
Program
Ilmuwan Pembelajaran Mesin dalam Python
85 Hr
Dalam artikel ini, kita akan membahas sebuah teknik penting dalam statistika dan pembelajaran mesin bernama bootstrapping. Istilah bootstrapping berasal dari ungkapan ‘pulling yourself up by your bootstraps’ karena teknik statistik ini memungkinkan Anda melakukan banyak hal dengan sumber daya yang sangat terbatas. Dengan bootstrapping, Anda bisa mengambil distribusi dengan bentuk atau ukuran apa pun lalu membuat distribusi baru dari hasil sampel ulang, dan menggunakan distribusi baru ini untuk mendekati distribusi probabilitas yang sebenarnya. Karena itu, bootstrapping sangat efektif untuk menetapkan ukuran akurasi seperti bias, varians, interval kepercayaan, dan galat prediksi pada estimasi sampel.
Sebelum mulai, jika Anda tertarik pada data science, pertimbangkan untuk mengikuti kursus DataCamp tentang ilmu data dan statistika, seperti Statistical Inference in R dan kursus Foundations of Inference in Python.
Mari kita mulai dengan menempatkan bootstrapping pada konteksnya di antara metode pengambilan sampel ulang. Meskipun ada berbagai jenis metode pengambilan sampel ulang, semuanya memiliki satu kesamaan penting: meniru proses pengambilan sampel. Alasan kita menggunakan metode ini adalah karena tidak praktis untuk terus-menerus mengambil sampel baru dari populasi yang diminati, sehingga resampling menjadi semacam jalan pintas.
Sebagai contoh, ketika kita ingin memahami sesuatu tentang populasi yang diminati, kita mungkin menjalankan survei dan menargetkan seribu respons. Namun, tidak ada yang akan menyebarkan survei yang sama ke populasi target sebanyak seribu kali. Karena keterbatasan praktis inilah kita menggunakan metode pengambilan sampel ulang untuk menghasilkan statistik tentang sampel kita, seperti galat baku.
Ada empat jenis utama metode pengambilan sampel ulang. Layak untuk menyebutkan metode lainnya karena semuanya berbagi sejarah inovasi dan penyempurnaan statistik yang sama. Khususnya, bootstrapping dikembangkan sebagai ekstensi, modifikasi, atau perbaikan dari metode jackknife.
Perlu membahas sedikit tentang jackknife karena jackknife adalah pendahulu bootstrapping, dan bootstrapping diperkenalkan sebagai semacam ekstensi dan perbaikan atas jackknife, yang dikembangkan pada 1950-an ketika komputer hanya memiliki sekitar satu kilobyte memori.
Jackknife adalah metode leave-one-out yang menghitung statistik yang diminati; ini dilakukan secara berurutan atau iteratif hingga setiap observasi telah disisihkan. Dengan jackknife, jumlah sampel ulang terbatas pada jumlah observasi, dan terutama karena alasan ini, jackknife cenderung kurang baik pada ukuran sampel kecil. Jackknife juga agak terbatas dalam jenis data yang dapat digunakan. Di sisi lain, tidak seperti bootstrap, jackknife dapat direproduksi dengan hasil yang sama setiap saat.
Bootstrapping memiliki beragam aplikasi dalam statistika dan pembelajaran mesin. Salah satu penggunaan paling umum adalah untuk mengestimasi interval kepercayaan ketika distribusi dasar tidak diketahui atau ketika ukuran sampel kecil. Kemampuan ini membuat bootstrapping sangat berharga pada situasi di mana metode parametrik tradisional mungkin kurang tepat.
Selain itu, bootstrapping sering digunakan dalam pengujian hipotesis dan validasi model, di mana teknik ini dapat membantu mengevaluasi ketangguhan prediksi model. Dalam pembelajaran mesin, bootstrapping menjadi dasar metode ensemble populer yang dikenal sebagai bagging, yang digunakan pada model seperti random forest untuk meningkatkan akurasi dengan mengurangi varians.
Untuk mengilustrasikan bootstrapping, kita perlu menggunakan bahasa pemrograman seperti R karena ini memungkinkan kita menghasilkan banyak dataset hasil sampel ulang; tanpa lingkungan pemrograman, prosesnya akan terlalu memakan waktu dan kompleks untuk dilakukan secara manual. Pada artikel ini, kita akan melihat cara melakukan bootstrap untuk interval kepercayaan sebuah distribusi dan juga untuk regresi linear menggunakan dataset Fish Market di Kaggle.
Sebelum melihat bootstrapping secara tepat, ada baiknya membiasakan diri dengan gagasan pengambilan sampel dengan pengembalian. Di sini, fungsi dasar R sample() menerima setidaknya dua argumen yang perlu ditentukan secara eksplisit dalam pemanggilan fungsi: x dan size. x menentukan daftar atau rentang nilai tempat kita memilih sampel dan size menentukan ukuran sampel kita. Ada argumen tambahan yang sering dinyatakan secara eksplisit, yaitu argumen replace. Kecuali ditentukan lain, replace = FALSE menjadi nilai baku.
Bootstrapping adalah pengambilan sampel dengan pengembalian. Saat kita mengambil sampel dengan pengembalian, kita mengembalikan nilai setelah setiap pengambilan. Maka setiap sampel independen dari nilai sebelumnya. Saat kita mengambil sampel tanpa pengembalian, kita tidak mengembalikan nilai, sehingga setelah sebuah nilai terpilih, nilai itu tidak bisa dipilih lagi; akibatnya dua nilai sampel tidak independen, dan apa pun nilai yang kita peroleh pada satu sampel akan memengaruhi kemungkinan nilai pada sampel berikutnya. Konsekuensinya, kita tidak dapat memilih ukuran sampel yang lebih besar dari ukuran vektor masukan kecuali kita menetapkan replace = TRUE. Bootstrapping tidak menghadapi masalah ini, dan kita dapat menghasilkan dataset sampel ulang bootstrap yang jauh lebih besar daripada data asli.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Sekarang mari unduh dataset kita dan membacanya dari folder unduhan ke RStudio menggunakan fungsi read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Untuk mulai, mari buat histogram dari akar kuadrat bobot ikan, untuk melihat distribusi kita. Distribusi ini, seperti yang terlihat, jauh dari distribusi normal, atau distribusi Gaussian. Jika pun ada kemiripan, ia cenderung bimodal.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")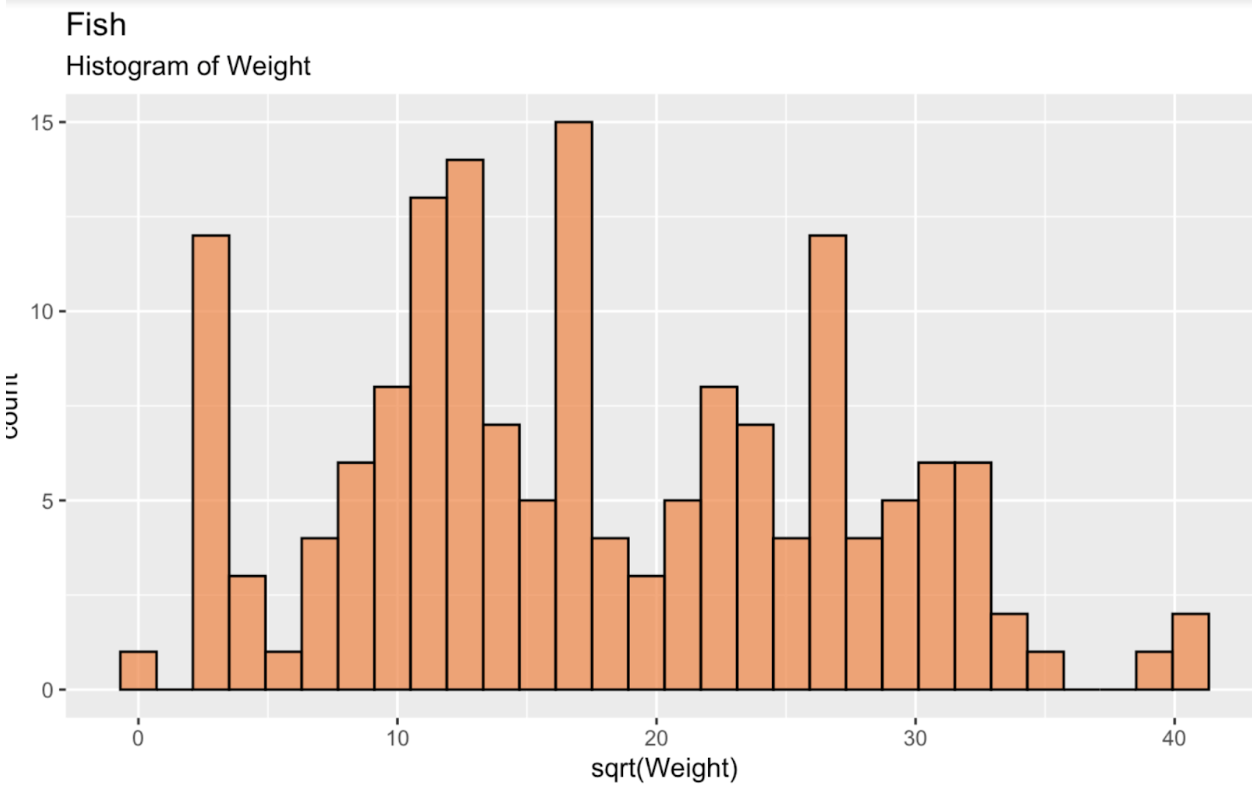
Histogram bobot ikan. Gambar oleh Penulis.
Kita dapat melakukan bootstrap di R menggunakan paket infer dari pustaka tidymodels. Mencetak tabel ini ke konsol memberi kita data frame berisi statistik yang diinginkan untuk setiap replikasi. Ketika kita membuat distribusi baru dari replikasi ini, distribusi tersebut akan berbentuk normal sehingga kita dapat menghasilkan interval kepercayaan.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")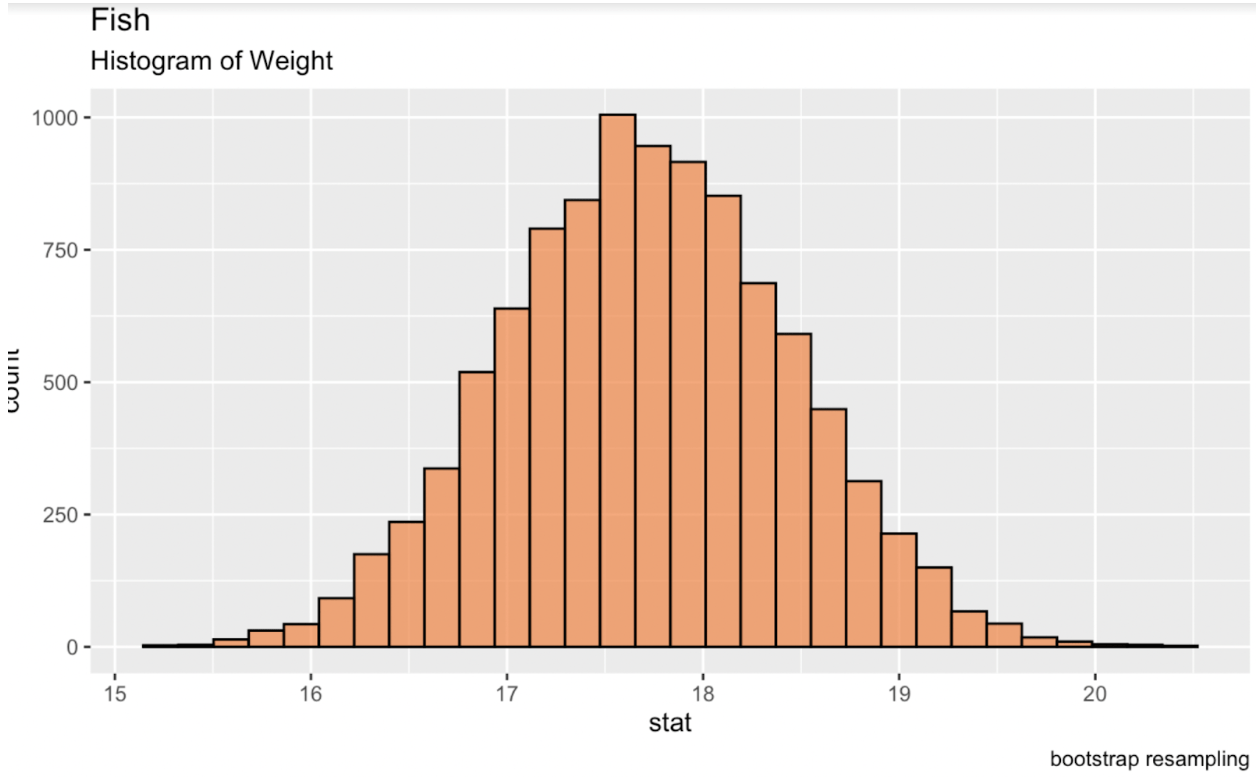 Histogram rataan bootstrap bobot ikan. Gambar oleh Penulis.
Histogram rataan bootstrap bobot ikan. Gambar oleh Penulis.
Regresi linear, tonggak utama pemodelan statistik, digunakan untuk menunjukkan hubungan antara satu atau lebih variabel bebas dan variabel terikat. Saat bekerja dengan model regresi, umum untuk menilai ketidakpastian di sekitar estimasi kita. Salah satu caranya adalah dengan menghitung interval kepercayaan regresi linear, yang memberikan rentang nilai tempat parameter sebenarnya, seperti rataan, kemungkinan berada. Di sini, kita akan membuat interval kepercayaan menggunakan bootstrapping, dan juga membuat interval kepercayaan menggunakan metode pendekatan normal, yang juga disebut interval kepercayaan Wald.
Dalam konteks regresi linear, bootstrap resampling melibatkan pengambilan sampel secara acak dari dataset untuk membuat banyak sampel bootstrap. Kita kemudian menyesuaikan model regresi pada setiap sampel. Terakhir, kita menggunakan distribusi koefisien model di seluruh sampel ini untuk mengestimasi interval kepercayaan. Pada kode berikut, kita menggunakan fungsi bootstraps() dari paket tidymodels untuk melakukan bootstrap resampling pada dataset kita. Lalu kita membuat histogram untuk menunjukkan rentang nilai yang terdapat pada sampel bootstrap untuk koefisien intersep dan bobot.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')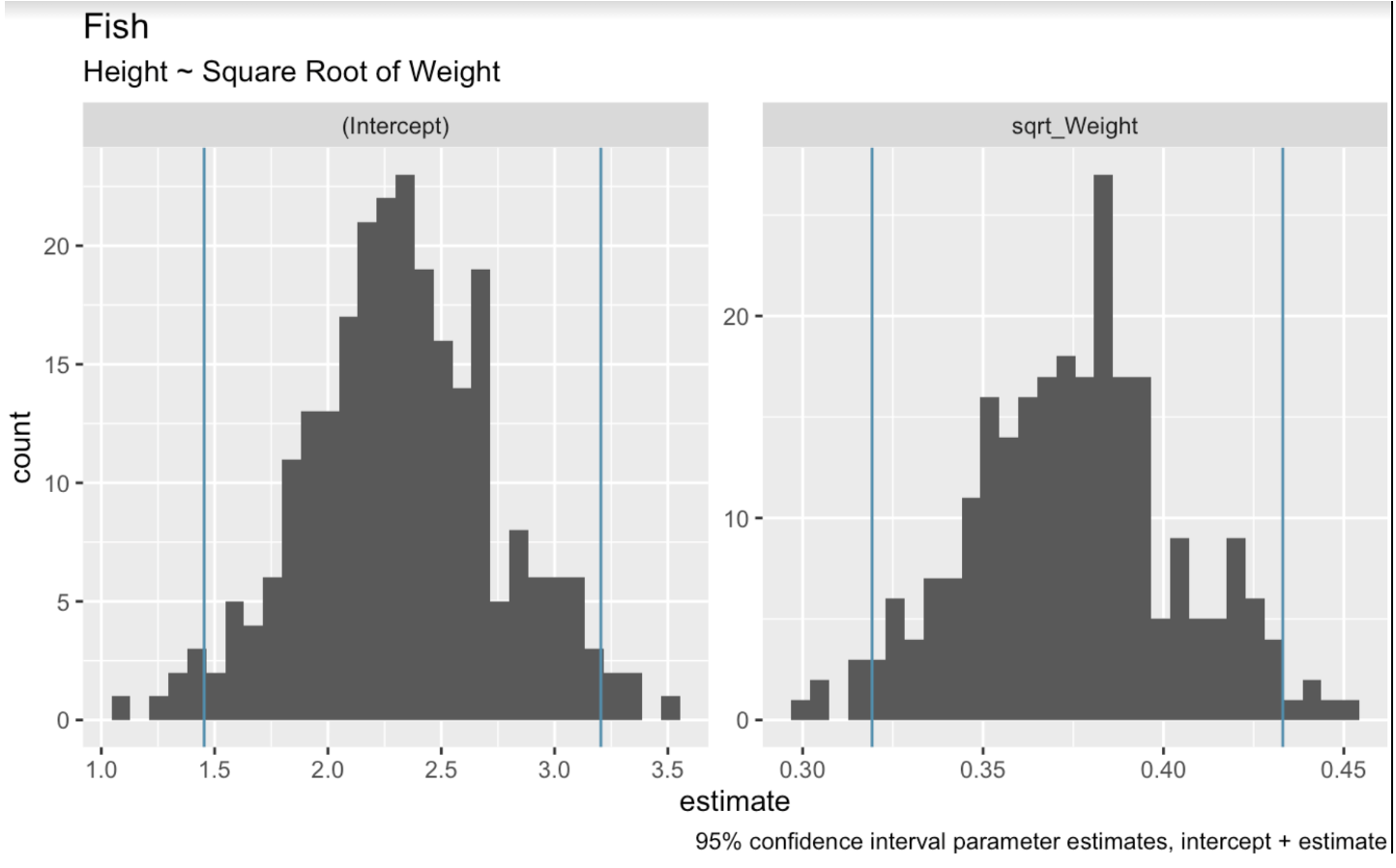
Koefisien model linear hasil bootstrap. Gambar oleh Penulis.
Saat kita menggambar kemungkinan garis regresi, kita akan memangkas garis paling ekstrem di kedua ujungnya untuk mendapatkan interval 95%. Fungsi int_pctl() memudahkan hal ini.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Sebagai langkah terakhir, mari sekarang membuat interval kepercayaan yang dihasilkan dari persamaan bentuk tertutup yang lebih teoretis. Kita dapat menemukan parameternya dengan memanggil summary() dari objek model linear kita.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Di sini, koefisien estimasi untuk variabel sqrt_Weight adalah 0,37569. Galat baku untuk sqrt_Weight adalah 0,02186. Derajat kebebasan adalah 157 (yaitu 159 observasi dalam dataset kita dikurangi dua parameter yang diestimasi). Dan nilai t untuk interval kepercayaan 95% dua ekor adalah 1,975189. Kita mengetahui angka terakhir ini melalui fungsi qt(): qt(0.975, 157). Pada visualisasi di bawah, garis biru adalah garis regresi linear hasil bootstrap, dan garis merah putus-putus adalah interval kepercayaan yang dihasilkan oleh rumus analitis umum.
# Wald confidence interval(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")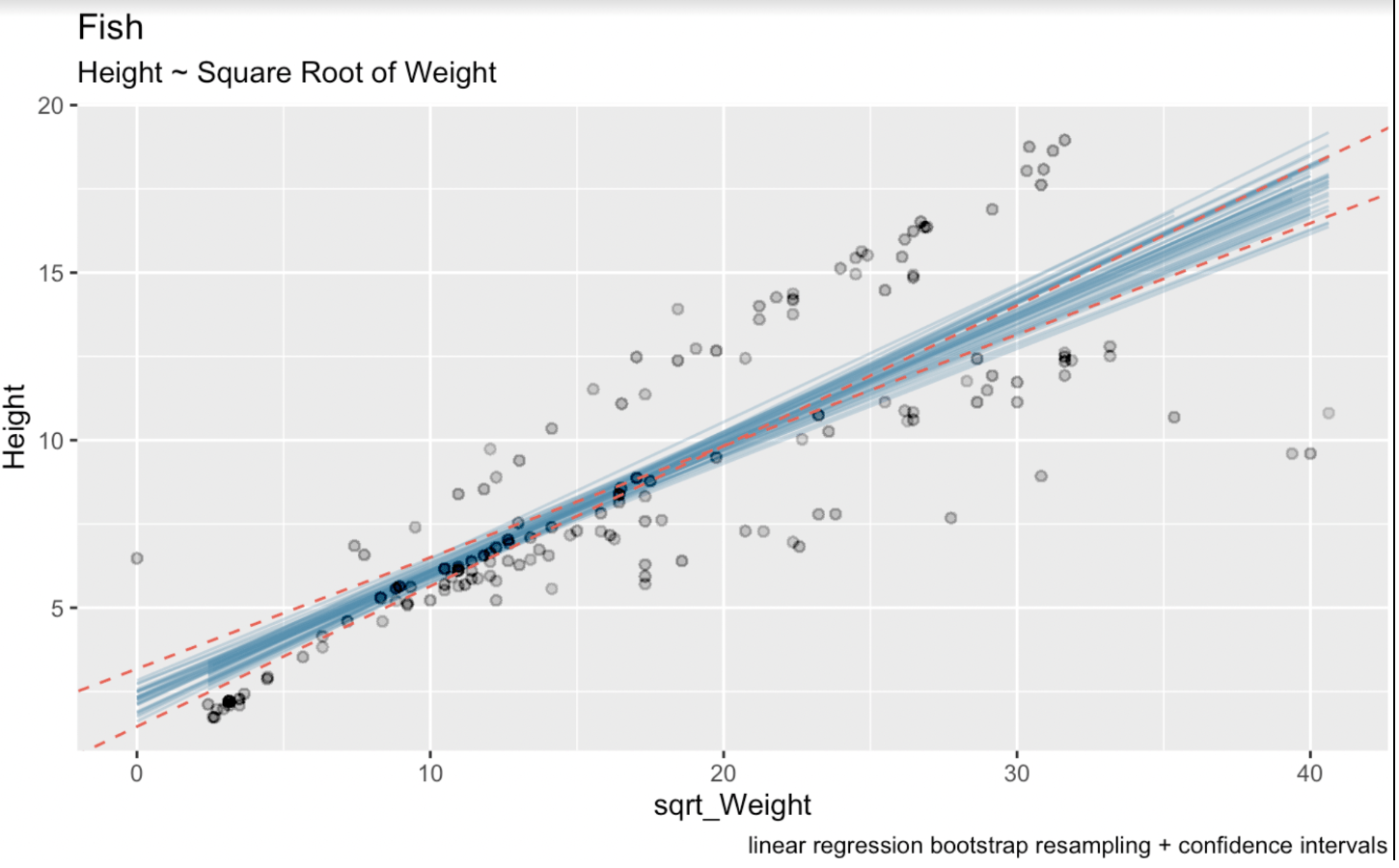
Regresi linear hasil bootstrap dengan interval kepercayaan. Gambar oleh Penulis.
Di sini terlihat jelas bahwa proses bootstrap resampling memperkenalkan sedikit lebih banyak ketidakpastian dalam estimasi kita. Ini karena interval untuk koefisien regresi linear dihitung menggunakan rumus teoretis yang bergantung pada asumsi tentang distribusi galat dan sifat penaksir. Rumus-rumus ini mengandalkan asumsi seperti kenormalan galat dan varians konstan.
Di sisi lain, bootstrap resampling bersifat bebas distribusi, artinya membuat asumsi minimal tentang distribusi data yang mendasari. Alih-alih, bootstrap secara langsung mengestimasi distribusi pengambilan sampel dari statistik yang diminati dengan melakukan resampling dari data yang diamati. Akibatnya, interval kepercayaan bootstrap bisa lebih tangguh dan andal ketika asumsi metode tradisional dilanggar atau saat berhadapan dengan ukuran sampel kecil, seperti pada kasus dataset Fish Market kita dengan 159 observasi.
Dalam bootstrapping parametrik, dibuat asumsi tentang distribusi dasar data, dan sampel ulang dihasilkan berdasarkan asumsi tersebut. Metode ini berguna ketika Anda memiliki pengetahuan awal atau asumsi kuat tentang distribusi data. Pikirkan tentang dataset pengambilan sampel yang mungkin tidak berdistribusi normal, tetapi konsep di balik pengambilannya lebih dikenal, sehingga Anda dapat membuat distribusi menggunakan parameter dari populasi.
Bootstrapping nonparametrik, di sisi lain, tidak membuat asumsi tentang distribusi data. Ia mengambil sampel ulang langsung dari data yang diamati dengan pengembalian, sehingga sangat berguna ketika distribusi sebenarnya tidak diketahui atau sulit didefinisikan. Pada contoh di atas, kita menggunakan bootstrapping nonparametrik. Kedua metode memungkinkan Anda mengestimasi statistik seperti galat baku dan interval kepercayaan. Namun, bootstrapping nonparametrik menawarkan fleksibilitas yang lebih besar untuk dataset dunia nyata, terutama saat berhadapan dengan sampel kecil atau kompleks, dan lebih umum digunakan dalam praktik.
Dalam peramalan deret waktu, bootstrapping dapat diterapkan untuk mengambil sampel ulang data historis dan menghasilkan prakiraan masa depan, menyediakan distribusi kemungkinan hasil alih-alih satu estimasi titik. Ini membantu memodelkan rentang skenario masa depan yang potensial dan membuat interval kepercayaan untuk prediksi. Bootstrapping juga menjadi dasar metode ensemble seperti bagging dalam model deret waktu, yang dapat mengurangi overfitting dan meningkatkan akurasi keseluruhan prakiraan dengan menggabungkan beberapa model. Kursus Forecasting in R kami akan mengajarkan cara melakukan resampling dalam peramalan deret waktu, baik Anda menggunakan peramalan ARIMA maupun metode lainnya.
Semoga Anda semakin menghargai bootstrapping, jika sebelumnya belum. Seperti yang telah kita lihat, bootstrapping adalah alat yang kuat dalam statistika dan pembelajaran mesin, dan menawarkan cara yang menarik untuk mengestimasi variabilitas dan keyakinan ukuran statistik tanpa memerlukan asumsi kuat tentang data yang mendasarinya.
Pertimbangkan untuk memulai jalur karier Machine Learning Scientist in Python kami dan pastinya Anda akan menjadi ahli dalam bekerja dengan berbagai jenis distribusi dan dataset yang kompleks. Jalur keterampilan Statistical Inference in R kami juga merupakan pilihan tepat dengan fokus pada pengujian hipotesis, randomisasi, dan pengukuran ketidakpastian.
Belajar bersama DataCamp
Program
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
