
Tracks
Chuyên gia Khoa học Học máy trong Python
85 giờ
Trong bài viết này, chúng ta sẽ khám phá một kỹ thuật quan trọng trong thống kê và học máy gọi là bootstrapping. Tên gọi bootstrapping bắt nguồn từ cụm từ “tự kéo mình lên bằng quai giày,” bởi vì kỹ thuật thống kê này cho phép bạn làm được rất nhiều với rất ít dữ liệu. Với bootstrapping, bạn có thể lấy một phân phối với bất kỳ hình dạng hay kích thước nào, tạo ra một phân phối mới gồm các mẫu lấy lại, và dùng phân phối mới này để xấp xỉ phân phối xác suất thực. Vì lý do đó, bootstrapping đặc biệt hiệu quả để gán các thước đo độ chính xác như thiên lệch, phương sai, khoảng tin cậy và lỗi dự đoán cho các ước lượng mẫu.
Trước khi bắt đầu, nếu bạn quan tâm đến khoa học dữ liệu, hãy cân nhắc các khóa học của DataCamp về khoa học dữ liệu và thống kê, như lộ trình kỹ năng Suy luận thống kê với R và khóa học Nền tảng suy luận trong Python.
Hãy bắt đầu bằng cách đặt bootstrapping đúng vị trí của nó trong số các phương pháp lấy mẫu lại. Mặc dù có nhiều loại phương pháp lấy mẫu lại khác nhau, chúng có một điểm chung quan trọng: chúng mô phỏng quá trình lấy mẫu. Lý do chúng ta dùng một phương pháp lấy mẫu lại là vì việc liên tục lấy mẫu mới từ quần thể quan tâm không thực tế, và lấy mẫu lại là một kiểu lối tắt.
Ví dụ, khi muốn hiểu điều gì đó về quần thể quan tâm, ta có thể cân nhắc triển khai một khảo sát và kỳ vọng nhận được một nghìn phản hồi. Tuy nhiên, không ai sẽ phát cùng một khảo sát vào quần thể mục tiêu đến một nghìn lần. Chính vì hạn chế thực tiễn này, chúng ta dùng một phương pháp lấy mẫu lại để tạo ra các thống kê về mẫu của mình, chẳng hạn như sai số chuẩn.
Có bốn loại phương pháp lấy mẫu lại chính. Đáng nói đến các phương pháp còn lại vì chúng chung một lịch sử đổi mới và cải tiến thống kê. Đặc biệt, bootstrapping được phát triển như một mở rộng, điều chỉnh hoặc cải tiến của phương pháp jackknife.
Đáng để nói kỹ hơn về jackknife vì đây là tiền thân của bootstrapping, và bootstrapping được giới thiệu như một dạng mở rộng và cải tiến của jackknife, vốn được phát triển vào thập niên 1950 khi máy tính chỉ có khoảng một kilobyte bộ nhớ.
Jackknife là phương pháp “loại-bỏ-một” trong lấy mẫu lại để tính một thống kê quan tâm; nó thực hiện tuần tự hoặc lặp lại cho đến khi từng quan sát đã được loại bỏ. Với jackknife, số lần lấy mẫu lại bị giới hạn bởi số quan sát, và chủ yếu vì lý do này, jackknife hoạt động kém hơn một chút với kích thước mẫu nhỏ. Jackknife cũng hơi hạn chế về kiểu dữ liệu có thể sử dụng. Mặt khác, khác với bootstrap, jackknife có thể tái lập giống nhau mỗi lần.
Bootstrapping có phạm vi ứng dụng rộng trong cả thống kê và học máy. Một trong những cách dùng phổ biến nhất là ước lượng khoảng tin cậy khi phân phối nền tảng không biết hoặc khi kích thước mẫu nhỏ. Khả năng này khiến bootstrapping đặc biệt hữu ích trong các tình huống mà các phương pháp tham số truyền thống có thể không phù hợp.
Ngoài ra, bootstrapping thường được dùng trong kiểm định giả thuyết và thẩm định mô hình, nơi nó giúp đánh giá độ bền vững của dự đoán mô hình. Trong học máy, bootstrapping là nền tảng của phương pháp tổ hợp phổ biến gọi là bagging, được dùng trong các mô hình như rừng ngẫu nhiên để cải thiện độ chính xác bằng cách giảm phương sai.
Để minh họa bootstrapping, chúng ta cần dùng một ngôn ngữ lập trình như R vì nó cho phép tạo nhiều bộ dữ liệu lấy mẫu lại; nếu không có môi trường lập trình, quy trình này quá tốn thời gian và phức tạp để làm thủ công. Trong bài viết này, chúng ta sẽ xem cách bootstrap khoảng tin cậy cho một phân phối và cả cho hồi quy tuyến tính bằng bộ dữ liệu Fish Market trên Kaggle.
Trước khi xem bootstrapping đúng nghĩa, sẽ hữu ích khi làm quen với ý tưởng lấy mẫu có hoàn lại. Ở đây, hàm cơ bản sample() trong R nhận ít nhất hai đối số cần được chỉ định rõ trong lời gọi hàm: x và size. x quyết định danh sách hoặc phạm vi giá trị mà từ đó ta chọn để tạo mẫu, và size quyết định kích thước mẫu. Có một đối số bổ sung thường được chỉ định rõ là đối số replace. Nếu không quyết định khác, mặc định là replace = FALSE.
Bootstrapping là lấy mẫu có hoàn lại. Khi lấy mẫu có hoàn lại, ta đưa giá trị vừa rút trở lại sau mỗi lần rút. Do đó, mỗi lần rút là độc lập với giá trị trước đó. Khi lấy mẫu không hoàn lại, ta không trả lại các giá trị, nên khi một giá trị đã được chọn, nó không thể được chọn lại; vì vậy có thể nói hai giá trị mẫu không độc lập, và giá trị ở một lần rút ảnh hưởng đến khả năng các giá trị ở lần rút tiếp theo. Hệ quả là ta không thể chọn kích thước mẫu lớn hơn kích thước của vector đầu vào trừ khi đặt replace = TRUE. Bootstrapping không gặp vấn đề này, và ta có thể tạo một bộ dữ liệu lấy mẫu lại theo bootstrap lớn hơn nhiều so với dữ liệu gốc.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Giờ hãy tải bộ dữ liệu và đọc nó từ thư mục tải xuống vào RStudio bằng hàm read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Bắt đầu, trước tiên hãy tạo biểu đồ histogram của căn bậc hai trọng lượng cá để xem phân phối của chúng ta. Phân phối này, như ta thấy, cách xa phân phối chuẩn, hay phân phối Gaussian. Nếu có gì đó, nó hơi hai đỉnh.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")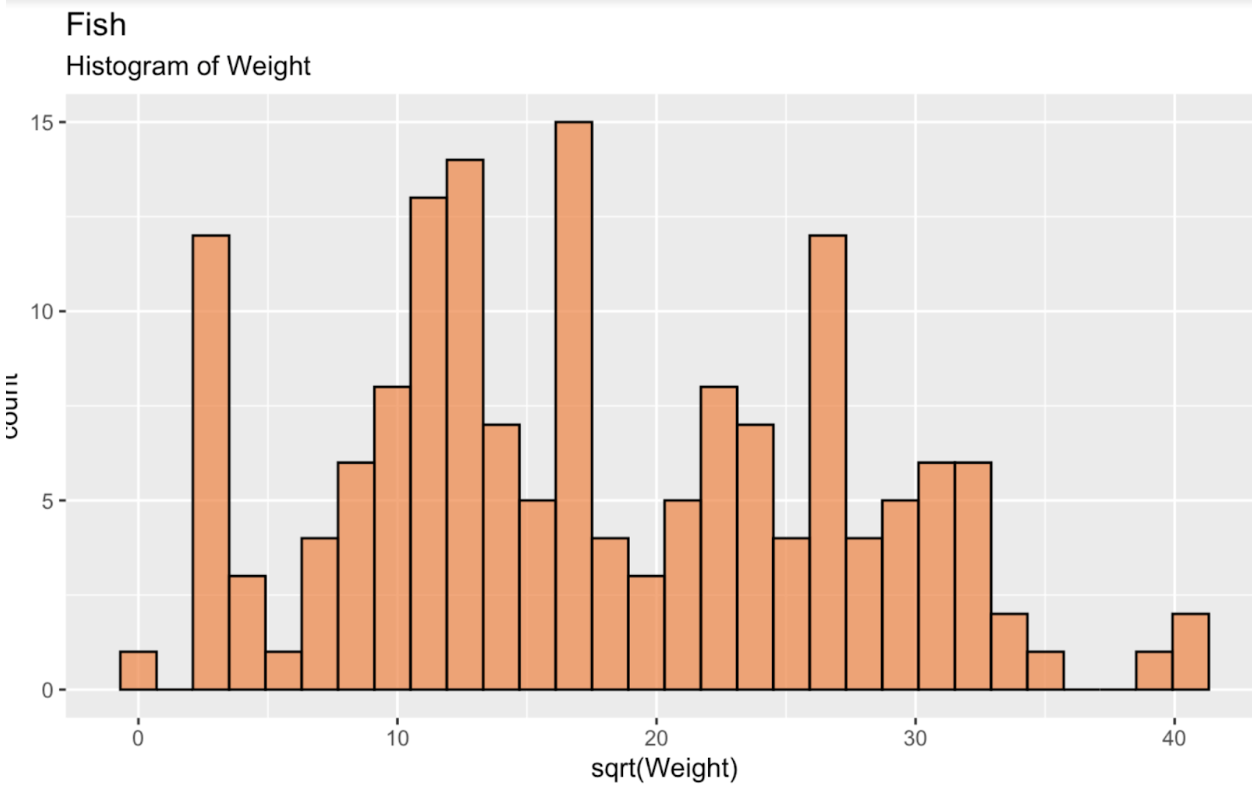
Histogram trọng lượng cá. Ảnh: Tác giả.
Chúng ta có thể bootstrap trong R bằng cách sử dụng gói infer từ thư viện tidymodels. In bảng này ra console sẽ cho ta một data frame gồm thống kê mong muốn cho mỗi lần lặp. Khi ta tạo một phân phối mới từ các lần lặp này, phân phối đó sẽ là phân phối chuẩn, từ đó ta có thể tạo ra khoảng tin cậy.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")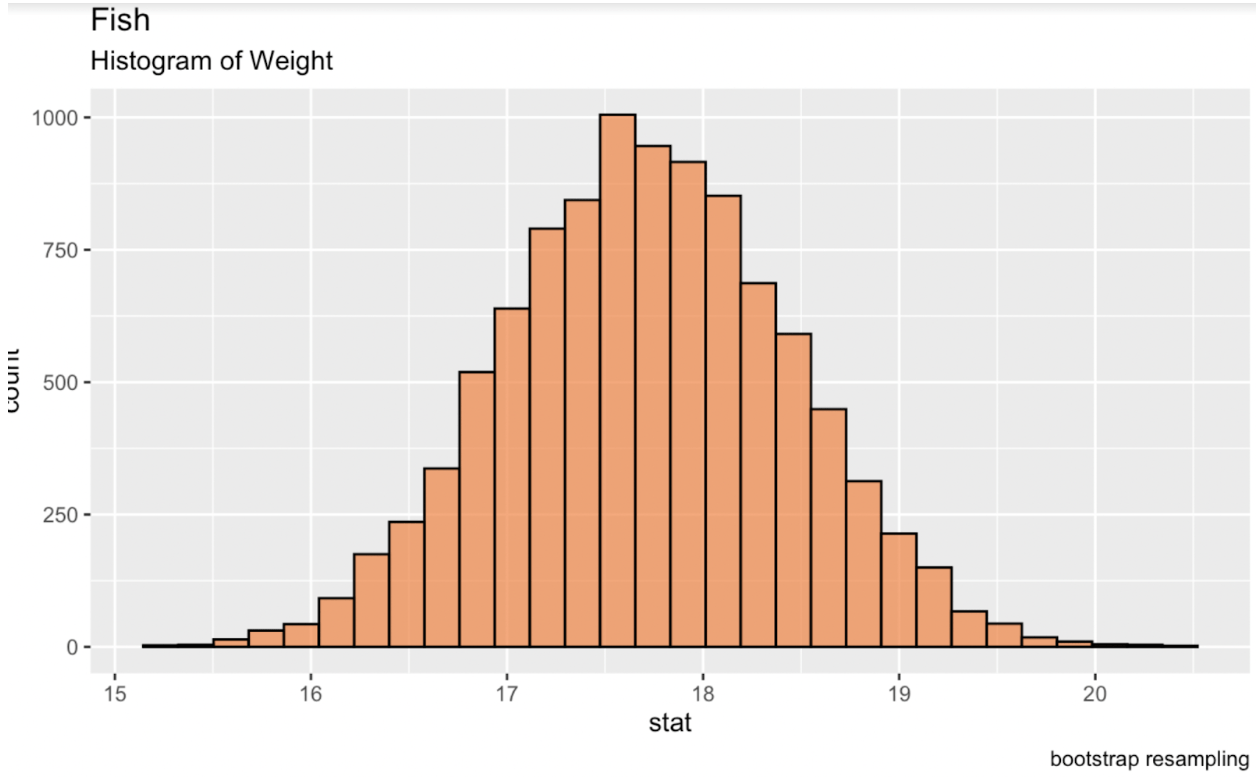 Histogram trung bình bootstrap của trọng lượng cá. Ảnh: Tác giả.
Histogram trung bình bootstrap của trọng lượng cá. Ảnh: Tác giả.
Hồi quy tuyến tính, nền tảng của mô hình hóa thống kê, được dùng để thể hiện mối quan hệ giữa một hoặc nhiều biến độc lập và một biến phụ thuộc. Khi làm việc với các mô hình hồi quy, việc đánh giá độ bất định quanh các ước lượng là điều phổ biến. Một cách để làm điều này là tính khoảng tin cậy cho hồi quy tuyến tính, cung cấp một khoảng giá trị trong đó tham số thực, như trung bình, có khả năng nằm. Ở đây, chúng ta sẽ tạo khoảng tin cậy bằng bootstrapping, và cũng tạo khoảng tin cậy bằng phương pháp xấp xỉ chuẩn, còn gọi là khoảng tin cậy Wald.
Trong bối cảnh hồi quy tuyến tính, lấy mẫu lại bootstrap liên quan đến việc lấy mẫu ngẫu nhiên từ bộ dữ liệu để tạo nhiều mẫu bootstrap. Sau đó ta khớp một mô hình hồi quy cho mỗi mẫu. Cuối cùng, ta dùng phân phối của các hệ số mô hình trên các mẫu này để ước lượng khoảng tin cậy. Trong đoạn mã sau, chúng ta dùng hàm bootstraps() từ gói tidymodels để thực hiện lấy mẫu lại bootstrap trên bộ dữ liệu. Sau đó, ta tạo các biểu đồ histogram để hiển thị phạm vi giá trị xuất hiện trong các mẫu bootstrap cho hệ số chặn và hệ số trọng lượng.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')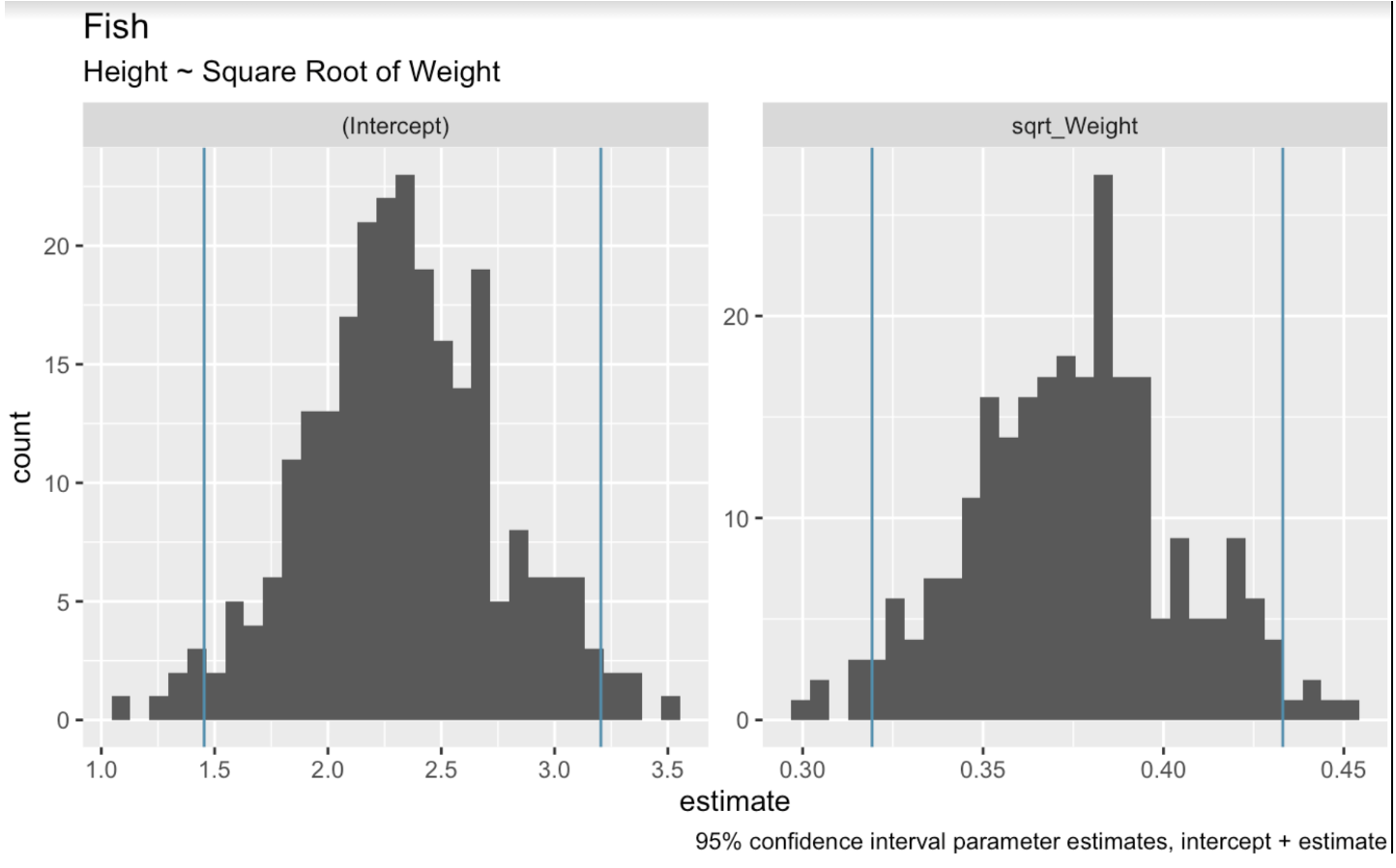
Các hệ số mô hình tuyến tính sau bootstrapping. Ảnh: Tác giả.
Khi vẽ các đường hồi quy khả dĩ, chúng ta sẽ cắt bớt những đường cực trị ở hai đầu để thu được khoảng 95%. Hàm int_pctl() giúp việc này trở nên dễ dàng.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Bước cuối cùng, hãy tạo các khoảng tin cậy được sinh ra từ các phương trình dạng đóng, mang tính lý thuyết hơn. Ta có thể tìm các tham số bằng cách gọi summary() của đối tượng mô hình tuyến tính.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Ở đây, hệ số ước lượng cho biến sqrt_Weight là 0,37569. Sai số chuẩn cho sqrt_Weight là 0,02186. Bậc tự do là 157 (tức 159 quan sát trong bộ dữ liệu trừ đi hai tham số ước lượng). Và giá trị t cho khoảng tin cậy 95% hai phía là 1,975189. Ta biết con số cuối cùng này thông qua hàm qt(): qt(0.975, 157). Trong hình dưới, các đường màu xanh là các đường hồi quy tuyến tính bootstrap, còn các đường đỏ đứt đoạn là khoảng tin cậy sinh ra bởi công thức phân tích thông dụng.
# Wald confidence interval(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")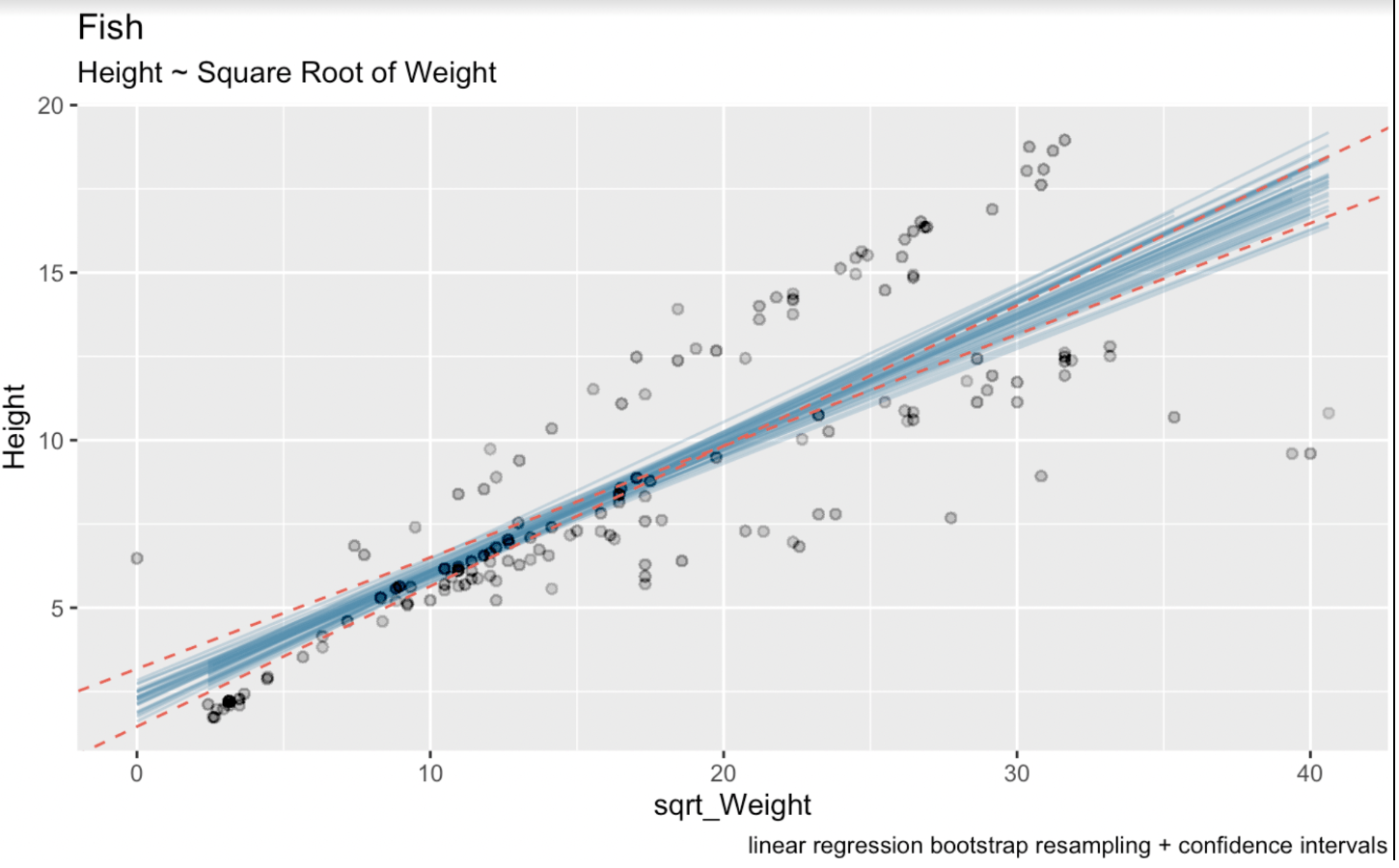
Hồi quy tuyến tính bootstrap với khoảng tin cậy. Ảnh: Tác giả.
Ở đây, ta có thể thấy rõ rằng quy trình lấy mẫu lại bằng bootstrapping đã đưa thêm một chút bất định vào ước lượng của chúng ta. Điều này là vì các khoảng cho hệ số hồi quy tuyến tính được tính bằng các công thức lý thuyết dựa trên các giả định về phân phối sai số và đặc tính của bộ ước lượng. Các công thức này dựa vào các giả định như sai số có phân phối chuẩn và phương sai không đổi.
Ngược lại, lấy mẫu lại bootstrap là phi tham số (distribution-free), tức là đưa ra rất ít giả định về phân phối dữ liệu nền tảng. Thay vào đó, bootstrapping ước lượng trực tiếp phân phối lấy mẫu của thống kê quan tâm bằng cách lấy mẫu lại từ dữ liệu quan sát. Kết quả là, khoảng tin cậy bootstrap có thể mạnh mẽ và đáng tin cậy hơn khi các giả định của phương pháp truyền thống bị vi phạm hoặc khi làm việc với kích thước mẫu nhỏ, như trong bộ dữ liệu Fish Market của chúng ta với 159 quan sát.
Trong bootstrapping tham số, ta đưa ra các giả định về phân phối nền tảng của dữ liệu và tạo các mẫu dựa trên những giả định đó. Phương pháp này hữu ích khi bạn có hiểu biết trước hoặc các giả định mạnh về phân phối của dữ liệu. Hãy nghĩ về một bộ dữ liệu lấy mẫu có thể không có phân phối chuẩn, nhưng ý tưởng đằng sau việc lấy mẫu được biết rõ hơn, nên bạn có thể tạo một phân phối bằng cách dùng các tham số từ quần thể.
Ngược lại, bootstrapping phi tham số không đưa ra giả định nào về phân phối dữ liệu. Nó lấy mẫu trực tiếp từ dữ liệu quan sát có hoàn lại, khiến nó đặc biệt hữu ích khi phân phối thực không biết hoặc khó xác định. Trong ví dụ trên, chúng ta đã dùng bootstrapping phi tham số. Cả hai phương pháp đều cho phép bạn ước lượng các thống kê như sai số chuẩn và khoảng tin cậy. Tuy nhiên, bootstrapping phi tham số linh hoạt hơn cho các bộ dữ liệu thực tế, đặc biệt khi làm việc với mẫu nhỏ hoặc phức tạp, và thường được dùng hơn trong thực hành.
Trong dự báo chuỗi thời gian, bootstrapping có thể được áp dụng để lấy mẫu lại dữ liệu lịch sử và tạo ra các dự báo tương lai, cung cấp một phân phối các kết quả khả dĩ thay vì một ước lượng điểm duy nhất. Điều này giúp mô hình hóa phạm vi các kịch bản tương lai tiềm năng và tạo khoảng tin cậy cho dự đoán. Bootstrapping cũng là nền tảng của các phương pháp tổ hợp như bagging trong mô hình chuỗi thời gian, có thể giảm quá khớp và cải thiện độ chính xác tổng thể của dự báo bằng cách kết hợp nhiều mô hình. Khóa học Dự báo trong R của chúng tôi sẽ dạy bạn cách lấy mẫu lại trong dự báo thời gian, dù bạn dùng dự báo ARIMA hay phương pháp khác.
Hy vọng bạn đã thêm trân trọng bootstrapping, nếu trước đây chưa. Như chúng ta đã thấy, bootstrapping là một công cụ mạnh mẽ trong cả thống kê và học máy, và mang đến một cách thú vị để ước lượng độ biến thiên và mức độ tin cậy của các thước đo thống kê mà không cần các giả định mạnh về dữ liệu nền tảng.
Hãy cân nhắc bắt đầu lộ trình nghề nghiệp Nhà khoa học học máy với Python và bạn chắc chắn sẽ trở thành chuyên gia trong làm việc với các loại phân phối và bộ dữ liệu phức tạp. Lộ trình kỹ năng Suy luận thống kê với R là một lựa chọn tuyệt vời khác với trọng tâm vào kiểm định giả thuyết, ngẫu nhiên hóa và đo lường bất định.
Học cùng DataCamp
Tracks
Courses
Courses