
Program
Makine Öğrenimi Bilimcisi Python'da
85 sa
Bu yazıda, istatistik ve makine öğrenmesinde önemli bir teknik olan bootstrapping’i inceleyeceğiz. Bootstrapping, ‘kendi çizmelerinizin askılarından tutup kendinizi yukarı çekmek’ deyiminden adını alır; çünkü bu istatistiksel teknik, çok az veriyle çok şey yapmanıza olanak tanır. Bootstrapping ile herhangi bir şekil veya boyuttaki bir dağılımdan yeniden örneklemelerle yeni bir dağılım oluşturabilir ve bu yeni dağılımı gerçek olasılık dağılımını yaklaştırmak için kullanabilirsiniz. Bu nedenle bootstrapping, örnek tahminlerine önyargı, varyans, güven aralıkları ve tahmin hatası gibi doğruluk ölçüleri atamanın özellikle etkili bir yoludur.
Başlamadan önce, veri bilimiyle ilgileniyorsanız, R ile İstatistiksel Çıkarım beceri yolu ve Python’da Çıkarımın Temelleri kursumuz gibi DataCamp’teki veri bilimi ve istatistik kurslarını göz önünde bulundurun.
Önce bootstrapping’i yeniden örnekleme yöntemleri arasındaki yerine doğru şekilde oturtalım. Farklı türlerde yeniden örnekleme yöntemleri olsa da, ortak bir noktaları vardır: örnekleme sürecini taklit ederler. Yeniden örnekleme yöntemi kullanmamızın nedeni, ilgi duyduğumuz popülasyondan sürekli yeni örnekler almak pratik olmadığından, yeniden örneklemenin bir tür kestirme yol olmasıdır.
Örneğin, ilgi duyduğumuz popülasyon hakkında bir şeyler anlamak istediğimizde bir anket yapmayı ve bin yanıt almayı düşünebiliriz. Ancak kimse aynı anketi hedef popülasyona bin kez uygulamaz. Bu pratik sınırlama nedeniyle, örneğimiz hakkında standart hata gibi istatistikler üretmek için bir yeniden örnekleme yöntemi kullanırız.
Dört ana yeniden örnekleme yöntemi vardır. Diğer yöntemlerden de bahsetmeye değer; çünkü istatistiksel yenilik ve iyileştirme tarihinde ortak bir geçmişi paylaşırlar. Özellikle bootstrapping, 1950’lerde bilgisayarların yaklaşık bir kilobayt belleğe sahip olduğu dönemde geliştirilen jackknife yönteminin bir uzantısı, değişikliği ya da iyileştirmesi olarak ortaya çıkmıştır.
Özellikle jackknife hakkında biraz konuşmak faydalıdır; çünkü jackknife, bootstrapping’in öncüsüdür ve bootstrapping, jackknife’ın bir tür uzantısı ve iyileştirmesi olarak tanıtılmıştır; jackknife, bilgisayarların yaklaşık bir kilobayt belleğe sahip olduğu 1950’lerde geliştirilmiştir.
Jackknife, ilgi duyulan bir istatistiğin hesaplandığı, her gözlemin teker teker çıkarıldığı bir bırak-bir yöntemi (leave-one-out)dir; bu işlem, her gözlem çıkarılıncaya kadar art arda/iteratif olarak yapılır. Jackknife’ta yeniden örnekleme sayısı, gözlem sayısıyla sınırlıdır ve büyük ölçüde bu nedenle küçük örneklemlerde biraz zayıf performans gösterir. Jackknife, kullanılabilecek veri türleri açısından da biraz sınırlıdır. Öte yandan, bootstrap’in aksine, jackknife her seferinde birebir yeniden üretilebilir.
Bootstrapping, hem istatistikte hem de makine öğrenmesinde çok geniş bir uygulama yelpazesine sahiptir. En yaygın kullanımlarından biri, temel dağılımın bilinmediği veya örneklem büyüklüklerinin küçük olduğu durumlarda güven aralıklarını tahmin etmektir. Bu özellik, geleneksel parametrik yöntemlerin uygun olmayabileceği durumlarda bootstrapping’i özellikle değerli kılar.
Ayrıca bootstrapping, sıklıkla hipotez testi ve model doğrulamada kullanılır; bir modelin tahminlerinin sağlamlığını değerlendirmeye yardımcı olabilir. Makine öğrenmesinde bootstrapping, varyansı azaltarak doğruluğu artıran bagging olarak bilinen popüler topluluk yönteminin temelini oluşturur; bu yöntem, rastgele ormanlar gibi modellerde kullanılır.
Bootstrapping’i göstermek için R gibi bir programlama dili kullanmamız gerekir; çünkü birden fazla yeniden örneklenmiş veri kümesi oluşturmayı sağlar; programlama ortamı olmadan süreç elle yapılamayacak kadar zaman alıcı ve karmaşık olur. Bu yazıda, Kaggle’daki Fish Market veri kümesini kullanarak bir dağılım ve bir doğrusal regresyon için güven aralıklarını nasıl bootstrap edeceğimizi ele alacağız.
Bootstrapping’e geçmeden önce, yerine koyarak örnekleme fikrine aşina olmak faydalıdır. Burada, temel R sample() fonksiyonu, çağrıda açıkça belirlenmesi gereken en az iki argüman alır: x ve size. x, örneğimizi seçtiğimiz değerlerin listesini veya aralığını, size ise örneklemimizin büyüklüğünü belirler. Sıklıkla açıkça belirtilen ek bir argüman da replace argümanıdır. Aksi belirtilmedikçe varsayılan olarak replace = FALSE atanır.
Bootstrapping, yerine koyarak örneklemedir. Yerine koyarak örneklediğimizde, her örneklemeden sonra değeri geri koyarız. Bu nedenle her örnek, kendisinden önce gelen değerden bağımsızdır. Yerine koymadan örneklediğimizde değerleri geri koymayız; dolayısıyla bir değer seçildiğinde tekrar seçilemez; iki örnekleme değeri bağımsız değildir ve bir örneklemede elde ettiğimiz değer, bir sonraki örneklemede gelecek değerlerin olasılığını etkiler. Bunun bir sonucu olarak, replace = TRUE belirtmedikçe, örneklem büyüklüğünü girdi vektörünün boyutundan daha büyük seçemeyiz. Bootstrapping’de bu sorunla karşılaşmayız ve orijinalimizden çok daha büyük bir bootstrap yeniden örneklenmiş veri kümesi üretebiliriz.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Şimdi veri kümemizi indirelim ve read.csv() fonksiyonunu kullanarak RStudio’da indirmeler klasörümüzden okuyalım.
fish_df <- read.csv('~/Downloads/FISH.csv')Başlamak için, dağılımımızı görmek amacıyla balık ağırlığının karekökünün bir histogramını oluşturalım. Bu dağılım, görüldüğü gibi normal ya da Gauss dağılımı olmaktan uzaktır. Hatta kısmen iki tepelidir.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")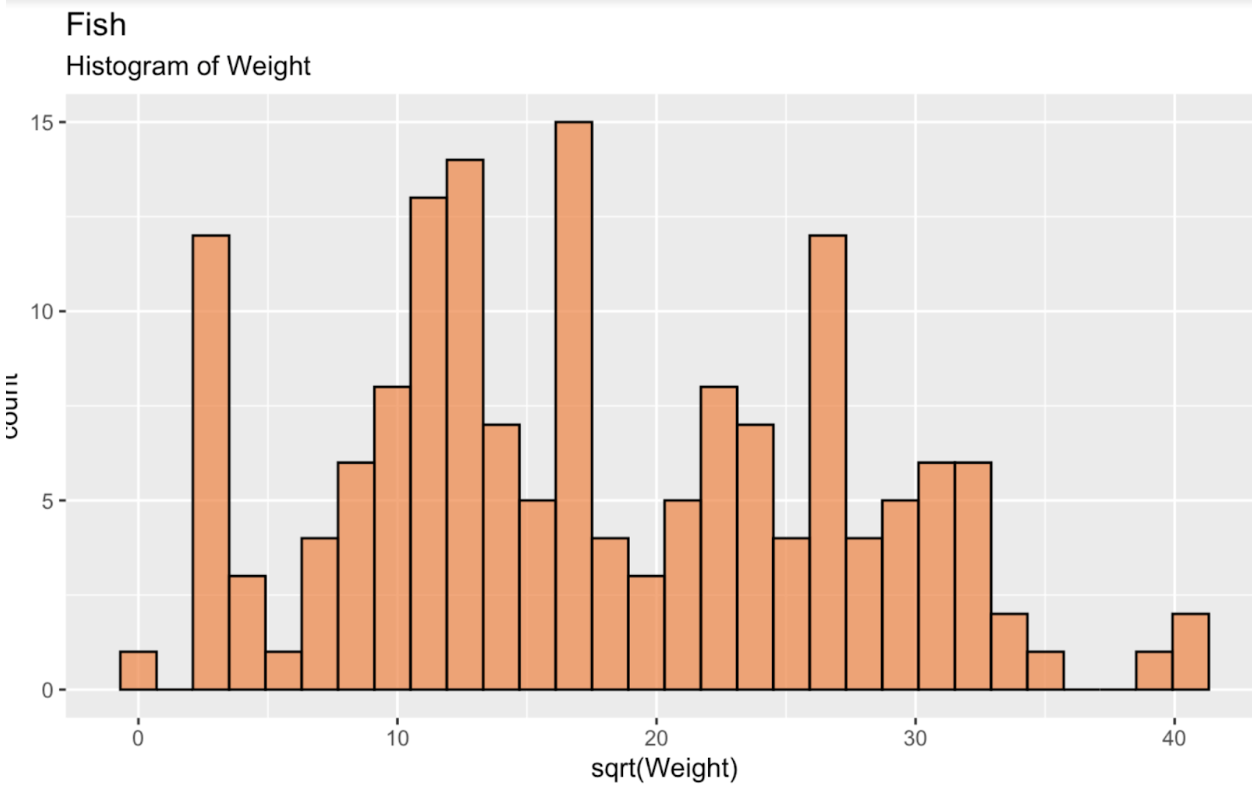
Balık ağırlığı histogramı. Görsel: Yazar.
R’de tidymodels kütüphanesindeki infer paketini kullanarak bootstrap yapabiliriz. Bu tabloyu konsola yazdırmak, her yineleme için istenen istatistiğin yer aldığı bir veri çerçevesi verir. Bu yinelemelerden yeni bir dağılım oluşturduğumuzda, bu dağılım bir normal dağılım olacak ve buradan güven aralıkları üretebileceğiz.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")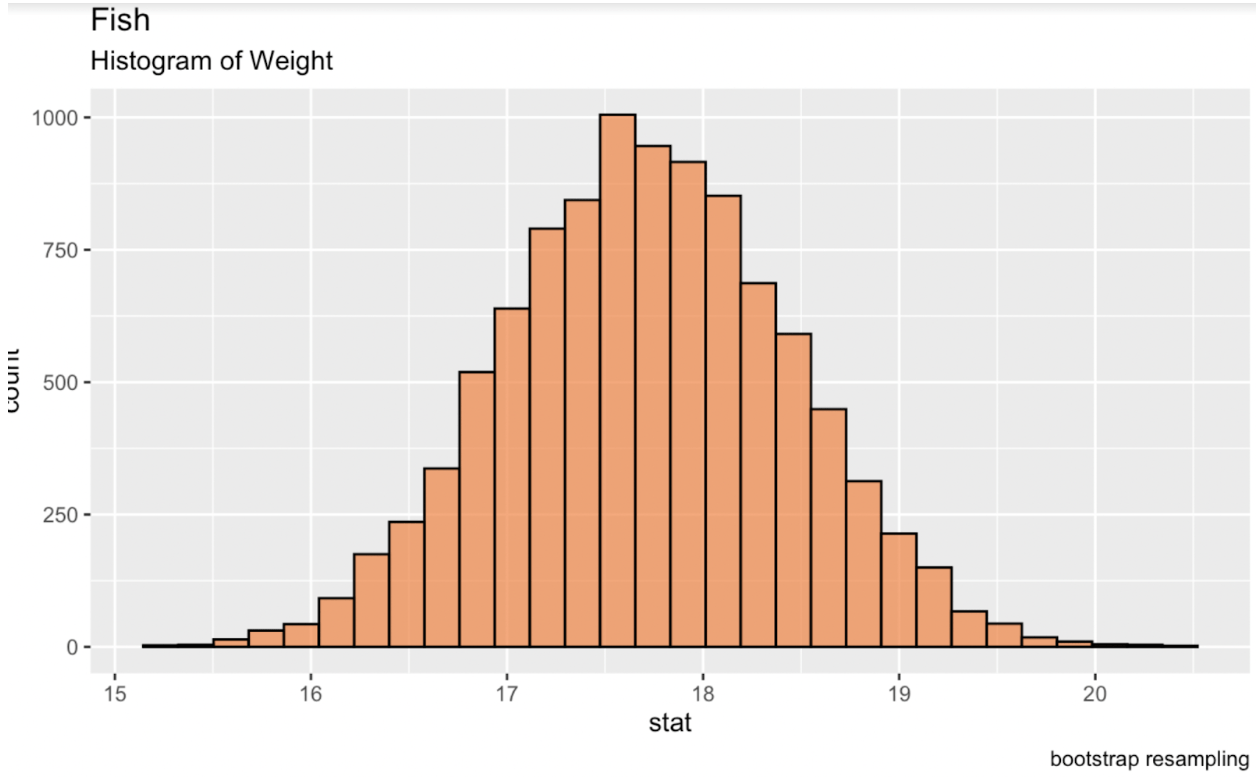 Balık ağırlığının bootstrap ortalamasının histogramı. Görsel: Yazar.
Balık ağırlığının bootstrap ortalamasının histogramı. Görsel: Yazar.
Doğrusal regresyon, istatistiksel modellemenin temel taşıdır ve bir veya daha fazla bağımsız değişken ile bir bağımlı değişken arasındaki ilişkiyi göstermede kullanılır. Regresyon modelleriyle çalışırken, tahminlerimiz etrafındaki belirsizliği değerlendirmek yaygındır. Bunu yapmanın bir yolu, ortalama gibi gerçek parametrenin yer alması muhtemel değer aralığını sağlayan doğrusal regresyon güven aralıklarını hesaplamaktır. Burada, bootstrapping kullanarak güven aralıkları oluşturacağız ve ayrıca normal yaklaşım yöntemiyle, yani Wald güven aralığıyla da güven aralıkları oluşturacağız.
Doğrusal regresyon bağlamında bootstrap yeniden örnekleme, veri kümesinden rastgele örnekleme yaparak birden çok bootstrap örneği oluşturmayı içerir. Daha sonra her örneğe bir regresyon modeli uydururuz. Son olarak, bu örnekler boyunca model katsayılarının dağılımını kullanarak güven aralıklarını tahmin ederiz. Aşağıdaki kodda, veri setimiz üzerinde bootstrap yeniden örnekleme yapmak için tidymodels paketindeki bootstraps() fonksiyonunu kullanıyoruz. Ardından kesişim ve ağırlık katsayıları için bootstrap yeniden örneklemelerimizde yer alan değer aralıklarını göstermek üzere histogramlar oluşturuyoruz.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')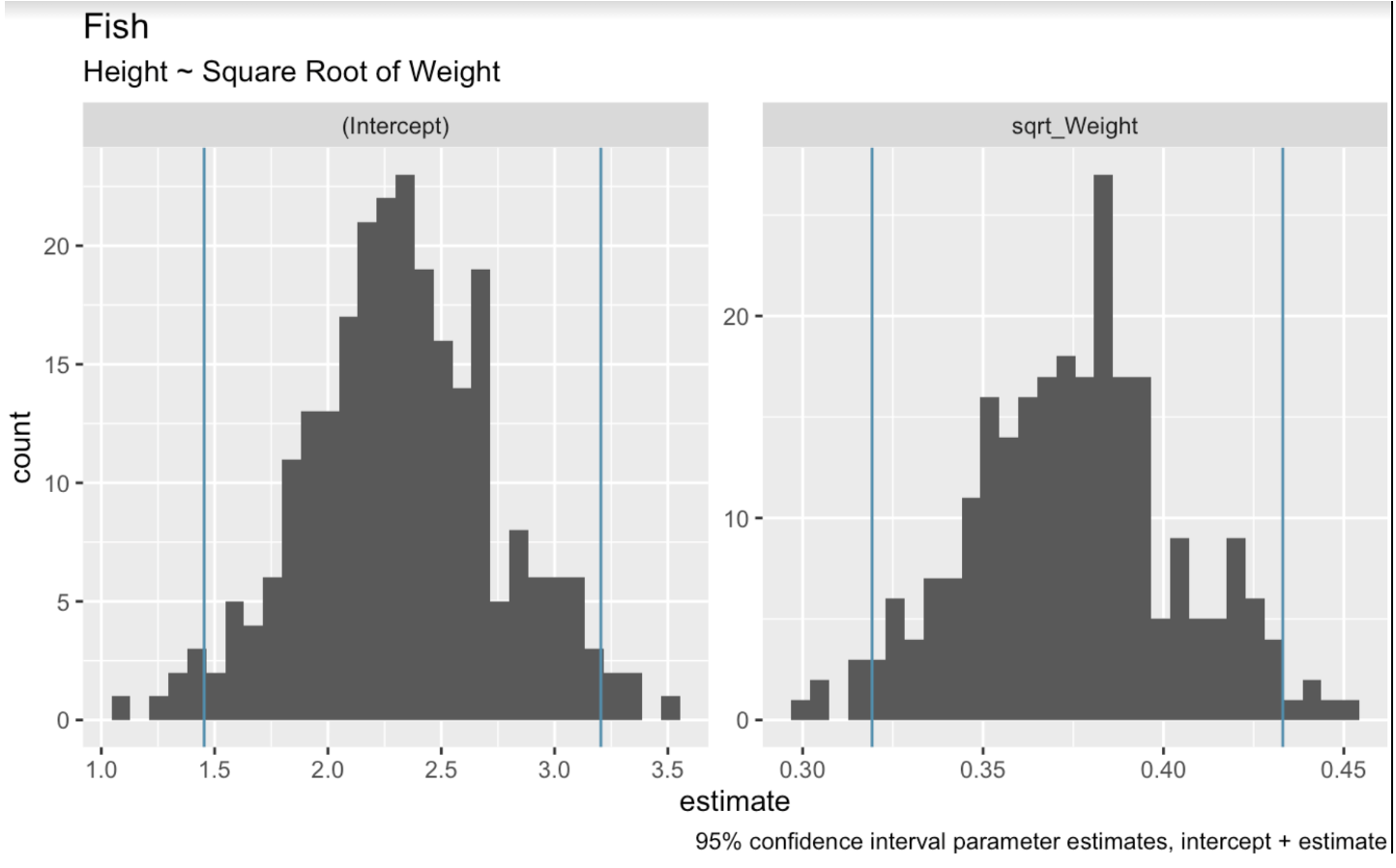
Doğrusal modelin bootstrap edilmiş katsayıları. Görsel: Yazar.
Olası regresyon doğrularımızı grafiğe dökerken, %95 aralık elde etmek için her iki uçtaki en uç doğruları kırpacağız. int_pctl() fonksiyonu bunu kolaylaştırır.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Son adım olarak, şimdi daha teorik, kapalı form denklemlerinden üretilecek güven aralıklarını oluşturalım. Parametreleri, doğrusal model nesnemizin summary() çağrısıyla bulabiliriz.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Burada, sqrt_Weight değişkeni için tahmin edilen katsayı 0.37569’dur. sqrt_Weight için standart hata 0.02186’dır. Serbestlik derecesi 157’dir (veri kümemizdeki 159 gözlem eksi iki tahmin edilen parametre). Ve %95 iki kuyruklu güven aralığı için t-değeri 1.975189’dur. Bu son sayıyı qt() fonksiyonundan biliyoruz: qt(0.975, 157). Aşağıdaki görselleştirmede mavi çizgiler bootstrap edilmiş doğrusal regresyon doğrularını, kırmızı noktalı çizgiler ise yaygın analitik formülle üretilen güven aralığını göstermektedir.
# Wald confidence interval(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")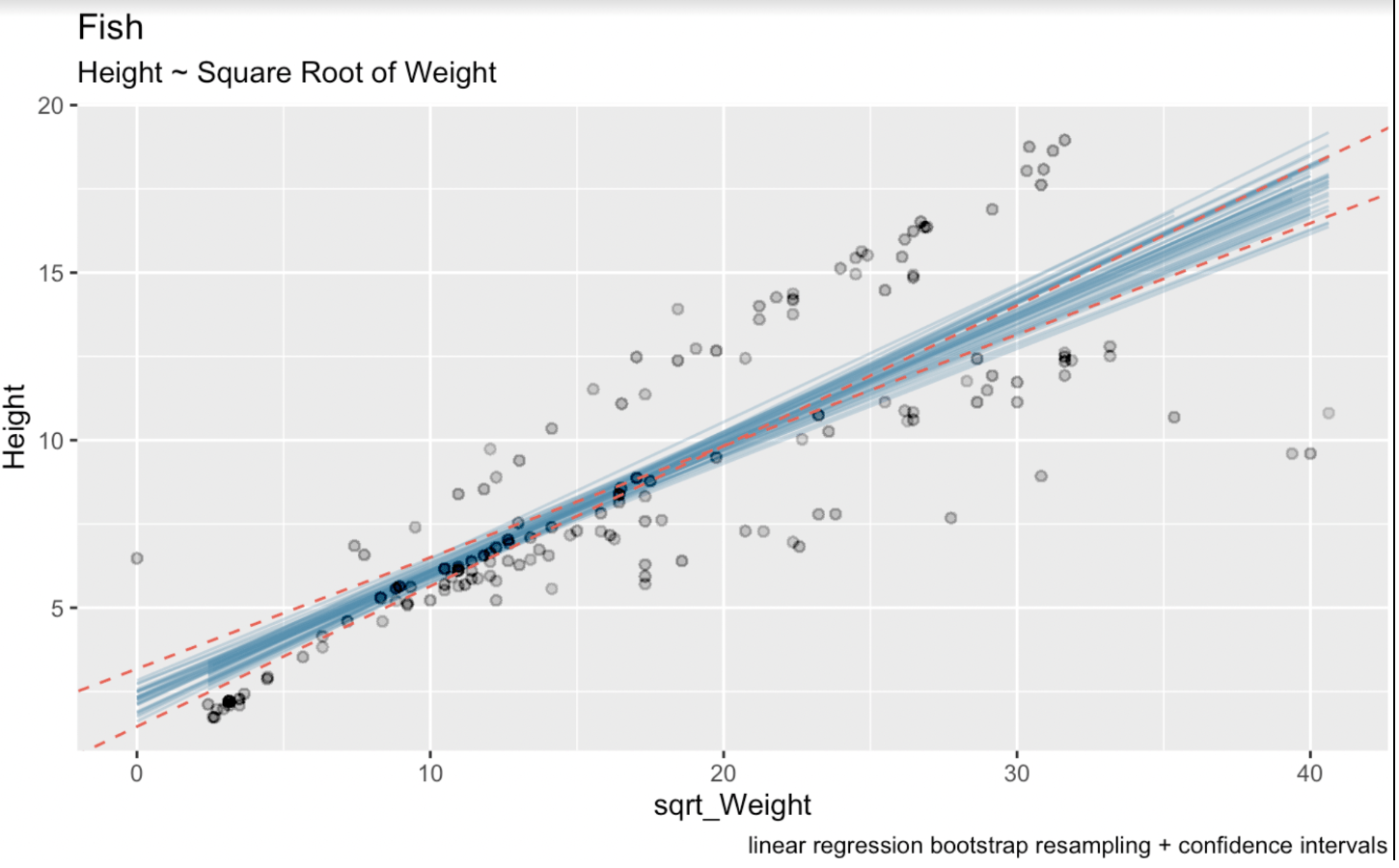
Güven aralıklarıyla bootstrap edilmiş doğrusal regresyonlar. Görsel: Yazar.
Burada açıkça görüyoruz ki, bootstrap yeniden örnekleme sürecimiz tahminimizde biraz daha fazla belirsizlik getirmiştir. Bunun nedeni, doğrusal regresyon katsayıları için aralıkların, hataların dağılımı ve tahmin edicinin özellikleri hakkındaki varsayımlara dayanan teorik formüllerle hesaplanmış olmasıdır. Bu formüller, hata terimlerinin normalliği ve sabit varyans gibi varsayımlara dayanır.
Öte yandan bootstrap yeniden örnekleme dağılımdan bağımsızdır; yani altta yatan veri dağılımı hakkında asgari varsayımda bulunur. Bunun yerine, ilgi duyduğumuz istatistiğin örnekleme dağılımını doğrudan gözlenen verilerden yeniden örnekleyerek tahmin eder. Sonuç olarak, geleneksel yöntemlerin varsayımları ihlal edildiğinde veya küçük örneklem büyüklükleriyle çalışırken (159 gözleme sahip Fish Market veri kümesi örneğinde olduğu gibi) bootstrap güven aralıkları daha sağlam ve güvenilir olabilir.
Parametrik bootstrapping’de, verilerin altta yatan dağılımı hakkında varsayımlar yapılır ve yeniden örneklemeler bu varsayımlara dayanarak üretilir. Bu yöntem, verilerin dağılımı hakkında önceden bilgiye veya güçlü varsayımlara sahip olduğunuzda kullanışlıdır. Normal dağılıma sahip olmayabilecek bir örnekleme veri kümesini düşünün; ancak örneklemenin ardındaki fikir daha iyi biliniyordur ve popülasyondan gelen parametrelerle bir dağılım oluşturabilirsiniz.
Parametrik olmayan bootstrapping ise verilerin dağılımı hakkında hiçbir varsayımda bulunmaz. Yerine koyarak doğrudan gözlenen verilerden yeniden örnekler ve bu da gerçek dağılımın bilinmediği veya tanımlaması zor olduğu durumlarda özellikle değerlidir. Yukarıdaki örneğimizde parametrik olmayan bootstrapping kullandık. Her iki yöntem de standart hatalar ve güven aralıkları gibi istatistikleri tahmin etmenize olanak tanır. Ancak parametrik olmayan bootstrapping, özellikle küçük veya karmaşık örneklerle çalışırken gerçek dünya veri setleri için daha fazla esneklik sunar ve pratikte daha yaygın olarak kullanılır.
Zaman serisi tahminlerinde, bootstrapping geçmiş verileri yeniden örneklemek ve geleceğe yönelik tahminler üretmek için uygulanabilir; bu da tek bir nokta tahmini yerine olası sonuçların bir dağılımını sağlar. Bu yaklaşım, potansiyel gelecek senaryolarının yelpazesini modellemeye ve tahminler için güven aralıkları oluşturmaya yardımcı olur. Bootstrapping ayrıca zaman serisi modellerinde bagging gibi topluluk yöntemlerinin temelini oluşturur; bu yöntemler, birden çok modeli birleştirerek aşırı uyumu azaltabilir ve tahminin genel doğruluğunu artırabilir. R ile Tahminleme kursumuz, ARIMA tahminleme veya başka bir yöntem kullanmanız fark etmeksizin, zaman serisi tahminlemede yeniden örneklemeyi nasıl yapacağınızı öğretecektir.
Eğer daha önce etmiyorsanız, umarım bootstrapping’i takdir etmeye başlamışsınızdır. Gördüğümüz gibi bootstrapping, hem istatistikte hem de makine öğrenmesinde güçlü bir araçtır ve altta yatan veriler hakkında güçlü varsayımlar gerektirmeden istatistiksel ölçümlerin değişkenliğini ve güvenini tahmin etmenin ilginç bir yolunu sunar.
Python ile Makine Öğrenimi Bilimcisi kariyer yolumuza başlamayı düşünün; dağılım türleri ve karmaşık veri kümeleriyle çalışmada uzmanlaşacağınızdan emin olabilirsiniz. R ile İstatistiksel Çıkarım beceri yolumuz da hipotez testi, rastgeleleştirme ve belirsizliğin ölçülmesine odaklanan harika bir seçenektir.
DataCamp ile Öğrenin
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
