
Corso
Machine Learning con PySpark
4 h
29.8K
Ti è mai capitato di debuggare un job Spark che è improvvisamente fallito e renderti conto di essere completamente perso per quanto profonda sia la tana del Bianconiglio di Spark?
Quando ho iniziato a lavorare con Apache Spark, pensavo di dover solo scrivere qualche trasformazione in PySpark e che Spark si sarebbe “magicamente” scalato sul cluster. Mi sbagliavo. Le prestazioni di Spark dipendono interamente dalla comprensione di ciò che succede dietro le quinte.
Questa guida è per chiunque non voglia trattare Spark come una scatola nera. Vedremo come è progettata l’architettura di Spark, dal modello master–worker e il flusso di esecuzione, fino alla gestione della memoria e ai meccanismi di tolleranza ai guasti.
Se vuoi creare applicazioni big data veloci, tolleranti ai guasti ed efficienti, sei nel posto giusto!
Prima ancora di scrivere la tua prima riga di PySpark, Spark ha già preso alcune decisioni architetturali per te. Spark non è veloce solo per il computing in memoria, ma perché è costruito su un’architettura master–worker che scala e sopravvive al caos del mondo reale, come crash dei nodi, hes, Java Virtual Machine (JVM) e volumi di dati incostanti.
Vediamo nel dettaglio l’architettura core di Spark e perché è ancora così potente e presente nei moderni workflow big data.
Al cuore di Spark c’è il modello master–worker . Pensa a questa analogia:
main(), crea il contesto Spark, gestisce lo scheduling del DAG e dice al cluster cosa fare.Questa configurazione ti consente di concentrarti nel definire le trasformazioni, mentre Spark decide dove e come eseguirle in parallelo sugli executor.
Quello che apprezzo di questo design è che è indipendente dal deployment. Lo stesso codice gira a prescindere che tu lo esegua in locale, su Kubernetes o Mesos. Questo rende semplice sviluppare e testare in locale, per poi scalare su cluster senza riscrivere il codice.
E c’è un altro vantaggio potente della separazione driver–worker: migliora l’isolamento dai guasti. Se un nodo worker muore mentre esegue un task, Spark può riassegnare quel task a un altro worker senza mandare in crash l’applicazione.
Vediamo cosa succede all’interno del driver e dei nodi.
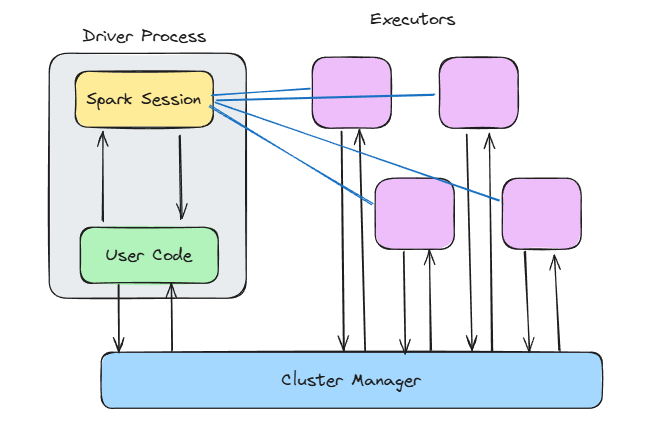
Architettura di Spark. Immagine dell’autore.
Quando chiami SparkContext() o usi SparkSession.builder.getOrCreate(), stai aprendo il portale verso tutta la magia interna di Spark.
Lo Spark context:
Spark costruisce dietro le quinte un grafo aciclico diretto (DAG) di trasformazioni. Quel DAG viene suddiviso in stage e task, poi eseguiti in parallelo.
Il DAG scheduler capisce quali task possono essere eseguiti insieme, e il Task scheduler li assegna agli executor. Nel frattempo, il Block manager assicura che i dati vengano messi in cache, shufflati o ricaricati secondo necessità.
Questo design a livelli rende Spark incredibilmente flessibile, perché puoi mettere a punto memoria, storage e compute in modo indipendente.
Se stai lavorando con trasformazioni Spark o feature engineering, dai un’occhiata al corso Feature Engineering with PySpark per vedere questa architettura in azione.
Gli executor sono dove il lavoro viene svolto.
Ogni executor esegue:
Puoi configurare quanta memoria riceve ogni executor, quanti core usa e se deve scrivere su disco quando la memoria si esaurisce.
Ma attenzione: se non allochi abbastanza memoria, incapperai continuamente in errori di out-of-memory. D’altro canto, allocarne troppa spreca risorse. Monitoraggio e tuning qui sono essenziali.
Scrivere codice in PySpark sembra piuttosto semplice. Filtri un DataFrame, fai una join, aggreghi qualcosa e avvii. Ma dietro quella pulita API, Spark avvia silenziosamente un motore di esecuzione che può distribuire il lavoro su più nodi.
Vediamo cosa succede dietro le quinte.
Ecco cosa la maggior parte degli utenti Spark non capisce subito: quando scrivi codice PySpark, non stai eseguendo nulla immediatamente. Stai costruendo un piano, e il Catalyst Optimizer di Spark prende quel piano e lo trasforma in una strategia di esecuzione efficiente.
Funziona in quattro fasi:
Catalyst Optimizer di Spark. Immagine di Databricks.
Quindi quella catena di .select(), .join() e .groupBy() non viene eseguita riga per riga. Viene analizzata, ottimizzata e compilata in qualcosa che gira velocemente su un cluster.
Dai un’occhiata a questo PySpark Cheat Sheet se vuoi un promemoria dei comandi PySpark più utili.
Quando il piano è pronto, entra in gioco il DAG scheduler.
Scompone il job in stage in base ai confini degli shuffle, decidendo cosa avviene in sequenza e cosa può essere eseguito in parallelo.
Ci sono due tipi principali di stage:
groupBy() o join(). I dati vengono quindi partizionati e inviati attraverso la rete. Questo tipo di stage è richiesto per calcolare il ResultStage.Una cosa fondamentale che ho imparato è minimizzare gli shuffle. Uno shuffle deve avvenire prima che uno stage finisca ed è costoso. Devi capire dove si verificano nel tuo DAG e se puoi ottimizzare ulteriormente il codice per ridurne il numero.
Una volta che il DAG scheduler ha creato tutti gli stage, possono essere eseguiti sui vari executor.
Il ciclo di vita di esecuzione dei task è più o meno così:
Un piccolo suggerimento dalla mia esperienza: se il tuo job Spark rimane bloccato dopo aver funzionato bene in precedenza, spesso è a causa della garbage collection o di ritardi nel fetch dello shuffle. Controlla sempre il codice e assicurati di capire l’architettura di Spark, così da ottimizzare efficacemente questi aspetti.
La gestione della memoria in Spark è un tema molto complesso e può costarti ore di debugging se non la comprendi.
Vediamo quindi come Spark gestisce la memoria sotto il cofano, così da esserne consapevole ed evitare ore a fare debugging di codice lento o di errori di out-of-memory.
Prima di Spark 1.6, la memoria era rigidamente divisa tra execution (per shuffle e join) e storage (per la cache). Con Spark 1.6 è stato introdotto il modello di memoria unificato.
Nel modello unificato, la memoria è suddivisa in tre pool chiave:
Il pool di memoria Spark è ulteriormente diviso in due pool:
Questa elasticità permette a Spark di essere più flessibile con volumi di dati imprevedibili.
Tuttavia significa anche perdere un po’ di controllo quando non sai cosa sta succedendo. Ad esempio, se fai cache() di un DataFrame grande ma hai anche aggregazioni costose nello stesso stage, Spark potrebbe espellere i dati in cache per fare spazio allo shuffle.
Nell’off-heap e nello storage colonnare di Spark entra in gioco il motore Tungsten.
Tungsten ha introdotto diverse ottimizzazioni che hanno migliorato le prestazioni di Spark:
E se lavori con i DataFrame, stai già usando queste ottimizzazioni sotto il cofano. È uno dei motivi per cui invito a usare DataFrame e API SQL al posto degli RDD grezzi. Ottieni tutta la potenza di Catalyst e Tungsten senza tuning extra.
Se stai lavorando con pipeline di data cleaning, vedrai questo in azione in Cleaning Data with PySpark.
Se lavori con sistemi distribuiti, sai una cosa con certezza: falliscono. I nodi vanno in crash. Si verificano errori di rete. Gli executor esauriscono la memoria e si spengono.
Ma Spark è costruito per gestire questi problemi e far sì che i tuoi job vadano comunque a buon fine.
Vediamo più a fondo come Spark garantisce che i job riescano anche in presenza di instabilità.
Gli RDD (Resilient Distributed Datasets) sono la struttura dati fondamentale in Spark. E si chiamano resilient per un motivo.
Spark usa la lineage per assicurare che ciascun RDD possa essere ricalcolato in caso di guasto di un nodo e perdita di dati.
Quindi, quando un nodo fallisce, Spark semplicemente ricalcola i dati persi usando il grafo di lineage.
Ecco come funziona in pratica:
map() o filter()): Spark ha bisogno solo della partizione persa per ricalcolare.groupBy() o join()): Spark potrebbe dover recuperare dati da più partizioni, poiché può richiedere l’output di diversi stage. La lineage evita di dover gestire i fallimenti manualmente. Tuttavia, se il tuo grafo di lineage diventa troppo lungo, contenendo centinaia di trasformazioni, ricalcolare i dati persi diventa costoso. Qui entra in gioco il checkpointing.
Quando affronti workflow complessi o job di streaming, Spark non può dipendere solo dalla lineage. Ecco dove entra in gioco il checkpointing.
Puoi chiamare rdd.checkpoint() per persistere lo stato corrente dell’RDD in un’area di storage affidabile (come HDFS).
Spark poi tronca la lineage. Se si verifica un errore, ricarica i dati direttamente invece di ricalcolarli.
Nello structured streaming, Spark usa anche i write-ahead log (WAL) per garantire che i dati non vadano persi in transito.
Ecco cosa lo rende così stabile:
Il checkpointing è opzionale per i job batch, ma richiesto per le pipeline di streaming.
Immagina un job Spark fallito dopo 10 ore di esecuzione, ma che puoi riprendere da dove si è interrotto grazie a checkpointing e WAL.
A questo punto hai visto come Spark elabora i job e gestisce memoria e guasti.
In questa sezione, entriamo in alcune evoluzioni architetturali avanzate che rendono Spark più dinamico, più real-time e più adattabile.
AQE è stata introdotta in Spark 3.0 e migliora le prestazioni delle query regolando dinamicamente i piani di esecuzione a runtime in base alle statistiche raccolte durante l’esecuzione.
Le funzionalità di AQE includono:
Questa funzionalità cambia le carte in tavola, perché permette ai job che prima richiedevano tuning manuale e tentativi continui di adattarsi in tempo reale.
Assicurati solo di abilitarla esplicitamente via configurazione (spark.sql.adaptive.enabled = true). E se stai usando Spark 3.0+, non c’è motivo per non farlo.
Lo Structured Streaming estende il motore di Spark nel dominio real-time, senza costringerti a imparare una nuova API.
Dietro le quinte applica ancora il micro-batching. Ma gestisce:
La potenza qui è che lo streaming sembra batch. Scrivi un groupBy() o un filter() e Spark gestisce tutto il resto, rendendo l’analisi streaming accessibile senza una toolchain specializzata.
Se esegui Spark in produzione, soprattutto in finanza, healthcare o settori simili, devi sapere come Spark gestisce autenticazione, crittografia e auditabilità.
Approfondiamo quindi questi temi e come Spark se ne occupa.
Spark ha molte funzionalità di sicurezza che devi prima abilitare. Ma una volta attivate, Spark offre una solida cassetta degli attrezzi per comunicazioni sicure e autenticazione:
spark.acls.enable=true e spark.ui.view.acls e spark.ui.view.acls.groups per limitarne l’accesso.Puoi controllare tutte le funzionalità di sicurezza nella documentazione ufficiale di Spark. Dagli un’occhiata e assicurati di abilitare le funzionalità di cui hai bisogno per mettere in sicurezza le tue applicazioni Spark.
Registrare chi ha fatto cosa e quando è altrettanto fondamentale.
Spark supporta:
spark.eventLog.enabled=true), Spark registra su disco ogni evento di job, stage e task. Puoi usare questi log per rigiocare la storia dei job o soddisfare requisiti di audit.Spark è molto potente e veloce, e può essere ottimizzato per essere ancora più veloce se sai dove intervenire.
Ci sono diverse aree in cui puoi provare a ottimizzare per ottenere il massimo da Spark. Vediamole più da vicino.
Se Spark ha un punto debole, è lo shuffle. Gli shuffle avvengono quando i dati devono essere spostati tra partizioni, in genere dopo trasformazioni ampie come groupByKey(), distinct() o join().
E quando gli shuffle vanno male, puoi avere un enorme I/O su disco, lunghe pause di garbage collection o task sbilanciati che non finiscono mai.
Ecco come migliorare gli shuffle:
reduceByKey() a groupByKey(): reduceByKey() aggrega localmente prima dello shuffle. groupByKey() manda tutto sulla rete..repartition(n) per aumentare il parallelismo, o .coalesce(n) per ridurlo. Non lasciare tutto al partizionamento di default di Spark.spark.sql.autoBroadcastJoinThreshold per controllare il limite di dimensione.collect(): evitalo quando possibile, perché riportare i dati al driver uccide le prestazioni.Ottimizzare la memoria di Spark può essere una scienza, ma puoi usare la checklist qui sotto per semplificare:
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=2
spark.dynamicAllocation.maxExecutors=20spark.memory.storageFraction.Adattare la configurazione della memoria può aiutare molto. Una volta ho ridotto un job da 30 minuti a 8 minuti solo modificando la configurazione della memoria, senza cambiare una riga di codice.
Questa è la parte in cui la maggior parte dei team sbaglia, perché indovina la dimensione del cluster invece di stimarla correttamente.
Ma puoi fare meglio usando le formule seguenti:
Per esempio:
Ma ricorda: è solo una stima. Usala come punto di partenza e poi ottimizza ulteriormente tramite profiling.
Spark esiste da un decennio, ma è ancora molto attuale. Sta evolvendo più che mai, grazie a piattaforme cloud-native, accelerazione GPU e integrazione più stretta con l’ML.
Se oggi usi Spark nello stesso modo di tre anni fa, probabilmente stai lasciando prestazioni sul tavolo e ti perdi ottime nuove funzionalità.
Vediamo alcune delle più recenti.
Se lavori con Databricks, probabilmente hai già usato e sentito parlare di Photon.
Se vuoi saperne di più su Databricks, ti consiglio il corso Introduction to Databricks.
Photon è il motore di nuova generazione sulla piattaforma Lakehouse di Databricks che offre prestazioni di query elevate a basso costo. È compatibile con le API Spark, quindi non devi adattare il tuo codice Spark per sfruttarlo.
Aiuta a potenziare in modo significativo il tuo codice SQL e PySpark.
Photon include le seguenti funzionalità:
Il serverless è fantastico, perché significa che non devi gestire cluster, pre-provisionare risorse e paghi solo per il tempo in cui Spark è in esecuzione.
E il serverless per Spark è già disponibile in servizi come Databricks Serverless, AWS Glue e GCP Dataproc Serverless.
Ecco perché è incredibile:
Serverless Spark è ideale per analytics interattive, job ad hoc o workload imprevedibili.
Ma fai attenzione: pipeline lunghe e costanti possono essere ancora più economiche su cluster fissi. Misura sempre sia costo sia latenza.
Man mano che l’industria evolve, il confine tra data engineering e AI si fa sempre più sfumato. Come ha esplorato Deepak Goyal, CEO & Founder di Azurelib Academy, nel podcast DataFramed
Il data engineering giocherà un ruolo vitale e fondamentale nel prossimo passaggio all’AI.
Deepak Goyal, CEO & Founder at Azurelib Academy
Approfondisci Spark con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

