streaming-Analysen ohne eine spezielle Toolchain möglich sind.
Wenn du Spark in der Produktion einsetzt, insbesondere im Finanzwesen, im Gesundheitswesen oder in ähnlichen Geschäftsbereichen, musst du wissen, wie Spark mit Authentifizierung, Verschlüsselung und Auditierbarkeit umgeht.
Lass uns also tiefer in diese Themen eintauchen und herausfinden, wie Spark sich um sie kümmert.
Spark hat viele Sicherheitsfunktionen, die du zuerst aktivieren musst. Aber sobald es aktiviert ist, bietet Spark ein solides Instrumentarium für sichere Kommunikation und Authentifizierung:
spark.acls.enable=true und spark.ui.view.acls und spark.ui.view.acls.groups einstellen, um sie einzuschränken.Du kannst alle Sicherheitsfunktionen in der offiziellen Dokumentation von Spark nachlesen. Sieh es dir an und stelle sicher, dass du die Funktionen aktivierst, die du für die Sicherheit deiner Spark-Anwendungen brauchst.
Die Aufzeichnung, wer was wann getan hat, ist ebenfalls wichtig.
Spark unterstützt:
spark.eventLog.enabled=true), speichert Spark jedes Job-, Stage- und Task-Ereignis auf der Festplatte. Du kannst diese Protokolle verwenden, um den Arbeitsverlauf wiederzugeben oder um Prüfungsanforderungen zu erfüllen.Spark ist ziemlich leistungsstark und schnell und kann sogar noch schneller werden, wenn du weißt, wo du die nötigen Anpassungen vornehmen musst.
Es gibt mehrere Bereiche, in denen du versuchen kannst, Spark zu optimieren, um das Beste aus ihm herauszuholen. Lass uns also tiefer in jeden Bereich eintauchen.
Wenn Spark einen Schwachpunkt hat, dann ist es der Shuffle. Shuffles entstehen, wenn Daten zwischen Partitionen verschoben werden müssen, typischerweise nach umfangreichen Transformationen wie groupByKey(), distinct() oder join().
Und wenn ein Shuffles schief geht, kann es zu massiver Festplatten-E/A, langen Pausen bei der Garbage Collection oder verzerrten Aufgaben kommen, die nie beendet werden.
Hier erfährst du, wie du die Shuffles verbessern kannst:
reduceByKey() gegenüber groupByKey()vor: reduceByKey() aggregiert lokal, bevor es gemischt wird. groupByKey() sendet alles über das Netzwerk..repartition(n), um die Parallelität zu erhöhen, oder .coalesce(n), um sie zu verringern. Überlasse es nicht der Standardpartitionierung von Spark.spark.sql.autoBroadcastJoinThreshold ein, um die Größenbegrenzung zu kontrollieren.collect(): Vermeide es, wenn möglich, da das Ziehen von Daten zum Treiber die Leistung beeinträchtigt.Die Einstellung des Speichers von Spark kann eine Wissenschaft für sich sein, aber mit der folgenden Checkliste kannst du es dir leichter machen:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Die Anpassung der Speicherkonfiguration kann eine große Hilfe sein. Ich habe einmal einen 30-Minuten-Job auf 8 Minuten reduziert, indem ich die Speicherkonfiguration angepasst habe, ohne eine einzige Zeile Code zu ändern.
Das ist der Teil, den die meisten Teams falsch machen, weil sie die Größe des Clusters schätzen, anstatt sie richtig einzuschätzen.
Aber du kannst es besser machen, wenn du die folgenden Formeln verwendest:
Zum Beispiel:
Aber denk daran: Dies ist nur eine Schätzung. Du kannst sie als Ausgangspunkt verwenden und dann durch Profiling weiter optimieren.
Spark gibt es schon seit einem Jahrzehnt, aber es ist immer noch auf dem neuesten Stand. Sie entwickelt sich dank Cloud-nativer Plattformen, GPU-Beschleunigung und engerer ML-Integration schneller als je zuvor.
Wenn du Spark heute noch genauso einsetzt wie vor drei Jahren, lässt du wahrscheinlich die Leistung auf der Tabelle liegen und verpasst tolle neue Funktionen.
Werfen wir einen Blick auf einige der neuesten.
Wenn du mit Databricks arbeitest, hast du wahrscheinlich schon mit Photon gearbeitet und davon gehört.
Wenn du mehr über Databricks erfahren möchtest, empfehle ich dir den Kurs Einführung in Databricks.
Photon ist die Engine der nächsten Generation auf der Databricks Lakehouse-Plattform, die eine schnelle Abfrageleistung zu niedrigen Kosten bietet. Sie ist mit den Spark-APIs kompatibel, sodass du deinen Spark-Code nicht anpassen musst, um sie nutzen zu können.
Es hilft dir, deinen SQL- und PySpark-Code deutlich zu verbessern.
Photon umfasst die folgenden Funktionen:
Serverless ist fantastisch, denn es bedeutet, dass du keine Cluster verwalten und keine Ressourcen im Voraus bereitstellen musst und dass du nur für die Zeit bezahlst, in der Spark läuft.
Und Serverless für Spark ist bereits in Diensten wie Databricks Serverless, AWS Glue und GCP Dataproc Serverless verfügbar.
Und hier ist der Grund, warum es so unglaublich ist:
Serverless Spark ist ideal für interaktive Analysen, Ad-hoc-Jobs oder unvorhersehbare Arbeitslasten.
Aber Vorsicht: Langlaufende, konsistente Pipelines können auf festen Clustern immer noch günstiger sein. Miss immer sowohl die Kosten als auch die Latenzzeit.
Wenn du maschinelles Lernen in großem Maßstab betreibst und Modelle in die Produktion bringen willst, ist Spark allein nicht genug. Du brauchst MLOps-Prinzipien, wie z.B. Lernpfad, Modellversionierung und Reproduzierbarkeit. Hier kommt MLflow ins Spiel.
MLflow lässt sich jetzt in Spark integrieren und bietet einen kompletten MLOPs-Stack für deine Pipelines.
Das kannst du:
mlflow.log_param() und mlflow.log_metric().pyspark.ml oder sklearn direkt in die Modellregistrierung von MLflow.Du brauchst das Werkzeug nicht zu wechseln. Du nutzt Spark weiterhin für Training, Feature Engineering und Scoring, während du MLflow für MLOPs-Aufgaben verwendest.
Wenn du nicht viel über Spark weißt, ist es wie eine riesige Blackbox. Du schreibst etwas PySpark-Code, drückst auf "Ausführen" und hoffst, dass es funktioniert.
Manchmal hat das gut funktioniert, manchmal hat es zu langen Debugging-Sitzungen geführt, um herauszufinden, was falsch gelaufen ist.
Erst als ich anfing, hinter die Kulissen zu schauen, ergab alles einen Sinn für mich. Und es hat eine ganze Weile gedauert, bis ich verstanden habe, was hier los ist.
Hier ist, worauf ich mich konzentrieren würde, wenn ich noch einmal von vorne anfangen würde:
Das ist genau das, was wir in diesem Artikel gelernt haben.
Wenn du weiter lernen willst, empfehle ich dir hier ein paar anfängerfreundliche Ressourcen:
Lerne mehr über Spark mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Moez Ali
Tutorial
Javier Canales Luna
Tutorial
Mark Pedigo
Tutorial
Allan Ouko

