
Cursus
Chercheur en apprentissage automatique en Python
85 h
Dans cet article, nous allons explorer une technique essentielle en statistiques et en apprentissage automatique : le bootstrap. Le terme vient de l’expression « se hisser par ses propres lacets », car cette approche statistique permet d’en faire beaucoup avec très peu. Avec le bootstrap, vous pouvez prendre une distribution de n’importe quelle forme ou taille, créer une nouvelle distribution de rééchantillonnages et utiliser cette dernière pour approcher la véritable loi de probabilité. C’est pourquoi le bootstrap est particulièrement efficace pour associer à des estimations d’échantillon des mesures de précision telles que le biais, la variance, les intervalles de confiance et l’erreur de prédiction.
Avant de commencer, si vous vous intéressez à la data science, envisagez de suivre ces cours DataCamp en data science et statistiques, comme notre parcours de compétences Statistical Inference in R et notre cours Foundations of Inference in Python.
Commençons par situer correctement le bootstrap parmi les méthodes de rééchantillonnage. Bien qu’il en existe de différentes natures, elles partagent un point commun : elles miment le processus d’échantillonnage. On utilise une méthode de rééchantillonnage parce qu’il n’est pas pratique de tirer sans cesse de nouveaux échantillons de la population d’intérêt : le rééchantillonnage est une forme de raccourci.
Par exemple, pour étudier une population cible, on peut envisager de lancer une enquête et d’espérer mille réponses. Cependant, personne n’administrera mille fois la même enquête à la même population. C’est en raison de cette contrainte pratique que l’on recourt au rééchantillonnage afin de générer des statistiques sur notre échantillon, comme l’erreur standard.
On distingue quatre grands types de rééchantillonnage. Il vaut la peine de les mentionner, car ils partagent une même histoire d’innovation statistique. En particulier, le bootstrap a été développé comme une extension, une modification ou une amélioration de la méthode du jackknife.
Il est utile d’évoquer le jackknife, précurseur du bootstrap, car le bootstrap a été introduit comme une extension et une amélioration du jackknife, développé dans les années 1950, à une époque où les ordinateurs avaient environ un kilooctet de mémoire.
Le jackknife est une méthode de type leave-one-out qui calcule une statistique d’intérêt en retirant successivement chaque observation. Avec le jackknife, le nombre de rééchantillonnages est limité au nombre d’observations, et c’est en grande partie pour cette raison qu’il est moins performant avec de petits échantillons. Le jackknife est également plus restreint quant aux types de données utilisables. En revanche, contrairement au bootstrap, le jackknife est parfaitement reproductible à chaque exécution.
Le bootstrap possède un large éventail d’applications en statistiques comme en apprentissage automatique. L’un de ses usages les plus courants est l’estimation d’intervalles de confiance lorsque la distribution sous-jacente est inconnue ou que la taille d’échantillon est réduite. Cette capacité le rend particulièrement utile lorsque les méthodes paramétriques traditionnelles ne sont pas adaptées.
Le bootstrap est aussi souvent utilisé pour les tests d’hypothèses et la validation de modèles, où il aide à évaluer la robustesse des prédictions. En apprentissage automatique, il est au cœur de la méthode d’ensemble appelée bagging, utilisée notamment dans les random forests pour améliorer la précision en réduisant la variance.
Pour illustrer le bootstrap, nous allons utiliser un langage comme R, qui permet de générer de multiples jeux de données rééchantillonnés : sans environnement de programmation, le processus serait trop long et complexe à effectuer manuellement. Dans cet article, nous allons estimer des intervalles de confiance pour une distribution et pour une régression linéaire à l’aide du jeu de données Fish Market de Kaggle.
Avant d’aborder le bootstrap proprement dit, rappelons le principe de l’échantillonnage avec remise. En R de base, la fonction sample() prend au minimum deux arguments à préciser explicitement : x et size. x définit la liste ou l’intervalle de valeurs dans lequel on pioche, et size la taille de l’échantillon. Un autre argument est souvent précisé : replace. Par défaut, replace = FALSE est activé.
Le bootstrap correspond à un tirage avec remise. Quand on échantillonne avec remise, on remet la valeur après chaque tirage. Chaque tirage est donc indépendant du précédent. Sans remise, une valeur sélectionnée ne peut plus l’être de nouveau : deux tirages ne sont pas indépendants, et la valeur obtenue au premier influe sur les possibilités du suivant. Conséquence : on ne peut pas choisir une taille d’échantillon supérieure à celle du vecteur d’entrée, sauf si l’on spécifie replace = TRUE. Le bootstrap ne souffre pas de cette contrainte : on peut générer un jeu de données rééchantillonné bien plus grand que l’original.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Téléchargeons maintenant le jeu de données et lisons-le depuis le dossier Téléchargements dans RStudio avec la fonction read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Pour commencer, traçons un histogramme de la racine carrée du poids des poissons afin d’observer la distribution. Comme on le voit, elle est loin d’être normale, ou gaussienne. Elle est même plutôt bimodale.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")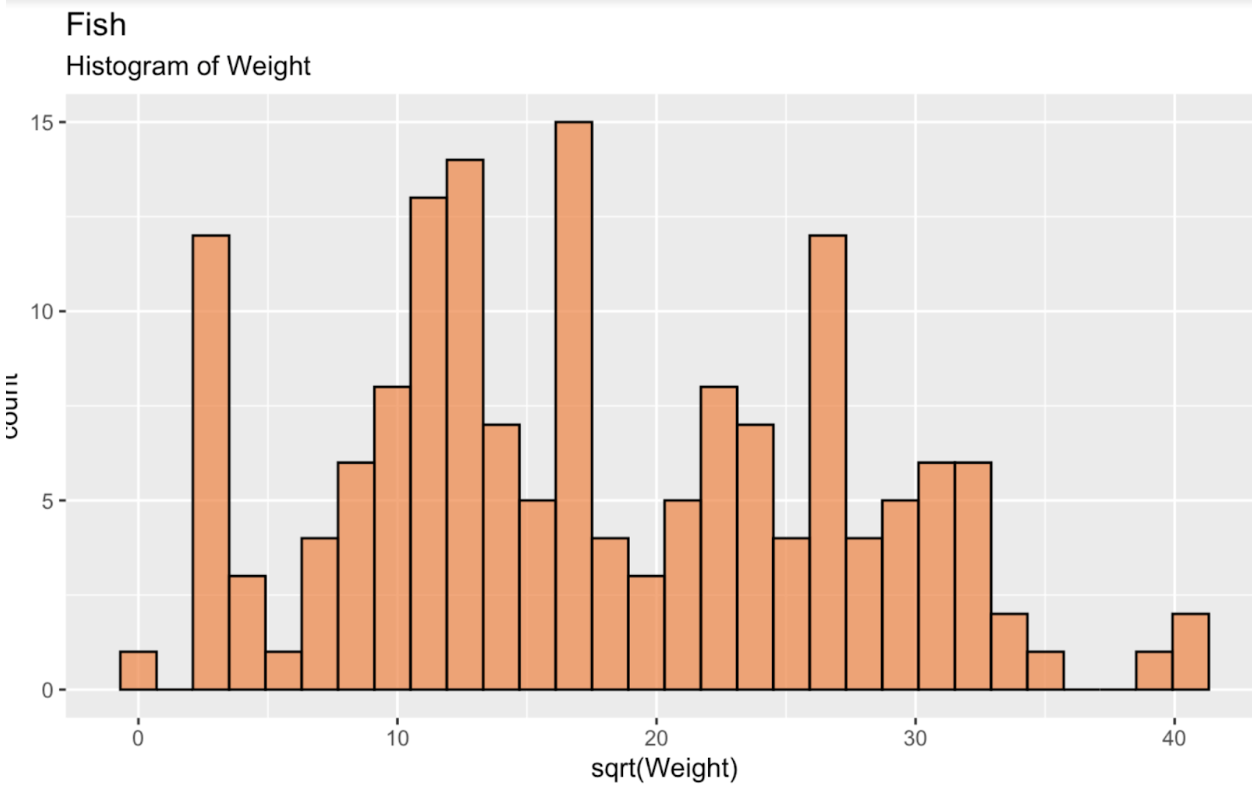
Histogramme du poids des poissons. Image de l’auteur.
On peut effectuer un bootstrap dans R avec le package infer de la librairie tidymodels. L’impression de cette table dans la console renvoie un data frame contenant la statistique souhaitée pour chaque réplique. En créant une nouvelle distribution de ces répliques, on obtient une distribution normale à partir de laquelle générer des intervalles de confiance.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")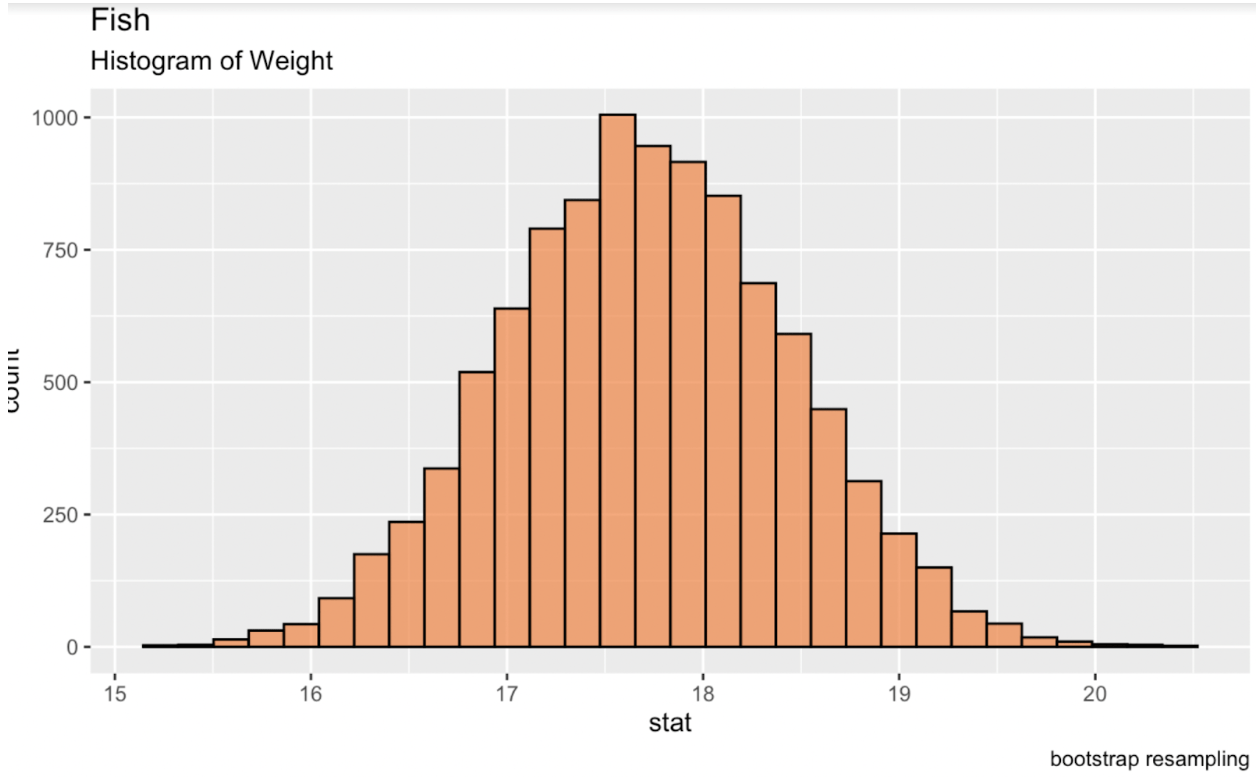 Histogramme de la moyenne bootstrap du poids des poissons. Image de l’auteur.
Histogramme de la moyenne bootstrap du poids des poissons. Image de l’auteur.
La régression linéaire, pilier de la modélisation statistique, met en évidence la relation entre une ou plusieurs variables indépendantes et une variable dépendante. Quand on travaille sur des modèles de régression, il est courant d’évaluer l’incertitude autour des estimations. Une façon de le faire consiste à calculer des intervalles de confiance en régression linéaire, qui fournissent une plage de valeurs dans laquelle le paramètre véritable (par exemple la moyenne) est susceptible de se situer. Ici, nous allons créer des intervalles de confiance par bootstrap, et aussi via l’approximation normale, appelée intervalle de confiance de Wald.
Dans le cadre d’une régression linéaire, le rééchantillonnage bootstrap consiste à tirer aléatoirement dans le jeu de données pour produire de multiples échantillons bootstrap. On ajuste ensuite un modèle de régression sur chaque échantillon. Enfin, on utilise la distribution des coefficients obtenus pour estimer les intervalles de confiance. Dans le code ci-dessous, nous utilisons la fonction bootstraps() du package tidymodels pour réaliser le rééchantillonnage bootstrap. Nous traçons ensuite des histogrammes pour montrer l’étendue des valeurs observées dans nos rééchantillonnages pour l’ordonnée à l’origine et le coefficient du poids.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')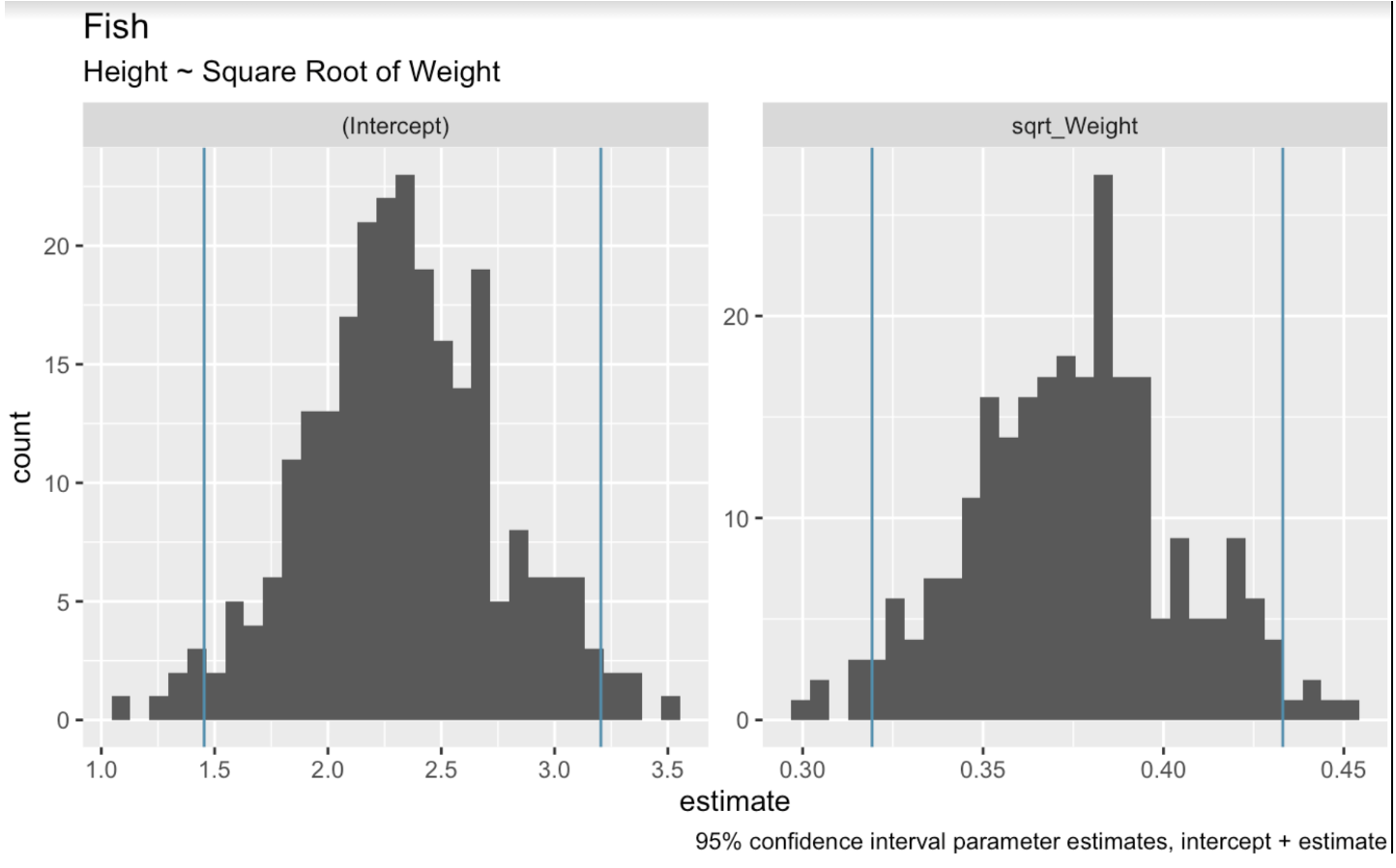
Coefficients bootstrap d’un modèle linéaire. Image de l’auteur.
Lorsque nous traçons les droites de régression possibles, nous coupons les plus extrêmes de part et d’autre afin d’obtenir un intervalle à 95 %. La fonction int_pctl() simplifie cette opération.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)En dernière étape, créons les intervalles de confiance issus des formules théoriques en forme fermée. Nous pouvons retrouver les paramètres en appelant summary() sur l’objet de notre modèle linéaire.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Ici, le coefficient estimé pour la variable sqrt_Weight est de 0,37569. L’erreur standard pour sqrt_Weight est de 0,02186. Les degrés de liberté sont de 157 (correspondant à 159 observations moins deux paramètres estimés). Et la valeur t bilatérale pour un intervalle de confiance à 95 % est 1,975189. Nous obtenons ce dernier chiffre via la fonction qt() : qt(0.975, 157). Sur la visualisation ci-dessous, les lignes bleues sont les régressions linéaires obtenues par bootstrap, et les pointillés rouges représentent l’intervalle de confiance généré par la formule analytique usuelle.
# Intervalle de confiance de Wald(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")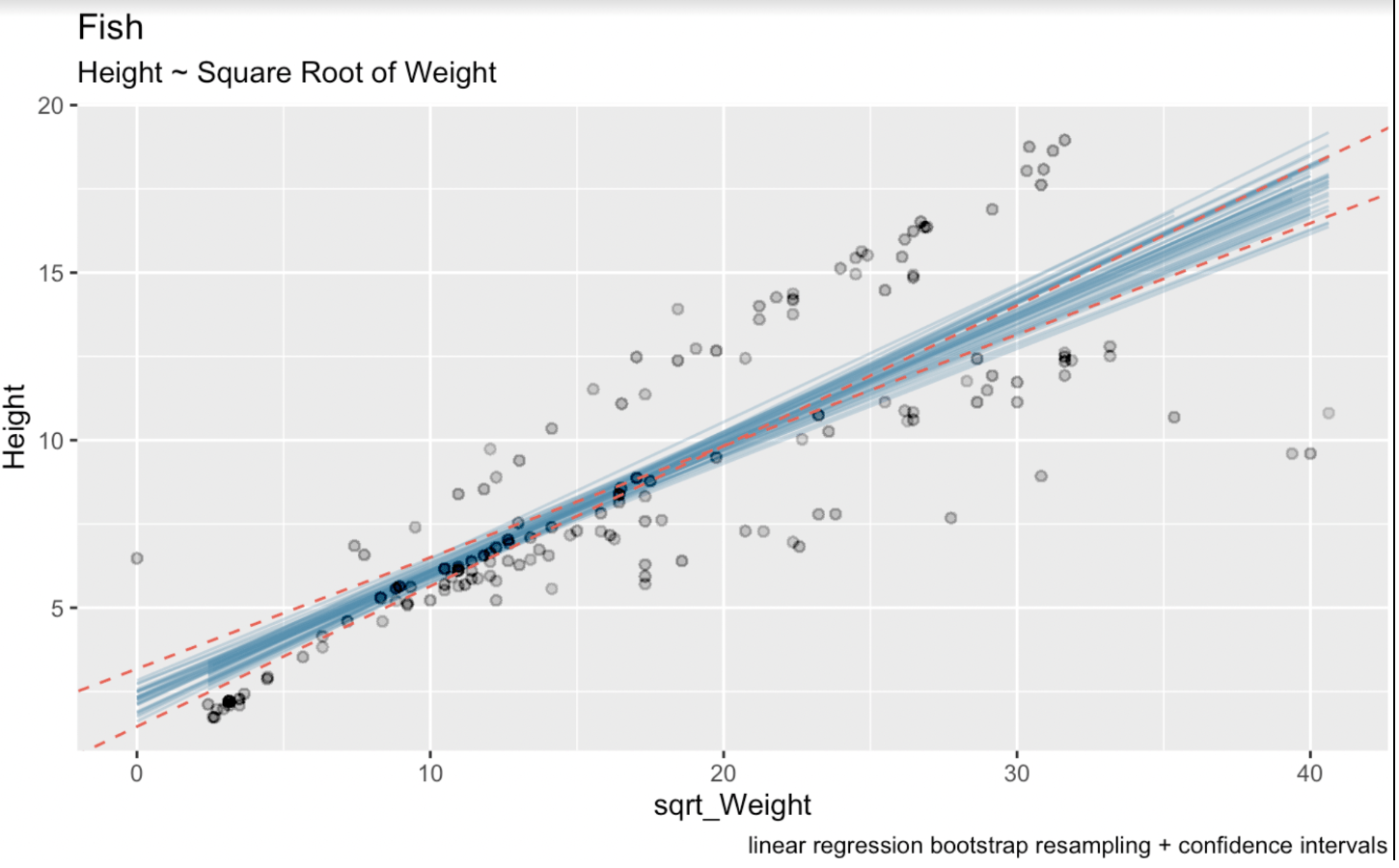
Régressions linéaires bootstrap avec intervalles de confiance. Image de l’auteur.
On voit clairement ici que notre processus de rééchantillonnage bootstrap a introduit un peu plus d’incertitude dans l’estimation. C’est parce que les intervalles de confiance des coefficients de régression linéaire sont calculés à l’aide de formules théoriques fondées sur des hypothèses concernant la distribution des erreurs et les propriétés de l’estimateur. Ces formules reposent notamment sur la normalité des erreurs et l’homoscédasticité.
Le rééchantillonnage bootstrap, en revanche, est non paramétrique : il fait un minimum d’hypothèses sur la distribution sous-jacente. Il estime directement la distribution d’échantillonnage de la statistique d’intérêt en rééchantillonnant les données observées. Par conséquent, les intervalles de confiance par bootstrap peuvent être plus robustes et fiables lorsque les hypothèses des méthodes traditionnelles sont violées ou lorsque l’on dispose de petits échantillons, comme dans notre jeu de données Fish Market avec 159 observations.
En bootstrap paramétrique, on pose des hypothèses sur la distribution sous-jacente des données et on génère les rééchantillonnages à partir de ces hypothèses. Cette approche est utile lorsque vous disposez de connaissances préalables ou d’hypothèses solides sur la distribution des données. Pensez à un jeu d’échantillons qui ne suit peut-être pas une loi normale, mais dont le mécanisme sous-jacent est mieux connu, ce qui permet de générer une distribution à partir des paramètres de la population.
Le bootstrap non paramétrique, lui, ne fait aucune hypothèse sur la distribution des données. Il rééchantillonne directement avec remise à partir des données observées, ce qui est particulièrement précieux quand la distribution véritable est inconnue ou difficile à caractériser. Dans l’exemple ci-dessus, nous avons utilisé un bootstrap non paramétrique. Les deux méthodes permettent d’estimer des statistiques comme les erreurs standards et les intervalles de confiance. Toutefois, le bootstrap non paramétrique offre davantage de flexibilité pour les jeux de données réels, notamment avec des échantillons petits ou complexes, et il est le plus utilisé en pratique.
En prévision de séries temporelles, le bootstrap peut être appliqué pour rééchantillonner les données historiques et générer des prévisions, fournissant une distribution de résultats possibles plutôt qu’une estimation ponctuelle. Cela aide à modéliser l’éventail des scénarios futurs et à créer des intervalles de confiance pour les prédictions. Le bootstrap est également à la base de méthodes d’ensemble comme le bagging en modèles de séries temporelles, qui peuvent réduire le surapprentissage et améliorer la précision globale des prévisions en combinant plusieurs modèles. Notre cours Forecasting in R vous apprendra à rééchantillonner en prévision temporelle, que vous utilisiez la prévision ARIMA ou une autre méthode.
J’espère que vous appréciez désormais le bootstrap, si ce n’était pas déjà le cas. Comme nous l’avons vu, c’est un outil puissant en statistiques et en apprentissage automatique, qui offre une manière élégante d’estimer la variabilité et la confiance des mesures statistiques sans imposer d’hypothèses fortes sur les données sous-jacentes.
Envisagez de commencer notre parcours de carrière Machine Learning Scientist in Python pour devenir à l’aise avec les types de distributions et les jeux de données complexes. Notre parcours de compétences Statistical Inference in R est une autre excellente option, axée sur les tests d’hypothèses, la randomisation et la mesure de l’incertitude.
Formez-vous avec DataCamp
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
Tutoriel
Samuel Shaibu
Tutoriel
Aditya Sharma
Tutoriel
Laiba Siddiqui
Tutoriel
DataCamp Team

