
Lernpfad
Wissenschaftler für maschinelles Lernen in Python
85 Std.
In diesem Artikel schauen wir uns eine wichtige Technik in Statistik und Machine Learning an: Bootstrapping. Der Name geht zurück auf die Redewendung „sich an den eigenen Stiefelschlaufen hochziehen“, denn auch statistisch erlaubt Bootstrapping, mit wenig viel zu erreichen. Mit Bootstrapping kannst du aus einer Verteilung beliebiger Form oder Größe neue Resampling-Verteilungen erzeugen und diese nutzen, um die wahre Wahrscheinlichkeitsverteilung zu approximieren. Darum eignet sich Bootstrapping besonders gut, um Stichprobenschätzungen Genauigkeitsmaße wie Bias, Varianz, Konfidenzintervalle und Prognosefehler zuzuordnen.
Bevor wir starten: Wenn dich Data Science interessiert, probiere diese DataCamp-Kurse zu Data Science und Statistik aus, zum Beispiel unseren Statistical Inference in R-Lernpfad und den Kurs Foundations of Inference in Python.
Verorten wir Bootstrapping zunächst korrekt unter den Resampling-Methoden. Es gibt verschiedene Arten von Resampling, aber sie haben eines gemeinsam: Sie ahmen den Stichprobenprozess nach. Wir setzen Resampling ein, weil es unpraktisch ist, fortlaufend neue Stichproben aus der Grundgesamtheit zu ziehen – Resampling ist eine Art Abkürzung.
Wenn wir zum Beispiel etwas über unsere Zielpopulation lernen möchten, könnten wir eine Umfrage durchführen und auf tausend Antworten hoffen. Niemand wird jedoch dieselbe Umfrage tausendmal in derselben Zielgruppe erheben. Aufgrund dieser praktischen Einschränkung nutzen wir Resampling-Methoden, um Statistiken über unsere Stichprobe zu generieren, etwa den Standardfehler.
Es gibt vier Haupttypen von Resampling. Die anderen Verfahren lohnen sich zu erwähnen, weil sie eine gemeinsame Geschichte statistischer Innovation teilen. Insbesondere wurde Bootstrapping als Erweiterung, Modifikation oder Verbesserung der Jackknife-Methode entwickelt.
Es lohnt sich, kurz beim Jackknife zu verweilen, denn es ist ein Vorläufer des Bootstrappings. Bootstrapping wurde als Erweiterung und Verbesserung des Jackknife eingeführt, das in den 1950ern entstand – zu Zeiten, als Computer rund ein Kilobyte Speicher hatten.
Das Jackknife ist eine Leave-one-out-Resampling-Methode, die die interessierende Statistik berechnet – sukzessive, bis jede Beobachtung einmal entfernt wurde. Die Zahl der Resamples ist damit auf die Zahl der Beobachtungen begrenzt; deshalb performt Jackknife bei kleinen Stichproben eher schwach. Zudem ist Jackknife hinsichtlich der einsetzbaren Datentypen etwas eingeschränkt. Dafür ist es – im Gegensatz zum Bootstrap – jedes Mal exakt reproduzierbar.
Bootstrapping hat ein breites Einsatzspektrum in Statistik und Machine Learning. Besonders häufig wird es genutzt, um Konfidenzintervalle zu schätzen, wenn die zugrunde liegende Verteilung unbekannt ist oder die Stichprobe klein ist. Dadurch ist Bootstrapping besonders wertvoll, wenn klassische parametrische Methoden nicht passen.
Außerdem wird Bootstrapping oft in Hypothesentests und der Modellvalidierung eingesetzt, um die Robustheit von Vorhersagen zu bewerten. Im Machine Learning bildet Bootstrapping die Basis für das populäre Ensemble-Verfahren Bagging, das etwa in Random Forests die Genauigkeit durch Varianzreduktion steigert.
Um Bootstrapping zu veranschaulichen, brauchen wir eine Programmiersprache wie R – so können wir viele Resampling-Datensätze erzeugen; manuell wäre das zu aufwendig. In diesem Artikel bootstrappen wir Konfidenzintervalle für eine Verteilung und für eine lineare Regression mit dem Fish Market-Datensatz auf Kaggle.
Bevor wir ins Bootstrapping einsteigen, machen wir uns mit Sampling mit Zurücklegen vertraut. In Base R nimmt die Funktion sample() mindestens zwei Argumente, die explizit gesetzt werden: x und size. x definiert die Werte, aus denen wir ziehen, und size die Stichprobengröße. Häufig wird zudem das Argument replace gesetzt. Standard ist replace = FALSE.
Bootstrapping ist Sampling mit Zurücklegen. Dabei wird der gezogene Wert nach jedem Zug zurückgelegt. Jede Ziehung ist somit unabhängig von der vorherigen. Ohne Zurücklegen werden Werte nicht zurückgelegt; ein einmal gewählter Wert kann nicht erneut gewählt werden – die Stichprobenwerte sind also nicht unabhängig, und ein Ergebnis beeinflusst die Wahrscheinlichkeit der nächsten Ziehung. Konsequenz: Die Stichprobengröße darf die Länge des Eingabevektors nicht überschreiten, es sei denn, wir setzen replace = TRUE. Beim Bootstrapping besteht diese Einschränkung nicht; wir können eine gebootstrapte Resampling-Verteilung erzeugen, die deutlich größer ist als das Original.
sample_without_replacement <- sample(x = 1:10, size = 10) # replace = FALSE as defaultsample_with_replacement <- sample(x = 1:10, size = 10, replace = TRUE)sample_with_replacement_and_weighted_probability <- sample(x = c(1, 0), size = 10, replace = TRUE, prob = c(0.8, 0.2))Laden wir nun den Datensatz herunter und lesen ihn aus dem Download-Ordner in RStudio mit der Funktion read.csv() ein.
fish_df <- read.csv('~/Downloads/FISH.csv')Als Erstes erstellen wir ein Histogramm der Quadratwurzel des Fischgewichts, um die Verteilung zu sehen. Diese Verteilung ist, wie man erkennt, weit von einer normalen bzw. gaußschen Verteilung entfernt – eher leicht bimodal.
fish_df <- fish_df %>% mutate(sqrt_Weight = sqrt(Weight))ggplot(fish_df, aes(x = sqrt(Weight))) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")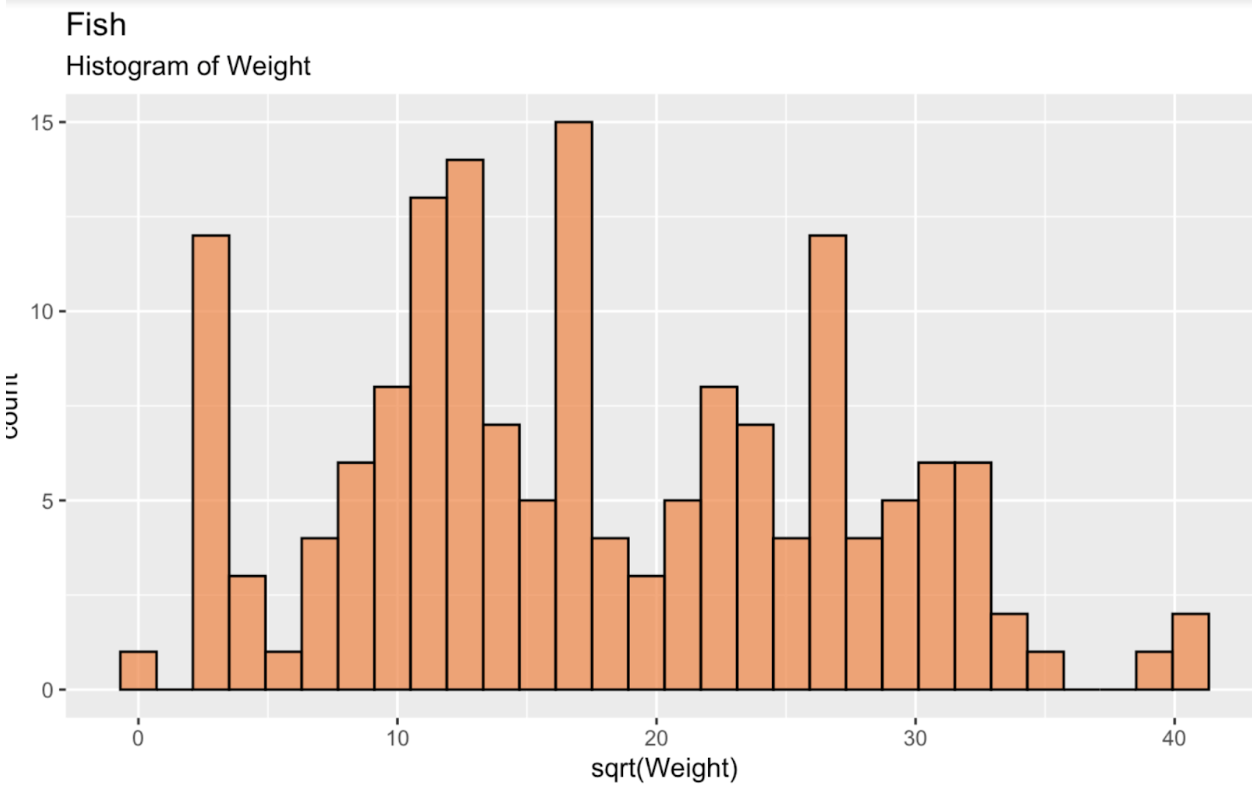
Histogramm des Fischgewichts. Bild: Autor.
Wir können in R mit dem Paket infer aus der tidymodels-Bibliothek bootstrappen. Die Ausgabe in der Konsole ist ein Data Frame mit der gewünschten Statistik je Replikat. Aus der Verteilung dieser Replikate entsteht eine annähernd normale Verteilung, aus der wir Konfidenzintervalle ableiten können.
library(tidymodels)fish_df %>% dplyr::select(sqrt_Weight) %>% specify(response = sqrt_Weight) %>% generate(reps = 10000, type = 'bootstrap') %>% calculate(stat = 'mean') -> fish_bootstrapped_ci_dfggplot(fish_bootstrapped_ci_df, aes(x = stat)) + geom_histogram(color = 'black', fill = '#ef8a47', alpha = 0.75) + labs(title = "Fish", subtitle = "Histogram of Weight")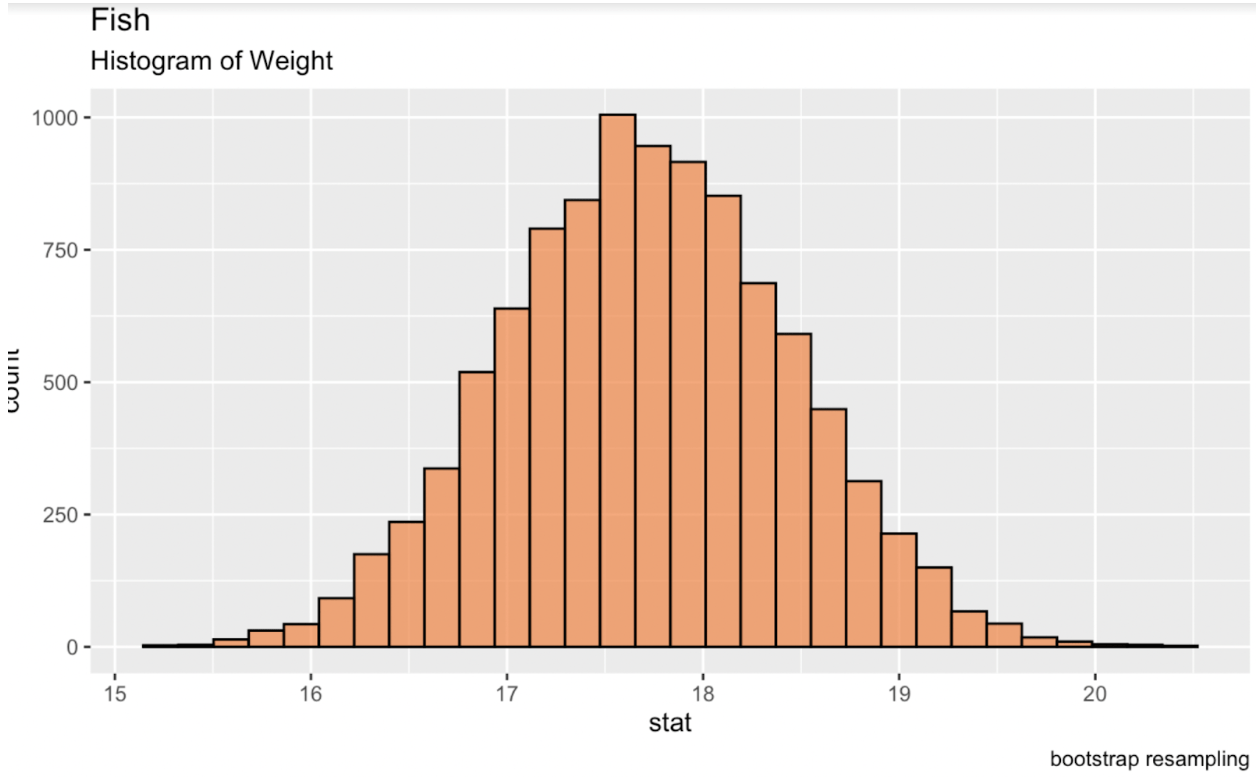 Histogramm des gebootstrapten Mittelwerts des Fischgewichts. Bild: Autor.
Histogramm des gebootstrapten Mittelwerts des Fischgewichts. Bild: Autor.
Lineare Regression, das Fundament vieler statistischer Modelle, zeigt den Zusammenhang zwischen einer oder mehreren unabhängigen Variablen und einer abhängigen Variable. Bei Regressionsmodellen schätzen wir häufig die Unsicherheit unserer Parameter. Eine Möglichkeit sind Konfidenzintervalle, die einen Bereich angeben, in dem der wahre Parameter (z. B. der Mittelwert) liegt. Hier erstellen wir Konfidenzintervalle per Bootstrapping und zusätzlich per Normalapproximation, auch Wald-Konfidenzintervall genannt.
Beim Bootstrapping im Kontext linearer Regression ziehen wir zufällig Stichproben aus dem Datensatz, erstellen daraus viele Bootstrap-Samples und fitten jeweils ein Regressionsmodell. Anschließend nutzen wir die Verteilung der Modellkoeffizienten über alle Samples hinweg, um Konfidenzintervalle zu schätzen. Im folgenden Code verwenden wir die Funktion bootstraps() aus tidymodels, um Bootstrap-Resampling durchzuführen, und visualisieren anschließend die Wertebereiche für Achsenabschnitt und Steigung.
boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)ggplot(boot_coefs, aes(estimate)) + geom_histogram(bins = 30) + facet_wrap( ~ term, scales = "free") + labs(title="fish", subtitle = "Height ~ Square Root of Weight") + labs(caption = "95% confidence interval parameter estimates, intercept + estimate") + geom_vline(aes(xintercept = .lower), data = percentile_intervals, col = '#528fad') + geom_vline(aes(xintercept = .upper), data = percentile_intervals, col = '#528fad')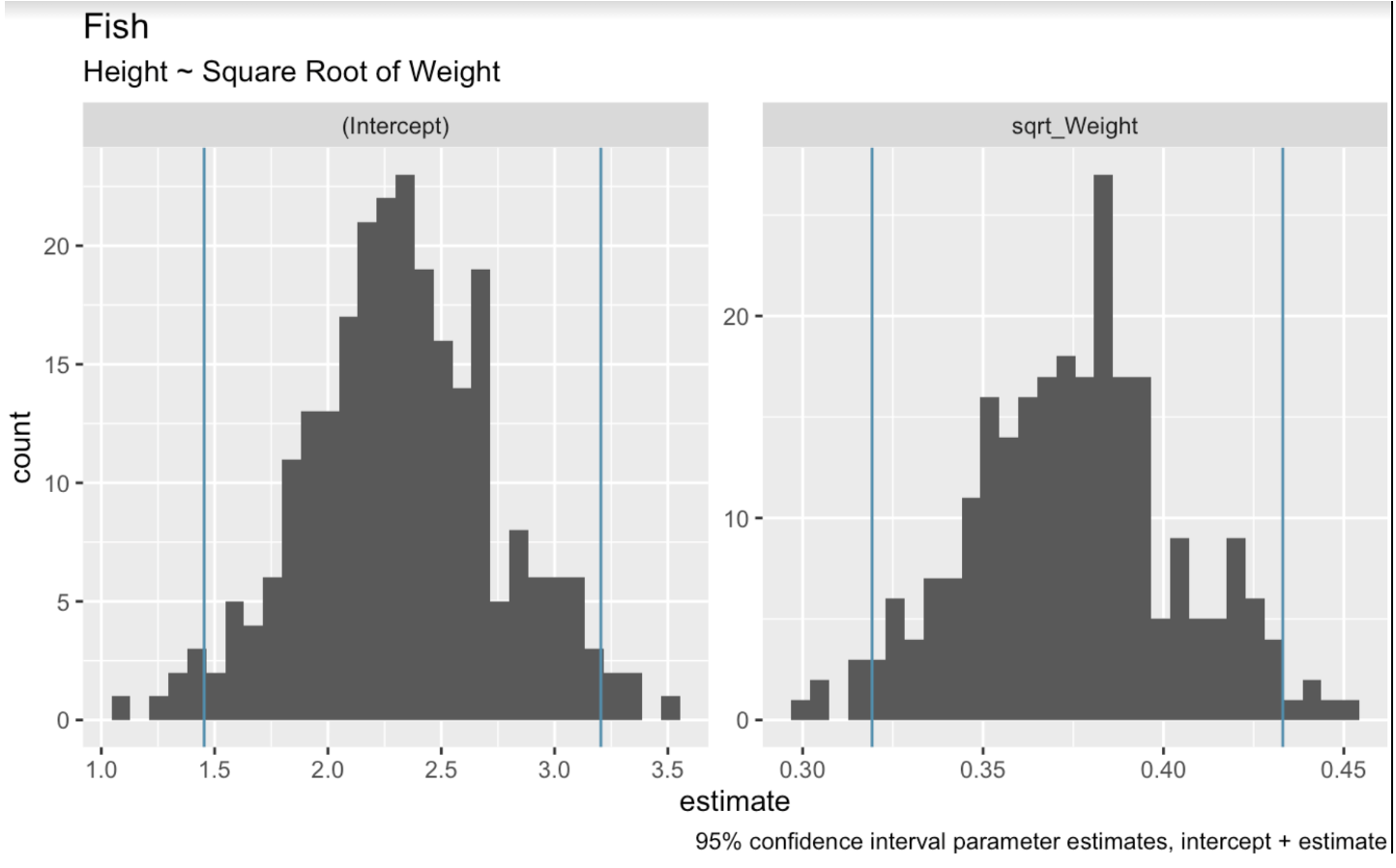
Gebootstrapte Koeffizienten des linearen Modells. Bild: Autor.
Wenn wir mögliche Regressionsgeraden darstellen, schneiden wir an beiden Enden die extremsten Linien ab, um ein 95%-Intervall zu erhalten. Die Funktion int_pctl() macht das einfach.
boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)boots <- bootstraps(fish_df, times = 250, apparent = TRUE)fit_lm_on_bootstrap <- function(split) { lm(Height ~ sqrt_Weight, analysis(split))}boot_models <- boots %>% dplyr::mutate(model = map(splits, fit_lm_on_bootstrap), coef_info = map(model, tidy))boot_coefs <- boot_models %>% unnest(coef_info)percentile_intervals <- int_pctl(boot_models, coef_info)boot_aug <- boot_models %>% sample_n(50) %>% mutate(augmented = map(model, augment)) %>% unnest(augmented)Zum Schluss erstellen wir Konfidenzintervalle über die theoretischen, geschlossenen Formeln. Die Parameter finden wir mit summary() auf dem Regressionsobjekt.
linear_model <- lm(Height ~ sqrt(Weight), fish_df)summary(linear_model)Call:lm(formula = Height ~ sqrt(Weight), data = fish_df)Residuals: Min 1Q Median 3Q Max-7.7425 -1.3611 -0.5628 2.2606 5.0131Coefficients: Estimate Std. Error t value Pr(>|t|)(Intercept) 2.31506 0.43636 5.305 3.77e-07 ***sqrt(Weight) 0.37569 0.02186 17.183 < 2e-16 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 2.533 on 157 degrees of freedomMultiple R-squared: 0.6529, Adjusted R-squared: 0.6506F-statistic: 295.3 on 1 and 157 DF, p-value: < 2.2e-16Hier beträgt der geschätzte Koeffizient für die Variable sqrt_Weight 0,37569. Der Standardfehler für sqrt_Weight ist 0,02186. Die Freiheitsgrade sind 157 (159 Beobachtungen minus zwei geschätzte Parameter). Der zweiseitige t-Wert für ein 95%-Konfidenzintervall ist 1,975189. Diesen Wert liefert die Funktion qt(): qt(0.975, 157). In der folgenden Visualisierung sind die blauen Linien die gebootstrapten Regressionsgeraden, die roten gestrichelten Linien zeigen das über die gängige analytische Formel berechnete Konfidenzintervall.
# Wald-Konfidenzintervall(CI_upper <- 0.37569 + 1.975 * 0.02186)(CI_lower <- 0.37569 - 1.975 * 0.02186)(CI_intercept_upper <- 2.31506 + 1.975 * 0.43636)(CI_intercept_lower <- 2.31506 - 1.975 * 0.43636)ggplot(boot_aug, aes(sqrt_Weight, Height)) + geom_line(aes(y = .fitted, group = id), alpha = .3, col = '#528fad') + geom_point(alpha = 0.005) + labs(title="fish", subtitle = "Height ~ Weight") + labs(caption = "linear regression bootstrap resampling") + geom_abline(intercept = 1.453249, slope = 0.4188635, linetype = "dashed", color = "#e76254") + geom_abline(intercept = 3.176871, slope = 0.3325165, linetype = "dashed", color = "#e76254")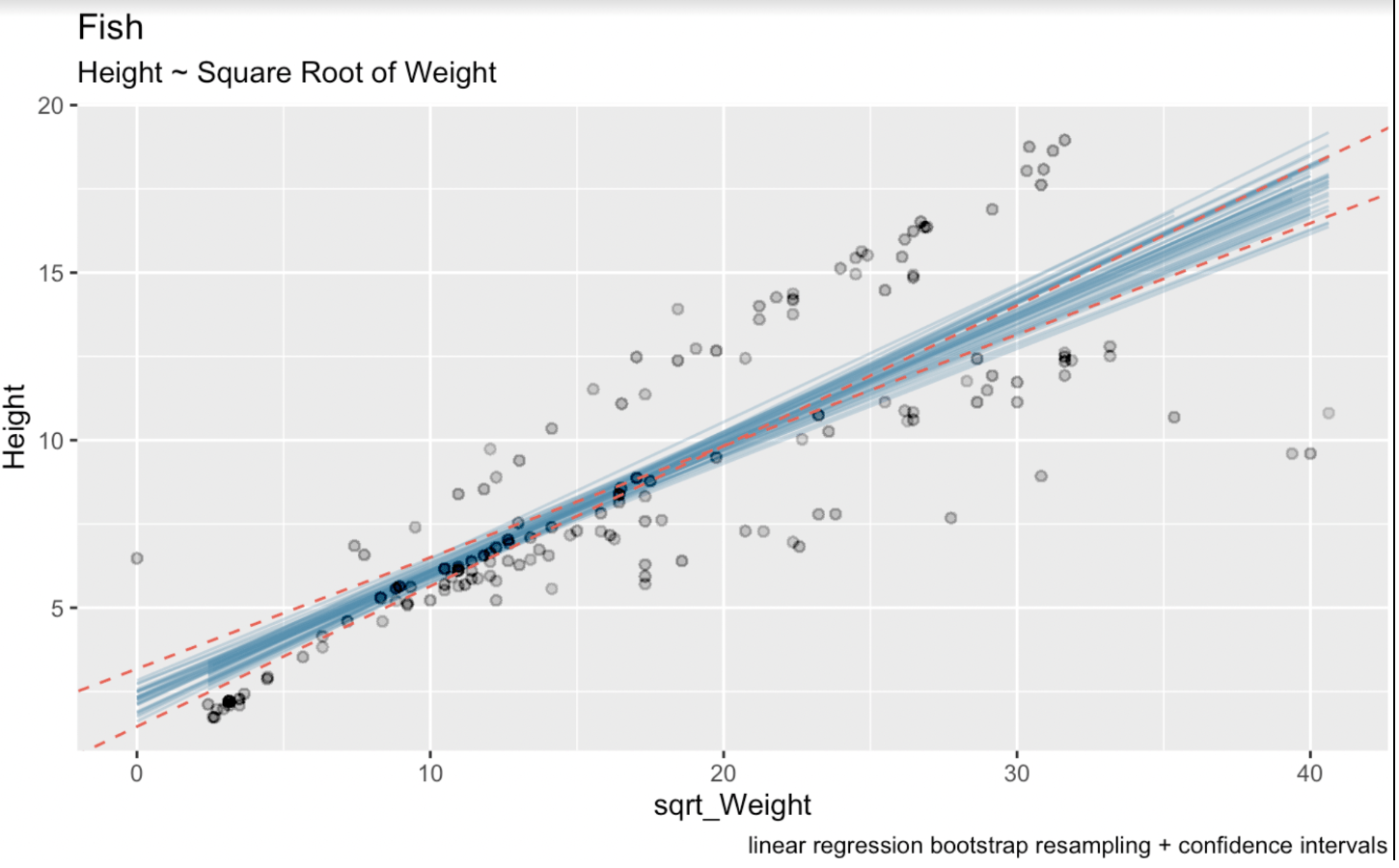
Gebootstrapte lineare Regressionen mit Konfidenzintervallen. Bild: Autor.
Hier sehen wir klar, dass unser Bootstrap-Resampling etwas mehr Unsicherheit in die Schätzung bringt. Das liegt daran, dass die Intervalle für Regressionskoeffizienten über theoretische Formeln berechnet wurden, die Annahmen über die Fehlerverteilung und die Eigenschaften des Schätzers voraussetzen – etwa Normalverteilung der Fehler und konstante Varianz.
Bootstrap-Resampling ist hingegen verteilungsfrei und trifft nur minimale Annahmen über die zugrunde liegende Datenverteilung. Stattdessen wird die Stichprobenverteilung der interessierenden Statistik direkt durch Resampling aus den beobachteten Daten geschätzt. Daher können Bootstrap-Konfidenzintervalle robuster und verlässlicher sein, wenn die Annahmen klassischer Methoden verletzt sind oder wenn die Stichprobe klein ist – wie in unserem Fish Market-Datensatz mit 159 Beobachtungen.
Beim parametrischen Bootstrapping treffen wir Annahmen über die zugrunde liegende Verteilung und generieren Resamples basierend darauf. Das ist sinnvoll, wenn Vorwissen oder starke Annahmen zur Verteilung vorliegen. Denk etwa an ein Stichprobenszenario ohne Normalverteilung, bei dem der Prozess dahinter aber gut verstanden ist – dann lässt sich mithilfe von Populationsparametern eine Verteilung konstruieren.
Nichtparametrisches Bootstrapping macht dagegen keine Verteilungsannahmen. Es resampelt direkt mit Zurücklegen aus den beobachteten Daten und ist daher besonders wertvoll, wenn die wahre Verteilung unbekannt oder schwer zu beschreiben ist. In unserem Beispiel oben haben wir nichtparametrisch gebootstrappt. Beide Methoden erlauben die Schätzung von Größen wie Standardfehlern und Konfidenzintervallen. In der Praxis ist das nichtparametrische Bootstrapping jedoch flexibler – insbesondere bei realen, kleinen oder komplexen Datensätzen – und wird daher häufiger eingesetzt.
In der Zeitreihenprognose kann Bootstrapping eingesetzt werden, um historische Daten zu resampeln und Vorhersagen zu generieren – nicht nur als Punktprognose, sondern als Verteilung möglicher Ergebnisse. Das hilft, die Spannbreite künftiger Szenarien abzubilden und Konfidenzintervalle für Prognosen zu erstellen. Bootstrapping bildet zudem die Grundlage für Ensemble-Methoden wie Bagging in Zeitreihenmodellen, die Overfitting reduzieren und die Prognosegenauigkeit durch die Kombination mehrerer Modelle verbessern. Unser Kurs Forecasting in R zeigt dir, wie du im Zeitreihenkontext resamplest – ob mit ARIMA oder anderen Verfahren.
Ich hoffe, du hast Bootstrapping schätzen gelernt – falls nicht schon geschehen. Wie gesehen, ist es ein starkes Werkzeug in Statistik und Machine Learning und bietet einen eleganten Weg, die Varianz und Sicherheit statistischer Maße zu schätzen, ohne starke Annahmen über die Daten treffen zu müssen.
Starte zum Beispiel unseren Machine Learning Scientist in Python-Karrierepfad und werde sicher im Umgang mit Verteilungen und komplexen Datensätzen. Eine weitere gute Option ist unser Statistical Inference in R-Lernpfad mit Fokus auf Hypothesentests, Randomisierung und Unsicherheitsmessung.
Lerne mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui

