
Programa
Cientista de machine learning em Python
85 h
Neste artigo, vamos explorar uma técnica importante em estatística e machine learning chamada bootstrapping. O nome vem da expressão “pulling yourself up by your bootstraps” porque, com muito pouco, é possível fazer bastante. Com bootstrapping, você pode pegar uma distribuição de qualquer formato ou tamanho, criar uma nova distribuição de reamostras e usá-la para aproximar a verdadeira distribuição de probabilidades. Por isso, o bootstrapping é especialmente eficaz para atribuir medidas de precisão como viés, variância, intervalos de confiança e erro de predição a estimativas amostrais.
Antes de começar, se você se interessa por ciência de dados, vale conferir estes cursos da DataCamp sobre ciência de dados e estatística, como a nossa trilha de habilidades Statistical Inference in R e o curso Foundations of Inference in Python.
Vamos posicionar o bootstrapping corretamente entre os métodos de reamostragem. Embora existam diferentes tipos, todos têm algo importante em comum: eles imitam o processo de amostragem. Usamos reamostragem porque não é prático continuar coletando novas amostras da população de interesse — a reamostragem funciona como um atalho.
Por exemplo, quando queremos entender algo sobre a população-alvo, podemos pensar em aplicar uma pesquisa e esperar mil respostas. Mas ninguém vai aplicar a mesma pesquisa mil vezes para a mesma população. Por essa limitação prática, usamos um método de reamostragem para gerar estatísticas sobre a nossa amostra, como o erro-padrão.
Há quatro tipos principais de reamostragem. Vale citar os demais porque compartilham uma história comum de inovação e aprimoramento estatístico. Em particular, o bootstrapping foi desenvolvido como uma extensão, modificação ou melhoria do método jackknife.
Vale falar um pouco do jackknife porque ele é um precursor do bootstrapping, apresentado como uma extensão e melhoria do jackknife, criado nos anos 1950, quando computadores tinham cerca de 1 kilobyte de memória.
O jackknife é um método leave-one-out que calcula uma estatística de interesse, repetindo o processo até que cada observação tenha sido removida. No jackknife, o número de reamostras é limitado ao número de observações e, em grande parte por isso, ele tende a ter desempenho inferior com amostras pequenas. Também é mais limitado quanto aos tipos de dados que pode usar. Por outro lado, ao contrário do bootstrap, o jackknife é totalmente reprodutível.
O bootstrapping tem uma ampla gama de aplicações em estatística e machine learning. Um uso comum é estimar intervalos de confiança quando a distribuição subjacente é desconhecida ou quando os tamanhos amostrais são pequenos. Isso o torna valioso em situações em que métodos paramétricos tradicionais podem não ser adequados.
Além disso, o bootstrapping é usado com frequência em testes de hipótese e validação de modelos, ajudando a avaliar a robustez das predições. Em machine learning, o bootstrapping é a base do método de ensemble conhecido como bagging, usado em modelos como random forests para melhorar a precisão ao reduzir a variância.
Para ilustrar o bootstrapping, precisamos usar uma linguagem como R, que permite gerar vários conjuntos de dados reamostrados; sem um ambiente de programação, o processo seria demorado e complexo demais para fazer manualmente. Neste artigo, vamos bootstrapar os intervalos de confiança para uma distribuição e também para uma regressão linear usando o dataset Fish Market do Kaggle.
Antes de ver o bootstrapping em si, vale se familiarizar com a ideia de amostragem com reposição. No R base, a função sample() recebe pelo menos dois argumentos que precisam ser definidos: x e size. x define a lista ou faixa de valores de onde vamos amostrar e size define o tamanho da amostra. Há também o argumento replace, frequentemente especificado. Se nada for definido, o padrão é replace = FALSE.
Bootstrapping é amostrar com reposição. Ao amostrar com reposição, devolvemos o valor após cada sorteio. Assim, cada amostra é independente da anterior. Ao amostrar sem reposição, um valor selecionado não pode ser escolhido de novo; logo, dois valores amostrais não são independentes, e o resultado de um sorteio afeta o próximo. Uma consequência disso é que não podemos escolher um tamanho de amostra maior que o vetor de entrada a menos que definamos replace = TRUE. Com bootstrapping isso não é um problema, e podemos gerar um conjunto reamostrado bem maior que o original.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Vamos baixar o dataset e ler o arquivo da pasta de downloads no RStudio usando a função read.csv().
fish_df <- read.csv('~/Downloads/FISH.csv')Para começar, vamos criar um histograma da raiz quadrada do peso dos peixes para visualizar a distribuição. Ela está longe de ser normal (ou gaussiana) — se algo, parece até bimodal.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")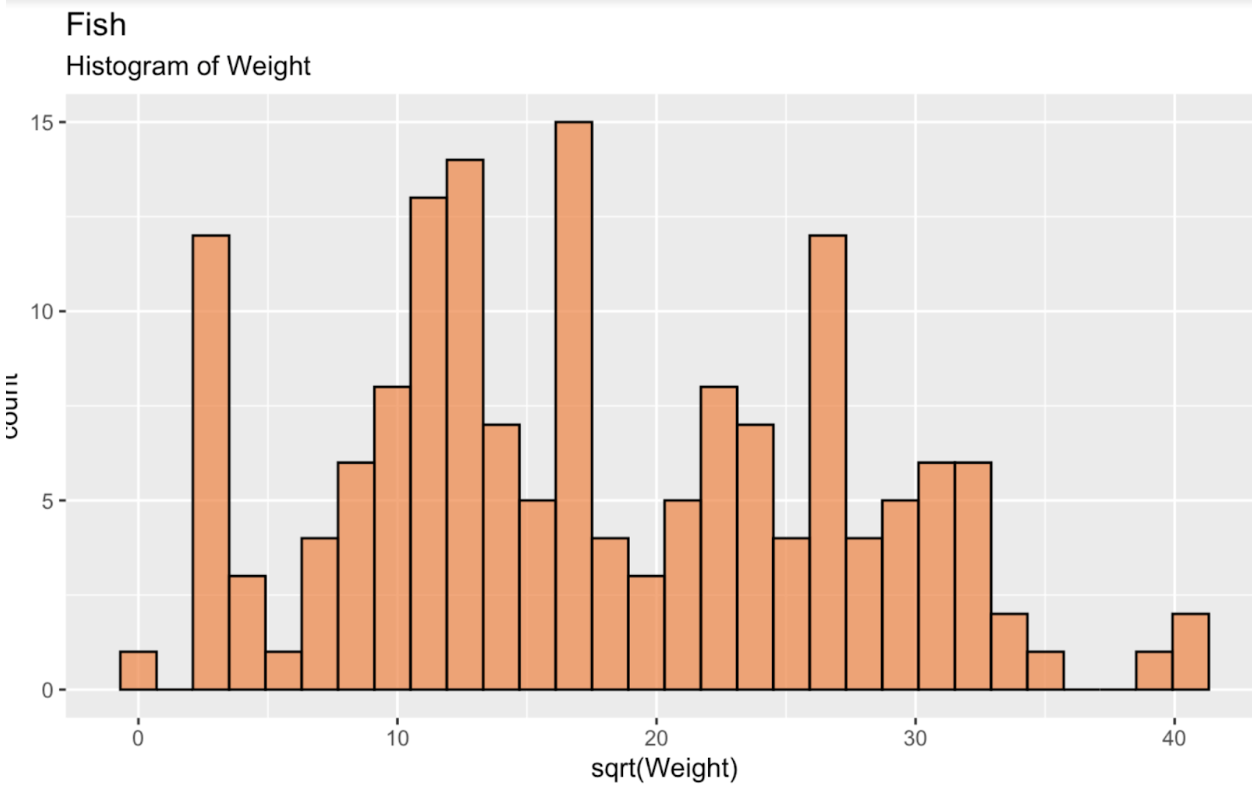
Histograma do peso dos peixes. Imagem do autor.
Podemos fazer bootstrapping no R usando o pacote infer da biblioteca tidymodels. Imprimir essa tabela no console gera um data frame com a estatística desejada para cada réplica. Ao criar uma nova distribuição dessas réplicas, obtemos uma distribuição aproximadamente normal, a partir da qual podemos gerar intervalos de confiança.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")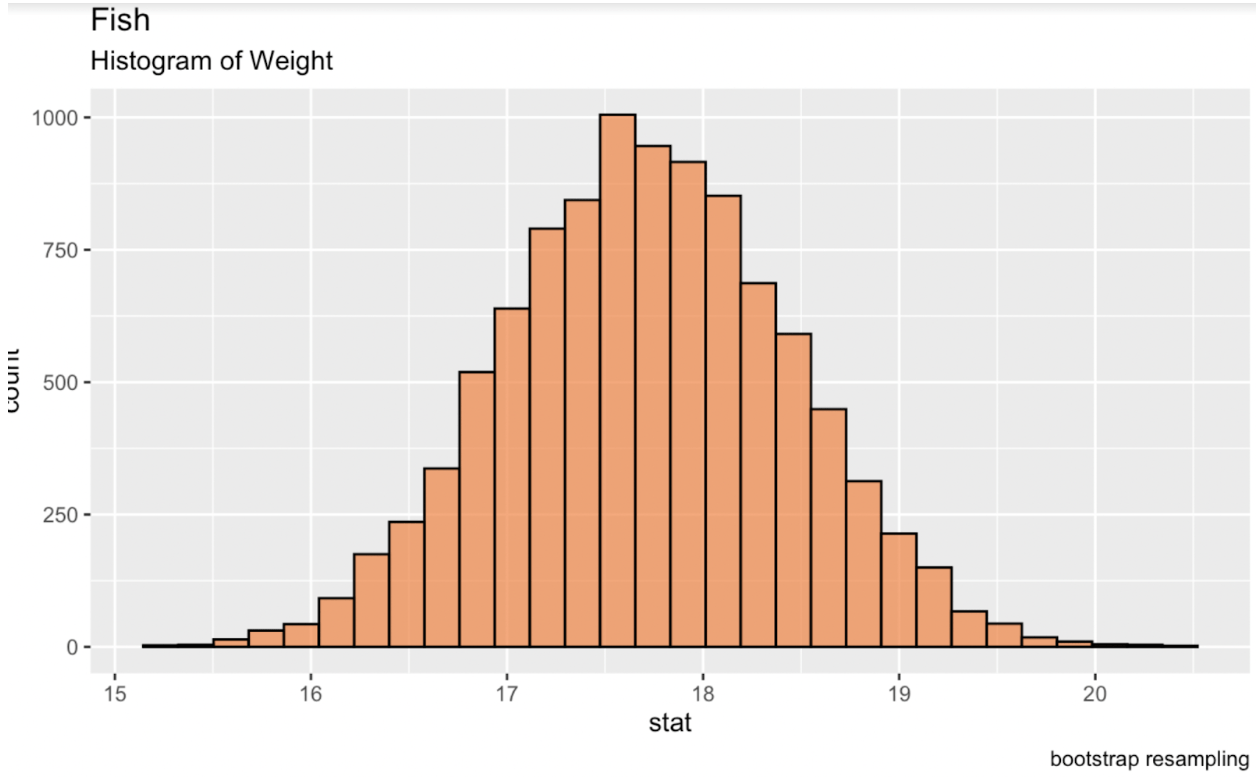 Histograma da média bootstrap do peso dos peixes. Imagem do autor.
Histograma da média bootstrap do peso dos peixes. Imagem do autor.
Regressão linear, a base da modelagem estatística, é usada para mostrar a relação entre uma ou mais variáveis independentes e uma variável dependente. Ao trabalhar com modelos de regressão, é comum avaliar a incerteza das estimativas. Uma forma é calcular intervalos de confiança da regressão linear, que fornecem uma faixa de valores na qual o parâmetro verdadeiro (como a média) provavelmente está. Aqui, vamos criar intervalos de confiança usando bootstrapping e também pelo método de aproximação normal, conhecido como intervalo de confiança de Wald.
No contexto de regressão linear, a reamostragem bootstrap envolve amostrar aleatoriamente do dataset para criar várias amostras bootstrap. Em seguida, ajustamos um modelo de regressão a cada amostra. Por fim, usamos a distribuição dos coeficientes do modelo nessas amostras para estimar intervalos de confiança. No código a seguir, usamos a função bootstraps() do pacote tidymodels para fazer a reamostragem bootstrap no nosso dataset. Depois, criamos histogramas para mostrar a faixa de valores presente nas reamostras para o intercepto e o coeficiente de peso.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')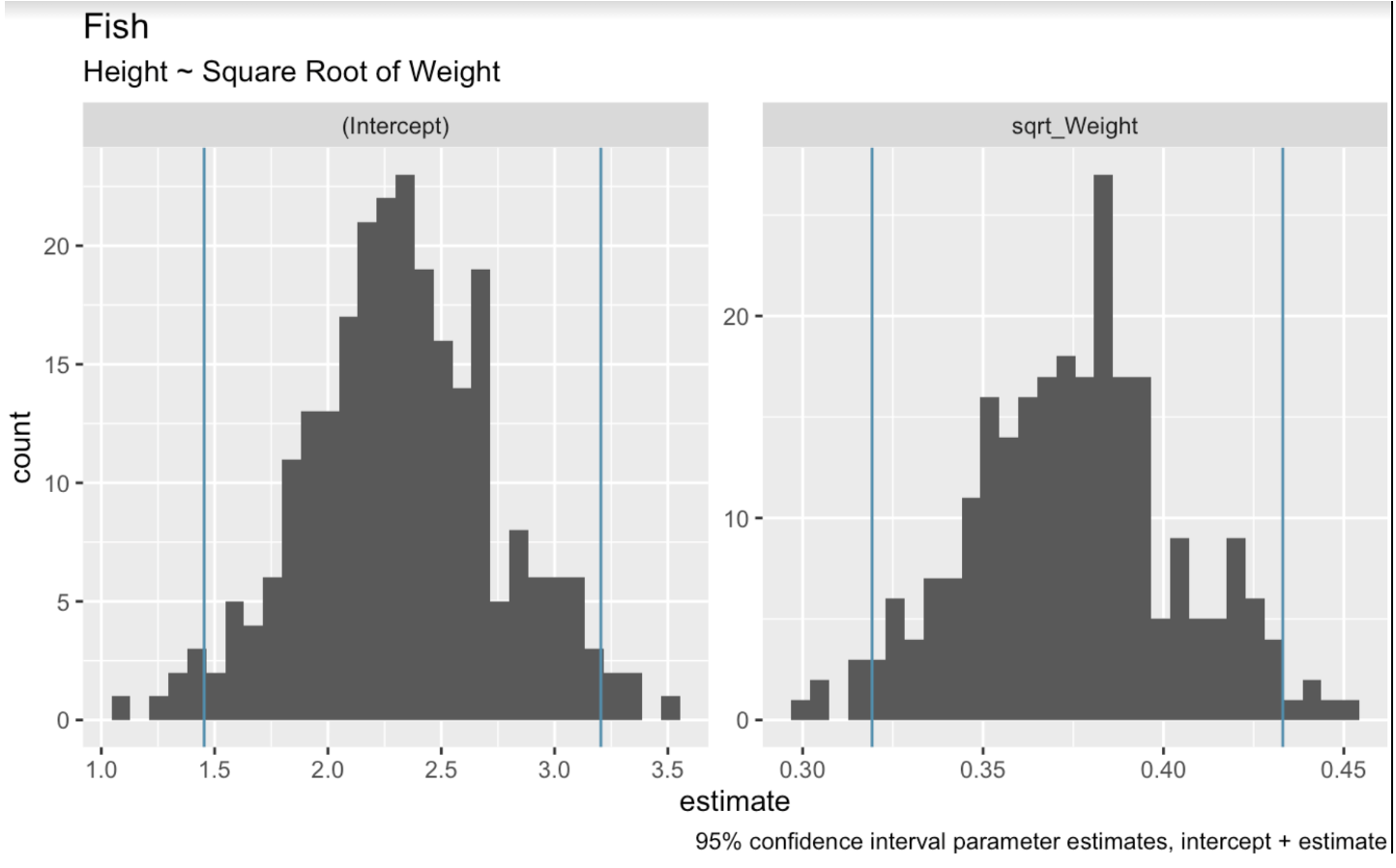
Coeficientes bootstrap do modelo linear. Imagem do autor.
Ao desenhar as possíveis retas de regressão, vamos cortar as mais extremas nas pontas para obter um intervalo de 95%. A função int_pctl() facilita isso.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Como passo final, vamos criar intervalos de confiança gerados pelas fórmulas fechadas mais teóricas. Podemos obter os parâmetros chamando summary() no objeto do nosso modelo linear.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Aqui, o coeficiente estimado para a variável sqrt_Weight é 0,37569. O erro-padrão de sqrt_Weight é 0,02186. Os graus de liberdade são 157 (ou seja, 159 observações no dataset menos dois parâmetros estimados). E o valor t para um intervalo de confiança bilateral de 95% é 1,975189. Sabemos esse número pela função qt(): qt(0.975, 157). Na visualização abaixo, as linhas azuis são as regressões lineares bootstrap e as linhas vermelhas tracejadas são o intervalo de confiança gerado pela fórmula analítica comum.
# Intervalo de confiança de Wald(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")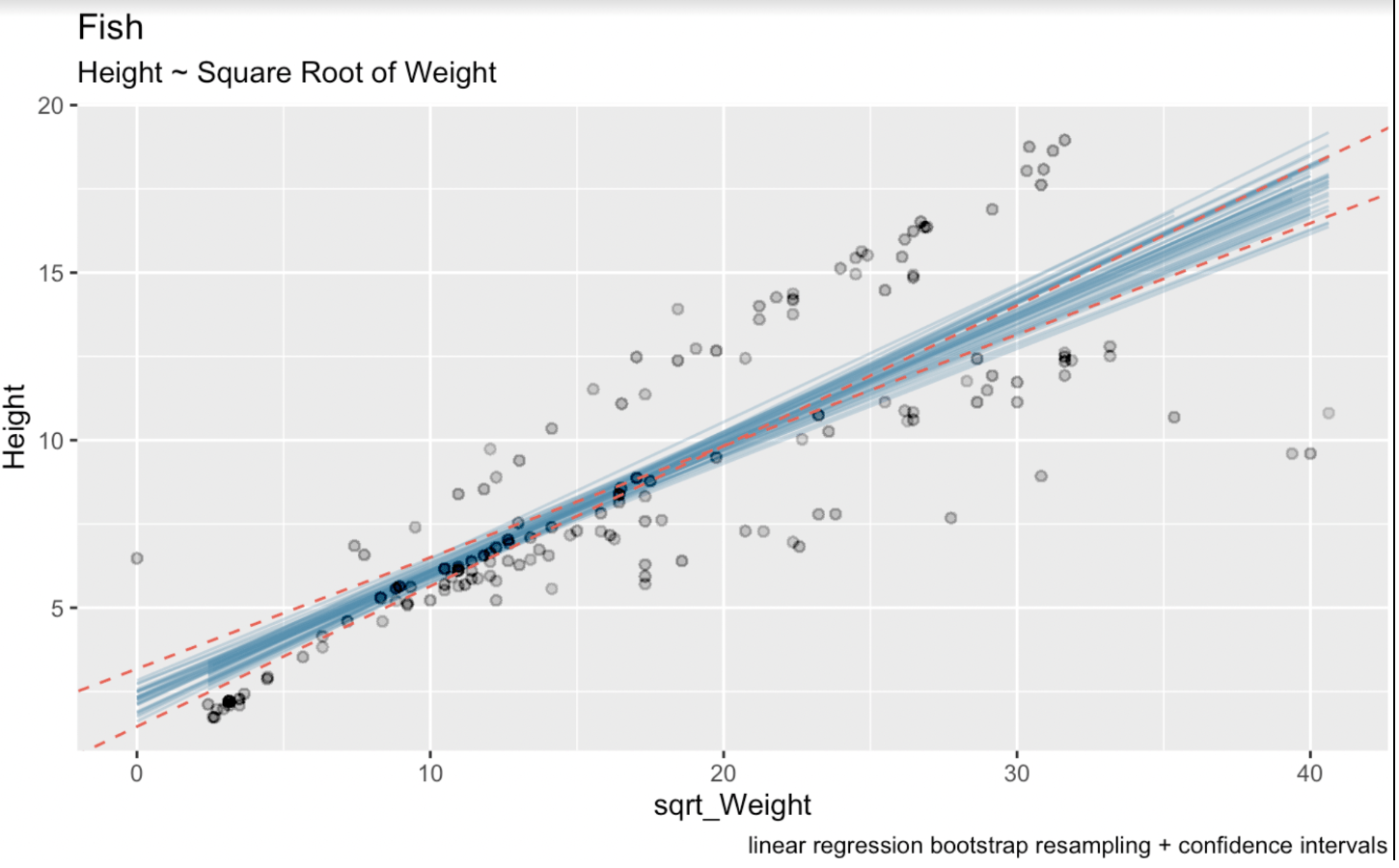
Regressões lineares com bootstrapping e intervalos de confiança. Imagem do autor.
Aqui vemos claramente que nosso processo de reamostragem por bootstrapping introduziu um pouco mais de incerteza na estimativa. Isso ocorre porque os intervalos da regressão linear foram calculados por fórmulas teóricas baseadas em suposições sobre a distribuição dos erros e as propriedades do estimador, como normalidade dos erros e variância constante.
O bootstrap, por sua vez, é livre de distribuição: faz hipóteses mínimas sobre a distribuição subjacente. Em vez disso, estima diretamente a distribuição amostral da estatística de interesse reamostrando dos dados observados. Como resultado, intervalos de confiança por bootstrap podem ser mais robustos e confiáveis quando as suposições dos métodos tradicionais são violadas ou quando lidamos com amostras pequenas — como no nosso dataset Fish Market, com 159 observações.
No bootstrapping paramétrico, fazemos suposições sobre a distribuição subjacente dos dados e geramos reamostras com base nessas suposições. Esse método é útil quando você tem conhecimento prévio ou suposições fortes sobre a distribuição dos dados. Pense em um conjunto de amostragem que talvez não seja normal, mas cujo mecanismo por trás da amostragem é bem conhecido, permitindo criar uma distribuição a partir de parâmetros da população.
Já o bootstrapping não paramétrico não faz suposições sobre a distribuição. Ele reamostra diretamente dos dados observados, com reposição, sendo particularmente valioso quando a distribuição verdadeira é desconhecida ou difícil de definir. No exemplo acima, usamos bootstrapping não paramétrico. Ambos os métodos permitem estimar estatísticas como erros-padrão e intervalos de confiança. No entanto, o não paramétrico oferece mais flexibilidade para dados do mundo real, especialmente com amostras pequenas ou complexas, e é o mais usado na prática.
Em previsão de séries temporais, o bootstrapping pode ser aplicado para reamostrar dados históricos e gerar previsões futuras, oferecendo uma distribuição de possíveis resultados em vez de um único ponto. Isso ajuda a modelar o leque de cenários futuros e criar intervalos de confiança para as predições. O bootstrapping também sustenta métodos de ensemble como bagging em modelos de séries temporais, que reduzem overfitting e melhoram a precisão ao combinar vários modelos. Nosso curso Forecasting in R vai te ensinar a reamostrar em previsão de séries, seja com ARIMA ou outro método.
Espero que você tenha passado a valorizar o bootstrapping, caso ainda não valorizasse. Como vimos, o bootstrapping é uma ferramenta poderosa em estatística e machine learning e oferece uma forma interessante de estimar a variabilidade e a confiança de medidas estatísticas sem exigir suposições fortes sobre os dados subjacentes.
Considere começar a nossa trilha de carreira Machine Learning Scientist in Python e se torne expert em trabalhar com tipos de distribuição e datasets complexos. Nossa trilha de habilidades Statistical Inference in R é outra ótima opção, com foco em testes de hipótese, randomização e medição de incerteza.
Aprenda com a DataCamp
Programa
Curso
Curso
blog
Arun Nanda
15 min
blog
Summer Worsley
15 min
Tutorial
Eladio Montero Porras
Tutorial
Tutorial
Somil Asthana
Tutorial
Vidhi Chugh


